crossing the chasm: sneaking a parallel file system into hadoop
TRANSCRIPT

Crossing the Chasm: Sneaking a parallel file system
into Hadoop
Wittawat TantisirirojSwapnil Patil, Garth Gibson
PARALLEL DATA LABORATORYCarnegie Mellon University

In this work …• Compare and contrast large storage system
architectures• Internet services • High performance computing
• Can we use a parallel file system for Internet service applications?• Hadoop, an Internet service software stack • HDFS, an Internet service file system for Hadoop• PVFS, a parallel file system
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 2

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 3
Today’s Internet services• Applications are becoming data-intensive
• Large input data set (e.g. the entire web)• Distributed, parallel application execution
• Distributed file system is a key component• Define new semantics for anticipated workloads
– Atomic append in Google FS – Write-once in HDFS
• Commodity hardware and network– Handle failures through replication

The HPC world• Equally large applications
• Large input data set (e.g. astronomy data)• Parallel execution on large clusters
• Use parallel file systems for scalable I/O• e.g. IBM’s GPFS, Sun’s Lustre FS, PanFS, and
Parallel Virtual File System (PVFS)
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 4

Why use parallel file systems?• Handle a wide variety of workloads
• High concurrent reads and writes• Small file support, scalable metadata
• Offer performance vs. reliability tradeoff• RAID-5 (e.g., PanFS)• Mirroring• Failover (e.g., LustreFS)
• Standard Unix FS interface & POSIX semantics• pNFS standard (NFS v4.1)
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 5

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 6
OutlineA basic shim layer & preliminary evaluation
• Three add-on features in a shim layer• Evaluation

HDFS & PVFS: high level design• Meta-data servers
• Store all file system metadata • Handle all metadata operations
• Data servers• Store actual file system data• Handle all read and write operations
• Files are divided into chunks• Chunks of a file are distributed across servers
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 7

PVFS shim layer under Hadoop
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 8
Hadoop applications
Hadoop framework
Hadoop applications
Hadoop framework
Extensible file system API
Hadoop applications
Hadoop framework
Extensible file system API
HDFS client library
Hadoop applications
HDFS servers
ClientServer
Hadoop framework
Extensible file system API
HDFS client library
Hadoop applications
Unmodified PVFS client library (C)
Unmodified PVFS serversHDFS servers
ClientServer
Hadoop framework
Extensible file system API
PVFS shim layerHDFS client library
Hadoop applications
Unmodified PVFS client library (C)
Forward requests to and respond from PVFS client library using Java Native Interface (JNI)
Unmodified PVFS serversHDFS servers
ClientServer

Preliminary Evaluation• Text search (“grep”)
• common workloads in Internet service applications
• Search for a rare pattern in 100-byte records• 64GB data set• 32 nodes• Each node servers as storage and compute nodes
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 9

Vanilla PVFS is disappointing …
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 10
2.5 times slower

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 11
Outline• A basic shim layer & preliminary evaluation
Three add-on features in a shim layerReadahead buffer
• File layout information• Replication
• Evaluation

Read operation in Hadoop• Typical read workload:
• Small (less than 128 KB)• Sequential through an entire chunk
• HDFS prefetches an entire chunk• No cache coherence issue with its write-once
semantic
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 12

Readahead buffer• PVFS has no client buffer cache
• Avoid a cache coherence issue with concurrent writes
• Readahead buffer can be added to PVFS shim layer• In Hadoop, a file can become immutable
after it is closed• No need for cache coherence mechanism
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 13

PVFS with 4MB buffer
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 14
still quite slow

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 15
Outline• A basic shim layer & preliminary evaluation
Three add-on features in a shim layer• Readahead buffer
File layout information• Replication
• Evaluation

