cs 680: game ai - drexel universitysanti/teaching/2012/cs680/slides/w3-rts... · • pathfinding in...
TRANSCRIPT

CS 680: GAME AI WEEK 3: PATHFINDING IN RTS GAMES
1/30/2012 Santiago Ontañón [email protected] https://www.cs.drexel.edu/~santi/teaching/2012/CS680/intro.html

Reminders • Some people haven’t told me their groups yet
• Projects: • At the end of each class there is a “project discussion session”:
• Please bring your laptops with your projects if you need help • For online students: feel free to contact me (via Discussion board or
email) if you need help • You can make your RTS AI systems play each other (in either S3 or
Starcraft)!
• Progress self-check indicator: • Your progress is good is you already have a dummy AI hooked to
your game (S3 or Starcraft) executing actions (even if it plays bad)

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, AD* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

Pathfinding • Problem:
• Finding a path for a character/unit to move from point A to point B
• One of the most common
AI requirements in games
• Specially critical in RTS games since there are lots of units
A
B

Pathfinding • Problem:
• Finding a path for a character/unit to move from point A to point B
• One of the most common
AI requirements in games
• Specially critical in RTS games since there are lots of units
A
B

Pathfinding • Simplest scenario:
• Single character • Non-real time • Grid • Static world • Solution: A*
• Complex scenario: • Multiple characters (overlapping paths) • Real time • Continuous map • Dynamic world

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

Example
Goal
Start
Reach “Goal” from “Start” Unit can move: up, down, left, right
Wall

Example: Breadth First Search
Goal
Start
Start
• A search algorithm explores nodes in the search space until the goal is found
• Different algorithms explore nodes in different orders
• At each point in time, two lists of nodes:
• Explored nodes (CLOSED) • Candidates to be explored
(OPEN)
OPEN CLOSED

Example: Breadth First Search
A
Goal
B
Start
C
Start
A B C
When a node is explored (expanded), all its successors (children) are added to the OPEN list

Example: Breadth First Search
D
A
Goal
B
Start
C
Start
A B C
D

Example: Breadth First Search
D
A
Goal
B
Start
E
C
Start
A B C
D E
Breadth First Search explores nodes in the same order they were added to the OPEN list: • Nodes that are closer to ‘Start’ are
always explored before nodes that are further.
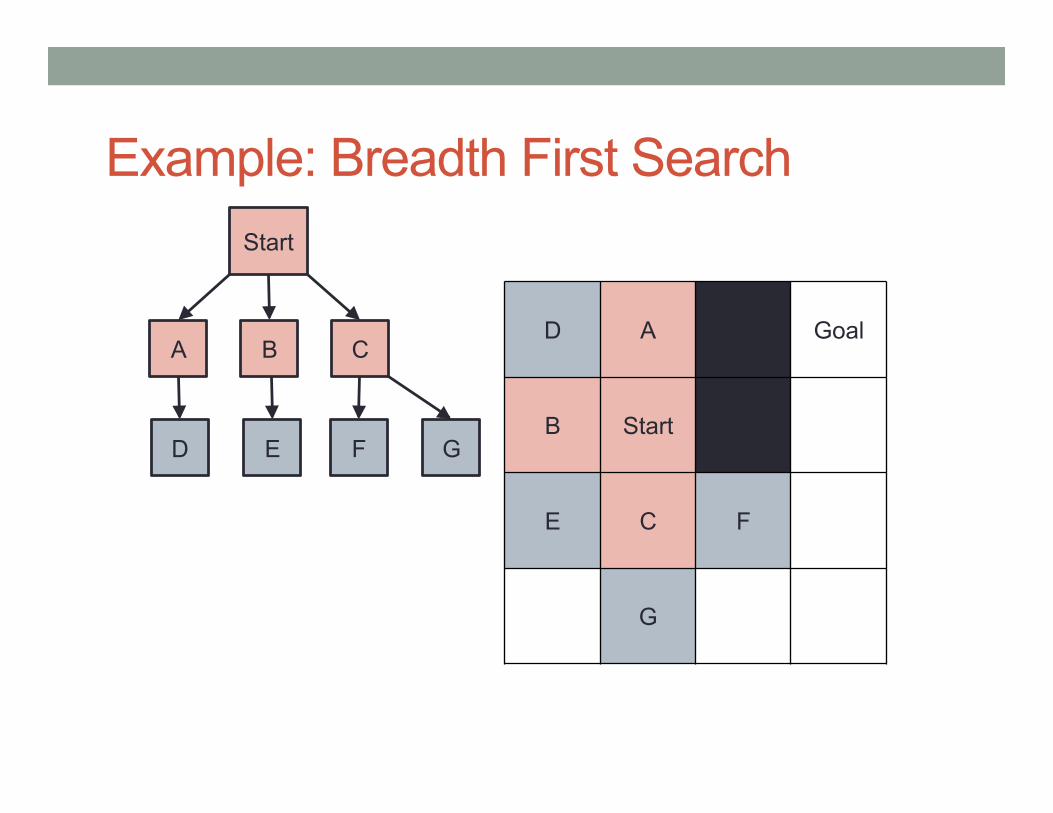
Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
G
Start
A B C
D E F G

