cs 426 parallel computing lecture 01: introductioncs.bilkent.edu.tr/~ozturk/cs426/set1.pdf ·...
TRANSCRIPT

CS426 L01 Introduction.1
CS 426 Parallel Computing
Lecture 01: Introduction
Ozcan Ozturk
http://www.cs.bilkent.edu.tr/~ozturk/cs426/

CS426 L01 Introduction.2
Course Administration
Instructor: Dr. Özcan Öztürk
Office Hours: 10:30 - 12:30, Monday or by appointment
Office: EA 421, Phone: 3444
WWW: http://www.cs.bilkent.edu.tr/~ozturk/
TA: Kaan Akyol
Office Hrs: posted on the course web page
URL: http://www.cs.bilkent.edu.tr/~ozturk/cs426/
Text: Required: Parallel Computing
Slides: pdf on the course web page after lecture

CS426 L01 Introduction.3
Grading Information
Grade determinates
Midterm Exam ~25%
- November 15 , In class
Final Exam ~25%
- December 20, In class
Projects (3-5) ~35%
- Due at the beginning of class (or, if its code to be submitted electronically, by 17:00 on the due date). No late assignments will be accepted.
Class participation & pop quizzes ~15%
Let me know about midterm exam conflicts ASAP
FZ Grade
%50 minimum grade average (midterm+project+quiz)
Grades will be posted on AIRS

CS426 L01 Introduction.4
Why did we introduce this course?
Because the entire computing industry has bet on parallelism
All major processor vendors are producing multicore chips
Every machine will soon be a parallel machine
There is a desperate need for all computer scientists and practitioners to be aware of parallelism
All programmers will be parallel programmers???
Some may eventually be hidden in libraries, compilers, and high level languages
But a lot of work is needed to get there
Big open questions:
What will be the killer applications for multicore machines?
How should the chips be designed?
How will they be programmed?

CS426 L01 Introduction.5
What is Parallel Computing? Parallel computing: using multiple processors in parallel
to solve problems more quickly than with a single processor, or with less energy
Examples of parallel machines
A computer Cluster that contains multiple PCs with local memories combined together with a high speed network
A Symmetric Multi-Processor (SMP) that contains multiple processor chips connected to a single shared memory system
A Chip Multi-Processor (CMP) contains multiple processors (called cores) on a single chip, also called Multi-Core Computers
The main motivation for parallel execution historically came from the desire for improved performance
Computation is the third pillar of scientific endeavor, in addition to Theory and Experimentation
But parallel execution has also now become a ubiquitous necessity due to power constraints, as we will see

CS426 L01 Introduction.6
Why Parallel Computing?
The real world is massively parallel

CS426 L01 Introduction.7
Why Parallel Computing?
Historically, parallel computing has been considered to be "the high end of computing", and has been used to model difficult problems in many areas of science and engineering: Atmosphere, Earth, Environment
Physics - applied, nuclear, particle, condensed matter
Bioscience, Biotechnology, Genetics
Chemistry, Molecular Sciences
Geology, Seismology
Mechanical Engineering - from prosthetics to spacecraft
Electrical Engineering, Circuit Design, Microelectronics
Computer Science, Mathematics

CS426 L01 Introduction.8
Simulation: The Third Pillar of Science
Traditional scientific and engineering paradigm:
Do theory or paper design.
Perform experiments or build system.
Limitations:
Too difficult -- build large wind tunnels.
Too expensive -- build a throw-away passenger jet.
Too slow -- wait for climate or galactic evolution.
Too dangerous -- weapons, drug design, climate experimentation.
Computational science paradigm:
Use high performance computer systems to simulate the phenomenon
Base on known physical laws and efficient numerical methods.
CS426 L01 Introduction.9
Why Parallel Computing?
Today, commercial applications provide an equal or greater driving force in the development of faster computers.
These applications require the processing of large amounts of data in sophisticated ways.

CS426 L01 Introduction.10
Why Parallel Computing?
For example: Databases, data mining
Oil exploration
Web search engines, web based business services
Medical imaging and diagnosis
Pharmaceutical design
Management of national and multi-national corporations
Financial and economic modeling
Advanced graphics and virtual reality, particularly in the
entertainment industry
Networked video and multi-media technologies
Collaborative work environments

CS426 L01 Introduction.11
Why Use Parallel Computing?
Save time and/or money:
In theory, throwing more resources at a task will shorten its time to completion, with potential cost savings. Parallel computers can be built from cheap, commodity components.
Solve larger problems:
Many problems are so large and/or complex that it is impractical or impossible to solve them on a single computer, especially given limited computer memory. For example:
"Grand Challenge" (en.wikipedia.org/wiki/Grand_Challenge) problems requiring PetaFLOPS and PetaBytes of computing resources.
Web search engines/databases processing millions of transactions per second

CS426 L01 Introduction.12
Why Use Parallel Computing?
Provide concurrency:
A single compute resource can only do one thing at a time. Multiple computing resources can be doing many things simultaneously. For example, the Access Grid (www.accessgrid.org) provides a global collaboration network where people from around the world can meet and conduct work "virtually".
Use of non-local resources:
Using compute resources on a wide area network, or even the Internet when local compute resources are scarce.
Limits to serial computing:
Both physical and practical reasons pose significant constraints to simply building ever faster serial computers:

