data base management system (dbms-io) data base
TRANSCRIPT

DATA BASE MANAGEMENT SYSTEM (DBMS-IO)DATA BASE ADMINISTRATOR'S PROCEDURES MANUAL

iJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJ

DEC-IO-AAPMA-A-D
DECSYSTEM-IO
DATA BASE MANAGEMENT SYSTEM(DBMS-IO)
Data Base Administrator's Procedures Manual
This document reflects the software as of version I of DBMS-IO.
For additional copies, order No. DEC-IO-AAPMA-A-Dfrom Software Distribution Center, Digital EquipmentCorporation, Maynard, Mass.
digital equipment corporation · maynard. massachusetts

First Printing, September, 1973
I
The information in this document is subject to change without noticeand should not be construed as a commitment by Digital EquipmentCorporation. Digital Equipment Corporation assumes no responsibilityfor any errors that may appear in this manual.
The software described in this document is furnished to the purchaserunder a license for use on a single computer system and can be copied(with inclusion of DIGITAL's copyright notice) only for use in suchsystem, except as may otherwise be provided in writing by DIGITAL.
Digital Equipment Corporation assumes no responsibility for the useor reliability of its software on equipment that is not supplied byDIGITAL.
Copyright ~ 1973 by Digital Equipment Corporation
The following are trademarks of Digital Equipment Corporation,Maynard, Massachusetts:
COP DIGITAL INDAC PS/8COMPUTER LAB DNC KAlD QUICKPOINTCOMTEX EDGRIN LAB-8 RAD-8COMSYST EDUSYSTEM LAB-8/e RSTSDDT FLIP CHIP LAB-K RSXDEC FOCAL OMNIBUS RTMDECCOMM GLC-8 OS/8 SABRDECTAPE IDAC PDP TYPESET 8DIBOL IDACS PHA UNIBUS

CONTENTS
Page
CHAPTER 11.11.21.2.11.2.21.2.31.2.41.31.3.11.3.21.3.31.41.4.1
'1.4.21.4.31.4.41.51.5.11.5.21.5.31.61.6.11.6.1.11.6.1.21.6.1.31.6.21.6.31.6.3.1
1.6.3.2
1.6.3.3
1.71.7.11.7.21.7.31.7.41.7.5
MAJOR CONCEPTSINTRODUCTIONDBMS-I0 LANGUAGESThe Device Media Control Language (DMCL)The Data Description Languages (DDLs)The Data Manipulatio~ Language (DML)Language RelationshipsOPERATIONAL ARCHITECTUREThe Data Base Control System (DBCS)The User Working Area (UWA)The Run-UnitTHE SCHEMA AND THE SUB-SCHEMAConceptsVariationsPlacement ControlDevice IndependencePROTECTION OF DATAPrivacy and IntegrityPrivacy of DataIntegrity of DataRECORDSLocation ModeDIRECT Location ModeCALCULATION Location ModeVIA Location ModeAccessing of RecordsRecord-Selection ExpressionsRecord-Selection-Expressions
Based on IdentifiersRecord-Selection-Expressions
Based on Currencypositional Record-Selection-
ExpressionsSETSCharacteristics of SetsOrdering of SetsTypes of Membership In SetsSet ModeMaintenance Of Set Relationships
1-11-21-21-31-51-51-51-51-61-71-71-71-81-91-91-101-101-101-111-121-121-121-121-121-131-14
1-14
1-15
1-151-161-161-171-191-201-22
CHAPTER 22.1
2.1.12.1.22.1.32.22.2.12.2.1.12.2.1.22.2.1.32.32.3.12.3.22.3.3
RESPONSIBILITY OF THE DATA BASE ADMINISTRATORDEFINITION AND ORGANIZATION OF THE
DATA BASE 2-1Understanding User Requirements 2-1Establishing Data Availability 2-1Organizing the Data Base 2-2PROTECTION OF THE DATA BASE 2-4General Considerations 2-4Data Base Access and Manipulation 2-4Data Base Integrity 2-5Save/Recovery/Restart 2-5DOCUMENTATION OF THE DATA BASE 2-6Data Base Directory (DBD) 2-7Standards 2-7Procedures For Data Base Usage 2-7
iii

2.3.4
2.3.5
2.3.62.3.72.3.82.3.9
CHAPTER 33.13.23.33.3.13.3.2
CHAPTER 4
4.14.24.34.44.4.14.4.24.5
CHAPTER 5
5.15.25.35.45.5
CHAPTER 66.16.1.16.1.26.1.36.1.46.26.2.16.2.1.16.2.1.26.2.1.36.2.1.46.2.1.56.2.1.66.2.1.76.2.1.86.2.26.2.36.2.3.16.2.3.26.2.3.36.2.46.3
Privacy Locks, Keys, and UserIdentification
DBMS Performance and UsageMeasurements
Save ProceduresRecovery And Restart ProceduresData Base Testing FacilitiesTraining Techniques And Guidelines
THE DEVICE MEDIA CONTROL LANGUAGE (DMCL)INTRODUCTIQNTHE CONCEPT OF PAGEDMCL ENTRIESDMCL Record EntryDMCL Area Entry
THE SCHEMA DATA DESCRIPTIONLANGUAGE (DDL)
INTRODUCTIONSCHEMA ENTRYAREA ENTRYRECORD ENTRYRecord Sub-EntryData Sub-EntrySET ENTRY
THE COBOL SUB-SCHEMA DESCRIPTIONLANGUAGE (DDL)
INTRODUCTIONSUB-SCHEMA IDENTIFICATIONAREA SECTIONRECORD SECTIONSET SECTION
DATA ORGANIZATION AND ACCESSDATA ORGANIZATIONIdentification Of A DBS FileIdentification Of A PageFormat And Identification Of A LineForming A Database KeyDATA ACCESSThe In-Core RepresentationSub-Schema BlockRecord BlockArea BlockWithin BlockControl BlockOwner BlockMember BlockData BlockI/O Buffering SchemeSTORE AlgorithmsDIRECTCALCVIAFIND AlgorithmOVERHEAD
iv
2-7
2-82-92-92-92-9
3-13-23-33-33-3
4-14-14-24-34-34-54-6
5-15-15-25-25-3
6-16-26-26-56-66-66-86-86-96-106-126-126-126-146-156-166-186-186-186-196-196-19

6.3.1 Record Overhead 6-206.3.2 Page Overhead 6-216.3.3 File Overhead 6-21
CHAPTER 7 THE SCHEMA DIRECTORY FILE7.1 INTRODUCTION 7-17.2 WORD BLOCKS IN SCH FILE 7-37.2.1 Schema Block 7-37.2.2 Sub-schema Block 7-47.2.3 Record Block 7-47.2.4 Area Block 7-57.2.5 Within Block 7-67.2.6 Owner Block 7-77.2.7 Member Block 7-77.2.8 Control Block 7-87.2.9 Data Block 7-87.2.10 Text Block 7-97.3 COBOL DML PREPROCESSOR 7-10
CHAPTER 8 RECOVERY FILES8.1 RECOVERY FILE OPERATION 8-18.2 PREFIX SECTOR 8-2
APPENDIX A ERROR MESSAGES
APPENDIX B ERROR STATUS CONDITION CODES
APPENDIX C DBMS-lO PROCESSES
APPENDIX D RESERVED WORDS
APPENDIX E A SCHEMA/SUB-SCHEMA EXAMPLE
v


FOREWORD
This manual describes DBMS-lO from the point of view of the
Data Base Administrator, and as such, it is the reference manual
for the system. It is not, though, intended to be a tutorial
guide for beginning Data Base Administrators or DBMS-IO users.
In addition, it is assumed that the reader has a knowledge of
the COBOL language.
The Data Base Administrator is assumed to be familiar with
the DECsystem-lO operating system and the editing and debugging
languages available to him. Such familiarity must be acquired
prior to attempting the undertaking of the role of Data Base
Administrator.
Chapter 1 is dedicated to the major concepts of DBMS-lO, Chapter
2 to the role of the Data Base Administrator, and Chapters 3 through
5 to the various languages known to the system. Chapter 6 details the
data organization and access employed, Chapter 7 deals with the
Schema Directory File, and Chapter 8 discusses recovery files and
techniques. A number of appendices are provided which contain infor
mation essential to the system.
vii


CHAPTER 1
MAJOR CONCEPTS
Since this manual is intended to be the primary reference
document for Data Base Administrators working under the DECsystem-lO
Data Base Management System (DBMS-IO), it is essential that it
contain not only the specifications for the languages peculiar to
DBMS-IO, but that it detail the terms and concepts embodied in these
languages in such a way as to assist the Data Base Administrator in
fully understanding the specifications themselves.
1.1 INTRODUCTION
A data base is a grouping or collection of interrelated data
which has been structured and linked to permit the referencing and
accessing of the data contained therein without regard to the physical
means of storage. In other words, the program, and not the sequence
in which data is stored, determines which data is to be accessed,
when, and by whom.
As these data bases increase both in use and sophistication,
their creation and management must be relinquished by individual
application programmers in favor of greater coordination and central
ized control. It has become too costly and/or impractical, in most
instances, for individual' programmers to create data bases for single
applications on a one-to-one basis. The need at present is for data
bases which are suitable for processing by, and available to, mUltiple
applications.
The objective in developing DBMS-IO was to make this possible
by providing features which:
(1) Allow data to be structured in the manner mostsuitable to each application, regardless ofthe fact that some or all of that data may beused by other applications; such flexibilitybeing achieved without requiring dat~ redundancy.
(2) Allow more than one run-unit to concurrentlyretrieve the data in the data base even whileone run-unit is updating it.
1-1

(3) Provide and permit the use of a variety of searchstrategies against an entire data base or portionsof a data base.
(4) Provide protection of the data base againstunauthorized access of data and from destructiveinteraction of programs.
(5) Provide for centralized capability to controlthe physical placement of data.
(6) Provide device independence for programs.
(7) Allow the declaration of a variety of datastructures ranging "from those in which noconnection exists between data items tonetwork structures.
(8) Allow the user to interact with the data whilebeing relieved of the mechanics of maintainingthe structural associations which have beendeclared.
It is important to note that the Data Manipulation Language is
not a universal language. Rather, it is an enhancement of COBOL and
it can thus be categorized as a host language system. As such, its
level of procedurality is about equal to that of COBOL and thus it is
appropriate for use in programming that large class of problems for
which COBOL is the most used and most suitable language.
1.2 DBMS-IO LANGUAGES
DBMS-IO provides three languages which function to allocate
media space, to describe a data base or subset of a data base, and to
transfer data between a data base and program. There are the Device
Media Control Language (DMCL), the Data Description Languages (DDLs),
and the Data Manipulation Language (DML), respectively.
1.2.1 The Device Media Control Language (DMCL)
The DMCL is the language used by the Data Base Administrator to
allocate storage space on mass storage devices for the physical
placement of a data base. This is accomplished by equating a data
base area name to a monitor filename, and specifying how large a file
must be created to contain the area. Actually, the DMCL is not a
self~contained language; it is an extension to the Schema DDL, and it
must pass through the DDL processor at the same time that the Schema
DDL is processed.
1-2

1.2.2 The Data Description Languages (DDLs)
The DDLs are the languages used for describing a data base
(schema definition), or that portion of a data base known to a
program (sub-schema definition). These descriptions provide the
definitions for the data-items, data-aggregates, records, sets, and
areas included in the data base, as well as the relationships that
exist and must be maintained between occurrences of these elements
in the data base.
A data-item is the smallest unit of named data in a data base.
An-oc~urrence of a data-item is represented by a value. Data-items
may be alphanumeric or numeric (either fixed or floating point) •
A data-aggregate is a named collection of data items within a
record. It may be a one dimensional ordered collection of data-items
with identical characteristics (a vector), or it may be a repeating
group--i.e., a collection of data-items, vectors, and/or other re
peating groups which occur an arbitrary number of times.
A record is a named collection of data-items and/or data
aggregates which is viewed as being contiguous. When a record is
described in a schema, this description also defines the record as a
record type--i.e., the name of the record and the record type are
synonYmous. An arbitrary number of occurrences of a record can be
present in a data base for any record description in the schema for
that data base. This distinction between the actual occurrences of
a record and the type of the record is an important one.
A set is a named collection of record types which describes the
logical relationships existing between these record types. Every
set type must have one record type declared as its owner record and
can have zero, one, or many record types declared as member records.
Each occurrence of a set must contain one occurrence of its owner
record type, but it may contain an arbitrary number of occurrences
of each of its member record types. Set occurrence ordering is
independent of the physical placement of particular records~
An area is a named sub-division of the addressable storage space
in a data base and may contain occurrences of both records and sets.
Areas may be opened by a run-unit with usage modes which permit, or
1-3

forbid, concurrent run-units to open the same area. An area may be
declared in a schema to be a temporary area--i.e., each run-unit
opening it is given a unique occurrence of the area which is made
available for reuse at the termination of the run-unit.
The concept of area permits the Data Base Administrator to
subdivide a data base rather than viewing the data base as a single
entity. Efficient storage and retrieval can be accomplished through
the use of areas. This concept, when used properly, fosters optim~za
tion of data base access since the run-unit becomes interested in
only a select region of the data base. Areas also provide a conven
ient unit for recovery, since duplication or backup can be performed
selectively--e.g., areas with minimal updating then would have to be
FAILSAFEd less often than those undergoing constant updating. Like
wise, some information might be maintained for retrieval only--e.g.,
income tax tables. Thus areas also provide a convenient means for
separating data according to usage.
A data base consists of all the record occurrences, set occur
rences, and areas which are controlled by a specific schema. In the
case of multiple data bases, there must be a separate schema for
each data base. Furthermore, the contents of different data bases
are disjoint, and the intersection of two or more data bases is not
permitted. Different data bases and nondata-base files may exist,
though, on the same physical and logical storage structures known
to the DECsystem-lO monitor.
A schema consists of Schema DDL entries (see Chapter 4) which
describe all of the areas, set types, record types, data-items, and
data-aggregates as they exist in the data base. A schema is not
data itself, but a description of data. It is established and
maintained by the Data Administrator as a main storage file which
imposes discipline over the entire data base. It can be extended
as the data base grows and refines.
A sub-schema selects those areas, set types, record types,
data-items, and data-aggregates known to a given program(s) and
describes them in the form in which they are known to those specific
programs using a Sub-Schema DDL. Since the only host language
currently associated with DBMS-IO is COBOL, only the COBOL Sub-Schema
DDL has been developed and is discussed in Chapter 5.
1-4

1.2.3 The Data Manipulation Language (DML)
The DML is the language used by programmers to access data in
the data base. It is not a complete language by itself, but is a
host-language extension. In other words, the DML relies on the host
language (in the current situation, COBOL) to offer the framework
from which the DML can provide the interface \vith the data" base. In
an application program, the DML commands and the host language
statements coexist freely, and the distinction between them is merely
conceptual. From the programmer's point of view, then, he is using
one, unified language that has the capabilities of both the host
language and the DML. The host language, then, is the language used
to manipulate data in primary storage, and the DML is the interface
language with the data base. Chapter 3 of the DBMS-IO Programmer's
Procedures Manual contains the specifications for the COBOL DML.
1.2.4 Language Relationships
As already stated (Section 1.2.1), the DMCL is an extension of
the Schema DDL. Whereas the latter describes the physical and logical
layout of the data base, the former specifies physical storage space
necessary to accommodate the data base. The relationship between DDL
and DML is the relationship between declarations and procedure. The
declarations impose a discipline over the executable code and are to
a large extent substitutes for procedures written in the DML and the
host language; that is, they are implicit procedures which may be
invoked by the execution of DML commands.
1.3 OPERATIONAL ARCHITECTURE
The DBMS-IO operational environment includes the Data Base
Control System (DBCS), the User Working Area (UWA), and the run-unit.
1.3.1 The Data Base Control System (DBCS)
The DBCS is the object-time module of DBMS-lO, controlling the
placement and access of data in the data base. It provides the
interface between the application program and the data base by asso
ciating monitor relative address blocks within the data base media
files with page locations in the data base.
1-5

It must be possible for the DBCS to distinguish each occurrence
of a record from every other occurrence of a record in the data base.
For this to be possible a unique identifier must be assigned by the
DBCS to each and every record occurrence in the data base. This
unique identifier is known as a database key.
A database key is assigned by the DBCS to a record occurrence
when it is stored for the first time in the data base. It is assigned
in accordance with:
(1) The declarations for that record in the schema;
(2) Arguments, if any are required, supplied by the run-unitadding the record to the data base.
A database key once assigned to a record occurrence remains as
the permanent identifier of that record occurrence until it is deleted
from the data base.
The permanence of database keys is an important element in the
integrity of t~e data base. Database keys are made available to and
may be saved by run-units and:
(1) Used for direct accessing;
(2) Referenced later in the execution of the same run-unit;
(3) Be re-inputted to a subsequent run-unit in which they arereferenced.
Database keys are mapped by the DBCS to physical addresses. It
is important to note, however, that positional record selection
expressions which specify an area-name are interpreted in terms of
database keys, (that is, NEXT within area-name means tne record
occurrence with the next higher database key in the named area).
1.3.2 The User Working Area (UWA)
Conceptually, the UWA is a loading and unloading zone where all
data provided by the DBCS in response to a call for data is delivered
and where all data to be picked up by the DBCS must be placed. Each
program has its own UWA. The data in the UWA of a program is not
disturbed except in response to the execution of a DML command or by
the user program's host language procedures. There is no implication
that UWA locations are contiguous.
1-6

The UWA is set up by the DBCS in accordance with the invoked
sub-schema. Each data-item included in the sub-schema will be
assigned a location in the UWA and may be referenced by its name
as declared in the sub-schema. Data-items included in the data base,
but not in the sub-schema invoked, cannot be referenced.
The DBCS must also provide for a number of System Communication
Locations (SCL). These locations are used for run-unit/system
interaction and are assigned space by the DBCS. The most important
of these locations are the currency status indicators which are
def~ned in Section 1.6. Seven other locations are also provided:
AREA-NAME, RECORD-NAME, ERROR-STATUS, ERROR-SET, ERROR-RECORD, ERROR
AREA, and ERROR-COUNT.
1.3.3 The Run-Unit
In this manual, the words 'run-unit' and 'program' are often
used interchangeably as if there were a one-to-one correspondence
between run-units and programs. However, strictly speaking, a program
is a set or group of instructions while a run-unit is an execution of
one or more programs where the precise correspondence between programs
and run-units depends on the operating system. The important fact to
note is that regardless of which of these two terms is used in the
manual there is exactly one UWA, one set System of Communication
Locations, and one set of Currency Status Indicators per run-unit.
This means that, from the point of view of DBMS-10, each run-unit is
a separate entity which it is servicing.
1.4 THE SCHEMA AND THE SUB-SCHEMA
1.4.1 Concepts
The concept of separate schema and sub-schema allows the
separation of the description of the entire data base from the des
cription of portions of the data base known to individual programs.
The concept is significant from several points of view:
(1) An individual programmer need not be concerned withthe universe of the entire data base but only withthose portions of the data base which are relevantto the program he is writing. Since the data basemay contain data which is relevant to, and sharedby, multiple applications, this may be important toease the writing, debugging, and maintaining of programs.
1-7

(2) A program is limited to the subset of the schema thatis known to it via its sub-schema. To a large extent,this automatically ensures the privacy and integrityof the rest of the data base from that program.
1.4.2 variations
A sub-schema may differ from a schema of which it is a subset
in several important respects:
(1) At the data-item level:
De script-i-6n-s-6f-sp-e-c-i-r1C-d-atCl-rt~m~rm,r~/be-om±ttetl.
The ordering of data-items may be changed.
(2) At the data-aggregate level:
Descriptions of specific data-aggregates may be omitted.
The ordering of data-aggregates may be changed.
(3) At the record level:
-- Descriptions of specific record types may be omitted.
(4) At the set level:
-- Descriptions of specific set types may be omitted.
(5) At the area level:
Descriptions of specific areas may be omitted.
A sub-schema must, however, be a consistent and logical subset
of the schema from which it is drawn. Specific rules are included
in Chapter 5.
The following additional points are also important to an under
standing of the concept of the schema and sub-schema.
(1) An object version of the source code schema may be"compiled" independently of any user program or anysub-schema.
1-8

