correlation and regression continued…. learning objectives by the end of this lecture, you should...
TRANSCRIPT

Correlation and Regressioncontinued…

Learning Objectives
By the end of this lecture, you should be able to:
– Interpret R2 – Describe the purpose of a residual plot– Define ‘influential’ datapoints– Explain the difference between influential points and outliers– Describe with examples what is meant by a ‘lurking’ variable

Reminder: It’s all about the concepts!
• Remember that the concepts are even more important than the ‘numbers’.
• The reason is that if you don’t really ‘get’ the concepts, the numbers you end up with can be wildly misleading.
• Concepts take more time and work to figure out, and often require repeated reviewing and lots of problems. But… they do come!
• The quizzes will be weighted more towards concepts.

Coefficient of determination: ‘R2’
R2 represents the percentage of
the variation in y (vertical scatter
from the regression line) that can
be explained by changes in x.
x
y
s
srb 1
R2, the coefficient of determination, is simply the square of the correlation
coefficient. However, it gives us another piece of information.

r = -1R2 = 1
Changes in x
explain 100% of
the variations in y.
y can be entirely
predicted for any
given value of x.
Here the change in x only
explains 76% of the change in
y. The rest of the change in y
(the vertical scatter, shown as
red arrows) must be explained
by something other than x.
r = 0.87R2 = 0.76

r = 0.87R2 = 0.76
So R2 is 76%.
In other words, the number of beers that were drunk only explains 76% of the BAC
Any ideas on what that other 24% may be due to???
For example, four different people drank 5 beers. Yet all of them had different BAC levels. In other words, there are clearly other variables in addition to the number of beers that determine the BAC .
One variable that is probably also a major contributer is the person’s blood volume. That is, a very large person who has lots of blood in their body will be less affected by 5 beers than a very small person with much less blood volume. (The concentration of alcohol is lower since the larger volume of blood dilutes it).
That seems to be a pretty big limitation… Anything we can do to try and improve this data?

Now: # beers/weight explains 81% of the variation in blood alcohol content.
Note that even though we have improved to 81%, we must be aware that there are yet more factors that contribute to variations in BAC among individuals.
r =0.7R2 =0.49
Lets change number of beers to number of beers / weight of the drinker and see what happens…
In this plot, # beers only explains 49% of the variation in blood alcohol content.
r =0.9R2 =0.81

Is the data truly linear?
• Recall how with density curves that we thought were showing a Normal distribution, we always followed up with a ‘normal quantile plot’ to help confirm.
• Well, we are fortunate to have a similar plot to help confirm linearity: it is called the ‘residual plot’.
• So: From now on, once you’ve drawn your scatterplot and are “pretty sure” it’s linear, you should follow it up with a residual plot to help confirm.

The distance from each datapoint to the regression line is called the residual. We can take this distance for every datapoint and plot them on a residual plot.
.
Observed (y)
Predicted (ŷ)
Residual Plots
Points above the line have a positive residual.
Points below the line have a negative residual.
The distance between y and y^ is the residual.
The method used to generate a residual plot demonstrated on this slide is for your information only. You do not need to worry about it for quizzes/exams.

If residuals are scattered randomly around 0, chances are your data fit a linear model, was normally distributed, and you didn’t have outliers.
The residual plot is similar in principle to the normal quantile plot we have used to determine if data fits a Normal distribution. In the same way that you should always check a suspected normal distribution by plotting a normal-quantile plot, you should always follow up a suspected linear dataset with a residual plot to confirm that the relationship is indeed linear!
Residual plots are used to confirm that the relationship is linear
This is important!

Residuals are randomly scattered— this supports (but doesn’t guarantee) that our data is linear.
Curved pattern—means the relationship
you are looking at is not linear.
These points are not random - there is
indeed a pattern here. Notice how the
variability increases as you move across
the plot.
If your residual plot is not normal, you should not trust any regression model!(i.e. don’t even bother doing it!)