CS426 L01 Introduction.14
The Computational Power Argument

CS426 L01 Introduction.15
The Computational Power Argument
Moore's law states [1965]:
``The complexity for minimum component costs has increased at a rate of roughly a factor of two per year. Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000.''
Gordon Moore (co-founder of Intel)
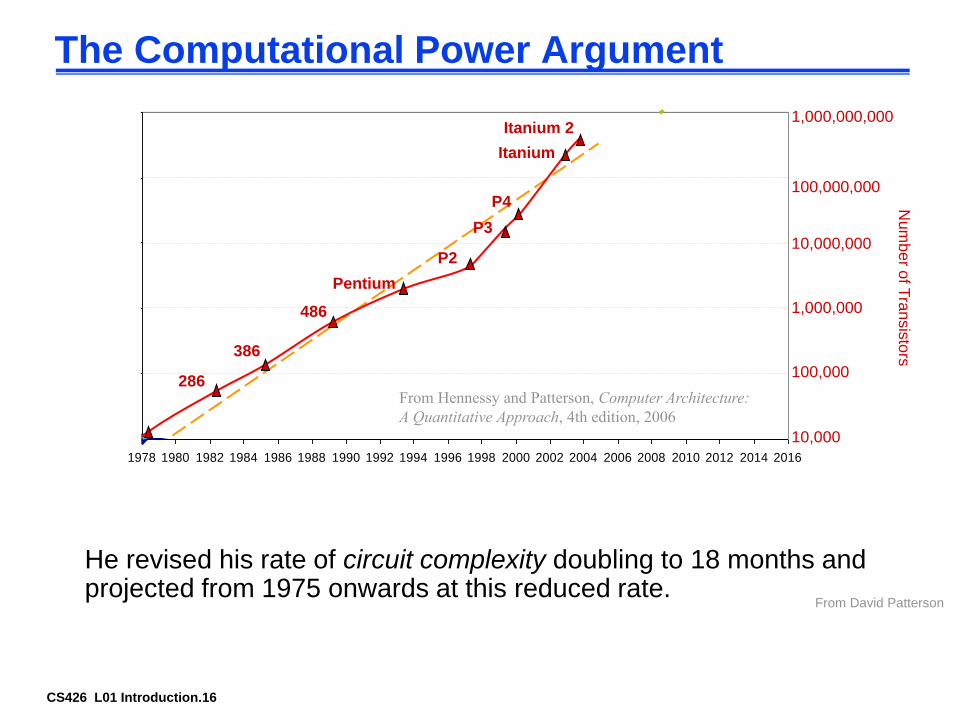
CS426 L01 Introduction.16
The Computational Power Argument
He revised his rate of circuit complexity doubling to 18 months and projected from 1975 onwards at this reduced rate.
1
10
100
1000
10000
100000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014 2016
Perf
orm
ance (
vs. V
AX
-11/7
80)
25%/year
52%/year
??%/year
8086
286
386
486
Pentium
P2
P3
P4
Itanium
Itanium 2
From David Patterson
1,000,000,000
100,000
10,000
1,000,000
10,000,000
100,000,000
From Hennessy and Patterson, Computer Architecture:
A Quantitative Approach, 4th edition, 2006
Num
be
r of T
ran
sis
tors
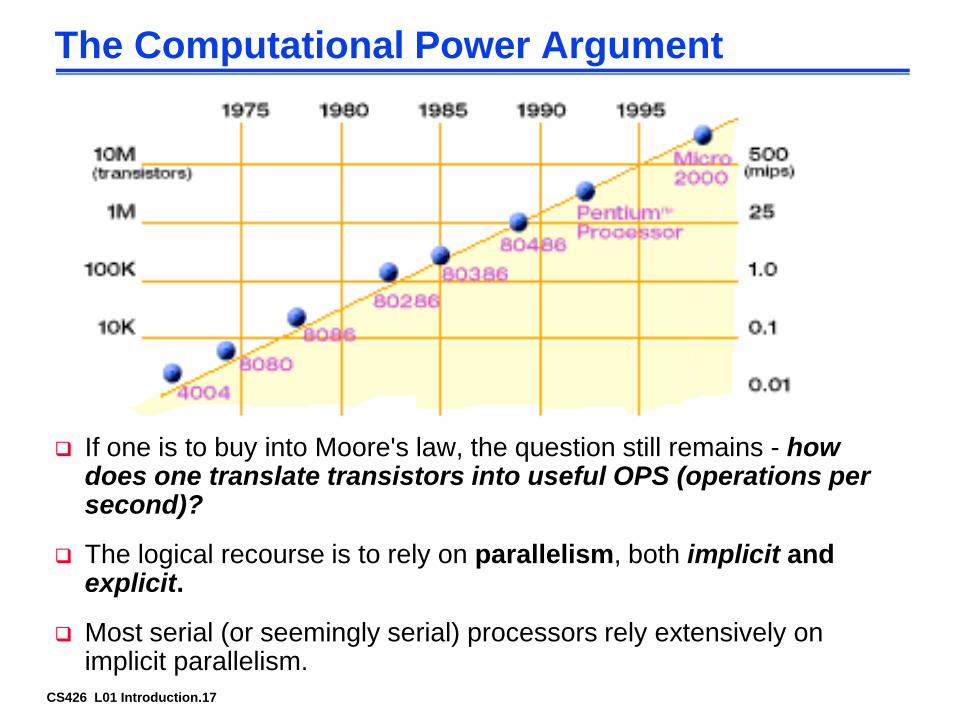
CS426 L01 Introduction.17
The Computational Power Argument
If one is to buy into Moore's law, the question still remains - how does one translate transistors into useful OPS (operations per second)?
The logical recourse is to rely on parallelism, both implicit and explicit.