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
G
Start
A B C
D E F G

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
H
G
Start
A B C
D E F G
H

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
J
H
G
I
Start
A B C
D E F G
H I J

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
J
H
G
I
Start
A B C
D E F G
H I J

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
J
H
G
I
Start
A B C
D E F G
H I J

Example: Breadth First Search
D
A
Goal
B
Start
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L
Goal

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L
Goal

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L
Goal

Example: Breadth First Search
D
A
Goal
B
Start
L
E
C
F
J
H
G
I
K
Start
A B C
D E F G
H I J
K L
Goal

Breadth First Search OPEN = [Start] CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeFirst() IF goal(N) THEN RETURN path to N CLOSED.add(N) FOR all children C of N that are not in CLOSED:
C.parent = N OPEN.add(C)
ENDFOR ENDWHILE

Breadth First Search • It will find the shortest paths for pathfinding
• But…
• High computational cost: will explore too many cells of the map
• Time Cost: Number of expanded nodes • Memory Cost: Number of expanded nodes

A* • Heuristic search algorithm:
• Finds the shortest path between a given start node and a goal
• Uses a heuristic to guide the search: • Heuristic: h(n) -> estimation of the distance from n to the goal
• Complete: if there is a solution, A* finds one • Optimal: if heuristic admissible, A* finds the optimal path
• A heuristic is admissible if it never overestimates the distance to the goal
• In Pathfinding: Euclidean or Hamming distances are admissible heuristics

Example: A*
Goal
Start g = 0 h = 3
Start 3
Assigns an “estimated cost”, f, to each node:
f(n) = g(n) + h(n)
Heuristic used: Manhattan Distance
Real cost from Start to n
Heuristic

Example: A*
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Start 3
A 3
B 5
C 5
Expands the node with the lowest Estimated cost first

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Start 3
A 3
B 5
C 5
D 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
E 7
Start 3
A 3
B 5
C 5
D 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
G g = 2 h = 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
G g = 2 h = 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5

Example: A*
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Differences wrt Breadth First Search

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
Goal
Start g = 0 h = 3
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N)

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A
Goal
B
Start g = 0 h = 3
C
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N) M

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A
g = 1
Goal
B
Start g = 0 h = 3
C
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N) M

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B
Start g = 0 h = 3
C
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N) M

