crawling part 2. expected schedule tonight quiz (~30 minutes) – in blackboard. a bit more than a...
TRANSCRIPT

Crawling
Part 2

2
Expected schedule tonight• Quiz (~30 minutes)
– In Blackboard. A bit more than a quiz.
• Review of project plans (~15 minutes)• Lab on crawling (30 - 45 minutes)
– Visualizing crawl– Using a basic crawler tool
• Explore the department pages• Explore some other sites• Highlight, extract and save elements, etc.
• Python for fetching web pages (~30 minutes)– Spot check activity
• Exception handling (~30 minutes)– Examples– Spot check activity

3
Next week – 9/20
• First time I am gone• Nakul (our class assistant) will be here• Lab exercises– Create database– Deal with messy HTML (Beautiful Soup)
• Introduction of Nutch– Full-featured open source crawler that is widely used for
real applications• As time allows, begin work on your crawler in class
with help as needed from Nakul– Complete as homework and submit through blackboard

4
9/27• I will be in Berlin for a conference on digital
libraries• We will have an online class– Timed quiz to begin at the normal class time.– Presentation: What to do with a collection of
documents after you have gathered them – An introduction to Indexing and Information Retrieval• There will be exercises to do, embedded in the
presentation. There will be places to put the exercise results in Blackboard.

5
Visualizing Crawl• We looked at the architecture of a crawl.• Now we will see what a crawl looks like as
it is happening• We will use a tool to direct a crawl –
WebSphinx– Created at Carnegie Mellon– Now available at SourceForge– This is not a very robust application and it
may be flaky, but we can see some interesting things by using it.

6
WebSphinx• See
http://www.cs.cmu.edu/~rcm/websphinx/
• and http://sourceforge.net/projects/websphinx/

7
WebSphinx lab• Download the software• Do a simple crawl: – Crawl: the subtree– Starting URLs:
• Pick a favorite spot. Don’t all use the same one (Politeness)
– Action: none– Press Start– Watch the pattern of links emerging– When crawl stops, click on the statistics tab.
• How many threads?• How many links tested? , links in queue?• How many pages visited? Pages/second?• Note memory use

8
Advanced WebSphinx• Default is depth-first crawl• Now do an advanced crawl:– Advanced
• Change Depth First to Breadth First• Compare statistics• Why is Breadth First memory intensive
– Still in Advanced, choose Pages tab• Action: Highlight, choose color• URL *new*

9
Just in case …
Crawl site: http://www.acm.org
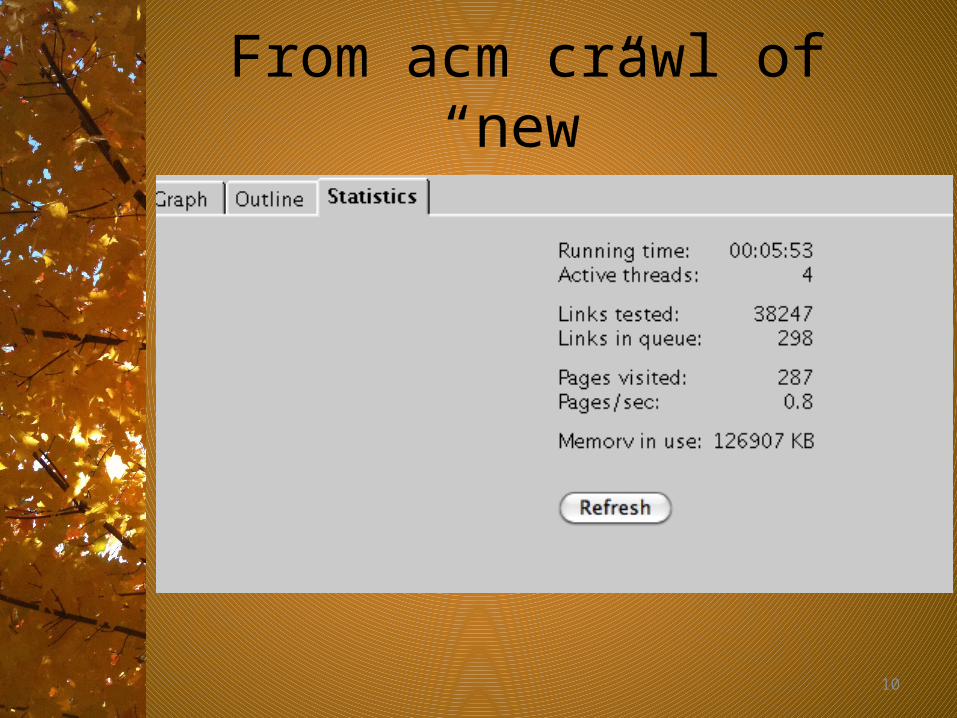
10
From acm crawl of “new”

11
Using WebSphinx to capture • Action: extract• HTML tag expression: <img>• as HTML to <file name>– give the file name the extension html as this
does not happen automatically– click the button with … to show where to save
the file• on Pages: All Pages• Start• Example results: acm-images.html