Most serial (or seemingly serial) processors rely extensively on implicit parallelism.
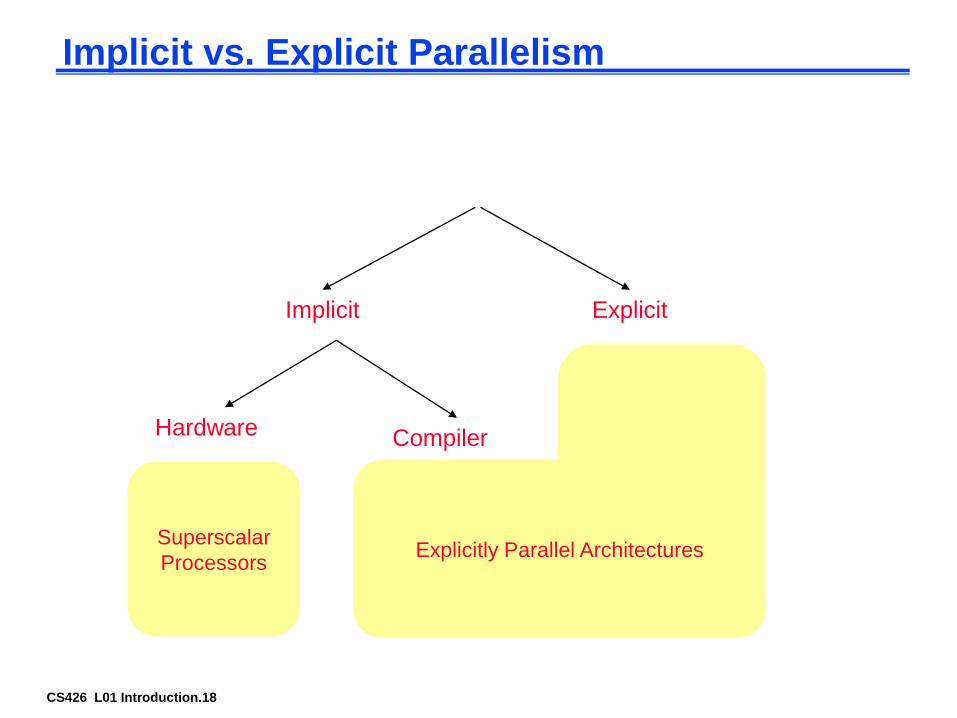
CS426 L01 Introduction.18
Implicit vs. Explicit Parallelism
Implicit Explicit
Hardware Compiler
Superscalar
Processors Explicitly Parallel Architectures
CS426 L01 Introduction.19
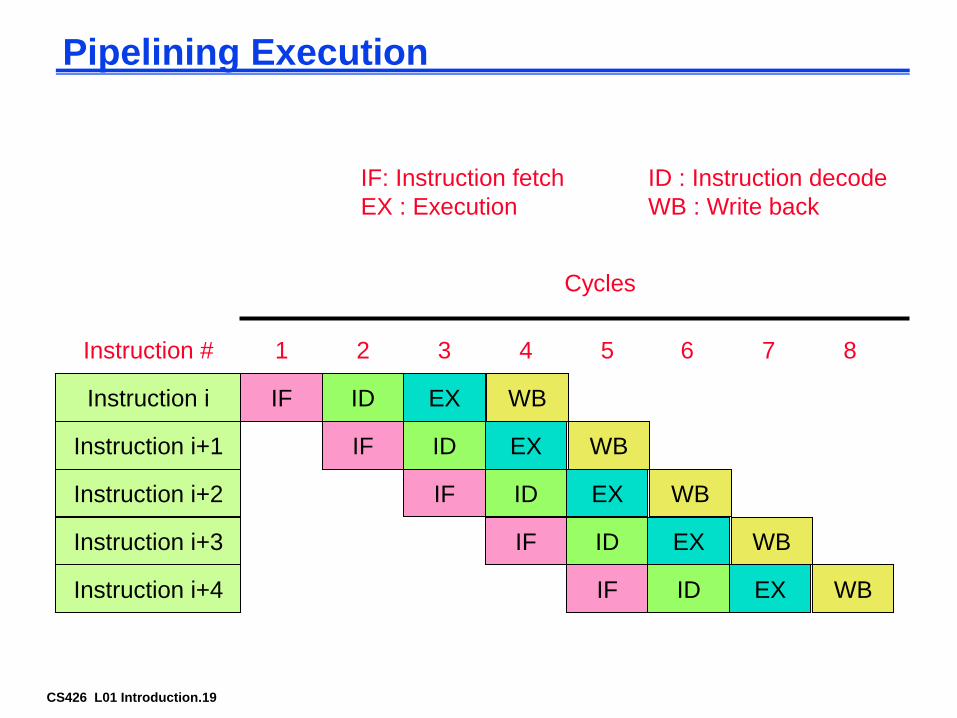
Pipelining Execution
Instruction i IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
Instruction i+1
Instruction i+2
Instruction i+3
Instruction i+4
Instruction # 1 2 3 4 5 6 7 8
Cycles
IF: Instruction fetch ID : Instruction decode
EX : Execution WB : Write back
CS426 L01 Introduction.20
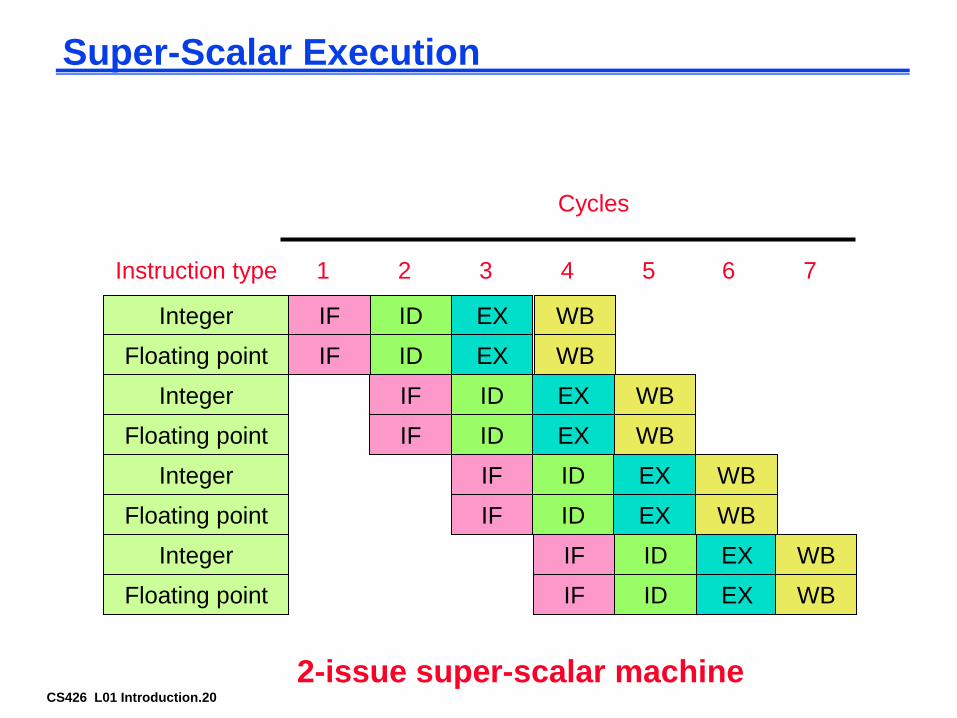
Super-Scalar Execution
Integer IF ID EX WB
Instruction type 1 2 3 4 5 6 7
Cycles
Floating point IF ID EX WB
Integer
Floating point
Integer
Floating point
Integer
Floating point
IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
2-issue super-scalar machine
CS426 L01 Introduction.21
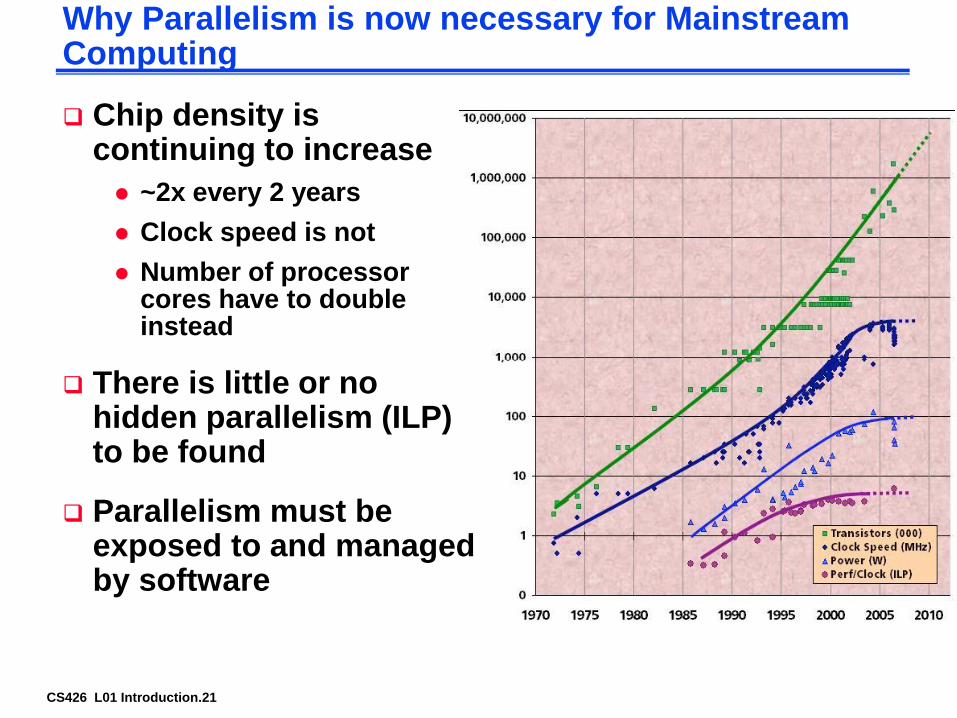
Why Parallelism is now necessary for Mainstream Computing
Chip density is continuing to increase
~2x every 2 years
Clock speed is not
Number of processor cores have to double instead
There is little or no hidden parallelism (ILP) to be found
Parallelism must be exposed to and managed by software

