current abstractions sequence gdknadgwiefeel database of sequences analysis string theory blast
Post on 19-Dec-2015
223 views
TRANSCRIPT

Biomolecular Interaction Network Database
Current Abstractions
Sequence
GDKNADGWIEFEEL
Database of Sequences
AnalysisString Theory
BLAST

Pathways and Interaction Databases
Sequence databases teach us about biological “similarity”, how things are related.
The 1st wave of Bioinformatics...
An interaction database should likewise teach us about “specificity”, how things work.
The 2nd wave of Bioinformatics...

Interaction pair“A binds B”
Database of Interactions
AnalysisGraph Theory“PATHFIND”
New Abstractions
Goodsell

http://bioinfo.mshri.on.ca
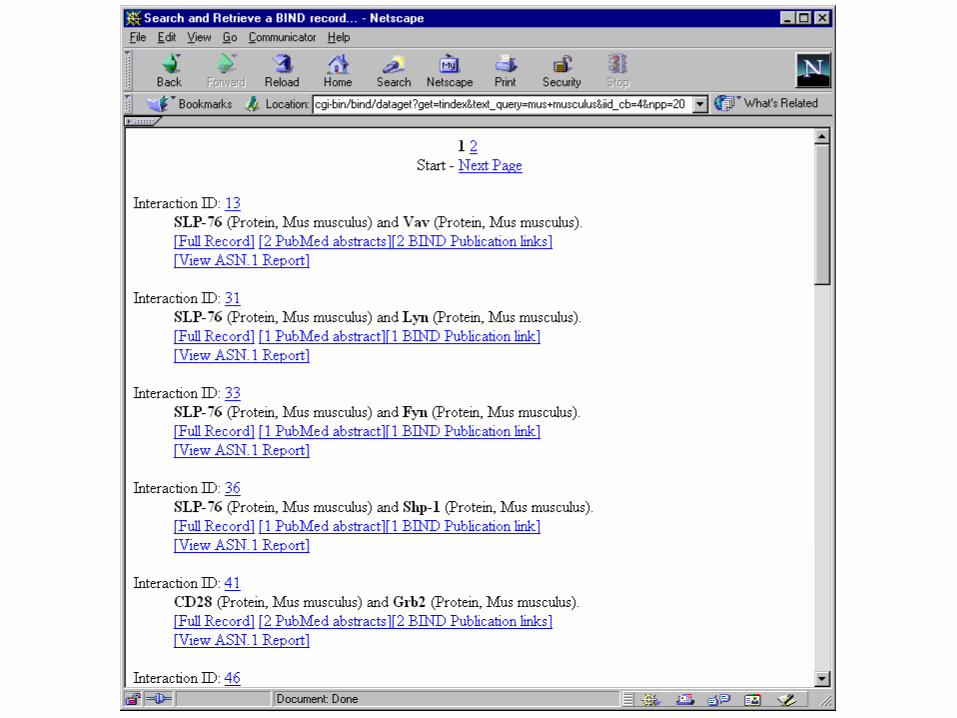
A Quick tour of BIND