(2) Object versions of a source code sub-schema may be"compiled" independently of any user program andstored in a library.
(3) An arbitrary number of sub-schemas may be declaredon the basis of any given schema.
(4) The declaration of a sub-schema has no effect onthe declaration of any other sub-schema andsub-schemas may overlap one another.
(5) Each sub-schema must be named.
(6) A user program invokes a sub-schema.
(7) The same sub-schema may be invoked by an arbitrarynumber of programs.
(8) Only the areas, records, data-items, and setsincluded in the sub-schema invoked by a programmay be referenced by that program.
1.4.3 Placement Control
The Schema DDL provides for control over the relative placement
of records. The objective of providing for control of relative
placement of records is to increase efficiency by advising DBMS-IO of
anticipated use patterns of records. Thus, the Schema DDL permits
specification of the area or areas to which occurrences of a partic
ular record-type are to be assigned by DBMS-IO. Where more than one
such area is specified, final selection takes place in a run-unit.
The Schema DDL also includes a clause which causes record occurrences
being added to the data base to be stored near some procedure, thereby
reducing overall access times.
The fact that the Schema DDL permits control over relative
placement of records does not necessarily have any physical connota
tions. What is required of DBMS-IO in response to this type of
declaration is for it to attempt to allocate storage space in a
manner which tends to optimize access times. The ability to achieve
some optimization of access times is important when considered in the
environment of the delays in accessing data occasioned by arm
movement and rotational delay in many of the currently available
direct access storage devices.
1.4.4 Device Independence
All interfaces of the DML with data in the data base are at the
symbolic or logical level. Application programs written using the
DML are thus device independent. In addition, programs receive and
1-9

place all data in their,User Working Area and the DBCS is responsible
for all aspects of physical input/output including buffering. No
Schema DDL entry includes references to the physical devices or media
space. Thus, a schema written using the Schema DDL is a logical
description of the data base and is not affected by the devices and
media used to store the data. The data base may, therefore, be stored
on any combination of secondary storage devices which are supported
by DBMS-ID.
1.5 PROTECTION OF DATA
1.5.1 Privacy and Integrity
The Schema and Sub-Schema DDLs and the DML include the provision
for the protection of data in the environment of a shared data
base--i.e., one which contains data relevant to, and shared by,
multiple programs or applications. In this type of environment, two
kinds of protection are required:
(1) Protection against unauthorized access of data, forwhich the term privacy is used in DBMS-ID.
(2) Safeguarding the data from destructive interactionof programs, for which the term integrity is used.
To some extent the mechanisms for providing privacy and ensuring
the integrity of data overlap, but for the most part they are quite
separate. This protection, needless to say, cannot guard against
unsocial behavior on the part of individual programs. If, for example,
a program is authorized to access and delete a particular record and
does so without regard for the fact that this same record is the owner
of a set which has members required by other programs, DBMS-ID can
o£fer no protection. Such action is in reality a logical error and
can only be avoided by the Data Base Administrator creating an
awareness among progr~mmers of their actions on others.
1.5.2 Privacy of Data
The data in the data base is protected through a mechanism of
privacy locks which are specified in the schema and sub-schema, and
privacy keys which must be provided by a run-unit seeking to access
or alter data which is protected by means of privacy locks declared
at the schema level, the sub-schema level, and the area level. A
l-lD

privacy lock is a single value, up to thirty characters in length,
and may be a constant or the value of a variable. A privacy key
is a value (again, either constant or variable) which is simply
matched against a privacy lock value.
In case of a violation, DBMS-IO aborts the run-unit and records
the violation. When repeated violations occur, the Data Base Admin
istrator should take positive action to remedy the situation (see
Section 2.2). While protection of privacy is the foremost use of
privacy locks and keys, it is by far not the only one. Thismechanism
can also be used, for example, to help ensure the consistency of
interrelated data) and to prevent errors by locking out clearly incon
sistent, meaningless, or incorrect actions.
1.5.3 Integrity of Data
When run-units are permitted to interact with the same data
concurrently, they require protection against each other. No pro
vision has been included in the DML for a run-unit to selectively
lock record occurrences and make them unavailable to concurrent
run-units. Had such a feature been included, then a deterioration
of the performance of DBMS-IO would have resulted.
Provision has been included, though, for giving a run-unit
exclusive or protected update rights over one or more areas. No
concurrent run-unit can gain access to the areas over which a run-unit
has acquired exclusive update rights. Protected update is a less
restrictive form of exclusive update which prevents condurrent update
but allows concurrent retrieval. These various rights are obtained
by executing the OPEN imperative in a program which specifies the
desired right, and they are relinquished simply by closing the area.
The exclusive update option means that changes to an area are
being done in place and therefore no other run-unit can be permitted
to access that area. If the run-unit aborts before closing the
area, the area cannot be accessed again. To guard against this, the
Data Base Administrator should keep at least one additional copy of
every area as backup. The protected update option means that changes
are being made in a separate area that is logically (but not physically)
equivalent to the area being updated. These changes will only be
1-11

physically made when the run-unit performing the update relinquishes
control by closing the area. If the run-unit aborts before closing
the area, all of its changes are discarded.
1.6 RECORDS
A record--i.e., an occurrence of a record type--is viewed as a
contiguous collection of data stored in the data base. The descrip
tion of record type in the schema includes a location mode which
determines the placement of the occurrences of that record type in
the data base and the form of reference to be used in order to access
these occurrences.
1.6.1 Location Mode
The Schema DDL provides for the following access methods to be
specified in the location mode clause for each record entry appearing
in the schema.
1.6.1.1 DIRECT Location Mode - Retrieval of an occurrence of the
record type is based on the unique identifiers (database keys)
assigned by the DBCS to each record occurrence in the data base. In
this method to be used, the database keys of the record to be selected
must be made available by the run-unit to the DBCS and thus must have
been saved previously by the run-unit. This is possible because the
database keys of the current record of the run-unit are always made
available to the run-unit by the DBCS and are stable for the life
of the record.
1.6.1.2 CALCULATION Location Mode - Retrieval is based on the values
supplied by the run-unit for the data-names which are contained in the
sought record and which have been declared as CALC keys. The DBCS
transforms the values so provided into a unique identifier and
retrieves the record on the basis of that identifier. The algorithm
used in this transformation is discussed in Chapter 6.
1.6.1.3 VIA Location Mode - Retrieval depends on the relationships
which have been established for the sought record by the DBCS on the
basis of the set declarations in the schema. Functionally, two
separate steps are involved:
1-12

(1) Selection by the DBCS of the appropriate occurrenceof the named set;
(2) Selection of the sought record from among themember record occurrences of the selected setoccurrence.
The process of set occurrence selection is controlled by decla
rations for the sought record in its capacity as a member record of
the named set. These declarations specify:
(1) The strategy to be used for selection.
(2) The data names which the run-unit must initializewith the values that will be used by DBMS-IO forset occurrence selection. Where, however, thestrategy is simply that set selection will behandled by user programs, no data names can bespecified.
Set occurrences are selected by means of selecting their owner
record occurrences, and a strategy specified to the DBCS must include
sufficient information for a unique owner record occurrence, and thus
set occurrence, to be selected. When the owner record occurrence is
not unique on the basis of the selection criteria specified for it
and a hierarchy of sets exists, the strategy must include selection
criteria for the owner record itself in its capacity as a member of
another set, and so on up the hierarchy until sufficient uniqueness
is established. From the viewpoint of the DBCS uniqueness is achieved:
(1) When an owner record is to be selected by the user programor when it is to be selected independently of its setassociations; that is, using the DIRECT or CALCULATIONaccess method.
(2) When occurrence selection involves a cycle and thereis a starting point for the cycle, in the sense thatthe owner of at least one set in the cycle is selectedindependently of the other sets in the cycle. It maybe selected as above or through its membership in aset not involved in the cycle. Occurrences of successive sets in the cycle can then be selected based onselection criteria for those sets. Selection terminatesbefore a second occurrence of the starting point set isselected. That is, the selection process proceeds inthe sequence of the cycle and does not traverse thecycle more than once.
1.6.2 Accessing of Records
While the Schema DDL provides the means to specify the access
methods required at the record level and at the set level, the DML
1-13

provides commands which allow. interaction with such specifications
and with any relationships which have been declared. The following
items are important to an understanding of the approach taken in the
accessing of records.
(1) The DML provides for the selection of individual records.
(2) Depending on the entry in the schema for a record, arecord occurrence may be accessed on the basis of anyof the data-item values in the record, or on the basisof a concatenation of such data-items values.
(3) The: DML is not an inquiry language.
(4) A record may always be accessed through any of thesets in which it participates as a member.
(5) A record may always be accessed by a complete scanof an area.
(6) The DML distinguished between the selection of arecord and its delivery to a run-unit.
(7) A record is selected by means of a FIND commandand its associated record-selection-expression.The record most recently selected,is known as thecurrent record of the run-unit.
(8) Values of data-items from a record are madeavailable to a run-unit in its UWA. The dataitems that appear in a run-unit's UWA dependon the invoked sub-schema.
(9) All of the available methods of accessing recordsmay be used in a given program.
(10) All of the available methods of accessing recordsmay be applied to the same data base or area.
1.6.3 Record-Selection-Expressions
As stated earlier search arguments for selecting records from a
data base are provided by run-units in the form of record-selection
expressions. There are three main types of record-selection
expressions:
(i) Record-selection-expressions based on identifiers.
(2) Record-selection-expressions based on currency.
(3) Record-selection-expressions that are positional.
1.6.3.1 Record-Selection-Expressions Ba~ed on Identifiers - All
record occurrences in the database can be retrieved on the basis of
their DBCS-assigned unique identifiers. In addition, if the declared
location mode is CALCULATED, any record of that, type may be retrieved
by specifying its record name and the value of the data-item specified
as the CALC key~
1-14

1.6.3.2 Record-Selection-Expressions Based on Currency - For the
duration of each run-unit the DBCS maintains currency status infor
mation on the identity of the last record occurrence accessed by the
run-unit of:
(1) Each record-type known to the run-unit (that is,current of record-name). .
(2) Each set-type known to the run-unit (that is,current of set-name). Note that the currentof set-name may be any record which participatesin the set whether as an owner or as a memberrecord.
(3) Each area-name known to the run-unit (that is,current of area-name).
(4) Any record-type known to the run-unit (that is,current of run-unit).
Record-selection-expressions based on currency enable the records
whose iaentifiers are currently saved by the DBCS for a run-unit to
be retrieved by that run-unit without the specification of any other
search arguments.
Currency status indicators are, in effect, place markers kept
by the DBCS for a run-unit. At the start of a run-unit its currency
status indicators, except for the current of run-unit, may be
selectively suppressed by a run-unit.
1.6.3.3 positional Record-Selection-Expressions - positional record
selection-expressions are all relative to the current record of set
name, or the current record of area-name. Record-selection-expressions
which are relative to the current record of set-name permit, for the
occurrence of the set named which is identified by the current record
of that set-name:
(1) The member records to be retrieved in the logicalorder declared for that set, either in the NEXTdirection or in the PRIOR direction from thecurrent record of the set.
(2) The OWNER, the FIRST, the LAST, or the nth recordof the set to be retrieved.
Record-selection-expressions which are relative to the current
record of area-name permit the NEXT, the PRIOR, the FIRST, the LAST,
or the nth record in the area named to be retrieved. Sequence, as it
relates to areas, is in terms of the unique identifiers of the record
1-15

occurrences present in the area. That is, sequence is defined by
values of database keys, the collating sequence of which is
implementor-defined.
Positional record-selection-expressions based on set name are an
important tool for traveling the logical relationships established
by means of set declarations. Such declarations provide a logical
road map of the data base. Record occurrences which participate in
more than one set are junction points. positional record-selection
expressions are the steering mechanism which permit branching off in
any direction from such junction points.
1.7 SETS
In order for DBMS-IO to allow data to be structured in the
manner most suitable to each application without requiring data
redundancy, it is necessary to represent the relationships between
records by methods other than physical juxtaposition of these records.
The Schema DDL provides the facility to declare structures through
the medium of the set. The set is, in effect, a building block which
allows various data structures to be built. DBMS-IO provides three
data structure representations~-
(1) Sequential structures (Figure 1-1)
(2) Tree structures (Figure 1-2)
(3) Network structures (Figure 1-3)
The DBMS-IO user is able not only to treat the case of one-to
many relationships, but he can now handle the more complex many-to
many relationships arising out of real-life situations. In addition,
the absence of structuring may be represented by declaring records
in the schema which do not participate in sets.
It will be assumed that the Data Base Administrator has a
general working knowledge of data structuring and linking. This is
essential if he is going to create efficient and realistic data bases.
1.7.1 Characteristics of Sets
The following characteristics are relevant to developing an
understanding of the concept of a set.
1-16

(1) A set is named collection of record types.
(2) An arbitrary number of sets may be declared in a schema.
(3) Each set must be named and must have one owner recordtype and can have zero, one, or many member recordsdeclared for it in the schema.
(4) Each set must have a SET ORDER specified for it in theschema (see Section 1.7.2).
(5) Any record type may be declared in the schema as theowner record type of one or more sets.
(6) Any record type may be declared in the schema as amember record type of one or more sets.
(7) Any record may be specified as both an owner recordin one or more sets and a member record in one ormore different sets.
(8) The capability for a record to participate as bothowner and member in the same set is not supportedby DBMS-10.
(9) A record occurrence cannot appear in more than oneoccurrence of the same set.
(10) A set occurrence is a collection of one or morelogically related record occurrences.
(11) Each occurrence of a set includes one occurrenceof its owner record. In fact, the existence ofthe owner record in the data base is a conditionof the existence of the set occurrence and distinguishes that set occurrence from all otheroccurrences of that set-name.
(12) A set occurrence which contains only an occurrenceof its owner record is known as an empty set.
(13) In addition to the occurrence of its owner record,a set occurrence may have an arbitrary number ofoccurrences of each of the member records declaredfor it in the schema.
(14) A special type of set which has exactly one occurrence and for which DBMS-10 is the owner may bedeclared. For convenience, this is known as asingular set.
1.7.2 Ordering of Sets
Each set named in the schema must have a SET ORDER specified for
it. The effect of this is to cause DBMS-10 to control, in accordance
with the set order specified, the logical order of the member record
occurrences within each set occurrence. The logical order of the
member records of a set is completely independent of the physical
placement of the records themselves. Thus, the same member record
occurrences could part~cipate in occurrences of two different sets
and be ordered differently in each of those sets.
1-17
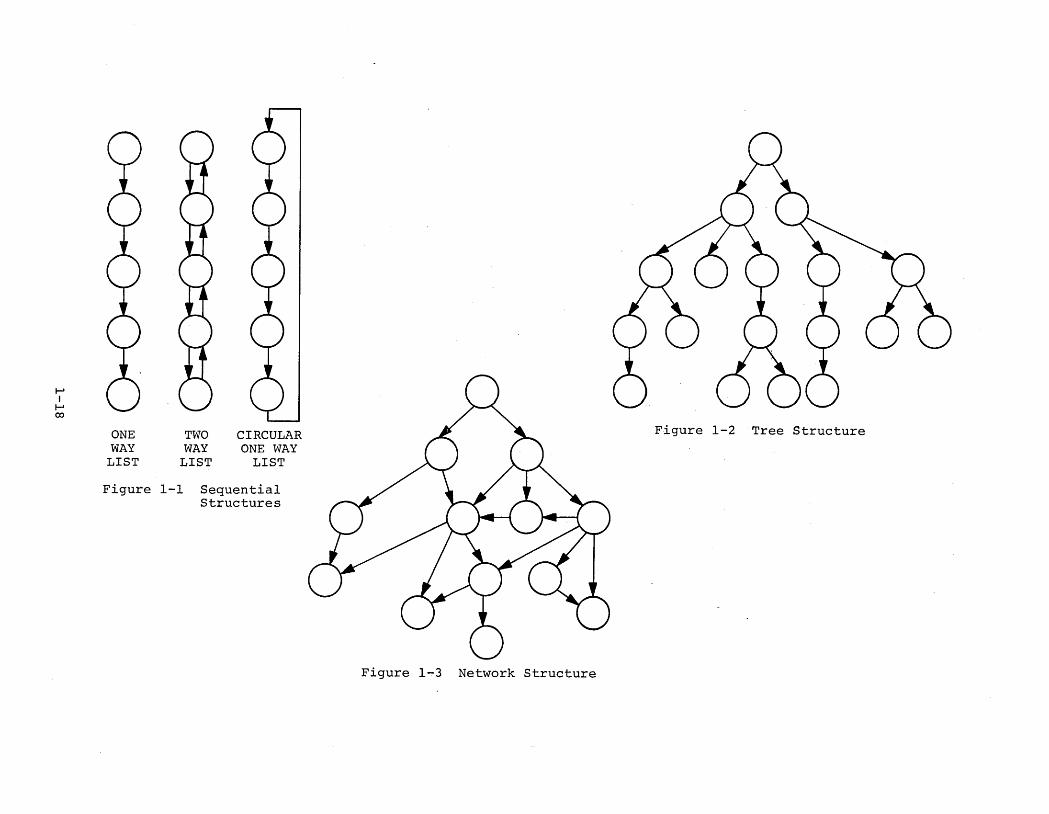
Figure 1-1 SequentialStructures
Figure 1-2 Tree StructureCIRCULARONE WAY
LIST
TWOWAY
LIST
ONEWAY
LIST
~
I~co
Figure 1~3 Network Structure

The member records of each occurrence of a given set may be
ordered in one of several ways:
(1) SORTED in ascending or descending sequence basedon the values of specified keys. The keysspecified may be data-items in each of themember records, the member records' namesor their unique identifiers, or any combinationof these.
(2) In the order resulting from inserting new memberrecord occurrences into the set:
(a) FIRST, that is, as the immediate successorto the owner record occurrence.
(b) LAST, that is, as the immediate predecessor to the owner record occurrence.
(c) NEXT, PRIOR, that is, after or beforeanother record occurrence which isselected by the user program storingor inserting the record in the set.
1.7.3 Types of Membership In Sets
The membership of a record type in a set is declared in the
schema to be AUTOMATIC or MANUAL and MANDATORY or OPTIONAL. A record
may have different types of membership in different sets.
AUTOMATIC means that membership in the set is established by the
DBMS-IO when a record occurrence is stored. That is, whenever an
occurrence of a record declared to be an automatic member of a set is
added to the data base, it will be logically inserted into (that is,
made a current member of) the appropriate occurrences of all the sets
in which it has been declared as an automatic member.
The addition to the data base of a record occurrence declared to
be a MANUAL member of a set will not cause it to be made a current
member of any occurrence of the sets in which it has been declared
as a manual member. Manual means that membership in the set is
established by a run-unit by means of an INSERT command.
MANDATORY means that, once the membership of a record occurrence
in a set is established, the membership is permanent. Its set
occurrence may be changed by a MODIFY command, but the record occur
rence cannot be removed from the set. If an owner record is deleted,
so are all its mandatory members.
1-19

OPTIONAL means that the membership of a record occurrence in a
set is not necessarily permanent. Its set occurrence may be changed
by a MODIFY command or by a REMOVE command followed by an INSERT
command. Its membership may be cancelled by a REMOVE or a DELETE
command of its owner. A record which is logically removed from any
sets in which it participates remains in the data base and is still
accessi~le, though not through any set in which it is no longer a
current member.
1.7.4 Set Mode
The current implementation of DBMS-IO provides for one set
mode - CHAIN - which is declared in the Schema DDL. For each occurrence
of a set declared to have a mode of CHAIN, a chain of pointers is
created which can be followed and which provides for serial access
to all records in the set occurrence. The -pointers are embedded in
the records themselves. An illustration of an embedded pointer
chain is shown in Figure 1-4. It represents a set occurrence with
two member records. The owner record of the set occurrence contains
a pointer to the first member record in the set which in turn contains
a pointer to the second member which points back to the owner. If
the set occurrence contained n member records the chain of pointers
would pass through the n member records.
Since Figure 1-4 is a representation of a chain with embedded
pointers it is assumed that the records shown contain data as well as
pointers. Of course, records may be members in multiple sets. To
the extent that the mode of such sets is CHAIN there would then be
multiple chains passing through these records (embedded pointers).
As a result, when any given record is accessed, a pointer for each
chain in which the record participates is available and may be
followed. A chain is thus a routing device or junction box. The
essential aspect of a chain is that there are pointers, directly
linking one record in the chain to the next record in the chain.
1-20
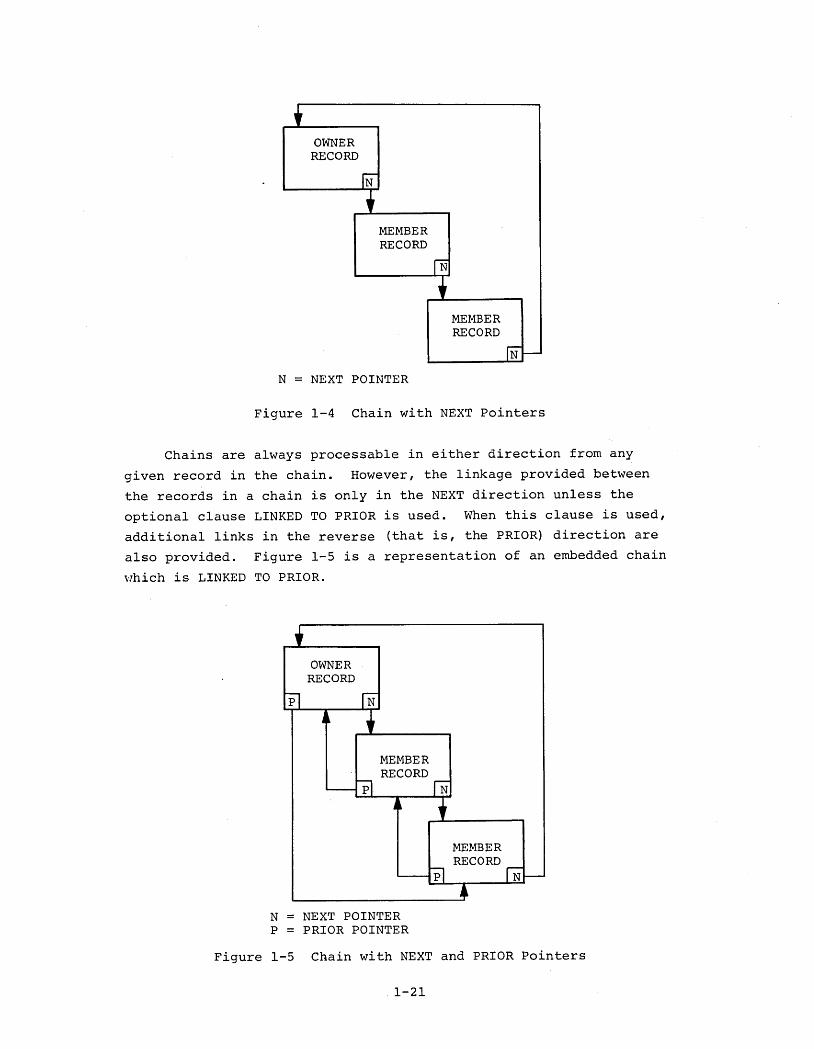
OWNERRECORD
MEMBERRECORD
MEMBERRECORD
N
N = NEXT POINTER
Figure 1-4 Chain with NEXT Pointers
Chains are always processable in either direction from any
given record in the chain. However, the linkage provided between
the records in a chain is only in the NEXT direction unless the
optional clause LINKED TO PRIOR is used. When this clause is used,
additional links in the reverse (that is, the PRIOR) direction are
also provided. Figure 1-5 is a representation of an embedded chain
which is LINKED TO PRIOR.
OWNERRECORD
MEMBERRECORD
N NEXT POINTERP PRIOR POINTER
Figure 1-5 Chain with NEXT and PRIOR Pointers
1-21

In addition, the occurrences of any of the member record types
specified fora set may be declared to be LINKED TO OWNER. This
causes the owner record of the set occurrence to be accessible
directly from each of the member record occurrences. Figure 1-6
illustrates this.
OWNERRECORD
N = NEXT POINTERP = PRIOR POINTERo = OWNER POINTER
Figure 1-6 Chain with NEXT, PRIOR and OWNER Pointers
The unique identifiers (i.e., database keys) assigned by the
DBCS for every record occurrence in the data base are used as pointers.
Space for a minimum of one pointer (the NEXT pointer) is required for
each record and must be assigned by the DBCS for each chain in which
a record participates as owner or member. Additional pointers and
space are required if the chain is declared to be LINKED TO PRIOR or
its members are declared to be LINKED TO OWNER.
1.7.5 Maintenance Of Set Relationships
The establishment and maintenance of relationships between
records specified by means of declaring sets in the schema, is a
responsibility of DBMS-ID. Such maintenance is required whenever:
1-22

(1) A record which has been declared as an owner ormember in one or more sets is added to or deletedfrom the data base.
(2) A record is explicitly inserted or removed froma set.
(3) A record is modified in a way which changes itslogical position in the set.
Programmers are not involved in the mechanics of this process
but must initialize with appropriate values those data-items which
are required by DBMS-IO to perform its functions. Such data-items
are declared in the schema. Programmers must also ensure that all
areas containing any record occurrences affected by a maintenance
operation are open for update.
1-23