CS426 L01 Introduction.22
Fundamental limits on Serial Computing: “Walls”
Power Wall: Increasingly, microprocessor performance is limited by achievable power dissipation rather than by the number of available integrated-circuit resources (transistors and wires). Thus, the only way to significantly increase the performance of microprocessors is to improve power efficiency at about the same rate as the performance increase.
CS426 L01 Introduction.23
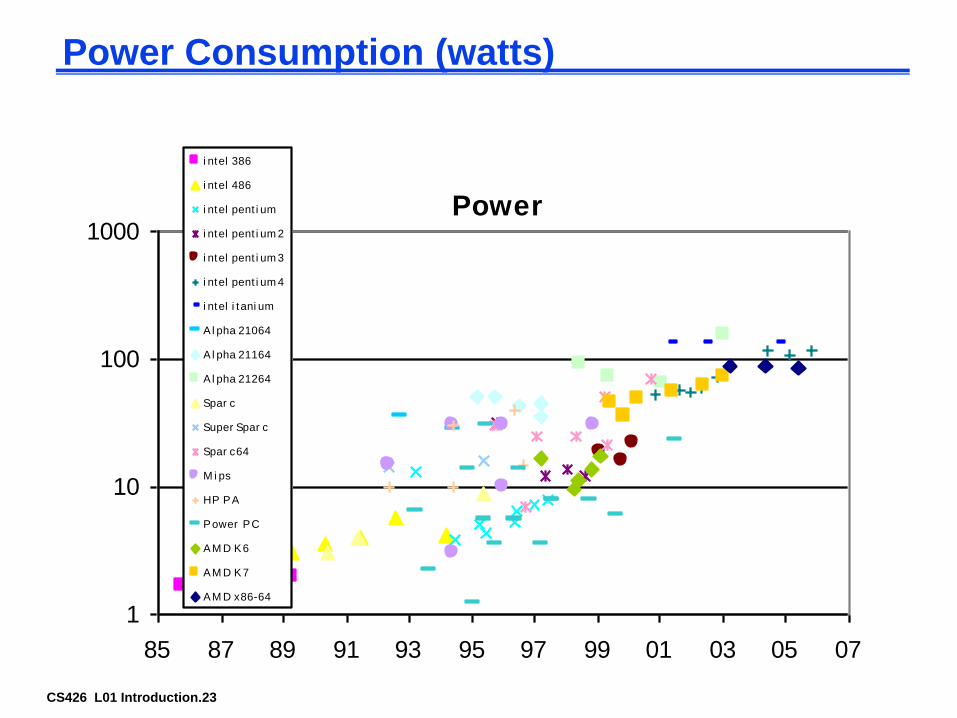
Power Consumption (watts)
Power
1
10
100
1000
85 87 89 91 93 95 97 99 01 03 05 07
i ntel 386
i ntel 486
i ntel pent i um
i ntel pent i um 2
i ntel pent i um 3
i ntel pent i um 4
i ntel i tani um
Al pha 21064
A l pha 21164
A l pha 21264
Spar c
Super Spar c
Spar c64
M i ps
HP PA
Power PC
AM D K6
AM D K7
AM D x86-64

CS426 L01 Introduction.24
Parallelism Saves Power
Power = (Capacitance) * (Voltage)2 * (Frequency)
Power α (Frequency)3
Baseline example: single 1GHz core with power P
Option A: Increase clock frequency to 2GHz Power = 8P
Option B: Use 2 cores at 1 GHz each Power = 2P
Option B delivers same performance as Option A with 4x less power … provided
software can be decomposed to run in parallel!

