data analysis : traditional and spark
TRANSCRIPT

Subject :
Friday, 20 December 2017
University Sidi Mohammed Ben Abdellah
Faculty of Sciences Dhar El Mehraz
PhD Student : Big data and Machine Learning for finance.
LIM Laboratory
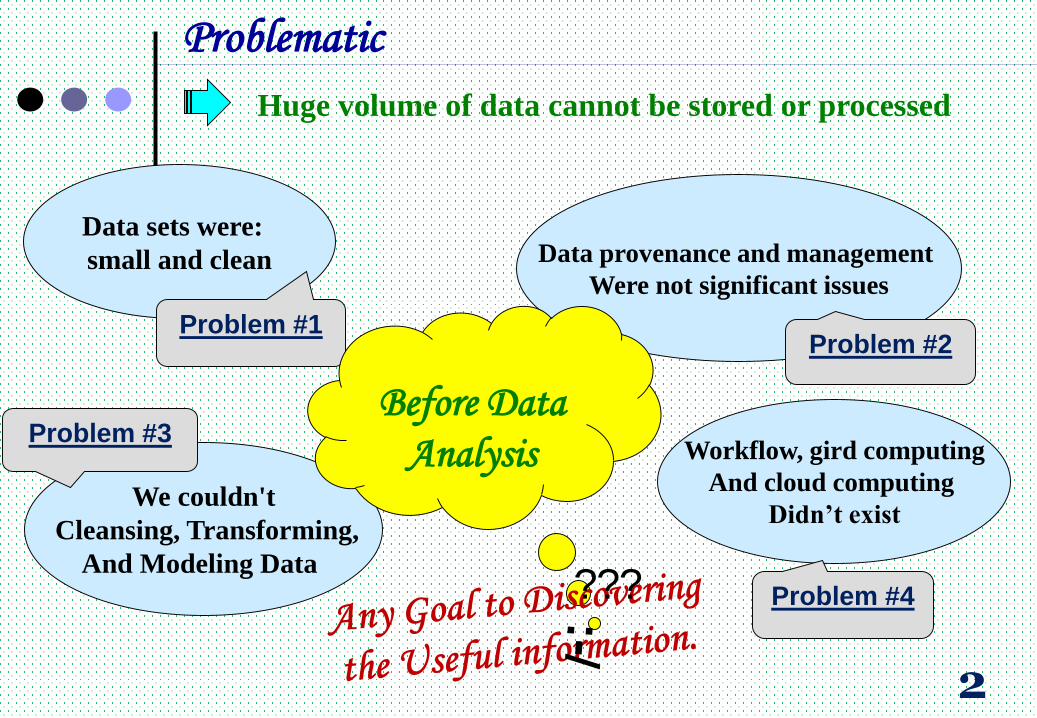
Problematic
Data provenance and management
Were not significant issues
We couldn't
Cleansing, Transforming,
And Modeling Data
Data sets were:
small and clean
Problem #3
Problem #1Problem #2
Before Data
Analysis
???
2
Huge volume of data cannot be stored or processed
Workflow, gird computing
And cloud computing
Didn’t exist
Problem #4

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
3Conclusion

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
4Conclusion

Motivation
5
Collect and manage large volumes of varying data
Make sense of that data and turn that insight into actions
Processing and transforming high volume of data and
mining them .
Getting meaningful information out of the huge amount
of data.
We need to :

