data-intensive science in the us doe: case studies and future challenges
TRANSCRIPT

14 This arTicle has been peer-reviewed. Computing in SCienCe & engineering
B i g D a t a
Given its leading role in high-performance computing for modeling and simulation and its many experimental facilities, the US Department of Energy has a tremendous need for data-intensive science. Locating the challenges and commonalities among three case studies illuminates, in detail, the technical challenges involved in realizing data-intensive science.
Data-Intensive Science in the US DOE: Case Studies and Future Challenges
T he growing ubiquity and volume of data are changing the landscape of commerce, science, and national se-curity. Companies like Google use a
form of data-intensive computing to organize in-formation for the mass market. The US Depart-ment of Defense maintains situational awareness through numerous sensors and data-intensive computing. The US National Oceanic and Atmo-spheric Administration (NOAA) and NASA gen-erate vast quantities of earth observational data that, with the help of data-intensive computing,
can be used to answer questions about planetary dynamics and ecosystems.
The US Department of Energy’s diverse mis-sions also rely heavily on the ability to extract meaning from data. Like scientists worldwide, DOE researchers rely on the Internet for knowl-edge discovery and make use of bibliometrics and textual analysis of scientific publications. Like other large organizations, the DOE defends its computer networks by analyzing large data streams in real time and identifying malicious content.
In these and other areas, the DOE’s data- centric computing needs are similar to those of other organizations. But there are two broad cat-egories in which DOE’s missions lead to unique data-centric computing needs; those two areas are our focus here.
First, the DOE is internationally acknowledged as a leader in the use of advanced computing to simulate complex physical and engineering sys-tems. DOE researchers routinely compute de-tailed models of time-dependent 3D systems on the world’s largest computers. These simulations generate enormous datasets that are difficult to extract and archive, let alone analyze. More com-prehensive analysis of this data would help in the discovery and identification of unanticipated phenomena, and also help expose shortcomings in the simulation methodologies and software.
James P. AhrensLos Alamos National LaboratoryBruce HendricksonSandia National LaboratoriesGabrielle LongArgonne National LaboratorySteve MillerOak Ridge National LaboratoryRobert RossArgonne National LaboratoryDean WilliamsLawrence Livermore National Laboratory
1521-9615/11/$26.00 © 2011 ieee
CopubliShed by the ieee CS and the aip
CISE-13-6-Hendrik.indd 14 10/19/11 5:30 PM

november/deCember 2011 15
As leadership-class computers continue to grow in size, the data analysis problems they inspire will be a major scientific challenge.
Second, the DOE manages some of the na-tion’s most advanced experimental resources, and these facilities generate tremendous amounts of data. Datasets generated at the DOE’s advanced facilities today significantly outstrip current analysis capabilities. As these facilities anticipate significant upgrades, the problem will increase tenfold and more. When datastreams aren’t opti-mally exploited, scientific discovery is delayed or missed. Also, real-time analysis of the data as it’s being generated would enable intelligent design and refinement of the experimental process. This would improve the utilization of the facility and the quality of science produced. This isn’t possible with current workflows and analytic capabilities.
Case StudiesTo paint a clearer picture of the potential opportu-nities that we’re missing, as well as dilemmas caused by not having better data analysis capabilities, here we look at case studies in three areas: scientific and engineering simulation data, climate data, and x-ray and neutron scattering data.
Case 1: Scientific and Engineering Simulation DataComputational modeling and simulation is central to numerous scientific and engineering domains. Computational results provide scientific insights that complement those of theory and experiment. The DOE is an acknowledged leader in com-putational simulation, with state-of-the-art facil-ities and simulation codes. Basic simulation data is often 4D (three spatial dimensions and time), but additional variable types, such as vector or tensor fields, multiple variables, multiple spatial scales, parameter studies, and uncertainty analysis can increase the dimensionality. There’s no shortage of DOE applications that push the state of the art in high-performance computing (HPC). These include fusion, nuclear energy, climate, national security, materials science, chemistry, biology, and more. In all of these scientific domains, high-end simulations can generate copious amounts of data. Workflows and systems for managing and analyzing this data are already at the breaking point. And as computations grow in complexity and fidelity and run on larger computers, the anal-ysis of the data they generate will become more challenging still.
As just one example, nuclear energy research-ers are contemplating the use of simulation to
understand the design space for new advanced nuclear reactors, to accelerate the design of such systems, and to optimize these designs. The codes developed to perform these calculations will lever-age the most efficient algorithms possible and take advantage of the most powerful computers avail-able. For these kinds of high-consequence simula-tions, it’s essential that the codes be verified and validated, and that uncertainties be quantitatively understood. This requires an adaptive approach, combining simulation and experimentation to re-solve ambiguity and refine understanding.
