cyber-physical systems research*
DESCRIPTION
Cyber-Physical Systems Research*. CSE 591 Guest Lecture September 10, 2012. Chris Gill Professor of Computer Science and Engineering Washington University, St. Louis, MO, USA [email protected]. - PowerPoint PPT PresentationTRANSCRIPT

Cyber-Physical Systems Research*
Chris GillProfessor of Computer Science and EngineeringWashington University, St. Louis, MO, USA
CSE 591 Guest LectureSeptember 10, 2012
*Research supported in part by NSF grants CNS-0716764 (Cybertrust) and CCF-0448562 (CAREER) and CCF-1136037 (CPS) and
CNS-1060093 (EAGER) & driven by contributions from (among others) Drs. Robert Glaubius (PhD 2009) and Terry Tidwell (PhD
2011); doctoral students David Ferry, Jordan Krage, Jing Li, and Jon Shidal; masters student Mahesh Mahadevan; undergraduate students
Braden Sidoti, David Pilla, Justin Meden, Eli Lasker, Micah Wylde, Carter Bass, Cameron Cross, Percy Fang, Tommy Powers, and Kevin Zhang; and Professors William D. Smart, Ron Cytron, Kunal
Agrawal, and Chenyang Lu

2 - Gill et al. – 04/19/23
Part I : Previous CPS-influenced Research
(for which the doctorates have been earned and the papers
published)

3 - Gill et al. – 04/19/23
Cyber-Physical System (CPS) Scheduling
First, a definition of CPS: physical semantics influence cyber (computation and communication) semantics and vice versa
E.g., if different activities contend for a shared (physical) resourceAiming camera to find/photograph faces
Aiming camera to find/avoid obstacles
How to share camera between these?
Scheduling access to such a resourceAllows such resources to be sharedRaises many other interesting questions
Lewis Media and Machines LabWashington University

4 - Gill et al. – 04/19/23
Nuances of the Scheduling Problem
How long an activity needs a resource may vary each timeWe’ll focus mainly on this issue in today’s talk
Issues we’ve addressed beyond that basic problem:We may have to learn distributions of times on-line
Different distributions in different operating modes
Image capture times with occlusion modes
timepro
bab
ilit
y

5 - Gill et al. – 04/19/23
Developing a System Model
A system model helps capture a problem rigorously» Gives a sound basis for reasoning about the problem
» Focuses attention on particular kinds of analysis
Identifies the important abstractions to work with» For example, resources, activities, and shares
Captures key assumptions about the problem» E.g., is time treated as discrete or continuous?
» E.g., is data available before, during, or after run-time?

6 - Gill et al. – 04/19/23
Basic Scheduling Problem System Model
Time is considered to be discrete» E.g., a Linux jiffy is the time quantum
Separate activities require a shared resource» Access is mutually exclusive (activity binds the resource)
» Binding intervals are independent and non-preemptive
» Each activity’s distribution of intervals is known up front
Goal: guarantee each activity a utilization fraction» For example, 1/2 and 1/2 or 1/3 and 2/3 over an interval
» Want to define a scheduling policy (decides which activity gets the resource when) that best fits that goal

7 - Gill et al. – 04/19/23
Formal System Model Representation
A state space describes such a system model well » Circles represent different combinations of utilizations
» Lower left corner is (0,0)» Vertical transitions give quanta to one resource
» Horizontal transitions give quanta to the other one
Dashed ray shows goal» E.g., 1/3 vs 2/3 share (x, y)
Number of dimensions is number of activities» Generalizes to 3-D, …, n-D
0,1
0,0 1,0
1,1
0,3
0,2 1,2
1,3
2,1
2,0 3,0
3,1
2,3
2,2 3,2
3,3

8 - Gill et al. – 04/19/23
Dealing with Uncertainty
timepro
bab
ilit
y
timepro
bab
ilit
y
Easy if the resource is bound for one quantum at a time»Just move closest to goal ray
However, we have a probability distribution of binding times»Multiple possibilities per action
Need to consider probable consequences of each action »Leads to our use of a Markov Decision Process (MDP) approach

