computing beyond a million processors - bio-inspired massively-parallel architectures
DESCRIPTION
Computing beyond a Million Processors - bio-inspired massively-parallel architectures. Andrew Brown The University of Southampton [email protected]. Steve Furber The University of Manchester [email protected]. SBF is supported by a Royal Society- Wolfson Research Merit Award. - PowerPoint PPT PresentationTRANSCRIPT

ACACES 12 July 2009 1
Computing beyond a Million Processors
- bio-inspired massively-parallel architectures
Steve FurberThe University of [email protected]
SBF is supported by a Royal Society-Wolfson Research Merit Award
Andrew BrownThe University of Southampton

ACACES 12 July 2009 2
Outline
• Computer Architecture Perspective• Building Brains• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 3
Multi-core CPUs• High-end uniprocessors
– diminishing returns from complexity– wire vs transistor delays
• Multi-core processors– cut-and-paste– simple way to deliver more MIPS
• Moore’s Law– more transistors– more cores
… but what about the software?

ACACES 12 July 2009 4
Multi-core CPUS
• General-purpose parallelization– an unsolved problem– the ‘Holy Grail’ of computer science for half a century?– but imperative in the many-core world
• Once solved– few complex cores, or many simple cores?– simple cores win hands-down on power-efficiency!

ACACES 12 July 2009 5
Back to the future
• Imagine…– a limitless supply of (free) processors– load-balancing is irrelevant– all that matters is:
• the energy used to perform a computation• formulating the problem to avoid synchronisation• abandoning determinism
• How might such systems work?

ACACES 12 July 2009 6
Bio-inspiration
• How can massively parallel computing resources accelerate our understanding of brain function?
• How can our growing understanding of brain function point the way to more efficient parallel, fault-tolerant computation?

ACACES 12 July 2009 7
Outline
• Computer Architecture Perspective• Building Brains• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 8
Building brains
• Brains demonstrate– massive parallelism (1012 neurons)– massive connectivity (1015 synapses)– excellent power-efficiency
• much better than today’s microchips
– low-performance components (~ 100 Hz)– low-speed communication (~ metres/sec)– adaptivity – tolerant of component failure– autonomous learning

ACACES 12 July 2009 9
(www.ship.edu/ ~cgboeree/theneuron.html)
Neurons
• Multiple inputs (dendrites)
• Single output (axon)– digital “spike”– fires at 10s to 100s
of Hz– output connects to
many targets• Synapse at
input/output connection
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40

ACACES 12 July 2009 10
Neurons
• A flexible biological control component– very simple
animals have a handful
– bees: 850,000– humans: 1012
(photo courtesy of the Brain Mind Institute, EPFL)
ACACES 12 July 2009 11
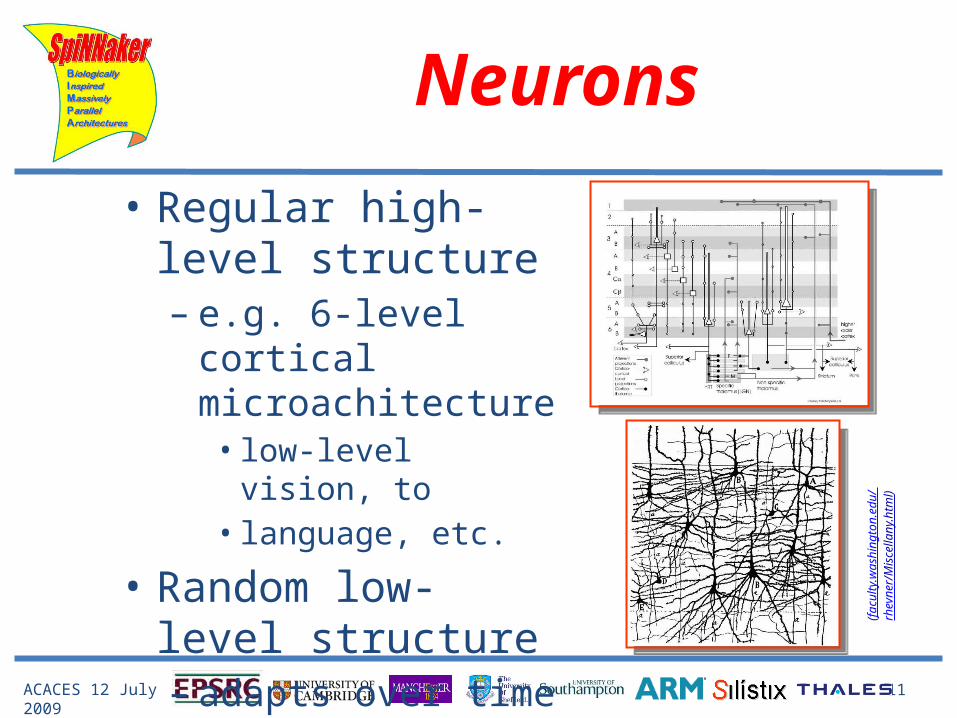
• Regular high-level structure– e.g. 6-level cortical
microachitecture• low-level vision, to• language, etc.
• Random low-level structure– adapts over time (f
acu
lty.
wash
ing
ton
.ed
u/
rhevn
er/
Mis
cella
ny.
htm
l)
Neurons

