data / information / knowledge presentation by pauline lake modifications by rick mercer...
TRANSCRIPT

Data / Information / Knowledge
Presentation by Pauline LakeModifications by Rick Mercer
Acknowledgment and Disclaimer: This presentation is supported in part by the National Science Foundation under Grant 1240841. Any opinions, findings, and conclusions or recommendations expressed in these materials are those of the authors and do not necessarily reflect the views of the National Science Foundation.

• Processing Large Data Sets
• Using Data
• Big Data and Mobile Computing
Outline

Sort a Petabyte (1015) bytes of data• 1015 = 103 x 103 x 103 x 103 x 103 bytes• Quicksort assumes the data are in RAM• 1 Petabyte would occupy
• 1,000 1-TB disk drives, or• 10,000 100-GB drives
Processing Large Data Sets

MapReduce is a programming model for processing large data sets
• Distributed file system -- data sets are stored over many computers
• Parallel algorithm -- i.e., many identical processes running simultaneously
• MapReduce, developed at Google• Hadoop, open source Apache version
The MapReduce Model

● References: • Petabyte Sort Blog (Quantcast Sort Blog)• Sorting Petabytes with Map Reduce (Google Research)
MapReduce Experiment: Sort a Petabyte (1018 bytes)

Problem: Count the occurrences of every word in a large
set of documents, D1, D2, …, DN.
• D1: “a man, a plan, a canal, panama”
• D2: “in for a penny in for a pound”
• …
• DN: ...
MapReduce Example

Algorithm:
Map Step:
for each word, w, in D1,...,DN,
output the partial count (w, 1)
Reduce: sum = 0
for each partial count, pc, produced by Map stepsum = sum + pc
MapReduce Example

● Problem: Count the occurrences of every word in a set of documents
MapReduce Example
Count the occurrences of every word in D1, D2, … DN.
Map/Reduce System

● Problem: Count the occurrences of every word in a set of documents
MapReduce Example
Count the occurrences of everyword in D1, D2, … DN.
Map/Reduce SystemMaster
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”

MapReduce Example
Map/Reduce System
Master
Mapper1 MapperM
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
Count the occurrences of everyword in D1, D2, … DN.
● Problem: Count the occurrences of every word in a set of documents
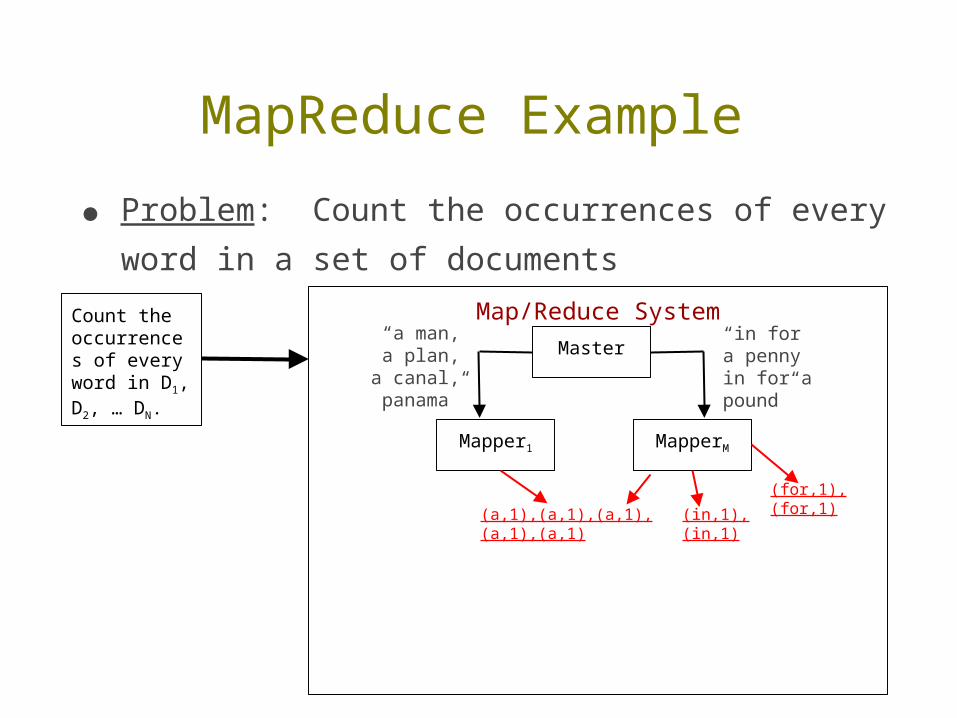
MapReduce Example
Map/Reduce System
Master
Mapper1 MapperM
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
(a,1),(a,1),(a,1),(a,1),(a,1)
(for,1),(for,1)(in,1),(in,1)
Count the occurrences of everyword in D1, D2, … DN.
● Problem: Count the occurrences of every word in a set of documents