9 - Gill et al. – 04/19/23
From Binding Times to a Scheduling MDP
We model these scheduling decisions as a Markov Decision Process (MDP) over use of the resource
The MDP is given by 4-tuple: (X,A,R,T)» X: the set of resource utilization states (how much use)
» A: the set of actions (giving resource to an activity)
» R: reward function for taking an action in a state (how close to the goal ray are we likely to remain)
» T: transition function (probability of moving from one state to another state)
Want to solve MDP to obtain a locally optimal policy

10 - Gill et al. – 04/19/23
Policy Iteration Approach
Define a cost function r(x) that penalizes deviation from the target utilization ray
Start with some initial policy 0
Repeat for t=0,1,2,…Compute the value Vt(x) -- the accumulated cost of following t -- for each state x.
Obtain a new policy, t+1, by choosing the greedy action at each state.
Guaranteed to converge to the optimal policy, requires storing Vt and t in lookup tables.

11 - Gill et al. – 04/19/23
Can’t do Policy Iteration Quite Yet
Unfortunately, the state space we have is infinite
Can’t apply MDP solution techniques directly to the state space as it stands» Need to bound the state space to solve for a policy
Our approach» Reduce the state space to a set of equivalence classes

12 - Gill et al. – 04/19/23
Insight: State Value Equivalence
Two states co-linear along the target ray have the same cost
Also have the same relative distribution of costs over future states (independent actions)
Any two states with the same cost have the same optimal value!

13 - Gill et al. – 04/19/23
Technique: State Wrapping
This lets us collapse the equivalent states down into a set of exemplar states» Notice how arrows (successors) wrap back into “earlier” states
Now we can add “absorbing” states to bound the space»Far enough from target ray, best decision is clear
Now we can use policy iteration to obtain a policy

14 - Gill et al. – 04/19/23
Automating Model Discovery
ESPI: Expanding State Policy Iteration [3]
1. Start with a policy that only reaches finitely many states from (0,…,0).
E.g., always run the most underutilized task.
» Enumerate enough states to evaluate and improve that policy
» If policy can not be improved, stop» Otherwise, repeat from (2) with newly
improved policy

15 - Gill et al. – 04/19/23
What About Scalability?
MDP representation allows consistent approximation of the optimal scheduling policy
Empirically, bounded model and ESPI solutions appear to be near-optimal
However, approach scales exponentially in number of tasks so while it may be good for (e.g.) sharing an actuator, it won’t apply directly to larger task sets

