computing and networking with fpgas and...
TRANSCRIPT

Informatik V
Computing and networking with FPGAs and GPUs
Andreas Kugel
Dept. for Application Specific Computing (ASC)
at Institute for Computer Engineering (ZITI) Heidelberg

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 2
Contents
• Intro ASC, CAG of ZITI• FPGA technology• ATLAS activities• GRACE project / SPH
– FPGA– GPU
• Networking (CAG)

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 3
ASC Activities
• Head: Prof. Dr. Reinhard Männer– Physics => Computer Engineering
• http://www.ziti.uni-heidelberg.de/ziti/
• Main Areas– Trigger and Data Acquisition in High Energy Physics
• ATLAS at LHC, CBM, XFEL
– Accelerated Scientific Computing (G. Marcus)• Simulations, Biocomputing (Haralick Feature Extraction)
– Virtual Reality in Medicine• Software and training machinery (also spin-off)
• Technologies: general purpose (CPU, GPU) + custom FPGA processors

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 4
CAG Activitites
• Neighbouring dept. with focus on computer architecture and communication– Head: Prof. Dr. Ulrich Brüning
• http://ra.ziti.uni-heidelberg.de/index.php
• High-speed, low latency interconnects– Optical communication infrastructure for physics
experiments– Active optical cables (AOC)– Accelerated cluster interconnects (FPGA/ASIC)
• EXTOLL low latency protocol• HTX(2,3) and PCIe (1,2) implementations

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 5
Thanks to ...
• Collaboration with R. Spurzem/ARI HD since 1998– Provides scientific use case for “application specific
computing”– Astrophysical simulations on accelerated clusters– Thanks to Rainer ... and Peter Berczik ...
• Support by Volkswagenstiftung / Baden-Württemberg for GRACE project

