comparison of the effects of broad-band noise … · j.p. vetrano chief, comsec engineering office...
TRANSCRIPT

RADC-TR-86-135 In-House Report August 1986
COMPARISON OF THE EFFECTS OF BROAD-BAND NOISE ON SPEECH INTELLIGIBILITY AND VOICE QUALITY RATINGS
Caldwell P. Smith
APPROVED FOR PUBLIC RELEASE; DISTRIBUTION UNLIMITED
ROME AIR DEVELOPMENT CENTER Air Force Systems Command
Griffiss Air Force Base, NY 13441-5700
AD/AI76TOO

This report has been reviewed by the RADC Public Affairs Office (PA) and is releasable to the National Technical Information Service (NTIS). At NTIS it will be releasable to the general public, including foreign nations.
RADC-TR-86-135 has been reviewed and is approved for publication.
APPROVED: J^^^-
J.P. VETRANO Chief, COMSEC Engineering Office Electromagnetic Sciences Division
APPROVED:
ALLAN C. SCHELL Chief, Electromagnetic Sciences Division
FOR THE COMMANDER
JOHN A. RITZ Plans and Programs Division
DESTRUCTION NOTICE - For classified documents, follow the procedures in DOD 5200.22-M, Industrial Security Manual, Section 11-19 or DOD 5200.1-R, Information Security Program Regulation, Chapter IX. For unclassified, limited documents, destroy by any method that will prevent disclosure of contents or reconstruction of the document.
If your address has changed or if you wish to be removed from the RADC mailing list, or if the addressee is no longer employed by your organization, please notify RADC (EEV) Hanscom AFB MA 01731-5000. This will assist us in maintaining a current mailing list.
Do not return copies of this report unless contractual obligations or notices on a specific document requires that it be returned.

Unclassified SECURITY CLASSIFICATION OF THIS PAGE
REPORT DOCUMENTATION PAGE la. REPORT SECURITY CLASSIFICATION
Unclassified lb RESTRICTIVE MARKINGS
2a SECURITY CLASSIFICATION AUTHORITY
2b OECLASSIFICATION / DOWNGRADING SCHEDULE
3 DISTRIBUTION/AVAILABILITY OF REPORT
Approved for public release; distribution unlimited.
4 PERFORMING ORGANIZATION REPORT NUMBER(S)
RADC-TR-86-135 5 MONITORING ORGANIZATION REPORT NUMBER(S)
6a. NAME OF PERFORMING ORGANIZATION Rome Air Development
Center
6b OFFICE SYMBOL (It applicable)
EEV
7J NAME OF MONITORING ORGANIZATION
Rome Air Development Center (EEV)
6c ADDRESS (Cry. State, and ZIP Code)
Hanscom AFB Massachusetts 01731-5000
7b ADDRESS (dry. Suit, and ZIP Cod*) Hanscom AFB Massachusetts 01731
8a. NAME OF FUNDING/SPONSORING ORGANIZATION Rome Air
Development Center
8b OFFICE SYMBOL (If applicable)
EEV
9 PROCUREMENT INSTRUMENT IDENTIFICATION NUMBER
8c. ADDRESS (City. Slate, and ZIP Code)
Hanscom AFB Massachusetts 01731-5000
10 SOURCE OF FUNDING NUMBERS
PROGRAM ELEMENT NO
33401F
PROJECT NO
7820
TASK NO
03
WORK UNIT ACCESSION NO
01 11 TITLE (Include Security Classification) .,..,...
Comparison of the Effects of Broad-Band Noise on Speech Intelligibility and Voice Quality Ratings
12 PERSONAL AUTHOR(S) Caldwell P. Smith
13a TYPE OF REPORT In-House
13b TIME COVERED FROM 85-8-1 TQ86-3-31
14 DATE OF REPORT (Year, Month, Day) 1986 August
15 PAGE COUNT 40
16 SUPPLEMENTARY NOTATION
COSATI CODES
FIELD
17 GROUP
02 SUB GROUP
ecessary and identity by Woo Speech perception
IB SUBJECT TERMS (Continue on reverie if necessary and identify by block number) Voice communication Intelligibility Articulation index
19 ABSTRACT (Continue on reverie if necessary and identify by block number)
Results of a study of effects of broad-band noise on speech intelligibility and voice quality are presented, with a comparison of three methods for evaluating speech signals: the Diagnostic Rhyme Test (DRT) for speech intelligibility, the Diagnostic Acceptability Measure (DAM) test for voice quality and acceptability, and the Mean Opinion Score (MOS also for evaluating speech quality and acceptability.
Speech samples were combined with broad-band noise, with accurate calibration of speech-to-noise energy ratios by using a new measurement algorithm developed under RADC sponsorship. Four scramblings (randomizations) of the Diagnostic Hhyme Test were prepared with each of three male speakers, for assessing speech intelligibility. Connected speech samples from the three speakers were prepared for assessing voice quality and acceptability. The processed speech samples were digitally recorded for subsequent presentation to listener crews.
20 DISTRIBUTION/AVAILABILITY OF ABSTRACT • UNCLASSIFIED/UNLIMITED Q SAME AS RPT DDTIC USERS
21 ABSTRACT SECURITY CLASSIFICATION Unclassified
22a NAME OF RESPONSIBLE INDIVIDUAL Caldwell P. Smith
22b TELEPHONE (Include Area Code)
(617) 377-3281 22c OFFICE SYMBOL
RADC/EEV DO FORM 1473.84 MAR 83 APR edition may be used until eahausted
All other editions are obsolete. SECURITY CLASSIFICATION OF 'HIS PAGE
Unclassified

Unclassified
19. (Contd)
The resulting intelligibility scores were used in constructing the relationship between Diagnostic Rhyme Test scores and values of the articulation index. From this relationship it was possible to estimate from previous standardized intelligibility data, the percent accuracy with which listeners would be expected to receive stereotyped operational messages ("sentences known to listeners") corresponding to various DRT intelligibility scores. For example, it was estimated that a DRT intelligibility score of 70, which has been estimated to be the threshold value below which intelligibility would be unacceptable, corresponds approximately to the value of the articulation index for which listeners would be expected to get 92 percent correct "sentences known to listeners. "
Intelligibility scores and voice quality ratings were also used in constructing regression models relating scores with speech-to-noise energy ratios. Category- scales for intelligibility scores, and voice quality ratings, were compared on a basis of their common relation to the scale of S/N ratios. It was determined that categories (for example, "very good", "fair"; and so on) for intelligibility scores and for DAM voice quality ratings were in rough agreement at the top and bottom of the range studied here (30 dB S/N ratio to 6 dB S/N ratio) but agreed poorly in the middle of the range. Categories for mean opinion scores were in poor agreement with the other two category scales.
Unclassified

Preface
The method for calibrating speech-to-noise energy ratios and the software
for using that algorithm were devised by J.T. Sims. The voice recordings of
speech with noise were prepared by Paul Gatewood. The assistance of
Marianne Bahia, John Fisher, John Olender, Fred Reinhard, Denis Robitaille
and Luigi Spagnuolo in making this study possible is gratefully acknowledged.
11!

