collaborative personal profiling for web service ranking and recommendation
TRANSCRIPT

Inf Syst FrontDOI 10.1007/s10796-014-9495-4
Collaborative personal profiling for web service rankingand recommendation
Wenge Rong · Baolin Peng · Yuanxin Ouyang ·Kecheng Liu · Zhang Xiong
© Springer Science+Business Media New York 2014
Abstract Web service is one of the most fundamentaltechnologies in implementing service oriented architecture(SOA) based applications. One essential challenge relatedto web service is to find suitable candidates with regard toweb service consumer’s requests, which is normally calledweb service discovery. During a web service discovery pro-tocol, it is expected that the consumer will find it hard todistinguish which ones are more suitable in the retrievalset, thereby making selection of web services a criticaltask. In this paper, inspired by the idea that the servicecomposition pattern is significant hint for service selec-tion, a personal profiling mechanism is proposed to improveranking and recommendation performance. Since serviceselection is highly dependent on the composition process,personal knowledge is accumulated from previous servicecomposition process and shared via collaborative filteringwhere a set of users with similar interest will be firstly
W. Rong · Y. Ouyang () · Z. XiongState Key Laboratory of Software Development Environment,Beihang University, Beijing 100191, Chinae-mail: [email protected]
W. Rong · B. Peng · Y. Ouyang · Z. XiongSchool of Computer Science and Engineering, Beihang University,Beijing 100191, China
W. Rong · B. Peng · Y. Ouyang · Z. XiongResearch Institute of Beihang University in Shenzhen, Shenzhen518057, China
K. LiuInformatics Research Centre, University of Reading, Reading RG66UD, UK
K. LiuSchool of Information Management and Engineering, ShanghaiUniversity of Finance and Economics, Shanghai 200433, China
identified. Afterwards a web service re-ranking mechanismis employed for personalised recommendation. Experimen-tal studies are conduced and analysed to demonstrate thepromising potential of this research.
Keywords Web service · Discovery · Personalisation ·Ranking · User group · Association rule
1 Introduction
The substantive deployment of service oriented architecture(SOA) based applications has led to the explosively increas-ing number of web services registered in public repositories.It is also envisaged that the number will keep growing inthe future. In such circumstances, the necessity of develop-ing dynamic web service locating mechanism is becomingindispensable. In other words, when consumers are lookingfor web services to support their applications, how to effec-tively return them a set of suitable web services with regardto the requirements has turned into a fundamental challenge,which is normally called web service discovery.
Web service discovery is a well known research topic anda number of other challenges are indirectly dependent on itsperformance (Gu and Lago 2009). Within a web service dis-covery process, there are two major tasks, i.e. matchmakingand selection. The web service matchmaking mainly laysemphasis on the comparison between service request andservice description files, while the selection mainly focuseson proper ranking and recommendation of the retrieved webservices. Though the scopes of matchmaking and selec-tion parts are not strictly isolated but overlapped, they dostudy web service discovery from different angles. Sreenathand Singh argue that it is reasonable to make a distinctionbetween these two parts and further indicate that the most

Inf Syst Front
difficult issue in web service discovery is probably not thematchmaking but the selection of a good service for certainconsumers (Sreenath and Singh 2004).
Currently, a lot of efforts have been attained in solvingweb service discovery problem among which semanticbased approaches have now become one of the most impor-tant solutions and several standards have been accordinglyproposed, e.g. DAML-S (Burstein et al. 2002), OWL-S(Martin et al. 2004), WSDL-S (Akkiraju et al. 2005),WSML (de Bruijn et al. 2006), and etc. The semanticoriented solution employs different level of semanticsimilarity to indicate whether the service candidates canmeet the consumer’s request. For example, a discoverymethodology based on DAML-S uses similarity degreeswhich consist of exact, plug in, subsumes and fail to findout the matched web services (Burstein et al. 2002). AnOWL-S based discovery model classifies similarity degreesinto exact, plug in, subsumes, subsumes-by, logic-basedfail, Nearest-neighbour and fail (Klusch et al. 2006).
Despite all of these advances, semantic oriented solu-tions also have certain possible limitations. For example,understanding of ontology or other related knowledge isimportant when consumers use this kind of approach sincethe submitted request must be in similar format based oncertain ontology, which places a burden on the consumer.Some semantic standards for web service discovery is revo-lutionary and do not build on current standard, which couldbe less attractive for industry and prevent wider commercialemployment.
Furthermore, the semantic similarity is effective inmatchmaking for quickly filtering web services in the repos-itory. It however may not be enough for highly efficientweb service ranking and recommendation though it can beemployed as the preliminary selection criteria in deed forcoarse ranking. Considering the increasing number of webservices available in the future, the matchmaking processwill likely find a large set of web service candidates withsame semantic similarity. The consumers will probably stillfind it hard to distinguish which services are more suit-able in the set of retrieved candidates as heterogeneitiesmay occur between these semantically equivalent web ser-vice candidates (Pires et al. 2002). This difficulty has beenindicated as a fundamental research question called seman-tically equivalent web service selection (Verheecke et al.2004; Tamani and Evripidou 2007).
In order to support more efficient ranking and recom-mendation with regard to the consumer’s requirement, moreconsideration is needed to be embedded into the selectionprocess. This kind of supplementary sources can be a varietyof known and unknown knowledge dispersed through theenvironment where the requesting web service will operate(Barros et al. 2005), because the services will always havecertain linked relationship to some extent (Chen and Paik
2013). One widespread type of the important contextualinformation during selection process exists as consumer’susage behaviour, which is based on the finding that theconsumer’s data consumption pattern can be employed forpredicting the consumer’s next behaviour (Kokash et al.2007).
A possible representation of such usage behaviour isthe dependencies among web services (Verma et al. 2004),which can be extracted from web service composition trans-actions as patterns are ubiquitous in composition processes(Tang and Zou 2010). Currently it is a frequently occurredsituation in real businesses when a consumer tries to lookfor functionalities in the public repository but no single webservice can meet the requirement. This has led to the neces-sity of coordinating existing services together to satisfy theconsumer’s needs. Therefore, in a typical web service dis-covery process, the requested service is most likely going tobe combined with other services through a certain composi-tion process. From this point of view, web service selectioncan be discussed in terms of composition process becauseit is highly dependent on the intended service aggregation(Schoop et al. 2006). As such it makes intuitive sense to con-ceive a personal profiling model based on the dependenciesobtained from service composition history to represent theconsumer’s service usage pattern.
Though experience based personal profiling is theoret-ically promising, the limitation of this approach is alsonotable. Due to the dramatically increasing number of webservices advertised in the repository, a typical consumer willonly have limited experience on a very small portion of thewhole service set. As such, it is envisioned that relying onpast experience of consumer himself might not work well ifthe requested services are never invoked by the consumer.To overcome this limitation, group knowledge is consideredas an important complement for personal profiling in webservice selection. The group collaboration is underpinnedby the hypothesis that service consumers with similar back-ground normally have similar preference on retrieved webservices (Rocco et al. 2005).
An important approach for group knowledge sharing issocial collaborative filtering (CF), which makes recommen-dation by learning other consumers’ previous experienceon the set of candidates (Manikrao and Prabhakar 2005;Shao et al. 2007; Kerrigan 2006; Zheng et al. 2009; Chenet al. 2010). CF has been widely used and proven successfulin recommender system, where it firstly asks users to rateitems in a product database. Afterwards when a user beginslooking for an item which that user does not use before, CFwill recommend it based on how other users rate on that itemand other items in similar situation. Theoretically a pureCF based recommender system is independent of particulardomain and is then adaptive to all cases (Adomavicius andTuzhilin 2005).