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 6
Technology
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 7
FPGA Technology
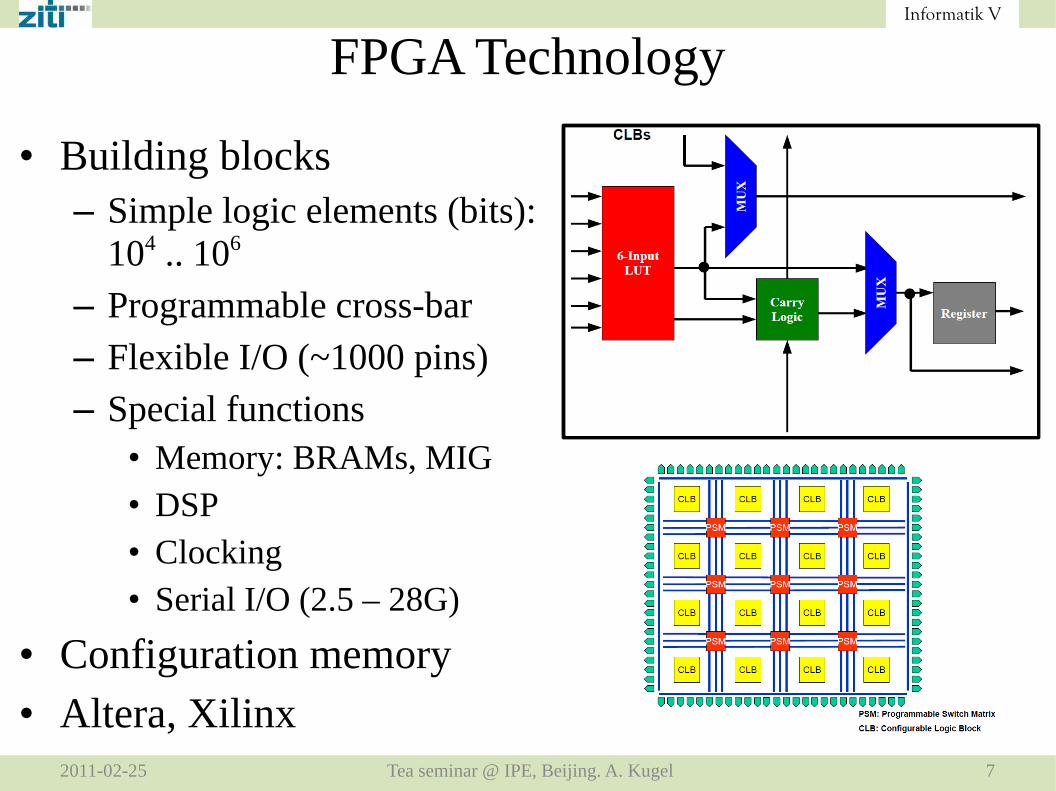
• Building blocks– Simple logic elements (bits):
104 .. 106
– Programmable cross-bar
– Flexible I/O (~1000 pins)
– Special functions• Memory: BRAMs, MIG• DSP• Clocking• Serial I/O (2.5 – 28G)
• Configuration memory
• Altera, Xilinx
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 8
FPGA Application Areas
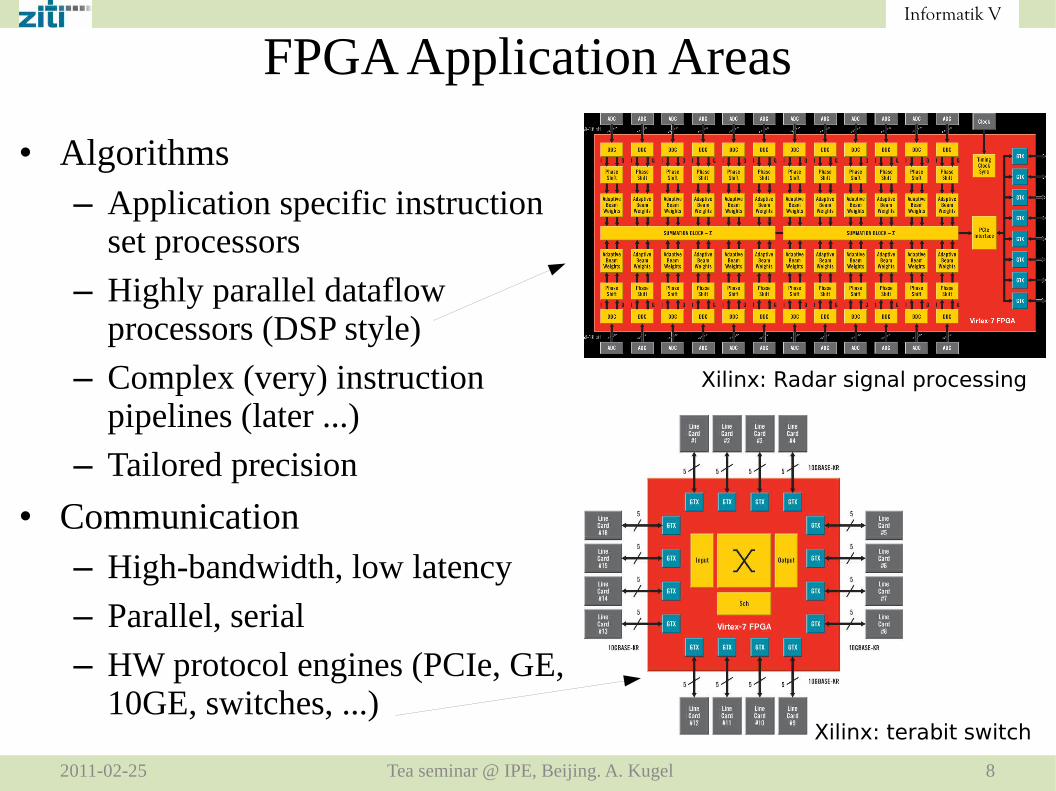
• Algorithms– Application specific instruction
set processors
– Highly parallel dataflow processors (DSP style)
– Complex (very) instruction pipelines (later ...)
– Tailored precision
• Communication– High-bandwidth, low latency
– Parallel, serial
– HW protocol engines (PCIe, GE, 10GE, switches, ...)
Xilinx: Radar signal processing
Xilinx: terabit switch

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 9
FPGA design flow
• Special coding style– HDL
– Blocks (MATLAB, IP-cores, ...)
– Pipeline Generators
– C-based (Impulse-C, Catapult-C, FCUDA, OpenCL, LLVM) exist ...
• Special tools flows– Simulation – takes time
– Compilation – takes more time, O(hours)
– Timing closure – iterate over sim + comp ... ATLAS FPGA histogramming

