cs4723 software validation and quality assurance lecture 14 defect prediction
TRANSCRIPT

CS4723Software
Validation and Quality Assurance
Lecture 14Defect Prediction

Defect Prediction
We have studied code review and design review
One important thing is to know what is the progress of the review Defect Prediction

Defect Prediction
Also useful in making decisions such as follows: Should I release the software / the new feature
now or later and do some extra testing & fixing?
How large a maintenance team should I have for the software project
How to assign team members to different groups for different feature / modules?

Defect Prediction
2-Class Classification Problem. Non-defective
If error = 0 Defective
If error > 0
More advanced: Grading problem Give each item a score (i.e., between 0 and 1) Rank items according to their scores

Defect Prediction
Three major types of Models Process Models Product Models Multivariate Models

Process Models
Phase Containment Models Rely on history to identify
How many defects were produced in each phase, How many defects from that phase were
discovered and corrected (Phase Containment) Predict defects for each phase and track
discovery and removal. Assume that defects predicted and not found were passed to the next phase.
Simple, easy to implement with common tools.

Process Models
Common features (factors) Quality of the software process (agile, well-
documented, design review, …) Number of revealed bugs in history Revealed bugs in testing Test coverage Other bug removal techniques used Fixed bugs
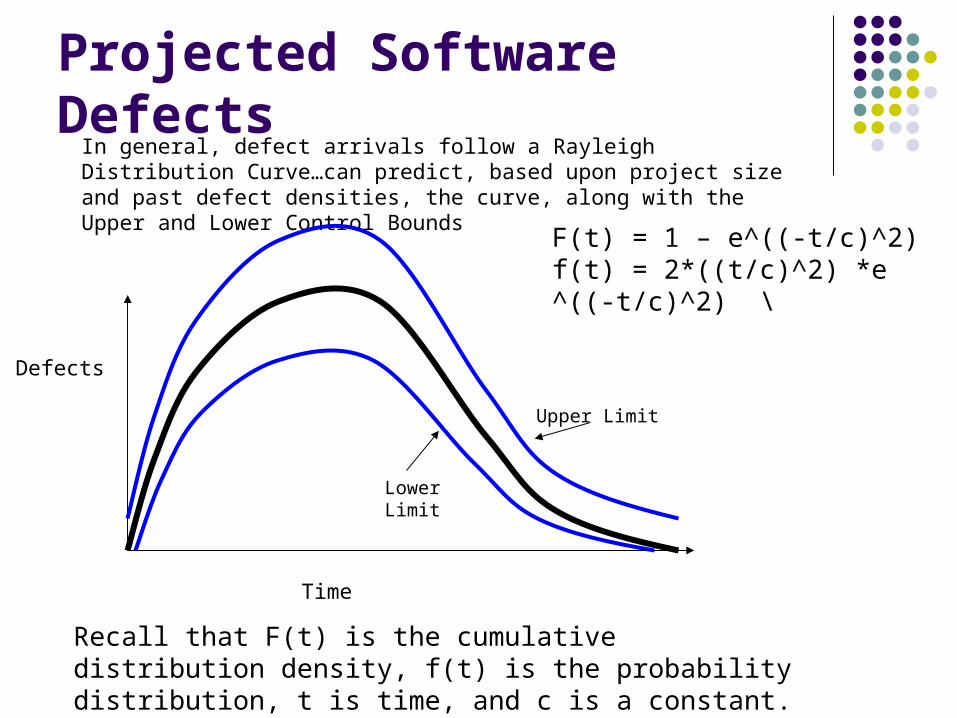
Projected Software DefectsIn general, defect arrivals follow a Rayleigh Distribution Curve…can predict, based upon project size and past defect densities, the curve, along with the Upper and Lower Control Bounds
Time
Defects
Upper Limit
Lower Limit
F(t) = 1 – e^((-t/c)^2)f(t) = 2*((t/c)^2) *e ^((-t/c)^2) \
Recall that F(t) is the cumulative distribution density, f(t) is the probability distribution, t is time, and c is a constant.