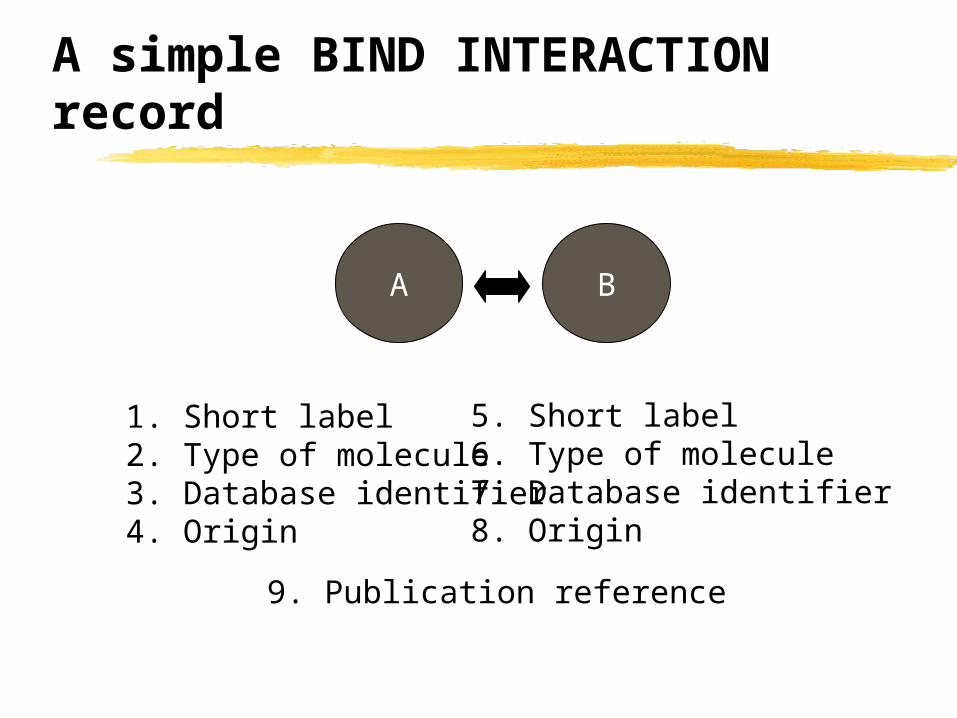
A simple BIND INTERACTION record
A B
1. Short label2. Type of molecule3. Database identifier4. Origin
5. Short label6. Type of molecule7. Database identifier8. Origin
9. Publication reference

Understanding the BIND data model
All cellular processescan be represented bya set of connected recordswhere each record describes a biomolecular interactionand its associated consequences.
A::B
?
C::D
?
E::F
?

Understanding the BIND data model
S PE
E + S E-S
INTERACTION record
S
CHEMICAL STATE data CHEMICAL ACTION data
S P

What BIND can encode...
Simple binding interactions Enzymes, substrates and complete metabolic
pathways including mechanisms Restriction enzymes, Transcription factors Limited proteolysis (insulin, clotting cascade,
complement) Reversible phosphorylation Glycosylation Intron splicing, tRNA base modifications Ubiquitin mediated protein degradation Viral life cycles in host cells

What BIND cannot encode
bulk phenomena membrane potentialsgradientscalcium waveswater
“perfect” cellular localization (4-D time-development/organism axis).

BIND Data Submission



BIND data
specification
API
BIND data
specification
API
data flow
TextData Entry
CGI
JavaChemistry
Tool
BIND SubmitterData Entry
Text Query
CGI
FlashVisualCGI
SeqHound
BIND VisitorQuery Internet clients
BIND servers
Backfillingand
Import

A c c D B
NCBI FTP Site
N C B IE M B LD D B JT I G R
S w is s - P r o tP D B
3D linksNUC-PROT
MEDLINE
" S e q H o u n d " S y s t e m A t S L R I
ASNDBGenBank binary data
Bioseqs
GenBank binary data Seq-Entries
SE l inks
S p e c ie s
T a x I D
ChromID
Redund
M M D B

BIND Software
A Visual Future...

How do we draw fast, high-quality, interactivepictures of pathways and mechanisms from BIND and support thousands or more of simultaneous web clients?
•keep “canned drawings” •long history (Metabolic Maps, 1968)•curators keep re-drawing… •large numbers of interactions•model may not scale well
•generate drawings “on the fly”•BIND data > symbolic interactions•graph theory (edge and vertex)•need consistent symbolic language for pathways•never been done for biological processes
BIND Visualization, Consider...

“On The Fly” Visualization Strategy
Algorithmic generation of pathway drawingsUser asks, “draw me a picture of ...”Server queries database for binding partners,
assembles an image, and sends it to the user
Define the symbolism in a creative and novel way continuous line-symbols for domains “mate-able” we have already a library of about 500 - 1000 symbols

Hand-drawn depiction ofputativecomputer generatedpathway graphic...