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 10
FPGA Co-Processors
• Co-Pro Blocks– Main FPGA– Host IF– Local DRAM– Local SRAM– I/O expansion– Clk, Ctl, Cfg
• Activities– Boards: VME, cPCI, PCI, PCIe (HTX at CA dept.)– Algorithms: stand-alone + hybrid– Tools: compilers, libraries, frameworks
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 11
Co-processors cont'
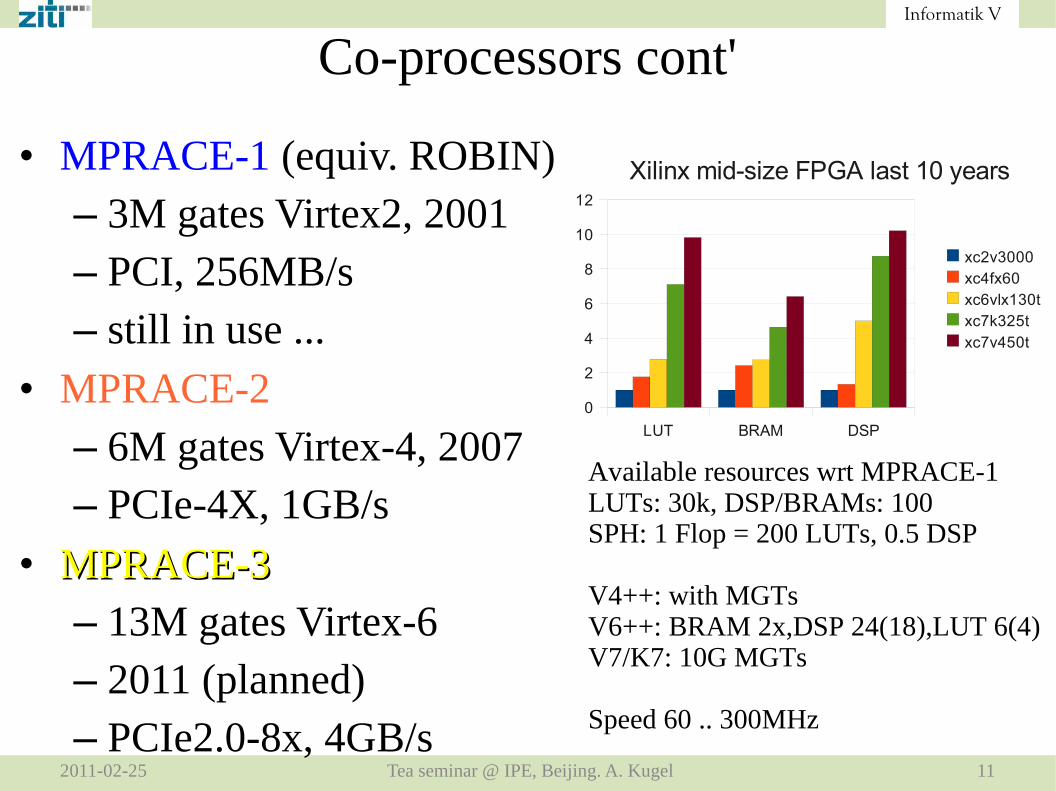
• MPRACE-1 (equiv. ROBIN)– 3M gates Virtex2, 2001– PCI, 256MB/s– still in use ...
• MPRACE-2– 6M gates Virtex-4, 2007– PCIe-4X, 1GB/s
• MPRACE-3MPRACE-3– 13M gates Virtex-6– 2011 (planned)– PCIe2.0-8x, 4GB/s
Available resources wrt MPRACE-1LUTs: 30k, DSP/BRAMs: 100SPH: 1 Flop = 200 LUTs, 0.5 DSP
V4++: with MGTsV6++: BRAM 2x,DSP 24(18),LUT 6(4)V7/K7: 10G MGTs
Speed 60 .. 300MHz
LUT BRAM DSP
0
2
4
6
8
10
12
Xilinx mid-size FPGA last 10 years
xc2v3000xc4fx60xc6vlx130txc7k325txc7v450t

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 12
MPRACE-2
10GE mezzanine

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 13
Software architecture
• Driver– Linux
• Generic driver
• Kernel/user mode
– IRQ handler (device spec)
– PCI + memory resources• SG-lists
– C, C++ user API
– Configurable devices IDs
• Libraries– Buffer management
• Buffer + translate
– Multi-client server (dynamic device allocation)
– Device library (next slide)

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 14
Device library
Board specific

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 15
PCI performance (Gen 1, 4x)
Downstream (FPGA reading)Upstream (host writing)
800MB/s upstream, 700MB/s downstreamBig difference, platform dependant, > factor 2xBest results with polling on FPGA register (DMA done). IRQ rates lower for packets < ~256kB
PCIe2.0 8x tests in progress