Process Models
Pros Easy to implement Perform prediction very quickly Taking into account the process of bug removal
Cons Require to collect lots of data during software
process

Product Models
Use only information in the current shape of the product to do prediction
Static Approach Static/Dynamic structure of source code Design documents Specifications

Features (Factors)
Code Size
Line Methods, Classes Function Calls
Complexity Nested loop Control flow graphs, Call graphs
Comments Warnings of tools like FindBugs

Static Code Attributes void main() { //This is a sample code
//Declare variables int a, b, c;
// Initialize variables a=2; b=5;
//Find the sum and display c if greater than zero
c=sum(a,b); if c < 0 printf(“%d\n”, a); return; }
int sum(int a, int b) { // Returns the sum of two numbers return a+b; }
c > 0
c
Module LOC LOCC V CC Error
main() 16 4 5 2 2
sum() 5 1 3 1 0
LOC: Line of CodeLOCC: Line of commented CodeV: Number of unique operands&operatorsCC: Cyclometric Complexity

Features (Factors)
Design Document Class Diagram
Complexity Coupling, Cohesion Hierarchy depth
Sequence Diagram Number of objects involved Number of object Interactions

Features (Factors)
Specification Number of features / sub-features
Complexity of feature contracts Special cases to handle
Out of power Network error
Non-functional requirements Performance Security Usability

Product Model
Pros Only static data is required, so applicable to any
software at any phase Cons
Still require some bug history for training (can be avoided by cross-learning)
Features are harder to extract

Code Metrics Tools
To Facilitate Production Model To Guide Code Review and Design Review Eclipse Metrics Plugin
Demo

Code Metrics Tools
Update Site http://metrics2.sourceforge.net/update
Generate Metrics Metrics View Rebuild
Dependency Graph Preference

Multivariate Models
Uses any of many variables and analysis of the relationships of the values for those variables and the results observed in historic projects.
Effective if you have a good match for the projects from which the model is created.

Classification with models
Basic machine learning problem Decide Element Granularity
Method, Class, Module, Feature, Whole Software Training data
Collect known bugs of elements as labels Features of these elements based on process model,
product model, or multivariate models. Learn how to classify based on training data Apply the learned knowledge to new data

Classification tools
Use mature machine learning techniques Naive Bayes Bayes Network Support Vector Machines Decision Tree …
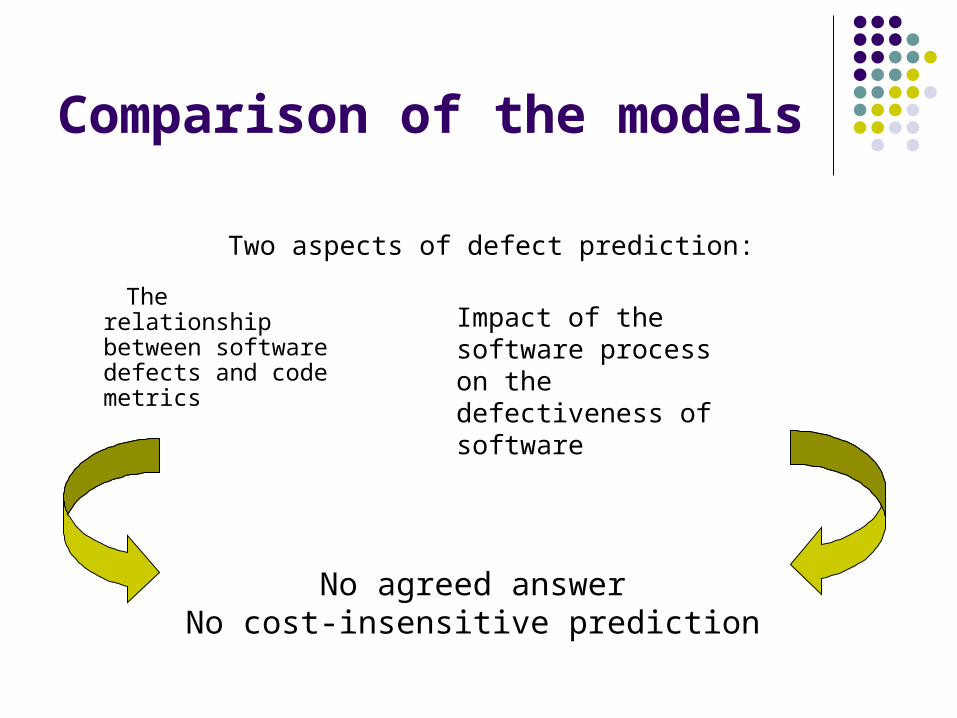
Comparison of the models
The relationship between software defects and code metrics
No agreed answerNo cost-insensitive prediction
Impact of the software process on the defectiveness of software
Two aspects of defect prediction:

Questions:
1. Which metrics are good defect predictors?
2. Which models should be used?
3. How accurate are those models?
4. How much does it cost? Benefits?
Questions to answer