Contents
1. INTRODUCTION 1
2. SPEECH MATERIALS FOR ASSESSING EFFECTS OF BROAD-BAND NOISE 2
3. LISTENER TESTS 3
4. INTELLIGIBILITY TESTS RESULTS 3
5. COMPARISONS WITH THE ARTICULATION INDEX 8
6. SPEECH PERFORMANCE WITH "OPERATIONAL MESSAGES" 10
7. VOICE QUALITY AND ACCEPTABILITY TESTS 11
8. MEAN OPINION'SCORES 15
9. COMPARISON OF CATEGORY SCALES 17
10. DISCUSSION 18
11. CONCLUSIONS 18
REFERENCES 2 1
APPENDIX A: Details of Variation in Diagnostic Rhyme Test Feature Scores With Speech-to-Noise Energy Ratios 23

Illustrations
1. Scatter Diagram of Overall Intelligibility Scores by Speakers lor Speech in Broad-band Noise, With a Regression Model Based on the Reciprocal of S/N Ratio 4
2. Category Scale for Diagnostic Rhyme Test Intelligibility Scores, With Examples of Voice Processor Categories 5
3. Intelligibility Scores and Regression Model for Speech in Broad-band Noise, in Relation to the Category Scale for Diagnostic Rhyme Test Intelligibility Scores 6
4. Intelligibility Scores vs S/N Ratio, With Multiple Regression Lines Calculated for Individual Male Speakers 7
5. Regression Lines vs S/N Ratio for the Individual Phonetic Features That Contribute to Intelligibility 8
6. Intelligibility Contours for Different Speech Materials Plotted vs the Articulation Index, With Contour for Diagnostic Rhyme Test Scores Obtained From These Studies 9
7. Scatter Diagram of Scores for Signal Quality vs S/N Ratio With Regression Model and 95 Percent Confidence Limits for the Ensemble of Scores 12
8. Scatter Diagram of Scores for Background Quality vs S/N Ratio With 2nd Order Regression Model Based on the Reciprocal of S/N Ratio 12
9. Scatter Diagram of Scores for Overall Voice Quality vs S/N Ratio With 2nd Order Regression Model Based on the Reciprocal of S/N Ratio 13
10. Category Scale for Diagnostic Acceptability Measure Voice Quality Scores With Examples of Voice Processor Categories 14
11. Scores for Overall Voice Quality vs S/N Ratio and Regression Model, in Relation to the Category Scale for Diagnostic Acceptability Measure Voice Quality Scores 15
12. Scatter Diagram of Mean Opinion Scores vs S/N Ratio With Linear Regression Model 16
13. Mean Opinion Scores and Linear Regression Model in Relation to the Categories Used by Listeners 16
14. Comparison of the Category Scales for Intelligibility Scores, Voice Quality Scores, and Mean Opinion Scores in Relation to the Scale for S/N Ratio and the Estimates of Values of the Articulation Index 17
Al. Regression Models for the Scores for Voicing-present, Voicing-absent, and Voicing (total) vs the Reciprocal of S/N Ratio 24
A2. Regression Models for Voicing-frictional, Voicing-non-frictional, and Voicing (total) vs the Reciprocal of S/N Ratio 24
A3. Regression Models for Voicing-frictional vs the Reciprocal of S/N Ratio, Indicating the Differences Among the Three Male Speakers 25
VI

Illustrations
A4. Regression Models for Voicing (total) vs the Reciprocal of S/N Ratio, Indicating Differences Among the Three Male Speakers 25
A5. Regression Models for Nasality Scores vs S/N Ratio Indicating Virtually No Differences Between the Total Score, and the Present and Absent State 26
A6. Regression Models for the Nasality Scores vs S/N Ratio, Indicating Only Slight Differences Between Total Scores and the Grave and Acute States 26
A7. Regression Models for Sustention (total) vs Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers 27
A8. Regression Models for Sustention-voiced vs the Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers 27
A9. Regression Models for Sustention-unvoiced vs Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers 28
A 10. Regression Models for Sibilation vs the Reciprocal of S/N Ratio, Showing Differences Between the Present and Absent State of Sibilation 29
All. Regression Models for Sibilation vs the Reciprocal of S/N Ratio, Showing Differences Between the Voiced and Unvoiced State of Sibilation 29
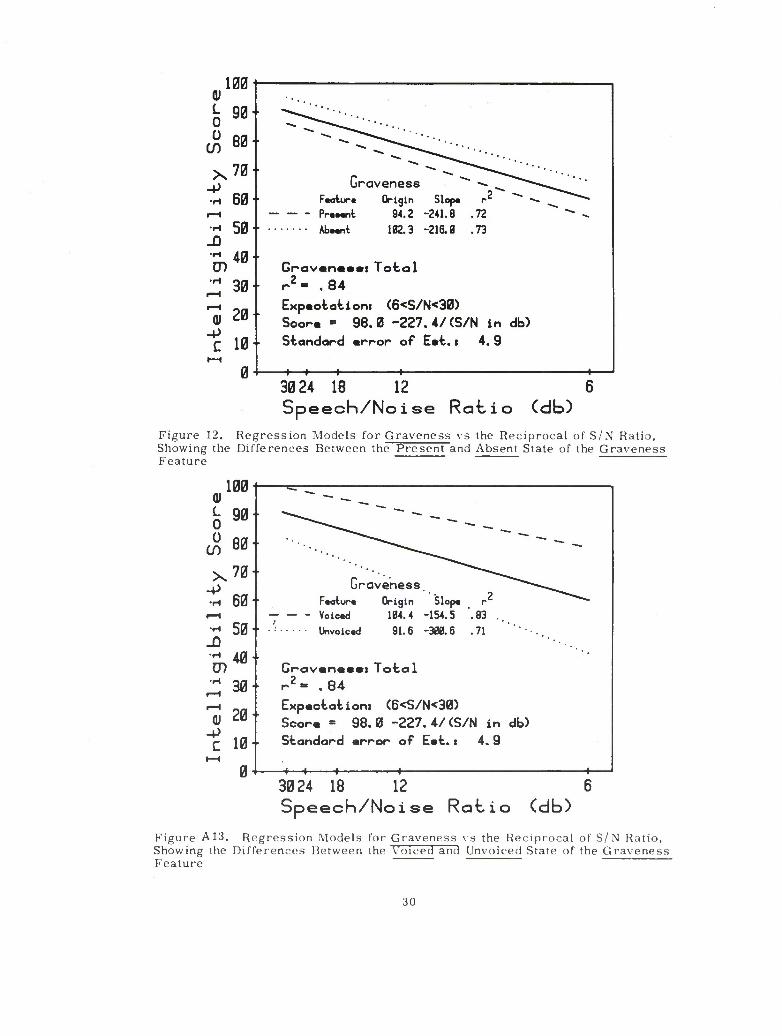
A 12. Regression Models for Graveness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Present and Absent State of the Graveness Feature 30
A 13. Regression Models for Graveness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Voiced and Unvoiced State of the Graveness Feature 30
A 14. Regression Models for Compactness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Present and Absent State of the Compactness Feature 31
A 15. Regression Models for Compactness vs the Reciprocal of S/ N Ratio, Showing the Differences Between the Voiced and Unvoiced State of the Compactness Feature 3 1
Tabl es
1. Estimate of Speech Performance With "Operational Messages"
vu

Comparison of the Effects of Broad-Band Noise on Speech Intelligibility and Voice Quality Ratings
1. INTRODUCTION
In the past few years, increased attention has been focused on effects of
acoustic background noise in degrading performance of digital voice communications
processors. In order to expand the information on this problem, a number of noise
environments of special interest including jet and prop aircraft cabin noise, typical
office noise, noise in shipboard environments, and the background noise in certain
vehicles were measured and recorded, and subsequently simulated in sound rooms
for the purpose of preparing standardized speech recordings representative of the
effects of those noise environments, for assessing speech intelligibility and voice
quality of various digital voice communications processors.
Those studies did not attempt to address the effects of noise environments on
listeners, for several reasons. Designers of digital voice processors and pre-
processors have virtually no options available for modifying their algorithms to
remedy that problem. In many cases, appropriate headphones and ear protectors
provide adequate solutions to the problem of noisy listener environments. Of
particular importance, speech testing to assess voice quality and naturalness is
most critically conducted when listeners are in a quiet environment, since when
listeners are placed in a noisy acoustic environment for the purpose of conducting
(Received for publication 7 August 1986)

