data compression solutions
DESCRIPTION
Data Compression SolutionsTRANSCRIPT

Solutions Manual
Introduction to Data CompressionThird Edition
Z. Li and K. Sayood

prave
ndra
Chapter 2 1
Chapter 2
Problem 1.
H(X) =M∑i=1
P (xi) log2
1
P (xi)≥
M∑i=1
P (xi) log2
1
1= 0
H(X)− log2M =M∑i=1
P (xi) log2
1
P (xi)−
M∑i=1
P (xi) log2M
=M∑i=1
P (xi)(log2
1
P (xi)− log2M)
=M∑i=1
P (xi) log2
1
MP (xi)
= E[log2
1
MP (X)]
Now we use Jensen’s inequality which states that if g(X) is a convex⋂
function E[g(X)] ≤g(E[X]).
E[log2
1
MP (xi)] ≤ log2E[
1
MP (X)]
= log2(M∑i=1
P (xi)1
MP (xi))
= 0
or
H(X) ≤ log2M
Problem 2.
Without loss of generality we can assume that the source alphabet is {1, 2, · · · ,M}. Let H1
represent the first order entropy and let H be the entropy of the source. Define
GK = −M∑
i1=1
· · ·M∑
iK=1
P (X1 = i1, X2 = i2 · · ·XK = iK) log2 P (X1 = i1, X2 = i2 · · ·XK = iK)
then by definition
H = limK→∞
1
KGK
If the Xi are independent we can write
P (X1 = i1, X2 = i2 · · ·XK = iK) = P (X1 = i1)P (X2 = i2) · · ·P (XK = iK)

prave
ndra
Chapter 2 2
and
GK = −M∑
i1=1
· · ·M∑
iK=1
P (X1 = i1)P (X2 = i2) · · ·P (XK = iK)[log2 P (X1 = i1)
+ log2 P (X2 = i2) + · · · log2 P (XK = iK)]
= −M∑
i2=1
P (X2 = i2) · · ·M∑
iK=1
P (XK = iK)M∑
i1=1
P (X1 = i1) log2 P (X1 = i1)
−M∑
i1=1
P (X1 = i1)M∑
i3=1
P (X3 = i3) · · ·M∑
iK=1
P (XK = iK)M∑
i2=1
P (X2 = i2) log2 P (X2 = i2)
...
−M∑
i1=1
P (X1 = i1) · · ·M∑
iK−1=1
P (XK−1 = iK−1)M∑
iK=1
P (XK = iK) log2 P (XK = iK)
The first summations in each term sum to 1 and the last summation (assuming identicaldistributions) are equal to H1, and
GK = KH1
Therefore,
H = limK→∞
1
KKH1 = H1
Problem 3.
a) 2 bits.
b) 1.75 bits.
c) 1.739818 bits.
Problem 4.
HQ −HP = −m∑
i=1
qi log2 qi +m∑
i=1
pi log2 pi
= −qj−1 log2 qj−1 − qj log2 qj + pj−1 log2 pj−1 + pj log2 pj
Given a functionfa(x) = −x log x− (a− x) log(a− x)
we can easily show that fa(x) is maximum for x = a2
Let
pj−1 + pj = c

prave
ndra
Chapter 2 3
thenqj−1 = qj =
c
2Then
HQ −HP = − c2
log2
c
2− c
2log2
c
2+ pj log2 pj + (c− pj) log2(c− pj) (1)
= fc(c
2)− fc(pj)
≥ 0
Therefore HQ ≥ HP .
Problem 7.
a) Start with the list of codewords
{0, 01, 11, 111}0 is a prefix for 01 generating a dangling suffix of 1. 11 is a prefix to 111 also generatinga dangling suffix of 1. Augment the codeword list with the dangling suffix.
{0, 01, 11, 111, 1}Now 1 is a prefix to 111 generating a dangling suffix of 11. As 11 is a codeword thecode is not uniquely decodeable.
b) Start with the list of codewords
{0, 01, 110, 111}0 is a prefix for 01 generating a dangling suffix of 1. Augment the codeword list withthe dangling suffix.
{0, 01, 110, 111, 1}1 is a prefix of 110 and 111 generating the dangling suffixes 10 and 11. As neither isa codeword we augment the list and continue.
{0, 01, 110, 111, 1, 10, 11}At this point we can get no new dangling suffixes therefore this code is uniquelydecodeable.
c) Start with the list of codewords
{0, 10, 110, 111}No codeword is a prefix of any other codeword. Therefore, this code is uniquelydecodeable.
d) Start with the list of codewords
{1, 10, 110, 111}1 is a prefix of 110 which generates a dangling suffix of 10 which is a codeword.Therefore this code is not uniquely decodeable.

prave
ndra
Chapter 3 4
Chapter 3
Problem 4.
a)
H =5∑
i=1
P (ai) logP (ai) = 1.817684bits
b) If we sort the probabilities in descending order we can see that the two letters withthe lowest probabilities are a2 and a4. These will become the leaves on the lowest levelof the binary tree. The parent node of these leaves will have a probability of 0.9. Ifwe consider parent node as a letter in a reduced alphabet the it will be one of the twoletters with the lowest probability: the other one being a1. Continuing in this mannerwe get the binary tree shown in Figure 1. and the code is
a a a a a1 2 3 4 5(0.04)(0.05)0.15)(0.26)(0.50)
(0.09)
(0.24)
(0.5)1
1
10
0
0
Figure 1: Huffman code for the five letter alphabet.
a1 110a2 1111a3 10a4 1110a5 0
c)
l = 0.15× 3 + 0.04× 4 + 0.26× 2 + 0.05× 4 + 0.5× 1 = 1.83bits/symbol
Problem 5.

prave
ndra
Chapter 3 5
a
a
a
a
4
2
3
1
(.35)
(.30)
(.25)
(.10)
(.35)
(.65)
(1.0)
Figure 2: Huffman code for the four letter alphabet in Problem 5.
a) The Huffman code tree is shown in Figure 2. The code is
a1 011a2 01a3 010a4 1
The average length of the code is 0.1×3+0.3×2+0.25×3+0.35×1 = 2 bits/symbol.
b) The Huffman code tree is shown in Figure 3. The code is
a
a
a
a
4
3
(.35)
(.30)
(.25)
(.10)
(.35)
(.65)
(1.0)
1
2
Figure 3: Minimum variance Huffman code for the four letter alphabet in Problem 5.
a1 01a2 11a3 00a4 10
The average length of the code is obviously 2 bits/symbol.

prave
ndra
Chapter 3 6
While the average length of the codeword is the same for both codes, that is they are bothequally efficient in terms of rate. However, the second code has a variance of zero for thecodelengths. This means that we would not have any problems with buffer control if wewere using this code in a communication system. We cannot make the same assertion aboutthe first code.
Problem 6. Examining the Huffman code generated in Problem 4 (not 3!) along with theassociated probabilities, we have
a1 110 0.15a2 1111 0.04a3 10 0.26a4 1110 0.05a5 0 0.50
The proportion of zeros in a given sequence can be obtained by first computing the proba-bility of observing a zero in a codeword
∑5k=1 P (0|ak)P (ak) and then dividing that by the
average length of a codeword. The probability of observing a zero in a codeword is
1× 0.15 + 0× 0.04 + 1× 0.26 + 1× 0.05 + 1× 0.50 = 0.96
0.96/1.83 = 0.52. Thus the proportion of zeros is close to a half. If we examine Huffmancodes for sources with dyadic probabilities we would find that the proportion is exactly ahalf. Thus the use of a Huffman code will not lead to inefficient channel usage.

