cuda 9.0 nvgraph - events.ll.mit.edu · to 𝑘clusters such that the cluster ... binary search. 28...
TRANSCRIPT

CUDA 9.0 NVGRAPHGPU ACCELERATED ANALYTICSGRAPHEX, MAY 2017
Joe Eaton Ph.D.

2
Agenda
Accelerated Computing
nvGRAPH in CUDA 8.0
Coming Soon in CUDA 9.0
Cyber Security Applications
Integration with Analytics

3
PERFORMANCE GAP CONTINUES TO GROW
0
100
200
300
400
500
600
700
800
2008 2011 2012 2014 2016
Peak Memory Bandwidth
NVIDIA GPU x86 CPU
M2090
M1060
K20
K80
Pascal
GB/s
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
2008 2010 2012 2014 2016
Peak Double Precision FLOPS
NVIDIA GPU x86 CPU
M1060
K20
GFLOPS
K80
Pascal
M2090

4
ANALYZE HOW WE CONNECTREALTIME ANALYSIS FOR NETWORKS
Whether telecommunications or utilities, graph analysis will accelerate insights into complex networks.
5
NVGRAPHEasy Onramp to GPU Accelerated Graph Analytics
GPU Optimized Algorithms
Reduced cost & Increased performance
Standard formats and primitives
Semi-rings, load-balancing
Performance Constantly Improving

6
APPLICATIONSPagerank (+, *)
//sw/gpgpu/naga/src/pagerank.cpp
• Ideal application: runs on web and social graphs
• Each iteration involves computing: 𝑦 = 𝐴 𝑥
• Standard csrmv
• PlusTimes Semiring
• α = 1.0 (multiplicative identity)
• β = 0.0 (multiplicative nullity)

7
APPLICATIONSSingle Source Shortest Path (min, +)
Common Usage Examples:
• Path-finding algorithms:
• Navigation
• Modeling
• Communications Network
• Breadth first search building block
• Graph 500 Benchmark
0
11
2
1
1
2
2
2
2
1
3
2
3
2
2 3
2

8
APPLICATIONSWidest Path (max,min)
Common Usage Examples:
• Maximum bipartite graph matching
• Graph partitioning
• Minimum cut
• Common application areas:
• power grids
• chip circuits

9
PROPERTY GRAPHS
Listens to Brother ofMarried to
Listens to Drives
Colleague of Works for
Works forHas petFIDO
BMW
IBM
Sister-in-law to
JIM
ROCK
MUSIC
STEVEJULIE
BOB

10
SUBGRAPH EXTRACTION
Developer’s FOAFimport graph
Friend-of-a-friend-graph
Friends at work graph
Employment graph
Explicit graph
Developer created graph
Developer imports graph
Software imports graph Friendship graph

11
Partitioning
Clustering
BFS
Graph Contraction
Triangle Counting
New Features, new pipelines
FEATURES IN CUDA 9.0 RELEASE

12
PARTITIONING AND CLUSTERING
Spectral Min Edge Cut Partition

13Balanced cut minimization Ground truth
SPECTRAL EDGE CUT MINIMIZATION80% hit rate

14
SPECTRAL MODULARITY MAXIMIZATION84% hit rate
A. Fender, N. Emad, S. Petiton, M. Naumov. 2017. “Parallel Modularity Clustering.” ICCS
Spectral Modularity maximization Ground truth

15
MODULARITY VS. LAPLACIAN CLUSTERING
A. Fender, N. Emad, S. Petiton, M. Naumov. 2017. “Parallel Modularity Clustering.” ICCS
Nvidia Titan X (Pascal)
Intel Core i7-3930K @3.2 GHz
Modularity:
higher and steadier modularity score
Laplacian:
more homogeneous clusters sizes
3x speedup over Laplacian scheme

16
SPEEDUP AND QUALITY VS. AGGLOMERATIVE*
A. Fender, N. Emad, S. Petiton, M. Naumov. 2017. “Parallel Modularity Clustering.” ICCS
*D. LaSalle and G. Karypis Multi-threaded
Modularity Based Graph Clustering Using the
Multilevel Paradigm, Parallel Distrib. Comput.,
Vol. 76, pp. 66-80, 2015.
Nvidia Titan X (Pascal)
Intel Core i7-3930K @3.2 GHz
3x speedup over agglomerative* scheme
Speed vs. quality trade-off
0.8s on network with 100 millions edges on a single Titan X GPU