Inf Syst Front
Though CF is a commonly used technique in recommen-dation, it also has its own limitations. One of the premisesin a pure CF based approach is the need of all consumers’ratings on each item before it can start to recommend items.Currently most CF based applications ask the users to pro-vide ratings explicitly after use of the items. Though thisexplicit way of accumulating ratings is easy to be imple-mented, it is not user friendly. Moreover, it is inevitable thatnot all users wish to give their feedbacks after their usageof products (Claypool et al. 2001). To overcome this kind ofinformation distortion, the importance of implicit feedbackmeasures has been stressed for recommender systems (Oardand Kim 1998). In this research an implicit feedback reali-sation is proposed and the invocation rate of a web servicein different web service composition processes is recordedas a possible indicator of the preference of that web serviceto a certain consumer.
The contribution of this paper is twofold. Firstly, aninvestigation has been carried out on contextual modellingfrom web service composition perspective where serviceranking and recommendation is implemented via recogni-tion of dependency in the composition process. Secondly,this work employed the CF based group knowledge sharingmechanism to constitute collaborative personal profile forthe improvement of selection performance, where implicitinvocation rate from service composition history is gatheredoff-line and transparent to consumers.
The rest of this paper is organized as follows. Section 2introduces the motivation and premise of this research. InSection 3, the personal profiling process is demonstratedand illustrated in detail. Experimental studies are presentedand discussed in Section 4. Section 5 will briefly introducerelated works as to web service selection in the literatureand Section 6 gives conclusion and discusses future work.
2 Motivation and premise
2.1 Service dependency
In web applications, functionalities requested by consumersoften cannot be satisfied by simply invoking a web ser-vice in the repository. As such the needs of aggregatingmore than one web service in order to meet the consumer’srequirement has become an important challenge. With theincreasing number of applications with complex businesslogic, it is anticipated that more and more business function-alities will rely on service composition to survive the fiercemarket competition. Service composition is essential for abusiness to keep competitive advantages. However, it is noteasy to obtain an ideally satisfactory service composition asthere are always various partially interleaved factors whichwill influence the final plan generation.
Currently, a large number of web service compositionsolutions have been proposed to support flexible businessprocess. For example, Rao and Su (2004) roughly clas-sified the service composition approaches into two majorcategories, i.e. workflow oriented approach and artificialintelligence planning oriented approach. The first type ofapproach mainly studies the composition process from theflow control’s perspective, whilst the second type laysemphasis on the inference of service selection via dynam-ically gathered information. Currently, a large number ofcomposition solutions have been proposed to support flexi-ble business process. Though these approaches use differenttheories, methods, tools and frameworks to enable adaptivecomposition, the intertwined relationship among web ser-vices in a composition process has been attached greaterimportance by all of them for properly selecting web ser-vices at runtime.
Considering that it is quite common situation that a webservice is requested for joining a web service compositionprocess to support complicated business functionalities, itis expected that the composition process is a subtle forcethat can provide some hints for web service discovery. Sincethe relationship among web services is one of the importantfactors to be investigated in a service composition process,it is natural to ask whether the selection of web services canbenefit from utilising this kind of information, which in factis the major inspiration of implementing a personal profilebased web service ranking and recommendation.
As indicated by Verma et al. (2004), one kind of rela-tionship is presented in forms of the interactive dependency,which means selection of a certain web service will havea visible effect on the way of selecting others and theninfluence the global performance of the whole compositionprocess. As such it is crucial to accommodate this kind ofinter-service dependency. Different works have reported theimportance of realising the service dependency for SOAbased systems from diverse perspective. For example, theinterrelation has been widely studied in QoS aware webservice composition applications where selection of differ-ent web service candidates must be carefully coordinatedwith each other to achieve optimisation with regards to theoverall QoS constraints (Feng et al. 2013). Cervantes andHall (2003) propose a mechanism to automate web servicedependency management in SOA model. Similarly, servicepattern is also comprehensively analysed and accordinglya mechanism is proposed by Liang et al. (2006) to capturethe patterns, which can represent the dependency to someextent. Basu et al. (2007) develop a tool to disclose theweb service dependency. From their work, it is not trivial tostate that the dependency can facilitate the service selectionas web service discovery is highly dependent on the com-position environment. That means whenever a consumerrequests a web service, it will be reasonable and helpful to

Inf Syst Front
study the corresponding web service composition processesinto which retrieved candidates will be joining for stronglyindicative hints.
A web composition process can be modelled by usingthe concept of abstract service and real service (Fang et al.2004). An abstract web service is a virtual service tem-plate stating the logic and business requirement and will bereplaced by a real web service when the service composi-tion process executed. Thus, web service composition canbe seen as a process to search for a new service S, whichconsists of a set of abstract web services, expressed as S =S1, S2, S3, . . . , Sn. Each abstract web service is linked toa set of real web services Si = si1, si2, si3, . . . , sim, whichare usually called functionality equivalent candidates sinceall of them can meet the request. Figure 1 is an exam-ple of the relationship between these two elements, whereS1, S2, . . . , S7 are abstract web services and s21, s22, s51 ands52 are real web services which can be invoked at run time(Rong et al. 2008).
For example in Fig. 1, given that there are two differentuser u1 and u2 requesting the same web service composi-tion, it might be possible that u1 prefers s21 and s51 whileu2 always selects s22 and s52. In this case it can be saidthat there are certain dependencies or patterns among webservice s21, s22, s51 and s52. Therefore, if the web serviceselection is studied from the composition perspective, thedependency deserves to be investigated in depth. Once theimportance of service dependency is realised, the next chal-lenge becomes to find a proper method to abstract anddefine the dependency. In this research, association rule isemployed to represent this kind of relationship.
2.2 Association rule
The idea of association rule mining is initially derivedfrom the requirement of supermarket management. Associ-ation rule is capable of disclosing the implicit relationshipsbetween set of basket items underneath the large collec-tion of basket transaction data. The most classic exampleof association rule is the relation between diaper and beer,
S1 S2 S3
S4
S6
S5
S7
s51 s52
s21 s22
Fig. 1 Web service composition example
which states that a few of purchase transactions that pur-chase diaper also purchase beer. Currently, association ruleis becoming one of the typical data mining techniques andwidely used in various domains. For example, in infor-mation retrieval applications, association rule is used todeal with document clustering (Moore et al. 1997), queryexpansion (Fonseca et al. 2005) and etc. Association min-ing technique also has been widely used in social networkanalysis to identify user relationship (Yang et al. 2006).
Formally, let T = t1, t2, . . . , tn be a set of transactionsinvolving a set of items of I = i1, i2, . . . , im, the rulebetween item sets X and Y is formed as X → Y , whereX, Y ⊆ I and X ∩ Y = φ, X is called the antecedent of therule and Y is called the consequent. A rule is called as anassociation rule when it satisfies some minimum specifiedspecifications. Several different measures have been pro-posed in the literature, such as conviction (Brin et al. 1997),collective strength (Aggarwal and Yu 1998), all-confidence(Omiecinski 2003), confidence (Agrawal et al. 1993) andetc., In this research, the mostly commonly used two con-straints, i.e. support constraint and confidence constraint(Agrawal et al. 1993), are employed to analyse the depen-dency information within the web service composition pro-cess. Particularly, support and confidence constraints aredefined as below:
1. Support. Support constraint represents the number oftransactions in T which support a rule. Given the ruleformed as X → Y , its support constraint is defined as
support (X → Y) = N(X, Y )
N(1)
where N(X, Y ) is the number of transactions that con-tain all the items of X and Y and N is the size of thewhole transaction set. The support value for a rule isto indicate the significance of the rule. Therefore, thesupport of an association rule should be more than apredefined threshold.
2. Confidence. Given a rule of X → Y , confidenceconstraint is to check the transactions in T that con-tain X also contain Y . Commonly, an association ruleshould be satisfied with a confidence score. Formally,the confidence of the rule X → Y is defined as
conf idence(X → Y) = support (X → Y)
support (X)(2)
2.3 Collaborative filtering based recommendation
In the previous section, the mechanism of employingservices usage behaviour history in term of dependencyfor predicting service future selection is discussed. Thereis however one possible problem with this approach.