CHAPTER 2
RESPONSIBILITY OF THE DATA BASE ADMINISTRATOR
Because DBMS-IO presupposes an environment where a data base
includes data that is shared by many user programs, it is necessary
for the schema and the sub-schema to be developed centrally. The
data base is, in a sense, a compromise between the needs of the
various user programs. Therefore, a means of mediating conflicting
needs is required for the data base. This mediation is the prime
responsibility of the Data Base Administrator, although it takes
on many different aspects.
2.1 DEFINITION AND ORGANIZATION OF THE DATA BASE
2.1.1 Understanding User Requirements
The timeliness, accuracy, and efficiency of the support to be
given to users must be explicitly agreed upon between the Data Base
Administrator and the users. Users must be educated in the
difference between access to specific existing data, information
dynamically derived from existing data, and the extensions of the
data base to include new data.
The Data Base Administrator must be aware of his organization's
long-range plans as well as of long-range needs of the users. For
instance, several groups of users might be formulating plans for
data bases using interrelated data. The Data Base Administrator
should be able to provide common access for these users. Under
standing short-range user plans and needs as they pertain to
specific application requirements is also necessary. A user, for
instance, might require data from an existing data base which could
possibly cause conflicts with the current users' interests.
These differences must be reconciled. The Data Base Administrator
has the responsibility to see that the data base is an effective,
efficient tool for all users.
2.1.2 Establishing Data Availability
One of the functions of the Data Base Administrator is to
assist users in their search for data to satisfy their application
requirements. He should maintain a Data Base Directory (DBD) in
which are recorded the record types and set types currently
2-1

available to users. The DBD will then be the initial source for
information relative to data availability. Should some data
elements be not available within the existing data base, the Data
Base Administrator will arrange the interface with the necessary
data sources to satisfy the demands of the user.
Additional factors to be included when considering data
availability are:
(1) present form and location of data;
(2) access techniques to be used;
(3) intended use of data in relation to its presentaccuracy, completeness, and timeliness;
(4) need for modification of data;
(5) present authorizing agent for use of data;
(6) cost of providing the data.
2.1.3 Organizing the Data Base
The establishment and definition of data interrelationships
is a vital function of the Data Base Administrator. Users will
generally imply, in their requests, their logical data needs.
Explicitly defined proposals should be given by the Data Base
Administrator, and these ought to reflect his knowledge of fore
seeable developments--including the needs of probable related
users. The physical structure of the data base must be designed
in such a way so as to effectively meet the logical data needs
of the users. Efficient physical structuring requires expertise
on the part of the Data Base Administrator in translating and
effecting logical data relationships. As part of the establish
ment and definition process, the Data Base Administrator must
weigh the advantages of a given set of linkages against its cost
in terms of additional space required and in the degradation of
data base access performance. A variety of factors must be taken
into consideration; among these are:
(1) logical data formats and relationships;
(2) physical data formats and relationships;
(3) access methods;
(4) frequencies of access;
2-2

require complex
Redundant data
where it may
(5) physical storage media requirements;
(6) search strategies.
Sophisticated application specifications thus might
data structures involving many interrelationships.
should be reduced to a minimum, and only permitted
be required for the sake of performance.
During the organization phase,' the Data Base Administrator
builds the schema and the sub-schemas necessary to describe the
data base as a whole and subsets of the data base, respectively.
Accordingly, he
(1) Employs data structures that model the business orproblem. This is provided in the Schema Data DescriptionLanguage in terms of areas, records, sets, data-items,and data-aggregates (see Chapter 4) .
(2) Assigns names in such a manner as to assure theiruniqueness.
(3) Selects search strategies based on the needs of thevarious users of the data base.
(4) Assigns areas to devices/media based on time/spacerequirements using the Device Media Control Language(see Chapter 3).
(5) Loads the data base.
Through arbitration with the various application areas, the
Data Base Administrator is responsible for the building of the
sub-schemas used for application programs. As such he
(6) Assigns names and/or synonYms to protect the uniquenessof the names already assigned to the data base.
(7) Selects and structures the proper subset of the database that must be available to the application programmer.
Detailed explanation of these seven points will be in the next
three chapters.
2-3

2.2 PROTECTION OF THE DATA BASE
2.2.1 General Considerations
The general considerations for data base protection are:
(1) data base access and manipulation;
(2) data base integrity;
(3) save/recovery/restart;
(4) violation of rules.
It is important that the Data Base Administrator review these
considerations and decide the degree to which they apply to his
particular environment. Provision for these considerations will
enable the Data Base Administrator to be better equipped to protect
the data base(s) under his control.
2.2.1.1 Data Base Access and Manipulation - The Data Base
Administrator should control the reading (access) and writing
(manipulation) of the data base. positive control must be exercised
if there is to be meaningful protection. Following are some
activities which should help establish and maintain this positive
control.
(1) The policy statements regarding the data base shouldbe published and circulated among the users. Thesestatements must reflect data base usage and helppromote a clear understanding regarding the data basewith user and operating personnel.
(2) It must be decided who has the right to know and/or theneed to know the content of the data as well as itsexistence. Authority should be determined as to whocan read data from the data base, add new occurrencesof data to the data base, update or change existingvalues of data in the data base, and delete data fromthe data base. Once the authority has been established,it is important to set up proper controls to insureauthority violations of the data base do not occur(see Chapters 4 and 5).
(3) In many data bases, certain elements of data areconfidential. Consideration should be given to thoseprotections which can be used to provide the requireddata security; such protections are software protectionand physical protection. In DBMS-lO, privacy locksand keys are used to restrict and/or control softwareaccess to the data base (see Section 1.5, Chapters4 and 5). Physical protection can take on numerousforms, including (but not limited to) use of dedicated
2-4

lease lines, physical separation of data elements, andlimiting the publication of information regardingstored data to the appropriate users of the data base.
2.2.1.2 Data Base Integrity - Data in the data base must be
accurate, complete, current, and timely. Some of the Data Base
Administrator's considerations along these lines are as follows:
(1) The Data Base Administrator should monitor the database for usage, response, and potential reorganization.
(2) When data errors are found, they should be correctedimmediately, and the responsible parties should benotified. The timeliness of error correction cannotbe overstressed.
(3) The Data Base Administrator can further protect thedata base and help insure data integrity by having acomplete audit trail of activity against the database. Such an audit trail would usually consist ofthe input transaction or message, a copy of the database record before update, and a copy of the database record after update. In the event of data baseproblems, this audit trail will be useful in determiningwhat occurred and in reconstructing data to itscorrect state.
(4) Application programs will be limited to the access andmanipulation of logical data. Only the Data BaseAdministrator has the need to know the characteristics,formats, organizations, and relationships of thephysical data contained in the data base. Limitingusers to logical data access will provide increaseddata base flexibility and a greater amount of dataindependence from application programs.
(5). The Data Base Administrator should participate inapplication program testing to help insure that theseprograms are working correctly and do not inadvertentlyor incorrectly alter the data base. This participationcould include providing test data bases, approvingprogram usage of the data base, and helping prescribetesting procedures.
2.2.1.3 Save/Recovery/Restart - The Data Base Administrator must
take proper steps to insure that the data base can be restored to
its proper state in the event of destruction or damage. He may
design and plan save/recovery/restart procedures which reflect the
particular problems and needs of his installation.
The responsibility of the Data Base Administrator does not
cease when the data base has been restored after a failure. He
must then identify the causes of the failure, and he should
assure that appropriate corrections have been made. Those
2-5

involved in the use of the data base should be notified that a
save/restore/restart procedure was necessitated and that some
data in the data base might have to be refreshed. As this is
part of data integrity, timeliness in carrying out this aspect
is most important.
2.2.1.4 Violation Of Rules - In administering the protection of
the data base, it is necessary to know whenever violations of
rules, standards, and accesses occur. Whenever a violation occurs,
the Data Base Administrator should detect the violation, identify
the violator, and report the violation. He must then follow up
to insure all problems and violations are satisfactorily resolved.
Should repeat violations or failure to correct a problem occur,
then the violator should be denied future access to the data base.
2.3 DOCUMENTATION OF THE DATA BASE
In addition to being the organizer of and administra~or of
the data in the data base, the Data Base Administrator is the
prime documentor and educator with regards to DBMS-IO at his
installation. He should provide for the recording of procedures,
standards, guidelines, and data base descriptions necessary for
the proper, efficient, and continuing utilization of the data base.
Documentation need be structured for and selectively distributed
to the data base administration, the computer operations staff,
the application programmers, and any other users. The Data Base
Administrator has the responsibility for providing and maintaining
adequate documentation of all types including, but not limited
to: description of the physical data base' (i.e., the Data Base
Directory); standards; procedures for data base usage; locks, keys,
and user identification; DBMS-IO performance and usage measurements;
save procedures; recovery and restart procedures; data base testing
facilities; training techniques and guidelines.
All of these documentation activities are important in them
selves and should not be taken lightly. A description of each
of them follows.
2-6

2.3.1 Data Base Directory (DBD)
The DBD'should contain narratives and/or diagrams illustrating
the data structures, as well as the relationships existing between
record types--including data base cross-references. Descriptions
should also be given of the attributes of physically stored record
types--i.e., location mode, area in which stored, format of
data-items, etc. (see Chapter 4). In addition, the physical
storage medium, including the~~ocation, allocator, and utilization
of storage space in terms of areas, as wellas the location of
the data base FAILSAFE tapes and their creation date.
2.3.2 Standards
Standards should be documented as they are established. Each
installation will have its own set of user and DBMS-IO standards.
Allowable deviations should also be noted, as well as any controls
over these deviations.
2.3.3 Procedures For Data Base Usage
These procedures might include, but are not limited to,
relationships between transactions and data bases, and responsi
bilities of the users and data base personnel. In order to
fully accomplish all the tasks assigned to him and his staff, the
Data Base Administrator should schedule time when the data base is
not available to users in order to perform reorganization procedures
(such as reassigning areas to different devices/media), FAILSAFE
procedures, and other "house-cleaning ll chores. This time is in
addition to the normal preventive maintainence time for the
computer system as a whole, and the users must be made aware of
these activities. Likewise, users who merely want to retrieve
information from the data base should know when this information
is being updated by other users so that fresh copies of data are
always available.
2.3.4 Privacy Locks, Keys, And User Identification
In addition to the normal logging and billing facilities of
the computer installation, DBMS-IO provides the means of locking
out a user from the data base until he supplies the proper key
in his program (see Section 1.4). Such a lock-out mechanism can
apply to subsets of the data' base (see Section 5.2) as well as
2-7

to specified access to any area (see Section 4.3). This mechanism
is only as effective, though, as the attention paid to it by the
Data Base Administrator. All privacy locks and keys are assigned
by the Data Base Administrator, and the strictest security must
surround their use. They should not, for instance, appear in the
DBD or any other document which may be viewed by more than one
user or multiple personnel.
Should the Data Base Administrator, or any user, suspect that
a privacy key has become public knowledge, the Data Base Administra
tor should immediately issue a new unique lock/key combination to
replace the one in question. Timeliness is of the utmost importance
if data privacy and integrity should be maintained.
The knowledge of a lock/key combination should only be
related to those users who absolutely need it for their particular
applications. Whenever a change is made, all affected by the
change should be individually notified in order that the respective
software may be changed.
A further step which can be taken by the Data Base Administrator
in securing positive user identification is to assign users and
data bases to specific project-programmer numbers with passwords
which are changed frequently. This will keep out non-DBMS-IO users,
and should help to eliminate people who could cause damage to the
data base. Likewise, lock/key combinations should be changed
periodically--especially in sensitive data bases. Whenever a user
ceases to participate in the data base, for whatever reason, all
locks, keys, passwords, and identifications should be changed
immediately.
2.3.5 DBMS Performance and Usage Measurements
As part of the Data BaSe Administrator's responsibility to
monitor the data base for usage, response, and potential re
organization, he should keep a record of the resources used and
frequency of use, the users serviced, the effectiveness as related
to response time and costs. In addition, he should document how
this monitoring is to be done.
2-8

2.3.6 Save Procedures
What data is to be backed-up? How much of it is to be
backed-up? Which facilities are to be used? What is the schedule
and frequency for back-up procedures? Such questions should be
answered and documented so that there is no confusion among staff,
users, and operators--especially if operators will be depended upon
to execute the save procedures.
2.3.7 Recovery And Restart Procedures
In case of crash, or other system failure, the operations
and/or Data Base Administration staff need to know what recovery
procedures are to be used to restore the data base and what
facilities were used as part of the save procedure. These
recovery procedures are extremely important in terms of data
integrity and reliability, and should be fully documented in
detail. Priorities and sequence of data base restoration should
also be laid down--this is extremely important for systems with
many data bases of varying relative importance and usage.
2.3.8 Data Base Testing Facilities
Users must know what facilities are available to them to aid
in the testing of their programs which interface with the data
base. The Data Base Administrator should, then, publish what
procedure will be used in obtaining a test data base, and what
test criteria must be met before a program will be accepted for
running with the real data base.
2.3.9 Training Techniques And Guidelines
The Data Base Administrator is the prime educator of the users
of the data base under his care. As such, he is responsible for
establishing user training methods and facilities. These would
include, but are not limited to: seminars and lectures concerning
programming using the Data Manipulation Language and interacting
with a shared data base, individual consultation with users having
specific conceptual and/or operational problems, providing manuals
and other DBMS-IO programming aids, establishing training
criteria which must be met before a programmer will be permitted
to use DBMS to interact with the data base, fostering of
optimization techniques in application programs.
2-9

I'

CHAPTER 3
THE DEVICE MEDIA CONTROL LANGUAGE (DMCL)
This chapter contains the entire description of ,the Device
Media Control Language (DMCL).
3.1 INTRODUCTION
The DMCL enables the Data Base Administrator to select individual
areas, to assign them to files, and to allocate storage space on mass
storage devices known to the monitor. Since the DMCL is not a lan
guage of its own right, but an extension to the Schema DDL, the DMCL
commands must be executed by the DDL processor prior to the processing
of the Schema DDL commands. Under DBMS-IO, the DMCL entries are
submitted to the DDL processor as part of the schema, but before the
Schema DDL entries.
There are two types of DMCL ENTRY which serve to:
(1) Specify the maximum number of records per page(Record Entry):
(2) Assign areas to files and specify the physicalsizes of these files in terms of pages (Area Entry) .
For each area described in the schema, there must be a DMCL
Area Entry. There can, though, only be one DMCL Record Entry per
schema. When constructing a schema, the DMCL Record Entry must always
precede the DMCL Area Entries.
The filenames specified in the DMCL Area Entries may be from one
to six letters or digits in length. No filename extension can be
given in the entry, although the DDL processor automatically assigns
the extension .DBS to these files. Each file so specified for
creation by the monitor must be uniquely named under the project and
programmer numbers to which the data base(s) belong. Data bases may
be created under any number of project and programmer nurnbersknown
to the monitor, and there may be duplication of filenames in different
project and programmer numbers, but it' is advised that all files to
which areas are assigned be given unique filenames.
3-1

Error messages associated with processing DMCL entries may be
found in Appendix A.
3.2 THE CONCEPT OF PAGE
For the purpose of direct access storage, data bases have been
described as being divided into areas. Each area is divided into
fixed-length, consecutive groups called pages, corresponding in size
to the page size specified in the DMCL Area Entry. Pages are further
divided into fixed-length, consecutive units called lines. Each line
contains an occurrence of a record type, its set linkages, and certain
system information for the DBCS. The length of a line is dependent
upon:
(1) The number of characters of data composing therecord type;
(2) The number of embedded pointers--i.e., setlinkages--defined for the record.
The length of a line, then, is determined by the record type
with which it is associated. A database key, then, specifies the
page and line number on which a record occurrence is to be found
(see Section 1.3.1).
Since input/output (I/O) operations between the DBCS and the
data base are handled by the monitor, data is transferred between
memory and the storage device as a block of words. Block size is
dictated by the physical device,being used. The physical device
normally used by DBMS-lO is the disk, which has a block size of 128
words. The monitor, though, knows nothing about pages and lines-
only blocks.
The DBCS, therefore, must translate database keys into relative
block numbers within the storage file for I/O access. The size of
a page of data storage corresponds to the size of an I/O buffer in
the DML preprocessor. The act of transferring a page from the disk
into a buffer in core is called a page-in, or the loading of a page.
All DML data retrieval and data manipulation operations are performed
on that portion of the data base which is in the buffer, and not
until the contents of the buffer are returned to the disk have any
changes been made permanent. This transferral of a page contained
in core to the disk is called page-out.
3-2

Page/buffer size is established at area allocation time by the
DMCL statements. This size is in multiples of 128 words--since blocks
of 128 words are read or written at one time by the monitor from or
to the disk. When a page/buffer size is greater than 128 words, the
page is sub-divided into sectors of 128 words each. This sub-division
has no effect on lines (which may cross over section boundaries), but
does increase the amount of I/O time needed to bring an entire page
into core. Increased buffer size also expands the need for memory
at run-time, but this is justifiable in many instances--e.g., when
an occurrence of a record type and its set linkages would take up
more than one block of storage space. DBMS-IO does not permit records
--i.e., lines--to run across a page boundary because they would not
be entirely in the buffer.
3.3 DMCL ENTRIES
This section describes the DMCL entries used to assign areas to
mass storage devices.
3.3.1 DMCL Record Entry
FUNCTION To specify the maximum number of records which can bestored on a page.
FORMAT RECORDS-PER-PAGE integer-l
NOTES This entry must precede all other entries in a schemadescription. Only one DMCL Record Entry can be associatedwith any single schema.
Integer-l is an unsigned positive decimal integer betweenI and (n/2)-1 where n is the page/buffer size in words.This is the maximum number of lines--i.e., records-permitted on a page.
3.3.2 DMCL Area Entry
FUNCTION To assign an area to a disk file, to specify the sizeof this file in terms of pages, to specify thepage/buffer. size in words.
FORMAT ASSIGN area-name-l TO filename-lFIRST PAGE IS integer-2LAST PAGE IS integer-3PAGE SIZE IS integer-4WORDS.
NOTES Area-name-l must be the name of an area defined in theschema. There must be a DMCL Area Entry for each areadefined in the schema.
Filename-l may be up to six characters or digits andcannot include a filename extension. The filenames
3-3

within a project and programmer number must be unique, andthe files so named will be assigned an extension of .DBSby the DDL processor.
Integer-2, integer-3, must be unsigned positive decimalintegers. Page numbers within files within a data basecannot overlap--i.e., if one file spans Pages 1 to 120,then no other file in the same data base can contain apage numbered less than 121. The numbering need not becontiguous between areas.
Integer-4 should be an integer multiple of 128, less 1.The reason for "less I" is that the DDL processor automatically allots the next largest integer multiple of 128as the page/buffer size--i.e., if the page size isspecified as 127 words, then the DDL processor allocates128 words; if it were specified as 128 words, though, 256words would be allocated.
A maximum page/buffer size of 32K words is imposed by thesystem.
The ordering of the statements in this entry is importantand must be maintained.
3-4

CHAPTER 4
THE SCHEMA DATA DESCRIPTION LANGUAGE (DDL)
This cha~ter contains the entire description of the Schema Data
Description Language (DDL).
4.1 INTRODUCTION
The DDL enables the Data Base Administrator to define and
describe the logical and physical mapping of a data base in terms of
a schema. A schema written in the Schema DDL consists of four types
of entry which serve to:
(1) Identify the schema (Schema Entry) ;
(2) Define areas (Area Entry) ;
(3) Define records (Record Entry) ;
(4) Define sets (Set Entry).
For each area, record type, and set type described in the schema,
a separate entry is required. However, one, and only one, Schema
Entry can appear in a schema. When a schema is constructed, the
following ordering of the entries must be maintained:
(1) The Schema Entry must always be the first entry;
(2) An Area Entry must precede the Record Entries for allrecord types within that area;
(3) A Record Entry must precede the Set Entries for allrecord types which participate in those sets aseither owners or members.
4.2 SCHEMA ENTRY
FUNCTION
FORMAT
EXAMPLE
NOTES
To identify a SCHEMA of a data base.
SCHEMA NAME IS schema-name.
SCHEMA NAME IS BARHEX.
The schema-name must be unique among the schema-namesknown to DBMS-ID. All schema-names are'limited to 1to 6 characters in length.
The schema identified by the specified schema-name consistsof the DDL entries that appear after this entry and beforethe END-SCHEMA indicator.
4-1

4 • 3 AREA ENTRY
FUNCTION To name and give certain characteristics of an area withina data base and to optionally specify privacy locks and/orthe temporary nature of the area.
FORMAT AREA NAME IS area-name-l[i AREA IS TEMPORARY]
[i PRIVACY LOCK [FOR f(EX::::::A)LUPDATE}~ PROTECTED
IS literal-I].
EXAMPLE
NOTES
AREA NAME IS PERSONNEL-AREAPRIVACY LOCK EXCLUSIVE UPDATE IS PAEXUPPRIVACY FOR RETRIEVAL IS PARER.
All area names must be unique among area-nameswithin the schema, and may be from I to 30characters in length.
At least one area-name must be specified in aschema. If only one area-name is specified, thenthat area and the data base are equivalent.
A temporary area is not shared among concurrentrun-units. Any run-unit which makes reference toan area defined as temporary is allocated a privateunique occurrence of that area. This is true evenwhen multiple run-units refer to the same area-name.When a close is executed on a temporary area or therun-unit terminates, record and set occurrences inthe area are no longer accessible and the spaceoccupied by the temporary area may be made availablefor re-use by the DBCS.
PRIVACY LOCK specifies the privacy lock which appliesto the use of an area. A separate PRIVACY clause maybe stated for each usage-mode. However, the sameusage-mode must not be specified in more than onePRIVACY clause.
The literals are privacy locks, to be matched withthe- pertinent privacy key. These literals mustconform to the data characteristics of privacylocks,'and are limited to six characters in length.
The same literal may be specified for one or moreoptions included in the PRIVACY clause. If theoptional FOR clause is omitted, the literal appliesto any use of the area.
If a PRIVACY clause is not specified for a givenusage-mode, then the use of that usage-mode on thedescribed area is without restriction.
The privacy locks associated with the three usagemodes must be satisfied by the run-unit in orderto enable it to open the area with the correspondingusage-mode.
4-2