A standard approach for analyzing and ar-chiving computational data involves two distinct subsystems attached to the simulation platform via a large switch complex. A separate subsystem consisting of many storage servers backed by en-terprise storage provides the raw storage for scien-tific data. An analysis cluster, also attached to the switch complex, is available to analyze archived data. But this approach requires that data be moved off the simulation machine prior to analy-sis. As the gap between compute performance and I/O performance grows, data-generation rates are increasingly problematic, and scientists are strug-gling to reduce their data output to minimize the cost to write data at runtime and analyze the data subsequently.
The DOE’s detailed simulations require the fastest and largest supercomputers available to-day and in the future. The largest supercomputer today is in the petascale class; current planning is focused on exascale class machines. The chip, memory, and networking technology trends that drive exascale architectures suggest that limiting factors include power and therefore data move-ment (a power-intensive operation). Because data movement dominates the computational costs at exascale, rethinking the entire data analysis pro-cess is required.
An in-depth data triage must occur while the data resides in the memory of the supercomput-ing platform. This will require fundamentally new, massively parallel data-reduction algorithms to effectively analyze these massive datasets. Ex-ample approaches include statistical and compres-sion techniques that downsample the data before transfer. These approaches can provide multiple levels of resolution that highlight areas of interest to the scientist. A key approach is the integration of science-driven feature-extraction algorithms that identify higher-order structures from the simu-lation results. These structures are information- rich but smaller in size than the massive datasets they’re derived from.
CISE-13-6-Hendrik.indd 15 10/19/11 5:30 PM
16 Computing in SCienCe & engineering
An important aspect of this process is preserv-ing the analyzed data’s scientific integrity. Re-cording the data’s provenance—that is, how it was created and processed—as well as understanding if and when bias is introduced during the analysis process supports reproducible science. Data man-agement processes that support effective data ar-chiving, curation, and sharing must be part of the analysis workflow from beginning to end.
An additional challenge comes from the increas-ing analytical complexity required for further sci-entific insight. Good methods exist for visualizing several variables in a subset of the simulation out-put. However, as simulations gain complexity and fidelity, it’s necessary to explore the output more holistically to search for unexpected behavior. This is essential to the validation process, and also
to the scientific discovery process. Exploratory analysis requires efficient techniques for access-ing disparate portions of the simulation output, and a high degree of user interactivity. However, methods for exploring fundamental issues like un-certainty quantification remain in their infancy. These kinds of advanced analysis capabilities are quite difficult to provide for large datasets.
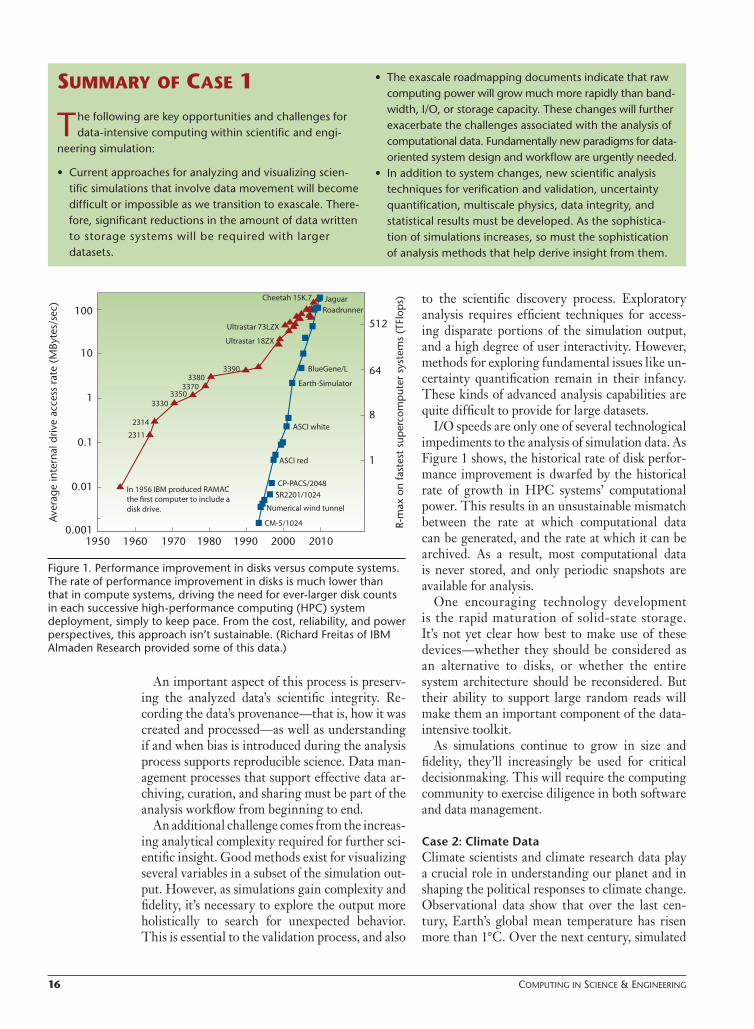
I/O speeds are only one of several technological impediments to the analysis of simulation data. As Figure 1 shows, the historical rate of disk perfor-mance improvement is dwarfed by the historical rate of growth in HPC systems’ computational power. This results in an unsustainable mismatch between the rate at which computational data can be generated, and the rate at which it can be archived. As a result, most computational data is never stored, and only periodic snapshots are available for analysis.