17
Kmeans Problem
Define K-means Objective
Find an assignment 𝑓(𝑖) of observation vectors 𝑥1, ⋯ , 𝑥𝑛 ∈ ℝ
𝑑
to 𝑘 clusters such that the cluster centroids 𝑐1, ⋯ , 𝑐𝑘 ∈ ℝ
𝑑 minimize
𝑖=1
𝑛
𝑥𝑖 − 𝑐𝑓 𝑖2

18
initializeCentroids();
assignCentroids();
while(!converged){
updateCentroids();
assignCentroids();
}
k-meansIterative optimization algorithm
https://en.wikipedia.org/wiki/K-means_clustering

19
k-means++initializeCentroids()
k-means is susceptible to local minima
Randomly choose observation vectors as initial centroids
Probabilities are chosen to spread out centroids
Theoretical guarantees of clustering quality
Speeds up convergence in practice
Mostly serial process, picks one point at a time

20
Kmeans*
Until k initial centroids are selected do:
Calculate d(x_i) = distance to nearest centroid (initial centroid is average of all data)
For each point assign a probability P_i(x)=𝑑 𝑥𝑖
𝑖𝑑 𝑥𝑖
Pick 4*k points by checking if rand(i) > P_i(x) for each point in parallel
Remove ‘nearby’ points using cosine and distance filters
if( D(x_i) < 2*D(x_j) and D(x_j)< 2*D(x_i))
if( dot( x_i, x_j)/ (D(x_i)*D(x_j)) > threshold) ->dot(a,b) = cos( angle_ab)/ |a||b|
drop point from initialization
Converges to epsilon-approximation of ideal answer in log(k) steps
Combines kmeans|| with inner product

21
Why it works
Distance and angle checks divide data into a spherical set of coordinates, and only allows one point in each sector to be picked at each time
Distance update prevents next round from picking nearby points, until k points are picked
Tends to pick only one point from each cluster

22
Find ClustersWhat is the ‘natural’ number of clusters in the data?
Once we have a good initialization and reliably good kmeans results, we can wrap that in an optimization loop.
R = marginal reduction in K-means error per cluster point
Using a straightforward binary search to find the number of clusters which maximizes R gives good results, comparable to human judgement even when the number of clusters isn’t clear. (overlapping or nearby clusters)

23
Implementation DetailsassignCentroids()
Computes distance between each observation vector and centroid
Performance bottleneck for k-means (requires O(𝑛𝑘𝑑) work)
Uses GEMM from cuBLAS
https://en.wikipedia.org/wiki/K-means_clustering

24
Implementation DetailsupdateCentroids()
Must add observation vectors in same cluster
Atomic add operations work well for single-precision
Double precision atomics added in Pascal
Sort and reduce using Thrust is more general, faster
Atomic add
Sort and reduce

25
How fast is it?World class
On Gaussian test data, we can run K-means initialization and solve very fast
200,000 data points
18 dimensions
512 clusters
140 milliseconds
Limited by available GPU memory only. This is at least 10x faster than other methods at scale.