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 16
Computing

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 17
FPGA computing
• Pre 2000
– FPGAs too small for floating point
• 2000..2007
– Big speedups with “massive” parallel implementations
– Several accelerated machines, SGI, Cray, ...
• Since
– GPUs dominating
– Niches exist still ..
Altera, 2007: Speedup 10..370
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 18
GPU computing
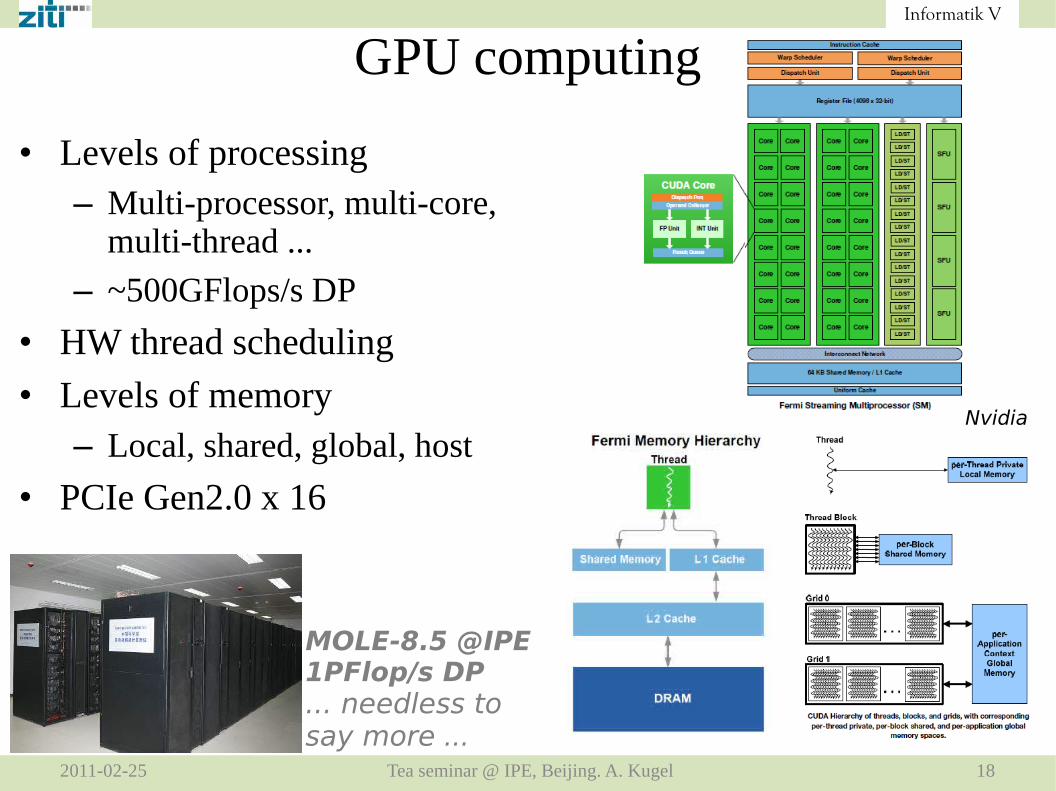
• Levels of processing– Multi-processor, multi-core,
multi-thread ...
– ~500GFlops/s DP
• HW thread scheduling
• Levels of memory– Local, shared, global, host
• PCIe Gen2.0 x 16
Nvidia
MOLE-8.5 @IPE1PFlop/s DP... needless to say more ...

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 19
Accelerating applications
• Acceleration = Parallelism
• CPU,GPU,FPGA,ASIC
– different levels of parallelism, tools, W/Flop
• Heterog. multicores: speedup drops rapidly with f (fraction of acceleratable time)
• Technology doesn't helpE.S Chung et al., 2010
now300 40 8

