conditional random fields crf 1 mark stamp. intro hidden markov model (hmm) used in o...
TRANSCRIPT

1
Conditional Random Fields
CRF
Mark Stamp

2
Intro
Hidden Markov Model (HMM) used ino Bioinformaticso Natural language processing o Speech recognitiono Malware detection/analysis
And many, many other applications Bottom line: HMMs are very useful
o Everybody knows that!CRF

3
Generic HMM
Recall that A is Markov processo Implies that Xi only depends on Xi-1
Matrix B is observation probabilitieso Note probability of Oi only depends on
Xi CRF

4
HMM Limitations
Assumptionso Observation depends on current stateo Current state depends on previous
stateo Strong independence assumption
Often independence is not realistico Observation can depend on several
stateso And/or current state might depend on
several previous statesCRF

5
HMMs
Within HMM framework, we can… Increase N, number of hidden states And/or higher order Markov process
o “Order 2” means hidden state depends on 2 immediately previous hidden states
o Order > 1 limits independence constraint
More hidden states, more “breadth” Higher order, increased “depth”CRF

6
Beyond HMMs
HMMs do not fit some situationso For example, arbitrary dependencies
on state transitions and/or observations
Here, focus on generalization of HMMo Conditional Random Fields (CRF)
There are other generalizationso We mention a few
Mostly focused on the “big picture”CRF

7
HMM Revisited
Illustrates graph structure of HMMo That is, HMM is a directed line graph
Can other types of graphs work? Would they make sense?CRF

8
MEMM
In HMM, observation sequence O is related to states X via B matrixo And O affects X in training, not scoringo Might want X to depend on O in scoring
Maximum Entropy Markov Model
o State Xi is function of Xi-1 and Oi
MEMM focused on “problem 2”o That is, determine (hidden) states
CRF

9
Generic MEMM
How does this differ from HMM?o State Xi is function of Xi-1 and Oi
o Cannot generate Oi using the MEMM, while we can do so using HMM
CRF

10
MEMM vs HMM
HMM Find “best” state sequence Xo That is, solve HMM Problem 2o Solution is X that maximizes
P(X|O) = Π P(Oi|Xi) Π P(Xi|Xi-1)
MEMM Find “best” state sequence Xo Solution is X that maximizes
P(X|O) = Π P(Xi|Xi-1,Oi)
where P(x|y,o) = 1/Z(o,y) exp(Σwjfj(o,x)) CRF

11
MEMM vs HMM
Note Σwj fj(o,x) in MEMM probabilityo This sum is over entire sequenceo Any useful feature of input
observation can affect probability MEMM more “general”, in this
senseo As compared to HMM, that is
But MEMM creates a new problemo A problem that does not occur in HMM
CRF

12
Label Bias Problem
MEMM uses dynamic programming (DP)o Also known as the Viterbi algorithm
HMM (problem 2) does not use DPo HMM α-pass uses sum, DP uses max
In MEMM probability is “conserved”o Probability must be split between
successor states (not so in HMM)o Is this good or bad?
CRF

13
Label Bias Problem
Only one possible successor in MEMM?o All probability passed along to that
stateo In effect, observation is ignoredo More generally, if one dominant
successor, observation doesn’t matters much
CRF solves label bias problem of MEMMo So, observation matters
We won’t go into details here…
CRF

14
Label Bias Problem
Exampleo Hot, Cold, and
Medium states In M state…
o Observation does little (MEMM)
o Observation can matter more (HMM)
CRF
H
C
0.7
0.6
0.3 0.3 M
0.99
0.1
0.01

15
Conditional Random Fields
CRFs a generalization of HMMs Generalization to other graphs
o Undirected graphs Linear Chain CRF is simplest case But also generalizes to arbitrary
(undirected) graphso That is, can have arbitrary
dependencies between states and observations
CRF

16
Simplest Case of CRF
How is it different from HMM/MEMM? More things can depend on each
othero The case illustrated is a linear chain
CRFo More general graph structure can work
CRF

17
Another View
Next, consider deeper connection between HMM and CRF
But first, we need some backgroundo Naïve Bayeso Logistic regression
These topics are very useful in their own right…o …so wake up and pay attention!
CRF

18
What Are We Doing Here?
Recall, O observation, X is state Ideally, want to model P(X,O)
o All possible interactions of Xs and Os But P(X,O) involves lots of
parameterso Like the complete covariance matrixo Lots of data needed for “training”o And too much work to train
Generally, this problem is intractable
CRF

19
What to Do?
Simplify, simplify, simplify…o Need to make problem tractableo And then hope we get decent results
In Naïve Bayes, assume independence
In regression analysis, try to fit specific function to data
Eventually, we’ll see this is relevant o Wrt HMMs and CRFs, that is
CRF