Inf Syst Front
Facing the huge number of available web services, a con-sumer normally has invoked only a very small portion ofthem. Accordingly the personal experience is always lim-ited, which therefore raises an interesting question: if theretrieved web service candidates are never involved into theconsumer’s business logic before, how to discern which oneis more suitable for this consumer in this case? Apparently itis not enough to constitute the personal profile by relying ona consumer’s own behaviour history as there are more usagepatterns which deserve to be analysed along with other con-sumers. In this research, group knowledge is considered asan important complement for personal profile based webservice selection.
Collaborative filtering is one of the most important socialcollaborative methods and served as the major inspirationfor the proposed approach in this study. In fact, CF has beenwidely used in recommender systems since it was firstlyproposed by Rich (1979). The fundamental idea of thismethod is to utilize other similar users’ options on relateditems as references to predict and recommend potentialfavourite items for a certain user.
Formally, let U = u1, u2, u3, . . . , um be a set of usersand I = i1, i2, i3, . . . , in be the set of product items, theuser-item rating database R can be built up and depicted asTable 1. Each user rates scores on a part of all items basedon individual experience. Normally the rating score in a CFbased recommender system is normalised to a fixed range,which is from 1–5 in Table 1, where φ indicates that theuser does not rate the corresponding item. For the examplein Table 1, the goal of CF based recommender system is torealise how much the user u2 likes the item i2.
Generally, CF based system can be divided into twogroups, i.e. memory-based approach and model-basedapproach (Breese et al. 1998). The memory-based approachpredicts a certain user’s preference on un-rated items basedon the ratings by other users. Normally the recommendationprocess starts from finding a set of users, called neighbours,who have similar ratings on the items with the given user.Afterwards, a rating preference combination algorithm willbe applied to surmise the favourite degree of that user to thetarget item. In contrast to memory-based approach, model-based approach does not use the user-item ratings directly.It alternatively collects all user-item ratings and generates a
Table 1 User-item rating matrix
u1 u2 . . . um
i1 3 1 . . . φ
i2 2 ? . . . 1
. . . . . . . . . . . . . . .
in 5 φ . . . 4
prediction model by using probabilistic approach e.g. Clus-ter, Bayesian network and etc. Once the model is built up,the rating prediction and recommendation on certain itemscould be made.
2.4 Problem formulation
After analysing the feasibility of utilising service depen-dency from past usage history as the implication for rec-ommending web services, in this research the web serviceselection task is then studied as a problem of employ-ing this kind of interactive relationship to reshuffle theinitially retrieved services candidates by implementing are-ranking mechanism and changing the order of all candi-dates. Re-ranking based approaches for item recommenda-tion have been widely used and proven successful for resultre-configuration (Skoutas et al. 2010; Teevan et al. 2005).
In the re-ranking model, matching process is responsiblefor quickly filtering a candidate list. Afterwards, the contex-tual information is employed to review the candidate set andselect a proper list. Since this kind of information will not beused in the matchmaking process, there is probably a limi-tation as the matchmaking process has no chance to polishits performance. However, this architecture makes it conve-nient in system update. The discovery matching model canbe modified or replaced whenever necessary without affect-ing the context awareness part, whilst the context basedselection part can also be ameliorated without disturbingthe matchmaking process. As such this architecture makesit convenient in updating web service discovery system asthe service re-ranking part can be easily modified, replacedor removed whenever necessary without affecting the webservice matchmaking process.
Assume a consumer has a web service request r and theexpected service will join with a set of other web services ina composition process for a business target, then the servicere-ranking task can be expressed as the following procedure
C′ = f (C, Context, P rof ile) (3)
where
1. C = c1, c2, . . . , cn is the set of service candidatesretrieved by matchmaking model for request r .
2. Context is the running context of request r consist-ing of the set of real web services which have beenidentified and selected by the consumer for the servicecomposition process.
3. Prof ile is the consumer’s personal profile obtainedfrom past web service usage experience.
4. C′ is the re-ranked set of C in condition of Context andProf ile.

Inf Syst Front
The re-ranked web service candidatesC′ can be thereforedenoted as
C′ = c′1, c′2, . . . , c′n (4)
Within C′ each candidate c′i satisfies
P(c′i |Context, P rof ile) > P (c′i+1|Context, P rof ile)
(5)
where P(c′|Context, P rof ile) is the probability of can-didate c′ will be selected by the consumer in condition ofContext and Prof ile.
Since the running context contains the set of alreadyselected web services, it is comparatively easy to be identi-fied. The consumer’s personal profile is accumulated fromusage history and in this research it is considered as indica-tive information towards the consumer’s preference. Assuch it is of much importance for implementing person-alised service selection and its building procedure will beelaborated in the following section.
3 Personal profiling
3.1 Individual based personal profiling
As discussed in previous sections, since consumers have dif-ferent viewpoints on the service composition process, thesubmitted requests will vary depending upon their individ-ual understanding and experience. Association rule providesa powerful means to study the correlation among differentweb services. It partially discloses a consumer’s preferenceon web services in different situation. As such it can be usedto describe consumers and surmise their interests in serviceselection.
In this research, a personal profile is built for each con-sumer, in which a set of association rules are identified andstored to help understand the original requirement. The per-sonal profile constitution process consists of the followingsteps, as shown in Fig. 2:
1. To build personal service composition database. Firstly,for each consumer, a personal web service compositiondatabase needs to be set up. In this database, all web ser-vice composition transactions during last pre-defined
PersonalComposition
PersonalProfile
2 1
Fig. 2 Personal profile generator
time interval I are recorded for individual to build theusage history record R , which is expressed as:
R = T1, T2, T3, . . . , Tn (6)
where Ti is a web service composition transactionoccurred within I and described as:
Ti = S1, S2, S3, . . . , Sm, Si ∈ S (7)
where S is the whole set of web services registeredin the repository.
2. To generate personal profile. After the personal usagedatabase is built up, it can be exploited to create thepersonal association rule set, or personal profile.
PR = Si → Sj (8)
where support (Si → Sj ) > γ and conf idence(Si →Sj ) > ξ . Support and confidence here corresponds tothe constraints defined in previous section, respectively.
3.2 Group based personal profiling
As discussed in previous sections, individual based personalprofiling has one possible problem as one user’s personalusage experience can only cover small part of the wholeservices available online. Therefore there is a need to con-stitute personal profile by considering other similar usersperformance. In this research, a group based personal profil-ing method has been proposed to revise the individual basedpersonal profile by using collaborative filtering, a widelyused technique in group knowledge sharing. Though CF hasshown promising potential in improving system adaptivityand performance, traditional CF based web service selectionmethod also has its own limitations, e.g. feedback distortion,which comes from the requirement that a pure CF systemneeds explicit feedback from users on their favourite itemsbefore the system can start to recommend items. Unfortu-nately, the ratings gathered from users may suffer distortionproblem probably because not all users wish to rate the itemafter they have used them (Claypool et al. 2001).
After considering the pros and cons of CF approach ingroup collaborative work, a specific group based personalprofile is proposed where an implicit rating accumula-tion method has been firstly developed to overcome theinformation distortion problem by monitoring consumer’spreference on each web service. Meanwhile, service depen-dency has been also taken into account for the selectionprocess based on the association rule.
Based on the discussion in previous sections, a CF basedpersonal profile generator is proposed and implemented byfour steps, as shown in Fig. 3. This profile generator isbased on individual personal profile generator, as depictedin Fig. 2, which is extended to support group knowledgesharing. As such besides the individual composition history,

Inf Syst Front
PersonalComposition
Group Based Personal Profile
1 3
GroupComposition
+
4
2
Fig. 3 CF based personal profile generator
it also studies the composition process histories of othersimilar consumers. The core parts in the personal profilegenerator include:
1. To build individual service composition database. Theindividual service composition database is implementedby using the same method of individual based personalprofile generator, as shown in Fig. 2. Formally, let U =u1, u2, . . . , un be the whole consumer set, the indi-vidual composition database for each consumer can bedefined as:
Rui = T1, T2, . . . , Tm (9)
where Ti is a web service composition transactionoccurred within a pre-defined time interval and can bedefined as:
Ti = S1, S2, . . . , Sm, Si ∈ S (10)
where S is the whole set of web services registered inthe repository.
2. To identify the neighbourhood. Given a user ui , thisprocess is responsible for finding a set of similar con-sumers ui which satisfies:
ui = uj |i = j and sim(ui, uj ) < γ (11)
where uj ∈ ∪T op N .3. To build group service composition database. For each
consumer ui , neighbourhood’s composition database isdefined as:
Rui = ∪Ru,where u ∈ ui (12)
4. To generate group based personal profile. After theindividual composition database and neighbourhood
composition database are identified, a database includeall composition transactions by those consumers arebuilt up, defined as:
R′ = Rui ∪ Rui (13)
The group based personal profile can be defined as aset of association rules extracted from R′ and expressedas:
PRui = Si → Sj | Si, Sj ∈ S (14)
where support (Si → Sj ) > γ and conf idence(Si →Sj ) > ξ .
Generally, the group based personal profile generationprocess is similar to it for individual personal profilegeneration. The difference exists in the new concept ofneighbourhood composition history. During the process, theneighbourhood identification is probably the most difficultpart, which will be elaborated in the following section fromthe viewpoint of web service usage pattern.
3.3 Neighbourhood identification
3.3.1 Implicit feedback identifier
It is indicated by a lot of work that explicit rating is notapplicable all the time. Therefore, some implicit ratingapproaches have been proposed and studied to overcomethe possible information distortion. For example, durationis one of the observable behaviours in examination group.In web usage application, a user’s browse duration on acertain web page could indicate its favour on that page.Apparently, different application domains should employdifferent observable behaviours or combinations of severalbehaviours to better understand consumers’ opinions sincedifferent approaches have their own rate explanation.
To calculate invocation rate of the user-service pair, itis necessary to firstly classify all of web services in therepository. A lot of semantic based classification methodsare proposed in the community. For example, Corella andCastells propose a semi-automatic semantic based methodfor web service classification (Corella and Castells 2006).After the web services in the repository have been classified,the repository can be defined as S = S1, S2, S3, . . . , St ,and Si represents a web service class.
Given a web service class Si = si1, si2, si3, . . . , simand a set of consumers U = u1, u2, u3, . . . , un, whenevera web service sij is selected by a consumer uk , the selec-tion is recorded. The overall selection number is defined asnumber(sij , uk), which indicates how many times the con-sumer uk select web service sij . After analysing a certain