prave
ndra
Chapter 3 7
Problem 8.
3
5
2
1
2
1
1
49
51
50
47 48
45
43 44NYT v
d
0 1
r
a
[aardv]
4
7
2
1
3
2
1
49
51
50
47 48
45
43 44NYT v0 1
r
a
[aardvar]
3
6
2
1
3
1
1
49
51
50
47 48
45
43 44NYT v
d
0 1
r
a
[aardva]
d
5
8
3
3
2
49
51
50
47 48r
a
[aardvark]
46
1
44
v45
1d
10
43
NYT k
41 42
Figure 4: Figure for Problem 8 in Chapter 3.
Problem 7. If we combine three letters in the first and second steps we get the followingcode:
a1 01a2 12a3 02a4 10a5 00a6 11
Thus the average length of the code is two ternary digits per symbol. If we calculate theaverage length of the code in Example 3.3.1 we obtain an average length of 1.7 ternary digitsper symbol.
Problem 10

prave
ndra
Chapter 3 8
a)
Message a2a1a3a2a1a2
Transmitted binary sequence 1010001011Received binary sequence 0010001011Decoded sequence a4a4a2a2
Depending on how you count the errors five characters are received in error before thefirst correctly decoded character.
b)
Message a2a1a3a2a1a2
Transmitted binary sequence 001011001000Received binary sequence 101011001000Decoded sequence a1a1a3a2a1a2
Only a single character is received in error.
c)
Message a2a1a3a2a1a2
Transmitted binary sequence 1010001011Received binary sequence 1000001011Decoded sequence a2a3a4a2a2
four characters are received in error before the first correct character.
For the minimum variance code the situation is different
Message a2a1a3a2a1a2
Transmitted binary sequence 001011001000Received binary sequence 000011001000Decoded sequence a2a2a3a2a1a2
Again, only a single character is received in error.
Problem 12.
Let’s first do the preprocessing: Note that ymax = 41 and because we are going to assume azero for the prediction of the first element of the sequence ymin = 0.
yi 32 33 35 39 37 38 39 40 40 40 40 39 40 40 41 40yi 0 32 33 35 39 37 38 39 40 40 40 40 39 40 40 41di 32 1 2 4 -2 1 1 1 0 0 0 -1 1 0 1 -1Ti 0 9 8 6 2 4 3 2 1 1 1 1 2 1 1 0xi 32 2 4 8 3 2 2 2 0 0 0 1 2 0 2 1
As J = 8 we divide the sequence of sixteen into two packets. The first packet consists of thenumbers:
32 2 4 8 3 2 2 2

prave
ndra
Chapter 3 9
There is significant variation in the values in this packet so we would be best served withone of the split sample options. The split sample option with m = 1 would require 43 bits,m = 2 would require 35 bits, m = 3 would require 39 bits and for m > 3 would require morethan 40 bits so we pick m = 2. In the table we show the translation for each number in thepacket
Number binary representation code32 100000 000000000012 000010 1014 000100 00018 001000 000013 000011 1112 000010 1012 000010 1012 000010 101
Stringing the codes together with an identifier for the code option gives us the code for thefirst packet.
The second packet looks very different.
0 0 0 1 2 0 2 1
It looks like a candidate for the low entropy option. However, as we do not have the lookuptables available we can just use the fundamental sequence option which gives us the followingcode for the packet.
11101001100101
Problem 13.
First iteration:
Letter Probabilitya1 0.7a2 0.2a3 0.1
Second iteration:
Letter Probabilitya2 0.2a3 0.1a1a1 0.49a1a2 0.14a1a3 0.07

prave
ndra
Chapter 3 10
Final iteration:
Letter Codea2 000a3 001a1a2 010a1a3 011a1a1a1 100a1a1a2 101a1a1a3 110

prave
ndra
Chapter 4 11
Chapter 4
Problem 1. Given a number a ∈ [0, 1) with binary representation [b1b2 . . . bn]
a = b12−1 + b22
−2 + · · ·+ bn2−n
If b has a binary representation with [b1b2 . . . bn] as prefix, then
b = b12−1 + b22
−2 + · · ·+ bn2−n + bn+12−(n+1) + · · ·
Therefore,b− a = bn+12
−(n+1) + · · ·
Obviously b− a ≥ 0 and b ≥ a. To show b < a+ 12n we note that
b− a = bn+12−(n+1) + bn+22
−(n+2) + · · ·≤ 2−(n+1) + 2−(n+2) + · · ·
<1
2n
Problem 4.
Count(1) = 40 Cum Count(0) = 0 Scale3 = 0Count(2) = 1 Cum Count(1) = 40Count(3) = 9 Cum Count(2) = 41Total Count = 50 Cum Count(3) = 50
If m = 6l(0) = 000000; u(0) = 111111 = 63
The first element of the sequence to be encoded is 1.
l(1) = 0 + b64× Cum Count(0)
50c = 0 = (00000000)2
u(1) = 0 + b64× Cum Count(1)
50c − 1 = 50 = (110010)2
The next element of the sequence is 3.
l(2) = 0 + b51× Cum Count(2)
50c = 41 = (101001)2
u(2) = 0 + b51× Cum Count(3)
50c − 1 = 50 = (110010)2

prave
ndra
Chapter 4 12
The MSBs of l(2) and u(2) are both 1. Therefore, we shift this value out and send it to thedecoder. All other bits are shifted left by one bit, giving
l(2) = (010010)2 = 18
u(2) = (100101)2 = 37.
Notice that while the MSBs of the limits are different, the second MSB of the upper limitis zero, while the second MSB of the lower limit is one. This is the condition for the E3
mapping. We complement the second MSB of both limits and shift one bit to the left,shifting in a zero as the LSB of l(2) and a one as the LSB of u(2). This gives us
l(2) = (000100)2 = 4
u(2) = (101011)2 = 43.
We also increment Scale3 to a value of one.
The next element in the sequence is 2. Updating the limits, we have
l(3) = 4 + b40× Cum Count(1)
50c = 36 = (100100)2
u(3) = 4 + b40× Cum Count(2)
50c − 1 = 35 = (100011)2
and the lower limit is greater than the upper limit. Clearly an unacceptable situation.Therefore we cannot use m = 6.
Problem 5
Letter Probability cdfa1 .2 FX(1) = 0.2a2 .3 FX(2) = 0.5a3 .5 FX(3) = 1.0
l(0) = 0
u(0) = 1
First letter is a1
l(1) = 0 + (1− 0)× 0 = 0
u(1) = 0 + (1− 0)× .2 = .2
Second letter is a1
l(2) = 0 + (.2− 0)× 0 = 0
u(2) = 0 + (.2− 0)× .2 = .04

prave
ndra
Chapter 4 13
Third letter is a3
l(3) = 0 + (.04− 0)× 0.5 = 0.02
u(3) = 0 + (.04− 0)× 1.0 = 0.04
Fourth letter is a2.
l(4) = 0.02 + (.04− 0.02)× 0.2 = 0.024
u(4) = 0.02 + (.04− 0.02)× 0.5 = 0.03
Fifth letter is a3
l(5) = 0.024 + (.03− 0.024)× 0.5 = 0.027
u(5) = 0.024 + (.03− 0.024)× 1.0 = 0.03
Sixth letter is a1
l(6) = 0.027 + (.03− 0.027)× 0.0 = 0.027
u(6) = 0.027 + (.03− 0.027)× 0.2 = 0.0276
Therefore a possible tag value is 0.0273.
Problem 6. The tag decodes to the following sequence:
a3a2a2a1a2a1a3a2a2a3
Problem 7
Letter Count Cum CountCum Count[0] = 0
a(=1) 37 Cum Count[1] = 37b(=2) 38 Cum Count[2] = 75c(=3) 25 Cum Count[3] = 100
a) Total Count = 100
m = dlog2(Total Count)e+ 2 = 7 + 2 = 9bits
b)
l(0) = (000000000)2 = (0)10
u(0) = (111111111)2 = (511)10

prave
ndra
Chapter 4 14
First letter is a(1)
l(1) = 0 + d512× 0
100e = (0)10 = (000000000)2
u(1) = 0 + d512× 37
100e − 1 = (188)10 = (010111100)2
Transmit 0.
l(1) = (000000000)2 = (0)10
u(1) = (101111001)2 = (377)10
Input = b (2)
l(2) = 0 + d378× 37
100e = (139)10 = (010001011)2
u(2) = 0 + d378× 75
100e − 1 = (282)10 = (100011010)2
(2)
This is an E3 condition ⇒ scale3=1
l(2) = (000010110)2 = (22)10
u(2) = (100110101)2 = (309)10 (3)
Input=a (1)
l(3) = 22 + d288× 0
100e = (22)10 = (000010110)2
u(3) = 22 + d288× 37
100e − 1 = (105)10 = (001101001)2
(4)
Transmit 0Transmit 1. Set scale3=0Transmit 0
l(3) = (001011000)2 = (88)10
u(3) = (110100111)2 = (423)10
input = c (3)
l(4) = 88 + d336× 75
100e = (340)10 = (101010100)2
u(4) = 88 + d336× 100
100e − 1 = (423)10 = (110100111)2

prave
ndra
Chapter 4 15
Transmit 1
l(4) = (010101000)2
u(4) = (101001111)2
E3 condition ⇒ Set scale3=1.
l(4) = (001010000)2 = (80)10
u(4) = (110011111)2 = (415)10
Input = a (1)
l(5) = 80 + d336× 0
100e = (80)10 = (001010000)2
u(5) = 80 + d336× 37
100e − 1 = (203)10 = (011001011)2
Transmit 0Transmit 1. Set scale3 = 0.
l(5) = (010100000)2 = (160)10
u(5) = (110010111)2 = (407)10
Input = b (2)
l(6) = 160 + d248× 37
100e = (251)10 = (011111011)2
u(6) = 160 + d248× 75
100e − 1 = (345)10 = (101011001)2
E3 condition ⇒ Set scale3=1.
l(6) = (011110110)2 = (246)10
u(6) = (110110011)2 = (43510
Input=b (2)
l(7) = 246 + d190× 37
100e = (316)10 = (100111100)2
u(7) = 246 + d190× 75
100e − 1 = (388)10 = (110000100)2
Transmit 1Transmit 0. Scale3 = 0
l(7) = (001111000)2
u(7) = (100001001)2

