corpus linguistics: promises, challenges, and research ... updated.pdf · corpus linguistics:...
TRANSCRIPT

Corpus Linguistics: Promises, Challenges, and Research Directions
Tony McEnery, Lancaster University
13 March 2017

Why are corpus tools important? The set of questions that can be answered given the state of the art in corpus exploitation
The set of questions that can be answered using the next generation of corpus exploitation tools
The set of all questions that could be answered using corpora, given optimal corpus exploitation tools
Note that exactly the same is true of corpora also – composition, annotation and markup.

• Corpus exploitation tools determine and hence enable/limit corpus linguistics.
• So do corpora. • The pseudo-procedure objection to corpus linguistics is
only partially addressed. There are still some research questions which, in principle, might be answered using corpora, but the process of answering them with the tools or the data we have is too time consuming to be practicable, if it is possible at all.
• This talk is about the history of combatting this objection to corpus linguistics.
• Concordancers are used as a shorthand in this talk for corpus exploitation tools
• We will also look at two examples of how corpus linguistics is pushing out beyond what is currently possible

Concordancing – the beginnings
• Hugh of St Cher, 1230
• Roberto Bussa, 1951
• The concordance becomes electronic
• From pseudo-procedure to viable procedure
• From use on selected, highly significant texts to many texts

First Generation Concordancers
• Held on a mainframe
• Single site use
• Not really portable
• But useful!
• Early issues and solutions with mark-up – Latin alphabet bias evident in the issues and solutions
• Café in LOB – café

• Typically working with relatively small corpora – 1 million words is a large corpus in this period
• Yet 1 million words is still small – frequent words may be amenable to study with such data
• But content words in particular are only very partially visible in such datasets

Second generation concordancers
• Enabled by a common platform becoming popular and widely used – the IBM PC in the 1980s/early 1990s.
• This meant that programs became more portable.
• This encouraged the development of interchange standards
• It also encouraged the development of packages that would be used at many sites – LMC, Kaye Concordancer, Micro-OCP

• More people started to use corpora because they could – you no longer needed a friendly computer scientist to help you ‘do’ corpus linguistics
• Issues persisted, however • Limited functionality – concordance, sort, wordlist • Limited mark-up awareness • Limited capacity or a complex indexing process (for
what was still limited capacity) • So first generation concordancers still had a very
important role to play in parallel to second generation concordancers – second generation concordancers had a subset of the abilities of the first
• However, they allowed replicability and the adoption of corpus linguistics more clearly than first generation systems – this was key

• The corpora in this period were still small.
• Some advances in corpus annotation, but the limited mark-up awareness of the programs makes using such corpora difficult.
• Many of these programs have limited memory – some cannot deal with the 1 million word corpora of the period, making the process of analysis yet more limited.

Third generation concordancers
• Starting in the mid-nineties
• Still the paradigm most corpus linguists are working with
• PC/Mac based, yet much more powerful than 2nd generation systems
• Functionality that extends up to and beyond what was available in the first generation
• Systems such as Antconc, MonoConc, Wordsmith and Xaira

Functionality
• Some mark-up awareness
• Cluster/bundle analysis
• Keyword analysis
• Collocation analysis – with choice
• Some inferential statistical analysis
• Able to deal with much larger datasets than second generation system, suitable for most studies
• The Latin bias was finally banished – this saved much reinvention of the wheel and encouraged the further spread of corpus linguistics

• Much more powerful
• Can easily deal with multi-million word corpora
• Scale still limited – in this period corpora grew in size, e.g. the BNC at 100 million words
• Only programs like Xaira could deal with data on the scale and offer mark-up awareness, but the use of that was limited, effectively, to the BNC

The End of the Story?
• Do third generation concordancers end the story of corpus tool development?
• No, for at least three reasons • There are tools from the first generation of
concordancing not generally available in third-generation concordance packages (collocational networks, MD analysis)
• There are techniques that have been developed recently which are not incorporated in contemporary concordancers (e.g. collostructures)