20
Naïve Bayes
Why is it “naïve”? Assume features in X are
independento Probably not true, but simplifies thingso And often works well in practice
Why does independence simplify?o Recall covariance: For X = (x1,…,xn) and
Y = (y1,…,yn), if means are 0, thenCov(X,Y) = (x1y1 +…+ xnyn) / n
CRF

21
Naïve Bayes
Independent implies covariance is 0
If so, in covariance matrix only the diagonal elements are non-zero
Only need means and variances o Not the entire covariance matrixo Far fewer parameters to estimateo And a lot less data needed for training
Bottom line: Practical solutionCRF

22
Naïve Bayes
Why is it “Bayes”? Because it uses Bayes Theorem:
o That is,
o Or,
o More generally,
where Aj form partition
CRF

23
Bayes Formula Example
Consider a test for an illegal drugo If you use drug, 98% positive (TPR =
sensitivity)o If don’t use, 99% negative (TNR =
specificity)o In overall population, 5/1000 use the drug
Let A = uses the drug, B = tests positive
Then
= .98 × .005 / (.98 × .005 + .01
× .995)
= 0.329966 = 33%CRF

24
Naïve Bayes
Why is this relevant? Spse classify based on observation
Oo Compute P(X|O) = P(O|X) P(X) / P(O)o Where X is one possible class (state)o And P(O|X) is easy to compute
Repeat for all possible classes Xo Biggest probability is most likely class
X o Can ignore P(O) since it’s constant CRF

25
Regression Analysis
Generically, method for measuring relationship between 2 or more thingso E.g., house price vs size
First, we consider linear regressiono Since it’s the simplest case
Then logistic regressiono More complicated, but often more
usefulo Used for binary classifiersCRF

26
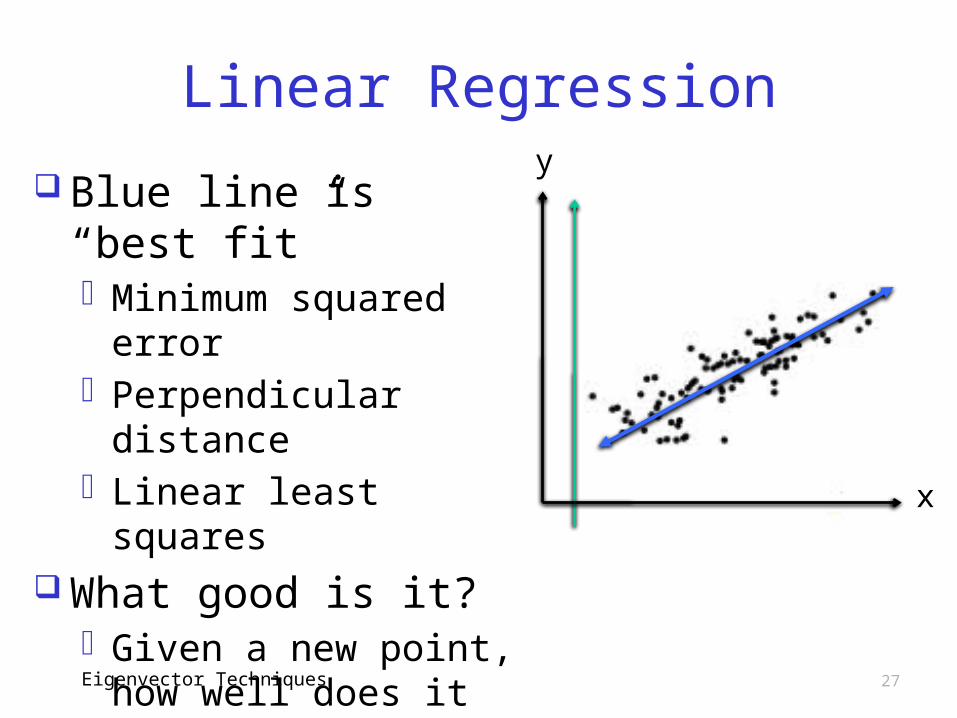
Linear Regression Spse x is house ft2
o Could be vector x of observations instead
And y is sale price Points represent
recent sales results How to use this
info?o Given a house to
sell…o Given a recent sale…Eigenvector Techniques
x
y
27
Linear Regression
Blue line is “best fit”o Minimum squared
erroro Perpendicular
distanceo Linear least squares
What good is it?o Given a new point,
how well does it fit in?
o Given x, predict yo This sounds
familiar…
Eigenvector Techniques
x
y