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 20
ATLAS
• Largest LHC particle detector
• Initial rate ~ 1GHz @ 108 channels (40MHz BX)
• H->4µ rate: 1000/a
• Trigger/DAQ: reduction to 100Hz*1MB– Don't loose any Higgs!
• Offline: Tier 0/1/2 data centers (e.g IHEP Beijing tier 2)
p pH
µ+
µ-
µ+
µ-
Z
Z
44*26m, 7000t
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 21
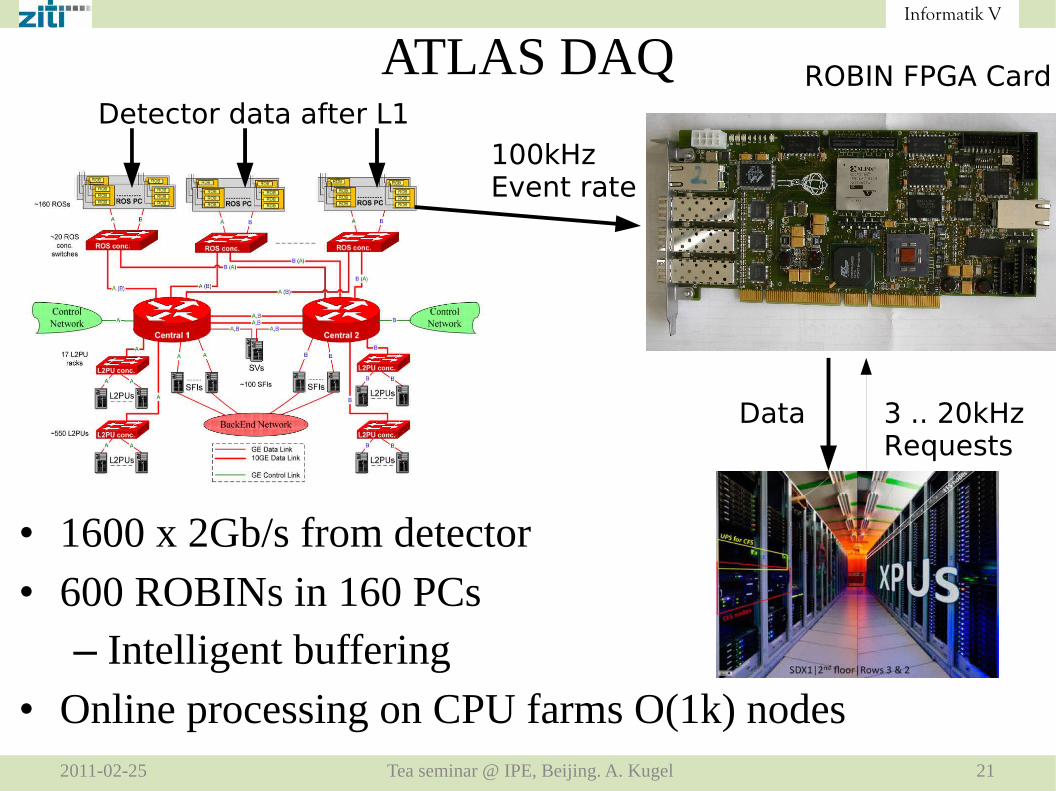
ATLAS DAQ
• 1600 x 2Gb/s from detector
• 600 ROBINs in 160 PCs– Intelligent buffering
• Online processing on CPU farms O(1k) nodes
100kHzEvent rate
3 .. 20kHzRequests
Data
ROBIN FPGA CardDetector data after L1

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 22
ATLAS Processing
• Tracking @ L2: Find tracks from RoI data– 1) Find tracks: Hough, Zfinder
• High-Luminosty: ~30 * #hits
– 2) Fit tracks: Fitting, Kalman to obtain track parameters
– CPU solutions installed
– FPGA solution for Hough (dropped)
– New GPU implementation for ZF/ Kalman: speedup ~ 35/5 (Tesla 1060)
• Upgrade: RoIs not sufficient – FTK (FPGA+CAM) after L1
– 109 patterns parallel, 103 speedup
ATLAS FTK collaboration
Vertex
P.J.Clark et al., 2011
A. Khomich et al., 2006
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 23
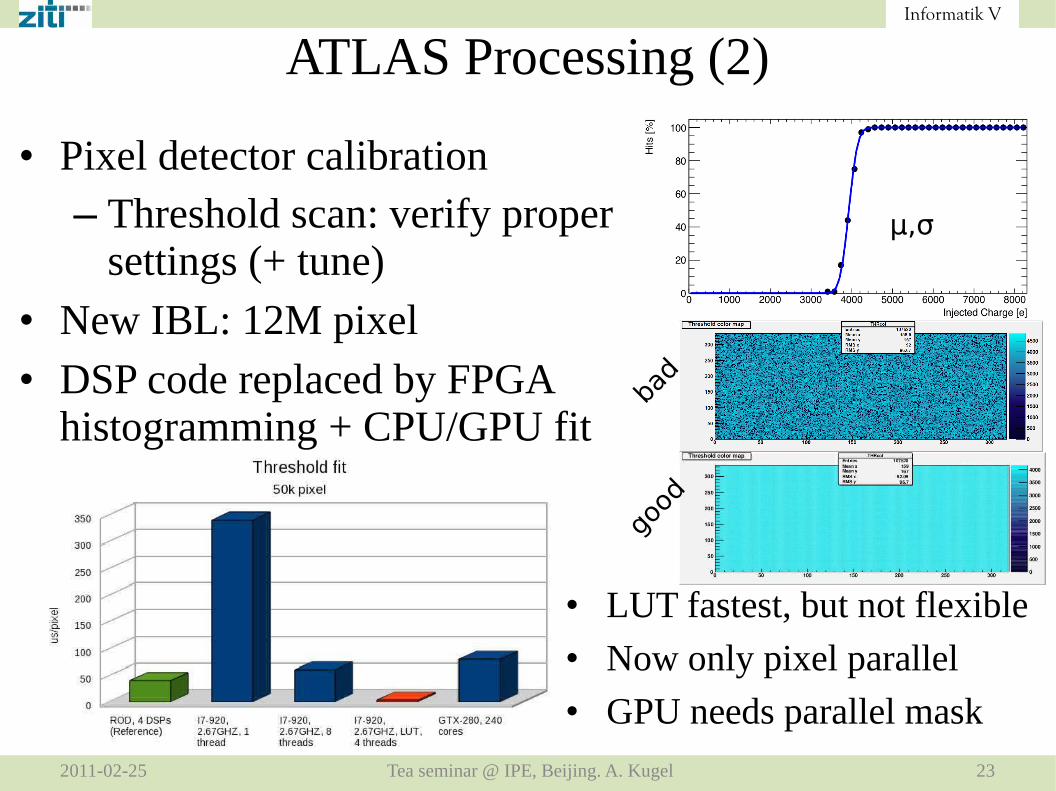
ATLAS Processing (2)
• Pixel detector calibration– Threshold scan: verify proper
settings (+ tune)
• New IBL: 12M pixel
• DSP code replaced by FPGA histogramming + CPU/GPU fit
μ,σ
• LUT fastest, but not flexible
• Now only pixel parallel
• GPU needs parallel mask
bad
good