• There are specialised concordancers which, while lacking the range of features available in popular third-generation concordancers such as WordSmith, nonetheless provide tools which are of clear relevance and importance to linguists (e.g. ICECUP)

The 3rd Generation Cannot be the End of the Story
• Talented individuals and limited resources – no large commercial concern has ever poured resources into the issue as they have for accountancy, word-processing or statistical analysis
• The standards we have are superficial – we agree on the forms of annotations, not on their meaning. This limits the reusability of data and the drive for packages to work with meaning rather than form
• The PC, while powerful, was also limited

The Next Generation – the 4th Generation of Concordancers
• Systems such as BNCWeb, CQPWeb and the corpora@BYU systems
• Address three issues
• The limited power of desktop PCs
• Problems arising from non-compatible PC operating systems

PC based 4th Generation Concordancers
• LancsBox
• Increasing PC power and memory permits the processing of larger corpora
• New tools being incorporated

#LancsBox manifesto
1. CONTENT FOCUS: Provide as much content as possible. The tool itself is never in the way of the content: ‘transparent lens’ principle.
2. RICHNESS OF INFORMATION: Provide informationally-rich content (multi-aspect, multivariate, multi-factor).
3. COMPLETENESS: Tell the whole story in one picture. Enable focusing on/ zooming in/ highlighting rather than hiding content.
4. TRANSPARENCY: The analyses need to be clearly related to the data. 5. INNOVATION: Don’t reinvent the wheel – analytical tools can be always
improved. 6. INTEGRATION: Allow easy combination and integration of techniques. 7. ACCESSIBILITY: The tools should be at hand – accessible with as few clicks as
possible. 8. CONTINUITY and PREDICTABILITY: The development should guarantee
continuity of good features and predictability of interaction with the tool. 9. CLARITY: Don’t show users options they don’t need. 10. FLEXIBILITY: Allow flexibility for advanced users.

#LancsBox http://corpora.lancs.ac.uk/lancsbox/
• Brezina, V., McEnery, T., & Wattam, S. (2015). Collocations in context: A new perspective on collocation networks, International Journal of Corpus Linguistics, 20(2), 139-173.
• http://www.ingentaconnect.com/content/jbp/ijcl/2015/00000020/00000002/art00001

http://corpora.lancs.ac.uk/lancsbox

Focus on content

Focus on comparison
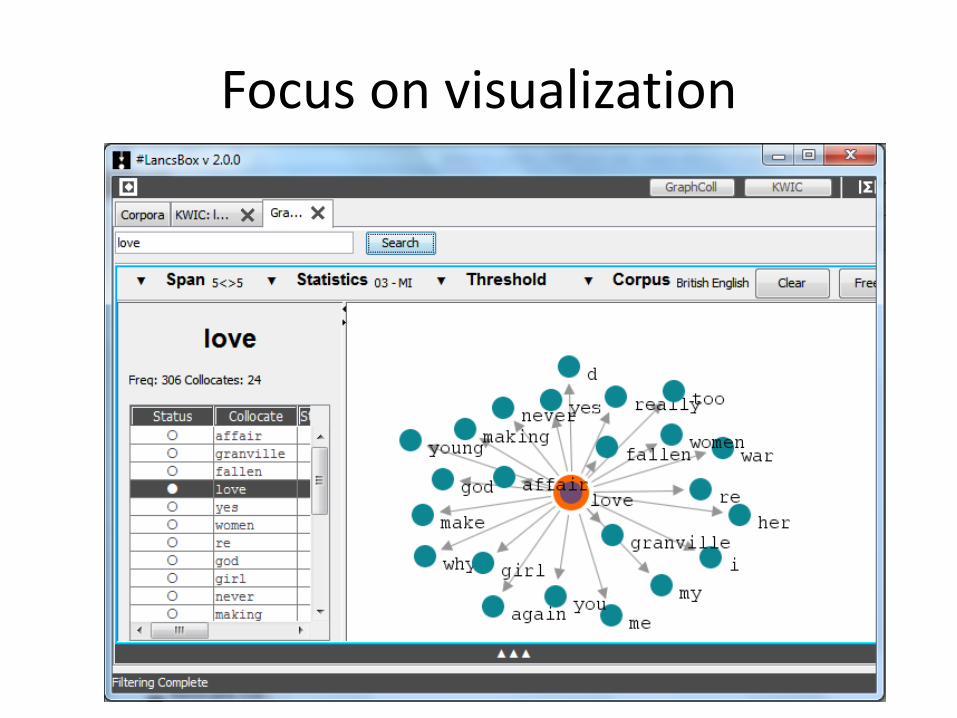
Focus on visualization