Outliers and Influential Points
and their effect on regression models

Correlations are calculated using
means and standard deviations, and
thus are NOT resistant to outliers.
As a test, we convert just one datapoint into an outlier.
Notice the dramatic effect on the correlation: from -0.91 to -0.75 !
Outliers can dramatically affect ‘r’
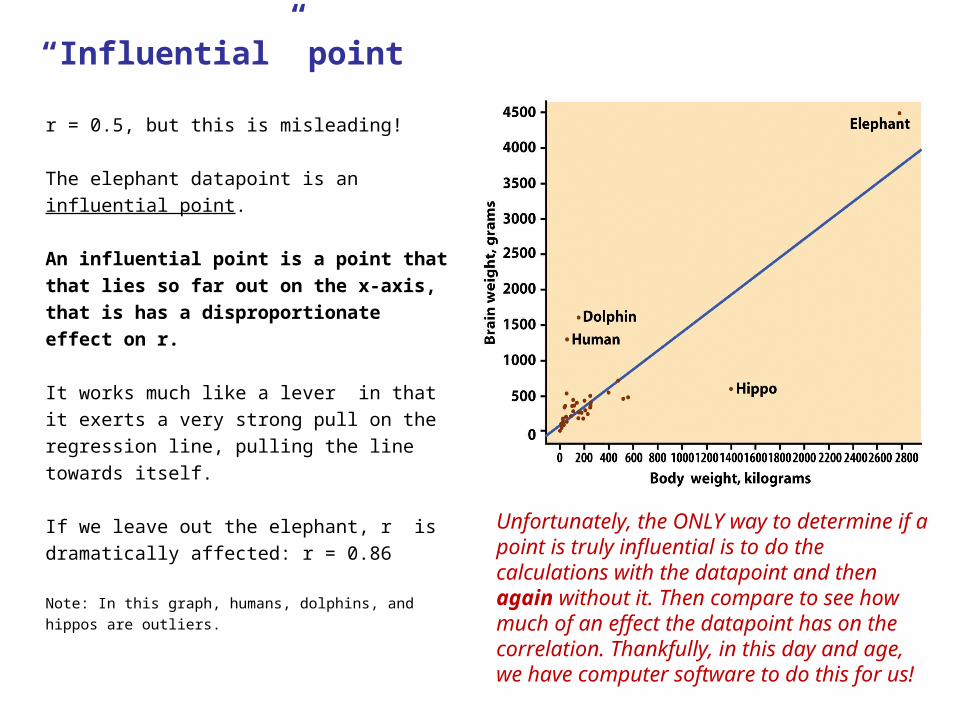
r = 0.5, but this is misleading!
The elephant datapoint is an influential point.
An influential point is a point that that lies so
far out on the x-axis, that is has a
disproportionate effect on r.
It works much like a lever in that it exerts a very
strong pull on the regression line, pulling the line
towards itself.
If we leave out the elephant, r is dramatically
affected: r = 0.86
Note: In this graph, humans, dolphins, and hippos are
outliers.
“Influential” point
Unfortunately, the ONLY way to determine if a point is truly influential is to do the calculations with the datapoint and then again without it. Then compare to see how much of an effect the datapoint has on the correlation. Thankfully, in this day and age, we have computer software to do this for us!

“Outlier” point: observation that lies outside the overall pattern of observations. (e.g. Child 19)
“Influential” point: observation that markedly changes the regression if removed. They do NOT have to be outliers (though they sometimes are). In the plot below, Child 18 is close to the line, and therefore, may not be an outlier.
Don’t confuse “outlier” with “influential”
Child 19 = outlier
Child 18 = influential point
Child 19 is an outlier of the relationship.
Child 18 is way out in the x direction and thus is an influential point.