Inf Syst Front
time interval, the selection ratio of each web service sij inthe service class Si by the user uk could be calculated anddefined as:
f req(sij , uk) =
number(sij ,uk )∑mj=1 number(sij ,uk)
if number(sij , uk) = 0
φ if number(sij , uk) = 0(15)
The selection ratio of a web service φ means the user neverselects it during the investigated time interval. Therefore therange of f req(sij , uk) is (0, 1].
3.3.2 Similar user finder
After getting the selection ratio of each web service by eachconsumer, a two-dimensional service-frequency table sim-ilar to Table 1 will be built up. The rating rsij ,uk is theselection frequency of a web service sij for that consumeruk in the particular web service class Si :
rsij ,uk = f req(sij , uk) (16)
The most popular similarity measures employed in CFinclude Pearson correlation based and Cosine basedapproaches. The obtained similar users by these two differ-ent methods are of not much difference. In this research,Pearson correlation (Resnick et al. 1994), the widely usedneighbourhood algorithm in memory-based CF applica-tions, is employed to find similar users by studying theirinvocation behaviours.
Firstly, the average invocation frequency of a certain useruk on each web service class Si is calculated and could bedefined as:
rsi ,uk =1
|Sc|∑s∈Sc
rs,uk (17)
where Sc = s ∈ S|rs,uk = φSecondly, the similarity between any two consumers is
measured, which can be measured as:
sim(ux, uy) =∑s∈Sxy (rs,ux − rsi ,ux )(rs,uy − rsi ,uy )√∑
s∈Sxy (rs,ux − rsi ,ux )2∑
s∈Sxy (rs,uy − rsi ,uy )2
(18)
where Sxy = s ∈ Si |rs,ux = φ and rs,uy = φ
3.4 Re-ranking framework
The proposed framework is depicted as Fig. 4, where a setof components are identified:
1. P , a consumer who submits the web service request.2. r , which is the service request being submitted to the
discovery system.3. Context = s1, s2, . . . , sk, which is the running con-
text consisting of a set of web services being integrated
with the retrieved service for a certain compositiontarget.
4. Tp, which is the consumer P ’s personal compositionhistory.
5. Sp, which is the set of similar consumers.6. Gp, which is the composition history of Sp.7. Prof ile, which is the personal profile consisting
of a set of association rule generated from SPand Gp.
8. M , which could be any type of the matching model.9. C = c1, c2, . . . , cn, which is the initially retrieved
set of candidates by employing a certain web servicematching model
10. f , which is the re-ranking model responsible for re-evaluate the initial retrieved candidate set C and makeproper recommendation.
11. C′ = c′1, c′2, . . . , c′n, which is the re-ranked service setbeing displayed to the consumer P .
Amongst the re-ranking frame, the re-ranking model isthe most important part for personalised recommenda-tion, which needs to collaborate with the initially retrievedcandidates C, running context Context , personal pro-file Prof ile. Its working procedure is show in Fig. 5where the overall weight of each candidate is cal-culated by summing up all confidence values accord-ing to Context and Prof ile, inspired by the idea ofLCA method (Huang and Suen 1995). During the re-ranking procedure, the Context is optional, which meansif the request service is not involved into any com-position process, the re-ranking part will not take anyaction.
4 Experimental study
4.1 Data preparation
Currently there is no standard dataset in the communityfor validating web service discovery, particularly for per-sonalised discovery approaches. One of the difficulties isbecause there are not enough web services advertised in theInternet or repository to constitute an objective test bed. Forexample, some works exploring the analysis of online webservices report their results based on thousands level webservices (Li et al. 2007; Al-Masri and Mahmoud 2008).
Some works evaluate their approaches by using otherdatasets, such as Movielens, a widely used dataset in recom-mender system (Sreenath and Singh 2004). In this research,Movielens is employed as a basic dataset. However, Movie-lens cannot be directly applied in the proposed experimentsince it does not contain transaction information, whichis a strong indicative hint for web service discovery. In

Inf Syst Front
Fig. 4 Web service rankingframework
Service Request r
Matching Model M
Re-ranking Model f
Personal Composition Transaction
C = (c1, c2, ..., cn)
C = (c 1, c 2, ..., c n)
Tp
Context = (s 1, s 2, ..., s k)
Consumer P
Group Composition Transaction
Gp
Sp
Subm
it
Identify Generate
Profile
this work, an artificial dataset is built up based on Movie-lens by manually adding information of service compositionprocess.
4.1.1 Data generation
The Movielens dataset consists of 100,000 ratings, from 0–5 (1–5 lest to most favourite, 0 no rating), and 943 userson 1,682 movies categorized into 19 groups (one moviemay belong to more than one groups). Each user has rated
Fig. 5 Service candidates re-ranking procedure
over at least 20 movies. Therefore, in this experiment, amovie in Movielens dataset is considered as a web service.After analysing the original Movielens dataset, 18 groupsof web services are obtained and the group “unknown” isdeleted since this group only contains 2 web services. Thetotal number of web services for our experiment is 2,891, asshown in Table 2. The number is more than 1,682 becausesome movies belong to different groups in Movielens whilein this experiment they are classified into different web ser-vice groups. The ratings in the dataset can be considered asusers’ preferences for the web services.
Table 2 Web service group-number
Group Number of service Group Number of service
1 251 10 24
2 135 11 92
3 42 12 56
4 122 13 61
5 505 14 247
6 109 15 101
7 50 16 251
8 725 17 71
9 22 18 27

Inf Syst Front
4.1.2 Web service composition preparation
Since Movielens does not contain any transaction informa-tion, which however in this work is considered as importanthints for service selection, the composition process is there-fore generated manually. A typical web service compositionexample has been given in Fig. 1. Considering that thesequence feature of transactions has been reported in a lot ofresearches in recommender systems (Shani et al. 2005), tosimplify the experimental study, in this research all web ser-vice composition transaction are considered as a set of webservice invoked sequentially, as shown in Fig. 6.
To avoid subjective judgement on the composition trans-actions, the generation function is defined as below:
T = f (A, L,N,R,H, S, C) (19)
where T is the set of generated web service compositiontransactions and f is the generation function that has 7input parameters, which are described as follow by using thecomposition example in Fig. 6.
1. A, which is used to define the number of abstractweb service composition processes. As discussed inSection 2, a web service composition can be consid-ered a set of abstract web services logically integratedtogether and real web services will be selected at run-time. In this experiment, each abstract composition pro-cess consists of a set of Group No., which is randomlyselected from the 18 groups in Table 2.
2. L, which is the number of the abstract web servicesbeing invoked in the composition process. For exam-ple, the length of abstract composition process in Fig. 6is 5 and a possible abstract composition process isG1, G5, G7, G9, G11, which means the real composi-tion process will be generated by randomly selectingweb services from Group 1, Group 5, Group 7, Group 9and Group 11 at runtime.
3. N , which indicates the number of abstract web ser-vice composition processes being used from the wholeabstract composition processes defined by Abstract. Ineach composition process, the selection of a real webservice from some specified group is based on the pre-defined preferences. Some work have reported that in
S1 S2 S3 S4 S5
... s52s21 s22
Fig. 6 Example of data preparation in the experiment
web based system, the request behaviours normally fol-low Zipf popularity distribution (Breslau et al. 1999),which means higher preference implies higher proba-bility of selection. In this research, this kind of schemais employed to generate actual web service invocation.
4. R, which indicates the number the selected composi-tion processes will keep repeating until completion ofrequired transactions.
5. H , which is used in CF to determine the size of theneighbourhood.
6. S, which is the support constraint for extracting associ-ation rules from composition history dataset.
7. C, which is the confidence constraint for extractingassociation rules from composition history dataset.
For example, T = f (200, 12, 50, 20, 10, 0.02, 0.20)indicates that there are 200 abstract composition processesavailable in the artificial dataset. Each abstract composi-tion process includes 12 abstract web services. Randomlyselected 50 out of the whole 200 processes will be run-ning 10 times to generate the composition history. WhenCF is employed to find group based personal profile, 10similar consumers will be explored and accordingly associ-ation rules will be generated by setting support = 0.02 andconf idence = 0.20.
4.1.3 Experiment preparation
After a batch of service composition transactions is obtainedfor each consumer, all of the composition transactions arepartitioned into training dataset and test dataset, by 80/20ratio. For each consumer 80 % randomly selected composi-tion transactions will be stored as his personal compositionhistory, while the 20 % transactions will be acted as testdataset for validation. Once training dataset is recognised,the personal profiles can be obtained by extracting depen-dency from the training dataset.
For each consumer, the personal profile are mined fromthe composition history combining both the consumer andthe neighbourhood’s composition transactions in the train-ing dataset. In this research, to simplify the experimentalstudy, the neighbour’s number is set to 10 (Herlocker et al.1999). Afterwards the rest 20 % test dataset and the person-alised association rule are explored to find correspondingweb services. For each composition process containing Nweb services in test dataset, the first N-1 web services willbe used as indicator to predict the last one, as illustrated inFig. 6.
4.2 Performance metrics
The performance metric adopted in this experiment is preci-sion, which is widely used in information retrieval and other

