copyright © curt hill 2003-2008 query evaluation translating a query into action
TRANSCRIPT

Copyright © Curt Hill 2003-2008
Query Evaluation
Translating a query into action

Copyright © Curt Hill 2003-2008
Why?
• Relational algebra is the means for accessing the tables– Relational calculus must be translated
into algebra before it is executed
• Several relational operators may be implemented in various ways
• None of these is always best

Copyright © Curt Hill 2003-2008
What factors are involved?• The organization of the file
– Existing sort order• The number and types of indexes• The size of the tables
– Both the cardinality and the number of pages
• Memory space available in buffer pool
• The source of much of this information is the system catalog

Copyright © Curt Hill 2003-2008
What is really needed?• The Join is the most expensive
common operator– At its heart is a cartesian product– This needs M by N accesses
• This is where most but not all optimizations occur
• Most of what will be discussed applies more to a join evaluation than most other operators

Copyright © Curt Hill 2003-2008
The M by N problem• Want Cartesian Product on
two tables, A and B– A contains M pages and B N
• Read each page in A • Read N pages of B to
connect• M N accesses
• We desperately want to avoid this
1
2
1
3
M
.
.
.
2
N
.
.
.
3
A B

Copyright © Curt Hill 2003-2008
File Techniques• Indexing
– Use the index to only examine the involved tuples
– If the key is the only field of interest the index may suffice without accessing the data
• Iteration– Examine all the tuples sequentially
• Partitioning– Group the tuples by sort key to avoid
the M by N problems– Sorting and hashing do this

Copyright © Curt Hill 2003-2008
Access Paths
• A way of retrieving one or more tuples from a relation
• Typically two ways– Scan entire file– Use an index to obtain record directly
• Every relational operator uses one or two tables so this is important

Copyright © Curt Hill 2003-2008
Conjunctive Normal Form
• A series of comparisons with ANDs connecting them
• All comparisons are of the form:Attr Op Value– Attr is field name – Op is a comparison such as =, >, etc– Value is a constant– Comparison is called a conjunct
• CNF has nothing to do with 1NF, 2NF, 3NF, BCNF among others

Copyright © Curt Hill 2003-2008
CNF Examples
• Courses table– Number = 160 AND Dept = ‘CS’
• Grades table– Dept = ‘CS’ AND Score > 89
• Join– S.Naid = G.Naid– First of these becomes a constant
when iterating through S table

Copyright © Curt Hill 2003-2008
Using a Hash Index
• Conjunct must use an equality• Whole key must be
– Indexed by hash index– Used in equality conjuncts
• Example from Grades table:– Naid = 2013 AND Dept = ‘CS’
AND Number = 160

Copyright © Curt Hill 2003-2008
Using a B+Tree index
• Any comparison operator• The B+Tree may only prefix a key• Example
– Naid = 2013 AND Dept = ‘CS’ AND Number = 160
– Only Dept and Number are actually indexed

Copyright © Curt Hill 2003-2008
Indexing CNF
• The form may include conjuncts that are not indexed
• Those conjuncts that are indexed are called the primary conjuncts
• A form may have two separate sets indexed by different indexes– Either can be retrieved and then the
others checked against them

Copyright © Curt Hill 2003-2008
Selectivity of Access Paths
• Number of pages fetched to obtain all records– This includes index and data pages
• The most selective path accesses the fewest pages– This minimizes the retrieval costs– Not always predictable

Copyright © Curt Hill 2003-2008
Reduction• Each conjunct reduces the number
of tuples that could be included in a query– This is the reduction factor– Each is a probability
• The expected probability of the conjunction of unrelated probabilities is their product
• It is often the case that the conjuncts are not unrelated, but this is still a good estimate