One encouraging technology development is the rapid maturation of solid-state storage. It’s not yet clear how best to make use of these devices—whether they should be considered as an alternative to disks, or whether the entire system architecture should be reconsidered. But their ability to support large random reads will make them an important component of the data- intensive toolkit.
As simulations continue to grow in size and fidelity, they’ll increasingly be used for critical decisionmaking. This will require the computing community to exercise diligence in both software and data management.
Case 2: Climate DataClimate scientists and climate research data play a crucial role in understanding our planet and in shaping the political responses to climate change. Observational data show that over the last cen-tury, Earth’s global mean temperature has risen more than 1°C. Over the next century, simulated
Figure 1. Performance improvement in disks versus compute systems. The rate of performance improvement in disks is much lower than that in compute systems, driving the need for ever-larger disk counts in each successive high-performance computing (HPC) system deployment, simply to keep pace. From the cost, reliability, and power perspectives, this approach isn’t sustainable. (Richard Freitas of IBM Almaden Research provided some of this data.)
Aver
age
inte
rnal
driv
e ac
cess
rat
e (M
Byte
s/se
c)
R-m
ax o
n fa
stes
t su
per
com
put
er s
yste
ms
(TFl
ops)
100512
64
8
1
10
1
0.1
0.01
0.0011950 1960 1970 1980 1990 2000 2010
Cheetah 15K.7 JaguarRoadrunner
BlueGene/L
Earth-Simulator
ASCI white
ASCI red
CP-PACS/2048SR2201/1024
Numerical wind tunnel
CM-5/1024
In 1956 IBM produced RAMACthe �rst computer to include adisk drive.
Ultrastar 73LZX
Ultrastar 18ZX
33903380
33703350
3330
2314
2311
Summary of CaSe 1
The following are key opportunities and challenges for data-intensive computing within scientific and engi-
neering simulation:
• Current approaches for analyzing and visualizing scien-tific simulations that involve data movement will become difficult or impossible as we transition to exascale. There-fore, significant reductions in the amount of data written to storage systems will be required with larger datasets.
• The exascale roadmapping documents indicate that raw computing power will grow much more rapidly than band-width, I/O, or storage capacity. These changes will further exacerbate the challenges associated with the analysis of computational data. Fundamentally new paradigms for data-oriented system design and workflow are urgently needed.
• In addition to system changes, new scientific analysis techniques for verification and validation, uncertainty quantification, multiscale physics, data integrity, and statistical results must be developed. As the sophistica-tion of simulations increases, so must the sophistication of analysis methods that help derive insight from them.
CISE-13-6-Hendrik.indd 16 10/19/11 5:30 PM

november/deCember 2011 17
data predict another 3 to 6°C increase because of the burning of fossil fuels and other human activities.1
To help better understand the consequences of global warming, scientists are looking at a diverse set of data sources obtained from model simula-tion experiments, remote sensors (such as radar and satellites), and mobile as well as in situ obser-vational platforms (such as a radiosonde measur-ing a parcel of air or an anemometer measuring wind). Producing hundreds of petabytes of data, these multiple data sources must be tightly inte-grated into a “smart data infrastructure system” to help scientists project the impact of future cli-mate change and define options for mitigating and adapting to that change.
Climate science relies on facilities that offer ac-cess to computational resources, data storage and movement, workflows and provenance, and analy-sis tools—to name a few. Simply stated, climate change research isn’t only a scientific challenge of the first order, but also a major technological and infrastructure challenge.
In response to these challenges, climate sci-entists and computational scientists are collabo-rating worldwide to assemble the largest-ever collection of simulation and observation datasets for the Fifth Phase of the Coupled Model Inter-comparison Project (CMIP5). CMIP5 is expect-ed to provide results that will be fundamental to the 2013 Fifth Assessment Report (AR5) of
climate science by the Intergovernmental Panel on Climate Change (IPCC). By comparison, the CMIP5 data archive will dwarf that of its prede-cessor, the Third Phase of the Coupled Model
Figure 2. The warming of the earth’s surface. Four maps of the northern hemisphere demonstrate the trend, with average surface temperature for 1919 (top left), 2002 (top right), 2061 (bottom left), and 2099 (bottom right). The center graph shows the global average as a function of time. The computations were based on observed temperature (pre-2000) and a climate model assuming a continued high rate of greenhouse gas emission.
1919 2002
2061 2099
Time 2061/12
Year 1880 2000 2100 Colder Warmer
Time 2099/12
Year 1880 2000 2100 Colder Warmer
Time 1919/12
Year 1880 2000 2100 Colder
2/12
20011880
58°F
56°F
61°F16.0°C
14.5°C
13.0°C1940 2000 2050
Surface Temperature Surface Temperature
Surface TemperatureSurface Te
2000 2100 Colder Warmer
Figure 3. The climate community’s revolutionary changes in data integration and exploration. Data providers keep their data where it’s generated and provide metadata about the data and its location to one or more centralized access points (ESG gateways) for end users to access and manipulate. The ESG integrates heterogeneous data and metadata sources (that is, simulation, observation, and reanalysis) into a common infrastructure, improving access for both scientists and nonscientists.