MapReduce Example
Map/Reduce System
Master
Mapper1 MapperM
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
(a,1),(a,1),(a,1),(a,1),(a,1)
(for,1),(for,1)(in,1),(in,1)
partial counts
Count the occurrences of everyword in D1, D2, … DN.ç
● Problem: Count the occurrences of every word in a set of documents

● Problem: Count the occurrences of every word in a set of documents
MapReduce Example
Count the occurrences of every word in D1, D2, … DN.
Map/Reduce System
Master
Mapper1 MapperM
Reducer1 Reducer2 ReducerR
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
(a,1),(a,1),(a,1),(a,1),(a,1)
Reducer3
(for,1),(for,1)(in,1),(in,1)

● Problem: Count the occurrences of every word in a set of documents
MapReduce Example
Count the occurrences of every word in D1, D2, … DN.
Map/Reduce System
Master
Mapper1 MapperM
Reducer1 Reducer2 ReducerR
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
(a,1),(a,1),(a,1),(a,1),(a,1)
(a,5)
Reducer3
(for,1),(for,1)(in,1),(in,1)
(in,2) (for,5)(man,1),...
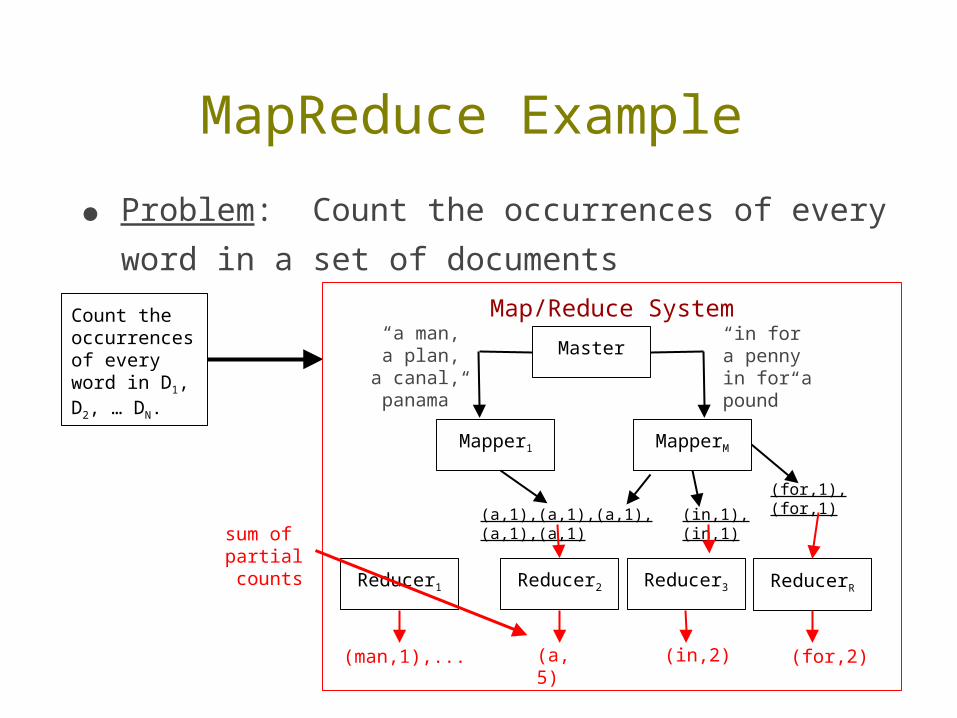
● Problem: Count the occurrences of every word in a set of documents
MapReduce Example
Count the occurrences of every word in D1, D2, … DN.
Map/Reduce System
Master
Mapper1 MapperM
Reducer1 Reducer2 ReducerR
“a man, a plan, a canal,
panama”
“in for a penny in for a pound”
(a,1),(a,1),(a,1),(a,1),(a,1)
(a,5)
Reducer3
(for,1),(for,1)(in,1),(in,1)