Copyright © Curt Hill 2003-2008
Selection• Use an index
– If all the fields in selection criteria are indexed
– If some of the selection criteria fields are indexed retrieve these and then reduce them with the other criteria
• Sequential scan – The criteria is tested on each tuple– Always possible
• If both are available– Use the cost estimators to determine which
is most selective
Copyright © Curt Hill 2003-2008
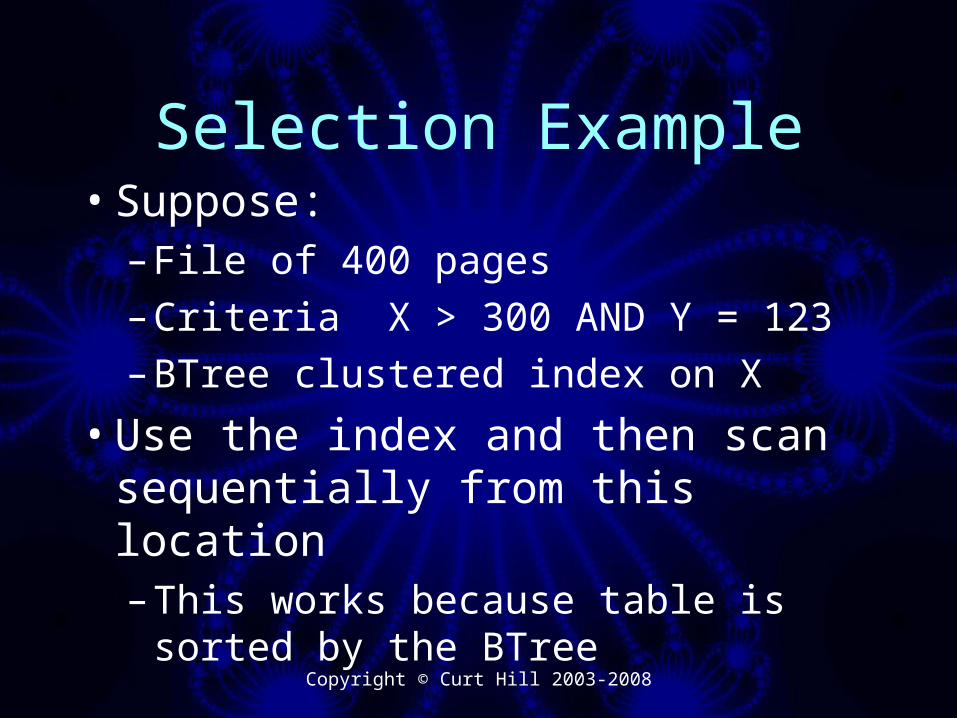
Selection Example• Suppose:
– File of 400 pages– Criteria X > 300 AND Y = 123– BTree clustered index on X
• Use the index and then scan sequentially from this location– This works because table is
sorted by the BTree

Filter Threshold• Suppose that I have a choice of
sequential scanning or accessing through a tree
• Each tree access needs several page accesses
• If only a few records are to be accessed the index approach will generate the fewest accesses
• If many then the scan will be best• We can calculate a reduction
probability and choose the best approach
Copyright © Curt Hill 2003-2008

Copyright © Curt Hill 2003-2008
Selection Example• Suppose:
– Page contains 20 records– Three page accesses for a record via
index
• What is the filter threshold? – If the probability of looking at a
record is 1 of 20 (5%) then clearly sequential scan is desirable
– Since it takes three accesses to get a record, divide the 5% by 3 to get 1.66%

Example Continued• The filter threshold is 1.66%• Estimate the reduction factor
using the product of the conjunct probabilities
• If the reduction probability is greater than 1.66% do a sequential scan
• If the reduction probability is less than 1.66% use the index
Copyright © Curt Hill 2003-2008

Copyright © Curt Hill 2003-2008
Projection• If the required fields are all in
the index, we may not need to access the data at all– Does not matter if index is
clustered or not
• If duplicates are to be eliminated– Sort or hash the results to do the
elimination

Copyright © Curt Hill 2003-2008
Join
• Very important • Very common• Very well studied• Many algorithms• Most DBMS use more than one
algorithm• We will consider three

Copyright © Curt Hill 2003-2008
Index Nested Loops Join• Select …
From t1 as A, t2 as B …Where A.x = B.y – B is indexed on Y
• Scan A sequentially• Use B’s index to find if x exists• The quality of the index
determines how many accesses are needed
• Desirable if we can restrict one of the files before accessing

Copyright © Curt Hill 2003-2008
Sort Merge Join
• AKA Zipper Join• Sort both tables on the join field• Does not require an index• It is much less expensive if one or
both files is already sorted on the field
• The accesses are M + N once sorted• The sort itself is N log N + M log M

Copyright © Curt Hill 2003-2008
The Sort Merge Join
1024 a
1092 b
1233 c
1279 d
1092 v
1068 u
1024 t
1024 s
1024 r
Faculty Schedule
1092 w
1279 x
1279 y
1279 z
Only one scan of each is needed.