Metadatacollection
Datadiscovery
Dataintegration
Dataproducts
Modelingcenters
(archival andstewardship)
Data providers
Decentralized process(ESG data node)
Centralized access(ESG gateway)
Researchsupporttools
User community
Web
por
tal a
nd c
lient
tool
acc
ess
Data
Security
CISE-13-6-Hendrik.indd 17 10/19/11 5:30 PM

18 Computing in SCienCe & engineering
Intercomparison Project (CMIP3). Released for climate study in 2004, the CMIP3 archive provided 35 terabytes of data and was used for the 2007 Nobel Prize-winning IPCC Fourth Assessment Report (AR4). For CMIP5, modeling groups will generate tens of petabytes of data, and the approx-imately 2-petabyte subset of data expected to be of highest interest to researchers will be replicated at several data centers around the world. As with CMIP3, Lawrence Livermore National Labora-tory’s Program for Climate Model Diagnosis and Intercomparison (PCMDI) will supervise the dis-tributed CMIP5 data archive and oversee the ef-fort to provide access to this valuable collection of output from model simulations and observations.
In this challenging undertaking, PCMDI has organized partnerships with global data centers funded to assist with CMIP5 data retrieval and dissemination to create an internationally distrib-uted data archival and retrieval federation. Their mission is to provide climate researchers world-wide with a science gateway to access the data, information, models, analysis tools, and compu-tational capabilities required to evaluate extreme-scale datasets. Its stated goals are to
•make data more useful to climate researchers by developing collaborative technology that enhances data usability;
•meet the specific needs of national and interna-tional climate projects for distributed databases, data access, and data movement;
• provide a universal and secure Web-based data access portal for broad-based multimodel data collections; and
• provide a wide range of climate data analysis tools and diagnostic methods to international climate centers and US government agencies.
To this end, the partners are working to integrate all important climate datasets—from climate simulations to observations—using distributed storage management, remote high-performance units, high-bandwidth wide-area networks, and user desktop platforms in a collaborative problem-solving environment.
In building the distributed climate archives, modeling groups provide data through an Earth System Grid (ESG) Data Node. Actual data hold-ings reside on numerous federated ESG Data Nodes. The nodes host those data and the meta-data services needed to publish data onto ESG and execute data product requests through an ESG Gateway. The ESG Gateways, which act as brokers handling data, process requests to serve specific user communities. Services deployed on a gateway include the user interface for searching and browsing metadata, for requesting data prod-ucts (including analysis and visualization tools), and for orchestrating complex workflows. These large-scale computations will frequently involve numerous resources spread throughout the mod-eling and observational climate communities. Ag-gregations of data and computational methods are varied; thus, needed resources must be positioned strategically throughout the global community to facilitate research to understand the complex nature of important climate processes.
Based on the growth rates established in the DOE report, Scientific Grand Challenges: Challenges in Climate Change Science and the Role of Computing at the Extreme Scale,2 data from the climate com-munity will reach hundreds of exabytes by 2020. To be ready for this expected onslaught, the ESG federated enterprise system is in place and await-ing the first set of CMIP5 simulation and obser-vational data. Besides the CMIP5 archive, NASA has also partnered with the Earth System Grid Center for Enabling Technologies (ESG-CET) team to disseminate NASA’s satellite data (includ-ing from Atmospheric Infrared Sounder, Micro-wave Limb Sounder, Cloudsat) and observational data archives. In addition, NOAA has partnered with the ESG-CET team to make the holdings of the National Climate Data Center, the world’s largest active archive of weather data, available to climate researchers. With more than 20,000 registered users and over 1 petabye of data down-loaded by the community, ESG-CET is quickly expanding to encompass increasingly larger inter-national climate data domains, paving the way for a truly global network of climate data and services whose goal is to make climate data easily acces-sible and easy to understand.
Summary of CaSe 2
The scale of climate data raises key opportu-nities and challenges:
• To understand the impacts of climate, climate simulations and observations studies will be conducted. These simulations and observa-tions will produce hundreds of petabytes of data that must be integrated, curated, and made available for analysis.
• To effectively handle these massive datasets, an advanced networking and analysis infra-structure must be researched, developed, and deployed.
CISE-13-6-Hendrik.indd 18 10/19/11 5:30 PM

november/deCember 2011 19
Climate science datasets are growing at an ex-tremely fast rate3 and will stress every aspect of our data-intensive science capabilities for many years to come.