Collocation in Hadoop• File layout information
• Describe where chunks are located
• Collocate computation and data• Ship computation to where data is located• Reduce network traffic
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 16
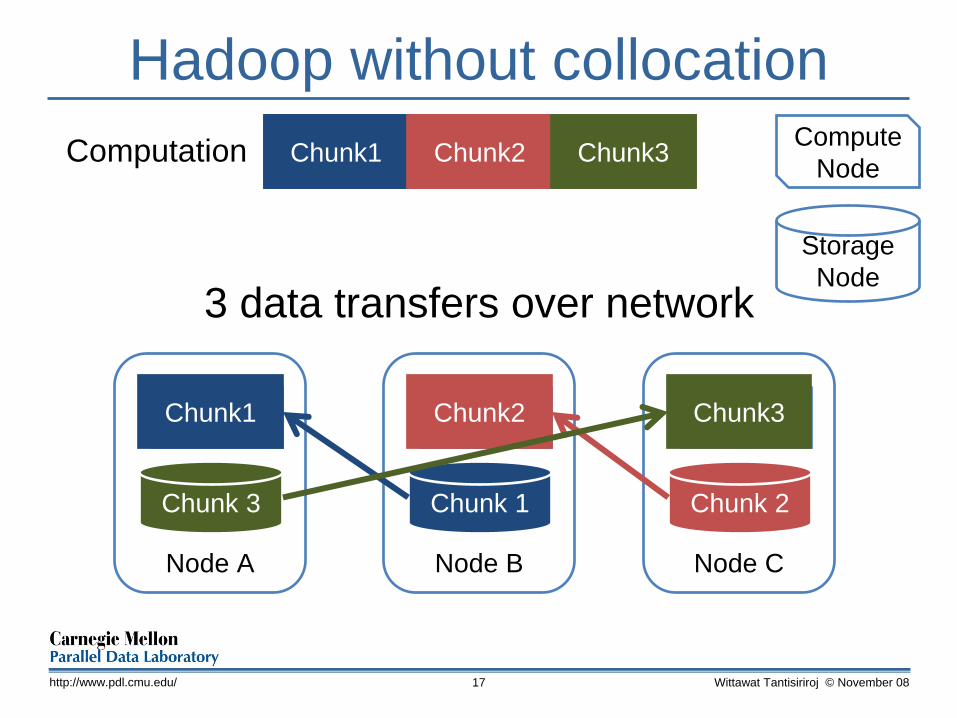
Hadoop without collocation
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 17
Node B
Chunk 1
Node C
Chunk 2
Node A
Chunk 3
Chunk1 Chunk2 Chunk3Computation Chunk1 Chunk2 Chunk3 ComputeNode
StorageNode
3 data transfers over network
Chunk1 Chunk2 Chunk3

Hadoop with collocation
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 18
Node B
Chunk 1
Node C
Chunk 2
Node A
Chunk 3
Chunk1 Chunk2 Chunk3Chunk1 Chunk2 Chunk3 ComputeNode
no data transfer over network
Chunk1Chunk3 Chunk2
Computation
StorageNode

Expose file layout information• File layout information in PVFS
• Stored as extended attributes• Different format from Hadoop format
• A shim layer converts file layout information from PVFS format to Hadoop format• Enable Hadoop to collocate computation and data
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 19

PVFS with file layout information
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 20
comparable performance

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 21
Outline• A basic shim layer & preliminary evaluation
Three add-on features in a shim layer• Readahead buffer• File layout information
Replication• Evaluation

Replication in HDFS• Rack-awareness replication
• By default, 3 copies for each file (triplication)1.Write to a local storage node2.Write to a storage node in the local rack3.Write to a storage node in the other rack
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 22

Replication in PVFS• No replication in the public release of PVFS• Rely on hardware based reliability solutions
• Per server RAID inside logical storage devices
• Replication can be added in a shim layer• Write each file to three servers• No reconstruction/recovery in the prototype
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 23

PVFS with replication
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 24
Hadoop framework
Extensible file system API
PVFS shim layer
Hadoop applications
Hadoop framework
Extensible file system API
PVFS shim layer
Hadoop applications
Unmodified PVFS client library (C)
Hadoop framework
Extensible file system API
PVFS shim layer
Hadoop applications
Unmodified PVFS client library (C)
Unmodified PVFS server
Unmodified PVFS server
Unmodified PVFS server