Copyright © Curt Hill 2003-2008
Hash Join• Sorting partitions the records so
that all the possible candidates for a join can be considered at once
• Hash join also partitions but using a hash instead of sort
• Two phases– Partitioning – Probing

Copyright © Curt Hill 2003-2008
Process• Partition phase
– Hash file R into the hash file r– Hash file S into the hash file s
• Probe phase– For each of k partitions
• Read partition in r• Hash each tuple into an in-memory hash
table using a new hash function• Read partition in s• Find matches with new hash function• Make joins and flush to output

Copyright © Curt Hill 2003-2008
Which to use?• This is where the system catalog
information plays into the process• Given the right data any of these
three will be best• So we test the possibilities
– Construct the alternative plans– Compute the estimate of accesses– Choose the lowest
• Considering the rest of the query is also important

Copyright © Curt Hill 2003-2008
Query Evaluation Plan
• A plan is a tree of relational operators
• Joins, unions, intersections have two descendents (relations)
• Projection and selection just one• These can be augmented with
access paths

Copyright © Curt Hill 2003-2008
A Query
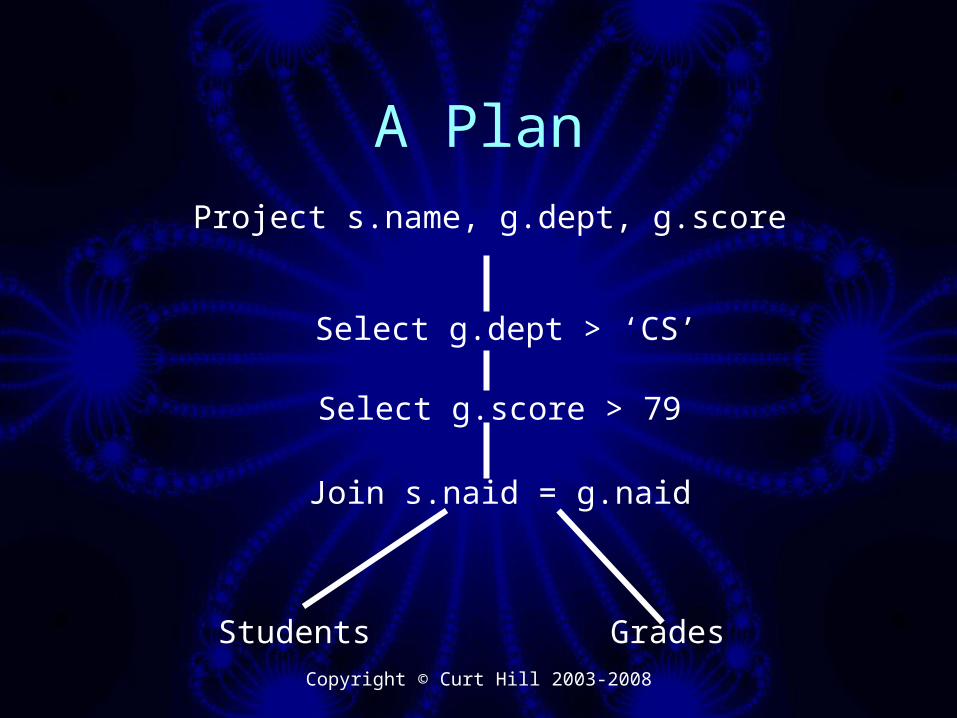
• Consider the following querySelect s.name, g.dept, g.scoreFrom grades g, students sWhere s.naid=g.naid AND g.score>79 and g.dept = 'CS'
Copyright © Curt Hill 2003-2008
A Plan
Join s.naid = g.naid
Students Grades
Select g.score > 79
Select g.dept > ‘CS’
Project s.name, g.dept, g.score

Copyright © Curt Hill 2003-2008
Optimization of Plans• We can reorganize the tree to produce a
better plan• In this case push the selection below
the join• The join has many fewer entries• This makes the index loop join or any
other much less expensive• Selections may be applied upon input
– Thus not cause any additional accesses

Copyright © Curt Hill 2003-2008
A Revised Plan
Join s.naid = g.naid
Students
Grades
Select g.score > 79
Select g.dept > ‘CS’
Project s.name, g.dept, g.score

Copyright © Curt Hill 2003-2008
Other optimizations• Pushing the selection below (that is
before) the join makes the table smaller and the join easier
• A projection also makes a table smaller by eliminating columns
• Eliminate any column that does not appear in the rest of the query
• This will reduce the number of pages and thus the cost of the join
• Projections may be done as the table is read or written– Thus do not add accesses

Copyright © Curt Hill 2003-2008
Another Revised Plan
Join s.naid = g.naid
Students
Grades
Select g.score > 79
Select g.dept > ‘CS’
Project s.name,s.naid
Project s.name, g.dept, g.score
Project g.naid,g.dept, g.score