speech tests, the noise can tend to mask distortions and make systems having
degraded voice quality sound more acceptable.
Using recorded speech test materials representing the various noise environ-
ments that were simulated, it has been possible to conduct intelligibility and voice
quality tests of voice processors with a high degree of reliability and repeatibility
of test results. However, it was found that there were wide variations, as much
as 10 to 12 dB, in the speech-to-noise energy ratios of different talkers used in
these simulations, even under conditions of close control of sound pressure levels,
careful phasing of transducers to obtain uniform noise fields, and close attention
to details of microphone placement, instructions to talkers, and so on.
Facing a need to accurately calibrate dozens of recordings of speech by
multiple talkers in various noise environments, a study was funded under which a
contractor worked in the Rome Air Development Center speech test and evaluation
facility to develop a measurement algorithm that might be used to facilitate accurate,
efficient measurement and calibration of speech-to-noise energy ratios. The
successful result of that study has now been published in the literature, and the
measurement algorithm is now being used to accurately calibrate each speaker's
speech recordings in the speech test and evaluation library of recordings used by
the Department of Defense Digital Voice Processor Consortium. The algorithm
was also used to calibrate speech-to-noise energy ratios in this pilot study.
2. SPEECH MATERIALS FOR ASSESSING EFFECTS OF BROAD-BAND NOISE
This study utilized existing recordings of three male speakers in a quiet non-
reverberant acoustic environment, using a high-quality (Altec 659A) dynamic
microphone in a close-talking position approximately 6 cm from the lips. The
reproduced speech signals were electrically mixed with white noise from a broad-
band noise generator and both were low-pass filtered at 4 kHz. Speech levels were 2
standardized using the measurement algorithm of Brady, and using the calibration
method of Sims, the speech-to-noise energy ratios were successively set at 6 dB,
12 dB, 18 dB, 24 dB, and 30 dB. At each S/N ratio high quality digital audio
recordings were prepared with a Sony PCM Fl digitizer, using sentence lists for
the purpose of assessing voice quality and acceptability and four scramblings
1. Sims, J. T. (1985) A speech-to-noise ratio measurement algorithm, J. Acoust. Soc. Am. . 7_8(No. 5): 167 1 - 1674.
2. Brady, P. T. (1968) Equivalent peak level: a threshold-independent speech- level measure, J. Acoust. Soc. Am., 44:695-699.

(randomizations) of the Diagnostic Rhyme Test (DRT) for assessing speech intel-
ligibility, for each of the three male speakers.
3. LISTENER TESTS
Evaluations of the speech test materials were performed "blind" by a con-
tractor, Dynastat Inc. , in which ten-member listener crews were presented the
reproduced digital recordings at an optimum listening level over headphones in a
sound room. Listener judgements of voice quality and acceptability were assessed
independently by two methods: the Diagnostic Acceptability Measure (DAM) test 3 4 of Voiers, and by mean opinion scores (MOS).
4. INTELLIGIBILITY TESTS RESULTS
Results of these intelligibility tests are summarized in Figure 1. Using three
talkers and four replications of the test at each of the five S/N ratios provided 12
speaker scores at each S/N ratio, or 60 scores in all. The scatter diagram of
scores shows the variation in scores that occurred at each S/N ratio, and an
exaggeration of a typical tendency for dispersion of scores to vary inversely with
the average score. Several regression models were calculated for the relationship between
intelligibility scores and S/N ratio, which led to a choice of the equation and
regression line shown plotted in Figure 1, expressing intelligibility in relation
to the reciprocal of the S/N ratio in dB. That particular regression model re- 2
suited in a value of r = 0. 9 1 and a standard error of estimate of 2. 48. The
regression equation is obviously not useful for extrapolating outside the range from
6 to 30 dB S/N (on this scale, 0 dB S/N is at infinity). However, the regression
model is suited for the purpose intended here, of relating this data to a scale of
categories of speech intelligibility scores.
3. Voiers, VV. D. (1977) Diagnostic acceptability measure for speech communica- tions systems, IEEE Proc. 1CASSP 77CH1197-3 ASSP. pp. 204-207.
4. CCITT (1981) Telephone Transmission Quality: Recommendations of the P Series, Yellow Book Vol. V, ITU, Geneva.

<D L 0 0
CO
X
100
90-
Q J) 80 + •H
U) *2- .91
^ ?C| I Expectation! (6<S/N<30> Q) /lfl T ORT SCOT.
-P C
101.5 - 158.6/CS/N in db)
i i 3024 18 12
Speech/Noise Rat 10 (db)
Figure 1. Scatter Diagram of Overall Intelligibility Scores by Speakers, for Speech in Broad-band Noise, With a Regression Model Based on the Reciprocal of S/N Ratio
The category scale for DRT intelligibility scores was established to assist in
the interpretation of intelligibility scores by users and planners of digital voice
communications systems. Intelligibility scores are classified in terms of eight
categories, ranging from "excellent" to "unacceptable", based on the ranges
illustrated in Figure 2. This category scale, which has been published previously
rates intelligibility scores below 70 as "unacceptable". However, there has been
some evidence that highly stereotyped messages well-known to talkers and
listeners can be successfully exchanged over a telephony channel even under condi-
tions such that the average intelligibility of the channel (assessed with the Diagnostic
Rhyme Test) is below 70.
5, 6
5. Smith, C. P. (1983) Narrowband (LPC-10) Vocoder Performance Under Combined Effects of Random Bit Errors and Jet Aircraft Cabin Noise, RADC-TR-83-293, ADA141333. Rome Air Development Center, Griffiss AFB, N. Y.
6. Smith, C. P. (1983) Relating the performance of speech processor to the bit error rate. Speech Technology 2(No. 1 ):41-53.

Categories of DRT Intelligibility Scores DRT Score Descriptive Examples
Category
100 " _ ,, o Hiqh Fidelity Speech Excellent 3 ' r
QR oCVSD-32
gi ___!"_r_-°°---_°_C_VS_DI16 o Conus Voice-Grade Tel. Service
Q7 o LPC-10, 'ideal' conditions
" ~ " ~o~LPI>r0~wTth ~error~
__ protection, 2Z BER
o LPC-10; no error
7Q protection, 21 BER -o~LPC~-F0~w7th "er^ro^"
__ protection, SZ BER
o Experimental 800 BPS Very Poor u . D
__ ' Voice Processor
~o LPC~-F0 in Helicopter UNACCEPTABLE newcop er
Figure 2. Category Scale for Diagnostic Rhyme Test Intelligibility Scores, With Examples of Voice Processor Categories
When the category scale is combined with the intelligibility scores and regression
model obtained in this study, the result presented in Figure 3 is obtained. A
30 dB S/N ratio resulted in scores distributed about equally in the "excellent" and
the "very good" categories, with the average value approximately at the boundary
between these categories.
The average score at 24 dB S/N ratio was in the "very good" category, with a few speaker scores in the "excellent" category.
All of the scores clustered in the "very good" category for the 18 dB S/N
condition.
Dispersion of the individual scores was noticeably increased at 12 dB S/N ratio,
with individual scores ranging from "very good" to "fair", with the average value
falling in the "good" category. Still greater dispersion was evident at 6 dB S/N,
individual scores ranging from "fair" (two), to "poor" (four), to "very poor" (five)
to "unacceptable" (one). The average intelligibility obtained at this S/N ratio was
approximately at the boundary between the "poor" and "very poor" categories.