16 - Gill et al. – 04/19/23
What our Policies Say about Scalability
To overcome limitations of MDP based approach, we focus attention on a restricted class of appropriate scheduling policies
Examining the policies produced by the MDP based approach gives insights into choosing (and into parameterizing) appropriate policies
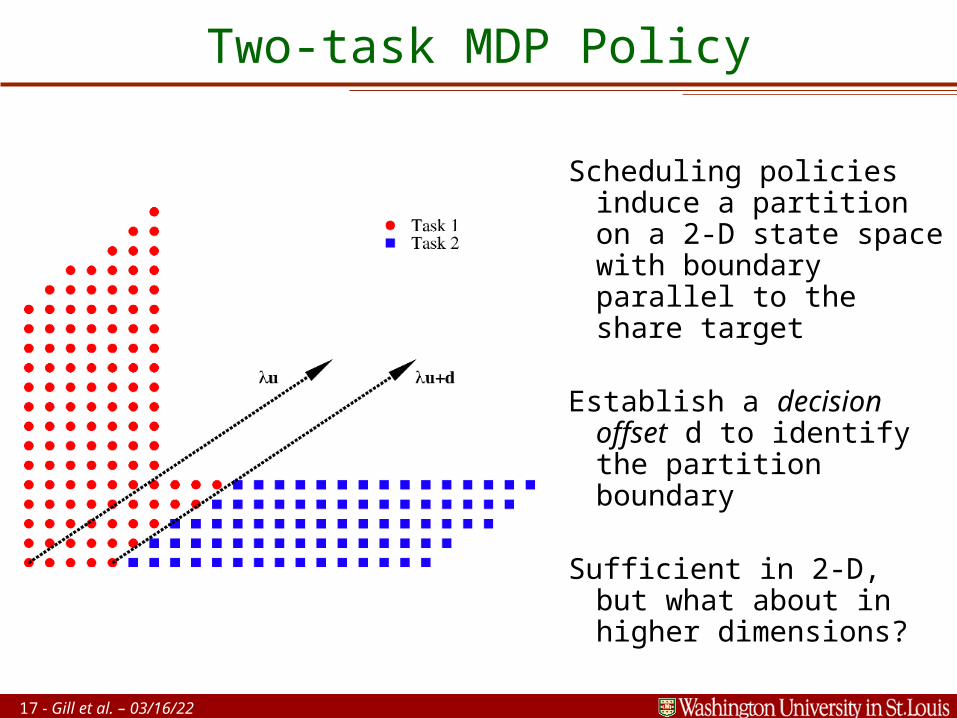
17 - Gill et al. – 04/19/23
Two-task MDP Policy
Scheduling policies induce a partition on a 2-D state space with boundary parallel to the share target
Establish a decision offset d to identify the partition boundary
Sufficient in 2-D, but what about in higher dimensions?

18 - Gill et al. – 04/19/23
Time Horizons Suggest a Generalization
H0 H1 H2 H3 H4
Ht={x : x1+x2+…+xn=t}
H0
H1
H2
(0,0) (2,0,0)
(0,2,0)
(0,0,2)
u
u

19 - Gill et al. – 04/19/23
Three-task MDP Policy
Action partitions meet along a decision ray that is parallel to the utilization ray
t =10 t =20 t =30

20 - Gill et al. – 04/19/23
Parameterizing a Partition
Specify a decision offset at the intersection of partitions
Anchor action vectors at the decision offset to approximate partitions
A “conic” policy selects the action vector best aligned with the displacement between the query state and the decision offset
a1a2
a3
x

21 - Gill et al. – 04/19/23
Conic Policy Parameters
Decision offset dAction vectors a1,a2,…,an
Sufficient to partition each time horizon into n regions
Allows good policy parameters to be found through local search

22 - Gill et al. – 04/19/23
Comparing Policies
Policy found by ESPI (for small numbers of tasks)πESPI(x) – chooses action at state x per solved MDP
Simple heuristics (for all numbers of tasks)πunderused(x) – runs the most underutilized task
πgreedy(x) – minimizes immediate cost from state x
Conic approach (for all numbers of tasks)πconic(x) – selects action with best aligned action vector
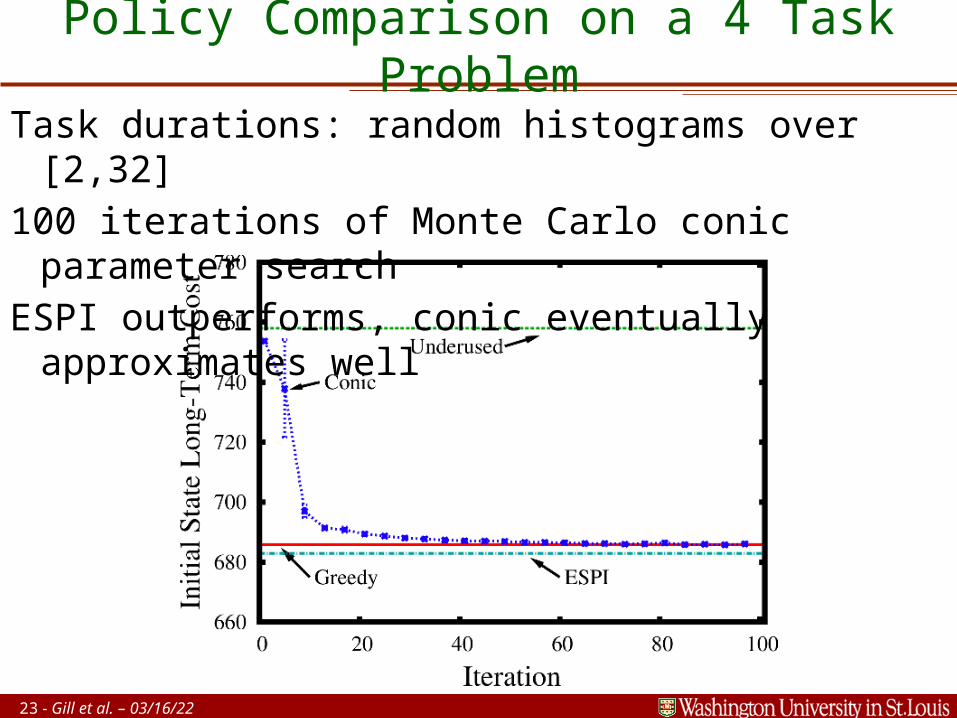
23 - Gill et al. – 04/19/23
Policy Comparison on a 4 Task Problem
Task durations: random histograms over [2,32]
100 iterations of Monte Carlo conic parameter search
ESPI outperforms, conic eventually approximates well