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 24
The GRACE Project
• Galaxy evolution: considering diffuse interstellar matter requires SPH (hydrodynamic force)
• Goal: Hybrid system for N-Body + SPH– CPU: Orbital Integration + I/O, O(N)– GRAPE: Gravitational force, O(N²)
• Now on GPU• Big speedup
• Once gravitation is done, SPH is most time consuming
– FPGA: SPH, O(Nn*N)
• Now on GPU• But also FPGA

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 25
SPH
• Two steps: density, acceleration
• Loop over particles (i), with neighbours (j). O(j) ~ 50
• Store intermediate results on host

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 26
SPH on FPGA
• Step 2 pipeline– 60 float ops
• Limited precision (16 bit significant)
• Algorithm not executed but cast into hardware
• Systolic process

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 27
FPGA Programming
• Algorithm: building-blocks + pipeline generator (PDL)
• Memory: External SRAM => custom interface
• I/O via PCIe => custom interfaceentity distance;clock clk;# parametersfloPValDef fpDef(m=>24, e=>8,s=>1,z=>0); # inputssignal (suppress_v);floPVal (v,a,t)(fpDef );
# calculatet2 = <floPSquare> t; s1 = v <floPMult> t;ss1 = gated(s1,suppress_v);half_a = <floPDiv2> a;s2 = half_a <floPMult> t2;s = ss1 <floPAdd> s2;
re s e t i D a t a
A s a v e
l a t c hQ
A s a v e
la t c hQ
A s a v e
la t c hQ
I 1 I2
s y n cQ 1 Q 2
rX
A X A Y A Z B X B Y B Z
f l o P V e c D if f Z GQ X Q Y Q Z
rY rZp
I 1 I2
c a lc P D iv R h o 2I1 : rh o InI2 : p InQ 1 : p D iv R h o 2 O u t
Q 1
r iX r iY r iZ
r i j X r i jY r i jZ
v r i j
A X A Y A Z B X B Y B Z
f l o P V e c C ro s s P ro dQ X Q Y Q Z
r i j x v i jY r i j x v i jZ
A X A Y A Z
f l o P V e c S q u a reQ
r i j2
p D iv R h o 2
is _ p D iv R h o 2 i p D iv R h o 2 j
A s a v e
la t c hQ
p D iv R h o 2 i
High level description HDL + visual representation

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 28
SPH on GPU
• N(pipelines) ~ 500 .. 1k = x(processors) * y(threads)
• Local, shared and global memory
• Map neighbour lists on threads: must fit in shared memory

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 29
Common GPU/FPGA Framework
• C, C++, Fortran interfaces
• Complete abstraction of SPH capabilities: racesph library
• Intelligent buffer manager, incl. re-formatting for FPGA
• Device specific libraries and drivers