CS426 L01 Introduction.25
Fundamental limits on Serial Computing: “Walls”
Frequency Wall: Conventional processors require increasingly deeper instruction pipelines to achieve higher operating frequencies. This technique has reached a point of diminishing returns, and even negative returns if power is taken into account.
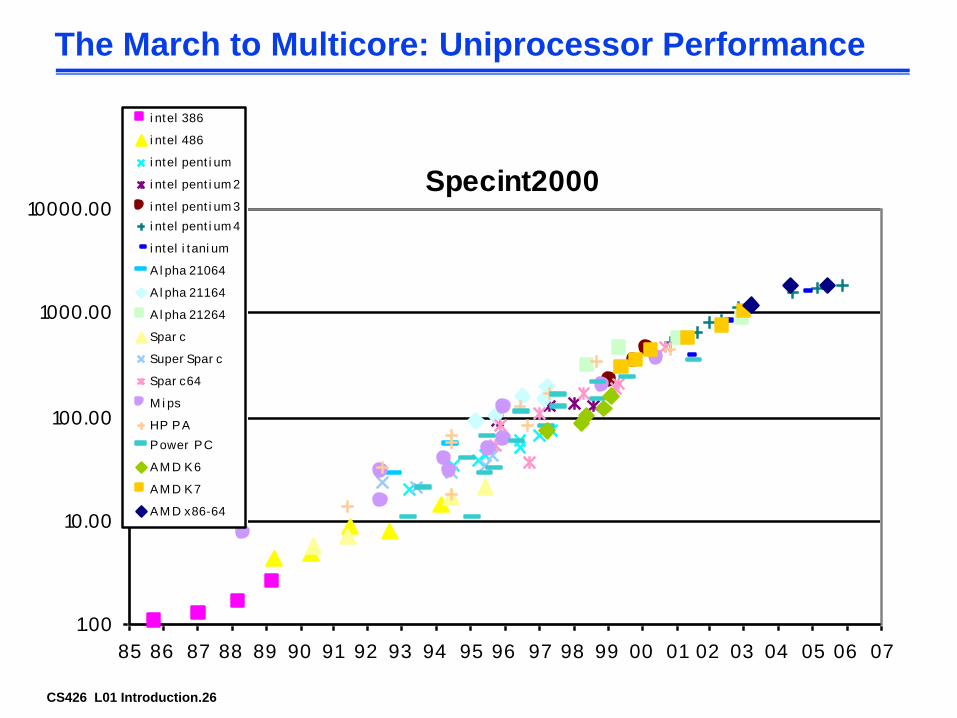
CS426 L01 Introduction.26
The March to Multicore: Uniprocessor Performance
Specint2000
1.00
10.00
100.00
1000.00
10000.00
85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 00 01 02 03 04 05 06 07
i ntel 386
i ntel 486
i ntel pent i um
i ntel pent i um 2
i ntel pent i um 3
i ntel pent i um 4
i ntel i tani um
Al pha 21064
A l pha 21164
A l pha 21264
Spar c
Super Spar c
Spar c64
M i ps
HP PA
Power PC
AM D K6
AM D K7
AM D x86-64
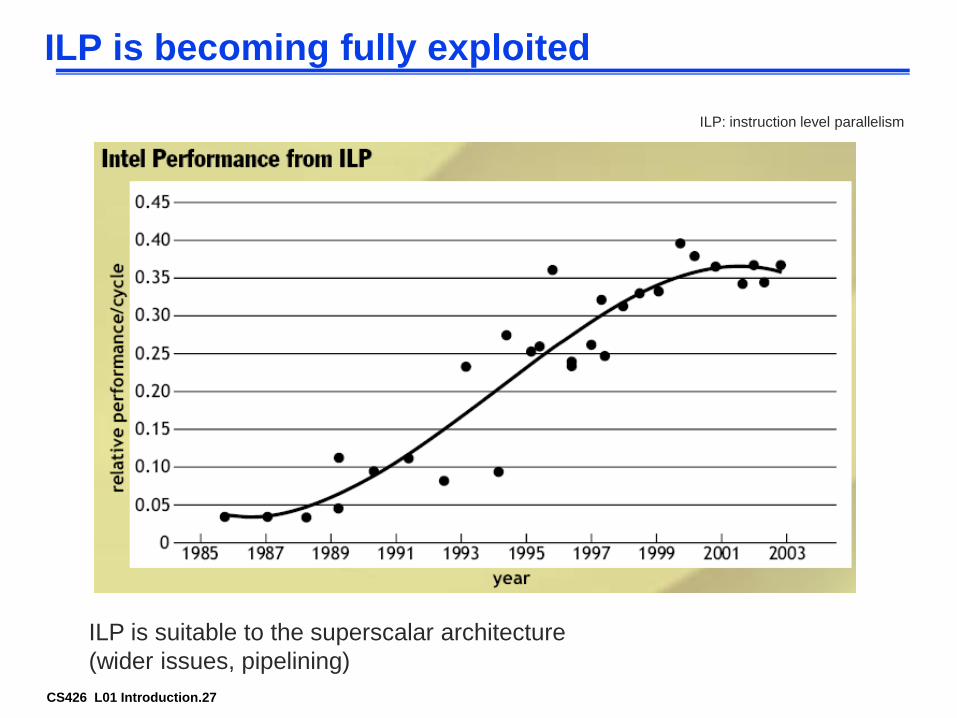
CS426 L01 Introduction.27
ILP is becoming fully exploited
ILP is suitable to the superscalar architecture
(wider issues, pipelining)
ILP: instruction level parallelism