4 • 4 RECORD ENTRY
The record Entry will be presented in terms of two sub-entries
Record Sub-Entry and Data Sub-Entry.
4.4.1 Record Sub-Entry
FUNCTION To name a record type in the schema - i.e., to specify ageneric name for all occurrences of the record type inthe data base. Also, to give certain characteristics ofrecord occurrences within a data base.
FORMAT RECORD NAME IS record-name-l
LOCATION MODE IS
(data-name-l )
DIRECT identifier-l
CALC USING data-name-2--r;-data-name-3] •••[DUPLICATES ARE[NOT]ALLOWED]
EXAMPLE
NOTES
VIA set-name-l
WITHIN area-name-l ,area-name-2 •.. AREA-ID ISdata-name-4]
RECORD NAME IS CUSTOMER-RECORDLOCATION MODE IS CALC USING ACCOUNTDUPLICATES ARE NOT ALLOWEDWITHIN MARKETING-AREA
Record-names must be unique within the records ofa schema, and may be 1 to 30 characters in length.
The LOCATION MODE clause is used to define the,criteria for selecting a record occurrence and toadvise the DBCS of the desired placement for arecord occurrence in an area.
Identifier-l is implicitly declared as a databasekey and is not part of a record. Data-name-l mustbe qualified with a record name and must refer toa data-item defined as a database key. Data-name-2and data-name-3 must refer to data-items includedin the record being described. Set-name-l must bea set in which the record is defined as being amember.
If the DIRECT option is specified, the specifieddata item must be initialized prior to the executionof a command that selects the record on the basis ofits location mode.
If CALC is specified, then data-name-2,3 .•. must beinitialized prior to the execution of a command thatstores a record or selects it on the basis of itslocation mode.
If VIA set-name-l is specified, then all data itemsused to select a unique set occurrence as specifiedin the set occurrence selection clause for the set
4-3

named must be initialized prior to the execution of acommand that stores a record or selects it on the basisof its location mode.
The LOCATION MODE clause controls placement of recordsaccording to the options selected. Specification ofDIRECT or CALC causes placement to be controlled bydata-name-l or identifier-lor by data-name-2,3 ••.respectively. Specification of VIA set-name-l SETcauses placement to be as close as possible to thelogical insert point 'of the record in set-name-l,thus permitting clustering of data.
The DUPLICATES clause refers to the CALC keys. Ifthe DUPLICATES ARE NOT ALLOWED clause is specified,no additional occurrence of this record type will beallowed to exist if all of its CALC key values areidentical to those of an occurrence already in thedata base. When this clause is omitted, the defaultis DUPLICATES ARE ALLOWED.
The WITHIN clause tells the DBCS into which area anoccurrence of the record is to be placed.
Area-name-l, area-name-2 must be the names of areasfor which an area entry is included in the schemaprior to this entry. By its appearance in an AREA-IDclause, data-name-4 is implicitly defined to be acharacter-string that conforms to the rules for theformation of area-names. If the LOCATION MODE IS VIAset-name clause is specified in this Record Entry,the WITHIN clause for this Record Entry must includeall areas named in the WITHIN clause of the OWNERrecord of the set named.
When only one area-name is specified, the contentsof data-name-4 determine the area into which a recordoccurrence is placed.
Data-narne-4 must be initialized with an appropriatearea-name or with NULL-VALUE prior to the executionof a command which stores a record or one whichselects a record on the basis of its LOCATION MODEclause.
If the LOCATION MODE clause specifies DIRECT orCALC, data-name-4 must be initialized with anarea-name included in the WITHIN clause; otherwisean error will occur.
If the LOCATION MODE clause specifies VIA set-nameSET, data-name-4 must be initialized with an areaname included in the WITHIN clause or with NULLVALUE. If it is initialized with a legal area-namethe record occurrence is placed in the named-area.If it is initialized with NULL-VALUE the recordoccurrence is placed as close as possible, withinthe constraints of the areas named in its WITHINclause, to its logical insert point in the setnamed.
4-4

4.4.2 Data Sub-Entry
FUNCTION To name a data-item or data-aggregate and indicate itsstructural level within a record.
FORMAT 1 ~ data-name-l (PICTURE) IS picture-string., FE.
EXAMPLE 1 02 ACCOUNT PICX(6).
FORMAT 2 02 data-name-2 SIZE IS integer-I.
EXAMPLE 2 02 ADDRESS SIZE IS 50.
FORMAT 3
~PICTURE) IS Picture-string]
(level-number) data-name-3 PIC
OCCURS integer-2 TIMES
EXAMPLE 3 03 SALES OCCURS 150 TIMES.
NOTES A data-name is a name that is not identical to anyreserved word, and may be from 1 to 30 charactersin length. A data-name must be unique within arecord.
A data sub-entry names and describes a data-item,vector or repeating group. Additional sub-entriesare required to name and describe the components ofa repeating group.
Format 1 is used to describe elementary data-itemswhich are not part of a data-aggregate. The 02level number-is mandatory. Format 2 is used tospecify a data-aggregate, which may only be definedat the 02 level.
Format 3 is used to describe data-items which makeup a data-aggregate, and may be any COBOL acceptedformat.
A picture-string must conform to the rules forANSI COBOL picture-strings.
A level number in Format 3 is an unsigned decimalinteger greater than 2 and less than 100, and itmust be specified.
In Format 2, i~teger-l must be equal to the sum ofthe number of character positions specified for eachof the subordinate sub-entries for that data-aggregate.
The OCCURS clause in Format 3 must conform to therules of ANSI COBOL for such a group.
If data-name-l is used as a database key using DIRECT,then it must have a picture X(lO).
4-5

4.5 SET ENTRY
FUNCTION To name a set type in the schema - i.e., to specify ageneric name for all occurrences of the set type inthe data base; to specify the mechanism to be utilizedto support the manipulation of a set; to specify theinsertion point of a member record occurrence withina set occurrence and thereby define the order ofsequential progression. Also to specify the name ofa record, each occurrence of which establishes theexistence of an occurrence of the set named in thisentry; to name the records which may, be members ofthe set named; and to specify the type of membershipin that set. In addition, to specify the sort controlkeys for the member records of a sorted set; tooptionally check and reject the insertion within thesame set occurrence of member record occurrences thatcontain duplicate values for the specified sortcontrol keys; to define the rules governing theselection of the appropriate occurrence of a set forthe purpose of inserting an occurrence of a memberrecord or accessing a desired member record.
FORMAT SET NAME IS set-name-l
;MODE IS CHAIN [LINKED TO PRIOR]
~FIRSTJALWAYS LASTNEXTPRIOR
; ORDER IS 1WITHIN RECORD-NAME JSORTE BY DATABASE-KEY
DUPLICATES~~*iT] ALLOWED
; OWNER IS {record-name-l}SYSTEM
;MEMBER IS record-name-2 (MANDATORY:\(AUTOMATIC)OPTIONAL J MANUAL
[LINKED TO OWNER]
[DUPLICATES ARE NOT ALLOWED FOR identifier-l[, identifier-2] ••• ]
G(ASCENDING "\[RANGE]~ DESCENDING!
[DUPLICATES ARE
4-6
KEY IS identifier-3
[~TJ ALLOWED]]NOT

EXAMPLE
NOTES
[i SET OCCURRENCE SELECTION IS THRU
( CURRENT OF SET JLOCATION MODE OF OWNER .
[USING identifier-4 [ ,identifier-S] ••• J)ALIAS FOR identifier-6 IS data-name-l .•.
SET NAME IS ORDER-SETMODE IS CHAIN LINKED TO PRIORORDER IS ALWAYS LASTOWNER IS CUSTOMER-RECORDMEMBER IS ORDER-RECORD OPTIONAL MANUAL OWNER
DUPLICATES ARE NOT ALLOWED FOR ORDERNUMSET SELECTION CURRENT.
SET NAME Clause
The set-name must be unique among the set-names ofthe schema.
MODE Clause
Each set within a schema may have only one MODEclause. All participating records of a set definedwith MODE IS CHAIN clause are linked to the nextrecord. The optional LINKED TO PRIOR clause causesthe DBCS to generate an additional pointer in theprior direction for the owner record and for eachmember record of each occurrence of the set.
ORDER Clause
If the ORDER IS SORTED clause is specified withthe DUPLICATES option, an ASCENDING/DESCENDINGclause without a DUPLICATES clause must bestated for each member sub-entry for this set.
ORDER FIRST refers to the position within the setoccurrence that immediately follows the ownerrecord occurrence. This is a reversed chronologicalsequencing in that the last member record insertedinto the set occurrence becomes the first member ofthe set occurrence.
ORDER LAST refers to the position within the setoccurrence that immediately precedes the ownerrecord occurrence. This is a chronological sequencingi the newest member record occurrencebecomes the last member in the set occurrence.
When both the ORDER IS LAST and MODE IS CHAINclauses are specified in a set entry, a pointerto the last member record of each set occurrencewill be associated with the owner record of thatset occurrence.
ORDER PRIOR/NEXT refers to insertion pointsrelative to the current record of the set. Whenever the current record of a given set-name is notknown to the DBCS no new member'records can be
4-7

inserted into an occurrence of that set-namewithout first establishing a current record for it.
The ORDER IS SORTED clause allows' specificationof a set order based on the record-names or thedatabase keys of the member records of the set,or on the values of the sort control data itemsspecified in the ASCENDING/DESCENDING clausesfor the member records of the set.
The optional WITHIN RECORD-NAME clause allowsrecords to be sorted without regard to the orderof other record types in the set. This does notmean that there is an implied major sort byrecord type. It means only that when a giventype of record is considered indepen~ently of anyother member record-type, it is in sequence by itsown sort key(s). If the ASCENDING/DESCENDINGclause is not used for any member record-type, thedatabase keys of the occurrences of that recordtype are used as ascending sort keys.
The optional BY DATABASE-KEY clause specifies thatthe member records of a set occurrence are kept inascending sequence by their database keys.
The optional DUPLICATES clause specifies the actionto be taken when a new record occurrence is to beadded to the set and the values of its sort controldata items are duplicates of sort control data itemsof record occurrences which currently participateas members of the set occurrence. Use of theDUPLICATES clause also specifies that the memberrecords in a set occurrence are to be maintainedin a single sequence regardless of the number ofdifferent member record-types specified in theset entry. The common sort key(s) are specifiedin the ASCENDING/DESCENDING clauses for each memberrecord type and must agree in size, mode and physicalposition within the record.
If the ORDER IS SORTED, and the WITHIN RECORD-NAME,BY DATABASE-KEY, or DUPLICATES clause is not used,the record-name of the member record is used as themajor sort key. Minor sort keys are specified bythe ASCENDING/DESCENDING clauses for each memberrecord-type. If the ASCENDING/DESCENDING clause isnot used for any member record-type, the databasekeys of the occurrence of that record type are usedas the sort keys for that record type.
OWNER Clause
Record-name-l must be previously defined in a recordentry.
If the OWNER IS SYSTEM clause is used in a set entry,none of its member sub-entries can include a setoccurrence selection clause.
4-8

MEMBER Clause
Record-name-2 must be previously defined in a recordentry.
Identifier-I, identifier-2 .•. must refer to data itemsincluded in record-name-2.
Record-name-2 cannot be the name of the recordspecified in the OWNER clause of this set entry.
If the optional word AUTOMATIC is used occurrencesof record-name-2 are inserted unconditionally intothe selected occurrence of the set at the time therecord occurrence is stored.
If the word OPTIONAL is used occurrences ofrecord-name-2 may be inserted into, or removed fromthe appropriate set occurrences by the executionof the INSERT and REMOVE commands respectively.
If the DUPLICATES NOT ALLOWED clause is used theDBCS will reject the insertion into any given setoccurrence of member record occurrences with duplicate values for the data items specified in thisclause. This may occur during an attempt to storea new record occurrence in the data base, or to insertan existing record occurrence into a set or to modifythe value of such a data item.
The optional LINKED TO OWNER clause causes eachmember record occurrence of this type to be directlyassociated with the database key of its OWNER. .The LINKED TO OWNER clause cannot be applied tomember record of sing~lar sets.
A MEMBER clause must be specified for each recordtype that can participate as a member in the setbeing described. More than one record type canbe declared as a member of any given set.
A record can be defined as a member in more than oneset. It may also be defined as an owner in one ormore sets.
The DUPLICATES NOT ALLOWED clause must be repeatedfor each data item or concatenation of data itemsfor which duplicate values are not allowed. Theidentifiers included in any single DUPLICATES NOTALLOWED clause will be concatenated.
Each occurrence of a member record participates inonly one occurrence of a set. That is, within aset, each member record occurrence may have oneand only one owner.
A record may not be defined as both an owner and amember of the sets such that a cycle is formed inwhich all records participate as automatic membersin. the sets included in the cycle.
4-9

Identifier-3, identifier-4, •.. must refer to dataitems specified in the Record Entry for the recordnamed in the MEMBER clause of this sub-entry.
ASCENDING/DESCENDING Clause
The ASCENDING/DESCENDING clause must be included inall member sub-entries of any set-entry which includesan ORDER IS SORTED clause specifying the optionalDUPLICATES clause. This clause must not be used ifthe set-entry does not include the ORDER IS SORTEDclause or if the ORDER IS SORTED BY DATABASE-KEYclause is used. For all other forms of the ORDERIS SORTED clause, specification of the ASCENDING/DESCENDING clause is optional.
The DUPLICATES clause must be stated if and only ifthe ASCENDING/DESCENDING clause is used and an ORDERIS SORTED clause does not include a DUPLICATES clause.
The order in which the keys are specified willdefine the major to minor sequence for sorting.
Within a member record some data items can bedefined as ascending keys and some can be definedas descending keys. That is, they can be intermixed.
If there are multiple member record types definedfor a set, the ASCENDING/DESCENDING KEY clauses canbe intermixed between record types. That is, onerecord type can be defined with an ASCENDING KEYclause, while another can have a DESCENDING KEYclause.
If the ORDER IS SORTED clause is used in a set entryand no ASCENDING/DESCENDING clause is specified in oneor more of its member sub-entries, the database keyof such a member record is used as an ascending key.
If the ORDER IS SORTED clause includes the DUPLICATESclause, the member records in a set occurrence aremaintained in a single sequence regardless of thenumber of different member record-types. The corresponding sort keys specified for each member recordtype must have identical data characteristics andmust also match in terms of whether they are ascending or descending.
If the optional word RANGE is used, the ordering ofthe member record occurrences is in accordance withthe above rules.
Where one or more data items declared with anASCENDING or DESCENDING RANGE KEY clause are specified as arguments in a SET OCCURRENCE SELECTIONclause the use of the optional word RANGE causeseach occurrence of such a data item to representa range of values and has the following implicationsfor the process of set occurrence selection.
4-10

An equality match between the range key (whichis in the record to be selected) and the inputargument value in the user working area is notrequired for a record to be selected as beingthe owner of the sought set occurrence.
A match will occur regardless of whether therange key has been specified as ascending ordescending as follows:
(a) If the input argument value in the UserWorking Area equals the value of anyspecific range key.
(b) If the input argument value in the UserWorking Area equals the value of anyspecific range key; then a match willoccur on the range key with the lowestvalue.
(c) If the input argument value in the UserWorking Area lies between two adjacentrange key values; the match will·occurwith the larger range key value.
A match will not. occur if the input value in theUWA is greater than the largest value of anyRANGE KEY. When this is the case an Error StatusCondition will occur.
If the DUPLICATES ARE NOT ALLOWED clause is used theDBCS will reject the insertion into any given setoccurrence of member record occurrences with duplicatevalues for the specified ascending/descending keys.This may occur during an attempt to store a newrecord occurrence in the data base, or insert anexisting record occurrence into a set, modify thevalue of a data item specified in an ASCENDING orDESCENDING KEY clause.
If the DUPLICATES ARE FIRST or the DUPLICATES ARELAST clause is used, member record occurrenceswith duplicate values for the specified ascending/descending keys will be inserted by the DBCS beforeor after, as specified, any existing member occurrenceswith such duplicate values.
If the DUPLICATES clause does not include any of theoptional words FIRST, LAST or NOT, the insertionpoint of duplicate member record occurrences relativeto existing duplicates is unpredictable.
SET OCCURRENCE SELECTION Clause
A USING clause may qualify the LOCATION MODE OF OWNERclause only when the LOCATION MODE clause in theRecord Entry for the owner record of the set in whichthis clause appears is VIA set-name. When this isthe case either an ALIAS or a USING clause must bespecified.
4-11

All identifiers must refer to declared data itemsof the owner record of the set(s) referenced.
Identifier-6 ••• must, if the LOCATION MODE clausein the Record Entry for the OWNER record of the setis DIRECT or CALC, refer to data items specified inthat LOCATION MODE clause. If, however, the LOCATIONMODE is VIA set-name, identifier-6 ••• must refer todata-items specified in the USING clause of a SETOCCURRENCE SELECTION clause for another set with thesame defined owner record type.
By their appearance in an ALIAS clause, all datanames are implicitly defined as having the samecharacteristics as their corresponding identifiers.A data-name specified in an ALIAS clause definesa data-name in the run-unit's User Working Area.
The LOCATION MODE OF OWNER option cannot be usedif the owner being referenced does not have aLOCATION MODE clause specified for it in itsRecord Entry.
If the LOCATION MODE OF OWNER option is used theRecord Entry for the owner record type beingreferenced must have a DUPLICATES NOT ALLOWEDclause if its LOCATION MODE IS CALC.
All other identifiers explicitly named in a SETOCCURRENCE clause must have a DUPLICATES NOT ALLOWEDclause in the appropriate Set Entries. The DUPLICATESNOT ALLOWED clause may be specified in the ASCENDING/DESCENDING KEY clause, the SEARCH KEY clause or theMEMBER clause of the relevant Set Entries.
The SET OCCURRENCE SELECTION clauses for the appropriate member record and set combinations will governthe selection of specific set occurrences whenever:
A STORE command is executed and the object recordis an automatic member of one or more sets.
A MODIFY command is executed which changes thevalue of a data item specified in a SET OCCURRENCESELECTION clause.
Prior to the execution of any command involving setoccurrence selection, the data items specified inthis clause must be initialized. The data itemsspecified by this clause are those which are explicitly named in it and/or those which are not explicitlynamed but which are implied by the LOCATION. MODEoption of this clause.
This clause applies where:
The owner record of the set occurrence to beselected is either procedurally pre-selected(the CURRENT OF SET option) or can be uniquelyidentified on the basis of its LOCATION MODEclause alone (the LOCATION MODE OF OWNER option
4-12

is used in this clause and the Record Entry forthe owner record of the set specifies that itsLOCATION MODE IS DIRECT or CALC).
The owner record of the set occurrence to beselected cannot be determined except in terms ofits membership in some other set and its associated SET OCCURRENCE SELECTION clause (theLOCATION MODE OF OWNER option is used in thisclause and the Record Entry for the owner recordof the set specifies that its LOCATION MODE ISVIA set-name).
The CURRENT OF SET option causes the DBCS to selectthe current set occurrence as defined by the currentof the appropriate set-name. This is the set-nameof which this clause is a part.
The LOCATION MODE OF OWNER option causes the DBCSto select a set occurrence on the basis of theLOCATION MODE clause specified in the Record Entryfor the owner of the appropriate set name. Thisis the set name of which this clause is a part.Unless the ALIAS option is used in the SET OCCURRENCESELECTION clause, or the LOCATION MODE clause in theRecord Entry for the owner record is VIA set-name,the arguments used for selection of the owner recordare the arguments specified in the LOCATION MODEclause of the Record Entry. These arguments musttherefore be initialized with the actual argumentvalues prior to each execution of any command controlled by the SET OCCURRENCE SELECTION clause.
If the LOCATION MODE OF OWNER option is used andthe LOCATION MODE clause in the Record Entry for theowner record is VIA set-name, the owner record to beselected must be located in terms of its membershipin another set. This selection is governed by theSET OCCURRENCE SELECTION clause for the set named inthe LOCATION MODE clause of the owner record, andby the USING option of the SET OCCURRENCE SELECTIONclause. The data items specified in the USING clausemust uniquely identify a specific record occurrencewithin an occurrence of the set named in the LOCATIONMODE clause of the owner record. The SET OCCURRENCESELECTION clause for the set named in the LOCATIONMODE clause may, in turn, specify LOCATION MODE OFOWNER and the LOCATION MODE may again be VIA set-name.
This condition may occur to an arbitrary number pflevels, but must eventually terminate with a SETOCCURRENCE SELECTION clause that does not specifyLOCATION MODE OF OWNER where the LOCATION MODE isVIA set-name. At each level other than the first,the arguments specified in a USING clause are usedto select an owner record in its capacity as amember of another set. The arguments specifiedmay be any data items in the records to be selected.
4-13

The optional ALIAS clause provides for the situationwhere a given record is defined as a member in morethan one set type, and each such set type has thesame owner record type. In this situation, morethan one argument value may be required for the dataitem named as an argument. The ALIAS clause providesthe User Working Area locations for such values.
For sets with more than one record type named asmember record - i.e., multiple MEMBER clauses -a SELECTION clause is needed for each MEMBER Clauseand precedes the next MEMBER Clause. SELECTIONCURRENT need not always be specified, as this isthe default.
4-14

CHAPTER 5
THE COBOL SUB-SCHEMA DATA DESCRIPTION LANGUAGE (DDL)
This chapter contains the entire description of the DBMS-IO
COBOL Sub-Schema Data Description Language (DDL).
5.1 INTRODUCTION
The COBOL Sub-Schema DDL enables the Data Base Administrator to
describe the subset of a data base known to one or more COBOL DML
programs in terms of a COBOL sub-schema. A sub-schema description
written in the COBOL Sub-Schema DDL consists of the Sub-Schema
Identification and three sections:
AREA SECTION
RECORD SECTION
SET SECTION
All sections must appear in the above order.
The Area, Record, and Set Sections consist of an entry for each
area, record, or set to be included in the sub-schema being defined.
Each such entry completely describes an area, record, or set.
Sub-schema descriptions follow the schema description, but
before the END-SCHEMA indicator, and are passed through the DDL
processor along with the DMCL and Schema DDL statements.
5.2 SUB-SCHEMA IDENTIFICATION
FUNCTION
FORMAT
EXAMPLE
NOTES
To define and name a sub-schema within a schema, andto specify the privacy lock for the use of a sub-schema.
SUB-SCHEMA NAME IS sub-schema-namePRIVACY LOCK IS literal-I.
SUB-SCHEMA NAME IS SUBOI PRIVACY SALEX.
Sub-schema-name must be unique among the sub-schema~names
associated with the specific schema.
Literal-l must conform to the data characteristics ofprivacy locks to be matched with the pertinent privacykeys.
5-1

5.3 AREA SECTION
FUNCTION
FORMAT 1
FORMAT 2
FORMAT 3
EXAMPLE
NOTES
To enumerate the areas of the schema that are includedin the sub-schema and, by implication, to remove fromview all other areas of the schema.
AREA SECTION.COPY area-name-l [,area-name-2]
AREA SECTION.COpy ALL AREAS.
AREA SECTION.COpy TEMPORARY area-name-3 [,area-name-4]
AREA SECTION.COpy MARKETING-AREA, INVENTORY-AREA.
Area-name-l, area-name-2, ..• must refer to areasdefined in the schema.
If Format 2 is used, Formats 1 and 3 entries are notallowed. Otherwise 1 and 3 may be repeated as needed.
Format 1 causes the entries for the referenced areasin the schema to be included in the sub-schema.
Format 2 causes all areas for which entries areincluded in the schema to be included in the sub-schema.
Format 3 designates the named areas to be sub-schematemporary. A sub-schema temporary area is a privateunique occurrence of a normal area which is alwaysopened as if protected update had been specified.However, any changes made to this area will be discardedwhen the run-unit closes the area or terminates. Thisis used to permit program testing on "live" data withoutloss of data base integrity.
5.4 RECORD SECTION
FUNCTION
FORMAT
EXAMPLE
NOTES
To enumerate and define the records of the schema thatare to be included in the sub-schema. By implication,to remove from view all other records of the schema.
RECORD SECTION.01 record-name-l.01 record-name-2.
RECORD SECTION.01 CUSTOMER-RECORD.01 ORDER-RECORD.01 STOCK-RECORD.01 SUPPLIER-RECORD.
All record-names must be unique within the record-namesused in the sub-schema. Since each record-name must bethe name of a record declared in the schema, this shouldbe no problem. No changes are allowed.
5-2