Inf Syst Front
application domains (Adomavicius and Tuzhilin 2005). Itmeasures the fraction of correct items among all retrieveditems and is usually defined as:
precision = correct ∩ retrieved
retrieved(20)
where correct is the number of corrected items in theretrieved set and retrieved is the total number of recom-mended items by the system. Particularly, the performanceP@k is used in this research, which means the average pre-cision of the top k candidates recommended by the frame-work. P@k has been widely used for evaluating systemperformance (Herlocker et al. 2004; Cormack and Lynam2006) as consumers will be likely not to select items beyondtop-k candidates (McLaughlin and Herlocker 2004). P@k
is normally defined as:
P@k =∑k
i=1 hit (si )
k(21)
where hit (si ) indicates whether the returned ith web servicecandidate is an acceptable one and is defined as:
hit (si ) =
1 si in the scope of corrected set0 otherwise
(22)
To make the analysis result more clear and convinci-ble, three different correct sets are used in the experiments.The first correct set only includes web services with rat-ing 5. The second set considers both rating 5 and rating4 as correct selection, while the third correct set includesall web services with rating no less than 3. Accordinglythe three correct datasets are denoted as Correct = 5,Correct = 5, 4, Correct = 5, 4, 3, respectively. Sincesome users do not rate any movie more than 3 in severalgroups, it is a difficult to evaluate such retrieved result asthe correct set is too small. Thus the composition transac-tions will be excluded from test dataset if there is no correctselection in the respective three anticipated datasets.
4.3 Analysis of experimental study
4.3.1 Feasibility of employing personal profile
This experiment is firstly to analyse the feasibility ofemploying personal profile to support web service selection.To validate the proposed framework, a baseline evaluationis constituted for performance comparison. In this research,the classical nearest-neighbour based collaborative filteringalgorithm discussed in Adomavicius and Tuzhilin (2005) isimplemented for the baseline assessment.
Let U = u1, u2, . . . , un the user set consisting of 943users and G = G1, G2, . . . , Gm the 18 groups shownin Table 2. The average baseline P@k is calculated as a
problem of find top-k services in each group for every userbased on the ratings of the user’s nearest neighbourhood.Since in the real applications the users are typically muchinterested in looking into the top 20 recommended items(Huang et al. 2007), the k in this experimental study isthen set to 1, 2, 3, 4, 5, 10, 20, respectively and the per-formance result is shown as in Table 3. From the table it isfound that the average P@k for classical memory based CFalgorithm is relatively low and the consumers will probablyfind the top-ranked candidates far from their business inter-ests, which is consistent to the report in (McLaughlin andHerlocker 2004).
To evaluate the proposed personal profile based serviceranking and recommendation, an artificial dataset is con-stituted for performance evaluation, as shown below. Thedataset contains 200 abstract composition transactions andeach transactions consists of 5 abstract web services, while100 randomly selected processes are executed 10 times toartificially create patterns in service compositions. Whenbuilding personal profile, 10 nearest neighbours’ usage his-tory are employed and the association rules in the personalprofile is generated by setting the confidence constraint to0.02 and the support constraint to 0.10.
T1 = f (200, 5, 100, 10, 10, 0.02, 0.10) (23)
Since the focus in this research has been attained to thegroup based personal profile and its capacity in serviceselection, to validate the performance of personal profile asfully as possible, the consumer’s own composition historyis deliberately excluded when generating personal profile inthis and following experiment studies. The reason of hidingthe consumer’s own composition process is to make surethere is no strong preference inferred from the consumer’sown composition history.
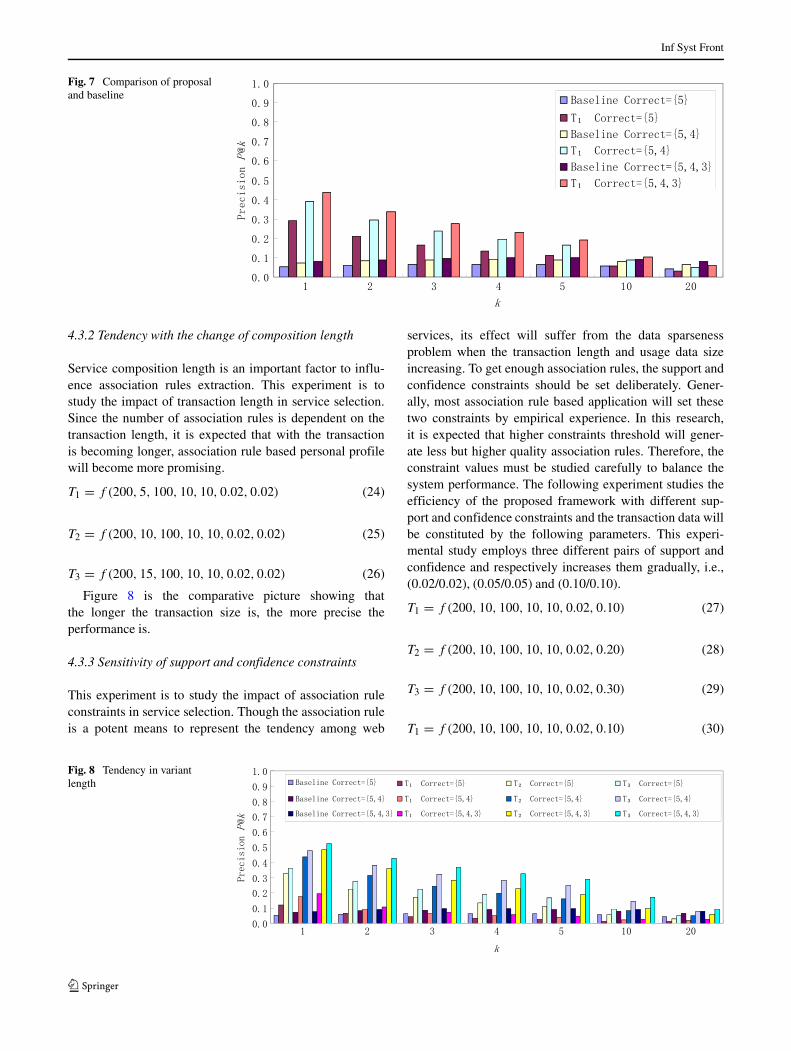
A comparative picture is depicted as Fig. 7. From theresult it is found that the proposed selection approach in T1
database works much better than baseline method. This sce-nario implies that when a consumer operates more similarservice compositions due to business requirement, it is morelikely that pattern can be identified and then used for serviceselection in future applications.
Table 3 Performance of baseline
Correct = 5 Correct = 5, 4 Correct = 5, 4, 3
P@1 5.4 % 7.4 % 7.8 %
P@2 6.1 % 8.4 % 8.9 %
P@3 6.5 % 8.9 % 9.6 %
P@4 6.5 % 9.0 % 9.8 %
P@5 6.5 % 8.9 % 9.8 %
P@10 5.7 % 8.1 % 9.1 %
P@20 4.2 % 6.6 % 8.0 %
Inf Syst Front
Fig. 7 Comparison of proposaland baseline
4.3.2 Tendency with the change of composition length
Service composition length is an important factor to influ-ence association rules extraction. This experiment is tostudy the impact of transaction length in service selection.Since the number of association rules is dependent on thetransaction length, it is expected that with the transactionis becoming longer, association rule based personal profilewill become more promising.
T1 = f (200, 5, 100, 10, 10, 0.02, 0.02) (24)
T2 = f (200, 10, 100, 10, 10, 0.02, 0.02) (25)
T3 = f (200, 15, 100, 10, 10, 0.02, 0.02) (26)
Figure 8 is the comparative picture showing thatthe longer the transaction size is, the more precise theperformance is.
4.3.3 Sensitivity of support and confidence constraints
This experiment is to study the impact of association ruleconstraints in service selection. Though the association ruleis a potent means to represent the tendency among web
services, its effect will suffer from the data sparsenessproblem when the transaction length and usage data sizeincreasing. To get enough association rules, the support andconfidence constraints should be set deliberately. Gener-ally, most association rule based application will set thesetwo constraints by empirical experience. In this research,it is expected that higher constraints threshold will gener-ate less but higher quality association rules. Therefore, theconstraint values must be studied carefully to balance thesystem performance. The following experiment studies theefficiency of the proposed framework with different sup-port and confidence constraints and the transaction data willbe constituted by the following parameters. This experi-mental study employs three different pairs of support andconfidence and respectively increases them gradually, i.e.,(0.02/0.02), (0.05/0.05) and (0.10/0.10).
T1 = f (200, 10, 100, 10, 10, 0.02, 0.10) (27)
T2 = f (200, 10, 100, 10, 10, 0.02, 0.20) (28)
T3 = f (200, 10, 100, 10, 10, 0.02, 0.30) (29)
T1 = f (200, 10, 100, 10, 10, 0.02, 0.10) (30)
Fig. 8 Tendency in variantlength