Algorithmic Visualization
length mapped to sequence mapping of sequence feature tables
legends automatically generated
can scale to the expected number of interactions/pathways
implementation is already underway...

bothStructure andFunction
Electronics CADsoftware showsschematicsalongsidephysicalrepresentations...
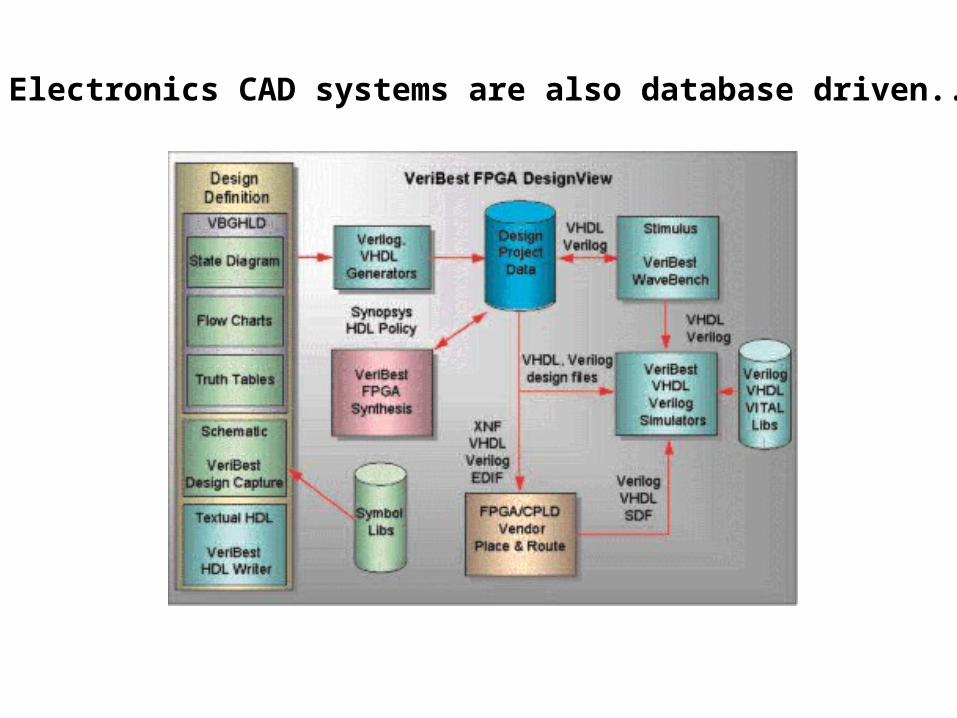
Electronics CAD systems are also database driven...

BIND Proposal
We propose a GenBank-style public interaction database public submissions of interactions active software development close ties to active proteomics and bioinformatics
research
We propose a distributed collaboration for managing indexing and database distribution.

BIND - Data Quality Assurances
Two-tiered expert indexing and validation professional indexers
public data submissionbackfilling of literature data
validation by active “interaction” scientists

BIND - Decentralized by Design
Indexing can be run at several sites enabling technology is a unique key
server
Indexing “nodes” should coincide with pockets of expertise

BIND - Hybrid Data Ownership Model
Like Entrez Some data is owned by databases (SWISSPROT) Other data is owned by submitters Ownership implies right to “edit”
Curated/Backfilled - BIND owns the record Submitted - Submitter owns the record
Redundant records are allowed (different citations) Dispute records may be entered