ACACES 12 July 2009 12
Neural Computation
• To compute we need:– Processing– Communication– Storage
• Processing:abstract model– linear sum of
weighted inputs• ignores non-linear
processes in dendrites– non-linear output function– learn by adjusting synaptic weights
w1
x1
w2
x2
w3
x3
w4
x4
yf

ACACES 12 July 2009 13
0&
/
)(
Aset
fireAif
IAA
xwI
ttx
A
A
iii
kiki
• Leaky integrate-and-fire model– inputs are a series of spikes– total input is a weighted
sum of the spikes– neuron activation is the
input with a “leaky” decay– when activation exceeds
threshold, output fires– habituation, refractory
period, …?
Processing

ACACES 12 July 2009 14
• Izhikevich model– two variables, one fast, one slow:
– neuron fires when
v > 30; then:
– a, b, c & d select behaviour
)(
140504.0 2
ubvau
Iuvvv
duu
cv
( www.izhikevich.com )
Processing
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40
0 20 40 60 80 100 120 140 160 180 200-14
-12
-10
-8
-6
-4
-2
0
2
0 20 40 60 80 100 120 140 160 180 200-14
-12
-10
-8
-6
-4
-2
0
2
v
u

ACACES 12 July 2009 15
Communication
• Spikes– biological neurons communicate principally
via ‘spike’ events– asynchronous– information is only:
• which neuron fires, and• when it fires
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40
0 20 40 60 80 100 120 140 160 180 200-80
-60
-40
-20
0
20
40

ACACES 12 July 2009 16
Storage
• Synaptic weights– stable over long periods of time
• with diverse decay properties?– adaptive, with diverse rules
• Hebbian, anti-Hebbian, LTP, LTD, ...
• Axon ‘delay lines’• Neuron dynamics
– multiple time constants• Dynamic network states