PVFS shim layer under Hadoop
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 25
Hadoop framework
Extensible file system API
PVFS shim layerHDFS client library
Hadoop applications
Unmodified PVFS client library (C)
Unmodified PVFS serversHDFS servers
ClientServer
Hadoop framework
Extensible file system API
PVFS shim layerHDFS client library
Hadoop applications
Unmodified PVFS client library (C)
PVFS shim layer
Readahead buffer
File layout info
Replication
Unmodified PVFS serversHDFS servers
ClientServer
~1,700 lines of code

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 26
Outline• A basic shim layer & preliminary evaluation• Three add-on features in a shim layer
EvaluationMicro-benchmark (non MapReduce)
• MapReduce benchmark

Micro-benchmark• Cluster configuration
• 16 nodes• Pentium D dual-core 3.0GHz• 4 GB Memory• One 7200 rpm SATA 160 GB (8 MB buffer)• Gigabit Ethernet
• Use file system API directly without Hadoop involvement
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 27

N clients, each reads 1/N of single file
• Round-robin file layout in PVFS helps avoid contention
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 28

Why is PVFS better in this case?• Without scheduling, clients read in a uniform pattern
• Client1 reads A1 then A4• Client2 reads A2 then A5• Client3 reads A3 then A6
• PVFS• Round-robin
placement• HDFS
• Randomplacement
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 29
A1A3
A2A5
A4A6
A1A4
A2A5
A3A6
Contention
A1A3
A2A5
A4A6
A1A4
A2A5
A3A6

HDFS with Hadoop’s scheduling• Example 1:
• Client1 reads A1 then A4• Client2 reads A2 then A5• Client3 reads A6 then A3
• Example 2:• Client1 reads A1 then A3• Client2 reads A2 then A5• Client3 reads A4 then A6
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 30
A1A3
A2A5
A4A6
A1A3
A2A5
A4A6
A1A3
A2A5
A4A6
A1A3
A2A5
A4A6

Read with Hadoop’s scheduling
• Hadoop’s scheduling can mask a problem with a non-uniform file layout in HDFS
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 31

N clients write to n distinct files
• By writing one of three copies locally, HDFS write throughout grows linearly
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 32

Concurrent writes to a single file
• By allowing concurrent writes in PVFS, “copy” completes faster by using multiple writers
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 33

Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 34
Outline• A basic shim layer & preliminary evaluation• Three add-on features in a shim layer
Evaluation• Micro-benchmark (non MapReduce)
MapReduce benchmark

MapReduce benchmark setting• Yahoo! M45 cluster
• Use 50-100 nodes • Xeon quad-core 1.86 GHz with 6GB Memory• One 7200 rpm SATA 750 GB (8 MB buffer)• Gigabit Ethernet
• Use Hadoop framework for MapReduce processing
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 35

MapReduce benchmark• Grep: Search for a rare pattern in hundred
million 100-byte records (100GB)
• Sort: Sort hundred million 100-byte records (100GB)
• Never-Ending Language Learning (NELL): (J. Betteridge, CMU) Count the numbers of selected phrases in 37GB data-set
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 36

Read-Intensive Benchmark
• PVFS’s performance is similar to HDFS
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 37

Write-Intensive Benchmark
• By writing one of three copies locally, HDFS does better than PVFS
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 38

Summary• PVFS can be tuned to deliver promising
performance for Hadoop applications• Simple shim layer in Hadoop• No modification to PVFS
• PVFS can expose file layout information• Enable Hadoop to collocate computation and data
• Hadoop application can benefit from concurrent writing supported by parallel file systems
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 39

Acknowledgements• Sam Lang and Rob Ross for help with PVFS
internals• Yahoo! for the M45 cluster• Julio Lopez for help with M45 and Hadoop• Justin Betteridge, Le Zhao, Jamie Callan,
Shay Cohen, Noah Smith, U Kang and Christos Faloutsos for their scientific applications
Wittawat Tantisiriroj © November 08http://www.pdl.cmu.edu/ 40