Each record 'named must be located within an area namedin the Area Section. If a record is located in more thanone area, and not all of these areas are included inthe sub-schema, then only the record occurrences locatedin the included areas are made part of the sub-schema.
5.5 SET SECTION
FUNCTION
FORMAT I
FORMAT 2
EXAMPLE
NOTES
To enumerate and define the sets of the schema that areto be included in the sub-schema, and, by implication,to remove from view all other sets of the schema.
SET SECTION.COpy set-name-l [,set-name-2]
SET SECTION.COpy ALL SETS.
SET SECTION.COpy ORDER-SET, INVENTORY-SET, SUPPLIER-SET.
All set names must refer to sets defined in the schema.
Format I entries may be repeated as required. IfFormat 2 is used, no Format I entries are allowed.
Format I causes the entries for the referenced sets inthe schema to be included in the sub-schema. No changesare allowed.
Format 2 causes all sets for which entries are includedin the schema to be included in the sub-schema.
An entry must be included in the Record Section for theowner record of each set included in a sub-schema.
If a set included in a sub-schema is SORTED on one ormore keys, all the records containing those keys areto be included in the sub-schema. Otherwise, no recordmodification will be permitted for members of that set.
5-3

11111111111111111111111111111111111111111111111111111111111111111111111111

CHAPTER 6
DATA ORGANIZATION AND ACCESS
Data organization refers to the manner in which data is arranged
in a data base. Data access refers to the way in which data from
the data base is read and/or written (I/O).
6.1 DATA ORGANIZATION
As discussed in previous chapters, a data base must be equated
to DECsystem-lO monitor files for storage on disks. The DDL
processor accepts the DMCL entries, which precede the DDL entries
in the Schema-Sub-Schema DDL file, and writes files based on the DMCL
entries. The assigment of physical space for these files (hereafter
called DBS files, because .DBS is the filename extension given these
files by the DDL processor) is performed automatically by the
monitor when the DBS files are ,written by the DDL processor. The
DBS files may be any length, and each data base may be divided into
as many files as its Data Base Administrator wishes, as long as
disk space is available. Under the DECsystem-lO monitor, files may
be concurrently read by more than one user at a time--thus permitting
concurrent retrieval of data from areas of a data base. Update of a
file by more than one person at the same time, though, is not possible,
although an updated version of an area of a data base may be written
by one user while other users continue to read the old version--i.e.,
protected update.
Pages are the basic partitions of the DBS files to which a data
base is assigned (see Chapter 3). By dividing the DBS files into
pages, and storing selected records on these pages, and using a page
as the basic I/O buffer size, DBCS operations that affect the records
on only one page can be handled with a single disk access. The DBS
files are random access files--i.e., they can be accessed by the
DBCS either sequentially or randomly (see Section 6.2).
Record locations on a page (hereafter referred to as lines) are
consecutively numbered starting with one. When combined with the
page number to form a database key (see Section 6.1.4), this line
number becomes the address of the corresponding record occurrence in
the data base.
6-1

Before cqnsidering data access, several aspects of data organi
zation should be discussed:
(1) identification of a DBS file;
(2) identification of a page--the page header;
(3) format and identification of a line;
(4) forming a database key.
6.1.1 Identification Of A DBS File
All files created by the DDL processor for storage of areas of
a data base are given the filename extension of .DBS when created.
Unique to each data base is a schema directory file--also created
by the DDL processor--in which the structure of that data base is
described (see Chapter 7). As part of each area description in this
directory, the corresponding DBS file appears. Further explanation
of this will be given in Section 6.2 and in Chapter 7.
6.1.2 Identification Of A Page
When a DBS file is created by the DDL processor, it is also
segmented into its appropriate number of pages, and each page is
given a page header which serves to specify:
(1) the page number;
(2) the pointer reference for the page;
(3) the space available on the page in terms of words;
(4) the record space available on the page.
The DECsystem-lO records data as 36-bit words, which can also be
viewed as 12 octal bytes. DBMS-IO is therefore designed to fit into
these 36-bit words of portions thereof.
A page header is thu~ a word block which has the following
format.
6-2

o
1
2
3
4
PAGE NUMBER
POINTER REFERENCE
SPACE AVAILABLE
RECORDS AVAILABLE~ -
where:
PAGE NUMBER is the number of the page in octal, rightjustified, and bit 0 is always zero.
POINTER REFERENCE is an octal number, right justified.The pointer reference is a function of the page numberand the records-per-page specified in the DMCL RecordEntry.
SPACE AVAILABLE is the number of words left on the pagewhich can be used for lines; it is initially calculatedby subtracting the number of words used for the pageheader from the page size, and is updated.
RECORDS AVAILABLE represents the maximum number ofrecords which can be assigned to a page as determinedfrom the DMCL Record Entry. The number of words necessaryto make this representation is dependent on the numberof records-per-page specified since one bit is allottedfor each record.
The following examples should be helpful in understanding how
the page header is formed.
EXAMPLE 6.1
Consider the following DMCL entries:
RECORDS-PER-PAGE 63.
ASSIGN EXAMPLE-AREA-l TO XFILEIFIRST PAGE IS 1LAST PAGE IS 43PAGE SIZE IS 127 WORDS.
The page headers in XFILEl.DBS would be five words long. This
size is calculated in the following manner. The first word contains
the page number; the second, the pointer reference; and the third,
the space available. Since the records-per-page is given as 63,
6-3

63 bits are needed to represent the 63 lines which the page could
at the most hold. Two words contain 72 bits, so the leftmost 64
bits of the combined fourth and fifth words are used for this
indication. Bit 0 of the fourth word is left zero, but the following
63 bits are turned on. Later, whenever a record is stored on a
particular page, it is assigned a number corresponding to the left
most "on" bit.
The space available now on any page in XFILEl.DBS is 123 words.
This figure is derived in the following way. The page size was
given as 127 words. The DDL processor always allocates page size
as the next higher multiple of 128 words (200 8 words). Since
127<1*128, 128 words is the page s~ze used. If 128 words had been
specified, 256 (400 8 words) would have been allocated. Thus,
since five words were needed for the page header, only 123 words
(173 8 words) remain for data storage.
The pointer reference is calculated as follows:
(I) convert the page number to octal and place it in thesecond word, right justified;
(2) take the records-per-page value and determine the nexthighest power of 2 (e.g., the next highest power of 2with respect to 63 is 6);
(3) shift the number in the second word left as many bitsas this power of 2 (thus in this example, it would beshifted 6 bits).
The resulting octal number is the pointer reference. For this
example, the pointer reference for Page 1 is 100, while for the
last page, the octal page number is 53 and its reference is 5300.
Thus, in an octal dump of XFILEl.DBS, the page header for the
first page would look like:
377777777777
6-4

EXAMPLE 6.2
Now consider these DMCL entries:
RECORDS-PER-PAGE 127.
ASSIGN EXAMPLE-AREA-2 TO XFILE2FIRST PAGE IS 100LAST PAGE IS 1201PAGE SIZE IS 200 WORDS.
The page header for Page S23 (1467 S) from an octal dump of
XFILE2.DBS is shown below.
~~~~~~~~1467777777777777
~~~~~~3156~~777777777777
377777777777
Note the page number in the first word is in octal; the pointer
reference entailed shifting 7 bits left; four words were needed to
accommodate records available, leaving 249 (371 S) words for data
storage. Note further, even though 200 words were specified for
page size, 256 (400S
) were allocated.
6.1.3 Format And Identification Of A Line
When the DDL processor creates a DBS file, the pages are
empty, except for their page headers which are always present. The
lines on a page are written by the DBCS during execution of a run
unit (see Section 6.2). The format and identification of a line,
though, really belongs to data organization, and will be discussed
here.
Each line begins on a word boundary, and covers as many words
as is necessary, terminating on a word boundary. Lines are confined
to the page on which they begin, and can never cross page boundaries.
A line has the following format:
LINE HEADER I POINTERS DATA
The line header is a single word and contains the following:
Bits 0 through S
Bits 9 through 17
the line number in octal.
the record type to which thisrecord occurrence belongs (seeChapter 7) •
6-5

Bits 18 through 19
Bits 20 through 28
Bits 29 through 35
DELETE flag.
Must be zero (MBZ).
the length of the line in words{includes header).
For each set link associated with the record occurrence be
longing to a line, there is an embedded set pointer as part of
the line. Every pointer is given one complete word, the contents
of which is the database key of the line to which it 'points. A
further discu~sion of pointers follows in Section 6.2.
A line from an octal dump of a DBS file appears below.
Line Number Record Type~.---------,--
,.-...~
~~1145~~~~3l
'\Header
6.1.4 Forming A Database Key
625742456264
/'Data
The construction of a database key is essentially the combina
tion of the line number and the number of the page on which it
resides. This is not an additive combination, but a merging of
the pointer reference in the page header (see Section 6.1.2) and
the line number. Thus, considering Example 6.1 again, the third
line on the fourth page would have 403 8 as its database key. In
Example 6.2, the database key for the ninth line on Page 823
would be 315611 8 .
6.2 DATA ACCESS
When a run-unit wishes access to a data base, the DBCS first
verifies the acceptability of the INVOKE statement of the run-unit.
For a run-unit which is permitted access, a User Working Area is
established for the run-unit, and an in-core map of the data base
is created. This in-core representation is actually a data base
itself--complete with record types and set types. Figure 6.1
shows the set structures of this in-core data base.
6-6

SUB-SCHEMABLOCK
RECORDBLOCK
AREABLOCK
A.W SET
DATABLOCK
D.C SET
R.M SET
MEMBERBLOCK
M.C SET
CONTROLBLOCK
WITHINBLOCK
R.O SET
OWNERBLOCK
O.M SET
Figure 6-1 In-Core Representation
The DBCS uses this in-core representation to govern the inter
actions with the data base. All data base I/O operations are
dependent on this map. The first point of this section to be covered,
then, will be the in-core representation of the sub-schema to which
a run-unit has access. Following this, the I/O buffering schema will
be discussed, and then the algorithms used to STORE and FIND record
occurrences.
6-7

6.2.1 The In-Core Representation
The in-core representation is a network structure of eight
record types (also called blocks) which serve to map the sub-schema
being accessed by the run-unit. It is created in core from the
schema directory (see Chapter 7) for the data base to which the
sub-schema belongs. A complete analysis will not be given, but
a description of each block is provided for those who are interested.
6.2.1.1 Sub-Schema Block - The sub-schema block is the root of the
in-core representation and has only one occurrence. The word
format for this block is shown in Figure 6-2. BITS/RECORD IN CORE
in the rightmost 30 bits of the first word is a function of the
records-per-page specified when the data base was created, and the
number which appears here is equal to (records-per-page/36) rounded
up. For all the blocks shown in this section, a word where NEXT,
OWNER, or PRIOR appears is a pointer to the appropriate block in
the in-core representation (refer to Figure 6-1 for set types used) •
BITS/RECORD IN FILE is identical with the RECORDS AVAILABLE
words in a page header (see Section 6.1.2). Thus, the size of
the sub-schema block, in words, depends on the records-pe~-page
specified in the DMCL Record Entry.
o
1
2
3
4
00
"
BITS/RECORD IN CORE
NEXT S.R SET I NEXT S.A SET
~
BITS/RECORD IN FILE~
I
n-l
n
Figure 6-2 In-Core Sub-Schema Block
6-8

6.2.1.2 Record Block - For each record type belonging to the
sub-schema invoked, there is set up a record block in core. The
format for this II-word block is given in Figure 6-3.
o
1
2
3
4
5
6
7
8
9
10
01 I TYPE I WITHIN ID PTR
CURRENT OF RECORD TYPE -TOTAL SIZE I DATA OFFSET I FLAG I LOC
10-
~
RECORD-NAME~
~
NEXT S.R SET NEXT R.W SET
NEXT R.O SET NEXT R.M SET
F 1//////////1//# CALC NEXT R.D SET
Figure 6-3 In-Core Record Block
TYPE refers to the octal number which denotes the record type.
WITHIN ID PTR is a pointer to the area block for the areain which the record is located.
CURRENT OF RECORD TYPE is the database key of the currentoccurrence of this record (see Section 1.6).
TOTAL SIZE is the total number of words on the lines onwhich occurrences of this record are stored.
DATA OFFSET is the number of words on these lines whichare used for the header and for pointers.
The FLAG bits in word 2 contain the following:
Bits 25-30 Must be zero (MBZ).
Bit 31
Bit 32
1
1
Delete not permitted.
Store not permitted.
LOC is the location mode for this record, and is given asfollows:
6-9

o None - no way to locate using this sub-schema.
1 DIRECT
2 CALC
3 VIA
RECORD-NAME is the name of the record type in SIXBIT.
The F(lag) bit in word 10 is the CALC duplicate flag. Ifduplicates are allowed, the bit is on; otherwise, it is off.
# CALC is the number of CALC fields ..
6.2.1.3 Area Block - An area block is written in core for each
area known to the invoked sub-schema. Each of these blocks contains
18 words, and the format appears in Figure 6-4.
o
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
02 FIRST PAGE
MODE LAST PAGE
PAGE SIZE I CH BUFFER TABLE PTR
FILENAME
EXT SECTOR OFFSET
NEXT RECOVERY SECTOR
DIRECTORY PTR FLAG I SIP IRCH
NEXT S.A SET NEXT A.W SET
CURRENT OF AREA
l-
I--
AREA-NAMEr-
-
RETRIEVAL LOCK
PROTECTED UPDATE LOCK
EXCLUSIVE UPDATE LOCK--
AREA SEQUENCE NUMBER
Figure 6-4 In-Core Area Block
6-10

MODE refers to the USAGE MODE specified for the area in theOPEN statement. The octal values, and the modes theyrepresent are:
o CLOSED - not yet:open
1 RETRIEVAL
2 EXCLUSIVE UPDATE
4 PROTECTED UPDATE
10 SCHEMA TEMPORARY
20 SUB-SCHEMA TEMPORARY
The way the DBCS works, if two areas are to be bridged usingsets, both areas must have the same usage mode; otherwise,the DBCS will disallow STOREs and INSERTs in these sets.Likewise, if a record is located within more than one area,the DBCS ANDs the modes for the areas and will not permitoperations on that record if the result is zero.
CH is the software channel on which I/O for this area isperformed.
BUFFER TABLE PTR points to in-core buffer table (seeSection 6.2.2).,
FILENAME and EXT refer to the monitor file in which thisarea is stored. Both are given in SIXBIT.
SECTOR OFFSET is the number of 128 (2008) word sectors atthe front of this file, which are used for recoverypurposes (see Chapter 8), and precede the first page.
NEXT RECOVERY SECTOR is the next available sector in therecovery file for this area (see Chapter 8).
DIRECTORY PTR points to a directory buffer which is used topage in from the recovery file.
FLAG in word 6 has the following configuration:
Bit 18Bit 19
II
Schema TemporarySub-Schema Temporary
SIP is the number of 128 (200 8 ) word sectors per page.
RCH is the software channel on which I/O for the recoveryfile for this area is done.
CURRENT OF AREA is the database key of the current recordoccurrence of this area (see Section 1.6) .
AREA-NAME is the name of the area in SIXBIT.
The LOCKS are all given in SIXBIT.
AREA SEQUENCE NUMBER is an access reference number for thearea which is advanced by the DBCS each time an area isopened. The primary use for this number is to assure the
6-11

retrieval user that he is always reading the data thatexisted in an area when his run-unit began, and that updateddata will not be made part of the permanent data base untilhe closes the area.
6.2.1.4 Within Block - According to the WITHIN CLAUSE specified in
the Schema Record Entry for records defined for the invoked sub
schema, there will be one or more in-core within blocks for a
record. These within blocks use two words, and the format is
given in Figure 6-5.
o
1
03 1/////////////// OWNER A.W SET
NEXT R.W SET NEXT A.W SET
Figure 6-5 In-Core Within Block
6.2.1.5 Control Block - A control block (Figure 6-6) exists for
all the data-items and data aggregates in the data base which have
been specified as either SORT keys or USING/ALIAS identifiers
in the SET SELECTION Clause.
o
1
2
06 k////IAD I/IU IS ALIAS PTR
OWNER M.C SET NEXT M.C SET
OWNER D.C SET NEXT D.C SET
Figure 6-6 In-Core Control Block
AD in word 0 is the ascending/descending flag.
U is the using flag and is on if the block is for usingcontrol.
S is the sort-type flag. When off, match sort is used;when on, range sort is performed.
The ALIAS PTR points to a core location in which is storedthe ALIAS (see Section 4.5) option used in the SETSELECTION Clause.
6.2.1.6 Owner Block - The DBCS uses a unique owner block to
identify and define each set type known to the sub-schema invoked
by the run-unit. Figure 6-7 shows the format for this seventeen
word block.
6-12

o
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
04 I CHAIN IND PRI OFFSET INEXT OFFSET
OWNER R.O SET NEXT R.O SET
///////////////////IFL NEXT O.M SET
DBKEY OF OWNER OF SET
DBKEY OF PRIOR OF SET
DBKEY OF CURRENT OF SET
DBKEY OF NEXT OF SET
l-
I-
SET-NAMEr-
I--
DBKEY OF NEW MEMBER OF SET
DBKEY OF NEW PRIOR OF SET
DBKEY OF NEW NEXT OF SET
RELINK POINT IF BACKUP IS NEEDED
OWNER OF SET IF BACKUP IS NEEDED
Figure 6-7 In-Core Owner Block
CHAIN IND denotes MODE IS CHAIN.
PRI OFFSET is the number of words to skip in the line containing an occurrence of an owner record belonging to thisset in order to find the prior pointer.
NEXT OFFSET is the offset to the next pointer in that line.
FLag in word 2 has the following format:
BitsBit
o - 1617 = 1
MBZSuppress update after FIND or STORE
The DBKEYs in words 3-6 are for those record occurrenceswhich are indicated.
SET-NAME is the name of the set in SIXBIT.
Words 12-16 are temporary storage words which are used tohold update and backup information during a FIND or STORE.Should a FIND or STORE require successive examination ofrecord occurrences, and one of the later examinations fail,then these words are used to return the data base to itsformer condition.
6-13

6.2.1.7 Member Block - A member block exists for each member
record in every set. Figure 6-8 shows this five word block.
o
1
2
3
4
05 1OWNER OFFSET I PRIOR OFFSETI NEXT OFFSET
///////////1//////////////////1 FLAGS
OWNER O.M SET NEXT O.M SET
OWNER R.M SET NEXT R.M SET
LAST M.C SET NEXT M.C SET
Figure 6-8 In-Core Member Block
The OFFSETs in word 0 refer to pointers in the lines onwhich occurrences of this record are located.
The rightmost 13 bits of word 1 are FLAGS which denotethe following:
SORTED
FIRSTNEXTLASTPRIOR
Record may be inserted into setLocation mode is VIA this setDBKEY sortA/D sortDUPLICATES flago allowed1 not allowed2 are first3 are lastSort by record-nameSort entire set on identical keysORDER flago ALWAYS1 ALWAYS2 ALWAYS3 ALWAYS4 SORTED5 SORTED BY DBKEY6 SORTED WITHIN RECORD7 DUPLICATES ALLOWED }
10 DUPLICA.TES NOT ALLOWED11 DUPLICATES FIRST12 DUPLICATES LAST
SET SELECTION CURRENTLOCATION OF OWNERAUTOMATICMANUALMANDATORYOPTIONAL
Bit 33 01
Bit 34 01
Bit 35 01
Bit 28 = 0= 1
Bits 29,32
Bit 23 = 1Bit 24 = 1Bit 25 1
= 0Bits 26,27
The other pointers refer to Figure 6-1.
6-14

6.2.1.8 Data Block - For each data item and data aggregate belonging
to the records defined for the invoked sub-schema, there exists a
data block which describes its location on the lines on which it
appears, its attributes, and MODIFY status. The format for such a
block is given in Figure 6-9.
o
1
2
3
4
5
6
7
8
9
10
07 / IIIIIIIII I FLAGS IIIIIIIIIIII/MODE/FLWORKING STORAGE DESCRIPTION
RECORD DESCRIPTION
OWNER R.D SET LENGTH OF FIELD
NEXT D.C SET NEXT R.D SET
I--
I--
DATA-NAMEI--
I--
RUNTIME ALT STORAGE SYNC NUMBER
Figure 6-9 In-Core Data Block
The following flag bits are used in word 0:
Bit 14 = 1 Data may be modifiedBit 15 1 Data has been modifiedBit 16 1 Data is also CONTROL fieldBit 34 1 Data is CALC fieldBit 35 1 Data is DIRECT field
MODE refers to the data storage mode:
o Binary-l1 Binary-22 Float-l3 SIXBIT4 ASCII5 DBKEY
(USAGE COMP)(USAGE COMP) (2 words)(USAGE COMP-I)(USAGE DISPLAY-6)(USAGE DISPLAY-7)
The WORKING STORAGE DESCRIPTION is a core pointer used toreference the data item, aggregate, or DBKEY.
RECORD DESCRIPTION is a bit offset to the data.
LENGTH OF FIELD is length of data field in octal.
DATA-NAME is the name in SIXBIT.
6-15

RUNTIME ALT STORAGE SYNC# is a count of the number of timesthe record occurrence, to which this data ~elongs, wasmodified and this data was not.
6.2.2 I/O Buffering Scheme
When an area is successfully opened by a run-unit--regardless
of the USAGE MODE specified--the DBCS allocates three (3) I/O
buffers to be used for I/O access for that area. The size of each
of these three buffers is identical with the page size specified
for the area in its DMCL Area Entry. Thus, the page is the
fundamental unit for I/O operations concerning the data base.
The run-unit cannot alter the number of page buffers ~eld
within the' program. This number is preset in the DBCS, although
it may be changed by altering the run-time package. These buffers
remain allocated for the duration of the run-unit, and cannot be
selectively discarded using CLOSE statements. However, if an
OPEN-CLOSE-OPEN sequence is executed for the same area, the DBCS
will reuse the same buffers.
The DBCS maintains in core a page-buffer table which serves to:
(1) specify the number of buffers currently allocated;
(2) give the core location which is the starting addressfor the buffer.
The format for the page-buffer table is found in Figure 6-10.
o
1
2
3
n-2
n-l
n
n = NUMBER OF BUFFERS ALLOCATED
////////////////////// BUFFER LOCATION 1
////////////////////// BUFFER LOCATION 2
////1///////////////// BUFFER LOCATION 3
I I
I I
I I
I II II I
////1///////////////// BUFFER LOCATION n-2
////1///////////////// BUFFER LOCATION n-l
////1//////////1////// BUFFER LOCATION n
Figure 6-10 Page-Buffer Table
6-16