(in,2) (for,2)(man,1),...
sum of partial counts
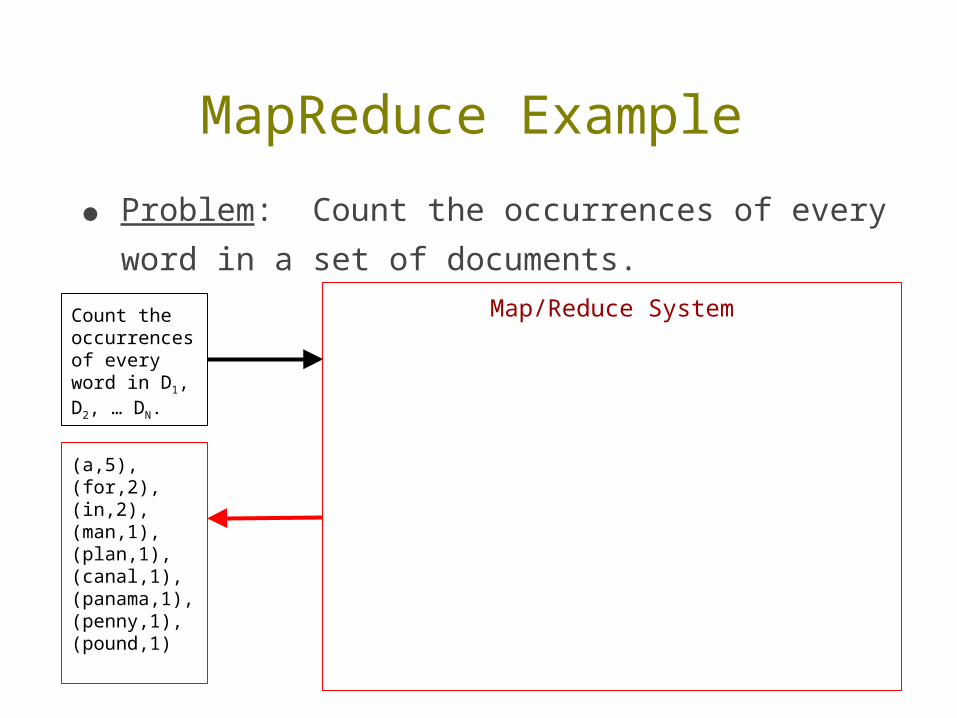
● Problem: Count the occurrences of every word in a set of documents.
MapReduce Example
(a,5),(for,2),(in,2),(man,1),(plan,1),(canal,1),(panama,1),(penny,1),(pound,1)
Count the occurrences of every word in D1, D2, … DN.
Map/Reduce System

Using Data

Big Data: Government Data● 2012, Data.gov, 84 programs, six departments
○ Benefit: helping government address problems○ Tradeoff: Government has too much data on us?

Big Data: Web Analytics● Analytics discovery and use of meaningful patterns in data
○ Benefit: Provide customers with targeted ads○ Tradeoff: Loss of privacy and anonymity of web search

Big Data: Data Mining● Data Mining -- discovering patterns in large data sets.
○ Benefit: Discovering risk factors in medical data.○ Tradeoff: Can we keep patient medical data secure?
Normal patients
Diabetic patients

Data Visualization● IBM chromogram of Wikipedia edits reveals known and
new editing patterns

Data Mining: Neonatal monitoring● Data mining real-time data (heart rate, respiratory rate, O2 satur-
ation) provides a non-invasive way of predicting neonatal health● Traditional approach: Apgar score: measure tone, cry, color,
breathing, … scale of 1 through 9, at birth 5 minutes, 10 minutes

Big Data and Mobile Computing

Big Data and Mobile
Google: Translate “Ciao mondo!”