prave
ndra
Chapter 4 16
To terminate the encoding send the bits in the lower limit.
Transmit 00111100.
c) Received sequence: 001010110001111000.
l(0) = (000000000)2 = (0)10
u(0) = (111111111)2 = (511)10
t = (001010010)2 = (86)10
86× 100− 1
512= 16
Compare this against the Cum Counts
k = 0 16 ≥ Cum Count[0] = 0
k = 1 16 < Cum Count[1] = 37
Decode k=1 ⇒ a.
First letter is a. Update upper and lower limits.
l(1) = 0 + d512× 0
100e = (0)10 = (000000000)2
u(1) = 0 + d512× 37
100e − 1 = (188)10 = (010111100)2
(5)
Shift out 0 from upper and lower limit and the tag and read in one more bit for thetag
l(1) = (000000000)2 = (0)10
u(1) = (101111001)2 = (377)10
t = (010101100)2 = (172)10
172× 100− 1
378= 45
k = 0 45 ≥ Cum Count[0] = 0
k = 1 45 ≥ Cum Count[1] = 37
k = 2 45 < Cum Count[2] = 75

prave
ndra
Chapter 4 17
Decode k = 2 ⇒ b
Update upper and lower limits
l(2) = 0 + d378× 37
100e = (139)10 = (010001011)2
u(2) = 0 + d378× 75
100e − 1 = (282)10 = (100011010)2
(6)
This is an E3 condition. Complement second msb on upper and lower limits and ontag and shift left. Read in a 0 into lsb of the lower limit, a 1 into lsb of the upperlimit, and a bit from the bitstream for the tag.
l(2) = (000010110)2 = (22)10
u(2) = (100110101)2 = (309)10
t = (001011000)2 = (88)10
(88− 22 + 1)× 100− 1
288= 23
k = 0 23 ≥ Cum Count[0] = 0
k = 1 23 < Cum Count[1] = 37
Decode k = 1 ⇒ a
Update upper and lower limits:
l(3) = 22 + d288× 0
100e = (22)10 = (000010110)2
u(3) = 22 + d288× 37
100e − 1 = (105)10 = (001101001)2
(7)
Shift out two 0’s from the upper and lower limits and the tag. Shift in 0’s into thelsbs of the lowerlimit, 1’s into the lsb’s of the upper limit and read two bits from thereceived bitstream into the lsb’s of the tag.
l(3) = (001011000)2 = (88)10
u(3) = (110100111)2 = (423)10
t = (101100011)2 = (355)10

prave
ndra
Chapter 4 18
(355− 88 + 1)× 100− 1
336= 79
k = 0 79 ≥ Cum Count[0] = 0
k = 1 79 ≥ Cum Count[1] = 37
k = 2 79 ≥ Cum Count[2] = 75
k = 3 79 < Cum Count[3] = 100
Decode k = 3 ⇒ c
Update upper and lower limits
l(4) = 88 + d336× 75
100e = (340)10 = (101010100)2
u(4) = 88 + d336× 100
100e − 1 = (423)10 = (110100111)2
Shift out 1 from upper and lower limits and tag.
l(4) = (010101000)2
u(4) = (101001111)2
t = (011000111)2
E3 condition. Complement second msb of upper and lower limits and tag and shiftleft.
l(4) = (001010000)2 = (80)10
u(4) = (110011111)2 = (415)10
t = (010001111)2 = (143)10
(143− 80 + 1)× 100− 1
336= 19
k = 0 19 ≥ 0
k = 1 19 < 37

prave
ndra
Chapter 4 19
Decode k = 1 ⇒ a.
Update upper and lower limits:
l(5) = 80 + d336× 0
100e = (80)10 = (001010000)2
u(5) = 80 + d336× 37
100e − 1 = (203)10 = (011001011)2
Shift 0 out of upper and lower limits and tag.
l(5) = (010100000)2 = (160)10
u(5) = (110010111)2 = (407)10
t = (100011110)2 = (286)10
(286− 160 + 1)× 100− 1
248= 51
k = 0 51 ≥ 0
k = 1 51 ≥ 37
k = 2 51 < 75
Decode k = 2 ⇒ b.
Update upper and lower limits:
l(6) = 160 + d248× 37
100e = (251)10 = (011111011)2
u(6) = 160 + d248× 75
100e − 1 = (345)10 = (101011001)2
E3 condition.
l(6) = (011110110)2 = (246)10
u(6) = (110110011)2 = (43510
t = (100111100)2 = (316)10
(316− 246 + 1)× 100− 1
190= 37

prave
ndra
Chapter 4 20
k = 0 37 ≥ 0
k = 1 37 ≥ 37
k = 2 37 < 75
Decode k = 2 ⇒ b.
Assuming we know that only seven symbols were transmitted we can stop decoding.

prave
ndra
Chapter 5 21
Chapter 5
Problem 3.
Index Codebook entry1 a2 b3 r4 y5 6 b6 a 6 b7 6 bb8 ba9 ar10 r 6 b11 6 ba12 arr13 ra14 ay15 y 6 b16 6 bby17 y 6 bb18 bar19 rr20 ray21 ya22 ar 6 b23 6 ba
Transmitted sequence is
1, 5, 2, 1, 3, 5, 9, 3, 1, 4, 7, 15, 8, 3, 13, 4, 9, 7, 14

prave
ndra
Chapter 5 22
Problem 4.
Index Codebook entry1 a2 6 b3 h4 i5 s6 t
7 th8 hi9 is10 s 6 b11 6 bh12 ha13 at14 t6 b15 6 bi16 is 6 b17 6 bhi18 is 6 bh19 hat20 t6 bi21 it22 t6 bis23 s 6 bh24 his25 s 6 bha26 at
The decoded message is this hat is his hat it is his hat

prave
ndra
Chapter 5 23
Problem 5.
Index Codebook entry1 a2 6 b3 r4 t
5 ra6 at7 ta8 ata9 atat10 t6 b11 6 ba12 a 6 b13 6 br14 rat15 t6 ba16 at6 b17 6 bab18 6 bra19 at
The decoded message is ratatatat a rat at a rat.
Problem 6.
< 0, 0, C(b) >< 0, 0, C(a) >< 0, 0, C(r) >< 1, 1, C(a) >< 0, 0, C(y) >< 5, 2, C(6 b) >
< 9, 3, C(6 b) >< 4, 1, C(y) >< 7, 4, C(r) >< 3, 1, C(y) >< 12, 4, C(a) >
Problem 7
The decoded sequence is ratatatat a rat at a rat.
Problem 8.
Initial dictionary:
Index Entry1 S2 6 b3 I4 T5 H

prave
ndra
Chapter 5 24
Received sequence: 4, 5, 3, 1, 2, 8, 2, 7, 9, 7, 4
Received Decode Update Dictionary4 T Entry 6: T . . .5 H Entry 6: TH Entry 7: H . . .3 I Entry 7: HI Entry 8: I . . .1 S Entry 8: IS Entry 9: S . . .2 6 b Entry 9: S 6 b Entry 10:6 b . . .8 IS Entry 10: 6 bI Entry 11: IS . . .2 6 b Entry 11: IS 6 b Entry 12:6 b . . .7 HI Entry 12: 6 bH Entry 13: HI . . .9 S 6 b Entry 13:HIS Entry 14:S 6 b7 HI Entry 14: S 6 bH Entry 15: HI . . .4 T Entry 15: HIT Entry 16:T . . .
Final Dictionary:
Index Entry1 S2 6 b3 I4 T5 H6 TH7 HI8 IS9 S 6 b10 6 bI11 IS 6 b12 6 bH13 HIS14 S 6 bH15 HIT16 T . . .