Focus on visualization (cont.)

Focus on visualization (cont.)

Focus on visualization (cont.)

Corpora are developing too
• 19th Century News Papers
• EEBO corpus
• SketchEngine Corpora
• The age of mutli-bilion word corpora is upon us
• CQPweb cqpweb.lancs.ac.uk
• Corpora of new types of data, with a fuller range of metadata and a broader range of contributors. An example – the Trinity-Lancaster Corpus

1,900+ L2 users
Three main proficiency levels
Age range: 9 to 72
10 different L1 and cultural backgrounds
2-4 different speaking tasks
Trinity Lancaster Spoken Learner Corpus Currently: 3.5 mil. words
~ 20,000 A4 ~ 300 h
GESE examinations (Trinity College London)

Other corpora
Corpus LINDSEI TLC
Size over 1 mil. words 3 mil. words (→ 4 mil)
No of speakers 554 1,900
Age range 20-30 9-72
Speaker backgrounds mostly European, Chinese, Japanese
Argentina, Brazil, China, India, Italy, Mexico, Russia, Spain, Sri Lanka & others
Speaker proficiency 1 level: upper-intermediate & advanced
3 levels: lower-intermediate to near-native
Type of language informal semi-formal, institutional
Availability - platform CD-Rom online platform

Combining the two
• Pushes the envelope of what we can achieve
• Generates new insights
• Challenges assumptions

Pushes the envelope
Phrase searched for: TAKE + ??? Trinity Lancaster Corpus - proficiency levels Lower-intermediate (CEFR: B1) Intermediate (CEFR: B2) Advanced (CEFR: C1 or C2)
Comparison: British English 2006 Method: GraphColl & MI score
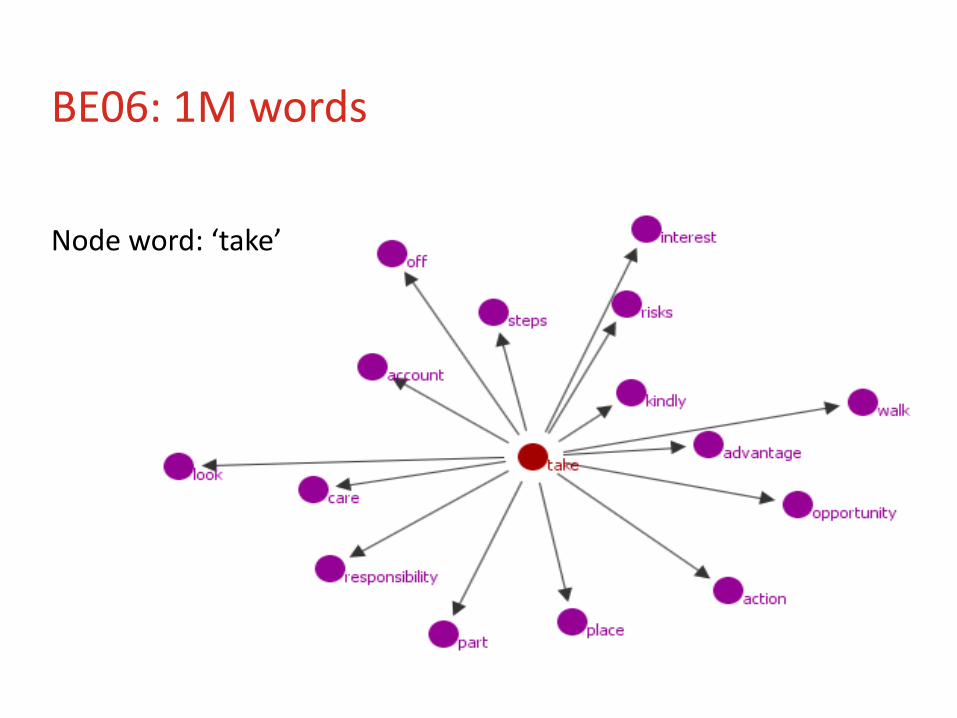
BE06: 1M words
Node word: ‘take’