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 30
SPH at ARI
• Two clusters in operation, Infiniband + accelerators
• HD(32) Grape+MPRACE-1
• MA(42) Tesla+MPRACE-2
• FPGA ~7GFlops @ 20W
• GPU (GTX8800) 2* as fast @ 150W
• Speedup ~ 10
• HW not up-to-date ...
GRAPE now GTX9800
Spurzem et al. 2007,2009
ARI Titan cluster, 4TF/s
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 31
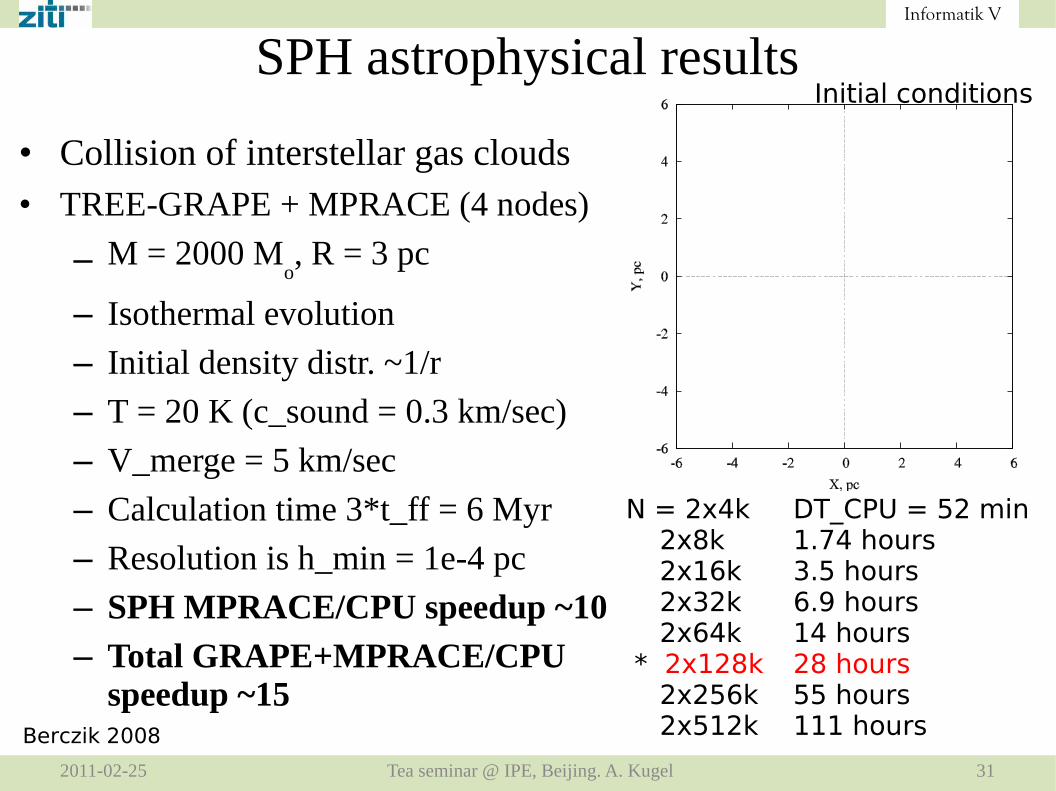
SPH astrophysical results
• Collision of interstellar gas clouds• TREE-GRAPE + MPRACE (4 nodes)
– M = 2000 Mo, R = 3 pc
– Isothermal evolution
– Initial density distr. ~1/r
– T = 20 K (c_sound = 0.3 km/sec)
– V_merge = 5 km/sec
– Calculation time 3*t_ff = 6 Myr
– Resolution is h_min = 1e-4 pc
– SPH MPRACE/CPU speedup ~10
– Total GRAPE+MPRACE/CPU speedup ~15
N = 2x4k DT_CPU = 52 min 2x8k 1.74 hours 2x16k 3.5 hours 2x32k 6.9 hours 2x64k 14 hours * 2x128k 28 hours 2x256k 55 hours 2x512k 111 hours
Initial conditions
Berczik 2008

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 32
SPH astrophysical results (2)Colliding ...

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 33
Networking

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 34
Network = bandwitdth & latency problems
• Parallelism is key to application acceleration
• Parallel applications are distributed applications
• Inter-node latency must be hidden/reduced for good scaling– Commodity networks don't
perform so well ...
– Some apps can tolerate latency
• Solution by CAG group: EXTOLL-based low-latency network