CS426 L01 Introduction.28
Fundamental limits on Serial Computing: “Walls”
Memory Wall: On multi-gigahertz symmetric processors --- even those with integrated memory controllers --- latency to DRAM memory is currently approaching 1,000 cycles. As a result, program performance is dominated by the activity of moving data between main storage (the effective-address space that includes main memory) and the processor.
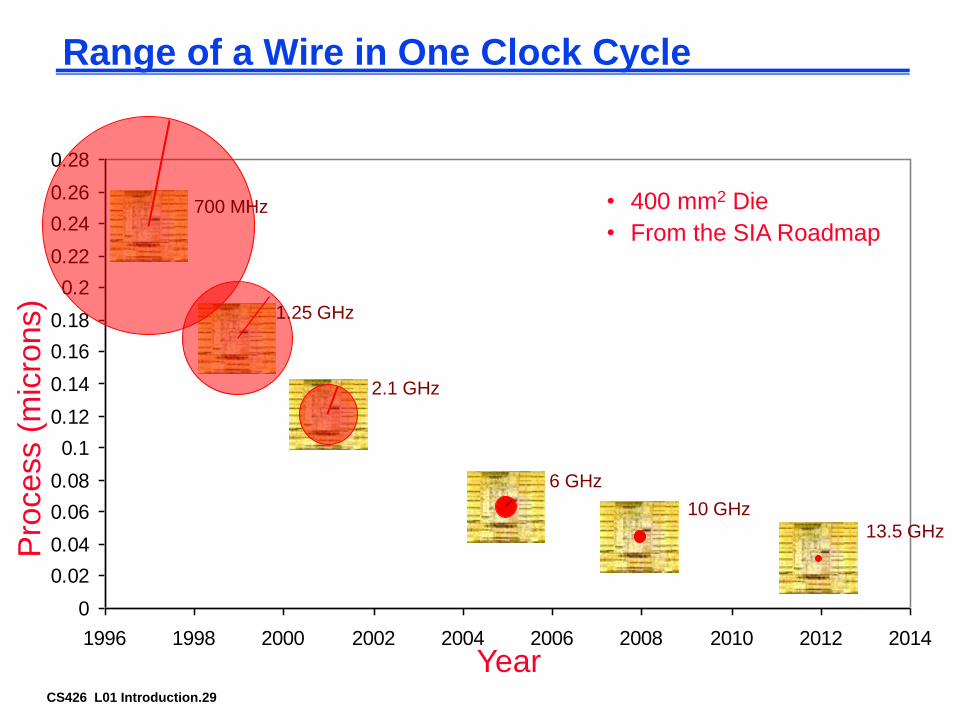
CS426 L01 Introduction.29
Range of a Wire in One Clock Cycle
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0.22
0.24
0.26
0.28
1996 1998 2000 2002 2004 2006 2008 2010 2012 2014
Year
Pro
ce
ss (
mic
ron
s)
700 MHz
1.25 GHz
2.1 GHz
6 GHz
10 GHz
13.5 GHz
• 400 mm2 Die
• From the SIA Roadmap
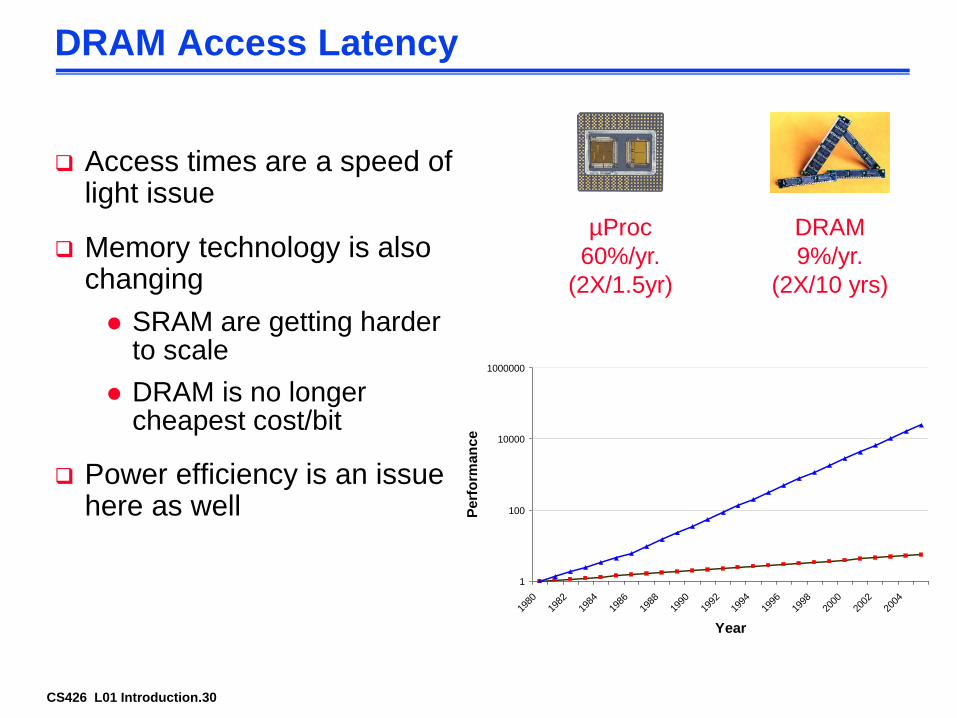
CS426 L01 Introduction.30
DRAM Access Latency
Access times are a speed of light issue
Memory technology is also changing
SRAM are getting harder to scale
DRAM is no longer cheapest cost/bit
Power efficiency is an issue here as well
1
100
10000
1000000
1980
1982
1984
1986
1988
1990
1992
1994
1996
1998
2000
2002
2004
Year
Perf
orm
an
ce
µProc
60%/yr.
(2X/1.5yr)
DRAM
9%/yr.
(2X/10 yrs)

CS426 L01 Introduction.31
Important Issues in parallel computing
Task/Program Partitioning.
How to split a single task among the processors so that each processor performs the same amount of work, and all processors work collectively to complete the task.
Data Partitioning.
How to split the data evenly among the processors in such a way that processor interaction is minimized.
Communication/Arbitration.
How we allow communication among different processors and how we arbitrate communication related conflicts.

CS426 L01 Introduction.32
Challenges
Design of parallel computers so that we resolve the above issues.
Design, analysis and evaluation of parallel algorithms run on these machines.
Portability and scalability issues related to parallel programs and algorithms
Tools and libraries used in such systems.

