data caching evolution - the safepeak deck from webcast 2014-04-24
TRANSCRIPT

October 15, 2015
Data Caching
Evolution
SafePeak Technologies Ltd.

2
Data Caching is a key component for high performance and
scalability application-database architecture
Reasons for application caching:
• Improve response times: reducing read data latency –
results are already in-memory cache
• Offload the “read load” from database servers (CPU & I/O)
• Improve overall system scalability and operational efficiency
Reasons for Data Caching

3
Evolution of Data Caching
DYI Local Caching
DYI Distributed Caching: Key-Value (KV)
DYI Data Grids:Distributed KV + Complex computing
AUTOMATED DYNAMIC CACHING:Automated performance with full data coherency
4
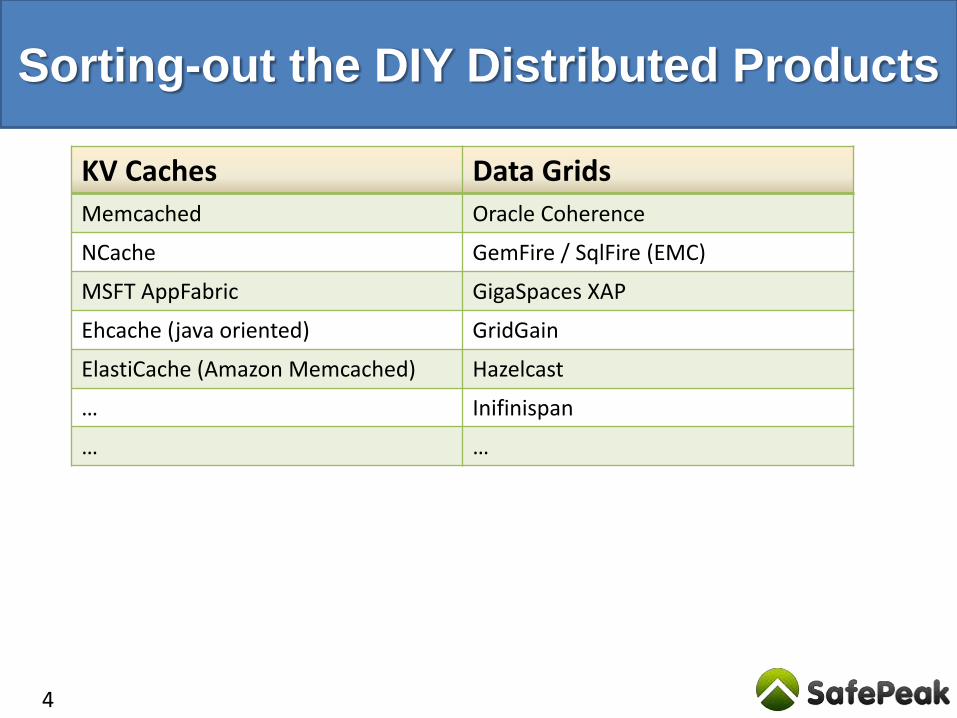
Sorting-out the DIY Distributed Products
KV Caches Data Grids
Memcached Oracle Coherence
NCache GemFire / SqlFire (EMC)
MSFT AppFabric GigaSpaces XAP
Ehcache (java oriented) GridGain
ElastiCache (Amazon Memcached) Hazelcast
… Inifinispan
… …

5
1. A big based hash table:
• A key/value store, living entirely in RAM on multiple servers
• Accessed from any server as if the item is in the local RAM
2. Keys and values are arbitrary binary (serializable) entities:
query record-sets, file-blobs, application variables
3. Basic operations are put(K,V), get(K,V), replace(K,V), remove(K)
4. Non-transactional, not a database, no interface with real database
5. Cache is Stale – requires an effort to mimic database to cover changes
6. Development oriented (no automation), medium to long dev project
DIY Distributed Caching