Inf Syst Front
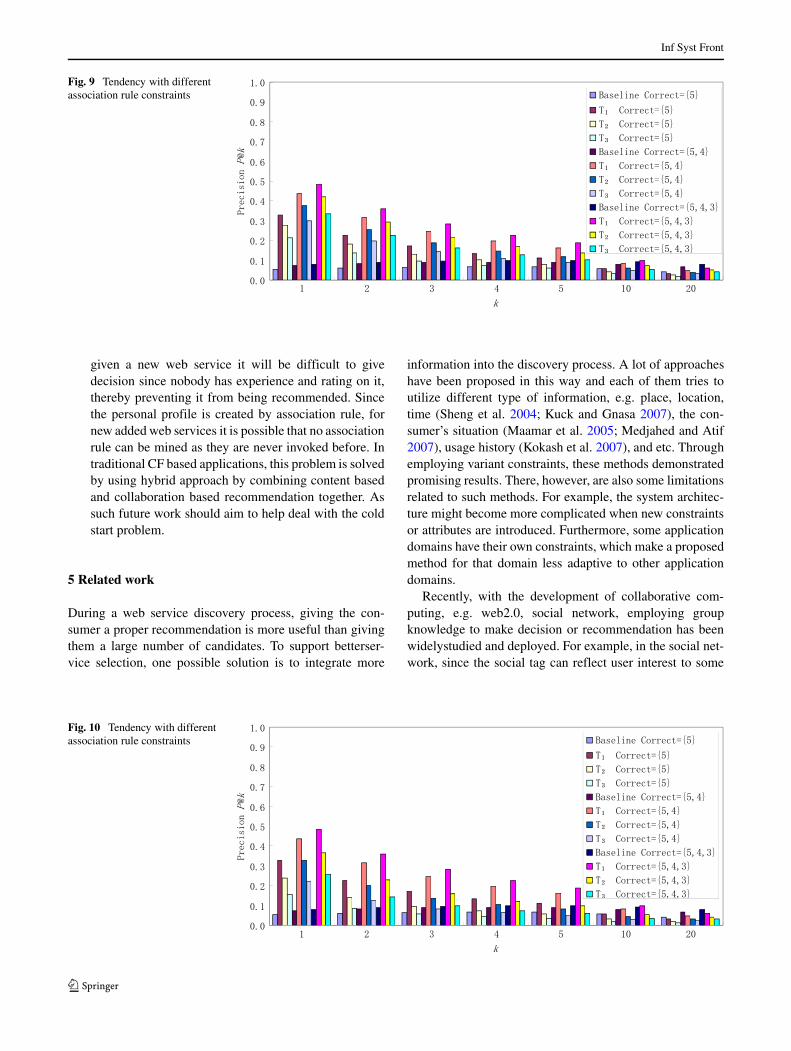
T2 = f (200, 10, 100, 10, 10, 0.06, 0.10) (31)
T3 = f (200, 10, 100, 10, 10, 0.10, 0.10) (32)
Figure 10 is the comparative picture showing that whenthe constraints are set higher, the performance will becomeunsatisfactory. The reason is probably because in such sit-uation the number of association rules will be reducedgradually. As such it will become difficult to predict servicepreference.
4.4 Discussions
The advantages of proposed personal profile in this researchare promising. Firstly, it is automatic and does not rely onconsumer’s heavy involvement. Secondly, if the web servicecollection, or training dataset for association rule mining,is big enough, theoretically it can sufficiently reflect theservice consumer’s real intention.
Generally, the association rule based personal profileworks well in the experiment study. By reviewing andanalysing the experiment in detail, some more interestingfindings are revealed. It is found that some of P@k forcertain consumer is 0. That is because all of the similarusers do not invoke web services from that group. In suchcase, no recommendation can be made. This is probably alimitation of group knowledge based recommendation sys-tems. As such it is argued that this group knowledge basedapproach will be useful when the consumer’s coverage onitems are big enough, which means the user-item matrixcould not be too sparse. Moreover, it is reasonable to con-sider of providing hybrid mechanism to take advantagesof group knowledge sharing and content based method. Inthe experimental study, different parameters are selected foranalysis, from which some lessons can be learned as listedbelow:
1. Web service composition does play as a kind of indica-tive hint for service selection to some extent. In factin our experiment, the selection of a web serviceonly relies on its pre-defined ratings. If business logicis employed, it is expected more patterns could bereflected by web service composition. As such it couldbe more indicative, particularly when a set of web ser-vice with lower preferences must be invoked in a certainsituation.
2. One key point for successful association rule basedapproaches is that the web service composition trans-action consists of enough web services. That meansif the web service composition is of short length, itmight be difficult to get enough association rules for theselection.
3. It is impossible to predict the invocation probability ofcertain web services if the web service compositions by
the entire neighbourhood of the user do not use the webservices before. It is one possible limitation comparedwith traditional CF based applications.
Despite the theoretical advance of the proposedapproach, there are some research challenges related to itpresented as below.
1. One of the major difficulties in web service relatedresearch is the limitation of objective test dataset.Though web service is lauded as a promising tech-nique for service component reuse and interoperability,the number of available web service is not as manyas expected. With the further development, large scaledata is obviously essential for any experiment basedstudy, not excepting web service area. Since currentlythere is no de facto standard dataset for web servicediscovery, in this research, the experiment is conductedbased on an artificial database Movielens from therecommender system domain, where the metadata iscollected from real dataset but the transactions are man-ually generated. Though the transaction generation isdesigned as carefully as possible to avoid any subjec-tive biases, it will be more convincing if the experimentcan be conducted on real dataset. It is then signif-icant to evaluate the proposal of service re-rankingmechanism in benchmark dataset, whenever available.Furthermore, without large scale test data set, a delib-erately designed selection mechanism could overrunthe other ones. As such in this research, we do notintend to prove the performance of the proposed re-ranking model is better, instead we wish to provide anforesight of the possibilities for service ranking andrecommendation.
2. As revealed by experiment studies, there are some chal-lenges to the proposed personal profile based selectionframework, among which two major problems shouldbe given priority in the future works, i.e. alleviationof sparsity and cold start problem. Sparsity is a greatchallenge for group coordination based approach indecision making (Huang et al. 2004). In this research,a group based personal profile is proposed to reveal aconsumer’s background and preference by using asso-ciation rule technique. It is a possible problem in asparse dataset that association rules cannot be properlyextracted, which has been shown in experiment studies.Since it is a common problem in all group informationbased system, a lot of approaches have been proposed inthe literature. One possible approach is to group homo-geneous attributes and then explore association ruleinside each group (Plasse et al. 2007).
3. The proposed personal profile approach in this researchalso suffers cold start problem, a typical challenge in CFbased applications (Schein et al. 2002), which means
Inf Syst Front
Fig. 9 Tendency with differentassociation rule constraints
given a new web service it will be difficult to givedecision since nobody has experience and rating on it,thereby preventing it from being recommended. Sincethe personal profile is created by association rule, fornew added web services it is possible that no associationrule can be mined as they are never invoked before. Intraditional CF based applications, this problem is solvedby using hybrid approach by combining content basedand collaboration based recommendation together. Assuch future work should aim to help deal with the coldstart problem.
5 Related work
During a web service discovery process, giving the con-sumer a proper recommendation is more useful than givingthem a large number of candidates. To support betterser-vice selection, one possible solution is to integrate more
information into the discovery process. A lot of approacheshave been proposed in this way and each of them tries toutilize different type of information, e.g. place, location,time (Sheng et al. 2004; Kuck and Gnasa 2007), the con-sumer’s situation (Maamar et al. 2005; Medjahed and Atif2007), usage history (Kokash et al. 2007), and etc. Throughemploying variant constraints, these methods demonstratedpromising results. There, however, are also some limitationsrelated to such methods. For example, the system architec-ture might become more complicated when new constraintsor attributes are introduced. Furthermore, some applicationdomains have their own constraints, which make a proposedmethod for that domain less adaptive to other applicationdomains.
Recently, with the development of collaborative com-puting, e.g. web2.0, social network, employing groupknowledge to make decision or recommendation has beenwidelystudied and deployed. For example, in the social net-work, since the social tag can reflect user interest to some
Fig. 10 Tendency with differentassociation rule constraints