Bit 0 of words 1 through n is the MUST WRITE flag--i.e., it
designates that a change has been made to the page in this buffer,
and this page must be written to the DBS file. In the area block,
there is a PAGE-BUFFER TABLE POINTER (see Section 6.2.1). This
pointer indicates the location on the page-buffer table which has
the starting address of the current page in core.
The current page when three are in core at the same time is
determined in the following manner. Consider the three buffers
schematically shown in Figure 6-11.
1 2 3 4 5 6
26 02 15 07 03 25
-- 26 02 15 07 03
-- -- 26 -02 15 07
~ ~ ~Figure 6-11 I/O Buffering Example
The number in a buffer square indicates the page in that buffer
after an I/O operation; the numbers in circles indicate a page which
was returned to the data base during the I/O operation. Six I/O
accesses are shown. After the first one, only Page 26 is in core;
after the second, both Pages 2 and 26 are in core; after the third,
all three buffers have a page in them. Note that core has
been expanded three times in order to accommodate all three
buffers. The current page in core refers to that page in core
on which the current record of area is located. Thus, if the current
of area were on Pa~e 2, Page 2 would be the current page. If the
current of area should change and be located on Page 15, then that
page would then be the current page.
Note, so long as Pages 15, 2, and 26 are in core, no change
has been made to the permanent data base. When the buffer in which
a page resides is needed for another page--or when the area is
closed--only then does any physical alteration of data occur in
the main storage. Which page is returned to the data base when
6-17

buffer space is needed? The one at the bottom of the buffer lot.
This is shown in I/O operations 4, 5, and 6 in Figure 6-11.
Four points should be remembered concerning the I/O buffering
scheme:
(1) Three buffers are allocated for each OPEN area; thisnumber is fixed.
(2) The buffer size is equal to the page size.
(3) The physical alteration of data in the DBS file do~s
not occur until the page is returned to the disk because~ither its buffer space is needed for another page orthe area is closed.
(4) Buffers remain allocated for the life of the run-unit.
6.2.3 STORE Algorithms
The algorithm used during a STORE operation depends on the
location mode of the record to be stored.
6.2.3.1 DIRECT - As explained in Section 6.1.4, a database key
(DBKEY) is a combination of the page number and the line number
on which a record occurrence is stored. When a new occurrence is
to be stored, and the record's location mode is DIRECT, one of the
following algorithms is used:
(1) If the run-unit specifies aDBKEY, the DBCS ignores therecord portion of the DBKEY and accesses the pagespecified. Once the page is in core, it is checkedfor space to store the new occurrence. If the room isthere, a new line is added to the page; if not, the nextpage is checked for room, and so on until room isfound for the new line. Should the last page of thearea be reached, then the DBCS folds back to the firstpage of the area and continues the search for room.
(2) If no DBKEY is given, the page number of the currentof area is used to begin the above process.
(3) If there is no current of area, the first page of thearea is used as the starting point.
6.2.3.2 CALC - If the location mode is CALC, then all fields
defined as the CALC fields for the record are hashed. The re
sulting number is folded over the pages of the area until this
number can be matched with a page number. The CALC chain on that
page is then searched for the next available line in which to locate
6-18

this record occurrence. Each page has a CALC chain which links
all the CALC records on that page, with ordering in the chain
being according to record type. The first word after the line
header for CALC records contains the pointer to the next CALC
record.
If duplicates are allowed, and positioning is not requested,
then the DBCS will place the record occurrence where it chooses.
If positioning is requested--e.g., LAST--the DBCS will comply.
6.2.3.3 VIA - When the location mode is VIA set-name, the DBCS
attempts to find the logical insert point for the record occurrence
in that set, and will use that as the starting point to find room
for the new line. If this logical point cannot be determined,
the current page of the area is used for the starting point. If
the current page of the area is not known, the first page of the
area is used. VIA can be used to place records where the member
records reside in a different area than the owner record.
6.2.4 FIND Algorithms
Again, these algorithms depend on the location mode of the
record to be found. A FIND DIRECT will always work, regardless
of mode, so long as the DBKEY is given. The DBCS will use the
DBKEY to access the correct page and line directly. FIND CALC
can only be used if the mode is CALC; in which case, the DBCS
calculates, or randomizes, to the appropriate page, and follows
the CALC chain on that page until it finds the desired record
occurrence.
6.3 OVERHEAD
As has been seen in the previous sections, a certain amount
of overhead is required by the DBMS-lO to hold the linking
information, page and line headers, etc., in the main storage
files used for the data base. This section describes how the
overhead can be determined, although rough estimates of overhead
are normally sufficient. The overhead can be defined in terms of
record (line), page, and file overhead. Overhead in run-units is
proportional to the storage overhead for that portion of the data
base known to it and will not be discussed separately.
6-19

6.3.1 Record Overhead
For each record type defined for the data base, the following
can be used to determine the amount of overhead in words;
(1) location mode is CALC 1 word(2) owner of set types 1 word per set(3) member of set types 1 word per set(4) LINKED TO OWNER in set types 1 word per set(5) LINKED TO PRIOR in set types 1 word per set
Add to the calculation 1 word for the line header, and the
overhead for each occurrence of this record type is found. Consider
the following examples:
EXAMPLE 6.3
The record type INVENTORY-RECORD is a CALC record, is the
owner of 4 sets, participates as a member in 5 sets, is LINKED TO
OWNER in 3 of these, and is LINKED TO PRIOR in 1 of them. using
the above overhead determination, the record overhead would be
calculated as:
1 (for CALC chain)4 (for owner of 4 sets)5 (for member of 5 sets)3 (for OWNER links)1 (for PRIOR link)
14
Adding the word for the line header gives a total of 15 words of
overhead for each occurrence of this record type.
EXAMPLE 6.4
The record type SUPPLIER-RECORD is a DIRECT record, and owns
only one set. The -line (record) overhead for this record type
would be one word for the line header and one word for being an
owner. Thus each line on which this record type appeared would
have 2 words of overhead.
A stand-alone record--i.e., one with no set linkages--will have
a minimum of one word of overhead if its location mode is DIRECT,
and two words if it is a CALC record.
6-20

There will be times when the Data Base Administrator will
have to decide whether to repeat a certain item of data in more
than one record or to create a set to eliminate the data redundancy.
If the redundant data would take up less than one 36-bit word in
storage, the justification for using a set would be minimal. This
is one of the judgments which Data Base Administrators have to
make every time a data base is organized or r~organized--justification
of set link overhead.
6.3.2 Page Overhead
Page overhead consists of the number of words which compose
the page header. In general, this overhead can be calculated
using the formaula:
Page Overhead = 3 + RND (R + O.S) words
where R is the records-per-page divided by 36. In Example 6.1, the
page overhead would be S words; in Example 6.2, it would be 7 words.
6.3.3 File Overhead
In addition to page and line overhead, every DBS file has a
128 (200 8 ) word sector at the front of the file used to store
recovery file (see Chapter 8) information. This overhead is
inherent to the system and cannot be altered by the Data Base
Administrator or a user.
6-21


CHAPTER 7
THE SCHEMA DIRECTORY FILE
Unique to every data base is a file created by the DDL processor
and named schema-name.SCH. This file reflects the attributes of the
data base, which was described using the DMCL and the DDLs, in terms
of a data base. In other words, the schema directory file is itself
a data base used to map another data base.
7.1 INTRODUCTION
The schema directory file (hereafter called the SCH file because
of its extension) is physically structured exactly like a DBS file.
It has a l2S (200 S) word recovery sector at the beginning, is divided
into 32 pages of 512 (lOOOS) words each, and each page is further
divided into lines. The page. headers are 7 words long - as if a
records-per-page of 127 had been specified - and the lines are.complete
with line headers and set pointers. Each line on the page contains
an occurrence of a record type - the same as in the DBS files. The
lowest record type code allocated by the DDL processor to a record
type submitted in a DDL entry is 101 (145 S). The reason for this is
that codes 001 through 100 (144 S) are reserved 'by the DDL processor
for assignment to record types in the SCH file. Figure 7-1 shows the
record types, which make up the data base in the SCH file, and the
corresponding set structure. The codes for the record types are
given below in octal.
Table 7-1
Codes for Record Types
RECORD TYPE CODE RECORD TYPE
~~l Schema Block~~2 Record Block~~3 Data Block~~4 Control Block~~5 Member Block~~6 Owner Block~~7 Within Block~l~ Area Block~ll Text Block~12 Sub-Schema Block
7-1

SCHEMABLOCK
S.S SET
TEXTBLOCK
DATABLOCK
D.C SET
RECORDBLOCK
R.M SET
MEMBERBLOCK
SUB-SCHEMABLOCK
WITHINBLOCK
R.O SET
OWNERBLOCK
O.M SET
AREABLOCK
M.C SET
CONTROLBLOCK
Figure 7-1 Schema Directory Representation
7-2

Currently codes 013 8 through 144 8 are reserved for future use by
the DDL processor.
The lines on the pages are divided again into header, pointers,
and data. Data, in the case of the SCH file, is in the form of the
word blocks which specify different attributes of the data base being
described. These word blocks are similar to the word blocks used by
the DBCS for the in-core representation (see Section 6.2.1). In fact,
the in-core blocks are initially written from the blocks in the SCH
file. The next section will describe how the blocks in the SCH file
appear. Section 7.3 will discuss how the DML preprocessor used this
schema directory to write an executable COBOL program.
7.2 WORD BLOCKS IN SCH FILE
Ten word blocks are used in the SCH file. Eight of them are
used by the DBCS to create its in-core representation; the other two
are unique to the SCH file.
7.2.1 Schema Block
The Schema block is the data portion of the schema line in the
SCH file. This one-word block (see Figure 7-2) provides information
on how many sub-schemas have been specified for the schema and how
many bits per record are used in the DBKEYS. This block is used to
write the in-core sub-schema block.
o 1////////1 LAST S-S BIT BITS PER RECORD
Figure 7-2 SCH Schema Block
LAST S-S BIT indicates the last bit used to designate sub-schemamembership. This is checked by the DDL processor when newsub-schemas are added.
BITS PER RECORD denotes how many rightmost bits in the DBKEY areallocated for the line number. See Section 6.2 for how this iscalculated.
7-3

7.2.2 Sub-schema Block
As shown in Figure 7-3, the sub-schema block is a block of 7
words which serves to identify a sub-schema. There is one for each
sub-schema in the schema.
o
1
2
3
4
5
6
BIT NUMBER
PRIVACY LOCK
,..-
-,SUB-SCHEMA NAME
-10-
Figure 7-3 SCH Sub-schema Block
BIT NUMBER indicates which bit is used in the other blocks toindicate membership in this sub-schema.
PRIVACY LOCK is the six character privacy lock, stored inSIXBIT.
SUB-SCHEMA NAME is stored in SIXBIT.
7.2.3 Record Block
The record block is a l3-word block (see Figure 7-4, and ident
ifies a record type according to its
(1) type
(2) name
(3) location
7-4

o1
2
3
4
5
6
7
8
9
10
11
12
01 I TYPE IDIIIIIIIIIIIIII CALC
TOTAL REC SIZEI DATA OFFSET IIIIIIIIIIIIILOC
f-
~
RECORD-NAME--
--
WITHIN ID~
~
SUB-SCHEMA FLAGS
Figure 7-4 SCH Record Block
Each record defined in the data base has a record block in the
SCH file, and this block serves as the basis for the in-core record
block.
TYPE is the record type code (see Section 7.1).
CALC is the number of fields on which this record is CALCed.D in bit 18 of word 0 is the duplicates allowed flag - when on,they are permitted.
TOT REC SIZE is the total line size in words for an occurrenceof this record type in the data base.
DATA OFFSET is the number of words in the line used for headerand pointers.
LOC is the same as for the in-core record block (see Section6.2.1) •
RECORD-NAME is the name of the record in SIXBIT.
WITHIN ID is the AREA-ID (if specified) in SIXBIT (see Section4.4.1) •
SUB-SCHEMA FLAGS denote for which sub-schema this record typeis defined.
7.2.4 Area Block
Each area defined for the data base has an entry in the SCH
file, and its area block comprises 15 words, (see Figure 7-5). These
blocks are used to create the area blocks in core by the DBCS.
7-5

o
1
2
3
4
5
6
7
8
9
10
11
12
13
14
02 FIRST PAGE
IIIIIII LAST PAGE
PAGE SIZE I III I SIP I IIIIIII
FILENAME
EXT I SECTOR OFFSET
l-
I-
AREA-NAME-
-
RETRIEVAL LOCK
PROTECTED UPDATE LOCK
EXCLUSIVE UPDATE LOCK
SUB-SCHEMA FLAGS
SUB-SCHEMA TEMP FLAGS
Figure 7-5 SCH Area Block
SUB-SCHEMA FLAGS are the same as for the record block.
SUB-SCHEMA TEMP FLAGS denotes for which sub-schema this area isdefined as sub-schema temporary.
For all other notes see "Area Block" in Section 6.2.1.
7.2.5 Within Block
The within block merely provides the link between a record type
and the areas within which it may be located. RECORD TYPE in this
single-word block (see Figure 7-6) is the record type code for the
record type whose WITHIN this is. The in-core within block is
written from this block.
01////////////////////// I RECORD TYPE
Figure 7-6 SCH Within Block
7-6

7.2.6 Owner Block
An owner block is written in the SCH file for each set type
defined for the schema. The block of seven words used to specify
the set is shown in Figure 7-7, and is used as the basis for the
in-core owner block.
o
1
2
3
4
5
6
04 1 CHAIN IND I PRI OFFSETI NEXT OFFSET
f-
"""""SET-NAME
~
~
SUB-SCHEMA FLAGS
Figure 7-7 SCH Owner Block
Word 0 is the same as for the in-core block (see Section 6.2.1).
SET-NAME is the name of the set in SIXBIT.
The SUB-SCHEMA FLAGS are the same as described for the recordblock.
7.2.7 Member Block
Each record that participates as a member of a set has associated
with it a member block that serves to identify it as a member of that
set. The SCH member block is three words long (Figure 7-8) and is used
to form the in-core member block. Words 0 and 1 are the same as for
the in-core block (see Section 6.2.1). TYPE R.M OWNER refers to the
record type code for the record type that is the owner of the set in
which this record is a member.
o
1
2
05 IOWNER OFFSET IPRIOR OFFSET INEXT OFFSET
FLAGS
//////////////////////1 TYPE R.M OWNER
Figure 7-8 SCH Member Block
7-7

7.2.8 Control Block
The control block appears for the same reasons as the in-core
control block - to specify SORT keys or range keys, or to specify
set selection invoking a USING clause. The control line carries the
pointers, and the block itself (see Figure 7-9) only contains the
FLAGS (same as for the in-core block) and the ALIAS NAME (see Section
4.5) in SIXBIT if it is used.
ALIAS NAME [if used]
0 06
1I-
2I-
3-
4-
5
IFLAGS I /1////////////////////
Figure 7-9 SCH Control Block
7.2.9 Data Block
An occurrence of the line for data is written for each data-item
and data-aggregate defined for the schema. This l7-word block
(Figure 7-10) is used to generate the in-core data block.
Word 0 is identical for both data blocks (see Section 6.2.1),as are words 2 and 3.
RECORD TYPE in word 4 is the record type code of the recordtype of which this data is part.
DATA-NAME is the data-name in SIXBIT.
PICTURE is the picture string for data-items in ASCII. Fordata-aggregates this is null.
SUB-SCHEMA FLAGS are the same as for the record block.
7-8

o
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
07 I111111111I FLAGS I IIIIIIIIIIIIIMODE I FL
1111111111111111111111111111111111111111111111
RECORD DESCRIPTION
1111111111111111111111 LENGTH OF FIELD
111111111111111111111 RECORD TYPE
--
DATA-NAME-I--
-
-PICTURE
-
I-
-
SUB-SCHEMA FLAGS
Figure 7-10 SCH Data Block
7.2.10 Text Block
The text block is unique to the SCrt file. The text block itself
is written for every data-aggregate specified in the schema descrip
tion. It is 22 words long, with the 21 words after the character
count being used for 105 7-bit ASCII characters to describe the data
7-9
sub-entries below the 02 level (see Section 4.4.2). Figure 7-11
illustrates the format of the text block.
o
1
2
3
4
5
6
7
8
9
10
11
12
20
21
CHARACTER COUNT
TEXT
Figure 7-11 SCH Text Block
7.3 COBOL DML PREPROCESSOR
Until such time that the COBOL DML imperatives are interfaced
with COBOL in the COBOL compiler, it will be necessary to pass pro
grams containing the COBOL DML through the COBOL DML preprocessor in
order to obtain ap executable COBOL program called LAFCOB.CBL. The
workings of the preprocessor are as follows. First, the preprocessor
scans the specified source code for any COBOL DML statements. If none
are found, it aborts the job; if these statements exist, it begins its
task of writing the COBOL program.
Next, the preprocessor checks for an INVOKE statement. When this
is found, the SCH file for the schema specified is opened and the
privacy key FOR COMPILE is compared with the privacy lock for the
7-10

sub-schema invoked. Should an invalid sub-schema-name be given, or a
key/lock match fail, no further processing is done. Otherwise, the
WORKING-STORAGE SECTION of the program is modified to include the
System Communication Locations (SCL), a register called DBMS-NULL
which is used in MACRO arguments, and those records and associated
data-items and data-aggregates that are defined as belonging to the
sub-schema invoked. Figure 7-12 shows an INVOKE statement from a
COBOL DML program, and gives the WORKING-STORAGE SECTION changes
made by the preprocessor from the information read from the Schema
Directory File.
INVOKE Statement
IDENTIFICATION DIVISION.PROGRAM- 10. STKSPL.
DATA DIVISION.WORKING-STORAGE SECTION.* DBMS
INVOKE SUPPL- INVENT OF SCHEMA JTAB01 PRIVACY KEY COMPILE JTCC01.
Resulting Code
IDENTIFICATION DIVISION.PROGRAM- ID. STKSPL.
DATA DIVISION.WORKING-STORAGE SECTION.77 AREA-NAME, PIC X(30).77 RECORD-NAME, PIC X(30).77 ERROR-STATUS, PIC 9(6).77 ERROR-SET, PIC X(30).77 ERROR-RECORD, PIC X(30).77 ERROR-AREA, PIC X(30).77 ERROR-COUNT, PIC 99, USAGE COMP.77 DB.MS- NULL PIC 99 USAGE COMP.Z1 I NVE NT OR Y- REC ORD.
02 PART-NUM PIC XeS) USAGE DISPLAY.02 PART-DESCRIP PIC X(20) USAGE DISPLAY.162 QUANTITY- ON-HND PIC 9(6) USAGE DISPLAY.02 REORDER-AT PIC 9(4) USAGE DISPLAY.02 QUANTITY-ON-ORD PIC 9(6) USAGE DISPLAY.02 QUANTITY-TD-SHP PIC 9(6) USAGE DISPLAY.02 UNIT-COST PIC 9(5) V99 USAGE DISPLAY.02 UNIT- LIST PIC 9(5) V99 USAGE D ISPLA Y.02 UNIT-RETAIL PIC 9(5) V99 USAGE DISPLAY.02 UNIT-QUANTITY PIC 9(4) USAGE DISPLAY.
{) 1 SUPPL IER- REc ORD.02 SUPPL-CODE PIC X(6) USAGE DISPLAY.02 SUPPLIER PIC X(15) USAGE DISPLAY.02 s'UPPL-A1.>DRESS PIC X(20) USAGE DISPLAY.02 SUPPL-CITY PIC X(10) USAGE DISPLAY.02 SUPPL-STATE PIC X(2) USAGE DISPLAY.02 SUPPL- ZIP PIC 9 (5) USAGE 1.> ISPLA Y.02 SUPPL-PHONE PIC 9(12) USAGE DISPLAY.
Figure 7-12 INVOKE Statement Example
7-11

In addition, a DBMS SECTION is added to the PROCEDURE DIVISION.
This section provides the arguments for a MACRO subroutine, which
will later be loaded with the COBOL program, that binds the system
parameters. This is shown for the same INVOKE statement in Figure
7-13.
PH OCEDURE 0 I VIS ION.DB MS- SEC TION.
ENTER MACRO SBIND USING "SUPPL- INVENT" ,"JTAB01" ,ERROR-COUNTENTER MACR a B I NO US I NG " I NVE NT OR Y- REC ORD", PART- NUM, PART- DESCR IP, QUA NT I TY- 0N- HNO, REORDER- AT, QUA NT ITY- ON- ORD, QUA NT ITY- To-SHP, UNIT-COST, UNIT- LIST, UNIT-RETAIL, UNIT- QUANTITY•ENTER MACRO BIND USING "SUPPLIER-RECORD", SUPPL- CODE,SUPPLIER, SUPPL- ADDRESS, SUPPL- CITY, SUPPL-STATE, SUPPL- ZIP, SUPPL- PHONE
Figure 7-13 DBMS Section Example
The remaining COBOL DML statements are translated into arguments
for the ENTER MACRO verb. The ENTER MACRO verb is used for linkage
to MACRO subroutines which are external to the resultant COBOL pro
gram. These MACRO subroutines are later loaded with the compiled
COBOL program to form a single, unified program. The COBOL DML
preprocessor during this phase does not check if the arguments given
in the COBOL DML code are valid for the sub-schema invoked - this is
done during run-time by the DBCS. However, syntax checking is/done,
as is checking for key words being used as arguments.
Three examples are given below which illustrate the conversion
of COBOL DML statements into MACRO calls.
7-12

EXAMPLE 7.1
FIND LAST STKHLD RECORD OF AREAl AREA.
The preceding code will generate:
ENTER MACRO FIND3 USING "LAST", "STKHLD", "AREAl", "AREA".
EXAMPLE 7.2
MODIFY DVQTR3.
This code will generate:
ENTER MACRO MODIFY USING "DVQTR3".
EXAMPLE 7.3
OPEN ALL USAGE MODE IS EXCLUSIVE UPDATE.
This code will generate:
ENTER MACRO OPEND USING "UPDATE", "EXCLUSIVE", DBMS-NULL,
, "ALL".
7-13

jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjJ

CHAPTER 8
RECOVERY FILES
Unlike other files, DBMS-IO mass storage files are susceptible to
damage if a terminal, system, or run-unit problem occurs while one of
these files is open for update. DBMS-lO, therefore, provides a
system of .recovery files which are used to maintain a backup to data
in the data base. This chapter describes these files and their use.
8.1 RECOVERY FILE OPERATION
Every file created or used by DBMS-IO - regardless whether it is
a mass storage (DBS) file, a schema directory (SCH) file, or a recov
ery (RCV) file - has a recovery file written for it every time it is
opened for protected update. Basically, the recovery file operates
as follows. When a file is changed by execution of theDML commands,
the page on which the change was made is written into the recovery
file created for that main file. If any problems occur during the
execution of the run-unit, the recovery file may be damaged but the
main file is unaffected. It will be necessary to run the program
again to perform the update a second time, but changes made by
previous run-units are safe in the main file and need not be restored.
Thus, data integrity is assured during update.
When a DBMS-IO file is opened, the DBCS will check for the
filename and file extension of a recovery file in the main file if
the DBCS finds a CURRENT STATUS of RECOV or UPDAT (see Section 8.2).
In the case of the latter, a single reader will have the pages from
the RCV file written into the main file. If there are other readers,
a new RCV file will be written which is a merge of the older RCV
file and any new changes made to the data in the data base. This
new RCV file would then be recovered later. When RECOV is encountered,
and there are no other readers, the main file is updated in place
from the RCV file.
If a DBS file or a SCH file has an ABORT STATUS, the data within
it is questionable and should be refreshed from the latest backup
source. The DBCS will not process an aborted file. The fourth
possibility is that the STATUS is READY, in which case the data in the
main file is in good order and is up to date.
8-1