26
ReferencesG. Karypis and V. Kumar. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM Journal on Scientific Computing, 20(1):359–392, 1998.
U. Von Luxburg. A tutorial on spectral clustering. Statistics and Computing, 17(4):395–416, 2007.
P. K. Chan, M. D. Schlag, and J. Y. Zien. Spectral k-way ratio-cut partitioning and clustering. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 13(9):1088–1096, 1994.
D. Calvetti, L. Reichel, and D. C. Sorensen. An implicitly restarted Lanczos method for large symmetric eigenvalue problems. Electronic Transactions on Numerical Analysis, 2(1):21, 1994.
D. Arthur and S. Vassilvitskii. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1027–1035. Society for Industrial and Applied Mathematics, 2007.
D. A. Bader, H. Meyerhenke, P. Sanders, and D. Wagner. Graph Partitioning and Graph Clustering, volume 588. American Mathematical Society and Center for Discrete Mathematics and Theoretical Computer Science, 2013.
B. Bahmani, B. Moseley, A. Vattani Scalable Kmeans++, 2012.
B. Catanzaro NV Research report on Kmeans using GEMM in distance calculation.
27
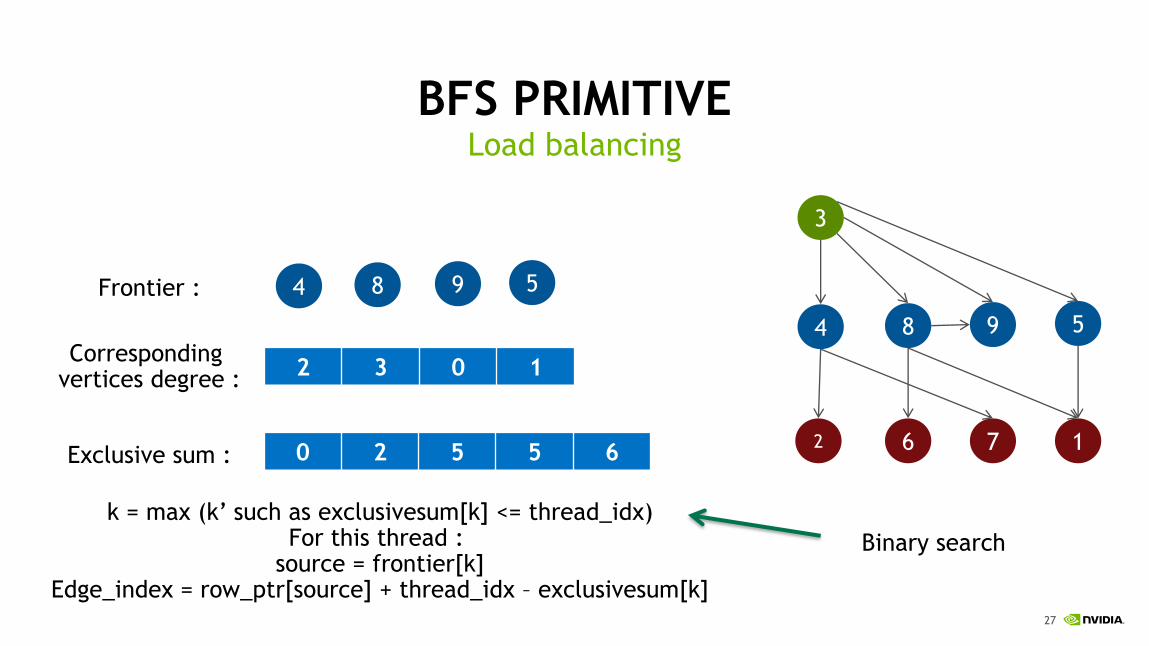
BFS PRIMITIVELoad balancing
8 9 54Frontier :
Corresponding vertices degree :
2 3 0 1
8 9 5
2
4
3
6 7 1Exclusive sum : 0 2 5 5 6
k = max (k’ such as exclusivesum[k] <= thread_idx)For this thread :
source = frontier[k]Edge_index = row_ptr[source] + thread_idx – exclusivesum[k]
Binary search

28
BOTTOM UPMotivation
• Sometimes it’s better for children to look for parents (bottom-up)
Frontier depth=3 8 9 5
Frontier depth=4
4
7 1
3 6 02

29
BOTTOM UPFinalizing, stragglers
• Some vertices have too many edges, and didn’t find a parent in their first edges
• We will continue the search in a separate kernel
• Overall, x5-10 when using (bottom up + top down) vs. (top down)

32
TOP-DOWN BFS
0
2
4
6
8
10
12
14
16
18
20
16 17 18 19 20 21 22 23 24 25
CPU GP100 (32-bit) GP100 (64-bit)
GTEPS
Graph500 scale
CPU: Intel Core i7-5930K @ 3.50GHz; GPU: NVIDIA Quadro GP100; edgefactor 16, harmonic mean over 64 random sources

33
DIRECTION-OPTIMIZED BFS
0
10
20
30
40
50
60
70
80
90
16 17 18 19 20 21 22 23 24 25
CPU GP100 (32-bit) GP100 (64-bit)
GTEPS
Graph500 scale
CPU: Intel Core i7-5930K @ 3.50GHz; GPU: NVIDIA Quadro GP100; edgefactor 16, harmonic mean over 64 random sources