Motivation
Explain the past Exploring data :
Univariate : Convert, Transform, Encoding between them
Bivariate : Analyze , compare between categorical an numerical
6
In Order to predict the future, we need to explore the past:
Predict the futureModeling data :
Classification, Regression, Clustering, Association rules…
That means that we can:
Suggest conclusion, Support decision-making, Knowledge
discovery for predictive and descriptive purposes.
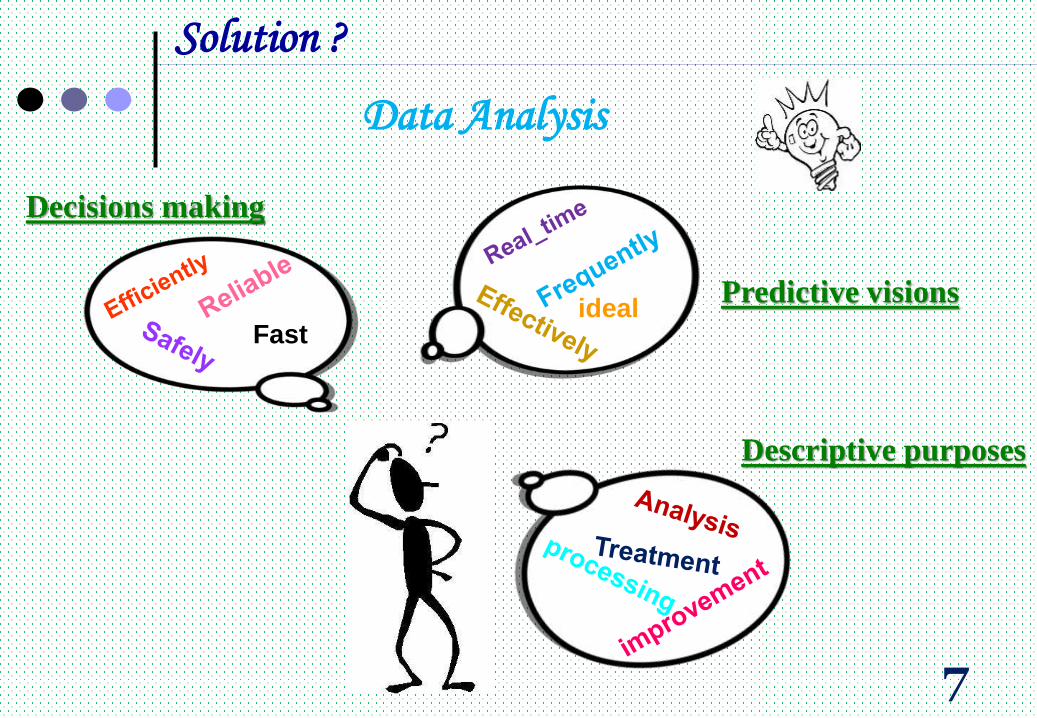
Solution ?
Data Analysis
Fast
Decisions making
7
Predictive visionsideal
Descriptive purposes

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
8Conclusion

Data Analysis ,that is to say?
To make some type of sense out of each data collection
To look for patterns and relationships both within a
collection, and also across collections.
To make general discoveries about the phenomena we are
researching.
9
Data analysis is a method in which data is collected and
organized so that one can derive helpful information from it.
In other words, the main purpose of data analysis is to look
at what the data is trying to tell us

Data Analysis mission
10
The mission of Data Analysis is to help analysts to answer
different question :
• What Happened?
Descriptive
• Why did it happen?
Diagnostic
• What will happen ?
Predictive
• How can we make it happen ?
Perspective
Insight
Hindsight Foresight

The Data Analysis Goal !!
11
Reference : SupInfo_Introduction Of BI

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
12Conclusion

Motivation
13

What is Apache Hadoop ?
14
Hadoop is an open-source software framework for storing
data and running applications on clusters of commodity
hardware.
It provides massive storage for any kind of data, enormous
processing power and the ability to handle virtually limitless
concurrent tasks or jobs.

History
15
2003/2004: Introducing Google File System and MapReduce
Created by Doug Cutting and Mike Carafella in 2005.
Cutting named the program after his son’s toy elephant.

Uses Of Hadoop
16
Data-intensive text processing
Assembly of large genomes
Graph mining
Machine learning and data mining
Data analysis

Who uses Hadoop ?
17

The Hadoop Ecosystem :
18
• Contains Libraries and other modules
Hadoop Common
• Hadoop Distributed File SystemHDFS
• Yet Another Resource NegotiatorHadoop YARN
• A programming model for large scale data processing
Hadoop MapReduce

Hadoop Distributed File System
19
Responsible for storing data on the cluster
Data files are split into blocks and distributed across the nodes
in the cluster
Each block is replicated multiple times
Overview:

HDFS Basic Concepts
20
Built to expect hardware failures
Built around the idea that the most efficient data processing
pattern is a write-once, read-many-times pattern
An HDFS cluster has two types of nodes:
namenode (the master)
datanodes (workers)