Level: Lower-intermediate (B1)
No. of speakers: 266
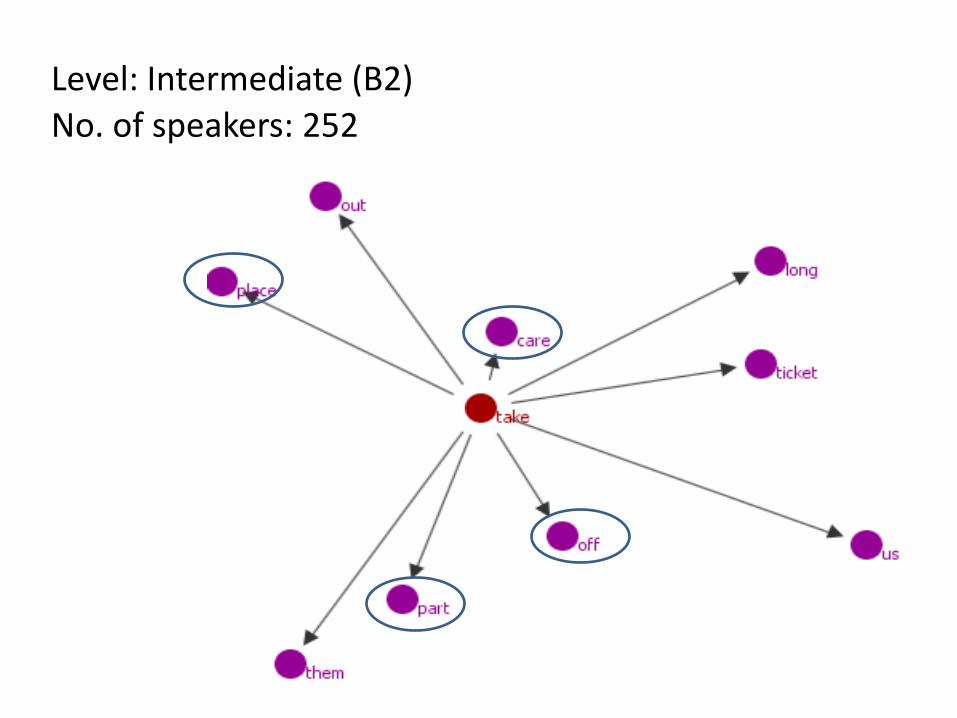
Level: Intermediate (B2) No. of speakers: 252
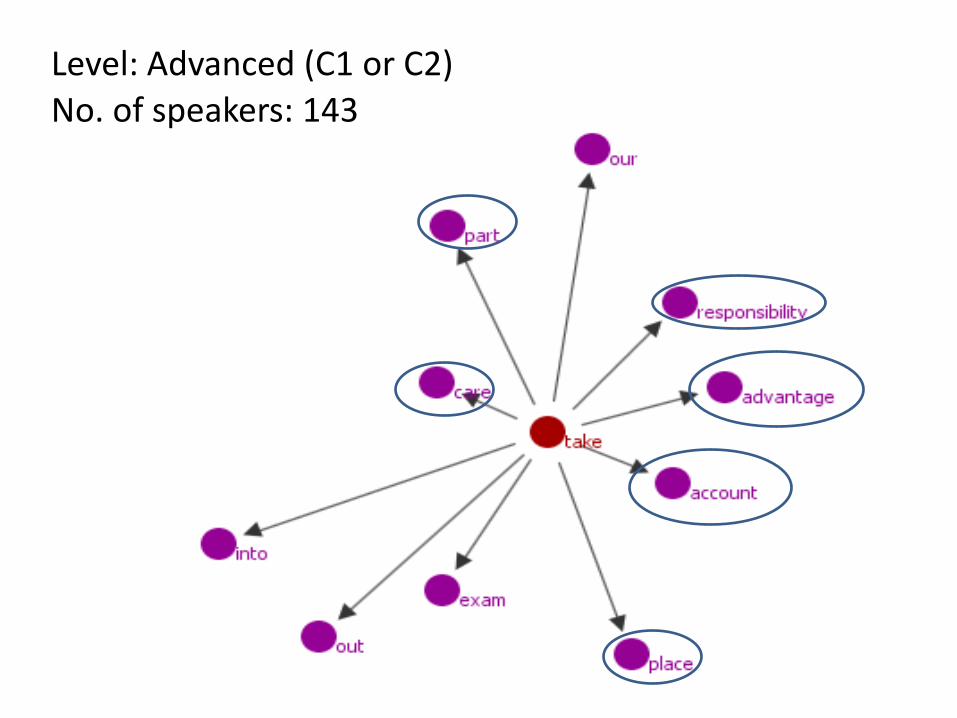
Level: Advanced (C1 or C2) No. of speakers: 143

