data mining an introduction. definitions data mining is … knowledge discovery using sophisticated...
TRANSCRIPT

Data Mining
An Introduction

Definitions
• Data Mining is …knowledge discovery using sophisticated blend of techniques from traditional statistics, artificial intelligence and computer graphics.
• Data mining is … discovery of useful, possibly unexpected, patterns in data.

Definitions
• Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and to summarize the data in novel ways that are both understandable and useful to the data owner
• Data mining is the extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from data in large databases.

Goals of Data Mining
• Explanatory– To explain some observed event or condition, e.g., why
sales of trucks has increased in region A?• Confirmatory
– To confirm a hypothesis, e.g., whether two-income families are more likely to buy family medical coverage as compared to single-income families
• Exploratory– To analyze data for new or unexpected relationships, e.g.,
what spending patterns are likely to accompany credit card fraud?

Data Mining Techniques
• Data mining can be performed on a data mart or EDW.
• Depending on the nature of the data to be analyzed and size of data set, any of the following techniques can be used:– Regression
• Test or discover relationships from historical data
– Decision tree induction• Test or discover ‘if…Then’ rules for decision tendency
– Clustering and Signal Processing• Discover subgroups or segments

Data Mining Techniques(Contd.)– Affinity
• Discover things with strong mutual relationships
– Sequence Association• Discover cycles of events & behaviours
– Case-based reasoning• Derives rules from real-world case examples
– Rule discover• Searches for patterns & correlations in large datasets
– Fractals• Compresses large databases without losing information
– Neural nets• Develops predictive models based on principles modeled after
human brain

Analytical Processing vs. Models
• To a database person, data-mining is a powerful form of analytic processing --- queries that examine large amounts of data.– Result is the data that answers the query.
• To a statistician, data-mining is the inference of models.– Result is the parameters of the model

Data Mining & Knowledge Discovery in Databases
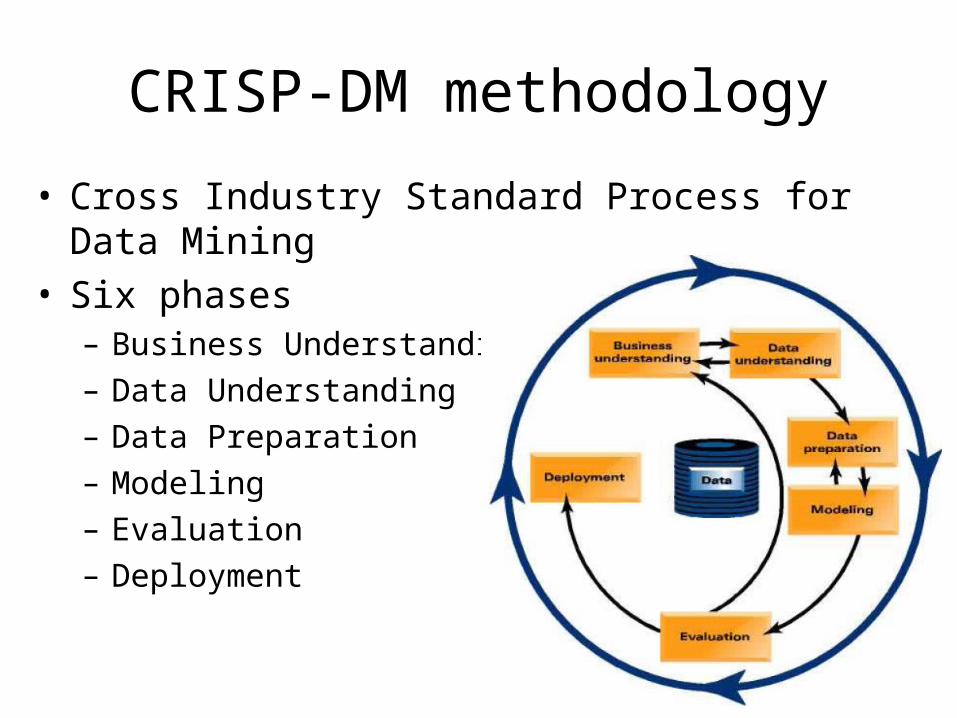
CRISP-DM methodology
• Cross Industry Standard Process for Data Mining• Six phases
– Business Understanding– Data Understanding– Data Preparation– Modeling– Evaluation– Deployment

Data Mining Applications• Profiling Populations
– Developing profiles of a high-value customers, credit risks, and credit-card frauds
• Analysis of business trends– Identifying markets with above/below average growth
• Target marketing– Identifying customers for promotional activity
• Usage analysis– Identifying usage patterns for products and services
• Campaign effectiveness– Comparing campaign strategies for effectivesness

Data Mining Applications• Product Affinity
– Identifying products that are purchased concurrently, or the shoppers characteristics for certain product groups
• Customer retention and churn– Examining the behaviour of customers who left for
competitors to prevent remaining customers from leaving• Profitability analysis
– Determining which customers are profitable• Customer Value Analysis
– Determining where valuable customers are at different stages in their life

Data Mining Applications
• Up-selling– Identifying new products and services to sell to a customer
based upon critical events and life-style changes• Intelligence gathering
– total information awareness• Web analysis
– Ranking web pages• Financial
– predict price movements to make better investments

13
Frequent ItemSets and
“Association Rules”
Some related concepts to Data Mining
Slides by Jeffrey Ullman, Stanford

14
The Market-Basket Model
• A large set of items, e.g., things sold in a supermarket.
• A large set of baskets, each of which is a small set of the items, e.g., the things one customer buys on one day.