24 - Gill et al. – 04/19/23
Policy Comparison on a Ten Task Problem
Repeated the same experiment for 10 tasksESPI is omitted (intractable here)Conic outperforms greedy & underutilized heuristics

25 - Gill et al. – 04/19/23
Comparison with Varying #s of Tasks
100 independent problems for each # (avg, 95% conf)
ESPI only tractable through all 2 and 3 task cases
Conic approximates ESPI, then outperforms others

26 - Gill et al. – 04/19/23
Expanding our Notion of Utility
Previously, utility was proximity to utilization target; now we let tasks’ utility and job availability* varytime-utility function (TUF) name
period boundarytermination time
termination timeperiod boundary
* Availability variable qi is defined over {0,1}; {0, tmi/pi }; or {0,1} tmi/pi
Time

27 - Gill et al. – 04/19/23
Utility × Execution Utility Density
A task’s time-utility function and its execution time distribution (e.g., Di(1) = Di(2) = 50%) give a distribution of utility for scheduling the task

28 - Gill et al. – 04/19/23
Actions and State Space StructureState space can be more compact here than before: dimensions are task availability, e.g., over (q1, q2), vs. time
Can wrap the state space over the hyper-period of all tasks (e.g., D1(1) = D2(1) = 1; tm1 = p1 = 4; tm2 = p2 = 2)
Scheduling actions induce a transition structure over states (e.g., idle action = do nothing; action i = run task i)
action 2action 1idle action
time timetime

29 - Gill et al. – 04/19/23
Reachable States, Successors, Rewards
States with the same task availability and the same relative position within the hyper-period have the same successor state and reward distributionsreachable states

30 - Gill et al. – 04/19/23
Evaluation
(target sensitive)
(linear drop)
(downward step)Different TUF shapes are useful to characterize tasks’ utilities (e.g., deadline-driven, work-ahead, jitter-sensitive cases)
We chose three representative shapes, and randomized their key parameters: ui, tmi, cpi
(we also randomized 80/20 task
load parameters: li, thi, wi)
utilitybounds
criticalpoints
terminationtimes

31 - Gill et al. – 04/19/23
How Much Better is Optimal Scheduling?
Greedy (Generic Benefit*) vs. Optimal (MDP) Utility Accrual
* P. Li, PhD Dissertation, VA Tech, 2004
2 tasks 3 tasks
5 tasks4 tasks
TUF nuances matter: e.g., work conserving approach degrades target sensitive policy