Experimental Set-Up Assessing Classification Accuracy
Accuracy Classification Results Cost-Sensitive Classification
Cost-Sensitive Defect Prediction
A well-known study by Moser et al. in 2008
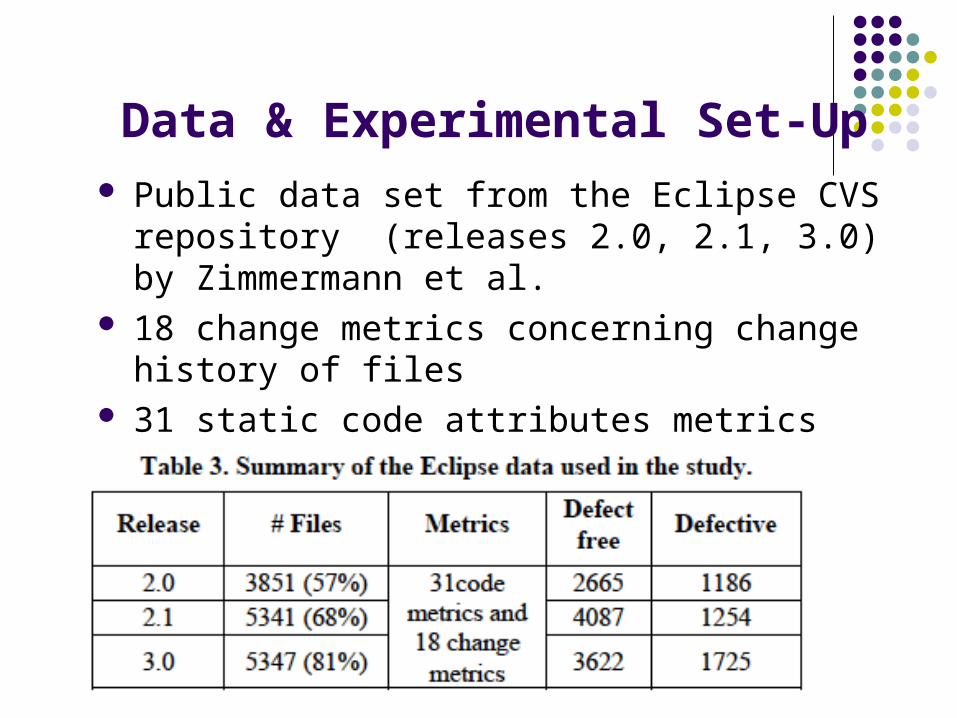
Data & Experimental Set-Up Public data set from the Eclipse CVS repository
(releases 2.0, 2.1, 3.0) by Zimmermann et al. 18 change metrics concerning change history of
files 31 static code attributes metrics that Zimmerman
has used at a file level

renaming or moving software elements
the number of files that have been committed together with file x
in weeks, starting from release date to its first appearance
Change Metrics