Case 3: X-Ray and Neutron Scattering DataOver the past two decades, scientific research at intense x-ray and neutron sources in the US has had a major impact on how we understand the world around us. Physics, materials science, chemistry, biology, geosciences, medicine, engi-neering, and the energy sciences have advanced significantly based on discoveries at these national facilities. Although measurement capabilities are uncovering previously inaccessible information, and the future is expected to bring these at an ever-increasing rate, data challenges are limit-ing our ability to fully interpret the experiments. In particular, while experimental capabilities are improving rapidly, robust capabilities for data handling and for the corresponding theory, mod-eling, and simulation needed to leverage and fully benefit from these results lag far behind.
As a concrete example, consider the Spallation Neutron Source at Oak Ridge National Labora-tory. SNS provides the most intense pulsed neu-tron beams in the world for scientific research and industrial development. Neutron scattering research has been used to develop many of the advanced materials that impact medicine, elec-tronics, aerospace, and other areas of everyday life. As the SNS develops to its full realization, its software-analysis and data-handling platforms will require enormous effort to reach commensu-rability with the experimental capabilities.
Another example is the Advanced Photon Source, which provides the brightest storagering- generated x-ray beams in the Western hemi-sphere. With the new APS upgrade project, capa-bilities will reach nanometers of spatial resolution for imaging and picoseconds of timing resolu-tion for dynamics research. The two major APS themes of “mastering hierarchical structures through imaging,” and “real materials under real conditions in real time” will ensure US leadership in x-ray-based research and development, but will require implementation of significant computa-tional resources. Here as well, software-analysis and data-handling platforms will require a tenfold expansion to reach commensurability with the upgraded experimental capabilities.
Detailed SNS data streams entail space (x, y) and time coordinates for every detected neutron. The data can be streamed for processing during an experiment or concatenated to produce an
“event list” data file for post-measurement analy-sis. Often experiments are performed varying one or more parametric values such as temperature, pressure, magnetic field, gas/liquid flow rates, or rotation angle—thus raw data starts at 3D and ranges to as many dimensions as the studied parametric variables. These 3D datasets typically range from 10 to 100 Gbytes in size; to process a raw dataset might require the simultaneous use of up to six calibration and correction datasets while also carrying along the proper experimental error estimates. Thus, the composite raw datasets can approach a terabyte of data to process per mea-surement, per instrument—before adding para-metric variations.
When using multiple measurements for tomo-graphic reconstruction of a sample, the data and computational requirements quickly become daunting. Measurements from 100 angles will re-sult in at least 100 terabytes of data that must be managed and processed. At the APS, typical mea-surements today make use of 720 angles, and real-time implementations are planned for the future.
The tomographic reconstruction algorithms use an optimization technique that typically requires O(1,000) iterations to converge. The total com-putational requirements are on the order of 1018 operations. And these operations involve complex data access patterns, which results in poor utiliza-tion of traditional high-performance computers. To avoid these difficulties, the data is typically reduced prior to analysis, inevitably losing in-formation. Improvements in data-processing ca-pabilities are essential to make maximal use of state-of-the-art experimental facilities.
Today, it’s well understood that single measure-ments alone rarely provide unambiguous results to complex questions. New science and basic un-derstanding are made possible by software that co-ordinates analyses across experimental techniques and user facilities. For example, the frontier in materials characterization exists where a variety of physical measurements—informed by theory, modeling, and simulations—are used to solve the
new science and basic understanding
are made possible by software that coordinates
analyses across experimental techniques
and user facilities.
CISE-13-6-Hendrik.indd 19 10/19/11 5:30 PM

20 Computing in SCienCe & engineering
important and difficult problems. Users require experiments that can be done in an environment capable of accumulating, managing, and analyz-ing the diverse data they’ll collect. Although the rewards are anticipated to be great, such systems today are beyond the horizon. Advancement to-wards this frontier will require a new generation of software for data analysis and modeling.
Starting with the simplest issues, software for data analysis, modeling, and simulation at x-ray and neutron facilities begins as soon as data re-duction and instrumental corrections are com-plete. In this area, there’s a need for on-demand real-time analysis of data while it’s being collected to ensure that the intended data is being measured and experimenters aren’t following blind alleys. Odd as it might sound, most of the data acquired at large facilities today aren’t subject to quality evaluation and interpretation until after the mea-surements are complete.
The large data streams associated with current and future experimental facilities are driving a change in the way experimental data is managed. It once was possible for users to process their data on their own computing resources, but this is no longer a viable solution. Instead, data management and processing must be an integral aspect of the experimental facility. SNS researchers have access to computing facilities at SNS and at ORNL, but these are primarily used for data reduction; the resulting reduced data is left for users to analyze at their home facilities.
However, a new scientific vision is emerging in which experimentation, data analysis, and com-putational modeling are more tightly coupled. In this vision, computation will be used to give users scientific inference as they perform their experi-ments. Experiments will engage a feedback loop to
measure, analyze, visualize, and then optimize for the next measurement iteration. This vision is be-ing realized on a modest scale today, but its full re-alization will require faster analysis and simulation capabilities to support real-time decision making.