15
Association Rule Mining
tran1 cust33 p2, p5, p8tran2 cust45 p5, p8, p11tran3 cust12 p1, p9tran4 cust40 p5, p8, p11tran5 cust12 p2, p9tran6 cust12 p9
transactio
n
id custo
mer
id products
bought
salesrecords:
• Trend: Products p5, p8 often bought together
market-basketdata

16
Support
• Simplest question: find sets of items that appear “frequently” in the baskets.
• Support for itemset I = the number of baskets containing all items in I.
• Given a support threshold s, sets of items that appear in > s baskets are called frequent itemsets.

17
Applications --- (1)
• Real market baskets: chain stores keep terabytes of information about what customers buy together.– Tells how typical customers navigate stores, lets
them position tempting items.– Suggests tie-in “tricks,” e.g., run sale on diapers
and raise the price of beer.
• High support needed, or no $$’s .

18
Applications --- (2)
• “Baskets” = documents; “items” = words in those documents.– Lets us find words that appear together unusually
frequently, i.e., linked concepts.
• “Baskets” = sentences, “items” = documents containing those sentences.– Items that appear together too often could
represent plagiarism.

19
Applications --- (3)
• “Baskets” = Web pages; “items” = linked pages.– Pairs of pages with many common references may
be about the same topic.
• “Baskets” = Web pages p ; “items” = pages that link to p .– Pages with many of the same links may be mirrors
or about the same topic.

20
Important Point
• “Market Baskets” is an abstraction that models any many-many relationship between two concepts: “items” and “baskets.”– Items need not be “contained” in baskets.
• The only difference is that we count co-occurrences of items related to a basket, not vice-versa.

21
Scale of Problem
• WalMart sells 100,000 items and can store billions of baskets.
• The Web has over 100,000,000 words and billions of pages.

22
Association Rules
• If-then rules about the contents of baskets.• {i1, i2,…,ik} → j means: “if a basket contains all
of i1,…,ik then it is likely to contain j.
• Confidence of this association rule is the probability of j given i1,…,ik.

23
ExampleB1 = {m, c, b} B2 = {m, p, j}B3 = {m, b} B4 = {c, j}B5 = {m, p, b} B6 = {m, c, b, j}B7 = {c, b, j} B8 = {b, c}
• An association rule: {m, b} → c.– Confidence = 2/4 = 50%.
+_
_ +

24
Interest
• The interest of an association rule is the absolute value of the amount by which the confidence differs from what you would expect, where items are selected independently of one another.

25
ExampleB1 = {m, c, b} B2 = {m, p, j}B3 = {m, b} B4 = {c, j}B5 = {m, p, b} B6 = {m, c, b, j}B7 = {c, b, j} B8 = {b, c}
• For association rule {m, b} → c, item c appears in 5/8 of the baskets.
• Interest = | 2/4 - 5/8 | = 1/8 --- not very interesting.

26
Relationships Among Measures• Rules with high support and confidence may
be useful even if they are not “interesting.”– We don’t care if buying bread causes people to
buy milk, or whether simply a lot of people buy both bread and milk.
• But high interest suggests a cause that might be worth investigating.

27
Finding Association Rules
• A typical question: “find all association rules with support ≥ s and confidence ≥ c.”– Note: “support” of an association rule is the
support of the set of items it mentions.
• Hard part: finding the high-support (frequent ) itemsets.– Checking the confidence of association rules
involving those sets is relatively easy.

28
Computation Model
• Typically, data is kept in a “flat file” rather than a database system.– Stored on disk.– Stored basket-by-basket.– Expand baskets into pairs, triples, etc. as you read
baskets.

29
Computation Model --- (2)
• The true cost of mining disk-resident data is usually the number of disk I/O’s.
• In practice, association-rule algorithms read the data in passes --- all baskets read in turn.
• Thus, we measure the cost by the number of passes an algorithm takes.

30
Main-Memory Bottleneck
• In many algorithms to find frequent itemsets we need to worry about how main memory is used.– As we read baskets, we need to count something,
e.g., occurrences of pairs.– The number of different things we can count is
limited by main memory.– Swapping counts in/out is a disaster.

31
Finding Frequent Pairs
• The hardest problem often turns out to be finding the frequent pairs.

Other Effective Approaches
• Naïve Algorithm• A-Priori Algorithm