36
Prof: B1.2 (high) Age: 11-13
Prof: B1.2 (high) Age: 25+

Generates New Insights
• Example – exploring lexis associated with marking epistemic stance within the Trinity-Lancaster corpus
• With the existing spoken learner corpora, a limited range of observations can be made
• But with a corpus from a range of L1 backgrounds, with plentiful metadata and with mark-up aware tools, we can go further and faster with our analyses
• Gablasova, D., Brezina, V., Mcenery, T., & Boyd, E. (2015). Epistemic stance in spoken L2 English: the effect of task and speaker style. Applied Linguistics.
• https://academic.oup.com/applij/article/doi/10.1093/applin/amv055/2952204/Epistemic-Stance-in-Spoken-L2-English-The-Effect
38
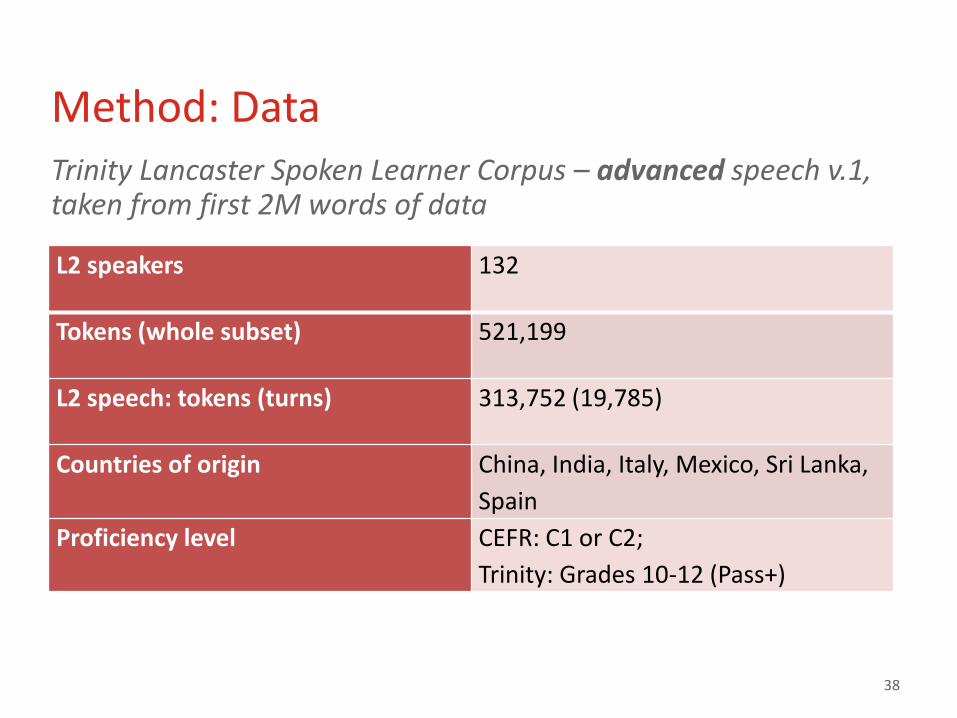
Method: Data Trinity Lancaster Spoken Learner Corpus – advanced speech v.1, taken from first 2M words of data
L2 speakers 132
Tokens (whole subset) 521,199
L2 speech: tokens (turns) 313,752 (19,785)
Countries of origin China, India, Italy, Mexico, Sri Lanka,
Spain
Proficiency level CEFR: C1 or C2;
Trinity: Grades 10-12 (Pass+)