Moreover, if predictive modeling and simula-tion were available in advance of measurements, it would expand greatly our insights into the ex-periments. In most areas, however, facilities don’t have these capabilities. Here, computational scat-tering science offers a promising opportunity to expand our insights into today’s leading-edge science.4 Such opportunities can be realized only by dramatic changes in how data is man-aged and analyzed at experimental facilities. The workflows and systems designed for traditional computational science must be redesigned for hybrid experimental/computational science.
Overall DOE Data-intensive LandscapeThe case studies we’ve sketched here differ in many details, but they share underlying features that are common to other scientific data problems. We now explore some of these common needs and extract broader lessons about the DOE’s challenges.
Data issuesFirst and foremost, data is important. Data is the source of all scientific insight that emerges from a computation or an experiment. Given the invest-ment required to obtain that data, it’s essential that data be managed in a disciplined and mindful man-ner to preserve its integrity and value for anticipated and unanticipated uses. Careful data management requires well-designed policies, architectures, and workflows. Appropriate hardware and software tools are required to collect, move, and store data. Integrity can be enhanced through access controls, cryptographic protocols, and redundancy. Gen-erally speaking, experimental communities have addressed these challenges more holistically than computational scientists. Commercial off-the-shelf products are available to meet many of these needs, particularly if the data volumes are modest.
The analysis of scientific data is often highly spe-cialized and depends upon the characteristics of the data and the precise questions being addressed. Simple scientific analytics might consist of sum-mary statistics or selections of data subsets. These are easily addressed by traditional data methods such as database queries or MapReduce, or via cus-tom tools written by domain scientists. However, more complex analytical problems can be consid-erably more challenging. For example, data from a fluid simulation might be analyzed to characterize
Summary of CaSe 3
Experimental sciences (specifically x-ray and neutron scattering experiments) provide several opportunities and challenges for
data-intensive computing:
• Experimental facilities are facing massive data challenges. Issues of data integrity and quality are important throughout the re-quired data-reduction process, from sensor output to storage.
• Cutting-edge science today is conducted by tightly coupling experimentation, modeling and simulation, and analysis. Data analysis, comparison, and archiving are at the heart of this scientific process. To facilitate successful science, data issues—including massive sizes, real-time analysis, data integrity, and advanced analysis challenges—must be addressed.
CISE-13-6-Hendrik.indd 20 10/19/11 5:30 PM

november/deCember 2011 21
recirculation regions, a new genomic fragment might be compared to a library of existing sequences, or a series of computations might be studied to quantify margins of uncertainty. Such specialized analytics aren’t well addressed by general-purpose tools. The functionality of databases and MapRe-duce approaches is sometimes too limited to easily express analytical needs, and these approaches can impose large inefficiencies. Instead, the scientific community has traditionally written customized algorithms and software for specific data analysis challenges. The complexity of these specialized analyses is compounded by the challenge of work-ing with large-scale data. As a result, analysis tends to be focused on answering specific questions, and not on open-ended exploration. Potential scientific discoveries are thus missed.
Although a computer can answer specific ques-tions about a dataset, much richer understanding can emerge by allowing scientists to explore the data interactively. Considerable work has gone into building interactive visualization environ-ments for simulation data. This data has a special-ized structure—often an underlying mesh or grid in 3D over time—that allows for efficient and in-tuitive exploration.
Data that doesn’t have an underlying physical geometry can be much more difficult to explore. Examples include biological pathway analysis, uncertainty characterization from ensembles of simulations, and cyber defense. For such applica-tions, novel data abstractions and representations are needed to communicate to a user. The choice of an abstraction and its visualization imposes a mental model on the user that can be highly infor-mative, but also deceptive. Spurious correlations and outliers can be an artifact of the human– computer interface, and not germane to the data. The development of environments for richly exploring complex data is an active research area.
As data sources become larger and more com-plex, the challenges become even more acute. Even today, in both experimental and computa-tional settings, the vast majority of data is never analyzed in any depth by humans or computers. Instead, a scientist typically studies data summa-ries or small subsets of the overall data to confirm or refute a hypothesis. The rest of the data is gen-erated, transferred, and archived, but ignored. It’s difficult to know how much deeper understand-ing is lurking in the unexamined and unanalyzed data. In the future, computers must play a grow-ing role in automatically identifying interesting phenomena and bringing them to the attention of scientists. Instead of just answering well-defined
questions about the data, advanced analysis sys-tems should be able to find interesting patterns, trends, and anomalies. To do this in a meaningful way will require advances in statistics, machine learning, information theory, and other areas of mathematics and computer science.
Software issuesWe need much faster analysis of data streams. The ability to study scientific data in situ would enable interactive steering for both computational and experimental science. In both domains, expensive resources are given a prescribed task and set loose with minimal oversight—and many tasks fail to deliver as planned, generating data of little or no value. As an alternative, we could actively steer the computation or the experiment based on the gen-erated data’s characteristics. Computations that become nonphysical could be ended early and re-gions of parameter space that are known to cause instabilities could be steered around. For experi-mental studies, parameters could be adapted on the fly to ensure the collected data’s quality and
relevance, and experiments could be redirected as soon as the necessary data has been gathered. In both domains, the result would be higher-quality science and improved useof precious resources.