ACACES 12 July 2009 17
Outline
• Building Brains• Computer Architecture Perspective• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 18
The Good News...Transistors per Intel chip
0.001
0.01
0.1
1
10
100
1970 1975 1980 1985 1990 1995 2000
Year
Mill
ion
s o
f tr
ansi
sto
rs p
er c
hip
8008
8080
8086
286
386
486
Pentium
4004
Pentium II
Pentium III
Pentium 4
ACACES 12 July 2009 19
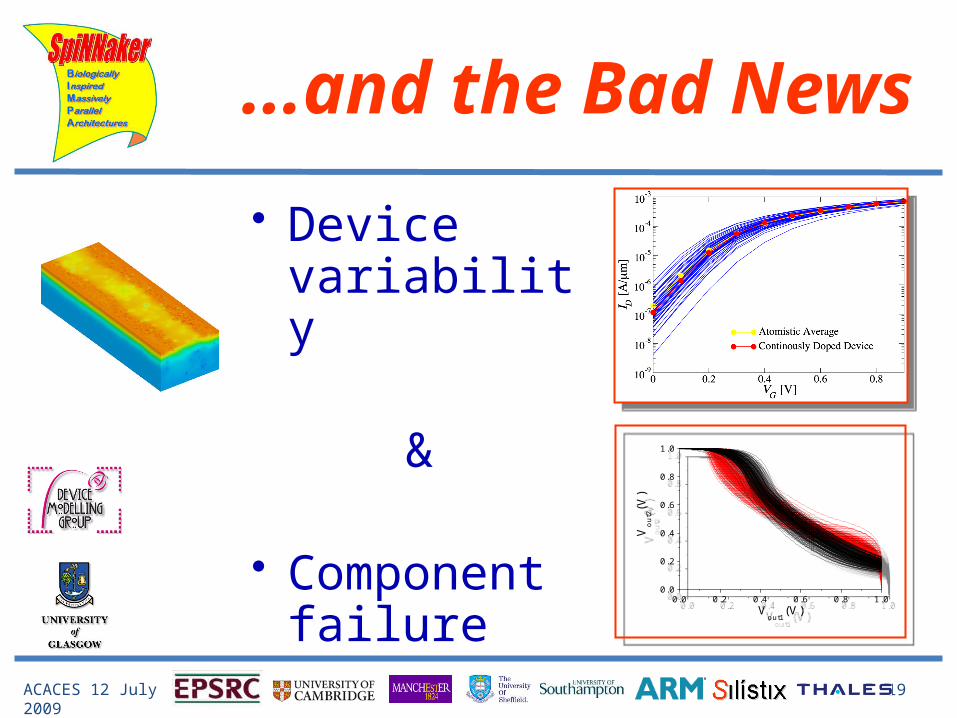
...and the Bad News
• Device variability
&
• Component failure
0.0 0.2 0.4 0.6 0.8 1.00.0
0.2
0.4
0.6
0.8
1.0
Vo
ut2(V
)
Vout1
(V)
0.0 0.2 0.4 0.6 0.8 1.00.0
0.2
0.4
0.6
0.8
1.0
Vo
ut2(V
)
Vout1
(V)

ACACES 12 July 2009 20
Atomic Scale devices
The simulationParadigm now
A 4.2 nm MOSFETIn production 2023
A 22 nm MOSFETIn production 2008

ACACES 12 July 2009 21
A view from Intel
• The Good News:– we will have 100 billion transistor ICs
• The Bad News:– billions will fail in manufacture
• unusable due to parameter variations
– billions more will fail over the first year of operation• intermittent and permanent faults
(Shekhar Borkar, Intel Fellow)

ACACES 12 July 2009 22
A view from Intel
• Conclusions:– one-time production test will be out– burn-in to catch infant mortality will be impractical– test hardware will be an integral part of the design– dynamically self-test, detect errors, reconfigure,
adapt, ...(Shekhar Borkar, Intel Fellow)

ACACES 12 July 2009 23
Outline
• Building Brains• Computer Architecture Perspective• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 24
Design principles
• Virtualised topology– physical and logical connectivity are
decoupled• Bounded asynchrony
– time models itself• Energy frugality
– processors are free– the real cost of computation is energy

ACACES 12 July 2009 25
Outline
• Building Brains• Computer Architecture Perspective• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 26
SpiNNaker project
• Multi-core CPU node– 20 ARM968 processors– to model large-scale systems of spiking neurons
• Scalable up to systems with 10,000s of nodes– over a million processors– >108 MIPS total
• Power ~ 25mw/neuron