6
DIY Distributed Caching
(Memcached example)
# perl examplemy $memclient = Cache::Memcached->new({ servers => [ '10.0.0.10:11211', '10.0.0.11:11211' ]});
3. Wrapping an SQL Query
2. Init a Memcached Client with a list of your pre-configured Memcached servers:
1. Install Memcached Service on servers (or even PCs)
# Define a query and use it as a key for the Memcached:sql = "SELECT * FROM user WHERE user_id = ?"key = 'SQL:' . user_id . ':' . md5sum(sql)# We check if the value is 'defined' (or in cache), since '0' or 'FALSE' can be legitimate values!if (defined result = memcli:get(key)) {
return result} else {
# Query not in Cache, Get resultset from database server and convert to arrayhandler = run_sql(sql, user_id)rows_array = handler:turn_into_an_array
# Cache it for five minutes memcli:set(key, rows_array, 5 * 60)return rows_array
}
4. Delete from cachesql = "SELECT * FROM user WHERE user_id = ?“key = 'SQL:' . user_id . ':' . md5sum(sql) memcli:delete(key)

7
DIY Data Grids: Distributed In-Memory
Computing and Data Management
* GridGain chart example
In-Memory Data Grids (IMDG): Manage data in distributed memory and
perform complex in-memory computing tasks.

8
1. Reliable In-Memory data storage, live data, and jobs executions with
balancing among grid nodes. Implements:
Implements KV cache interface + Has indexed search by values
Reliable distributed locks interface
Events Processing => data change notifications and management
Advanced use-cases: Messaging, Map-Reduce calculations, Cluster-wide
singleton, more …
2. Very high read-write performance
3. Development oriented (no automation), a long dev project
DIY Data Grids:
Caching Concepts

9
Automated Dynamic Caching
1. Application agnostic – Supports Custom and 3rd-party applications
2. Caching of any read-based queries and stored procedures
3. Never stale cache. Writes trigger:
Real-time eviction/invalidation of the right cache items
Real-time database synchronization
4. Efficient cache management
Keeps “hot-data” in memory

10
Automated Dynamic Caching
Results of queries return in microseconds (Avg: 100µsec = 0.000100sec).
Ensures data delivery and high availability for SQL Server applications.
Safeguards against unpredictable traffic spikes and usage surges.

11
1. Caching concept: Combination of cache and in-memory database –
Smart caching of Hot-data Results with real-time eviction on DMLs
2. Minimal configuration and management. Self-learning and self-adaptive:
• DB Schema – objects definition and dependencies map between objects
• Recognizes SQL patterns and their tables/views dependencies, that are
automatically activated for caching and real-time cache eviction
• Self-adaptive to schema and application changes
3. 100% ACID, 100% data integrity, 100% up-to-date database
4. Fast: µs access to in-memory hot data: x10-x1000 faster
5. Safe: embedded failover proxy & optional cluster deployment
SafePeak Software for SQL Server apps:
Automated Dynamic Caching

Results: Large Mobile Telecom CustomerE-Commerce Application
12
Aberdeen Group
Research: E-commerce response time acceleration effect: From 6 to 5 sec.:
Sales Conversions
Customer Satisfaction
Page Views
12.5%7.5% 19%
9X Faster DB

Case Study: Tier 1 SW VendorSharePoint Application
SQL Server CPU Time (% )
13
• 1/10 CPU Load• 1/10 I/O Load• No more overload
CPU Overload
• Cache hit = 75%• Acceleration: 70% - 350%
Application Time (Sec)

14
Real Time Performance Analysis & Control
Intuitive browser-base Interface
Manage Cache on Database, Table and
Query Level
Automated SQL Patterns Detection
and Analysis
Real-time & statistical Business Info on
production queries
Production Deployment in
just HOURS
DB speed=98msCache speed=0.15msNew Average=3.8ms

15
Better, Faster, Cost-Effective
SAFEPEAK:
Dynamic
Caching
Yes
Hours
Yes
None
Low
App coding
Caching and
DB Tuning
No
Months
No
•Dev + DBA Time
•3rd party apps
limitations
High
Hardware
Scale-Up
No
Weeks
Yes
•Hardware
•SW Licenses
•IT+DBA Time
High
Virtualization
Optimized
Deployment
Time
Application
Agnostic
Hidden High
Cost Factors
Cost
“SafePeak’s unique plug and play, automated solution, provides customers
an immediate improvement of application performance and response time. A key
differentiator vis-à-vis existing solutions.” Massimo Pezzini, VP & Fellow - Gartner

SafePeak Product Demo
16