Interactive steering requires real-time data analy-sis to either self-monitor or to support a human de-cision maker. Data analysis and transmission would need to be designed into the workflow to a greater degree than it is today. Sufficient and appropriate computational resources for analyzing data insitu would need to be part of the system architecture.
Another important scientific opportunity is insight that could arise from a closer coupling between different experiments or between ex-perimentation and simulation. For example, using first-order difference methods to combine neu-tron and x-ray structure factors, we could observe atomic and nanoscale ordering in unprecedented detail compared to either method alone. Each ex-perimental and computational method provides distinct insights, but their combination offers infor-mation that’s otherwise inaccessible. Realizing this
in the future, computers must play a growing
role in automatically identifying interesting
phenomena and bringing them to the
attention of scientists.
CISE-13-6-Hendrik.indd 21 10/19/11 5:30 PM

22 Computing in SCienCe & engineering
vision will require better methods for managing and aligning multiple datasets, and techniques for analyzing them simultaneously.
architectural issuesAll of these data-intensive computing opportuni-ties require advanced computational capabilities. Unfortunately, the current HPC ecosystem isn’t a good match for the needs of many data-intensive applications. Data-intensiveapplications might require advanced computing to perform analytics for large and complex datasets, or they might re-quire answers to be computed quickly for real-time applications such as cybersecurity or experimental steering. In either case, the needs of data-intensive applications are distinct from those of the modeling and simulation applications that have driven tra-ditional HPC. We envision the need for advances across a wide spectrum of the computing landscape.
Data-intensive computing will place high de-mands on hardware. Data-intensive applications require less computing power than modeling and simulation applications, but they place more de-mand on all layers of the memory and communica-tion systems. Improvements in memory’s effective performance and power efficiency are critical. Networks are needed that have higher bandwidth and lower latency, particularly for small messages. Current processor architectures rely on high spatial and temporal locality to effectively use memory hierarchies, but many data-intensive ap-plications have poor locality. Architectures that exploit massive multithreading might be able to achieve much higher performance for data ap-plications while consuming much less power. It’s worth exploring even more radical memory- centric designs, in which memory actually re-quests computing services instead of having pro-cessors request data from dumb memory.
Systems issues for data-intensive applications are also quite different from those associated with
modeling and simulation. The balanced machine for data applications will require more memory and bandwidth, and comparatively less compute power. Data applications can benefit greatly from a shared address space and programming models that support fine-grained parallelism instead of just bulk synchronous parallelism. Many data- intensive applications benefit from close inter-actions with human decision makers. Having a human in the loop requires fresh thought about how a high-performance computer is managed and scheduled.
M uch has been written about the transformative potential of data-intensive science. Common ex-amples include the opportunity
for the Internet to advance the social sciences and the data challenges associated with future tele-scopes. Here, we focused on areas of science and engineering that are perhaps less exotic, but no less important. A principal conclusion is that even mature areas of science and engineering have a tremendous need for data-intensive technologies.
However, this opportunity won’t be easily re-alized. As we described, numerous challenges must be addressed and difficult research problems solved. In some respects, the challenges are greater in mature fields than in new areas of science. Ex-isting cultures and workflows might need to be reinvented before data can be put to maximal use. We believe that the potential of data-intensive science will provide the necessary impetus for communities to change, but this change will take many years to come to full fruition.
acknowledgmentsLos Alamos National Laboratory is operated by the Los Alamos National Security for the National Nuclear Security Administration of the US Department of En-ergy under contract DE-AC52-06NA25396. Sandia
Summary of ChallengeS
There are several opportunities and challenges for the US Department of Energy in a data-intensive
landscape:
• DOE missions require the analysis of diverse data types and sizes, including scientific and sensor-based data. Issues of data integrity, provenance, and ease of analysis must be dealt with carefully as this data is the source of our primary product: scientific understanding and insight.
• Integrated data analysis approaches that reduce data movement and bridge the gap between experiments, sim-ulations, and analysis are critical to reducing the problem of analyzing massive data. This tightly coupled approach will improve the scientific process by reducing barriers between these different sources of scientific knowledge.
• Traditional high-performance computing (HPC) architec-tures aren’t designed to efficiently process data-intensive workloads. A multipronged approach that includes the integration of data-intensive features into HPC architectures as well as designing custom data-intensive architectures from scratch will help us efficiently handle massive datasets.
CISE-13-6-Hendrik.indd 22 10/19/11 5:30 PM

november/deCember 2011 23
National Laboratories is a multiprogram laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corpo-ration, for the DOE’s National Nuclear Security Ad-ministration under contract DE-AC04-94AL85000. Work by Gabrielle Long and Robert Ross were sup-ported by the DOE Office of Science under contract DE-AC02-06CH11357. Oak Ridge National Labora-tory is managed by UT-Battelle for the DOE under contract DE-AC05-00OR22724. This work was per-formed under the auspices of the DOE by Lawrence Livermore National Laboratory under contract DE-AC52-07NA27344.