Inf Syst Front
extent, it is then argued that users who have most commontags can be considered having common interests. Based onthis idea, an Internet Social Interest Discovery system hasbeen proposed in which users with the shared social tags arediscovered and grouped together (Li et al. 2008). Generallyspeaking, it is always a fact that preferences of users withsimilar interests are basically consistent. Therefore, in webservice applications collaboration is also a usual mechanismfor service selection.
As an important social collaboration method, CF hasbeen proven successful in different recommender systems,e.g. e-business applications, where the consumers will begiven suggestions during the purchasing process. In webservice related applications, CF has also been widely stud-ied and a lot of CF based methods have been developedtowards web service discovery. For example, Manikrao andPrabhakar (2005) provides a recommendation method basedon the model-based CF methods, in which predictions ofweb services for a user will be calculated and presented inorder of their ratings. Sreenath and Singh (2004) proposean extended concept-based collaborative evaluation systemfor web service selection by using some ideas of collab-orative filtering. In that approach, agent instead of user isused to collect the rating for each web service. Shao et al.(2007) uses memory-based CF in QoS aware web servicediscovery. It uses QoS value as the rating score and triesto find similar users via observing similar QoS experience.Kerrigan (2006) develop a CF based web service selec-tion mechanism using goal and preference together but notsingle rating to predict and recommend webservices.
6 Conclusion and future work
With the mushrooming number of web services in pub-lic repositories, it is becoming vital to provide an efficientweb service discovery with respect to a given consumer’srequirement. A typical web service discovery consists oftwo major tasks, i.e., matchmaking and selection. Thispaper particularly focusing on web service selection as itis pointed out by some scholars that recommendation of aproper service is probably the most important task in webservice discovery applications.
Since it is anticipated that a retrieved web service willoften partake in some composition processes, it can beargued that the web service composition provides some use-ful information for web service discovery. As such in thisresearch, web service selection is studied from a web ser-vice composition perspective and the possibility of usingpersonal profile is explored to facilitate web service rank-ing and recommendation. By utilising composition trans-actions, two personal profiles are proposed, i.e. individualbased personal profile and group based personal profile.
By combining the composition transaction information, apersonalised web service ranking mechanism is developed.The experimental study has shown some interesting resultsand it is believed the research direction is promising.
Despite the potential benefit of the proposed method,there are some more points which deserve to be stud-ied further in the future. In this research, the rankingmechanism only considers one-to-one association rule likesi → sj to simplify the problem. Considering the depen-dency also exists between more than two services such as(si , . . . , sj ) → sk , it is worthy to explore this kind of depen-dency among the services to facilitate the ranking processin the future works. Furthermore, as indicated in previoussection, CF based approaches normally suffer sparsity andcold start problem, which need more efforts to improve theproposed framework.
Acknowledgments This work was partially supported by the StateKey Laboratory of Software Development Environment of China (No.SKLSDE-2013ZX-25), the National Natural Science Foundation ofChina (No. 61103095), and the National High Technology Researchand Development Program of China (No. 2013AA01A601). We aregrateful to Shenzhen Ke y Laboratory of Data Vitalization (Smart City)for supporting this research.
References
Adomavicius, G., & Tuzhilin, A. (2005). Toward the next genera-tion of recommender systems: a survey of the state-of-the-art andpossible extensions. IEEE Transactions on Knowledge and DataEngineering, 17(6), 734–749. doi:10.1109/TKDE.2005.99.
Aggarwal, C.C., & Yu, P.S. (1998). A new framework for itemset gen-eration. In Proceedings of 17th ACM SIGACT-SIGMOD-SIGARTsymposium on principles of database systems (pp. 18–24).doi:10.1145/275487.275490, db/conf/pods/AggarwalY98.html.
Agrawal, R., Imielinski, T., Swami, A.N. (1993). Mining associ-ation rules between sets of items in large databases. In Pro-ceedings of 1993 ACM SIGMOD international conference onmanagement of data (pp. 207–216). doi:10.1145/170035.170072,db/conf/sigmod/AgrawalIS93.html.
Akkiraju, R., Farrell, J., Miller, J., Nagarajan, M., Schmidt, M.-T.,Sheth, A., Verma, K. (2005). Web service semantics—WSDL-S.http://www.w3.org/Submission/WSDL-S/.
Al-Masri, E., & Mahmoud, Q.H. (2008). Investigating Web ser-vices on the World Wide Web. In Proceedings of 17thinternational conference on World Wide Web (pp. 795–804).doi:10.1145/1367497.1367605.
Barros, A., Dumas, M., Bruza, P. (2005). The move to Web serviceecosystems. BPTrends Newsletter, 3(12).
Basu, S., Casati, F., Daniel, F. (2007). Web service dependency dis-covery tool for SOA management. In Proceedings of 4th IEEEinternational conference on services computing (pp. 684–685).doi:10.1109/SCC.2007.130.
Breese, J.S., Heckerman, D., Kadie, C.M. (1998). Empiricalanalysis of predictive algorithms for collaborative filtering.In Proceedings of 14th international conference on uncer-tainty in artificial intelligence (pp. 43–52). http://rome.exp.sis.pitt.edu/UAI/Abstract.asp?articleID=231&proceedingID=14.