28
Regression Analysis
In many problems, only 2 outcomeso Binary classifier, e.g., malware vs
benigno “Malware of specific type” vs “other”
Then x is an observation (vector) But each y is either 0 or 1
o Linear regression not so good (Why?)o A better idea logistic regressiono Fit a logistic function instead of line
CRF

29
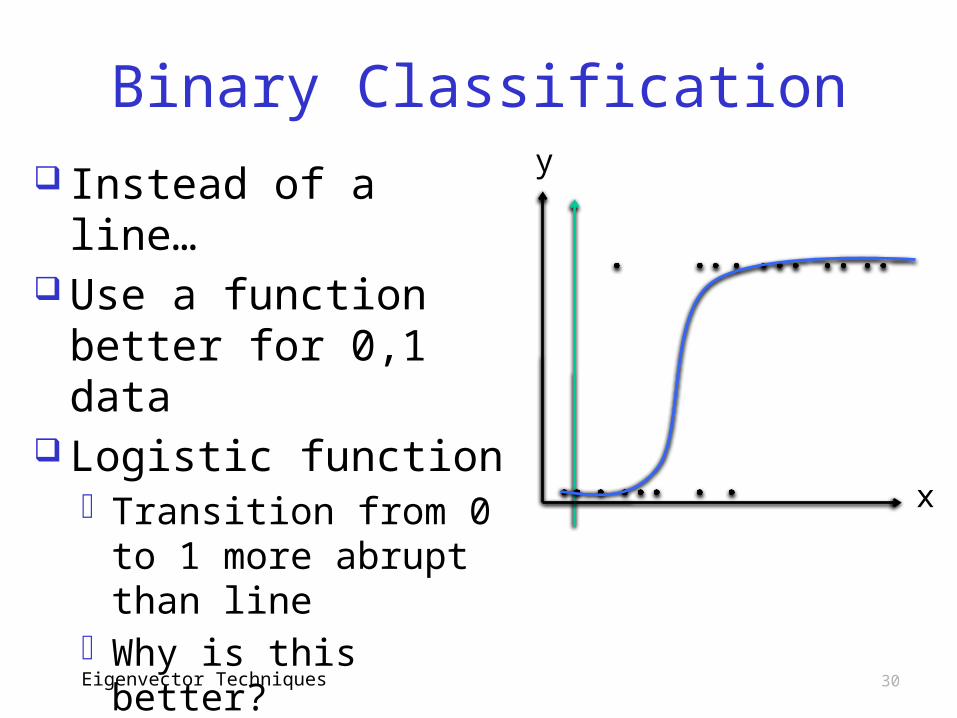
Binary Classification Suppose we
compute score for many files
Score is on x-axis Output on y-axis
o 1 if file is malwareo 0 if file is “other”
Linear regression not very useful here
Eigenvector Techniques
x
y
30
Binary Classification Instead of a line… Use a function
better for 0,1 data Logistic function
o Transition from 0 to 1 more abrupt than line
o Why is this better?o Less wasted time
between 0 and 1Eigenvector Techniques
x
y

31
Logistic Regression
Logistic functiono F(t) = 1 / (1 + e-t) o Input: –∞ to ∞ o Output: 0 to 1, can
be interpreted as P(t)
Here, t = b0 + b1xo Or t=b0+b1x1+…+bmxm
o I.e., x is observationCRF

32
Logistic Regression Instead of fitting a line to data…
o Fit logistic function to data And instead of least squares error…
o Measure “deviance” distance from ideal case (where ideal is “saturated model”)
Iterative process to find parameterso Find best fit F(t) using data pointso More complex training than linear
case…o …but, better suited to binary
classification
CRF

33
Conditional Probability
Recall, we would like to model P(X,O)o Observe that P(X,O) includes all
relationships between Xs and Os o Too complex, too many parameters,
too… So we settle for P(X|O)
o A lot fewer parameterso Problem is tractableo Works well in practiceCRF