References1. S. Solomon et al., eds., Contribution of Working Group
I to the Fourth Assessment Report of the Intergovern-
mental Panel on Climate Change, 2007, Cambridge
Univ. Press, www.ipcc.ch/publications_and_data/
ar4/wg1/en/contents.html.
2. W. Washington et al., Scientific Grand Challenges:
Challenges in Climate Change Science and the Role of
Computing at the Extreme Scale, US Dept. Energy,
2008; www.er.doe.gov/ascr/ProgramDocuments/
Docs/ClimateReport.pdf.
3. B. Allcock et al., ASCR Science Requirements, report,
US Office of Advanced Scientific Computing
Research Network Requirements Workshop,
2009; www.es.net/assets/Papers-and-Publications/
ASCR-Net-Req-Workshop-2009-Final-Report.pdf.
4. B. Fultz, K. Herwig, and G. Long, Computational Scat-
tering Science 2010, Argonne Nat’l Lab., 2010, www.its.
caltech.edu/~matsci/Publish/CompScatWkshp_2010.
html.
James p. ahrens leads the Data Science at Scale Team in the Applied Computer Science Group at Los Alamos National Laboratory. His research interests include visualization and the intersection of data-intensive and high-performance computing. He initiated, led, and continues to work on the ParaView project, an open-source large-scale scientific visualization tool. Ahrens has a PhD in computer science from the Uni-versity of Washington. He is a member of IEEE Com-puter Society. Contact him at [email protected].
bruce hendrickson is the senior manager for Com-putational Sciences and Mathematics at Sandia National Laboratories. His research interests include parallel algorithms, combinatorial scientific comput-ing, and linear algebra, and, more recently, computer architectures and data mining. Hendrickson has a PhD in computer science from Cornell University. He is a member of SIAM, the ACM, IEEE, and AAAS. Contact him at [email protected].
Gabrielle long is a senior physicist (retired) and former division director of the X-Ray Science Division of Ar-gonne National Laboratory; she currently divides her time between work at Argonne and at the US National Institute of Standards and Technology (NIST), where she is a former acting division chief of the Ceramics Division and leader of the Materials Microstructural Characterization Group. Her research interests include disordered materials, materials deformation, materi-als microstructure characterization, in situ materials processing, small-angle scattering, x-ray optics, x-ray inelastic scattering, anomalous scattering, and dy-namical diffraction by imperfect (real) crystals. Long has a PhD in physics from the Polytechnic Institute of Brooklyn. Contact her at [email protected].
steve Miller is senior systems manager for the newly formed Data Systems Section in Oak Ridge National Laboratory’s Neutron Scattering Science Division (NSSD), where researchers provide data acquisition and analysis and computing support for the scientific research performed at the ORNL Spallation Neutron Source experimental user facility. Miller has an MS in engineering from the University of Florida. Contact him at [email protected].
robert ross is a computer scientist at Argonne Na-tional Laboratory and a fellow at the Computation Institute of the University of Chicago. His research interests are in system software for HPC systems, in particular parallel file systems and libraries for I/O and message passing. Ross has a PhD in computer engineering from Clemson University. He received the 2004 Presidential Early Career Award for Scientists and Engineers and is a member of the ACM. Contact him at [email protected].
dean williams leads software development for the International Panel on Climate Change, which was recognized in 2007 with a Nobel Peace Prize; he also works in the Lawrence Livermore National Labora-tory’s Program for Climate Model Diagnosis and In-tercomparison, where the team he leads collects and organizes data from climate modeling centers around the world. His research interests include high-perfor-mance and distributed computing, enhancing interop-erability between climate analysis tools, and enabling end-to-end simulation and analysis workflow for the Earth science communities. Williams has an MS in computer science from the California State University at Chico. Contact him at williams13@ llnl.gov.
Selected articles and columns from IEEE Computer Society publications are also available for free at
http://ComputingNow.computer.org.
CISE-13-6-Hendrik.indd 23 10/19/11 5:30 PM

To Order North America1-877-762-2971
Rest of the World+ 44 (0) 1243 843291
Order Onlinecomputer.org/store
wiley.com/ieeecs
NEW TITLE FROM WILEY &
“Bo Sandén has written a splendid book that should be read by every developer of systems that interact with the real world.”—Michael A. Jackson, from the Foreword
This book is the fi rst available in-depth introduction to the entity-life modeling (ELM) approach for the design of multithreaded, reactive software, making it an instant authoritative reference.
15% Offfor CS Members
www.computer.org
978-0-470-87659-6 • March 2011 Hardcover • 320 pages • $89.95 A Wiley-IEEE Computer Society Press Publication
CISE-13-6-Hendrik.indd 24 10/19/11 5:30 PM