1. Change Model uses proposed change metrics
2. Code Model uses static code metrics
3. Combined Model uses both types of metrics
Build Three Models for Predicting the Presence or Absence of
Defects in Files
Change Metrics
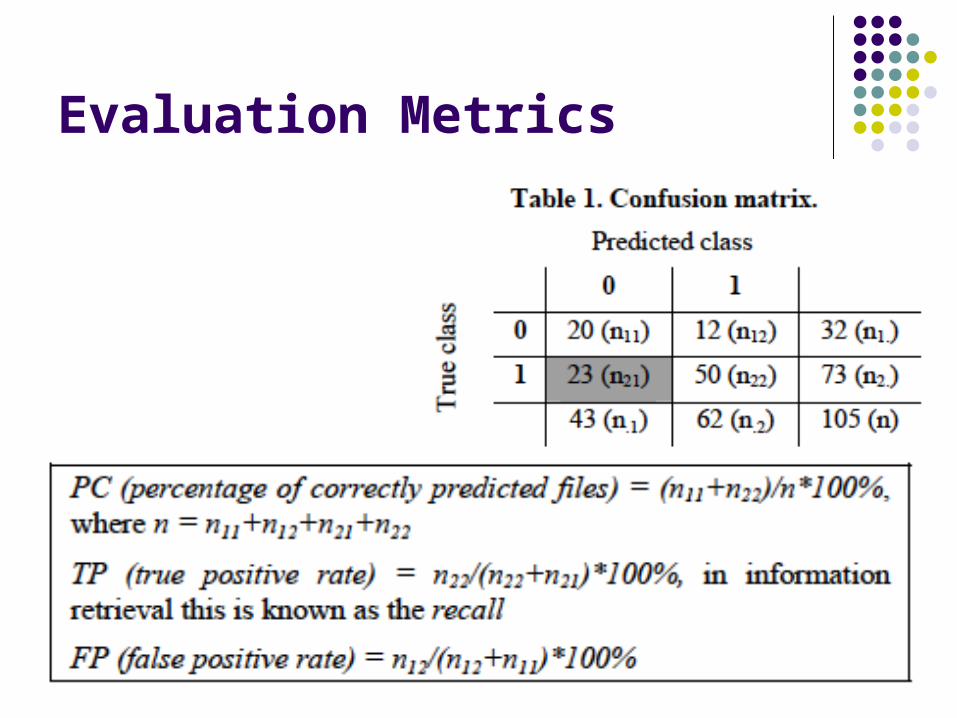
Evaluation Metrics
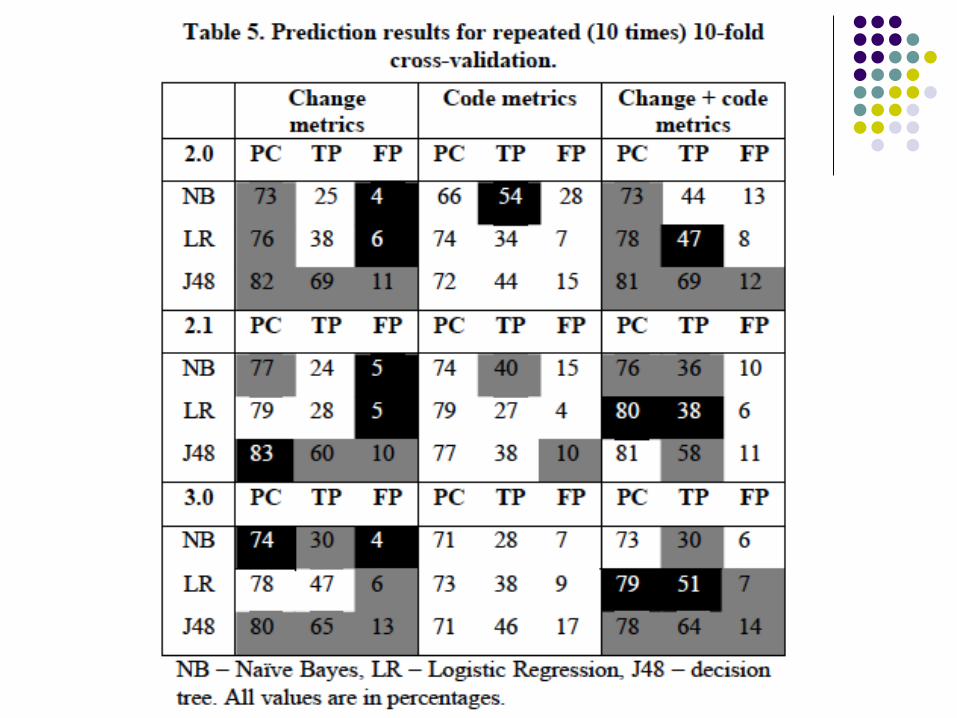

Defect Free: Large MAX_CHANGESET or
Low REVISIONS Smaller MAX_CHANGESET and
Low REVISIONS and
REFACTORINGS
Defect Prone: High number of BUGFIXES
Analysis of decision tree