34
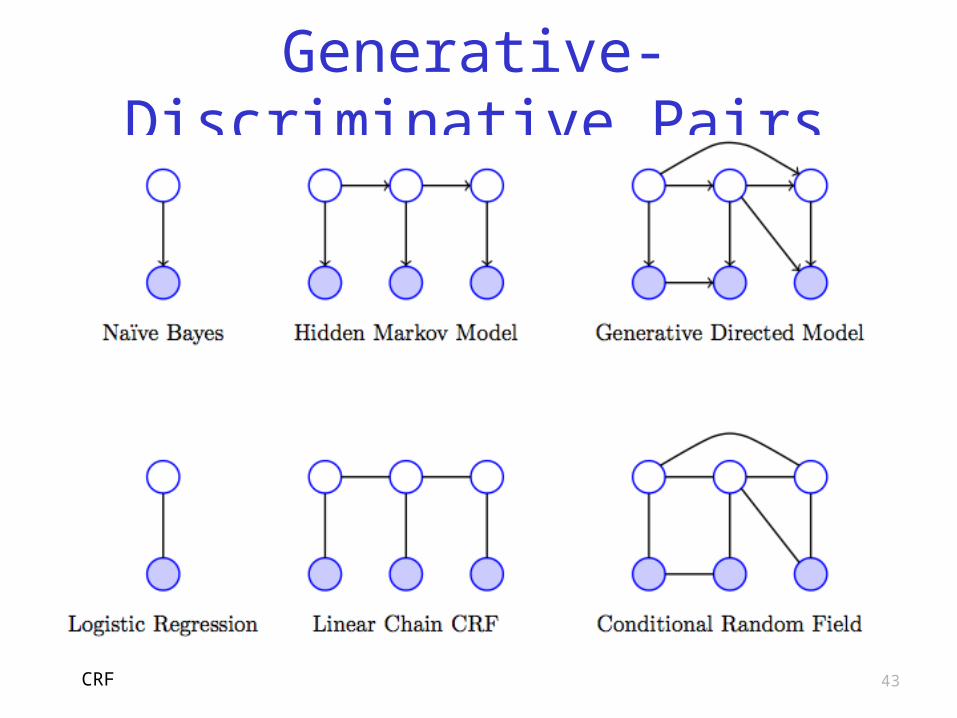
Generative vs Discriminative
We are interested in P(X|O) Generative models
o Focus on P(O|X) P(X)o From Naïve Bayes (without
denominator) Discriminative models
o Focus directly on P(X|O)o Like logistic regression
Tradeoffs?CRF

35
Generative vs Discriminative
Naïve Bayes is generative model o Since it uses P(O|X) P(X)o Good in unsupervised case, unlabeled
data Logistic regression is discriminative
o Directly deal with P(X|O)o No need to expend effort modeling O o So, more freedom to model Xo Unsupervised is “active area of
research” CRF

36
HMM and Naïve Bayes
Connection(s) between NB and HMM?
Recall HMM, problem 2o For given O, find “best” (hidden) state
X We use P(X|O) to determine best X Alpha pass used in solving problem
2 Looking closely at alpha pass…
o It is based on computing P(O|X) P(X)o With probabilities from the model λ
CRF

37
HMM and Naïve Bayes
Connection(s) between NB and HMM?
HMM can be viewed as sequential version of Naïve Bayeso Classifications over series of
observationso HMM uses info about state transitions
Conversely, Naïve Bayes is a “static” version of HMM
Bottom line: HMM is generative model
CRF

38
CRF and Logistic Regression
Connection between CRF & regression?
Linear chain CRF is sequential version of logistic regressiono Classification over series of
observationso CRF uses info about state transitions
Conversely, logistic regression can be viewed as static (linear chain) CRF
Bottom line: CRF discriminative model
CRF

39
Generative vs Discriminative
Naïve Bayes and Logistic Regressiono A “generative-discriminative pair”
HMM and (Linear Chain) CRFo Another generative-discriminative pairo Sequential versions of those above
Are there other such pairs?o Yes, based on further generalizationso What’s more general than sequential?
CRF

40
General CRF
Can define CRF on any (undirected) graph structureo Not just a linear chain
In general CRF, training and scoring not as efficient, so…o Linear Chain CRF used most in
practice If special cases, might be worth
considering more general CRFCRF

41
Generative Directed Model
Can view HMM as defined on (directed) line graph
Could consider similar process on more general (directed) graph structures
This more general case is known as “generative directed model”
Algorithms (training, scoring, etc.) not as efficient in more general case
CRF

42
Generative-Discriminative Pair
Generative directed modelo As the name implies, a generative
model General CRF
o A discriminative model So, this gives us a 3rd generative-
discriminative pair Summary on next slide…
CRF
43
Generative-Discriminative Pairs
CRF

44
HCRF
Yes, you guessed it…o Hidden Conditional Random Field
So, what is hidden? To be continued…
CRF

45
Algorithms
Where are the algorithms?o This is a CS class, after all…
Yes, CRF algorithms do existo Omitted, since lot of background
neededo Would take too long to cover it allo We’ve got better things to do
So, just use existing implementationso It’s your lucky day…CRF

46
References
E. Chen, Introduction to conditional random fields
Y. Ko, Maximum entropy Markov models and conditional random fields
A. Quattoni, Tutorial on conditional random fields for sequence prediction
CRF

47
References
C. Sutton and A. McCallum, An introduction to conditional random fields, Foundations and Trends in Machine Learning, 4(4):267-373, 2011
H.M. Wallach, Conditional random fields: An introduction, 2004
CRF