prave
ndra
Chapter 6 25
Chapter 6
Problem 3(a)
Lets first obtain all cyclical shifts of the message to be encoded
e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t aa e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e tt a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c ee t a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b cc e t a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b e t aa 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b e tt a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b ee t a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b bb e t a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b a n dd 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b a nn d 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b aa n d 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c e t aa 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c e tt a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c ee t a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b cc e t a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a e t aa 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a e tt a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a e
Now let’s sort the cyclically shifted sequences:

prave
ndra
Chapter 6 26
6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c e t a6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b a n d6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a e t a6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b e t aa 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c e ta 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a e ta 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b e ta e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e ta n d 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 bb e t a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 bc e t a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 bc e t a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 bd 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b a ne t a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b ce t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t ae t a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b be t a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b cn d 6 b b e t a 6 b c e t a e t a 6 b c e t a 6 b at a 6 b a n d 6 b b e t a 6 b c e t a e t a 6 b c et a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e t a et a 6 b c e t a e t a 6 b c e t a 6 b a n d 6 b b et a e t a 6 b c e t a 6 b a n d 6 b b e t a 6 b c e
The sequence consisting of the last letters of the cyclically sorted set is
a d a a t t t t 6 b 6 b 6 b 6 b n c a b c a e e e e
If we now begin with the index assignments
6 b 0a 1b 2c 3d 4e 5n 6t 7
The move to front indices are
1 4 1 0 7 0 0 0 3 0 0 0 7 6 4 6 2 2 7 0 0 0

prave
ndra
Chapter 6 27
and the original sequence has an index of 14 (the first sequence in the list has an index of0).
Problem 3(b)
In order to decode we first need to obtain the sequence of last letters from the move-to-frontindices. Using the initial index assignment the first letter (with index of 1) is decoded to bea. The index assignment changes to
a 0 d 46 b 1 e 5b 2 n 6d 3 t 7
The next index is 4 and the element with an index of 4 is d. The index assignment nowbecomes
d 0 d 4a 1 e 56 b 2 n 6b 3 t 7
nd the next decoded letter is a. Continuing in this fashion the sequence of index assignmentsand decoded letters are:
a 0 d 4d 1 e 56 b 2 n 6b 3 t 7
Decode 0 as a.
Decode 7 as t and change index assignment to:
t 0 b 4a 1 c 5d 2 e 66 b 3 n 7
Decode 0 as t.
Decode 0 as t.
Decode 0 as t.
Decode 3 as 6 b and change the index assignment to:

prave
ndra
Chapter 6 28
6 b 0 b 4t 1 c 5a 2 e 6d 3 n 7
Decode 0 as 6 b.Decode 0 as 6 b.Decode 0 as 6 b.Decode 7 as n and change index assignment to:
n 0 d 46 b 1 b 5t 2 c 6a 3 e 7
Decode 6 as c and change index assignment to
c 0 a 4n 1 d 56 b 2 b 6t 3 e 7
Decode 4 as a and change the index assignment to
a 0 t 4c 1 d 5n 2 b 66 b 3 e 7
Decode 6 as b and change the index assignment to:
b 0 6 b 4a 1 t 5c 2 d 6n 3 e 7
Decode 2 as c and change the index assignment to:
c 0 6 b 4b 1 t 5a 2 d 6n 3 e 7

prave
ndra
Chapter 6 29
Decode 2 as a and change the index assignment to:
a 0 6 b 4c 1 t 5b 2 d 6n 3 e 7
Decode 7 as e and change the index assignment to:
e 0 n 4a 1 6 b 5c 2 t 6b 3 d 7
Decode 0 as e.
Decode 0 as e.
Decode 0 as e.
Thus the decoded sequence of last letters becomes:
a d a a t t t t 6 b 6 b 6 b 6 b n c a b c a e e e e
In order to get the transformation array we need to get the sequence of first letters. This issimply the sorted version of our decoded sequence.
L: a d a a t t t t 6 b 6 b 6 b 6 b n c a b c a e e e eF : 6 b 6 b 6 b 6 b a a a a a b c c d e e e e n t t t t
From this we can construct T as
4 12 5 6 18 19 20 21 0 1 2 3 17 10 7 9 11 8 13 14 15 16
Now we begin decoding the original sequence. The last letter of the original sequence is inlocation 14 (starting the count with 0) which is an a. T [14] = 7 therefore the precedingletter is t. T [7] = 21, therefore the letter preceding t is e. T [21] = 16, therefore the letterpreceding e is c. T [16] = 11 therefore the letter preceding c is 6 b. Continuing in this fashion
T [11] = 3 ⇒ a (8)
T [3] = 6 ⇒ t
T [6] = 20 ⇒ e
T [20] = 15 ⇒ b

prave
ndra
Chapter 6 30
T [15] = 9 ⇒ 6 bT [9] = 1 ⇒ d
T [1] = 12 ⇒ n
T [12] = 17 ⇒ a
T [17] = 8 ⇒ 6 bT [8] = 0 ⇒ a
T [0] = 4 ⇒ t
T [4] = 18 ⇒ e
T [18] = 13 ⇒ c
T [13] = 10 ⇒ 6 bT [10] = 2 ⇒ a
T [2] = 5 ⇒ t
T [5] = 19 ⇒ e
and we obtain the decoded sequence.

prave
ndra
Chapter 7 31
Chapter 7
Problem 1
Let w(n) and b(n) represent white and black runs of length n respectively.
The lines of the image are w(16)w(4), b(1), w(2), b(1), w(1), b(1), w(6)w(4), b(1), w(2), b(1), w(8)w(4), b(4), w(1), b(1), w(6)w(4), b(1), w(2), b(1), w(1), b(1), w(6)w(4), b(1), w(2), b(1), w(1), b(1), w(6)w(16)w(16)
Replacing the runlengths with the corresponding modified Huffman codes:
1010101011, 010, 0111, 010, 000111, 010, 11101011, 010, 0111, 010, 100111011, 011, 000111, 010, 11101011, 010, 0111, 010, 000111, 010, 11101011, 010, 0111, 010, 000111, 010, 1110101010101010
Problem 4 a
Number of bits in 15 seconds: 9600× 15 = 144, 000.
This corresponds to 144,0008
= 18, 000 pixels.
At 512 pixels per line this is a little more than 35 lines which corresponds to about 6.9% ofthe image.
Problem 4 b
There are 512×5128×8
= 4, 096 8× 8 blocks in the image. If each block is represented by a singlepixel, this corresponds to 32,768 bits which would be transmitted in 3.4133 seconds over a9600 bps line. The second approximation would require three times as many pixel or 10.24seconds. Together the first two approximations would require about 13.65 seconds.

prave
ndra
Chapter 8 32
Chapter 8
Problem 2.
a)
M = 1 : R = 1 D = 0;
M = 2 : R =1
2
We have four possibilities with the following probabilities and distortions:
Message Probability Distortion00 P (0)2 001 P (0)(1− P (0)) 1
2
10 P (0)(1− P (0)) 12
11 (1− P (0))2 0
Total distortion D = 0.16
Similarly (with more calculations) we obtain
M = 4 : R = 0.25 D = 0.1856
M = 8 : R = 0.125 D = 0.1970
M = 16 : R = 0.0625 D = 0.199780
For a binary source
R =
{Hb(p)−Hb(D) D < min p, 1− p0 otherwise
(9)
Comparing with the rate distortion function
Distortion Rate from scheme Optimal rate0.0 1.0 0.7219280.16 0.5 0.0876190.1856 0.25 0.0297520.1970 0.125 0.0060410.199780 0.0625 0.000440
b) If we encoded the output of the encoder using an entropy code which achieves aperformance equal to the entropy the comparison is not as lopsided

prave
ndra
Chapter 8 33
Distortion Rate from entropy coded scheme Optimal rate0.0 0.721928 0.7219280.16 0.12 0.0876190.1856 0.045 0.0297520.1970 0.01043 0.0060410.199780 0.0010 0.000440
Problem 4.
H(Xd|Yd) = −∞∑
j=−∞
∞∑i=−∞
P (xi|yj)P (yj) logP (xi|yj)
= −∞∑
j=−∞
∞∑i=−∞
fX|Y (xi|yj)∆fY (yj)∆ log fX|Y (xi|yj)∆
= −∞∑
j=−∞
∞∑i=−∞
fX|Y (xi|yj)fY (yj)∆∆ log fX|Y (xi|yj)∆
−∞∑
j=−∞
∞∑i=−∞
fX|Y (xi|yj)fY (yj)∆∆ log ∆
= −∞∑
j=−∞
∞∑i=−∞
fX|Y (xi|yj)fY (yj)∆∆ log fX|Y (xi|yj)− log ∆
(10)
Problem 5.
H(X|Y )−H(X) = −N−1∑i=0
M−1∑j=0
P (xi, yj) logP (xi|yj) +N−1∑i=0
M−1∑j=0
P (xi, yj) logP (xi)
=N−1∑i=0
M−1∑j=0
P (xi, yj) logP (xi)
P (xi|yj)
= E
[log
P (xi)
P (xi|yj)
]
Now we use Jensen’s inequality
H(X|Y )−H(X) = E
[log
P (X)
P (X|Y )
]
≤ log
[E
[P (X)
P (X|Y )
]]