The size of an RCV file depends on:
(1) the number of pages in the main file;
(2) the number of pages needing recovery.
For every multiple (or fractional multiple) of 128 (2008
) pages
in the main file, a 128 (200 8 ) word sector is created in the RCV
file to contain page pointers to the recovery pages. The rest of the
file (except the prefix sector described in the next section) grows
as each new page is added to the file. As each page is added, a
pointer is created for it. The recovery file is closed when the area
is closed. Thus the recovery file size can be smaller than, equal
to, or greater than the size of the file for which it was created.
During a merge of RCV files, the prefix sector of the newer file
supersedes all other prefix sectors. The old recovery pages are made
part of the new RCV file, and new pages are added as 'needed. Any
change made to a recovery page which is already in a RCV file super
sedes the older page.
8.2 PREFIX SECTOR
All DBMS-IO files have a 128 (200 8 ) 36-bit word sector preceding
all other contents which is known as the prefix sector and is part of
the file overhead. This sector serves to specify:
(1) the current status of the file;
(2) the filename and file extension of the latestrecovery file written for the file;
(3) certain access information.
A schematic of the 7-word recovery block of this prefix (or
recovery) sector is shown in Figure 8-1; a description of the block
follows.
CURRENT STATUS is a 5-character ASCII word which denotesthe present status of the file, and is used by the DBCS todetermine if recovery is needed - or even possible (see Section8.1). The four conditions are:
READY - no recovery file exists and the data in the file is good.
ABORT - for some reason the file was not closed successfully.
UPDAT - the file was aborted, in the middle of a recoveryprocedure to update the main file.
RECOV - a recovery file exists for this file and the data in thefile is processable.
8-2

o
1
2
3
4
5
6
CURRENT STATUS
RECOVERY FILENAME
EXT I /////////11///////////
A~A SEQUENCE #
NEXT AVAILABLE SECTOR
NUMBER OF READERS
FIRST RECOVERY SECTOR
Figure 8-1 Prefix Sector
RECOVERY FILENAME is the filename of the recovery file inSIXBIT. These filenames are randomly generated internally bythe DBCS as a function of time of day when needed.
EXT is the file extension for the recovery file in SIXBIT.
AREA SEQUENCE # is a binary number, and is the same as theone used by the DBCS in the in-core area block (see Section6.1.2). This number is used by the DBCS in order to assigna reader to the proper version of the data base.
NEXT AVAILABLE SECTOR is the number of the next availablesector in the recovery file in which a page can be begun(only used in a recovery file prefix sector).
NUMBER OF READERS is the number of run-units currentlyaccessing the file.
FIRST RECOVERY SECTOR is the number of the first sector inthe recovery file that is used for recovery pages (onlyused in a recovery file prefix sector).
Every time a file is opened, for whatever reason, its prefix
sector is updated. Thus, the name of the recovery file for any given
file is always the latest one available.
8-3


APPENDIX A
ERROR MESSAGES
The error messages issued by the DDL processor, the DML pre
processor, and the DBCS are listed in the following sections.
Lower case words are generic terms; the actual name or number is
given when the message is issued.
A.I DDL PROCESSOR MESSAGES
Listed below are the error messages that can be received during
the processing of the DMCL, Schema DDL, and COBOL Sub-Schema DDL
entries by the DDL processor. Those messages that are marked D
are associated with DMCL entries; those marked S with schema entries;
those marked C with sub-schema entries. Those messages marked with
E indicate messages that are output at the end of processing, and
those with A are associated with the processing of all entries. Any
message beginning with the word WARNING is a warning message and does
not affect the processing. All other messages indicate fatal errors,
and processing of the description file cannot be done. Most messages
are accompanied by the phrase
ON LINE # n
where n is the line of the description file on which the error occurs.
If the message
PROGRAM ERROR
should be received, a DDL processor error has occurred, and the
processor has aborted. The Software Specialist should be immediately
notified, as this indicates a processor failure.
S data-name UNDEF IN RECORD
A END-OF-FILE BEFORE END-SCHEMA
S ERROR - AID INVALID WITH DBKEY SORT
S ERROR - AID MUST BE FOR SORTED SET
S ERROR - AREA-ID MISSING
A ERROR - AREA-NAME MISSING
A-I

S ERROR - CANNOT BE BOTH OWNER AND MEMBER OF SET
S ERROR - CANNOT HAVE BOTH DISPLAY 6 AND DISPLAY 7
S ERROR - DATA-NAME HAS CONFLICTING MODES
DS ERROR - DEVICE-MEDIA CONTROL MISSING FOR AREA
S ERROR - DIRECT FIELD MISSING
A ERROR - DUPLICATE AREA-NAME
D ERROR - DUPLICATE CLAUSE
S ERROR - DUPLICATE DATA-NAME
SC ERROR - DUPLICATE PRIVACY LOCK
SC ERROR - DUPLICATE RECORD-NAME
D ERROR - DUPLICATE RECORDS-PER-PAGE FOUND
SC ERROR - DUPLICATE SET-NAME
C ERROR - DUPLICATE SUB-SCHEMA NAME
D ERROR - FILENAME MUST BE UNIQUE
D ERROR - FIRST PAGE MISSING
DS ERROR - INVALID AREA-NAME
S ERROR - INVALID CALC FIELD
S ERROR - INVALID DATA-NAME
D ERROR - INVALID DUPLICATE AREA-NAMES
D ERROR - INVALID FILENAME
C ERROR - INVALID NAME
D ERROR - INVALID NUMERIC VALUE
S ERROR - INVALID OR MISSING-DATA-NAME
D ERROR - INVALID PAGE RANGE
S ERROR - INVALID PICTURE CLAUSE
SC ERROR - INVALID SET-NAME
A ERROR - KEYWORD MISSING
D ERROR - LAST PAGE MISSING
S ERROR LOCATION MODE MISSING
S ERROR - MODE CLAUSE MUST PRECEDE MEMBER
S ERROR - MULTIPLE SCHEMA ENTRIES
A-2

ERROR - OWNER CLAUSE MUST PRECEDE MEMBER CLAUSE
ERROR - OWNER OF SET NOT IN SUB-SCHEMA
ERROR - PAGE SIZE TOO LARGE
ERROR - PAGES C~NNOT OVERLAP
ERROR - RECORD-NAME MISSING
ERROR - SCHEMA NAME MISSING
ERROR - SIZE CANNOT BE ZERO
ERROR - SORT FIELDS DO NOT AGREE
ERROR - TOO MANY FILES
ERROR - TOO MANY SORT FIELDS DEFINED
D ERROR - NUMERIC EXPECTED
S
C
D
D
SC
S
S
S
D
S
C ERROR - TOO MANY SUB-SCHEMAS DEFINED
SC ERROR - UNDEFINED RECORD-NAME
A ERROR - UNEXPECTED END-OF-STATEMENT
S ERROR - VIA SET set-name INVALID FOR RECORD record-name
S ERROR - WITHIN CLAUSE MISSING
S ERRORS FOR SET set-name *********
C INVALID OR MISSING RECORD-NAME
C MISSING OR INVALID PRIVACY LOCK
S MODE CLAUSE MISSING
C NO AREA DEFINED IN SUB-SCHEMA FOR RECORD
S ORDER CLAUSE MISSING
S OWNER CLAUSE MISSING
S SORT FIELD(S} MISSING
S SORT FIELDS DO NOT AGREE IN NUMBER MODE' SIZE
A WARNING - PERIOD MISSING - ASSUMED
A WARNING - UNEXPECTED PERIOD - IGNORED
E ***** n ERRORS FOUND *****
A-3

A.2 DML PREPROCESSOR MESSAGES
The error messages from the DML preprocessor are listed below.
All preprocessor errors are fatal. Except for the two messages
indicated by *, the error messages are followed by
ON LINE # n
where n is the line on which the error occurs.
ERROR - INVALID AREA-NAME
ERROR - INVALID DATA-NAME
ERROR - INVALID· RECORD-NAME
ERROR - INVALID SET-NAME
ERROR - KEYWORD EXPECTED
ERROR - UNEXPECTED END-OF-STATEMENT
* FATAL ERROR - NO PROCEDURE DIVISION FOUND
,INVALID INVOKE STATEMENT
* NO DBMS STATEMENTS FOUND
A.3 DBCS MESSAGES
The error messages from the object-time system, DBCS, are listed
below. All of these messages are fatal and denote serious failures
of DBMS-IO. The Data Base Administrator should determine the cause
for this failure, as the correction needed may be as simple as
adding more storage space for the data base. If the Data Base
Administrator cannot correct the situation which caused the error,
it should be reported immediately to the Software Specialist.
ALLOCR PAGE FAILURE
BLKERR IN GETBLK
CANNOT OPEN SCHEMA DEFINITION FILE
DYNAMIC STORAGE EXHAUSTED
FATAL ERROR IN DIRECTORY I/O
FATAL SET MUST WRITE ERROR
PAGE REQUESTED IS NOT PAGE READ
RECOVERY PAGE I-O ERROR
A-4

APPENDIX B
ERROR STATUS CONDITION CODES
The Error Status Condition codes which are made available in
the special register ERROR-STATUS are actually the combination of a
major code--designating which imperative was attempted--and a minor
code--denoting the condition which caused the failure of execution.
Thus, the contents of ERROR-STATUS would read as MMrnrn, where MM is
the major code and mm is the minor code.
The following table is a summary of the DML commands and their
associated major codes.
Table B-1
Major Error Codes
DML COMMAND MAJOR CODE
CLOSE 01DELETE 02FIND 03GET 05INSERT 07MODIFY 08OPEN 09REMOVE 11STORE 12
The minor codes representing the existing Error Status
Condition appear in this second 'table.
Table B-2
Minor Error Codes
CONDITION MINOR CODE
Area not open 01
Database key inconsistent with area-name 02
Violation of DUPLICATES NOT ALLOWED clause 05
Current of set, area, or record-name not known 06
End of set, area, or record 07
B-1
Table B-2 (Cont.)
CONDITION MINOR CODE
Referenced area, record, or set-name not insub-schema 08
Incorrect usage mode for area 09
Privacy breach attempted 10
Physical space not available 11'-
Database key not available 12
No current record of run-unit 13
Object record is mandatory automatic in named set 14
Object record is mandatory in named set 15
Record already a member of named set 16
Current record of run-unit not of record-name 20
Record not currently member of named or implied set 22
No set occurrence satisfies argument values 25
No record satisfies rse specified 26
Area already opened 28
Unqualified DELETE attempted on non-empty set 30
Removed record involved 50
Deleted record involved 51
Function requested not permitted 78
Access requested conflicts with existing access 87
No channels available 88
Area in abort status 89
Usage mode conflict 99
B-2

APPENDIX C
DBMS-IO PROCESSES
This appendix gives a brief outline of the processes involved
in using the DBMS-IO.
C.I DATA DEFINITION PROCESS
To create a data base, the following steps should be taken:
(1) Draw a schematic of the data structure to be built,deciding which record types are to be owner records,which are to be member records, which should standalone, what location mode should be used for a givenrecord, what data relationships are to be maintained,etc. Also decide which record types should be locatedin different areas~
- (2) Using the Schema DDL, write the schema description ofeach area, record type, and set type (see Chapter 4) •
(3) Decide in what files the areas are to be stored.Define the records-per-page for the schema and establish the page size and page range for each area.Suppose a data base is to be designed which willhold data on a company's inventory and its customers.Primary concern would center around inventory information and sales information. Then set up an area tohold the data essentially belonging to the former,and one for the data inherent to the latter.
(4) Define as many sub-schemas as might be necessary.
(5) Complete the description of the data base and save itas a permanent file having either no extension or theextension .DDL. This file will be passed through theDDL processor which will create the schema file.
An example of a data base description file is given in Appendix
E. Figure C-I illustrates the Data Definition Process.
To run the DDL processor, the following sequence is observed:
.R DDL
INPUT DDL FILENAME*?
C-l
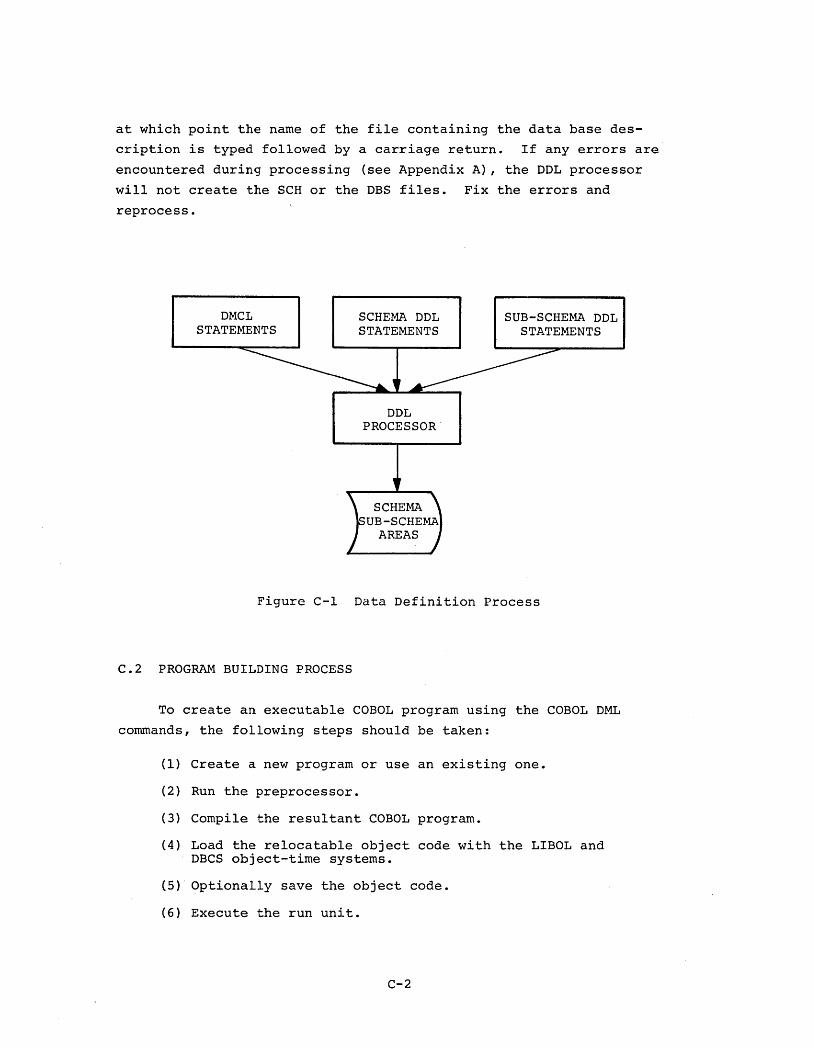
at which point the name of the file containing the data base des
cription is typed followed by a carriage return. If any errors are
encountered during processing (see Appendix A), the DDL processor
will not create the SCH or the DBS files. Fix the errors and
reprocess.
DMCLSTATEMENTS
SCHEMA DDLSTATEMENTS
SUB-SCHEMA DDLSTATEMENTS
DDLPROCESSOR'
Figure C-l Data Definition Process
C.2 PROGRAM BUILDING PROCESS
To create an executable COBOL program using the COBOL DML
commands, the following steps should be taken:
(1) Create a new program or use an existing one.
(2) Run the preprocessor.
(3) Compile the resultant COBOL program.
(4) Load the relocatable object code with the LIBOL andDBCS object-time systems.
(5) Optionally save the object code.
(6) Execute the run unit.
C-2

Figure C-2 shows this process schematically.
COBOL, DML \ SCHEMAAND INVOKE ... DML .... JSUB-SCHE~... PREPROCESSOR ~
STATEMENTS j AREAS J
•COBOL SOURCEPROGRAM WITHMACRO CALLS
•COBOLCOMPILER
•\ \~~LOCATABLE)
BJECT CODE)
•LIBOL AND DBCS .... LOADER .... EXECUTABLEROUTINES ... .. RUN-UNIT
Figure C-2 Program Building Process
The following examples show how this is done at the terminal.
EXAMPLE C.I
Running an old COBOL DML program:
.. RUN DSK: OLDFIL
EXAMPLE C.2
Creating a new program:
.R DDL
INPUT DDL FILENAME
*NEWFILE
.COMPILE LAFCOB.CBL
~LOAD LAFCOB, SYS:DBCS.REL
.EXECUTE LAFCOB
C-3

11111111111111111111111111111111111111111111111111111111111111111111I

APPENDIX D
RESERVED WORDS
In addition to the standard COBOL reserved words, the following
words are reserved in DBMS-10, along with their abbreviations enclosed
in parentheses.
-A- -E-
ACTUAL ENCODINGALIAS EXCLUSIVE (EXCL)ALLALLOWEDALTER -F-ALWAYSARE FINDAREA FIRSTAREA-CODE FIXEDAREA-ID FLOATASCENDING FORAUTOMATIC (AUTO)
-G--B-
GETBINARY (BIN)BITBY -I-
IF-C- IN
INDEXCALC INDEXEDCALL INSERTCHAIN ISCHARACTER (CHAR)CHECKCLOSE -K-COMPLEXCURRENT KEY
-D- -L-
DATABASE-KEY (DBKEY) LASTDECIMAL (DEC) LINKEDDECODING LOCATION (LOC)DELETE LOCKDESCENDING (DESC) LOCKSDIRECTDISPLAYDUPLICATES (DUP)DYNAMIC
D-l

-M-
MANDATORYMANUALMEMBERMEMBERSMODEMODIFY
-N-
NON-EXCLUSIVE (NEXCL)NOT
-0-
OCCURRENCEOCCURSOFONONLYOPENOPTIONAL (OPT)ORORDEROWNER
-P-
PICTURE (PIC)POINTER-ARRAY (PTR)PRIORPRIVACYPROCEDURE (PROC)PROTECTED (PROT)
-R-
RANGEREALRECORDRECORD-NAMEREMOVERESULTRETRIEVAL (RETR)
-S-
SCHEMASEARCHSELECTIONSELECTIVESETSORTEDSOURCESTORESYSTEM
-T-
TEMPORARY (TEMP)THRUTIMESTO
-U-
UPDATEUSAGEUSEUSING
-V-
VALUEVIAVIRTUAL
-W-
WITHIN
D-2

APPENDIX E
A SCHEMA/SUB-SCHEMA EXAMPLE
Consider a research company which is organized into departments.
Some of these departments are actively engaged in research; others
are support departments--e.g., accounting, payroll, legal, etc.
Each research department is broken up into research project groups,
although there are some special projects which overlap departments.
The research projects are supported by contracts and grants which
come from external sources--some projects receiving .funds from more
than one contract or grant. The employees of the company are
grouped according to department, project, and personnel classifica
tion. Research personnel--other than project leaders--work only at
one project at a time. There are, though, some project leaders who
administer more than one project. The example at hand, then, is to
create a data base which contains data and data relationships which
describe this activity.
The schema needed to describe the company's organization,
personnel, and associated research projects is quite simple, but is
illustrative as an example. A step-by-step approach in its
creation follows.
(1) Sub-divide the data into areas. Two areas might be usedfor this example--one which encompasses data on thecorporate organization, personnel, and employee classifications (call it PERSONNEL-AREA), and another whichhandles data on the research projects, research contracts,and contract sources (call it RESEARCH-AREA).
(2) Assign these areas to disk files. Just call the filesFILEOI and FILE02, respectively, and set the page sizeat 127 words. Let the records-per-page be 63. How manypages should be allotted to an area? The actual numberwould depend on the size of the company. For the sakeof the example, let PERSONNEL-AREA have 100 pages,and RESEARCH-AREA have 60 pages.
(3) Define record types and associated data-items and dataaggregates. The record types chosen for this examplereflect the aforementioned attributes of the company.They are
DEPARTMENT-RECORDEMPLOYEE-RECORDCLASSIFICATION-RECORDPROJECT-RECORDCONTRACT-RECORDSOURCE-RECORD
E-l
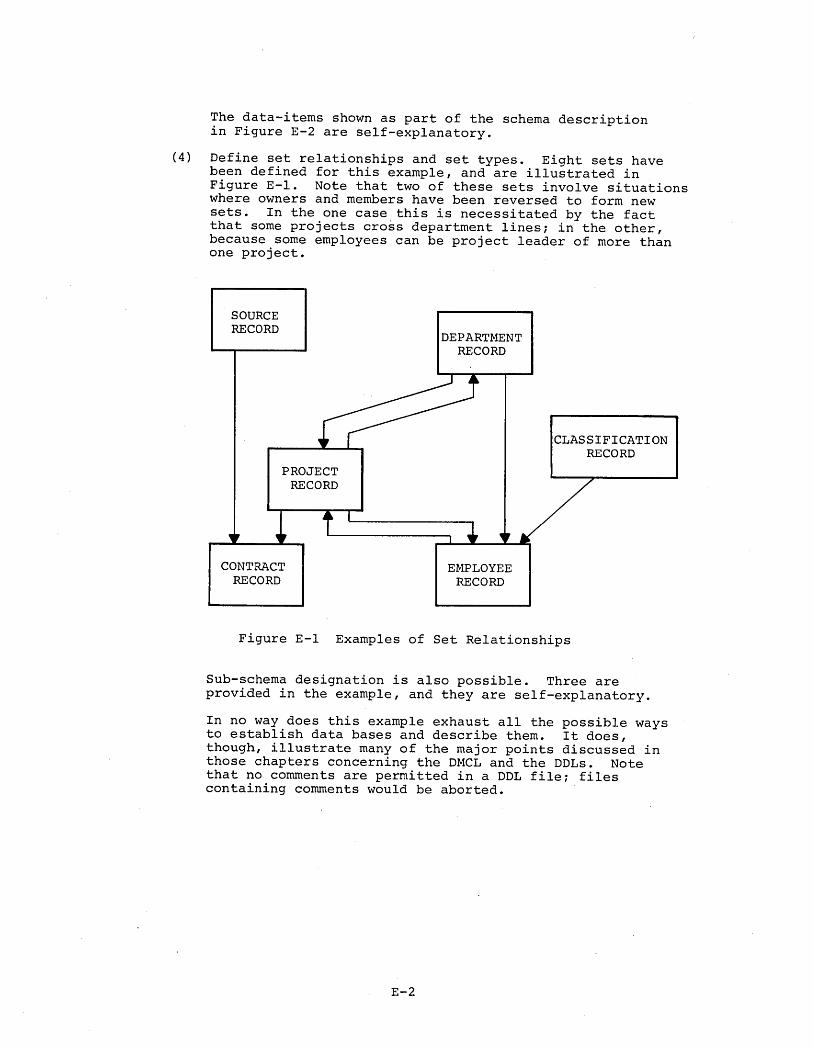
The data-items shown as part of the schema descriptionin Figure E-2 are self-explanatory.
(4) Define set relationships and set types. Eight sets havebeen defined for this example, and are illustrated inFigure E-I. Note that two of these sets involve situationswhere owners and members have been reversed to form newsets. In the one case this is necessitated by the factthat some projects cross department lines; in the other,because some employees can be project leader of more thanone project •
. SOURCERECORD DEPARTMENT
RECORD
CLASSIFICATIONRECORD
PROJECTRECORD
CONTRACTRECORD
EMPLOYEERECORD
Figure E-I Examples of Set Relationships
Sub-schema designation is also possible. Three areprovided in the example, and they are self-explanatory.
In no way does this example exhaust all the possible waysto establish data bases and describe them. It does,though, illustrate many of the major points discussed inthose chapters concerning the DMCL and the DDLs. Notethat no comments are permitted in a DDL file; filescontaining comments would be aborted.
E-2