L
90
80-
70*
• excel lent
0 0
CO
X
•SI •
liNJ •
very good
good
r- H moderate 1 \ •
CD
fair • N. • •
poor ^\^.
•H very poor •
d)
c t—1
unacceptable
1 1 1 1
•
1—
30 24 18 12 6
Speech/Noise Ratio (db)
Figure 3. Intelligibility Scores and Regression Model for Speech in Broad-band Noise, in Relation to the Category Scale for Diagnostic Rhyme Test Intelligibility Scores
Individual talkers have been consistently found in hundreds of tests to exhibit
significant differences in intelligibility scores (any intelligibility score based on
a single speaker should be viewed with suspicion). Significant differences were
found in the scores for these three speakers, though the background noise added
to the dispersion of the scores and made the speaker differences less conspicuous.
The relative ranking of the speaker's scores tended to be maintained each S/N ratio;
consequently an alternative regression model with separate regression lines calcu-
lated lor each speaker and having a common slope resulted in an increase of r to
0. 94 and a reduction of the mean square residual. The alternative regression
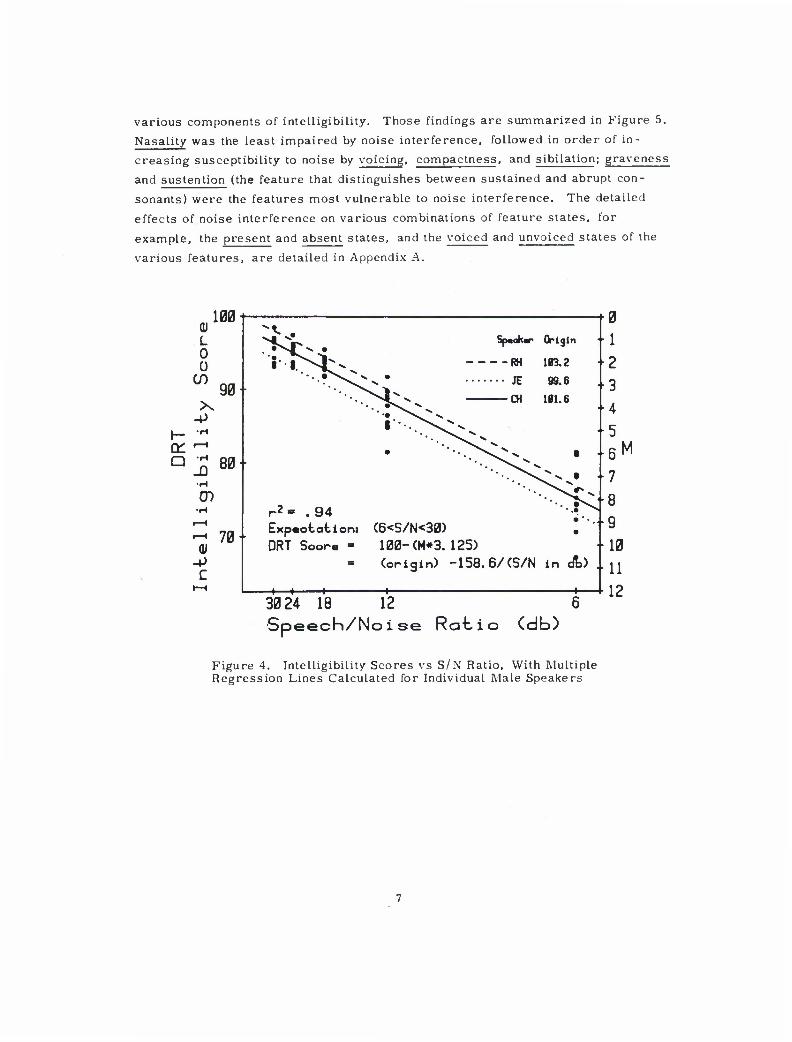
model is illustrated in relation to the scatter diagram of scores in Figure 4.
A "fringe benefit" of intelligibility testing with the Diagnostic Rhyme Test is
that it provides separate, independent scores for various phonetic features that 7 8
contribute to intelligibility ' and permits an evaluation of the effects of noise on
7. Voiers, VV.D. (1977) Diagnostic evaluation of speech intelligibility, in Speech Intelligibility and Speaker Recognition, M. Hawley, Ed. , Dowden Hutchinson & Ross, Stroudsburg, PA, pp. 374-387.
8. Voiers, W. D. (1983) Evaluating processed speech using the Diagnostic Rhyme Test, Speech Technology. l(No. 3):30-39.
various components of intelligibility. Those findings are summarized in Figure 5.
Nasality was the least impaired by noise interference, followed in order of in-
creasing susceptibility to noise by voicing, compactness, and sibilation; graveness
and sustention (the feature that distinguishes between sustained and abrupt con-
sonants) were the features most vulnerable to noise interference. The detailed
effects of noise interference on various combinations of feature states, for
example, the present and absent states, and the voiced and unvoiced states of the
various features, are detailed in Appendix A.
Q
L 0 0
90 •
r2 - .94 Exp«ct ati ons DRT Soor. -
1—1 1
Spaakar Origin
RH 103.2
^ " JE 99.6
X -p •H
i—t
•H
0) •«-t
l—i
H 70- QJ
-P C
i—t
. Xfs • .• ^
(6<S/N<30> I'" 100-<M«3. 125) (origin) -158. 6/(S/N in do) ..
—1 1
3024 18 12 Speech/Noise
0 1 2 3 4 5 6M
7
8 9 10 11 12
Ratio (db)
Figure 4. Intelligibility Scores vs S/N Ratio, With Multiple Regression Lines Calculated for Individual Male Speakers

-0 •H
* 30- —
20- Z
10- -P c
0
50-
40- - Faoiur* Origin Slops
Nowllty 99.2 -IB. 6 Voicing 07.2 -53.6
CoapoeUM* 184.9 -169.8 Slbllotion 188.1 -218.4 Crovonaoo 96.8 -227.4 Sootontton 111.8 -272.5
• •>
12 3024 18 Speech/Noise Ratio (db)
Figure 5. Regression Lines vs S/N Ratio for the Individual Phonetic Features That Contribute to Intelligibility
5. COMPARISONS WITH THE ARTICULATION INDEX
The articulation index provides a means of predicting speech intelligibility of
different types of speech materials (nonsense syllables, phonetically balanced word
lists, sentences) in relation to the speech signal level and the interfering noise level 9
and their energy spectra, in combination with different listening conditions. Those
relationships have been summarized in an American National Standard that pro-
vided the basis for the summary shown in Figure 6. The curve labeled "Rhyme
Tests" in the figure is based on earlier versions of rhyme tests that, unlike the
Diagnostic Rhyme Test, did not provide an adjustment of intelligibility scores for
chance effects
9. Beranek, L. L. (1947) The design of speech communications systems IRE Proc. , 3_5(No. 9):880-890.
10. ANSI S3. 5-1969 (1969) American National Standard Methods for the Calculation of the Articulation Index, American National Standards Institute, N. Y.

100
QJ L O o
CO
90
80
>.70 -P •iH
,-H 60
CO 50
40 QJ
_P C 50
^—^
_C 20 o QJ 0J 10 Q_
CO 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 ARTICULATION INDEX
0.8 0.9
Figure 6. Intelligibility Contours lor Different Speech Materials Plotted vs the Articulation Index, With Contour for Diagnostic Rhyme Test Scores From These Studies. This figure derives from ANSI S3. 5-1969, American National Standard Methods for the Calculation of the Articulation Index. This version is non-standard, in that the Diagnostic Rhyme Test curve has been added. Also the ordinate scale which is usually labeled "Percent of syllables, words, or sentences understood correctly" is relabeled "Speech Intelligibility Score", as DRT scores are not "percent correct" but include a correction for a priori probabilities

This study made it possible to estimate values of the articulation index at each
of the S/N ratios of these tests and construct a new curve that has been added to
the figure, estimating the variation in Diagnostic Rhyme Test scores with values
of the articulation index over the range studied here.
The ordinate scale in Figure 6 has customarily been labeled "Percent of
syllables, words, or sentences understood correctly. " However, Diagnostic
Rhyme Test scores are corrected for a priori probabilities with the calculation
r-r,-, (Number of items right — Number of items wrong) v . IJ!\I score = w*—. I r r *. ^ I Total number of items
00
Accordingly, the ordinate scale in Figure 6 was re-labeled "Speech Intelligibility
Score." The dashed contour labeled "Diagnostic Rhyme Test" (three male speakers)
represents the relationship calculated in this study. If these DRT scores were
modified to remove the correction for chance and thus express "Percent correct"
a curve would be obtained that approximates the older curve labeled "Rhyme Tests"
for the range investigated here. However, the asymptote of the curve would not
approach 100 for "perfect conditions" (A.I. = 1.0) as there are typically about
2 percent listener errors for Diagnostic Rhyme Tests conducted with high fidelity
speech signals.
6. SPEECH PERFORMANCE WITH "OPERATIONAL MESSAGES"
The relationships between speech intelligibility and the articulation index
summarized in Figure 6 permit estimation of speech performance with stereotyped
voice messages well-known to listeners (typical "operational messages" that have
been advocated for use in speech test and evaluation), shown in Table 1.
Extrapolation of the curve for DRT scores vs the AI gives an estimate of an
articulation index of about 0. 30 for a DRT score of 70, the score that has been
postulated as representing a threshold score representing the boundary between
"unacceptable" and "very poor" intelligibility performance. While the ANSI
relationships shown in Figure 6 suggest that well-known stereotyped voice messages
might be received with better than 90 percent accuracy under such conditions, the
relationships also suggest that were any emergency to occur in which communi-
cators were required to depart from their usual stereotyped communications and
need to use unfamilar words and phrases, the intelligibility performance of that
channel would present serious difficulties. Figure 6 also tends to explain why
some speech tests using "operational messages" resulted in subjects producing
judgements that a voice processor had acceptable performance, even though that
processor had scored below 70 in formal Diagnostic Rhyme Tests.
10