prave
ndra
Chapter 8 34
= log
N−1∑i=0
M−1∑j=0
P (xi, yj)P (xi)
P (xi|yj)
= log
N−1∑i=0
M−1∑j=0
P (yj)P (xi)
= 0
where equality is achieved when P (xi) = P (xi|yj) or in other word the random variables Xand Y are independent.
Problem 6
I(X;Y ) =N−1∑i=0
M−1∑j=0
P (xi, yj) logP (xi|yj)
P (xi)
=N−1∑i=0
M−1∑j=0
P (xi, yj) logP (xi, yj)
P (xi)P (yj)
=N−1∑i=0
M−1∑j=0
P (xi, yj) logP (yj|xi)
P (yj)
= I(Y ;X)
Problem 7
I(X;Y ) = H(X)−H(X|Y )
H(X) = −p log p− (1− p) log(1− p) = Hb(p)
H(X|Y ) = −P (0|0)P (Y = 0) logP (0|0)− P (0|1)P (Y = 1) logP (0|1)− P (1|0)P (Y = 0) logP (1|0)− P (1|1)P (Y = 1) logP (1|1)
= −(1−D)P (Y = 0) log(1−D)−DP (Y = 1) logD −DP (Y = 0) logD − (1−D)P (Y = 1) log(1−D)
= −[(1−D) log(1−D)][P (Y = 0) + P (Y = 1)]− [D logD][P (Y = 0) + P (Y = 1)]
= −(1−D) log(1−D)−D logD
= Hb(D)
ThereforeI(X;Y ) = Hb(p)−Hb(D)

prave
ndra
Chapter 9 35
Chapter 9
Problem 1. Leibnitz rule is given by
δ
δt
∫ b(t)
a(t)f(x, t)dx =
∫ b(t)
a(t)
δ
δtf(x, t)dx+ f(b(t), t)
δ
δtb(t)− f(a(t), t)
δ
δta(t)
where a(t) and b(t) are monotonic functions of t.
The quantization noise power is given by:
σ2q = 2
M2−1∑
i=1
∫ i∆
(i−1)∆
(x− 2i− 1
2∆)2
fX(x)dx+ 2∫ ∞
(M2−1)∆
(x− M − 1
2∆)2
fX(x)dx
Taking a derivative with respect to ∆ and using Leibnitz rule we obtain:
δ
δtσ2
q = 2
M2−1∑
i=1
[2(−(2i− 1)
2)∫ i∆
(i−1)∆
(x− 2i− 1
2∆)fX(x)dx+
i∆2
4fX(i∆)− (i− 1)∆2
4fX((i− 1)∆)
]
+
[2(−(M − 1)
2)∫ ∞
(M2−1)∆
(x− M − 1
2∆)fX(x)dx−
(M2− 1)∆2
4fX((
M
2− 1)∆)
]
Setting this to zero and noticing that
M2−1∑
i=1
[i∆2
4fX(i∆)− (i− 1)∆2
4fX((i− 1)∆)
]=
(M2− 1)∆2
4fX((
M
2− 1)∆)
we obtain the desired result.
Problem 6.
Input c(x) Quantize c−1(x) Uniformly quantized-0.8 -1.6 -1.5 -0.75 -0.51.2 2.13 2.5 1.75 1.50.5 1.0 0.5 0.25 0.50.6 1.2 1.5 0.75 0.53.2 3.47 3.5 3.25 3.5-0.3 -0.6 -0.5 -0.25 -0.5

prave
ndra
Chapter 10 36
Chapter 10
Problem 1
Decrease in mse due to the inclusion of an output point at (∆, 0) is 0.0038. By symmetry,the same is true for the inclusion of outputs at the other three points. The increased msebecause of the removal of one of the corner points is 0.00026
σ2q,original = 10−
SNR10 = 0.07178
σ2q,new = 0.05768
SNRnew = 12.39dB
Therefore the increase in SNR is 0.95 dB
Problem 5
a) Referring to Figure 5:
PA =∫ 3∆
2∆e−√
2xdx∫ 4∆
3∆e−√
2ydy = 0.00059
PB =
(∫ 4∆
3∆e−√
2xdx
)2
= 0.00021
Total increase in overload probability is 8PA + 4PB = 0.0056.
b)
PC =∫ ∆
0
1√2e−√
2xdx∫ 5∆
4∆
1√2e−√
2ydy = 0.00166
Decrease of probability of overload is 8PC = 0.01329.

prave
ndra
Chapter 10 37
A
A
B
CC
AB
A
C
C
C
C
A
A BB
A
A
Figure 5: Figure for Problem 5 in Chapter 10.

prave
ndra
Chapter 12 38
Chapter 12
Problem 1. Let X = {a1, a2, · · · , aN} then
V = {v : v =N∑
i=1
ciai, ci ∈ R}
where R denotes the set of real numbers.
1a. Let v1,v2 ∈ V . Then by definition
v1 =N∑
i=1
αiai, and v2 =N∑
i=1
βiai
for {αi}, {βi} ∈ R, and
v1 + v2 =N∑
i=1
αiai +N∑
i=1
βiai =N∑
i=1
(αi + βi)ai
Define γi = αi + βi, then γi ∈ R and
v1 + v2 =N∑
i=1
γiai
and v1 + v2 ∈ V1b. By picking ci to be zero for all i, we obtain a vector θ which by definition is in V andfor which vi + θ = vi for all vi ∈ V . Thus θ is the additive identity and it is contained in V .
1c. Let x =∑N
i=1 αiai. Define
−x =N∑
i=1
(−αi)ai
If αi ∈ R then (−αi) ∈ R and −x ∈ V
Problem 2. Let F (ω) = F [f(t)] and assume all integrals exist and we can switch the orderof integration. ∫ ∞
−∞|f(t)|2dt =
∫ ∞
−∞f(t)f ∗(t)dt
=∫ ∞
−∞
[1
2π
∫ ∞
−∞F (ω)ejωtdω
]f ∗(t)dt
=1
2π
∫ ∞
−∞F (ω)
[∫ ∞
−∞f ∗(t)ejωtdt
]dω
=1
2π
∫ ∞
−∞F (ω)
[∫ ∞
−∞f(t)e−jωtdt
]∗dω
=1
2π
∫ ∞
−∞F (ω)F ∗(ω)dω
=1
2π
∫ ∞
−∞|F (ω)|2dω

prave
ndra
Chapter 12 39
Problem 3. Let F (ω) = F [f(t)].
F[f(t)ejωot
]=
∫ ∞
−∞f(t)ejωote−jωtdt
=∫ ∞
−∞f(t)e−j(ω−ωo)tdt
= F (ω − ωo)
Problem 4. Let F (ω) = F [f(t)], F1(ω) = F [f1(t)], and F2(ω) = F [f2(t)], and assumethat all the integrals exist and we can change the order of integration.
F (ω) =∫ ∞
−∞f(t)e−jωtdt
=∫ ∞
−∞
∫ ∞
−∞f1(τ)f2(t− τ)dτe−jωtdt
=∫ ∞
−∞
∫ ∞
−∞f1(τ)f2(t− τ)e−jωtdτdt
Let u = t− τ , then t = u+ τ and dt = du.
F (ω) =∫ ∞
−∞f1(τ)
∫ ∞
−∞f2(u)e
−jω(u+τ)dudτ
=∫ ∞
−∞f1(τ)e
−jωτ[∫ ∞
−∞f2(u)e
−jωudu]dτ
=∫ ∞
−∞f1(τ)e
−jωτF2(ω)dτ
= F1(ω)F2(ω)
Problem 5. We will make use of the fact that as the inverse Fourier transform of the deltafunction is given by
F−1 [δ(ω)] =1
2πδ(ω)e−jωtdω =
1
2π
Therefore, by uniqueness of the Fourier transform
F[
1
2π
]= δ(ω)
We will also make use of the modulation property of the Fourier transform.
First note that f(t) =∑∞
n=−∞ δ(t− nT ) is a periodic function with period T and thereforehas a Fourier series representation
f(t) =∞∑
n=−∞cne
jnωot, ωo =2π
T

prave
ndra
Chapter 12 40
cn =1
T
∫ T2
−T2
∞∑n=−∞
δ(t− nT )dt =1
T
∫ T2
−T2
δ(t)dt =1
T
Therefore,
f(t) =1
T
∞∑n=−∞
ejnωot
= =ωo
2π
∞∑n=−∞
ejnωot
= ωo
∞∑n=−∞
1
2πejnωot
Now using the fact that F[
12π
]= δ(ω) and the modulation property
F[
1
2πejnωot
]= δ(ω − nωo)
F (ω) = F [f(t)]
= F[ωo
∞∑n=−∞
1
2πejnωot
]
= ωo
∞∑n=−∞
F[
1
2πejnωot
]
= ωo
∞∑n=−∞
δ(ω − ωo)
Problem 6.
(a).
H(z) =∞∑
n=0
2−nz−n
=∞∑
n=0
(2−1z−1)n
=1
1− 2−1z−1|2−1z−1| < 1
=2z
2z − 1|z| > 1
2
(b).
H(z) =∞∑
n=0
(n2 − n)3−nz−n