HDFS Basic Concepts (2)
21
Written in Java based on the Google’s GFS
Provides redundant storage for massive amounts of data
Works best with smaller number of large files

Data Retrieval
22
When a client wants to retrieve data
Communicates with the NameNode to determine which
blocks make up a file and on which data nodes those
blocks are stored
Then communicated directly with the data nodes to read
the data

Interaction between HDFS components:
23

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
24Conclusion

MapReduce Overview :
25
Programming paradigms
Designed to solve one problem
Consists of two part
Map
Reduce

The Mapper :
26
Execute the map fonction on data.
Executed on each node where the data lives.
Output <key, value> pairs on each node.

The Reducer :
27
Execute the reduce fonction on data.
Gets a list of all values associated with a key as input
The reducer outputs zero or more final key/value pairs
o Usually just one output per input key

Mapreduce : WordCount
28

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
29Conclusion

Apache Spark :
What is Apache Spark ?
A fast and general engine for large-scale data processing.
An open source lightning-fast cluster computing technology.
Does real-time data processing with huge data.
Originally developed at the university of California, Berkeley's
AMP Lab.
30

Features of Apache Spark :
Spark solves general purpose cluster computing systems (Real time data
and Batch Processing).
Spark runs up to 100 times faster than Hadoop MapReduce in memory
or 10 time faster on disk.
Speed :
31

Features of Apache Spark :
Write applications quickly in Java, Scala, Python, R.
Spark has easy-to-use APIs for operating on large datasets
Ease of use :
32

Features of Apache Spark :
Spark combine and support:
SQL, Streaming, and Complex analytics.
A Unified Engine :
33

Features of Apache Spark :
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can
access diverse data sources including HDFS, Cassandra, HBase,
and S3.
Runs Everywhere :
34

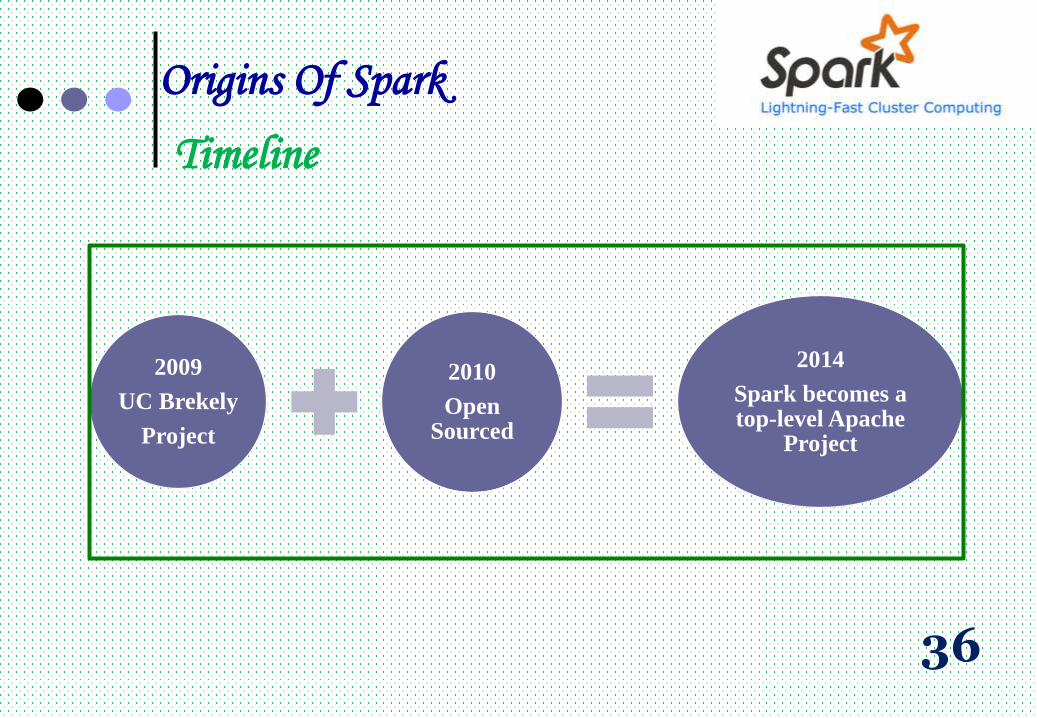
Origins Of Spark
Timeline
35
2003
Nutchproject begins
development.
2006
Yahoo hires Nutch
developers and releases
Hadoop
2008
Data processing
options
Origins Of Spark
Timeline
36
2009
UC Brekely
Project
2010
Open Sourced
2014
Spark becomes a top-level Apache
Project

Apache Spark Components :
37
Spark Core Engine :
Foundational component
Task distribution
Scheduling
Input / Output
That underline general execution engine, reference datasets
in external storage.