CS426 L01 Introduction.33
Units of Measure in HPC
High Performance Computing (HPC) units are:
Flop: floating point operation
Flops/s: floating point operations per second
Bytes: size of data (a double precision floating point number is 8)
Typical sizes are millions, billions, trillions…
Mega Mflop/s = 106 flop/sec Mbyte = 220 = 1048576 ~ 106 bytes
Giga Gflop/s = 109 flop/sec Gbyte = 230 ~ 109 bytes
Tera Tflop/s = 1012 flop/sec Tbyte = 240 ~ 1012 bytes
Peta Pflop/s = 1015 flop/sec Pbyte = 250 ~ 1015 bytes
Exa Eflop/s = 1018 flop/sec Ebyte = 260 ~ 1018 bytes
Zetta Zflop/s = 1021 flop/sec Zbyte = 270 ~ 1021 bytes
Yotta Yflop/s = 1024 flop/sec Ybyte = 280 ~ 1024 bytes
• See www.top500.org for current list of fastest machines
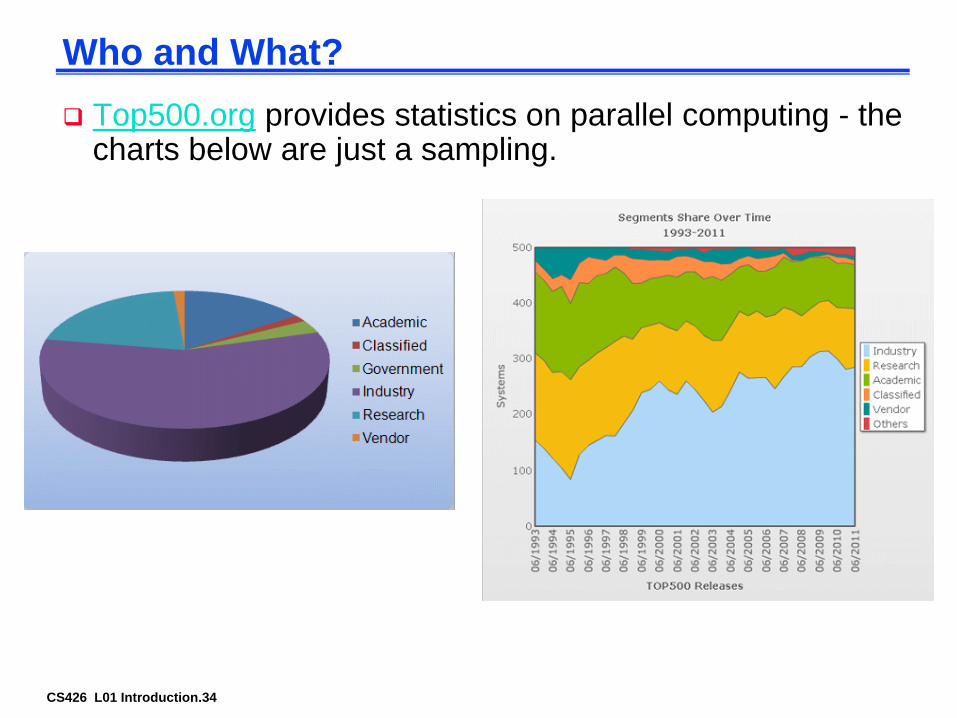
CS426 L01 Introduction.34
Who and What?
Top500.org provides statistics on parallel computing - the charts below are just a sampling.
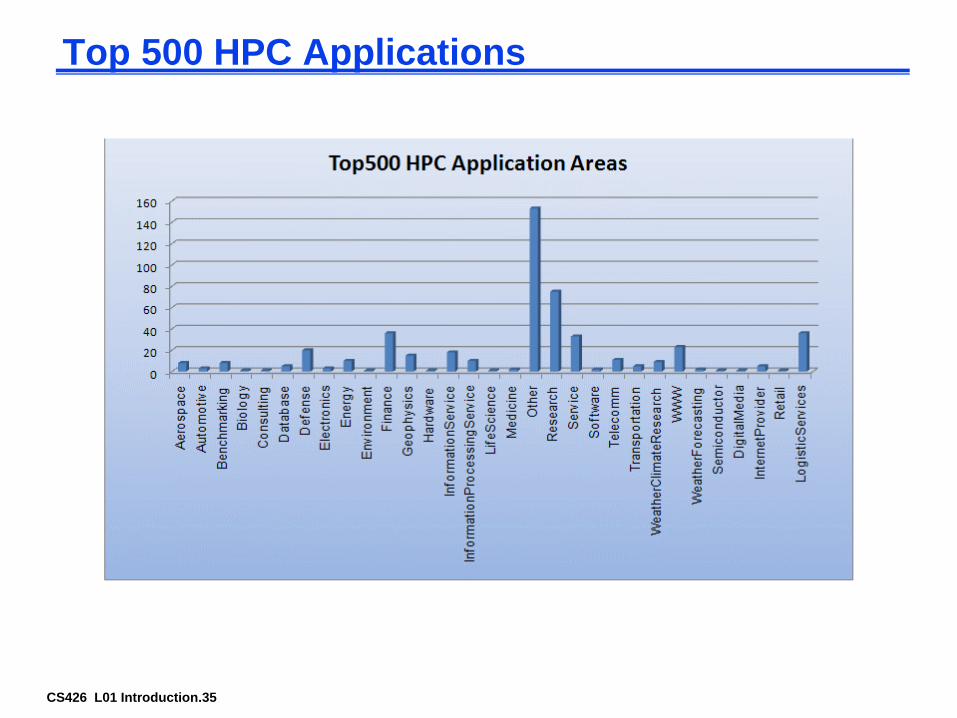
CS426 L01 Introduction.35
Top 500 HPC Applications
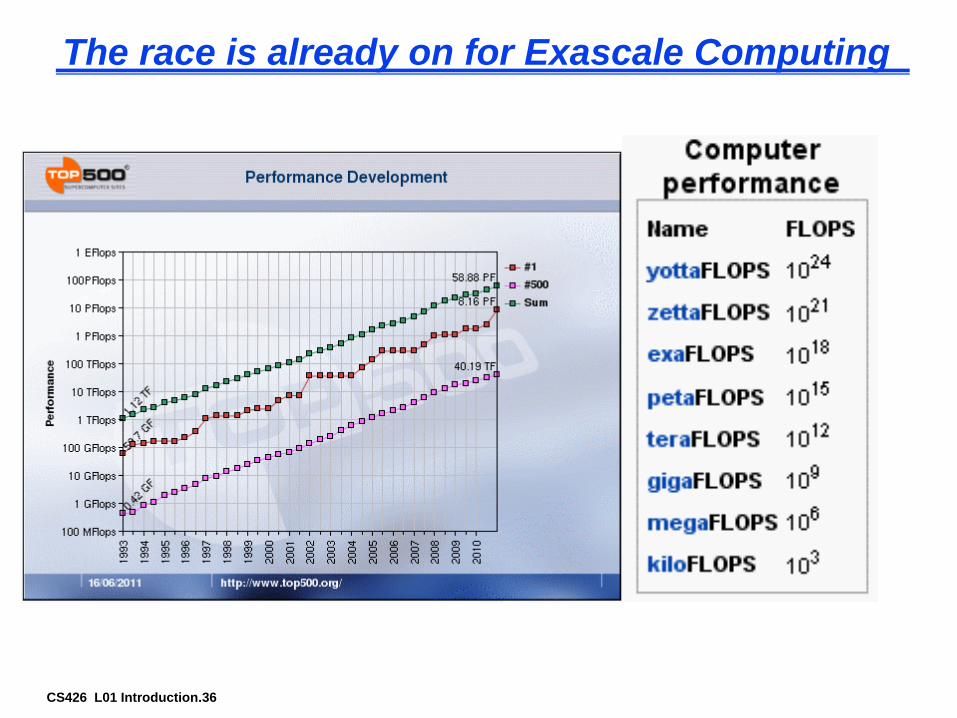
CS426 L01 Introduction.36
The race is already on for Exascale Computing

CS426 L01 Introduction.37
37
What is a parallel computer?
Parallel algorithms allow the efficient programming of parallel computers.
This way the waste of computational resources can be avoided.
Parallel computer v.s. Supercomputer
supercomputer refers to a general-purpose computer that can solve computational intensive problems faster than traditional computers.
A supercomputer may or may not be a parallel computer.