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B
Start g = 0 h = 3
C
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N) M
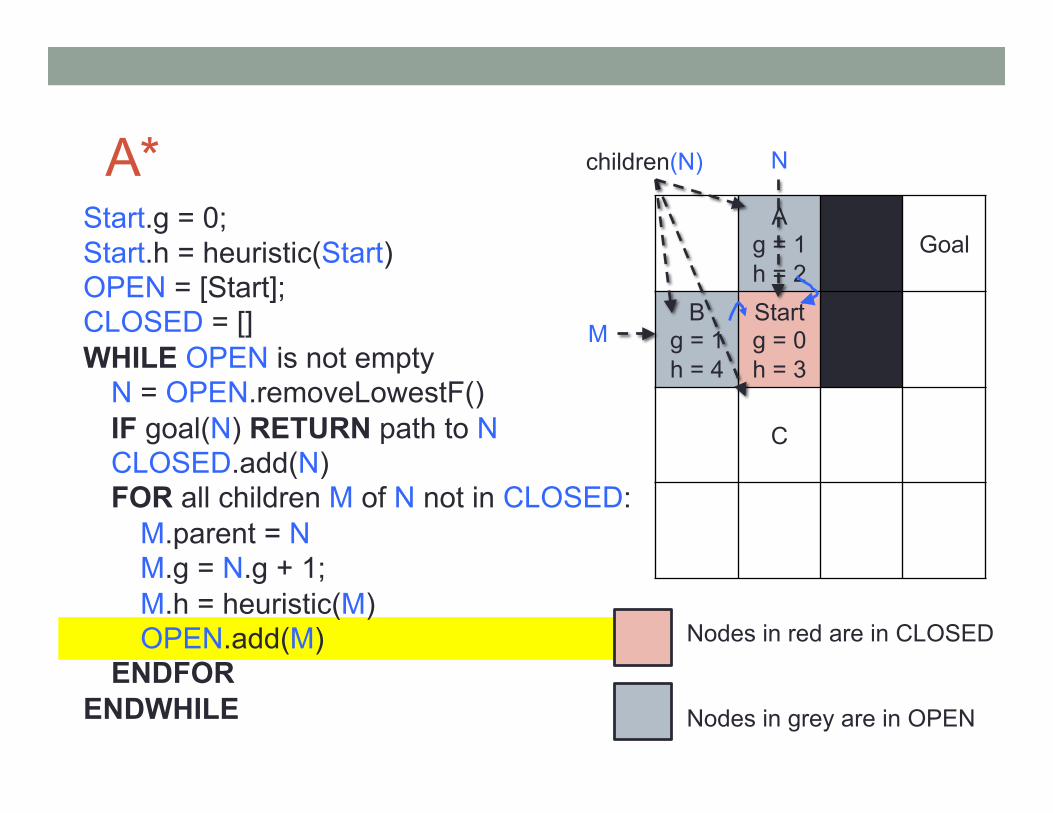
A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N)
M

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N children(N)
M

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* Start.g = 0; Start.h = heuristic(Start) OPEN = [Start]; CLOSED = [] WHILE OPEN is not empty
N = OPEN.removeLowestF() IF goal(N) RETURN path to N CLOSED.add(N) FOR all children M of N not in CLOSED:
M.parent = N M.g = N.g + 1; M.h = heuristic(M) OPEN.add(M)
ENDFOR ENDWHILE
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
C g = 1 h = 4
Nodes in red are in CLOSED Nodes in grey are in OPEN
N

A* • Optimal: finds the shortest paths for pathfinding
• With an admissible heuristic
• Faster than Breath First Search: • Explores less cells of the map (same worst-case scenario though)
• Time Cost: Number of expanded nodes
• Memory Cost: Number of expanded nodes

A* • The heuristic biases the search of the algorithm towards
the goal:
Start
Goal
Breadth First
Search
No bias

A* • The heuristic biases the search of the algorithm towards
the goal:
Start
Goal
Breadth First
Search
No bias
A*
Biased towards the
goal

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

TBA* (Time-Bounded A*) • Main problem of A* for games is that it is not real-time:
• A* needs to run to completion before returning a solution
• In games, we have a limited amount of time for AI computations per frame, before the unit we are controlling needs to move
• TBA* is the simplest real-time variant of A*: • Given a finite amount of time, returns the best path found so far • During the subsequent frames, TBA* continues refining the path • The unit can start moving right away, without waiting for A* to
complete

TBA* • Uses A* as a subroutine (executing only NS steps of A* at
a time)
A*
Path Tracer
Unit OPEN List
CLOSED List
Start Goal
NS,NT Current Path
New Path
Action
1
2
3
Loc

TBA* • Uses A* as a subroutine (executing only NS steps of A* at
a time)
A*
Path Tracer
Unit OPEN List
CLOSED List
Start Goal
NS,NT Current Path
New Path
Action
1
2
3
Loc
1) Improve the search results
2) Compute a new path
3) Follow the path