Big Data and Mobile
Google: Translate “Ciao mondo!”
Map/Reduce(speech recognition)

Big Data and Mobile
Google: Translate “Ciao mondo!”
“Hello world!” Map/Reduce(speech recognition)
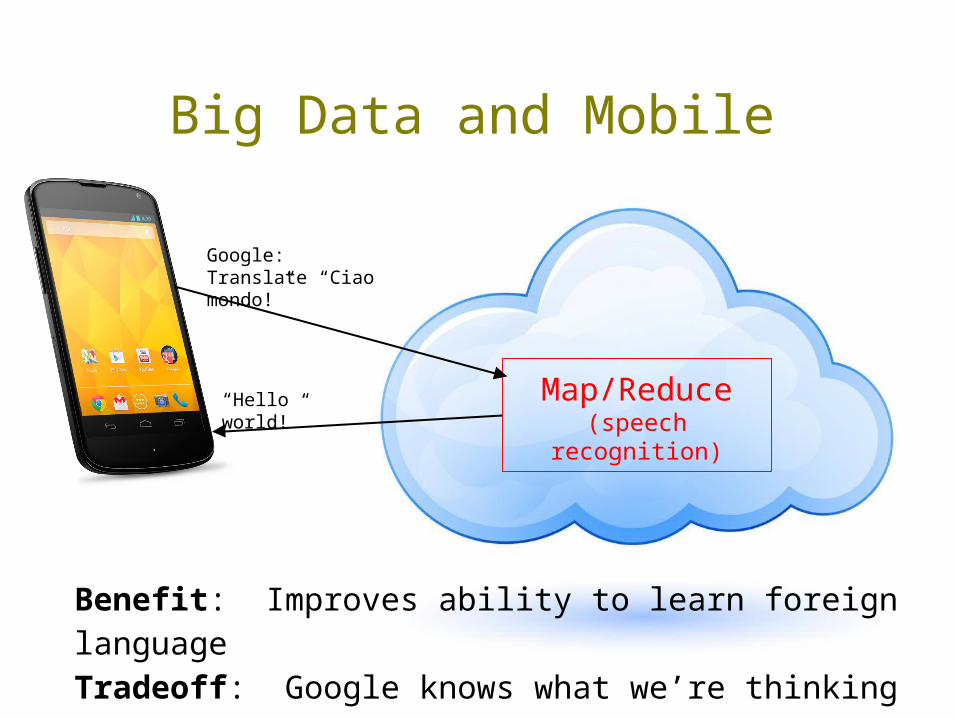
Big Data and Mobile
Google: Translate “Ciao mondo!”
“Hello world!” Map/Reduce(speech recognition)
Benefit: Improves ability to learn foreign languageTradeoff: Google knows what we’re thinking about