Table 1. Estimate of Speech Performance With "Operational Messages" Based on the Articulation Index
S/N Ratio Avg. DRT Estimated Est. of Avcj. percent correct: Score A. I. Sentences known to Listeners
('Operational Messages')
30 db 96 .85
24 db 95 .76
18 db 93 .64
12 db 87 . 50
6 db 75 .34
(by extrapolation:)
(70) (.30)
99Z
99Z
98Z
97Z
94Z
(92X)
7. VOICE QUALITY AND ACCEPTABILITY TESTS
As the voice quality and acceptability tests were not replicated there were far
fewer listener scores than for intelligibility. Separate scores for signal quality
and for background quality are obtained with the Diagnostic Acceptability Measure
(DAM) test. A weighted combination of background and signal quality scores pro-
duces scores for overall quality, called the Composite Acceptability Estimate
(DAM/CAE). With additive background and linear processing it might be anticipated
that background quality scores would vary with the S/N ratio and signal quality
scores would remain relatively constant. This was not the case. While background
quality scores varied more widely, there was also significant variation in the
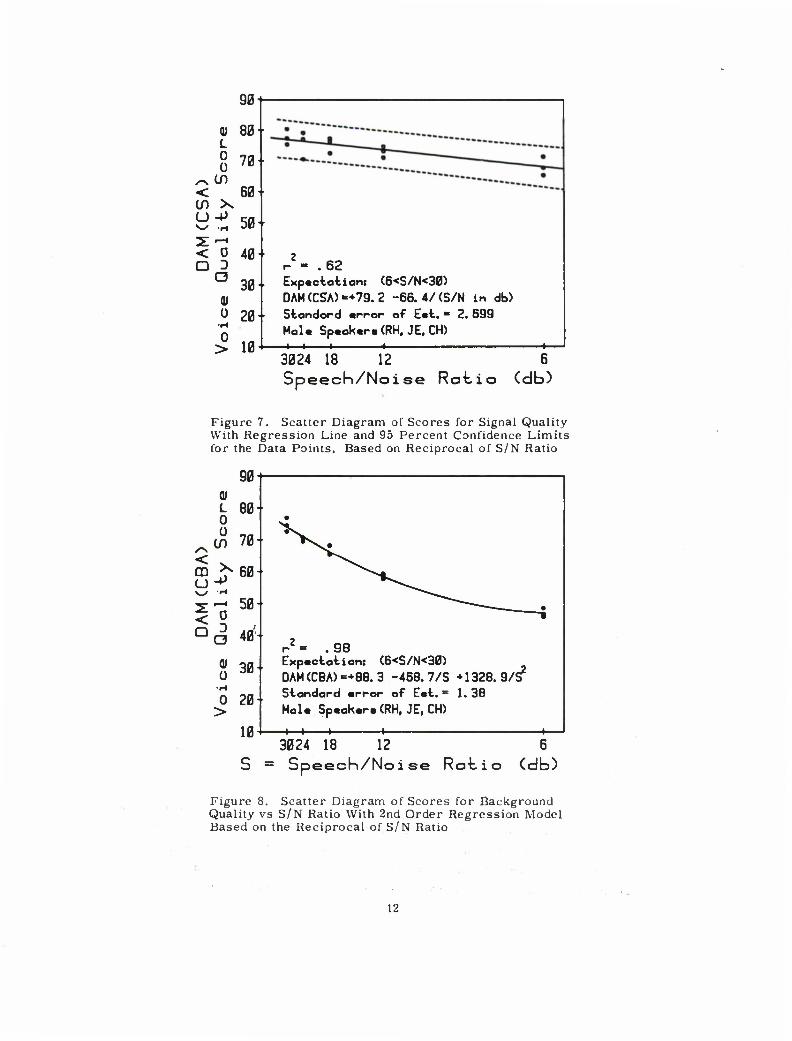
judgements of signal quality at the various background noise levels. Figure 7 shows
the scatter diagram of signal quality scores (DAM/CSA) in relation to S/N ratio
with the regression line and 95 percent confidence limits for the ensemble of
scores, modelled in relation to the reciprocal of S/N ratio.
Scores for background quality, representing the Composite Background Accept-
ability (DAM/CBA) are shown in relation to S/N ratio in Figure 8. A 2nd order
regression model based on the reciprocal of S/N ratio resulted in a value of 2
r = 0. 98 and a standard error of estimate of 1. 38, with a range of approximately
25 compared with a range of approximately 10 points for signal quality.
11
90
m 80
0 0
< tn x
< o a
70 •
60
50-
40
30 + II 0 20
> 10
r- - .62 Exp.ctation: (6<S/N<30) DAM (CSA) «+79. 2 -66.4/<S/N in db) Standard trror of E«t. • 2. 699 MoU Sp«ak.r« (RH, JE, CH>
3024 18 12 Speech/Noise Rat 10
6 (db)
Figure 7. Scatter Diagram of Scores for Signal Quality With Regression Line and 95 Percent Confidence Limits for the Data Points, Based on Reciprocal of S/N Ratio
90- 01 L 80- 0
CD ,x 60-
2:- 50- < S Qa 40'-
2 30' 0 20- >
10-
r' - .98 Expectation: <6<S/N<30) DAM(CBA)~*88.3 -468. 7/S +1328. 9/ST
S =
Standard tprop of Eot. • Hal* Sp.ak.ra (RH,JE, CH)
1.38
-+- -*- 3024 18 12 Speech/Noi se Rat l o (db)
Figure 8. Scatter Diagram of Scores for Background Quality vs S/N Ratio With 2nd Order Regression Model Based on the Reciprocal of S/N Ratio
12

Scores for overall quality are not the average of the signal and background
quality scores, but a function of the product of the two. A scatter diagram of those
scores representing the Composite Acceptability Estimate (DAM/CAE) is pre-
sented in Figure 9 with a 2nd order regression curve based on the reciprocal of 2
S/N ratio. This regression model resulted in a value of r =0. 96 and a standard
error of estimate of 1. 94.
90 <D L 80
< Xs 60
DQ40
W 30 0
0 20 >
10
Expectation: (6<S/N<30)
DAM(CAE)=+77.6 -474. 9/S +1510. 9/S Standard error of Est.= 1.94
Male Speakers(RH, JEfCH)
I I
s = 3024 18 12 Speech/Noise Rati io
6
(db)
Figure 9.', Scatter Diagram of Scores for Overall Quality vs S/N Ratio. With a 2nd Order Regression Model Based on the Reciprocal of S/N Ratio
The same caveat regarding extrapolation to estimate scores outside the
measured range of S/N ratios (6 dB to 30 dB) expressed for speech intelligibility
data applies here, and even more strongly in the case of the 2nd order regression
models. Again, however, the regression model serves a useful purpose in con-
junction with a scale of categories that has been established to assist in the inter-
pretation of DAM voice quality ratings. The category scale, shown in Figure 10,
utilizes the same eight labels for categories as used for intelligibility scores,
ranging from "excellent" to "unacceptable". The category scale refers to the
scores for overall voice quality (DAM/CAE): no separate category scales for signal and background quality have been attempted.
13