TBA* OPEN = [Start], CLOSED = [] CurrentPath = [] Loc = Start WHILE Loc != Goal DO
A*(OPEN,CLOSED,Goal,NS) NewPath = PathTracer(OPEN,CLOSED,Loc, NT) IF Loc in NewPath CurrentPath = NewPath stepForward(CurrentPath) ELSE stepBack(CurrentPath) IF
ENDWHILE

Example: TBA* (NS = 3, NT = 3)
Goal
Start g = 0 h = 3
Start 3
CurrentPath = [] NewPath= []
Loc

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
E 7
Start 3
A 3
B 5
C 5
D 5
CurrentPath = [] NewPath= []
A* is executed for NS = 3 cycles

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
E 7
B 5
C 5
CurrentPath = [] NewPath= [Start,A,D]
Path Tracer is executed for NT = 3 cycles
Start 3
A 3
D 5

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
E 7
B 5
C 5
CurrentPath = [Start,A,D] NewPath= [Start,A,D]
Unit moves along the path
Start 3
A 3
D 5

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
A* is executed for NS = 3 cycles
CurrentPath = [Start,A,D] NewPath= [Start,A,D]

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
CurrentPath = [Start,A,D] NewPath= [Start,A,D]
Path Tracer is executed for NT = 3 cycles (not enough to trace completely)

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal
B g = 1 h = 4
Start g = 0 h = 3
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
CurrentPath = [Start,A,D] NewPath= [Start,A,D]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5 A* is executed for NS = 3 cycles
CurrentPath = [Start,A,D] NewPath= [Start,A,D]

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5 Path Tracer is executed for NT = 3 cycles
CurrentPath = [Start,A,D] NewPath= [Start,C,F,J]

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5 Unit moves along the path
CurrentPath = [Start,A,D] NewPath= [Start,C,F,J]

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5 Path Tracer is executed for NT = 3 cycles
CurrentPath = [Start,A,D] NewPath= [Start,C,F,J]

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,A,D] NewPath= [Start,C,F,J]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,A,D] NewPath= [Start,C,F,J,L,Goal]
Path Tracer is executed for NT = 3 cycles

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,C,F,J,L,Goal] NewPath= [Start,C,F,J,L,Goal]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,C,F,J,L,Goal] NewPath= [Start,C,F,J,L,Goal]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,C,F,J,L,Goal] NewPath= [Start,C,F,J,L,Goal]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,C,F,J,L,Goal] NewPath= [Start,C,F,J,L,Goal]
Unit moves along the path

Example: TBA* (NS = 3, NT = 3)
D g = 2 h = 3
A g = 1 h = 2
Goal g = 5 h = 0
B g = 1 h = 4
Start g = 0 h = 3
L g = 4 h = 1
E g = 2 h = 5
C g = 1 h = 4
F g = 2 h = 3
J g = 3 h = 2
G g = 2 h = 5
I g = 3 h = 4
K g = 4 h = 3
I 7
J 5
F 5
G 7
E 7
Start 3
A 3
B 5
C 5
D 5
L 5
K 7
Goal 5
CurrentPath = [Start,C,F,J,L,Goal] NewPath= [Start,C,F,J,L,Goal]
Unit moves along the path

TBA* • Real-time:
• Each execution cycle takes at most a constant time function of NS and NT
• Optimal: • Will eventually find the same optimal path found by A* • Although the unit might perform some additional movements at the
beginning until the algorithm converges to a final path

LRTA* (Learning Real-Time A*) • Real-Time A* variant that converges to optimal path:
• Unit can start moving from step 1, but might waste moves • Eventually, algorithm converges to the optimal path, and units
reaches destination
• Idea: • Learn a better heuristic • After each iteration of the algorithm, the heuristic better
approximates the real distances to the goal • Eventually, it converges to the real distance to the goal • Unit just moves to the cell with lowest heuristic around until
reaching the goal

LRTA*
3 2
Goal 0
4 Start 3 1
5 4 3 2
6 5 4 3
Initializes the heuristic in each cell to h