Data From Existing Literature
The “Backfilling” problem How do we go through the literature and put in the
relevant interactions into a new database?
Joel Martin (NRC-IIT, Ottawa) PubMed abstracts can be classified by SVM
intoprotein-protein interactions (95% accuracy)protein-DNA interactions (99% accuracy)2 seconds analysis time per abstract
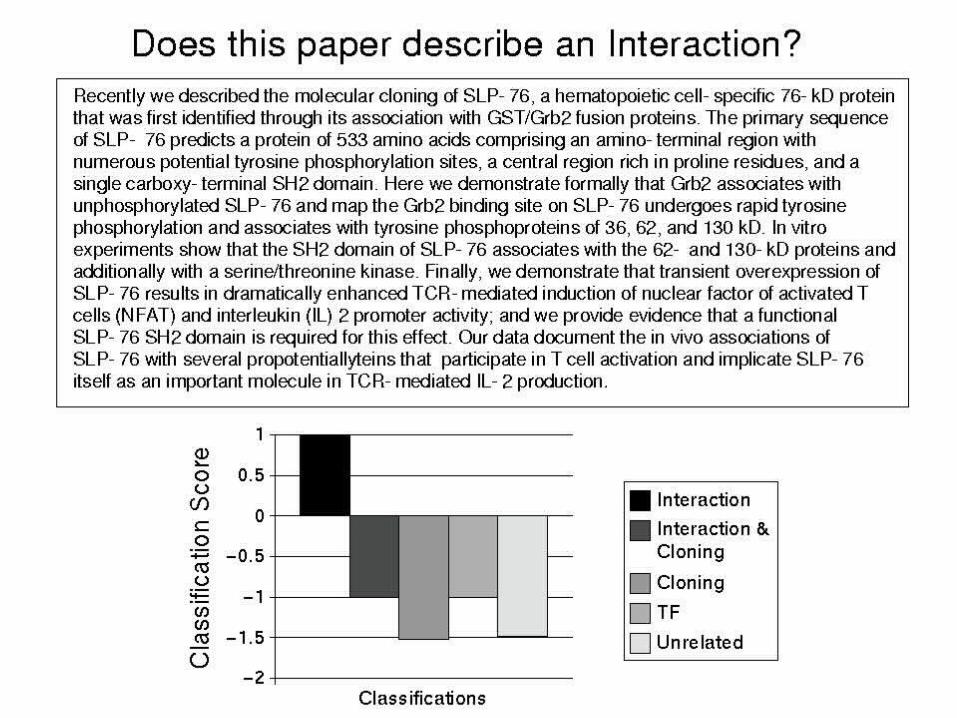

Semi-Automated Backfilling
Automated text classification identifies paper describing interaction
Entrez-spiders find and cluster sequences of related papers
Backfilling indexers are presented with a “probable BIND record”

BIND Database Features
Provides for precise descriptions of biochemical mechanisms and function.
Provides a mapping of interaction space to graph theory.
Tightly linked to the Entrez system.

A Dynamic Data Specification
Ready for change, suggestions and evolution to a mature data model...

BIND interaction
Date
Updates
Accession
Molecule A
Molecule B
Descriptionplace, binding conditions, binding sites,
chemical mechanism, kinetics
Source (literature)
Molecule A Molecule B
Short Label
ID and DB reference
Origin/Cell Stage
Sequence (NCBI Seq)
Structure (NCBI Biostruc)
Text Description
Short Label
ID and DB reference
Origin/Cell Stage
Sequence (NCBI Seq)
Structure (NCBI Biostruc)
Text Description

Rapid Application Development
NCBI’s ASN.1 to C compiler, which generates bug-free code for each specified object: memory allocation freeing read from file (stream) write to file (stream)
This has saved us 2-4 person yearsAllows us to rapidly test changes to BIND
spec.We leveraging work already paid for!

The data is the database...
BIND has “exchange” types lists of BIND ASN.1 records Self-contained, extracted by an ASN.1 parser Automated rules derived from the specification. ASN.1 to XML via XER.
BIND data can be fed into any DBMS, on any platform.
We use a royalty-free DBMS allowing us to maintain distributed BIND indexing sites.

BIND the fine print...

Required Interaction Database Submissions… (when one is funded and ready to go)
At the discretion of the participating granting bodies, mandate that an interaction “accession” be required for publication, as for: sequences (GenBank) structures (PDB)
This ensures the growth and use of an interaction database and protects the investment in its development.

BIND Personnel
Software Developers System Administrators Help/Training Database Specialists BIND Indexers On-callers (validation)
Rotation, check entries for consistency, content
Resource for indexers to consult with

http://bioinfo.mshri.on.ca [email protected]
Hogue LabGary Bader Ian DonaldsonKaterina MichalickovaAdrian HeilbutKiran Deol Submitters and Volunteers...Tony PawsonBerivan Baskin
BIND Colaborators: Francis Ouellette CMMT UBC VancouverJoel Martin IIT-NRC OttawaChristoph Sensen, IMB-NRC Halifax