CS426 L01 Introduction.38
Parallel Computers: Past and Present
1980’s Cray supercomputer
20-100 times faster than other computers(main frames, minicomputers) in use.
The price of supercomputer is 10 times other computers
1990’s “Cray”-like CPU is 2-4 times as fast as a microprocessor.
The price of supercomputer is 10-20 times a microcomputer
Make no sense
The solution to the need for computational power is a massively parallel computers, where tens to hundreds of commercial off-the-shelf processors are used to build a machine whose performance is much greater than that of a single processor.
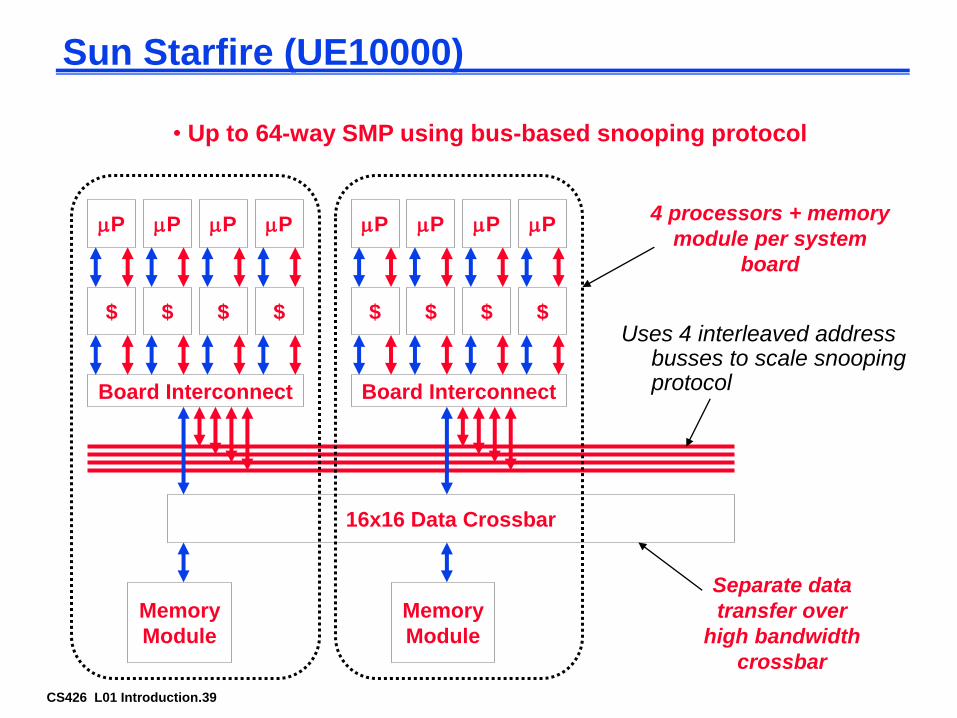
CS426 L01 Introduction.39
Sun Starfire (UE10000)
Uses 4 interleaved address busses to scale snooping protocol
16x16 Data Crossbar
Memory
Module
Board Interconnect
P
$
P
$
P
$
P
$
Memory
Module
Board Interconnect
P
$
P
$
P
$
P
$
4 processors + memory
module per system
board
• Up to 64-way SMP using bus-based snooping protocol
Separate data
transfer over
high bandwidth
crossbar
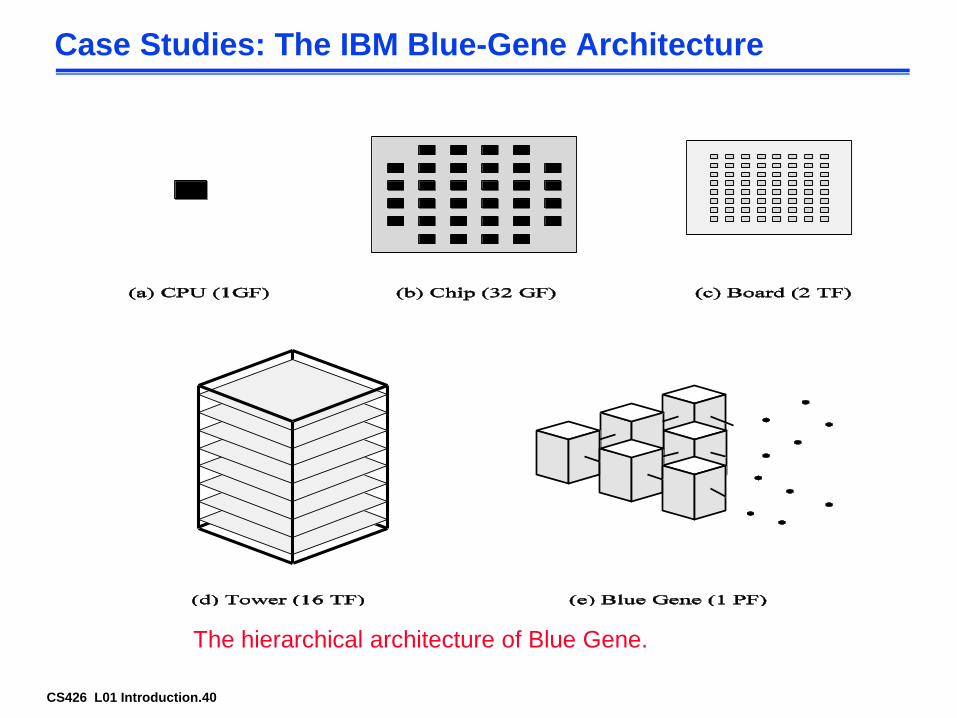
CS426 L01 Introduction.40
Case Studies: The IBM Blue-Gene Architecture
The hierarchical architecture of Blue Gene.

CS426 L01 Introduction.41
Next Week
Parallel Programming Platforms