LRTA*
3 2 f = 1+2
Goal
0
4 f = 1+4
Start 3 1
5 4 f = 1+4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 2 f = 1+2
Goal
0
4 f = 1+4
Start 3 1
5 4 f = 1+4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 2
Goal 0
4 Start 3 1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 f = 1+3 2
Goal
0
4 Start
3 f = 1+3
1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 f = 1+3 4
Goal
0
4 Start
3 f = 1+3
1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 4
Goal 0
4 Start 3 1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
3 4 f = 1+4
Goal
0
4 f = 1+4
Start 3 1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
5 4 f = 1+4
Goal
0
4 f = 1+4
Start 3 1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

LRTA*
5 4
Goal 0
4 Start 3 1
5 4 3 2
6 5 4 3
In each step: • Breadth-first search with
bounded depth (e.g. 1) • Updates the heuristic of the
current node to the best f found • Move to the lowest heuristic cell
around

Other Algorithms: • IDA* (Iterative Deepening A*):
• Like A*, but trades memory by time (only needs memory to store the path, NO open nor closed lists)
• RIBS (Real-Time Iterative Deepening Best-First Search): • Improves on LRTA* by updating several cells at a time, rather than
one
• kNN LRTA* (k-Nearest Neighbor LRTA*): • Useful when pathfinding is executed multiple times in the same
map • It remembers previous paths, and uses them to better estimate
newer paths

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

Pathfinding in Dynamic Environments • A* variants (TBA*, LRTA*, etc.) assume environment
doesn’t change
• In a RTS game, units move, new buildings are constructed and destroyed: environment is dynamic
• Simple solution (used in many games!): • Recompute the path each time something changes (always!)
• Better solution: • Specialized algorithms that can take this into account

D* Lite • Same behavior as D*, but simpler
• Works on dynamic environments: • Modeled by changing the cost of moving from one cell to another • If one cell n is not reachable from another n‘, the cost from n to n’ is
infinity
• Searches from goal to start
• Maintains a “consistency test” on nodes to determine when more search is needed: • At the start • When the environment changes

D* Lite • Maintains an estimate (rhs) of the distance to the goal:
• A* maintains the g-estimates: actual distance from start • rhs-estimate: 1-step look ahead g-estimate
• If g(n) = rhs(n), n is considered consistent
• If all nodes are consistent, finding the optimal path is just moving to the best neighbor
• Search is only carried out on inconsistent nodes. When the environment changes, nodes become inconsistent
rhs(n) = minn02Succ(n)(c(n, n0) + g(n0))

D* Lite (Simplified Algorithm) Initialize g and rhs of all nodes to infinity g(Goal) = rhs(Goal) = 0 U = [Goal] Loc = Start WHILE Loc != Goal
ComputeShortestPath() Loc = bestNeighbor(Loc) FOR all cells N with cost changed Update rhs(N) Add to U any inconsistent neighbor of N ENDIF
ENDWHILE

D* Lite (Simplified Algorithm) Initialize g and rhs of all nodes to infinity g(Goal) = rhs(Goal) = 0 U = [Goal] Loc = Start WHILE Loc != Goal
ComputeShortestPath() Loc = bestNeighbor(Loc) FOR all cells N with cost changed Update rhs(N) Add to U any inconsistent neighbor of N ENDIF
ENDWHILE
• U plays the role of the OPEN list in A*.
• Node consistency plays the role of the CLOSED list in A*
• Equivalent to A*, but using U and consistency