• OUTLIER: is a point that lies way above or below your regression line. Can mean that you have anomalies in your dataset (valid but unusual results, bad measurements, other anomalies).
• INFLUENTIAL POINT: Observations that are a ways off in the horizontal (x-axis) direction. Can be way off to the right or way off to the left. The key is that it is a ways off from the “rest of the group”. Influentials are often not unusual or abnormal datapoints, but they do have a strong tendency to pull the regression line towards them, thereby changing the slope – sometimes dramatically. In other words, they can significantly affect b1. For this reason, influential points can cause you to end up with a less accurate regression line and formula.
• What do we do about outliers/influentials? As we’ve said repeatedly, how you handle awkward datapoints such as outliers and influential points becomes a very involved topic. For now, the emphasis is on identifying them.
Outlier vs Influential restated

A correlation coefficient and a regression line can be calculated for ANY two datasets.
However, generating a linear regression model on a nonlinear association and using it to
make predictions/conclusions is not only meaningless but misleading.
Remember, “knowing” something – when some of your underlying facts are
incorrect is dangerous – and not just in statistics!!!
Reminder: Always plot your data
So make sure to always plot your data before you run a correlation or regression analysis.
(Is this all starting to sound a bit familiar?)

All four datasets below give:•r ≈ 0.816,
•A regression formula of approximately ŷ = 3 + 0.5x ….

However, the scatterplots show us that correlation/ regression
analysis is highly inappropriate for some of them!
What are your thoughts on each of these datasets?
Moderate linear
association;
regression OK.
Obvious nonlinear
relationship;
regression not OK.
One point deviates
from the highly
linear pattern; this
outlier must be
examined closely
before proceeding.
Or is it??? Remember that we should do a quick residual plot to support our hypothesis that it is indeed linear.

Lurking variables
A lurking variable is a variable not included in the study design, and yet has an effect on the response variable.
Lurking variables can cause us to falsely assume a relationship.
What is the lurking variable in these examples?
Strong positive association between number of firefighters at a fire site and the amount of damage a fire does. Does this mean that by sending fewer firefighters out, we can decrease the amount of damage?
Negative association between moderate amounts of wine drinking and death rates from heart disease in developed nations. So if we start giving out free alcohol at every health physical, we can reduce death rates?

There is quite some variation in BAC for the same number of beers drank. Can you think of one key lurking variable?
The scatter is much smaller now. The weight (i.e. blood
volume) was indeed a lurking variable that was
(significantly) influencing the response variable.
In addition to # of beers, a person’s blood volume is a significant factor determining BAC.
As discussed earlier, we can try changing number of beers to number of beers/weight of the individual.

Even after including the weight of the individual in our model, the R2 is still only 0.81. Can you think of other lurking variables that are affecting the BAC?
• One important example is genetics: Individuals of Asian ancestry typically have lower levels of the enzyme ADH (alcohol dehydrogenase) present in our liver and stomach. ADH is breaks down alcohol. Because of the lower ADH levels, Asians typically will have higher BAC levels then non-Asians.

Factoring in the genetic component just discussed, how might you try to generate an even better (i.e. more accurate) regression model?
• Recall our discussion on modifying a plot so that it breaks down the original dataset into separate categories. In this case, then, a better setup would be to use two separate models for people of Asian v.s. non-Asian ancestry. On this graph, you might use, say, blue dots for Asians, and red dots for non-Asians.

** Make sure you confirm some things before trusting your regression model and using it for predictions/analysis **
Do not use a regression on inappropriate data. Pattern in the residuals Presence of large outliers Check a residual plot! Clumped data falsely appearing linear
Beware of lurking variables.
Avoid extrapolating.
A relationship, even a very strong one, does not itself imply “causation” (more on this in an upcoming lecture).

Pop Quiz: Suppose this dataset was made up entirely of male caucasians of approximately the same age. Would you feel comfortable generating a regression model using this dataset?
• There is an influential point. If we generated the regression model with, and then without this datapoint, we would get two very different formulas. The question, then, is whether or not to exclude this observation from our analysis.
• Because all of the other observations are clustered closely together, and because only one single dataopint is influential, I would probably leave it out. However, if I chose to do so, I would have to be sure and include this fact in any discussion of the results of this study.