RECORDS-PER-PAGE 63.ASSIGN PERSONNEL-AREA TO FILE01FI RST PAGE IS 1LAST PAGE IS 100PAGE SIZE IS 127 WORDS.
ASSIGN RESEARCH-AREA TO FILE02FIRST PAGE IS 300LAST PAGE IS 359PAGE SIZE IS 127 WORDS.
SCHEMA NA ME IS SCHEX.
AREA NAME IS PERSONNEL-AREAPRIVACY EXCLUSIVE UPDATE IS PREXUPPRIVACY PROTECTED UPDATE IS PRPTUPPRIVACY RETRIEVAL IS PRRTLK.
AR EA NA ME IS RESEAR CH- AREAPRIVACY LOCK RSCHLK.
RECORD NAME IS DEPARTMENT-RECORDLOCATION MODE IS DIRECT DPTKEYWITHIN PERSONNEL-AREA.
02 DEPARTMENT PIC X(20).
RECORD NAME IS EMPLOYEE-RECORDLOCATION MODE VIA CLASS-SETWITHIN PERSONNEL-AREA.
02'32020202020202
EMPLOYEEHOME- ADDRESSHOME- PHO NESS- NUMBERMARITAL-STATUSHIREDDEPENDENTSBASE- SALARY
PIC X(25).PIC X(40).PIC9(HD.PIC 9(9).PIC X.PIC 9(8).PI C 99.PIC 9(5) V99.
RECORD NAME IS CLASSIFICATION-RECORDLOCATION MODE IS CALC USING CLASSIFICATIONDUPLICATES ARE NOT ALLOWEDWITHIN PERSONNEL-AREA.
02 CLASSIFICATION PIC X(15).~2 LEVEL PIC 99.
Figure E-2 Schema/Sub-schema Examples
E-3

RECORD NAME IS PROJECT-RECORDLOCATION MODE CALC USING PROJECT-IDDUPLICATES ARE NOT ALLOWEDWITHIN RESEARCH-AREA.
02 PRO JECT- I D PIC 99 V3 999 •02 PROJECT-TITLE PIC X(30).
RECORD NAME IS CONTRACT-RECORDLOCATION MODE VIA FUNDS-SETINI TH IN RES EARCH- AR EA.
~2 CONTRACT- NUMBER PIC 9(7).02 CONTRACT-DATE PIC 9(10).02 COMPLETION-DATE PIC 9(10).02 I NIT IAL- AM 0UNT PIC 9( 7) ~ 9•02 BALANCE PIC 9(7) ~9.
RECORD NAME IS SOURCE-RECORDLOCATION DIRECT SRCKEYWITHIN RESEARCH-AREA.
02 SOURCE- NAME PIC X(25) •02 SOURCE-ADDRESS PIC X(40).02 SOURCE-PHONE PIC 9( 10).02 SOURCE-CONTACT PIC X(25).02 SOURCE-TITLE PIC X(lliD.
SET NAME IS DEPT- SETMODE IS CHAIN LINKED TO PRIORODER IS SORTED DUPLICATES NOT ALLOWEDOWNER IS DEPARTMENT-RECORDMEMBER IS EMPLOYEE-RECORD OPTIONAL M\NUAL LINKED TO OWt-JER
ASCENDING KEY IS SS-NUMBER.SELECTON CURRENT.
SET NAME IS CLASS-SETMODE IS CHAIN LINKED TO PRIORORDER IS SORTEDOWNER IS CLASSIFICATION-RECORDMEMBER IS EMPLOYEE-RECORD OPTIONAL MANUAL LINKED TO OWNER
ASCENDING KEY IS BASE-SALARYSELECTION CURRENT.
SET NAME IS PROJECT-SETMODE IS CHAIN LINKED TO PRIORORDER IS ALWAYS LASTOWNER IS PROJECT-RECORDMEMBER IS EMPLOYEE-RECORD OPTIONAL ;'t'1ANUAL LINKED TO O\·JNERSET SELECTION IS CURRENT.
Figure E-2 (cant) Schema/Sub-schema Example
E-4

SET NAME IS PROJLDR-SETMODE IS CHAIN LINKED TO PRIDRORDER IS ALWAYS NEXTOWNER IS EMPLOYEE-RECORDMEMBER IS PROJECT-RECORD OPTIONAL MANUAL LINKED TO OWNERSET SELECTION CURRENT.
SET NAME IS DEPT-PROJ-SET _MODE IS CHAIN LINKED TO PRIORORDER IS SORTEDOWNER IS DEPARTMENT-RECORDMEMBER IS PROJECT-RECORD MAND AUTO LINKED TO OWNER
ASCENDING KEY IS PROJECT-IDSELECTION CURRENT.
SET NAME IS SPECIAL-PROJ-SETMODE IS CHAIN LINKED TO PRIOROR DER IS SORTEDOWNER IS PROJECT-RECORDMEMBER IS DEPARTMENT-RECORD OPTIONAL MANUAL LINKED TO OWNERSET SELECTION IS CURRENT.
SET NA ME IS FU NDS- SE TMODE IS CHAIN LINKED TO PRIORORDER IS ALWAYS LASTOWN~R IS PROJECT-RECORDMEMBER IS CONTR.4CT-RECORD i'14ND AUTO LINKED TO OWNERSELECTION IS CURRENT.
SET ~J.AME IS SOURCE- SETMODE IS CHAIN LINKED TO ?RIORORDER IS ALWAYS LASTOWNER IS SOURCE-RECORDMEMBER IS CONTRACT-RECORD MAND AUTO LINKED TO OWNERSELEC TION CU RRENT.
SUB-SCHEMA NAME IS FUNDINGPRIVACY LOCK IS DNUF.
AREA SECTION.COpy RESEARCH-AREA.
SECTION.SOURCE-RECORD.CONTRACT-RECORD.PROJECT-RECORD.
SECTION.COPY SOURCE- SET, FUNDS- SET.
RECORD0101~1
SET
Figure E-2 (cent) Schema/Sub-schema Example
E-5

SUB-SCHEMA IS DEPT-PROJPRIVACY LOCK IS DEPROJ.
AREA SECTION.COpy TEMPORARY PERSONNEL-AREA, RESEARCH-AREA.
RECORD- SEC TI ON.01 DEPARTMENT-RECORD.01 PROJECT-RECORD'01 CONTRACT-RECORD.SET SECTION.
COpy DEPT-PROJ-SET, SPECIAL-PROJ-SET, FUNDS-SET.
SUB-SCHEMA NAME TOTAL PRIVACY ETHING.AREA SECTION.
COpy ALL AREAS.RECORD SEC TI ON.01 DEPARTMENT-RECORD.01 EMPLOYEE-RECORD.01 CLA SSIr I CAT I 0N- RECOR D•01 PROJECT-RECORD.01 CONTRACT-RECORD.01 SOURCE-RECORD.SET SECTION.
COpy ALL SETS.
END- SCHEMA.
Figure E-2 (cant) Schema/Sub-schema Example
E-6

Aceess,Data, 6-6
Aceess1no a record, 1-13Ac:eelllnQ data 1n a data
base, 1-5Allocating storage space,
1-2, 3-1Area, 1-3
Temporary, 4.2Area block, 6-10, 7.SAREA Clause, 4-2Area entry, 3-1, 4-1, 4--2Area entry,
OMC~, 3-3AREA SECTION Clause, 5-2Areal,
Assioning, 3-1Seleetlnq, 3-1
ASCE~DJNG/DESCENDINGKEYClaule, 4-6
ASSIGN Clause, 3-3Ass1qning areas, 3-1Assigning database key, 1.6AUTOMATIC Set memberShip,
1-19
BlOCk,Area, 6-10, 7-5Control, 6-12, 7-8Data, 6-15, 7-8Member, 6--14, 7-7Owner, 6-12, 7-7Reeord, 6-9, 7-4SCH File Word, 7-3Schema, 7-3SUb-schema, 6-8, 7-4Telt, 7-9W.ithin, 6-12, 7-6
CALC Loeat1on mode, 1-12,4-3
Storing by, 6-18CHAIN Set mode, 1-20Characteristies of sets,
1-16Clause,
AREA, 4-2ARF.A SECTION, 5-2ASCENDING/DESCENDING KEY,
4-6ASSIGN, 3.3DUPLICATES, 4-3, 4-6FIRST PAGE, 3-3LAST PAGE, 3-3LINKED TO OWNE~, 4-6LOCATION MODE, 4-3MEr~BER, 4-6MODE, 4-6OROE~, 4-6
INDEX
OWNER, 4-6PAGE SIZE, 3-3PRIVACY LOCK, 4-2RECORD, 4-3RECORD SECTION, 5--2RECORDS-PER-PAGE, 3.3SCHEMA, 4-1SET, 4-6SET SECTION, 5-3SET SELECTION, 4-7SUa-SCHEMA, S-lWITHIN, 4-3
Codes,Error status condition,
B-1Major error, a-1Minor error, B-1
Control block, 6--12, 7-8Currency statuI indicators,
1.7
Data access, 6-6Data agqreqate, 1-3Data availability,
Establishing, 2-1Data base, 1-1
AceesslnQ data 1n a, 1-5Deseribinq a, 1-3, 4-1nescribing portions of a,
.1-3Documenting tne,2-6OrQanizinq the, 2-2ProtectinQ the, 2.4~ubdivldinq a, 1-4
Data base access, 2~4
Data base administrator,1-1
Data base administrator,Responsibility of, 2-1
Data Base Control System,1-5
Data base directory, 2-7Data base 1nteqritv, 2-5Data base man1pulation, 2-4Data base map,
In.core, 6-6Data base representation,
In·core, 6·8Data base test1ng, 2-9Data base use,
Procedures for, 2.7Data blOCk, 6-15, 7.8Data d~f1nit~on ~roeess,
C-1Data description language,
Schema, 4-1SUb-schema, 5-1
Data in a data base,Accessing, 1-5
INDEX-l

Data integrity, 1-11Data item, 1-3Data manipulatIon language,
1-5Data organization, 6-1Data privacy, 1-10Data protection, 1... 10Data structures, 1.16Data sUb-entry, 4-5Database Key, 1-6
AsslQnlng, 1"6Formlnc; a, 6-6Permanence of, 1-6
DBCS, 1-5OBCS Messages, A-4DBMS Performance
measurement, 2.eDBMS section, 7"'12DBMS Usage measurement, 2-8DBMS-l0 features, 1-1DBMS-l0 lanquaqe, 1-2DBMS-l0 object-time modUle,
1-5DBMS-10 operational
architecture, 1-5DBMS-10 processes, C-lDBS File, 6-1DBS File Identification,
6-2DOL,
Schema, 1-3, 4-1Sub-schema, 1-3, 5.1
DOL Processor Messages, A-IDescribing a data base, 1-3,
4-1Describing portions Of a
data base, 1-3DeVice independence, 1-9DeVice media control
lanquage, 1-2, 3-1DIRECT Location mode, 1-12,
4.3Storln~ by, 6-18
OMCL, 1-2, 3-1DMCL Area entry, 3-3DMCL Record entry, 3-3DML, 1--5DML preprocessor, 7.10DML Preprocessor MeSSages,
A-4Doeumentin9 the data hase,
2-6DUPLICATES Clause, 4-3, 4-6
Error codes,Hajor, B-1Minor, B--l
Error. messages, A~l
Error status conditioncodes, a-l
Error status indicator.,1-'
Estab11shino ~ataavailability, 2-1
Example,Schema/sub-schema, E-l
Exclusive update, 1-11
F1le,DBS, 6-1RCV, e-1Recovery, B",lseH, 7-1Schema direetory, '-1
File overhead, 6-21FIND algorithms, 6-19FIRST PAGE Clause, 3-3Format,
Line, 6~5
Paqe header, 6-3Forming a database Key, 6.6
Header,Page, 6-2
Host language, 1-2
1/0 buffering schema, 6-16Identification,
DBS File, 6-2Line, 6.5Page, 6.2SUb-schema, 5-1
In·core data base maP, 6-6In-core data base
representatIon, 6-8In-core Dage/buffer table,
61:116Integrity,
Data base, 2-5Integrity of data, 1-11TNVOKE statement, '-11
Language,Data man1pulatlo~, 1.5Pevice media contrOl, 1-2,
3"'1Schema data descriPtion,
1.. 3, 4-1SUD. schema data
description, 1-3, 5-1Language rp.lationshiPs, 1-5LAST PAGE Clause, 3-3Line, 3-2, 6-1Line format, ~.5
Line identification, 6.5LINKED TO OWNER Clause, 4-6Location mode, 1-12
CAIJC, 1.12, 4- 3DI~ECT, 1-12, 4.35tor1nQ by CALC, 6-18
INDEX-2

Storin9 by DIRECT, 6~18
Stor1n~ by VIA, 6-19VIA, 1"12, 4-3
LOCATION MODE Clause, 4-3
Malntalninq setrelatlonshl~s, lM22
Major concepts, 1-1Major error codes, B-1MANDATORY Set membership,
1-19MANUAL Set membership, 1-19Map,
In-core data base, 6-6Member bloCK, 6-14, 7.7MEMBER Clause, 4-6Messages,
DBCS, A-4DOL· Processor, A-lDML Pre~rocessor, A.4
Minor error codes, a-lMODE Clause, 4-6
Network structures, 1-16NEXT PoInters, 1-21
OPTIONAL Set me~bersh1p,
1-20ORDER Clause, 4-6Orderlnq of set~, 1-17Organizing the data base,
2-2Overhead~
File, 6-21Paqe, 6-21Record, 6-20
Owner block, 6-12, 7-7OWNER Clause, 4-6OWN e: R Pol nt er s, t - 22
Page, 3·2, 6-1Paqe header, 6-2Page header format, 6-3Paqe identification, 6-2Page overhead, 6-21Paqe size, 3-2PAGE SIZE Clause, 3~3
Page""ln, 3-2Page-out, 3-2Page/buffer size, 3-3Page/buffer table,
In-core, 6-16Performance measurement,
DBMS, 2-8Permanence of database key,
1-6Placement control, 1·9J?ointers, 1",20
NEXT, 1""21OWNER, 1.. 22
PRIOR, 1-22Prefix sector, 8-2preprocessor,
DML, 7.10PRIOR Pointers, 1-22Privacy key, 1-10, 2-7Privacy lOCK, 1-10, 2-7PRIVACY LOCK Clause, 4.2Privacy of data, 1~10
Prncedures,Recovery, 2-9Restart, 2-9Save, 2-9
Procedures tor data baseuse, 211117
Program buIldIng process,C·2
Protected update, 1~11
Protecting the data base,2-4
Protection of data, 1-10
ReV P'ile, e-lRecord, 1-3
AccessinQ a, 1-13Record bloCk, 6-9, 7-4RECORD Clause, 4-3Record entry, 3-1, 4"'1, 4-3Record entry,
DMCL, 3-3Re~ord identifier, 1-6Record occurrence, 1-3,
1-12Record overhead, 6-20RECORD SECTION Clause, 5-2Record selection
expressions, 1-14Record SUb-entry, 4~3
Record ty"e, 1 "'3RECORDS.PER-PAGE Clause,
3-3Recovery tile, e-1Recovery file operation,
, R-1Recovery procedures, 2-9Representation,
Schema directory, 7-2Reserved words, 0-1Responsib1lity of data base
administrator, 2-1Restart procedures, 2-9Run-unit, 1·7
Save procedures, 2.9Save/recovery/restart, 2-5SCt: File, 7.'SCH File W~rd BloCk, '.3Schema, '-4Schem.a bloCK, '-3SCHEMA Clause, 4-1
INDEX-3

Schema data descriptionlanQuage, 1-3, 4-1
Schema DOL, 1-3, 4~1
Schema directory file, 7-1Schema directory
representation, 7-2Schema entry, 4-1Schema/sub-schema
differences, 1-eSchema/sub-schema exam~le,
E-lSelectinq areaS, 3-1Sequential structures, 1-16Set, 1.3, 1.16Set Characteristics, 1-16SET Clause, 4-6Set entry, 4-1, 4-6Set membership, 1-19
'AUTOMATIC, 1-19MANDATORY, 1-19MANUAL, 1-19OPTIONAL, 1-20
Set mode, 1-20CHAIN, 1"20
Set occurrence, 1-3Set occurrence selection,
1-13Set orderinq, 1"'17Set relationShips,
MaintalnlnQ, 1-22SET SECTION Clause, 5.3SET SELECTION Clause, 4.'Set type, 1-3Standards, 2.7statement,
INVOKE, '-11StopplnQ violation of rUles,
2-6Storaoe space,
Allocating, 1·2, 3-1STORE algorithms, 6-18Storlna by CALC Location
mode, 6-18Storina by DIRECT Location
mode, 6-18Storlna by VIA Location
mode, 6-'19
Strueturel,Data, 1-16Networ~, 1-16Sequential, 1-16Tree, 1-16
Sub-schema, 1-4Sub-schema blOCk, 6-8, 7-4Sua-SCHEMA Clause, 5-1Sub-schema data descriPtion
lanquaQe, 1-3, 5.. 1Sub-schema DOL, 1-3, 5-1Sub-schema identification,
5-1Subdividing a data base,
1",4System com~unicat1on
locations, 1-7
Temporary area, 4-2Test blOCk, '-9Testlna,
Data base, 2-9TralninQ techniques, 2-9Tree structures, 1.16
Understand1nQ userrequirements, 2-1
Uni~ue record identifier,1-6
Update,Exclusive, 1-11Protected, 1-11
Usage measurement,DBMS, 'i.-e
Usage-mode, ~ .. 2User identification, 2~'
User requirements,Understanding, 2-1
User working area, 1-6UWA, 1"6
VIA Location mode, 1-12,4~]
Storlnq by, 6-19Vlnlfttlon of rUles,
Stopping, 2-6
Within bloCk, 6-12, 7.. 6WITHIN Clause, 4-3
INDEX-4

DECsystem-lOData Base Management System (DBMS-lO)
Data Base Administrator's Procedures ManualDEC-lO-AAPMA-A-D
READER'S COMMENTS
NOTE: This form is for document comments only. Problemswith software should be reported on a SoftwareProblem Repcrt (SPR) form (see the HOW TO OBTAINSOFTWARE INFO~mTION page) .
Did you find errors in this manual? If so, specify by page.
Did you find this manual understandable, usable, and well-organized?Please make suggestions for improvement.
Is there sufficient documentation on associated system programsrequired for use of the software described in this manual? If not,what material is missing and where should it be placed?
Please indicate the type of user/reader that you most nearly represent.
o Assembly language programmer
[] Higher-level language programmer
[] Occasional programmer (experienced)
o User with little programming experience
o Student programmer
o Non-programmer interested in computer concepts and capabilities
Name Date _
Organization _
Street _
City State Zip Code _or
Country
If you do not require a written reply, please check here. 0

.------------------------------------------------------------Fold lIere------------------------------------------------------------
.------------------------------------------------ Do Not Tear - Fold lIere and Staple -----------------------------------------------
FIRST CLASS
PERMIT NO. 33
MAYNARD, MASS.
BUSINESS REPLY MAILNO POSTAGE STAMP NECESSARY IF MAILED IN THE UNITED STATES
Postage will be paid by:
Software CommunicationsP. O. Box FMaynard, Massachusetts 01754

j
jjjjI
{jII
jj
{jjjjjI
J
IJIj{lJjJj
{jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjJ

DIGITAL EQUIPMENT CORPORATION, Maynard, Massachusetts, Telephone: (617) 897-5111 • ARIZONA, Phoenix • CALIFORNIA,Sunnyvale, Santa Ana, Los Angeles, Oakland, San Diego and San Francisco (Mountain View) • COLORADO, Denver. CONNECTICUT,Meriden • DISTRICT OF COLUMBIA, Washington (Riverdale, Md.) • FLORIDA, Orlando • GEORGIA, Atlanta • ILLINOIS, Chicago• INDIANA, Indianapolis • LOUISIANA, New Orleans • MASSACHUSETTS, Cambridge and Waltham • MICHIGAN, Ann Arbor andDetroit (Southfield) • MINNESOTA, Minneapolis • MISSOURI, St. Louis • NEW JERSEY, Englewood, Metuchen, Parsippanyand Princeton • NEW MEXICO, Albuquerque • NEW YORK, centereach (L1.), Manhattan, Syracuse and Rochester • NORTHCAROLINA, Durham/Chapel Hill • OHIO, Cleveland and Dayton • OKLAHOMA, Tulsa • OREGON, Portland • PENNSYLVANIA,Philadelphia and Pittsburgh • TENNESSEE, Knoxville • TEXAS, Dallas and Houston • UTAH, Salt Lake City • WASHINGTON,Seattle • WISCONSIN, Milwaukee • ARGENTINA, Buenos Aires • AUSTRALIA, Adelaide, Brisbane, Melbourne, Perth and Sydney• AUSTRIA, Vienna • BELGIUM, Brussels • BRAZIL, Rio de Janeiro, Sao Paulo and Porto Alegre • CANADA, Calgary, Alberta;Vancouver, British Columbia; Ottawa and Toronto, Ontario; and Montreal, Quebec • CHILE, Santiago • DENMARK, Copenhagen• FINLAND, Helsinki. FRANCE, Grenoble and Paris. GERMANY, CoI~gne, Hannover, Frankfurt, Munich and Stuttgart. INDIA, Bombay.ITALY, Milan • JAPAN, Tokyo • MEXICO, Mexico City • NETHERLANDS, The Hague • NEW ZEALAND, Auckland • NORWAY, Oslo •PHILIPPINES, Manila • PUERTO RICO, Miramar • SPAIN, Barcelona and Madrid • SWEDEN, Stockholm • SWITZERLAND,Geneva and Zurich • UNITED KINGDOM, Birmingham, Edinburgh, London, Manchester and Reading • VENEZUELA, Caracas