prave
ndra
Chapter 12 41
=∞∑
n=0
n(n− 1)3−nz−n
= 3−2∞∑
n=0
n(n− 1)(3−1)n−2z−n
Setting m = 2 in Example 11.9.2
H(z) =1
9
2z
(z − 13)2
(c).
H(z) =∞∑
n=0
(n2−n + 0.6n)z−n
=∞∑
n=0
n2−nz−n +∞∑
n=0
0.6nz−n
=1
2
∞∑n=0
n(2−1)n−1z−n +∞∑
n=0
0.6nz−n
=1
2
z
(z − 12)2
+z
z − 0.6|z| > 0.6
Problem 7.
(a).
yn = 0.6yn−1 + 0.5xn + 0.2xn−1
Y (z) = 0.6z−1Y (z) + 0.5X(z) + 0.2z−1X(z)
Therefore,Y (z)(1− 0.6z−1) = (0.5 + 0.2z−1)X(z)
and
H(z) =Y (z)
X(z)=
0.5 + 0.2z−1
1− 0.6z−1
=5z + 2
10z − 6
(b).
H(z) =5z + 2
10z − 6
Performing long division we obtain the series
0.5 + 0.5z−1 + 0.3z−2 + 0.18z−3 + 0.108z−4 + 0.0648z−5 + · · ·

prave
ndra
Chapter 12 42
At this time we can see the pattern. From the third term on the nth element of the seriesis of the form 0.3(0.6)n−2. Therefore,
hn =
{.5 n = 0, 10.3(0.6)n−2 n > 1
Problem 8.
(a)
H(z) =5
z − 2
We have a pole outside the unit circle therefore this is the Z-transform of a left handedsequence. Therefore, {hn} is of the form
h0 + h−1z + h−2z2 + · · ·
Using the long division method we get the series
−5
2− 5
4z − 5
8z2 − 5
16z3 − · · ·
Therefore,
hn =
{−5(2)−(n+1) n = 0,−1,−2, · · ·0 n = 1, 2, 3, · · ·
(b)
H(z) =z
z2 − 0.25=
z
(z − 0.5)(z + 0.5)
Let’s expand this using partial fraction expansion:
H(z)
z=
6 z6 z(z − 0.5)(z + 0.5)
=A1
z − 0.5+
A2
z + 0.5
To find the coefficients A1 and A2
A1 =1
z + 0.5|z=0.5 = 1
A2 =1
z − 0.5|z=−0.5 = −1
Therefore,
H(z) =z
z − 0.5− z
z + 0.5
andhn = 0.5nu[n]− (−0.5)nu[n]

prave
ndra
Chapter 12 43
(c)
H(z) =z
z − 0.5
By inspection,hn = 0.5nu[n]

prave
ndra
Chapter 13 44
Chapter 13
Problem 1
|X1 −X2|2 = (X1 −X2)T (X1 −X2)
= (AT Θ1 − AT Θ2)T (AT Θ1 − AT Θ2)
= ΘT1AA
T Θ1 −ΘT1AA
T Θ2 −ΘT2AA
T Θ1 + ΘT2AA
T Θ2
= ΘT1 Θ1 −ΘT
1 Θ2 −ΘT2 Θ1 + ΘT
2 Θ2
= |Θ1 −Θ2|2
Problem 2a.
If we transform
10 11 12 11 12 13 12 11
we obtain the coefficients
32.527 -1.281 -1.307 0.450 -1.414 -0.301 0.541 0.255
Notice that the DC coefficient has a rather high value while the other coefficients haverelatively low values.
When we transform the vector
10 -10 8 -7 8 -8 7 -7
we obtain the coefficients
0.354 4.251 0.350 5.046 2.475 8.384 1.769 20.388
This time the higher frequency coefficients have larger magnitudes than the low frequencycoefficients.
Concatenating the coefficients we obtain the plot shown in Figure 6.
Problem 2b. If we concatenate the two vectors and take a 16 point DCT the results are
23.25 21.78 -3.92 -6.96 -0.68 6.04 -3.25 -2.57 0.75 3.16 -6.14 1.61 1.63 5.50 -14.24 13.56
The results are plotted in Figure 7
Problem 2c. Comparing the plots shown in Figures 6 and 7 we can see that we obtaina larger number of coefficients with relatively large magnitudes when we use the 16 pointDCT. This is due to the differing natures of the two vectors. As more large magnitudecoefficients mean more bits required, it would be better from a compression perspective touse two 8 points DCT rather than one 16 point DCT in this example.

prave
ndra
Chapter 13 45
0 2 4 6 8 10 12 14 16−15
−10
−5
0
5
10
15
20
25
30
35
8 po
int D
CT
coe
ffici
ents
Figure 6: Plot of the 8 point coefficients of the two vectors. The first eight coefficients belongto the first vector while the second eight coefficients are the result of an 8 point DCT of thesecond vector.

prave
ndra
Chapter 13 46
0 2 4 6 8 10 12 14 16−15
−10
−5
0
5
10
15
20
25
30
35
16 p
oint
DC
T c
oeffi
cien
ts
Figure 7: Plot of the 16 point DCT coefficients obtained by taking the 16 point DCT of theconcatenation of the two vectors.

prave
ndra
Chapter 13 47
Problem 3
a) By rows: 10 2 4 07 1 3 15 1 1 14 0 0 0
Then by columns:
26 4 8 24 2 2 08 2 6 02 0 0 −2
b) By columns first:
10 7 5 42 1 1 04 3 1 00 1 1 0
Then by rows:
26 4 8 24 2 2 08 2 6 02 0 0 −2
c) Results of a) and b) are identical.

prave
ndra
Chapter 14 48
Chapter 14
Problem 1 The impulse response {hn} of a system is the output when the input is δn where
δn =
{1 n = 00 otherwise
By the second property if the input to the system is aδn then the output is {yn} = {αhn}.Let’s write this as
αδn ⇒ {αhn}
We can write the input sequence {xn} as
{xn} = x0δn + x1δn−1 + x2δn−2 + · · ·
Using both properties we can see that
x0δn ⇒ {x0hn}x1δn−1 ⇒ {x1hn−1}x2δn−2 ⇒ {x2hn−2}
......
xMδn−M ⇒ {xMhn−M}...
...
Adding the left side we obtain the input sequence. By the second property the correspondingoutput is the sum of the right side or
yn =∑
xkhn−k
Problem 2.
(a) Let’s use a very simple impulse response:
h1,0 =1
2, h1,1 =
1
2, h1,2 =
1
2, h1,3 = −1
2
This satisfies the requirement that |h1,j| = |h1,k|. Furthermore,
3∑i=0
h21,i = 4× 1
4= 1
and3∑
i=0
h1,ih1,i+2 = h1,0h1,2 + h1,1h1,3 =1
4− 1
4= 0
and the orthonormality requirement is satisfied.

prave
ndra
Chapter 14 49
(b) The magnitude and phase response of this filter are plotted in Figure 8. It is not a verygood filter.
(c) Using Equation (13.23) we obtain the following coefficients for the high pass filter:
h2,0 = −1
2, h2,1 = −1
2, h1,2 =
1
2, h1,3 = −1
2
(d) The magnitude and phase response of th high pass filter are plotted in Figure 9.
Problem 3.
x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 · · ·1 -1 1 -1 1 -1 1 -1 1 -1 1 · · ·
(a)
yn = h0xn + h1xn−1
=1√2xn +
1√2xn−1
y0 =1√2× 1 +
1√2× 0 =
1√2
y1 =1√2× (−1) +
1√2× 1 = 0
y2 =1√2× 1 +
1√2× (−1) = 0
y3 =1√2× (−1) +
1√2× 1 = 0
......
Or
yn =
{1√2
n = 0
0 n > 0
(b)
wn = h0xn + h1xn−1
=1√2xn −
1√2xn−1
w0 =1√2× 1− 1√
2× 0 =
1√2

prave
ndra
Chapter 14 50
w1 =1√2× (−1)− 1√
2× 1 = −
√2
w2 =1√2× 1− 1√
2× (−1) =
√2
w3 =1√2× (−1)− 1√
2× 1 = −
√2
......
Or
wn =
{1√2
n = 0√2(−1)n n > 0
(c) The filter response in part (a) corresponds to a low pass filter and the filter response inpart (b) corresponds to a high pass filter. After the initial transient the output of the lowpass filter is zero while the output of the high pass filter is an amplified version of the input.Thus the input is a high pass signal.
Problem 4.
x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 · · ·1 1 1 1 1 1 1 1 1 1 1 · · ·
(a)
yn = h0xn + h1xn−1
=1√2xn +
1√2xn−1
y0 =1√2× 1 +
1√2× 0 =
1√2
y1 =1√2× 1 +
1√2× 1 =
√2
y2 =1√2× 1 +
1√2× 1 =
√2
y3 =1√2× 1 +
1√2× 1 =
√2
......
Or
yn =
{1√2
n = 0√2 n > 0

prave
ndra
Chapter 14 51
(b)
wn = h0xn + h1xn−1
=1√2xn −
1√2xn−1
w0 =1√2× 1− 1√
2× 0 =
1√2
w1 =1√2× 1− 1√
2× 1 = 0
w2 =1√2× 1− 1√
2× 1 = 0
w3 =1√2× 1− 1√
2× 1 = 0
......
Or
wn =
{1√2
n = 0
0 n > 0
(c) After the initial transient the output of the high pass filter is zero while the output ofthe low pass filter is an amplified version of the input. Thus the input is a low pass signal.