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 35
EXTOLL Network
• Sub-µs end-to-end latency
• Switch-less, 3D-torus– Hop latency O(100ns)
• Reliable transport– CRC, retransmission
• Hardware barriers• Hardware multicast• Global interrupts
Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 36
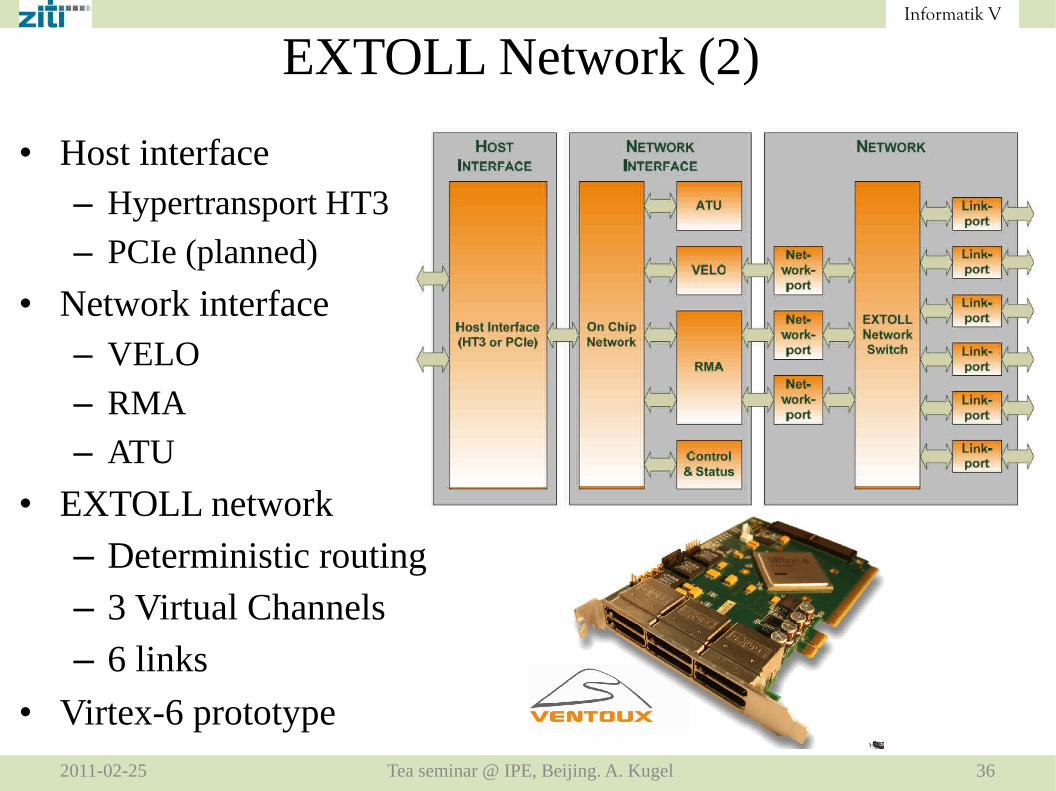
EXTOLL Network (2)
• Host interface– Hypertransport HT3
– PCIe (planned)
• Network interface– VELO
– RMA
– ATU
• EXTOLL network
– Deterministic routing
– 3 Virtual Channels
– 6 links
• Virtex-6 prototype

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 37
EXTOLL SW Architecture
• Separate application and management interfaces
• Middleware and low-level API access
– MPI/OpenMPI
– PGAS/GasNET (prototype)
– Message based (libVELO)
– Shared memory (libRMA)
• Set of Linux kernel drivers
• Management software

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 38
Host interfaces
• Hypertransport inherently lower latency than PCIe => 1st choice– Interfaces directly to
CPU: AMD only– Small overhead, no
encoding– 8/16 bit DDR HT3
@400,600 .. 2400 MHz– HT3 protocol engine
• Sync, framing, buffers

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 39
Host interfaces (2)
• PCIe– Off-CPU (any)– Bi-directional serial
interface• 2.5, 5, 8 Gbit/s• 1, 4, 8, 16 switched,
packed based• 8B10B encoding,
CDR required• Ubiquitous ...• Many slots/node

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 40
HTX/EXTOLL enabled systems
• Experimental HTX cluster (8 nodes) at ZITI– Application testing– No GPU (as no PCIe)
• HTX + PCIe ZITI demonstrator– Upgrade to Ventoux this
spring– GPU + EXTOLL possible
• Commercial HT2600 ASIC-based ~2012

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 41
More custom interconnects
• FPGAs capable to run 40G and 100G links• Xilinx XC7VH870T
– 16 * 28Gbit/s – 72 * 13Gbit/s
• Xilinx XC7K325T– 16 * 11Gbit/s
• Potential for custom computing/communication accelerators?– Plus embedded GPUs?

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 42
Summary
• HPC dominated by GPU-accelerated clusters• Scaling of some applications suffers from network
latencies– Low-latency implementations needed (EXTOLL)
• FPGA-based accelerators– where GPUs don't perform well (thread/memory
mapping ...)– Fast I/O on accelerator– Special applications (embedded, ATLAS ...)– Power consumption

Informatik V
2011-02-25 Tea seminar @ IPE, Beijing. A. Kugel 43
Thanks for you attention