Big Data and Mobile
Google: Augment reality
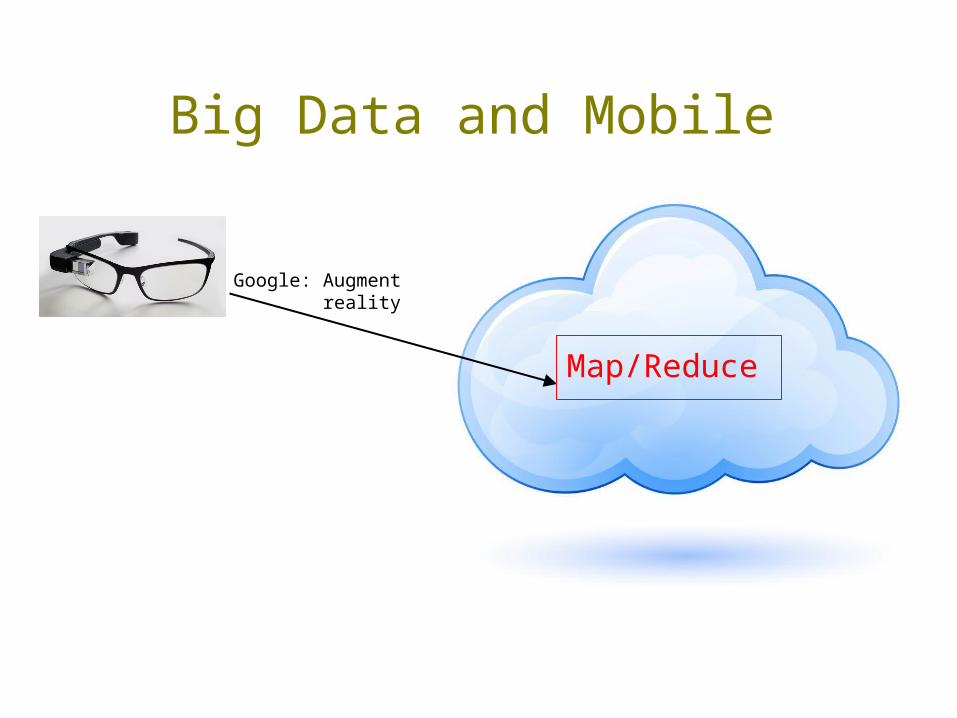
Big Data and Mobile
Google: Augment reality
Map/Reduce
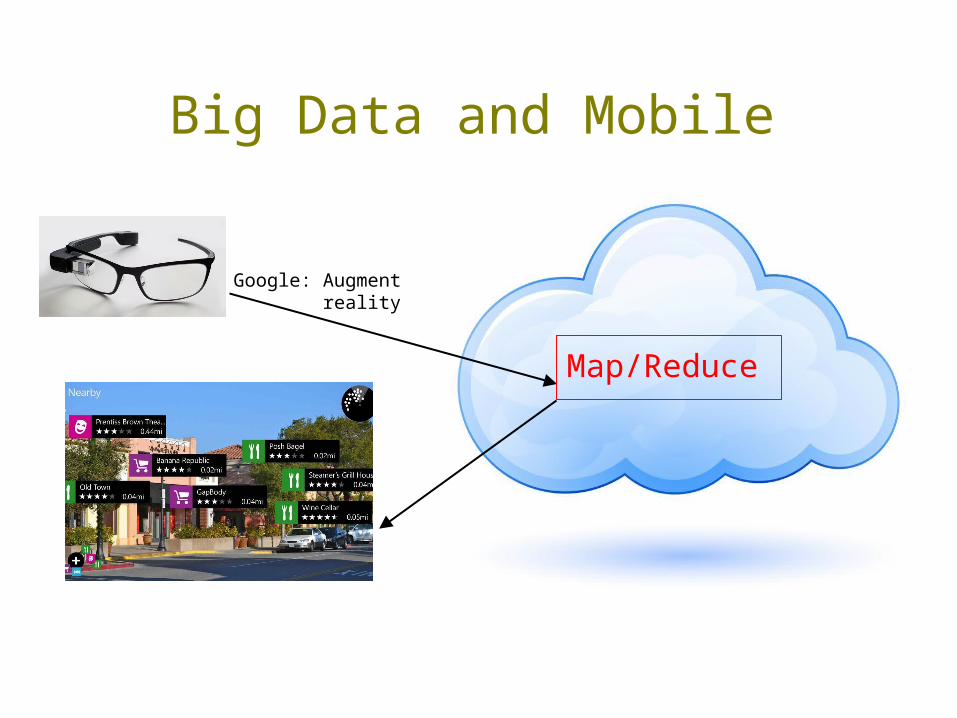
Big Data and Mobile
Google: Augment reality
Map/Reduce

Big Data and Mobile
Google: Augment reality
Map/Reduce
Benefit: Better awareness of what’s around us.Tradeoff: Google knows where we are, what we’re thinking.

● The Digital era involves Large Data Sets● Presents challenges and opportunities.● Requires new processing and visualization
techniques● Comes with the promise of benefits● Comes with tradeoffs in terms of privacy and
security
Summary