Categories of DAM Voice Quality Scores
DAM Score Descriptive Examples
Category
_ ,, o Hiqh Fidelity Speech Excellent a ' r
64 OORHS "(Zero ~BER~ Very Good
58 - --j- - -z~- - -R-
Good 53 o~CVSiM6 7Zer^~BERr
Moderate n... Q in Urrice noise
~o~LPC"-r0~wTth "error"
_ protection, 1Z BER
~o~LPC"-r0~«Tth "error" _R protection, 2Z BER
~~~ ~~ ~o~LPC"-r0~wTth"erT-^r~ __ ' protection, 5Z BER
" UN"ACC"EPT"ABLE' "°'LPC" f0'i; "Hal fc^ "
Figure 10. Category Scale for Diagnostic Acceptability Measure Voice Quality Scores With Examples of Voice Processor Categories
As with the category scale for intelligibility scores, these labels do not repre-
sent judgements of listeners but judgements of a committee of experts that has
been involved with extensive tests of voice processors and has had opportunities
to obtain informal judgements of voice processor quality from users and correlate
those opinions with results of formal DAM tests. This category scale should be
considered tentative and subject to revision as further knowledge is gained (as is
the case with the category scale for intelligibility scores).
Combining the category scale for voice quality scores with the data obtained
in these studies produce the result shown in Figure 11.
The 30 dB S/N ratio resulted in voice quality ratings clustered around the
boundary between the "excellent" and "very good" categories, a result that by
coincidence was similar to that obtained with speech intelligibility scores. The
24 dB S/N ratio resulted in voice quality ratings in the "very good" and "good"
categories, while the 18 dB S/N ratio resulted in scores bracketing the "good"
category. At 12 dB S/N ratio the voice quality scores clustered around the
boundary between "moderate" and "fair". The 6 dB S/N ratio produced scores in
the "poor" category.
14

01 L 0 0
^^
< ^
< §
<D 0
•l-t
0 >
90
80
70
60
50
40
30
20 +
10
S
••
excellent
^ty^ very good ;:vv^-
good moderate
fair ^*^~-^_
poor •
v«ry poor
unacceptable
1—1 1 1 1
3024 18 12 Speech/Noise Rat x o
6 (db)
Figure 11. Diagnostic Acceptability Measure Scores for Overall Quality vs S/N Ratio and Regression Model, in Relation to the Category Scale for Diagnostic Acceptability Measure Voice Quality Scores
8. MEAN OPINION SCORES
Mean opinion scores result from tests in which listeners make direct judge-
ments of telephony channels. There are differing versions of the test procedure.
In one version, subjects conduct conversations over the telephony channel under
test and then make their judgements of the channel. Other versions involve only
listening to speech samples and then rating the speech sample. In this instance
the ratings were obtained by the latter method, using a five-point scale represent-
ing "excellent", "good", "fair", "poor", and "bad", with results shown in
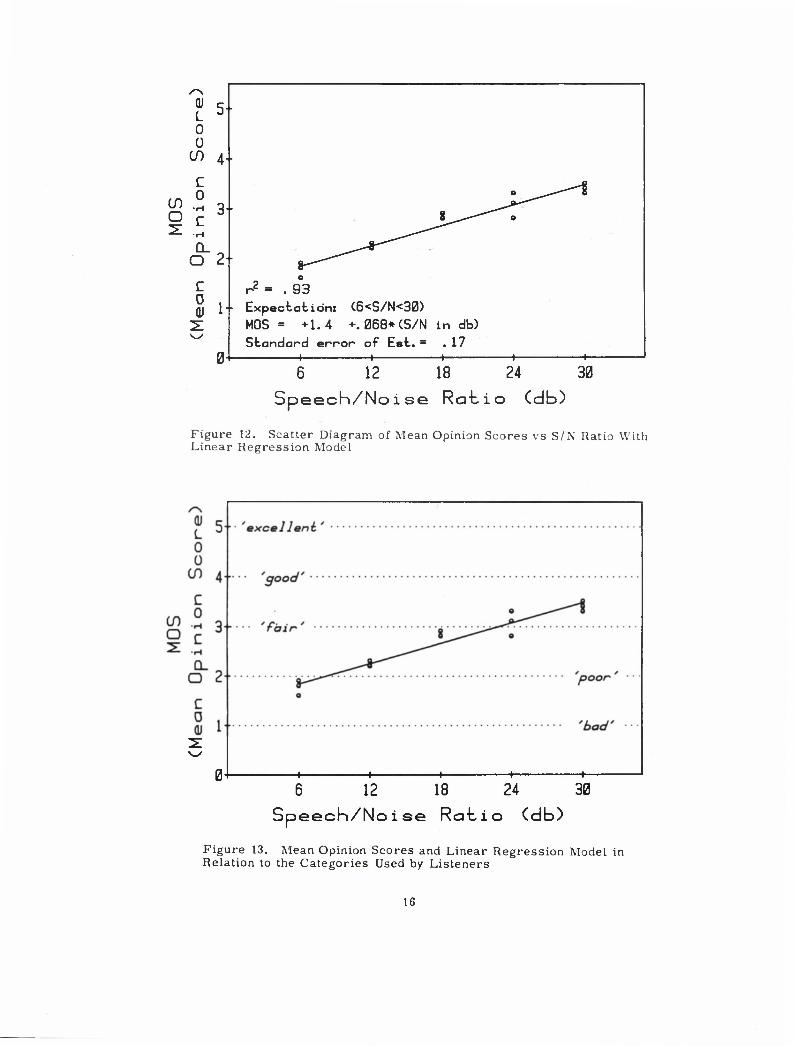
Figure 12 together with a regression model.
The speech samples on which listeners made their judgements were the same
sentence recordings used for the Diagnostic Acceptability Measure voice quality
tests. The regression model best fitting these points was based on the S/N ratios
rather than the reciprocals of those values, and resulted in a value of r =0. 93 and
a standard error of estimate of 0. 17. The ratings and the regression curve are
shown in relation to the category scale for the mean opinion scores in Figure 13.
15
L 0 0 10
5-
4-
a- 3 Or
C^2+
c 0 1-
r2 = .93
Expectation: (6<S/N<30)
MOS = +1.4 +. 068* (S/N in db)
Standard error of Est. = . 17 1 1 1 1 1
6 12 18 24 30
Speech/Noise Ratio (db)
Figure 12. Scatter Diagram of Mean Opinion Scores vs S/N Ratio With Linear Regression Model
12
>eec h/N oi se 18
Rat 24 30
10 (db)
Figure 13. Mean Opinion Scores and Linear Regression Model in Relation to the Categories Used by Listeners
16

9. COMPARISON OF CATEGORY SCALES
In Figure 14, the category scales for intelligibility and quality ratings are
compared, based on their common relationship to S/N ratio; the values calculated
for the articulation index at the five S/.\T ratios tested are also shown.
DRT Intelligibility
Score
DAM(CAE) Voice Quality
Score
exceJJent ex-ceJ'Jen 6 1
30- 0
-P °24-
very good
very good 1
QJ
218- 0
good |
Il2 good moderate
0 QJ
moderate fain
fair
Q.6- CO
• • poor '' very poor poor |
MOS AI Mean Opinion Estimate
Score
•- (. 85)
fair
poor
»- (. 76)
•- (. 64)
i-(.5)
L (. 34)
Figure 14'; Comparison of the Category Scales for the Intelli- gibility Scores, Voice Quality Scores, and Mean Opinion Scores in Relation to the Scale for S/N Ratio and the Estimates of Values of the Articulation Index
Diagnostic Rhyme Test intelligibility and Diagnostic Acceptability Measure
voice quality scales are in fair agreement at the top and bottom of the range but
show little agreement in the middle of the range. The mean opinion score ratings
gave fair agreement only at the bottom of this scale.
17

10. DISCUSSION
The discrepancies between the category scales for Diagnostic Rhyme Test
intelligibility scores. Diagnostic Acceptability Measurement voice quality scores,
and Mean Opinion Scores emphasize the different origins of these scales. While
the categories representing the numerical ratings in obtaining Mean Opinion Scores
represent direct judgements by listener crews, the other two category scales were
created by a committee with members long experienced in test and evaluation of
digital voice communications processors and the interpretation of Diagnostic Rhyme
Test Scores and Diagnostic Acceptability Measurement scores. Repeatedly faced
with the problem of interpreting to others the significance of scores obtained for