32 - Gill et al. – 04/19/23
Divergence Increases with # of Tasks
Note we can solve 5 task MDPs for periodic task sets (but even representing a policy may be expensive)

33 - Gill et al. – 04/19/23
How Should Policies be Represented?
State Action
0 a1
1 a2
2 a2
3 a1
4 a1
5 a2
6 a2
7 a2
8 ?
9 a2
Scheduling policy can be stored as a lookup table (size = # states)»Tells best action to take in each (modeled) state
How to minimize run-time memory cost?
What to do about unexpected states?
How to take advantage of heuristics?
Policy Table

34 - Gill et al. – 04/19/23
How to minimize memory footprint?
Decision trees compactly encode tabular data
Trees can be built to approximate the policy
(0, a1)
(1, a2)
(2, a2)
(3, a1)
(4, a1)
(5, a2)
(6, a2)
(7, a2)
(8, ?)
(9, a2)
x < 5
x < 3
a1
Inner Nodes Contain Predicates Over State Variables
Leaf Nodes Contain Action Mappings
a2
a2

35 - Gill et al. – 04/19/23
What to do about Unexpected States?
Trees abstract structure of encoded policy
State x = 8 assigned a “reasonable” action (a2)
(0, a1)
(1, a2)
(2, a2)
(3, a1)
(4, a1)
(5, a2)
(6, a2)
(7, a2)
(8, ?)
(9, a2)
x < 5
x < 3
a1
Inner Nodes Contain Predicates Over State Variables
Leaf Nodes Contain Action Mappings
a2
a2

36 - Gill et al. – 04/19/23
How to Take Advantage of Heuristics?
Leaf nodes also can recommend heuristics Trade run-time cost for accuracy of encoding
(0, a1)
(1, a2)
(2, a2)
(3, a1)
(4, a1)
(5, a2)
(6, a2)
(7, a2)
(8, ?)
(9, a2)
x < 5
x < 3
a1
Inner Nodes Contain Predicates Over State Variables
Leaf Nodes Contain Action Mappings
greedy(x)
a2

37 - Gill et al. – 04/19/23
Optimal Tree Size Varies
37
Size of Tree
00 20 40 60 80 100
0.1
0.2
0.3
0.4
0.5

38 - Gill et al. – 04/19/23
Comparative Performance of Trees
38
1
0.8
0.6
0.4
0.2
0
Fraction of Optimal0 0.
10.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
optimalbesttreeheuristicgreedyPseudo 0

39 - Gill et al. – 04/19/23
Part II : Current CPS Projects
(for which we’re looking to recruit doctoral students)

40 - Gill et al. – 04/19/23
1: Hybrid Real-Time Structural Testing
Need to determine how structures will behave under stress»E.g., ground motion from an earthquake
Can’t afford to test an entire structure»Esp. destructively
Need to combine physical tests and numerical simulation»In real-time at fine time scales (<= 1KHz)

41 - Gill et al. – 04/19/23
1: Real-time Parallel Computing for HRTST
Need to exploit new multicore platforms»Parallelize simulation w/ timing guarantees
Need to develop real-time parallel models and theory»Latency bounds, etc.
Must develop new tools and platforms for real-time parallel concurrency»E.g., atop Linux

42 - Gill et al. – 04/19/23
2: Cyber-Physical System Design Need new design and evaluation methods for CPS»E.g., when dynamics and physics affect what is ok or optimal
Need to re-examine classic trade-offs»Time, storage, power
Need to develop new algorithms and data structures»To accommodate CPS
Modal Hash Table(also Binary Tree, etc.)

43 - Gill et al. – 04/19/23
Concluding Remarks
CPS research opens up diverse new problem areas»E.g., MDP based scheduling policies for physical resources
Our current research is similarly pioneering»Platforms and algorithms for real-time parallel computing
»Adaptive data structures for diverse CPS semantics
Research is a team sport (please try out! :-)»Multiple faculty, doctoral students, masters students, and undergraduates working collaboratively to advance the state of the art (and write about it :-)