34
Graph Contraction

35
Triangle Counting
High Performance Exact Triangle Counting on GPUs
Mauro Bisson and Massimiliano Fatica
Part of GraphChallenge
Our results are an order of magnitude faster than previous results
Work ongoing to extend to multi-GPU and distributed, first version is single GPU
Next part is to count K-trusses, not done yet
36
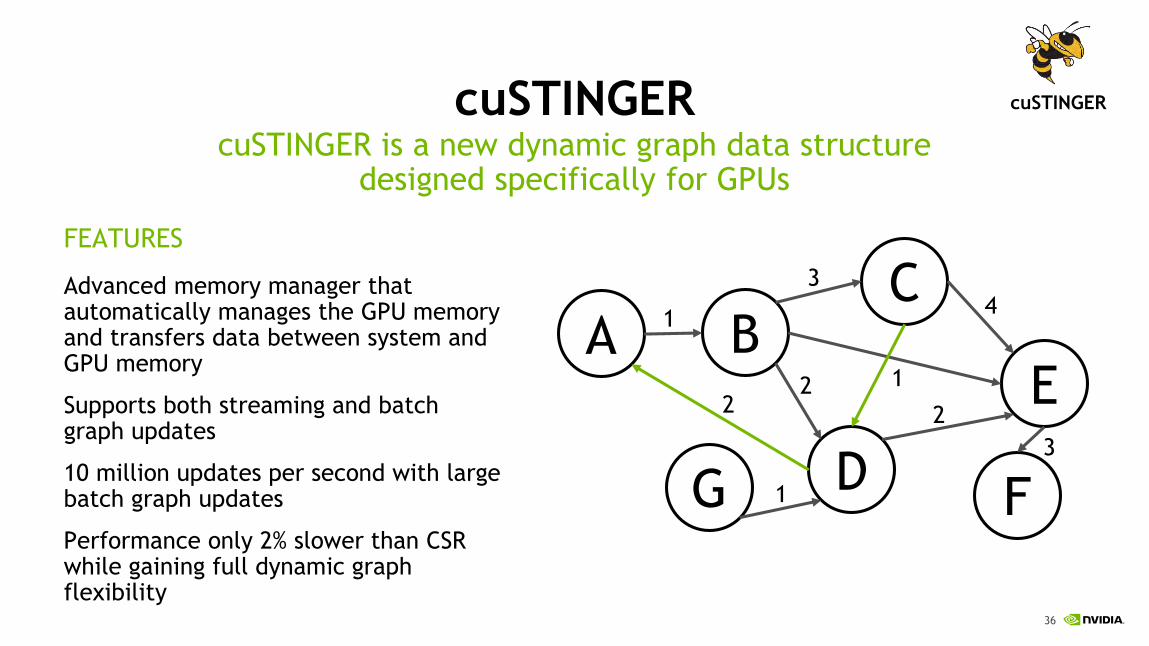
cuSTINGER
FEATURES
Advanced memory manager that automatically manages the GPU memory and transfers data between system and GPU memory
Supports both streaming and batch graph updates
10 million updates per second with large batch graph updates
Performance only 2% slower than CSR while gaining full dynamic graph flexibility
cuSTINGER is a new dynamic graph data structure designed specifically for GPUs
cuSTINGER
A BC
D
E
FG
1
1
1
22
2
4
3
3

37
TOWARD REAL TIME BIG DATA ANALYTICSGPUs enable the next generation of in-memory processing
DUAL BROADWELLSERVER
NVIDIA DGX-1 SERVER
GPU PERFORMANCE INCREASE
Aggregate Memory Bandwidth 150 GB/s 5760 GB/s 38 X
Aggregate SP FLOPS 4 TF 85 TF 21 X
Single DGX-1 server provides the computecapability of dozens of dual-cpu servers

38
ACCELERATED DATABASE TECHNOLOGYBig data ISVs moving to the accelerated model
Integration with SPARK is coming!
SQL
No SQL
Graph

42
SUMMARYGPUs for High Performance Data Analytics
GPU computing is not just for scientists anymore!
GPUs excel at in-memory analytics.Streaming – FirehoseGraph – Pagerank PipelineAnalytics - nvGRAPH
Savings in infrastructure size & cost by using GPU servers versus standard dual-CPU server.Database In-Memory performance 20-100x at practical scale

43
REFERENCES
GPU Processing of Streaming Data: A CUDA implementation of the Firehose benchmark
Mauro Bisson, Massimo Bernaschi, Massimiliano Fatica IEEE HPEC 2016
NVIDIA corporation & Italian Research Council
A CUDA Implementation of the Pagerank Pipeline Benchmark
Mauro Bisson, Everett Phillips, Massimiliano Fatica IEEE HPEC 2016
NVIDIA corporation