Apache Spark Components :
Spark SQL :
Data Frames
38
Spark Streaming :
Streaming analytics
Micro batches
Lambda architecture
That introduce a new data abstraction called Schema RDD.

Apache Spark Components :
MLlib
Machine Learning
39
GraphX
Graph processing
Based on RDDs
SparkR
R package for Spark
Distributed Data Frames.

Apache Spark Architecture :
40is like a master
is like threads
or nodes
Spark Context :
Have all data
which we store.
The Driver
Instructs the workers
To execute some tasks.

Spark abstraction :
41
RDD : Resilient Distributed Datasets.
Data Frames/Datasets.
DStreams.

Resilient Distributed Datasets : RDD
Transformations are generated as Directed Acyclic
Graph(DAG).
DAG can be recomputed during failure.
Transformations are : map, filter, flatMap, textFile,… .

43Loading Data
From diff sources
Reduce,
Classification of
Transformed data
Any type of data source
Streaming data
HDFS file
Any database …
Transformations are :
Map, filter.
Lifecycle in Spark
For real-time
analysis
Future research
analysis

Load data on Cluster.
Create RDD, do Transformations
Perform actions, create Data frame.
Perform Queries on Data Frame .
Run SQL on Data Frame.
Lifecycle in Spark (2)

45
Areas Spark Shines :

Languages statistics
46

Products statistics
47

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
48Conclusion

Implementation
49
What we will need:
HORTONWORKS Sandbox (HDP Sandbox, a single node virtual machine, makes it
easy to handle Apache Hadoop, Apache Spark, Apache Hive, Apache HBase and many
other Apache data projects).
• Python .
• PIP: Utility for installing python packages
• yum install pip
• MRJob
• pip install mrjob
• Apache Spark (it included in VM sandbox)
• Dataset.

Implementation
50
Hadoop application

Implementation
51
To better understand how MapReduce Work we will illustrate
with an example :
How many movies did each user rate in the Movie Lens data
set?

Make it a MapReduce Problem :
52
MAP each input line to (user, 1)
Reduce each user with the sum of all the 1’s

Putting it all together
53

Execution:

Implementation
55
Spark application

Using MLlib in Spark :
56
ALS algorithm :
ALS recommendation algorithm takes as input user preferences by
item and generates an output of recommending items for a user.
100k line dataset containing real information about movie
ratings.
Adding a User to test with.

Putting it all together
57

We add a new user in our data set with id == 0 for our running test :

Explanation :

Execution:

Outline
MapReduce
Data Analysis
Motivation
Hadoop
Spark
Implementation
61Conclusion

In any big data discussion, you end up talking about Hadoop or
Apache Spark.
While both tools are sometimes considered competitors, it is
often accepted that they work even better when they are
together.
62
ConclusionHadoop VS Spark

Here is an overview of their characteristics and their
differences:
They do different things,
You can use one without the other,
Spark is speedier,
You may not need Spark's speed,
Failure recovery: different, but still good.
63
ConclusionHadoop VS Spark

64
Conclusion
Collecting data from different sources
Transforming them if necessary
Aggregating them in order
Restore them in a visual way
So Data Analysis = Turning Data into Profits.

Apache Hadoop :
http://hadoop.apache.org/ [13,,…,8] Last updated : [11/01/2011].
Apache Spark :
https://spark.apache.org/ [13,…,24] Last visited : [02/11/2017].
MapReduce Tutorial :
https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
[25,…,28] Last visited : [02/11/2017].
Others :
Lynda, Udemy, TutorialPoint, OppenClassrooms, etc.
65
References

Thank You For Your
Attention Questions ?
Comments ?