voice processors under different test conditions, it was decided to construct rating
scales based on descriptive labels, that might be used by anyone wishing to esti-
mate the significance of a particular Diagnostic Rhyme Test intelligibility score
or Diagnostic Acceptability Measurement voice quality rating. The category scales
for these scores were constructed by the committee after many discussions of this
issue and extensive reviews of performance data covering a wide variety of pro-
cessors and test conditions.
It is therefore not surprising, considering the ad hoc nature of the Diagnostic
Rhyme Test and Diagnostic Acceptability Measurement category scales, that the
categorizations do not agree well in their relationship to the effects of broad-band
noise on speech. These findings may provide the basis and incentive for further
studies of the discrepancies between the category scales and the issue of whether
the scales might or should be brought into closer agreement.
11. CONCLUSIONS
Tests of speech with additive broad-band noise resulted in the following findings;
• Estimates were made of the relationship between
Diagnostic Rhyme Test intelligibility scores, and
values of the articulation index.
• A comparison of category scales for Diagnostic Rhyme
Test intelligibility scores, Diagnostic Acceptability
Measurement voice quality ratings, and Mean Opinion
Scores was established. Values of the articulation
index in relation to those category scales were
established.
18

From the relation between Diagnostic Rhyme Test
scores and the articulation index it was possible to
make estimates of the percent correct of stereotyped
messages known to listeners, that is, "operational messages", in relation to Diagnostic Rhyme Test scores.
Test results highlighted the importance of conducting
speech test and evaluation with multiple speakers, and
of replicating tests whenever practicable.
The study confirmed the utility of the new algorithm
developed in the Rome Air Development Center speech
test and evaluation facility for measuring and calibrating
speech-to-noise energy ratios.
19

References
1. Sims, J. T. (1985) A speech-to-noise ratio measurement algorithm, J. Acoust. Soc. Am. , TJUNo. 5):167 1-1674.
2. Brady, P. T. (1968) Equivalent peak level: a threshold-independent speech- level measure, J. Acoust. Soc. Am., 44:695-699. __________________-________——— ***—_
3. Voiers, W.D. (1977) Diagnostic acceptability measure for speech communica- tions systems, IEEE Proc. ICASSP 77CHU97-3 ASSP, pp. 204-207.
4. CCITT (1981) Telephone Transmission Quality: Recommendations of the P Series, Yellow Book Vol. V, ITU, Geneva.
5. Smith, C. P. (1983) Narrowband (LPC-10) Vocoder Performance Under Combined Effects of Random Bit Errors and Jet Aircraft Cabin Noise, RADC-TR-83-293, ADA141333, Rome Air Development Center. Griffiss AFB, N. Y.
6. Smith, C. P. (198.3) Relating the performance of speech processor to the bit error rate, Speech Technology 2(No. l):41-53.
7. Voiers, W.D. (1977) Diagnostic evaluation of speech intelligibility, in Speech Intelligibility and Speaker Recognition, M. Hawley, Ed. , Dowden Hutchinson & Ross, Stroudsburg, PA, pp. 374-387.
8. Voiers, W.D. (1983) Evaluating processed speech using the Diagnostic Rhyme Test, Speech Technology, HNo. 3):30-39.
9. Beranek, L. L. (1947) The design of speech communications systems, IRE Proc. 3i5(No. 9):880-890.
10. ANSI S3. 5-1969 (1969) American National Standard Methods for the Calculation of the Articulation Index, American National Standards Institute, N. Y.
21

Appendix A Details of Variation in Diagnostic Rhyme Test Feature
Scores With Speech-to-Noise Energy Ratios
Figures Al through A 15 that follow, present the results of analyzing separately
the effects of broad-band noise on each of the intelligibility feature states.
Nasality was little affected by noise over the range tested here; this was true
not only for the overall scores for this feature, but also for the contrasts between
nasality-present and nasality-absent, and for the grave and acute states of this
intelligibility feature.
The remaining feature scores tended to show varying degrees of susceptibility
to noise interference. The voiced state of sibilation was degraded by noise to a
greater degree than the unvoiced state; however the opposite was true for the
features graveness and compactness.
The present state of sibilition and graveness were more susceptible to noise
than the absent state; however the opposite was true of the features voicing and
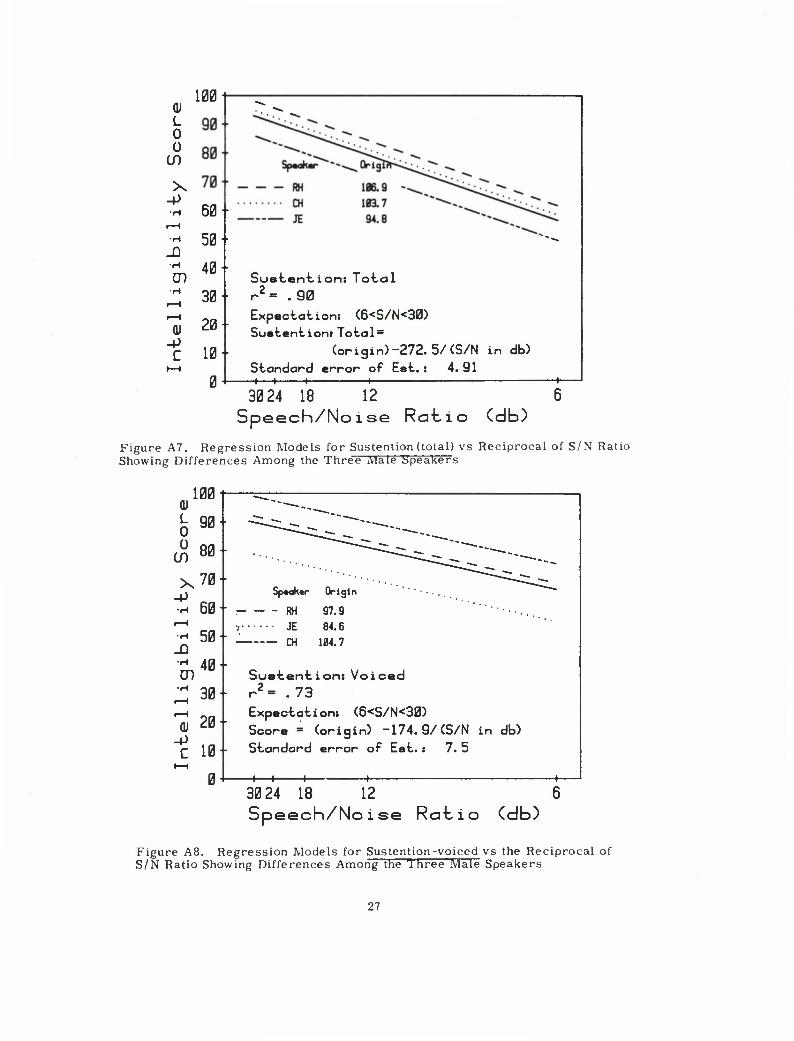
compactness. The feature scores that exhibited significant differences among
speakers included voicing (frictional) and voicing (total); sustention (voiced),
sustention (unvoiced) and sustention (total).
23

100
JJ80 + X70 +
"£ 60-
en
50-
40-
30-
« 20{
0
Voicing F«tur. Qrigln Slop* r2
• Pr~«it. 99.4 -S1.7 .14 AbW. 95.1 -55.8 .21
Voioinq: Total r • . c4 Expectation: (6<S/N<30) Scor. - 97.24 -53.6/CS/N in db>
Standard trror of E«t.t 4. 67
t t —»— 12 3024 18
Speech/Noise Rat 10 (db) Figure Al. Regression Models for the Scores for Voicing-present, Voicing-absent, and Voicing (total) vs the Reciprocal of S/ N Ratio
1001 01 L 93
x7B-
~ 60- l—t
Voicing Faotur* Origin
T Frlot. 83.9 Slap. -M.7 .88
•* 50-
U1
Hon-frlst. IK. 6
Voicing: Total
-56.6 .41
- 30
^ 20^
rZ- .24
Exp.ct ati oni (6 <S/N <30)
Soor« - 97.24 -53 .6/CS/N in db)
i 10 Standard irror of E.t.t 4.67
I 1 1 1 r— 3024 18 12 Speech/Noi se Ratio (db)
Figure A2. Regression Models for Voicing-frictional, Voicing-non-frictional, and Voicing (total) vs the Reciprocal of S/N Ratio
24

1001 0) L 90-
X70-
^ 60-
^ 50- •H 40.. (7) - 30-