D* Lite (Full Algorithm)
Part shown in the previous slide
locally overconsistent vertex at the time ComputeShortest-Path() expands it is the same as the f-value of the vertex.The second component of its key is its start distance.Theorem 3 Whenever ComputeShortestPath selects a lo-cally overconsistent vertex for expansion on line 10 ,then its key is .Theorems 2 and 3 imply that ComputeShortestPath() ex-
pands locally overconsistent vertices in the order of mono-tonically nondecreasing f-values and vertices with the samef-values in the order of monotonically nondecreasing startdistances. A* has the same property provided that it breaksties in favor of vertices with smaller start distances.Theorem 4 ComputeShortestPath expands locally over-consistent vertices with finite f-values in the same order asA*, provided that A* always breaks ties among vertices withthe same f-values in favor of vertices with the smallest startdistances and breaks remaining ties suitably.The next theorem shows that ComputeShortestPath() ex-
pands at most those locally overconsistent vertices whosef-values are less than the f-value of the goal vertex and thosevertices whose f-values are equal to the f-value of the goalvertex and whose start distances are less than or equal to thestart distances of the goal vertex. A* has the same propertyprovided that it breaks ties in favor of vertices with smallerstart distances.Theorem 5 ComputeShortestPath expands atmost those locally overconsistent vertices with
.
EfficiencyWe now show that LPA* expands many fewer vertices thansuggested by Theorem 1. The next theorem shows that LPA*is effi cient because it performs incremental searches andthus calculates only those g-values that have been affectedby cost changes or have not been calculated yet in previoussearches.Theorem 6 ComputeShortestPath() does not expand anyvertices whose g-values were equal to their respective startdistances before ComputeShortestPath() was called.Our fi nal theorem shows that LPA* is effi cient because
it performs heuristic searches and thus calculates only theg-values of those vertices that are important to determine ashortest path. Theorem 5 has already shown how heuristicslimit the number of locally overconsistent vertices expandedby ComputeShortestPath(). The next theorem generalizesthis result to all locally inconsistent vertices expanded byComputeShortestPath().Theorem 7 The keys of the vertices that ComputeShort-estPath() selects for expansion on line 10 never exceed
.To understand the implications of this theorem on the ef-
fi ciency of LPA* remember that the key of a vertex is.
Thus, the more informed the heuristics are andthus the larger they are, the fewer vertices satisfy
and thus are expanded.
procedure CalculateKey01’ return ;procedure Initialize02’ ;03’04’ for all ;05’ ;06’ U.Insert CalculateKey ;procedure UpdateVertex07’ if ;08’ if U.Remove ;09’ if U.Insert CalculateKey ;procedure ComputeShortestPath10’ while U.TopKey CalculateKey OR11’ U.TopKey12’ U.Pop ;13’ if CalculateKey14’ U.Insert CalculateKey15’ else if16’ ;17’ for all UpdateVertex ;18’ else19’ ;20’ for all UpdateVertex ;procedure Main21’22’ Initialize ;23’ ComputeShortestPath ;24’ while25’ /* if then there is no known path */26’ ;27’ Move to ;28’ Scan graph for changed edge costs;29’ if any edge costs changed30’31’32’ for all directed edges with changed edge costs33’ Update the edge cost ;34’ UpdateVertex ;35’ ComputeShortestPath ;
Figure 3: D* Lite.
D* LiteSo far, we have described LPA*, that repeatedly determinesshortest paths between the start vertex and the goal vertexas the edge costs of a graph change. We now use LPA* todevelop D* Lite, that repeatedly determines shortest pathsbetween the current vertex of the robot and the goal vertexas the edge costs of a graph change while the robot movestowards the goal vertex. D* Lite is shown in Figure 3. Itdoes not make any assumptions about how the edge costschange, whether they go up or down, whether they changeclose to the current vertex of the robot or far away from it, orwhether they change in the world or only because the robotrevised its initial estimates. D* Lite can be used to solve thegoal-directed navigation problem in unknown terrain (as de-scribed in the section on “Motivation”). The terrain is mod-eled as an eight-connected graph. The costs of its edges areinitially one. They change to infi nity when the robot discov-ers that they cannot be traversed. One can implement therobot-navigation strategy by applying D* Lite to this graphwith being the current vertex of the robot andbeing the goal vertex.
Search DirectionWe fi rst need to switch the search direction of LPA*. Theversion of LPA* presented in Figure 2 searches from thestart vertex to the goal vertex and thus its g-values are esti-mates of the start distances. D* Lite searches from the goalvertex to the start vertex and thus its g-values are estimates
This method is equivalent to A*, but using g and rhs (ComputeShortestPath from previous slide)

Example: D* Lite
g = ∞ rhs = ∞
g = ∞ rhs = ∞
Goal g = 0
rhs = 0
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
g = ∞ rhs = ∞
• All g and rhs are initialized to infinity
• Goal g and rhs initialized to 0
• The only inconsistent node is Goal
U = [Goal]