Overall picture: certainty vs uncertainty
0 1 2 3 4
Uncertainty Certainty
Same for L1 speakers!

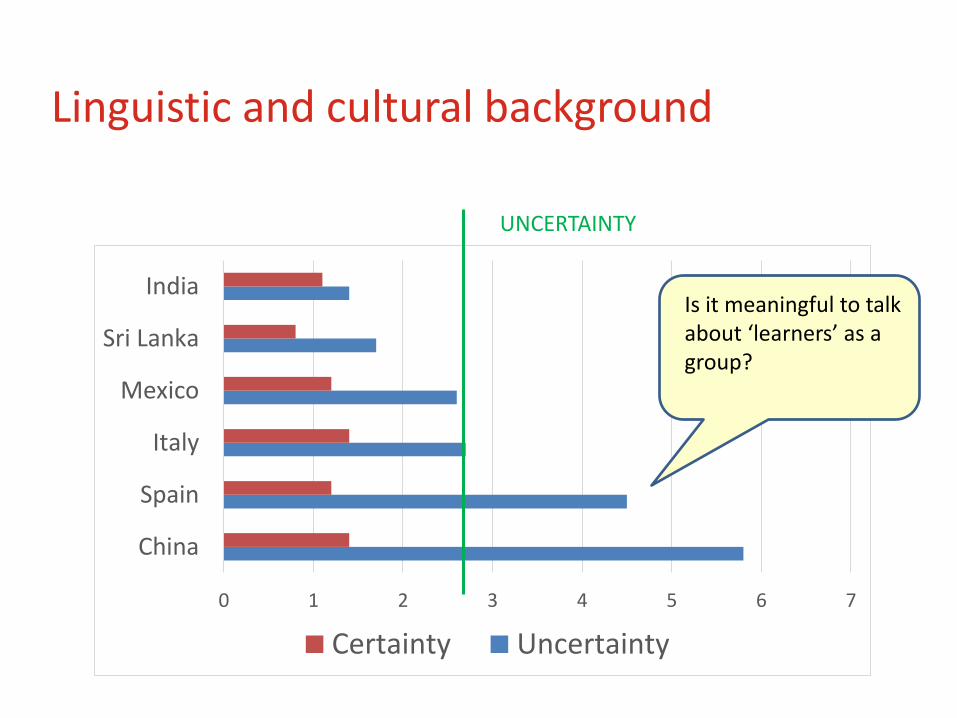
Linguistic and cultural background
0 1 2 3 4 5 6 7
China
Spain
Italy
Mexico
Sri Lanka
India
Certainty Uncertainty
CERTAINTY
Linguistic and cultural background
0 1 2 3 4 5 6 7
China
Spain
Italy
Mexico
Sri Lanka
India
Certainty Uncertainty
Is it meaningful to talk about ‘learners’ as a group?
UNCERTAINTY

Gender
0 0.5 1 1.5 2 2.5 3 3.5 4
Certainty
Uncertainty
Women Men

L2 proficiency
0 0.5 1 1.5 2 2.5 3 3.5 4
Certainty
Uncertainty
Lower marks
Higher marks
Language testing: speakers who used more certainty markers also got higher marks. Perhaps the cognitive effort of marking uncertainty has an effect?