12
Python module for web access• urllib2
– Note – this is for Python 2.x, not Python 3• Python 3 splits the urllib2 materials over several modules
– import urllib2– urllib2.urlopen(url [,data][, timeout])
• Establish a link with the server identified in the url and send either a GET or POST request to retrieve the page.
• The optional data field provides data to send to the server as part of the request. If the data field is present, the HTTP request used is POST instead of GET– Use to fetch content that is behind a form, perhaps a login page– If used, the data must be encoded properly for including in an HTTP
request. See http://www.w3.org/TR/html4/interact/forms.html#h-17.13.4.1
• timeout defines time in seconds to be used for blocking operations such as the connection attempt. If it is not provided, the system wide default value is used.http://docs.python.org/library/urllib2.html

13
URL fetch and use• urlopen returns a file-like object with
methods:– Same as for files: read(), readline(),fileno(),
close()– New for this class: • info() – returns meta information about the
document at the URL• getcode() – returns the HTTP status code sent with
the response (ex: 200, 404)• geturl() – returns the URL of the page, which may
be different from the URL requested if the server redirected the request

14
URL info• info() provides the header information that
http returns when the HEAD request is used.• ex:
>>> print mypage.info()Date: Mon, 12 Sep 2011 14:23:44 GMTServer: Apache/1.3.27 (Unix)Last-Modified: Tue, 02 Sep 2008 21:12:03 GMTETag: "2f0d4-215f-48bdac23"Accept-Ranges: bytesContent-Length: 8543Connection: closeContent-Type: text/html

15
URL status and code
>>> print mypage.getcode()200
>>> print mypage.geturl()http://www.csc.villanova.edu/~cassel/

16
Spot check• Work with a partner– Create a file with at least 3 good urls– For each url,• fetch the page• Create a file to hold the content of the page• for each line on the page
– strip off the html code– write the remaining content to the file– if there is a link on the page, add it to a list of links
– Print out the list of links– Print out the number of lines in each file,
with the file name
Most of this was done for homework.

17
Messy HTML• So far, we have assumed that the HTML
of a page is good. – Browsers may be forgiving. – Human and computerized html generators
make mistakes.• Tools for dealing with imperfect html
include Beautiful Soup and NekoHTML.– Beautiful Soup is Python, NekoHTML is Java– Beautiful Soup – next week

18
Exceptions: How to Deal with Error Situations
number = 0while not 1 <= number <= 10: try: number= int(raw_input('Enter number from 1 to 10: '))
if not 1 <= number <= 10:print 'Your number must be from 1 to 10:'
except ValueError: print 'That is not a valid integer.'
Here: recognize an error condition and deal with itIf the named error occurs, the “except” clause is executed and the loop is terminated.
book slide

19
Exceptions (continued)
• What if a negative is entered for square root?
• Can raise an exception when something unusual occurs.
def sqrE(number): if number < 0: raise ValueError('number must be positive') #do square root code as before
Note: ValueError is an existing, defined error classbook slide

20
Exceptions (continued)
#What if value entered is not a number?def sqrtF(number): if not isinstance(number, (int, float)):
raise TypeError('number must be numeric') if number < 0: raise ValueError('number must be positive') #do square root code as before
book slide

21
How Much Type Checking is Enough?
• A function with little type checking of its parameters may be difficult to diagnose errors.
• A function with much type checking of its parameters will be harder to write and consume more time executing.
• If the function is one that only you will use you may need less type checking.
• A function written for others should have more type checking.
book slide

22
Checking for failed url fetchimport urllib2url = raw_input("Enter the URL of the page to fetch: ")try: linecount=0 page=urllib2.urlopen(url) result = page.getcode() if result == 200: for line in page: print line linecount+=1 print page.info() print page.getcode() print "Page contains ",linecount," lines."except: print "\nBad URL: ", url
The except clause is triggered by any error in the try

23
Spot check on Exceptions• In pairs, write python code to do the
following:– Accept input from the keyboard
• Prompt with instructions to enter a number, and to enter some character you choose to end
– Verify that the value read is numeric– Calculate the minimum, maximum and average
of the values read– Terminate reading when a non numeric
character is entered– Print out the values calculated

24
For October 4• Your basic crawler (Individual work)
– Read a seed url– Fetch the page– Extract links from the page
• Put the links on a queue of pages to visit
– Extract the text from the page, stripping off the html code• Deal with possibly bad html• Put the extracted documents in a database for later analysis
– Take the next url from the queue and repeat– How will you deal with robot exclusions?– What will you do about rapid access to a server?– We will do individual presentations of working crawlers
then.