Example: D* Lite
g = 9 rhs = 9
g = 8 rhs = 8
Goal g = 0
rhs = 0
g = 8 rhs = 8
g = 7 rhs = 7
g = 1 rhs = 1
g = 7 rhs = 7
g = 6 rhs = 6
g = 2 rhs = 2
g = 6 rhs = 6
g = 5 rhs = 5
g = 4 rhs = 4
g = 3 rhs = 3
• After running ComputeShortestPath, the nodes relevant for the path from Start to Goal will be consistent
• Some nodes away from the path might not, D* Lite will not expand unnecessary nodes in U (Like A*)
U = []

Example: D* Lite
g = 9 rhs = 9
g = 8 rhs = 8
Goal g = 0
rhs = 0
g = 8 rhs = 8
g = 7 rhs = 7
g = 1 rhs = 1
g = 7 rhs = 7
g = 6 rhs = 6
g = 2 rhs = 2
g = 6 rhs = 6
g = 5 rhs = 5
g = 4 rhs = 4
g = 3 rhs = 3
• The Unit can now move by choosing the minimum neighbor around
U = []

Example: D* Lite
g = 9 rhs = 9
A g = 8
rhs = 8
B g = ∞
rhs = ∞
Goal g = 0
rhs = 0
g = 8 rhs = 8
g = 7 rhs = 7
g = 1 rhs = 1
g = 7 rhs = 7
g = 6 rhs = 6
g = 2 rhs = 2
g = 6 rhs = 6
g = 5 rhs = 5
g = 4 rhs = 4
g = 3 rhs = 3
• If something changes, nodes become inconsistent, and are pushed back into U
U = [A,B,Goal]

Example: D* Lite
g = 3 rhs = 3
A g = 2
rhs = 2
B g = 1
rhs = 1
Goal g = 0
rhs = 0
g = 4 rhs = 4
g = 3 rhs = 3
g = 1 rhs = 1
g = 5 rhs = 5
g = 4 rhs = 4
g = 2 rhs = 2
g = 6 rhs = 6
g = 5 rhs = 5
g = 4 rhs = 4
g = 3 rhs = 3
• After running ComputeShortestPath, again, nodes are made consistent again.
• No need to replan from scratch, only inconsistent nodes are updated, and their changes propagated
U = []

Example: D* Lite
g = 3 rhs = 3
A g = 2
rhs = 2
B g = 1
rhs = 1
Goal g = 0
rhs = 0
g = 4 rhs = 4
g = 3 rhs = 3
g = 1 rhs = 1
g = 5 rhs = 5
g = 4 rhs = 4
g = 2 rhs = 2
g = 6 rhs = 6
g = 5 rhs = 5
g = 4 rhs = 4
g = 3 rhs = 3
• The Unit can again move by choosing the minimum neighbor around
U = []

D* Lite • D* Lite can handle dynamic environments
• Doesn’t need to replan from scratch
• As presented it is not real-time (ComputeShortestPath might have to update an arbitrary number of nodes):
• It can be made real-time by limiting the number of updates ComputeShortestPath performs per cycle

Other Algorithms • D*
• Previous to D* Lite • Same behavior, but more complex
• AD* (Anytime Dynamic A*) • Tunes quality of paths depending on available time • Reuses past paths in new searches to improve their quality • Uses a “bloating” coefficient to find paths faster when little time
available (a multiplier of the heuristic)

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and
waypoints)
• Project Discussion

Waypoints • Predefine a collection of waypoints, and do pathfinding in
the waypoint graph:

Precomputation • If environment is largely static paths can be precomputed
• To reduce the amount of precomputation: • Precomputation only in the waypoint graph • Precomputation of paths between each possible map location is
not feasible
• At runtime, the precomputed path can be used as a starting point: • If environment changes a bit, the path can be modified locally using
obstacle avoidance techniques (faster than pathfinding)

Outline • Student Presentation:
“A Multiagent Potential Field-based Bot for a Full RTS Game Scenario”
• Student Presentation: “Interactive Navigation of Multiple Agents in Crowded Environments”
• Pathfinding • Basics: Breadth First Search, A* • Pathfinding in Static Domains: TBA*, LRTA* • Pathfinding in Dynamic Domains: D*, D* Lite, DA* • Easy ways to Improve Speed (Precomputation and waypoints)
• Project Discussion

Project 1: RTS Games • Issues with Starcraft / BWAPI?
• http://code.google.com/p/bwapi/wiki/UsingBWAPI
• Issues with S3?