Cost-Sensitive Classification
Cost-sensitive classification - costs associated with different errors made by a model
min
>1 FN implicate higher costs than FP
Costly to fix an undetected defect in post release cycle than to inspect defect-free file
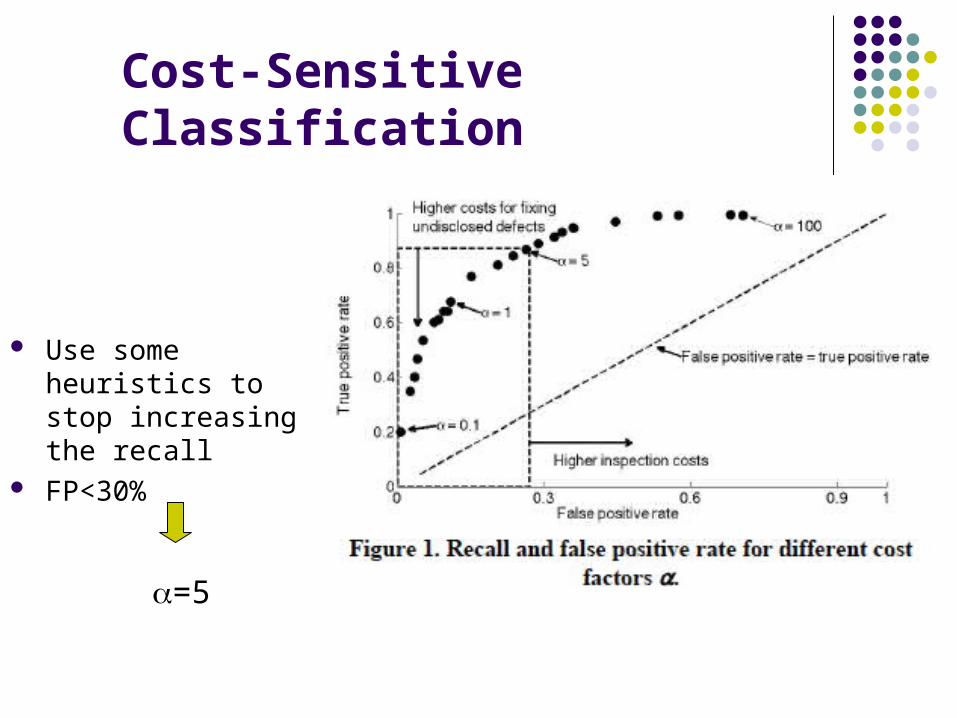
Cost-Sensitive Classification
Use some heuristics to stop increasing the recall
FP<30%
=5
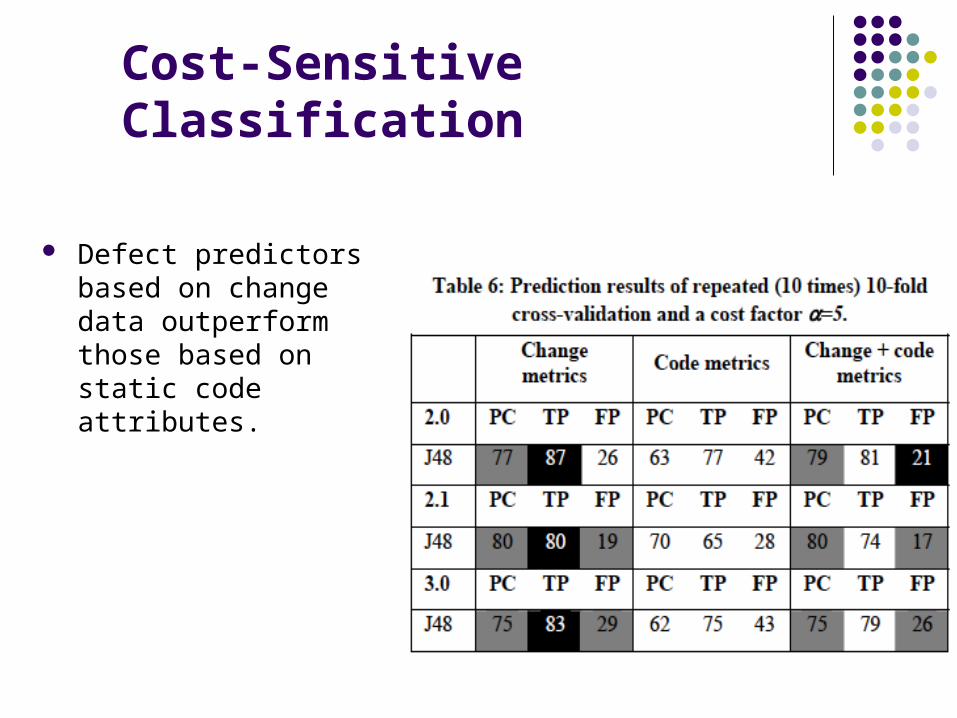
Cost-Sensitive Classification
Defect predictors based on change data outperform those based on static code attributes.

Conclusions
18 change metrics, J48 learner, =5 give accurate results for 3 releases of the Eclipse project:
>75% of correctly classified files>80% recall< 30% FP rate
Hence, the change metrics contain more discriminatory and meaningful information about the defect distribution that the source code itself.

Conclusions Defect prone
files with high revision numberslarge bug fixing activities
Defect-freefiles that are large CVS commitsrefactorings several times files

Current research on defect prediction
Better features More sophisticated code features
Dependencies, type information, … More sophisticated change features
Type of fix, impact of fix, fix comments, …
More precise labeling Remove patches Remove new feature adding

Review on Defect Prediction
Models Process model Product model Multivariate model
Approach Machine learning
Comparison Process model is better, but require more
accumulated data