H 20
0
Spaokar
- - RH
JE
— CH
Origin
98.9 84.8 97.9
Voicing: Frictional
r2- .63
Exp.ctation: (6<S/N<30)
Scor. - (origin) -50. 7/(S/N in db)
Standard «rror of Eat.t 5. 6
H r- 3024 18 12 Speech/Noise Ratio (db)
Figure A3. Regression Models for Voicing-frictional vs the Reciprocal of S/N Ratio, Indicating the Differences Among the Three Male Speakers
QJ L 0 0
CO
X
•H
(D
QJ -P
C
100
90
80
70
60
50
40
30
20
10
0
Spaakcr Origin
CH 98.3 RH 180.7 • JE 92.8
Voicing: To tal r2 = .64 Expectation: (6<S/N <30) Voicing: T otal =
.. (origin) -53. 6/ (S/N in db) Standard 1—1 1—
error of E 1
st. : 3.31 1
30 24 18 12 Speech/Noise Ratio (db)
Figure A4. Regression Models for Voicing (total) vs the Reciprocal for S/N Ratio, Indicating Differences Among the Three Male Speakers
25

lUUl at L 98
~ 68 Nasality
Faaiurt Origin Slop*
Pr^«nt 98.9 -13.7 r-2
.85 •H 50- _Q '^40-
- 30-
U 20-
Ab.«nt 99.5 -23.4
Natality: Total r2- . 18 Expectation: (6<S/N<30)
.19
Scort - 99.2 -18. B/CS/N in db)
H 11J Standard trror of E»t.t 1.9
1—( 1 1 ,
3024 18 12 Speech/Noise Rat l o (db)
Figure A5. Regression Models for Nasality Scores vs S/N Ratio, Indicating Virtually No Differences Between the Total Score, and the Present and Absent State
100
JJ80 + X70 +
~Z 60 \
ID
Hi -P C
50-
40-
30-
20
10-
0
Nasallty F«atur« Origin
-7 Crov« 99.6 Acut« 96.8
Na»ality: Total r2- .18
Slop. -27.9
-9.3
r2 .17 .05
Expectation* (6<S/N<30) Soar. - 99.2 -18. 6/(S/N in db) Standard trror of E"t. t 1.9
I t
3024 18 12 Speech/Noise Ratio (db)
Figure A6. Regression Models for Nasality Scores vs S/N Ratio, Indicating Only Slight Differences Between Total Scores and the Grave and Acute States
26
QJ L 0 0 CO
X -p
•l-t
•H 00
QJ -P c
100
60'
50-
40-
30-
20 •
10-
0
Sustention: Total r2 = .90
Expectation: (6<S/N<30) Sustention: Total =
(origin)-272. 5/(S/N in db) Standard error of Est.: 4. 91 i t i 1
3024 18 12 6 Speech/Noise Ratio (db)
Figure A7. Regression Models for Sustention (total) vs Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers
1MD- ^^ QJ "**—•^
k 90' -CL^r — *—— „ o ^*——»»»^— ^^ """•"•^•^
CO 80' ^^^TT; ., x70- ^""^••"••-^c-
-»> • Spaokv Origin
•H 60 ' : RH 97.9 •—< v JE 84.6 •H 50 CH 1B4.7
•H 40. U) Sustention: Voiced
Z 30] r2= .73
^ 20- Expectation: (6<S/N<30)
Score = (origin) -174.9/(S/N in db) Standard error of Est.: 7.5 "c 10
i—• 1—i I 1 I
30 24 18 12 6 Speech/Noise Ratio (db)
Figure A8. Regression Models for Sustention-voiced vs the Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers
27

100 01
X70j -P •H 60 •
^ 50- _Q '^40i CD - 38 f
H 20
In
Spaokar Origin
RH 115.9
JE 105.0
CH 102.7
Sustention: Unvoiced r2 - .87 Expectation: (6<S/N<30) Score = (origin) -370. 1/(S/N in db) Standard error of Eet.: 7.8
I I 30 24 18 12 6 Speech/Noise Ratio (db)
Figure 'A9. Regression Models for Sustention-unvoiced vs Reciprocal of S/N Ratio Showing Differences Among the Three Male Speakers
28

W
ai
c
40-
30-
20-
10-
0
— — — Pr«Mnt 50+ Abaant
Sibilation F»aiur« Origin Slop*
112.1 -316.5 103.2 -103.3
.77
.65
Sibi1 at ions Total
r2« .81
Exp.ctation: (6<S/N<30)
Scor. -108.1 -218.4/CS/N in db) Standard «rror of E«t. i 5. 3
-l—i i i 3024 18 12 6 Speech/Noise Ratio (db)
Figure A 10. Regression Models for Sibilation vs the Reciprocal of S/N Ratio, Showing the Differences Between the Present and Absent State of Sibilation
d)
X70-
*^ *^^ '••••.
Sibilation •^ ^ •H 60-
i—i F«aUra Origin Slop* r2
Voicd 109.7 -275.4 .79 •H 50- ' •', Unvoted 106.4 -161.5 .68
ID Sibil ationi Total
2 30- I 20
r2- .81
Exp-ctationj (6<S/N<30)
Soar* - 108.1 -218. 4/(S/N in db)
"S 10- Standard trror of E«t. t 5. 3 r—1
I 1 1 1 1
3024 18 12 Speech/No is< Ratio (db)
Figure All. Regression Models for Sibilation vs the Reciprocal of S/N Ratio, Showing the Differences Between the Voiced and Unvoiced State of Sibilation
29
(D k 90- 0 ^•^^***"^«-»
c8«- "*" ""-^^""^"^-^ '
X70- -P Graveness *" —• ^"*"—.^^ •H 60 F«atur« Origin Slops r^ "" -~
i—« Pr»wnt 94.2 -241.8 .72 ••>•.
•H 50- AbMni 102.3 -216.0 .73 _Q •H 40. 0) - 30- r2- .84
H 20 Exp.otation: (6<S/N<30) Soor. - 98.0 -227.4/CS/N in db)
"c 10' Standard trror of E»t.t 4. 9 i—i
a- 1—i I i i 3024 18 12 Speech/Noii Rat 10 (db)
Figure 12. Regression Models for Graveness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Present and Absent State of the Graveness Feature
100 OJ
0 (/) 80-
x70^
"^ 60-
~ 50- _Q
CD
« 30 -
H 20-
"c 10 H
0
Graveness Fxatur* Origin Slop*
— - Volc«d
• • • • Unvoic«d
104.4 -154.5 91.6 -300.6
r .83 .71
Gra 2_
n«»»: Total r~- .84 Expectations (6<S/N<30) Scor. = 98.0 -227.4/CS/N in db) Standard error of E»t. : 4. 9
-i—I 1 I
30 24 18 12 Speech/Noise Rat 10 (db)
Figure A 13. Regression Models for Graveness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Voiced and Unvoiced State of the Graveness Feature
3 0

"£ 60-
^ 50- •H 40..
U) 2 30- u 20-
0
Compactness Foaiuro Origin Slops r
Prooont 103.8 -116.6 .67
Ab.«ni 105.9 -223.0 .76
-ompactrn 2, r
jtn«««t Total
.84 Exportation: (6<S/N<30) Scor. - 104.9 -169. 8/(S/N in db> Standard error of E»t. i 3. 6
3024 18 12 Speech/Noise Ratio (db)
Figure 14. Regression Models for Compactness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Present and Absent State of the Compactness Feature
X70^
~Z 60-
* 50-
'^40i 2 30 •""* rut v 20-
0
Compactness Fooiuro Origin Slop* r2
- Voiood 102.2 -72.9 .54
Unvoiood 107.6 -266.7 .77
Compaotnooo: Total
r2- .84 Expectation (6<S/N<30) Scon. • 104.9 -169. 8/ (S/N in db) Standard error of Eet. i 3. 6
I I
3024 Spe
18 12 jch/Noise Rat 10 (db)
Figure A 15. Regression Models for Compactness vs the Reciprocal of S/N Ratio, Showing the Differences Between the Voiced and Unvoiced State of the Compactness Feature
31