Results: Effect of task
Source: Gablasova et al. 2015

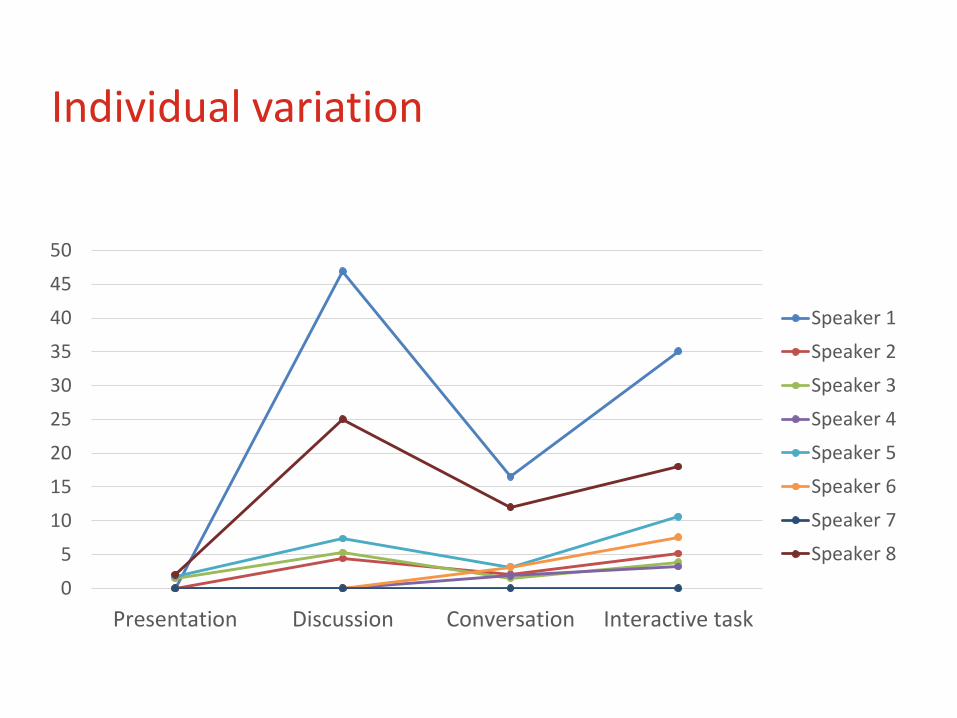
Individual variation
0
5
10
15
20
25
30
35
40
45
50
Presentation Discussion Conversation Interactive task
Speaker 1

Individual variation
0
5
10
15
20
25
30
35
40
45
50
Presentation Discussion Conversation Interactive task
Speaker 1
Speaker 2
Individual variation
0
5
10
15
20
25
30
35
40
45
50
Presentation Discussion Conversation Interactive task
Speaker 1
Speaker 2
Speaker 3
Speaker 4
Speaker 5
Speaker 6
Speaker 7
Speaker 8

L1 cultural and linguistic background
Gender
Proficiency
Type of tasks
Individual variation
Factors that affected variation