prave
ndra
Chapter 14 52
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−400
−300
−200
−100
0
Normalized Frequency (×π rad/sample)
Pha
se (
degr
ees)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−8
−6
−4
−2
0
2
4
Normalized Frequency (×π rad/sample)
Mag
nitu
de (
dB)
Figure 8: Magnitude and phase response of a filter with impulse response {0.5,0.5,0.5,-0.5}.

prave
ndra
Chapter 14 53
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
50
100
150
200
Normalized Frequency (×π rad/sample)
Pha
se (
degr
ees)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−8
−6
−4
−2
0
2
4
Normalized Frequency (×π rad/sample)
Mag
nitu
de (
dB)
Figure 9: Magnitude and phase response of a filter with impulse response {-0.5,-0.5,0.5,-0.5}.

prave
ndra
Chapter 15 54
Chapter 15
Problem 1
(a)
f(t) = sin(2t) =ej2t − e−j2t
2j
The Fourier transform is given by
F (ω) = F[ej2t − e−j2t
2j
]
=1
2jF[ej2t
]− 1
2jF[e−j2t
]by linearity
=1
2j[δ(ω − 2)− δ(ω + 2)]
(b)
f1(t) =
{sin(2t) −2 ≤ t ≤ 20 otherwise
F1(ω) =∫ 2
−2sin(2t)e−jωtdt
=∫ 2
−2
[ej2t − e−j2t
2j
]e−jωtdt
=1
2j
[∫ 2
−2e−j(w−2)tdt−
∫ 2
−2e−j(w+2)tdt
]
=2
j
[sin(2(ω − 2))
2(ω − 2)− sin(2(ω + 2))
2(ω + 2)
]
(c)
f2(t) =
{(1 + cos(π
2t)) sin(2t) −2 ≤ t ≤ 2
0 otherwise
F2(ω) =∫ 2
−2(1 + cos(
π
2t)) sin(2t)e−jωtdt
=∫ 2
−2sin(2t)e−jωtdt+
∫ 2
−2cos(
π
2t) sin(2t)e−jωtdt
The first integral is identical to part (b). Evaluating the second integral we obtain
1
j
[sin(2(w − π
2− 2))
2(w − π2− 2)
−sin(2(w − π
2+ 2))
2(w − π2
+ 2)+
sin(2(w + π2− 2))
2(w + π2− 2)
−sin(2(w + π
2+ 2))
2(w + π2
+ 2)
]

prave
ndra
Chapter 15 55
(d) The magnitudes of F (ω), F1(ω), and F2(ω) are plotted in Figure 10, Figure 11 andFigure 12.
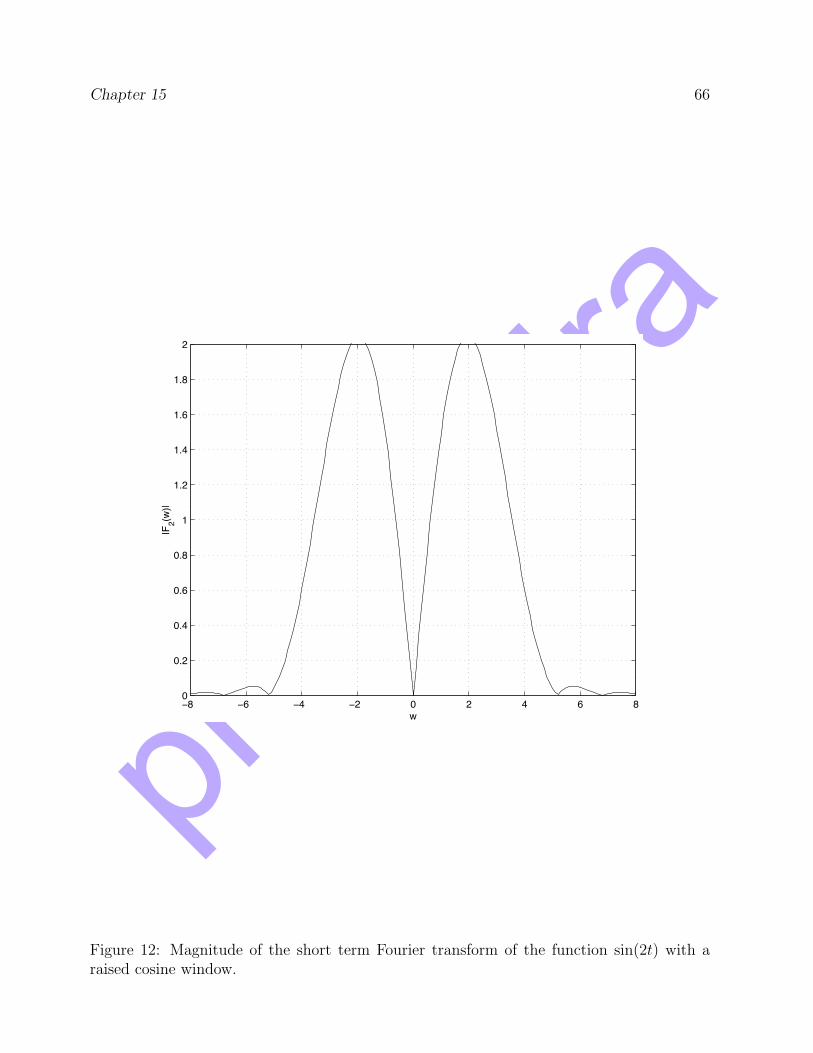
While both short term Fourier transforms broaden out the peak, the use of the rectangularwindow introduces a number of extraneous peaks of significant size. The use of the raisedcosine window considerably reduces the size of these extraneous peaks.
Problem 2.
f(t) =
{1 + sin(2t) 0 ≤ t ≤ 1sin(2t) otherwise
ψ(t) =
{1 0 ≤ t < 1
2
−1 12≤ t < 1
cj,k =∫f(t)ψj,k(t)dt
andψj,k(t) = 2j/2ψ(2jt− k)
c0,0 =∫ 1
0f(t)ψ(t)dt
=∫ 1
2
0(1 + sin(2t)−
∫ 1
12
(1 + sin(2t))dt
=1
2[− cos(0) + 2 cos(1)− cos(2)]
c0,1 =∫ 2
1f(t)ψ(t− 1)dt
=∫ 3
2
1sin(2t)dt−
∫ 2
32
sin(2t))dt
=1
2[− cos(2) + 2 cos(3)− cos(4)]
c0,2 =∫ 3
2f(t)ψ(t− 2)dt
=∫ 5
2
2sin(2t)dt−
∫ 3
52
sin(2t))dt
=1
2[− cos(4) + 2 cos(5)− cos(6)]
We can see a pattern here:

prave
ndra
Chapter 15 56
c0,k =1
2[− cos(2k) + 2 cos(2k + 1)− cos(2k + 2)]
To find c1,k we use
c1,k =√
2∫ψ(2t− k)f(t)dt
So
c1,0 =√
2∫ 1
4
0(1 + sin(2t))dt−
√2∫ 1
2
14
(1 + sin(2t))dt
=
√2
2
[− cos(0) + 2 cos(
1
2− cos(1)
]
c1,1 =√
2∫ 3
4
12
(1 + sin(2t))dt−√
2∫ 1
34
(1 + sin(2t))dt
=
√2
2
[− cos(1) + 2 cos(
3
2− cos(2)
]
c1,2 =√
2∫ 5
4
1sin(2t)dt−
√2∫ 3
2
54
sin(2t)dt
=
√2
2
[− cos(2) + 2 cos(
5
2− cos(3)
]
Again, we can see the pattern:
c1,k =
√2
2
[− cos(k) + cos(
2k + 1
2)− cos(k + 1)
]
Continuing for c2,k we find that
c2,k =2
2
[− cos(
k
2) + cos(
2k + 1
4)− cos(
k + 1
2)
]
Looking at the expressions for c0,k, c1,k and c2,k we can see a common pattern:
cj,k =2
j2
2
[− cos(
2k
2j) + 2 cos(
2k + 1
2j)− cos(
2k + 2
2j)
]
Problem 3. We assume the following:

prave
ndra
Chapter 15 57
• We have a bit budget of 30 bits.
• We can send the initial threshold value To separately without effecting the bit budget.
• We use the following codes
Zerotree root zr 00Significant positive sp 11Significant negative sn 01Isolated zero iz 10
21 6 15 12-6 3 6 33 -3 0 -33 0 0 0
T0 = 16
Dominant Pass:
21 ⇒ sp [11]
6 ⇒ zr [00]
−6 ⇒ zr [00]
3 ⇒ zr [00]
Ls = {21}Refinement Pass:
21− 24 = 3 ⇒ Correction term = −4 [0]
Second Pass:
T0 = 8
Dominant Pass:
6 ⇒ iz [10]
−6 ⇒ zr [00]
3 ⇒ zr [00]
15 ⇒ sp [11]
12 ⇒ sp [11]
6 ⇒ iz [10]
3 ⇒ iz [10]
Ls = {21, 15, 12}

prave
ndra
Chapter 15 58
Refinement Pass:
21− 20 = 1 ⇒ Correction term = 2 [1]
15− 12 = 3 ⇒ Correction term = 2 [1]
12− 12 = 0 ⇒ Correction term = −2 [0]
Third Pass:
Pass:
T0 = 4
Dominant Pass:
6 ⇒ sp [11]
−6 ⇒ sn [01]
And we have used up thirty bits.
The transmitted bitstream is
110000000100000111110101101101
(b)
The received bitstream is
110000000100000111110101101101
and we begin with knowledge of the initial threshold and size of the image. For sake referencelets represent the “image” as
a b e fc d g hi j m nk l o p
To = 16 and the first codeword is 11 or sp. Therefore
a = 24
The next three codewords are 00 corresponding to a zerotree root. Therefore,
b = c = d = e = f = g = h = i = j = k = l = m = n = o = p = 0
There are no tree roots that are significant so this is the end of the first dominant pass. Atthe end of this pass Ls = {a}. In the refinement pass we get a 0 corresponding to a negativecorrection for a. Therefore,
a = 24− 4 = 20

prave
ndra
Chapter 15 59
The next bits are from the second dominant pass.
To = 8 and 10 means an isolated zero. Thus b < To but some of the descendants of b aregreater than To.
The next codeword is 00 therefore, c is a zerotree root.
The next codeword is 00 therefore, d is a zerotree root.
As b was an isolated zero the next bits correspond to its descendants.
11 means e is significant, therefore, e = 12
11 means f is significant, therefore, f = 12
10 means g is insignificant, therefore, g = 0
10 means h is insignificant, therefore, h = 0
The significance list now becomes Ls = {a, e, f}1 means a positive correction, therefore, a = 20 + 2 = 22.
1 means a positive correction, therefore, e = 12 + 2 = 14.
0 means a negative correction, therefore, f = 12− 2 = 10.
Now we start the third dominant pass with To = 4.
11 means b is significant, therefore, b = 6
01 means c is significant negative, therefore, c = −6.
and we have reached the end of the received bitstream.
The reconstructed image is as follows
22 6 14 10-6 0 0 00 0 0 00 0 0 0
Problem 4. We assume the following:
• We have a bit budget of 30 bits.
• We can send the initial value of n separately without effecting the bit budget.
21 6 15 12-6 3 6 33 -3 0 -33 0 0 0

prave
ndra
Chapter 15 60
First Pass n = 4
LIP : {(0, 0), (0, 1), (1, 0), (1, 1)}LIS : {(0, 1)D, (1, 0)D, (1, 1)D}LSP : {}
First examine the contents of LIP .
(0, 0) → 21 |21| ≥ 16 Transmit 11 and move to LSP
(0, 1) → 6 |6| < 16 Transmit 0
(1, 0) → −6 | − 6| < 16 Transmit 0
(1, 1) → 3 |3| < 16 Transmit 0
Now examine the contents of LIS
(0, 1)Dis not significant Transmit 0
(1, 0)Dis not significant Transmit 0
(1, 1)Dis not significant Transmit 0
LSP is empty.
Transmitted bits from the first pass:
11000000
Second Pass n = 3
LIP : {(0, 1), (1, 0), (1, 1)}LIS : {(0, 1)D, (1, 0)D, (1, 1)D}LSP : {(0, 0)}
First examine the contents of LIP .
(0, 0) → 21 |21| ≥ 16 Transmit 11 and move to LSP
(0, 1) → 6 |6| < 8 Transmit 0
(1, 0) → −6 | − 6| < 8 Transmit 0
(1, 1) → 3 |3| < 8 Transmit 0

prave
ndra
Chapter 15 61
Now examine the contents of LIS
(0, 1)Dis significant Transmit 1
(0, 2) → 15 |15| ≥ 8 Transmit 11 and move to LSP
(0, 3) → 12 |12| ≥ 8 Transmit 11 and move to LSP
(1, 2) → 6 |6| < 8 Transmit 0 and move to LIP
(1, 3) → 3 |3| < 8 Transmit 0 and move to LIP
(1, 0)Dis not significant Transmit 0
(1, 1)Dis not significant Transmit 0
Finally, for the second pass, examine the contents of LSP
(0, 0) → 21 n = 3 Transmit 0
Transmitted bits in the second pass.
0001111100000
Third Pass n = 2
LIP : {(0, 1), (1, 0), (1, 1), (1, 2), (1, 3)}LIS : {(1, 0)D, (1, 1)D}LSP : {(0, 0), (0, 2), (0, 3)}
First examine the contents of LIP .
(0, 1) → 6 |6| ≥ 4 Transmit 11 and move to LSP
(1, 0) → −6 | − 6| ≥ 4 Transmit 10 and move toLSP
(1, 1) → 3 |3| < 4 Transmit 0
(1, 2) → 6 |6| ≥ 4 Transmit 11 and move to LSP
(1, 3) → 3 |3| < 4 Transmit 0
Now examine the contents of LIS
(1, 0)Dis not significant Transmit 0
And we have used up the thirty bits.

prave
ndra
Chapter 15 62
The transmitted bits are
110000000001111100000111001100
(b)
The received bits are
110000000001111100000111001100
Begin with n = 4.
LIP : {(0, 0), (0, 1), (1, 0), (1, 1)}LIS : {(0, 1)D, (1, 0)D, (1, 1)D}LSP : {}
First LIP
11 ⇒ (0, 0) → 16, move to LSP
0 ⇒ (0, 1) → 0
0 ⇒ (1, 0) → 0
0 ⇒ (1, 1) → 0
Then to LIS
0 ⇒ (0, 1)D is insignificant
0 ⇒ (1, 0)D is insignificant
0 ⇒ (1, 1)D is insignificant
LSP is empty.
Second pass, n = 3.
LIP : {(0, 1), (1, 0), (1, 1)}LIS : {(0, 1)D, (1, 0)D, (1, 1)D}LSP : {(0, 0)}
Begin with LIP
0 ⇒ (0, 1) → 0
0 ⇒ (1, 0) → 0
0 ⇒ (1, 1) → 0

prave
ndra
Chapter 15 63
Then to LIS
1 ⇒ (0, 1)D is significant
11 ⇒ (0, 2) → 8 move to LSP
11 ⇒ (0, 3) → 8 move to LSP
0 ⇒ (0, 2) → 0 move to LIP
0 ⇒ (0, 2) → 0 move to LIP
0 ⇒ (1, 0)D is insignificant
0 ⇒ (1, 1)D is insignificant
(11)
On to LSP .
0 ⇒ (0, 0) → 16
Third pass, n = 2.
LIP : {(0, 1), (1, 0), (1, 1), (1, 2), (1, 3)}LIS : {(1, 0)D, (1, 1)D}LSP : {(0, 0), (0, 2), (0, 3)}
Begin with LIP
11 ⇒ (0, 1) → 4 move to LSP
10 ⇒ (1, 0) → −4 move to LSP
0 ⇒ (0, 1) → 0
11 ⇒ (1, 2) → 4 move to LSP
0 ⇒ (1, 3) → 0
Now to LIS
0 ⇒ (1, 0)D is not significant
We have reached the end of transmission. The reconstructed “image” is
16 4 8 8-4 0 4 00 0 0 00 0 0 0

prave
ndra
Chapter 15 64
−8 −6 −4 −2 0 2 4 6 80
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
|F(w
)|
w
Figure 10: Magnitude of the Fourier transform of the function sin(2t).

prave
ndra
Chapter 15 65
−8 −6 −4 −2 0 2 4 6 80
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
|F1(w
)|
w
Figure 11: Magnitude of the short term Fourier transform of the function sin(2t) with arectangular window.
prave
ndra
Chapter 15 66
−8 −6 −4 −2 0 2 4 6 80
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
|F2(w
)|
w
Figure 12: Magnitude of the short term Fourier transform of the function sin(2t) with araised cosine window.