ACACES 12 July 2009 27
SpiNNaker project

ACACES 12 July 2009 28
• Fault-tolerant architecture for large-scale neural modelling
• A billion neurons in real time
• A step-function increase in the scale of neural computation
• Cost- and energy-efficient
SpiNNaker project

ACACES 12 July 2009 29
SpiNNaker system

ACACES 12 July 2009 30
CMP node

ACACES 12 July 2009 31
ARM968 subsystem

ACACES 12 July 2009 32
GALS organization
• clocked IP blocks• self-timed
interconnect• self-timed inter-
chip links

ACACES 12 July 2009 33
Outline
• Building Brains• Computer Architecture Perspective• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 34
Circuit-level concurrency
• Delay-insensitive comms– 3-of-6 RTZ on chip– 2-of-7 NRZ off chip
• Deadlock resistance– Tx & Rx circuits have high deadlock
immunity– Tx & Rx can be reset independently
• each injects a token at reset• true transition detector filters surplus
token
din
(2 phase)
dout
(4 phase)
¬reset ¬ack
Tx Rxdata
ack

ACACES 12 July 2009 35
System-level concurrency
• Breaking symmetry– any processor can be Monitor Processor
• local ‘election’ on each chip, after self-test
– all nodes are identical at start-up• addresses are computed relative to node with host
connection (0,0)
– system initialised using flood-fill• nearest-neighbour packet type• boot time (almost) independent of system scale

ACACES 12 July 2009 36
Application-level concurrency
• Event-driven real-time software– spike packet arrived
• initiate DMA
– DMA of synaptic data completed
• process inputs• insert axonal delay
– 1ms Timer interrupt
update_Neurons();
update_Stimulus();
sleeping
event
goto_Sleep();
Priority 1 Priority 2Priority 3
Timer MillisecondInterrupt
DMA CompletionInterrupt
Packet ReceivedInterrupt
fetch_Synaptic_
Data();

ACACES 12 July 2009 37
Application-level concurrency
• Cross-system delay << 1ms– hardware
routing– ‘emergency’
routing• failed links• Congestion
– if all else fails• drop packet

ACACES 12 July 2009 38
• Firing rate population codes– N neurons– diverse tuning– collective coding of
a physical parameter– accuracy– robust to neuron
failure(Neural Engineering,
Eliasmith & Anderson 2003)
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 10
50
100
150
200
250
300
350
400
450
500
firin
g ra
te
parameter
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 10
50
100
150
200
250
300
350
400
450
500
firin
g ra
te
parameter
N
Biological concurrency

ACACES 12 July 2009 39
Unordered N-of-M
Ordered N-of-M
M-bit binary
Number of codes CNM M!/(M-N)! 2M
e.g. M=100, N=20 1021 1039 1030
e.g. M=1000, N=200 10216 10591 10301
• Single spike/neuron codes– choose N to fire from a population of M– order of firing may or may not matter
Biological concurrency

ACACES 12 July 2009 40
Outline
• Building Brains• Computer Architecture Perspective• Living with Failure• Design Principles• The SpiNNaker system• Concurrency• Conclusions

ACACES 12 July 2009 41
Software progress
• ARM SoC Designer SystemC model
• 4 chip x 2 CPU top-level Verilog model
• Running:• boot code• Izhikevich model• PDP2 codes
• Basic configuration flow
• …it all works!

ACACES 12 July 2009 42
Where might this lead?
• Robots– iCub EU project– open humanoid
robot platform– mechanics, but no
brain!

ACACES 12 July 2009 43
Conclusions
• Many-core processing is coming– soon we will have far more processors than we can
program• When (if?) we crack parallelism…
– more small processors are better than fewer large processors
– synchronization, coherent global memory, determinism, are all impediments
• Biology suggests a way forward!– but we need new theories of biological concurrency

ACACES 12 July 2009 44
UoM SpiNNaker team