Challenges Assumptions
• How stable are collocates? • If you look only at one corpus, your view of that question
will be limited. If we use only one measure our view may be limited.
• If you look at a range of corpora with no particular connection, your view of the question may be unfair.
• But with a wider range of corpora which might be sensibly compared available, we can more easily compare them.
• Gablasova, D, Brezina, V. and McEnery, T. ‘Collocations in Corpus-Based Language Learning Research: Identifying, Comparing, and Interpreting the Evidence’, Language Learning (Currently Early View)
• http://onlinelibrary.wiley.com/doi/10.1111/lang.12225/full
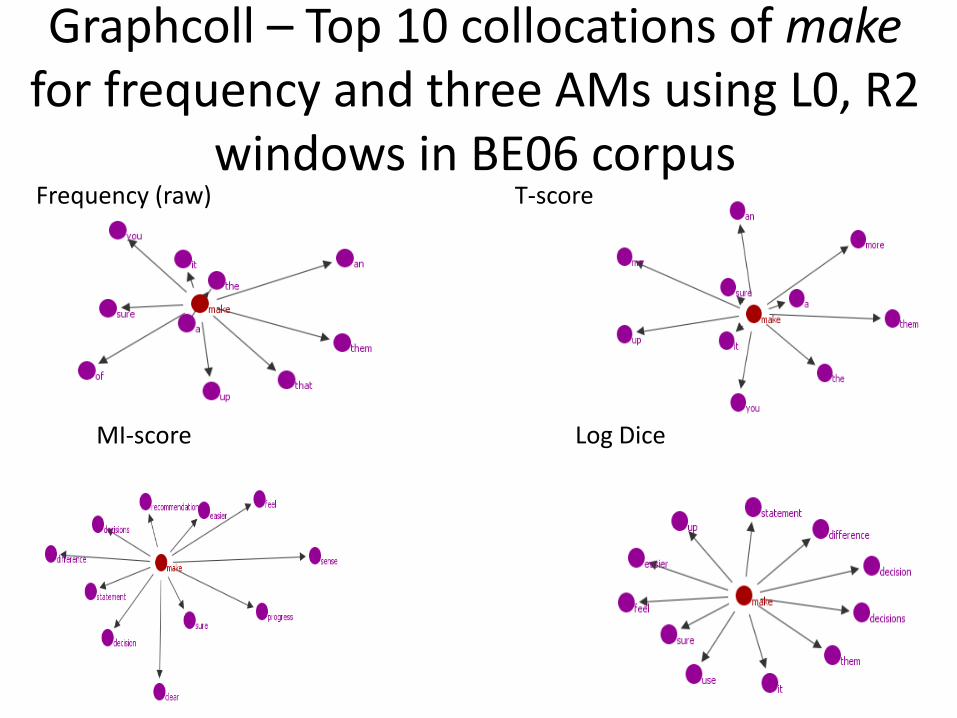
Graphcoll – Top 10 collocations of make for frequency and three AMs using L0, R2
windows in BE06 corpus Frequency (raw) T-score
MI-score Log Dice
Figure 1 Top ten collocations of make for frequency and three AMs using L0, R2 windows in BE06 corpus

Corpus Size Representativeness
British National Corpus (BNC) 98,560,118 Written and spoken (10M), diff.
registers
BNC_A 15,778,043 Written, academic writing
BNC_N 9,412,245 Written, news
BNC_F 16,143,913 Written, fiction
BNC – Context governed
(BNC_CG)
6,196,134 Spoken, formal
BNC – Demographic
(BNC_Dem)
4,234,093 Spoken, informal
BNC – 2014 Spoken (BNC_SP) 4,789,185 Spoken, informal
CANCODE (CANC) 5,076,313 Spoken, informal

BNC BNC_A BNC_N BNC_F BNC_CG BNC_D BNC_SP CANC
MI-score
sure 6.80 7.09 7.26 5.78 6.90 6.64 6.26 6.92
decision 4.55 3.67 4.07 5.86 6.12 7.91 7.57 8.07
point 3.44 2.92 3.84 3.68 4.11 3.12 3.01 3.93
t-score
sure 74.52 13.58 21.45 32.24 28.59 16.92 18.36 22.31
decision 27.59 9.44 9.22 10.45 11.58 5.08 6.82 10.82
point 27.41 9.50 7.78 35.61 13.78 3.43 4.20 6.47
Log Dice
sure 9.63 7.60 9.52 9.61 10.68 10.17 10.07 10.61
decision 6.91 6.61 7.16 6.62 8.31 7.05 7.60 8.87
point 6.90 6.65 6.74 6.55 8.52 6.03 6.30 7.30
Collocates are sensitive to both the measure and the data used.

No conclusion – but a future
• We have travelled a long way and the size of the field has grown because of that journey.
• What next? • An increasing range of corpora with some of the
‘hard to access’ material becoming more commonly available?
• Allowing for a clearer flow of information between concordancers and database and spreadsheet programs?
• The incorporation of ever more sophisticated statistical analyses into our tools?