Inf Syst Front
Breslau, L., Cao, P., Fan, L., Phillips, G., Shenker, S. (1999). Webcaching and Zipf-like distributions: evidence and implications. InProceedings of 18th annual joint conference of the IEEE computerand communications societies (pp. 126–134).
Brin, S., Motwani, R., Ullman, J.D., Tsur, S. (1997). Dynamic item-set counting and implication rules for market basket data. InProceedings of 1994 ACM SIGMOD international conference onmanagement of data (pp. 255–264). doi:10.1145/253260.253325,db/conf/sigmod/BrinMUT97.html.
Burstein, M.H., Hobbs, J.R., Lassila, O., Martin, D.L., McDermott,D.V., McIlraith, S.A., Narayanan, S., Paolucci, M., Payne, T.R.,Sycara, K.P. (2002). DAML-S: Web service description for thesemantic Web. In Proceedings of 1st international semanticweb conference (pp. 348–363). http://link.springer.de/link/service/series/0558/bibs/2342/23420348.htm.
Cervantes, H., & Hall, R.S. (2003). Automating sService dependencymanagement in a service-oriented component model. In Proceed-ings of 6th international workshop on component-based softwareengineering.
Chen, W., & Paik, I. (2013). Improving efficiency of service discoveryusing Linked data-based service publication. Information SystemsFrontiers, 15(4), 613–625. doi:10.1007/s10796-012-9381-x.
Chen, X., Liu, X., Huang, Z., Sun, H. (2010). RegionKNN: ascalable hybrid collaborative filtering algorithm for person-alized Web service recommendation. In Proceedings of 8thIEEE international conference on web services (pp. 9–16).doi:10.1109/ICWS.2010.27.
Claypool, M., Le, P., Waseda, M., Brown, D. (2001). Implicitinterest indicators. In Proceedings of 2001 international con-ference on intelligent user interfaces (pp. 33–40). doi:10.1145/359784.359836.
Corella, M.A., & Castells, P. (2006). Semi-automatic semantic-basedWeb service classification. In Proceedings of 2001 interna-tional conference on intelligent user interfaces (pp. 459–470).doi:10.1007/11837862 43.
Cormack, G.V., & Lynam, T.R. (2006). Statistical precision of infor-mation retrieval evaluation. In Proceedings of 29th annual inter-national conference on research and development in informationretrieval (pp. 533–540). doi:10.1145/1148170.1148262.
de Bruijn, J., Lausen, H., Polleres, A., Fensel, D. (2006). The Webservice modeling language WSML: an overview. In Proceed-ings of 3rd European semantic Web conference (pp. 590–604).doi:10.1007/11762256 43.
Fang, J., Hu, S., Han, Y. (2004). A service interoperability assess-ment model for service composition. In Proceedings of 2004IEEE international conference on services computing (pp. 153–158). http://csdl.computer.org/comp/proceedings/scc/2004/2225/00/22250153abs.htm.
Feng, Z., Peng, R., Wong, R.K., He, K., Wang, J., Hu,S., Li, B. (2013). QoS-aware and multi-granularity servicecomposition. Information Systems Frontiers, 15(4), 553–567.doi:10.1007/s10796-012-9378-5.
Fonseca, B.M., Golgher, P.B., Possas, B., Ribeiro-Neto, B.A.,Ziviani, N. (2005). Concept-based interactive query expan-sion. In Proceedings of 2005 ACM international conferenceon information and knowledge management (pp. 696–703).doi:10.1145/1099554.1099726.
Gu, Q., & Lago, P. (2009). Exploring service-oriented systemengineering challenges: a systematic literature review. Ser-vice Oriented Computing and Applications, 3(3), 171–188.doi:10.1007/s11761-009-0046-7.
Herlocker, J.L., Konstan, J.A., Borchers, A., Riedl, J. (1999). An algo-rithmic framework for performing collaborative filtering. In Pro-ceedings of 22nd annual international ACM SIGIR conferenceonresearch and development in information retrieval (230–237).doi:10.1145/312624.312682.
Herlocker, J.L., Konstan, J.A., Terveen, L.G., Riedl, J. (2004).Evaluating collaborative filtering recommender systems.ACM Transactions on Information Systems, 22(1), 5–53. doi:10.1145/963770.963772.
Huang, Y.S., & Suen, C.Y. (1995). A method of combining multipleexperts for the recognition of unconstrained handwritten numerals.IEEE Transactions on Pattern Analysis and Machine Intelligence,17(1), 90–94. http://www.computer.org/tpami/tp1995/i0090abs.htm.
Huang, Z., Chen, H., Zeng, D.D. (2004). Applying associative retrievaltechniques to alleviate the sparsity problem in collaborative filter-ing. ACM Transactions on Information Systems, 22(1), 116–142.doi:10.1145/963770.963775.
Huang, Z., Zeng, D., Chen, H. (2007). A comparison of collaborative-filtering recommendation algorithms for E-commerce. IEEE Intel-ligent Systems, 22(5), 68–78. doi:10.1109/MIS.2007.80.
Kerrigan, M. (2006). Web service selection mechanisms in theWeb service execution environment (WSMX). In Proceedings of2006 ACM symposium on applied computing (pp. 1664–1668).doi:10.1145/1141277.1141671.
Klusch, M., Fries, B., Sycara, K.P. (2006). Automated semantic Webservice discovery with OWLS-MX. In Proceedings of 5th inter-national joint conference on autonomous agents and multiagentsystems (pp. 915–922). doi:10.1145/1160633.1160796.
Kokash, N., Birukou, A., D’Andrea, V. (2007). Web service discoverybased on past user experience. In Proceedings of 10th interna-tional conference on business information systems (pp. 95–107).doi:10.1007/978-3-540-72035-5 8.
Kuck, J., & Gnasa, M. (2007). Context-sensitive service discoverymeets information retrieval. In Proceedings of 5th IEEE interna-tional conference on pervasive computing and communications(pp. 601–605). doi:10.1109/PERCOMW.2007.32.
Li, Y., Liu, Y., Zhang, L.-J., Li, G., Xie, B., Sun, J. (2007). Anexploratory study of Web services on the internet. In Proceed-ings of 5th IEEE international conference on Web services (pp.380–387). doi:10.1109/ICWS.2007.37.
Li, X., Guo, L., Zhao, Y.E. (2008). Tag-based social interest discovery.In Proceedings of 17th international conference on World WideWeb (pp. 675–684). doi:10.1145/1367497.1367589.
Liang, Q.A., Chung, J.-Y., Miller, S., Yang, O. (2006). Ser-vice pattern discovery of Web service mining in Web ser-vice registry-repository. In Proceedings of 2006 IEEE inter-national conference on e-business engineering (pp. 286–293).doi:10.1109/ICEBE.2006.90.
Maamar, Z., Mostefaoui, S.K., Mahmoud, Q.H. (2005). Con-text for personalized Web services. In Proceedings of 38thHawaii international conference on system sciences. doi:10.1109/HICSS.2005.164.
Manikrao, U.S., & Prabhakar, T.V. (2005). Dynamic selection of Webservices with recommendation system. In Proceedings of 2005international conference on next generation web services practices(pp. 117–121). doi:10.1109/NWESP.2005.32.
Martin, D.L., Paolucci, M., McIlraith, S.A., Burstein, M.H.,McDermott, D.V., McGuinness, D.L., Parsia, B., Payne, T.R.,Sabou, M., Solanki, M., Srinivasan, N., Sycara, K.P. (2004).Bringing semantics to Web services: the OWL-S approach.In Proceedings of 1st international workshop on seman-tic web services and web process composition (pp. 26–42).http://springerlink.metapress.com/openurl.asp?genre=article&issn=0302-9743&volume=3387&spage=26.
McLaughlin, M.R., & Herlocker, J.L. (2004). A collaborative filter-ing algorithm and evaluation metric that accurately model theuser experience. In Proceedings of 27th annual international ACMSIGIR conference on research and development in informationretrieval (pp. 329–336). doi:1008992.1009050.

Inf Syst Front
Medjahed, B., & Atif, Y. (2007). Context-based matching for Web ser-vice composition. Distributed and Parallel Databases, 21(1), 5–37. doi:10.1007/s10619-006-7003-7.
Moore, J., hong Han, E.-h., Boley, D., Gini, M., Gross, R., Hast-ings, K., Karypis, G., Kumar, V., Mobasher, B. (1997). Web pagecategorization and feature selection using association rule andprincipal component clustering. In Proceedings of 7th workshopon information technologies and systems.
Oard, D., & Kim, J. (1998). Implicit feedback for recommender sys-tems. In Proceedings of AAAI workshop on recommender systems(pp. 81–83).
Omiecinski, E. (2003). Alternative interest measures for mining asso-ciations in databases. IEEE Transactions on Knowledge andData Engineering, 15(1), 57–69. http://computer.org/tkde/tk2003/k0057abs.htm.
Pires, P.F., Benevides, M.R.F., Mattoso, M. (2002). Building reli-able Web services compositions. In Proceedings of NODe 2002Web and database-related workshops on Web, Web-services, anddatabase systems (pp. 59–72). http://link.springer.de/link/service/series/0558/bibs/2593/25930059.htm.
Plasse, M., Niang, N., Saporta, G., Villeminot, A., Leblond, L. (2007).Combined use of association rules mining and clustering methodsto find relevant links between binary rare attributes in a large dataset. Computational Statistics & Data Analysis, 52(1), 596–613.doi:10.1016/j.csda.2007.02.020.
Rao, J., & Su, X. (2004). A survey of automated Web service com-position methods. In Proceedings of 1st international workshopsemantic web services and web process composition (pp. 43–54).doi:10.1007/978-3-540-30581-1 5.
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., Riedl, J.(1994). GroupLens: an open architecture for collaborative fil-tering of netnews. In Proceedings of 1994 ACM confer-ence on computer supported cooperative work (pp. 175–186).doi:10.1145/192844.192905.
Rich, E. (1979). User modeling via stereotypes. Cognitive Science,3(4), 329–354.
Rocco, D., Caverlee, J., Liu, L., Critchlow, T. (2005). Domain-specificWeb service discovery with service class descriptions. In Proceed-ings of 3rd IEEE international conference on Web services (pp.481–488). doi:10.1109/ICWS.2005.49.
Rong, W., Liu, K., Liang, L. (2008). Association rule based con-text modeling for Web service discovery. In Proceedings of5th IEEE international conference on enterprise computing, E-commerce and E-services (pp. 299–304). doi:10.1109/CECan-dEEE.2008.137.
Schein, A.I., Popescul, A., Ungar, L.H., Pennock, D.M. (2002).Methods and metrics for cold-start recommendations. In Proceed-ings of the 25th annual international ACM SIGIR conference onresearch and development in information retrieval (pp. 253–260).doi:10.1145/564376.564421.
Schoop, M., de Moor, A., Dietz, J.L.G. (2006). The pragmaticWeb: a manifesto. Communication of the ACM, 49(5), 75–76.doi:10.1145/1125979.
Shani, G., Heckerman, D., Brafman, R.I. (2005). An MDP-based rec-ommender system. Journal of Machine Learning Research, 6,1265–1295. http://www.jmlr.org/papers/v6/shani05a.html.
Shao, L., Zhang, J., Wei, Y., Zhao, J., Xie, B., Mei, H. (2007). Person-alized QoS prediction for Web services via collaborative filtering.In Proceedings of 5th IEEE international conference on Webservices (pp. 439–446). doi:10.1109/ICWS.2007.140.
Sheng, Q.Z., Benatallah, B., Maamar, Z., Dumas, M., Ngu, A.H.H.(2004). Enabling personalized composition and adaptive pro-visioning of Web services. In Proceedings of 16th interna-tional conference on advanced information systems engineer-ing (pp. 322–337). http://springerlink.metapress.com/openurl.asp?genre=article&issn=0302-9743&volume=3084&spage=322.
Skoutas, D., Alrifai, M., Nejdl, W. (2010). Re-ranking Web ser-vice search results under diverse user preferences. In Proceedingsof 4th international workshop on personalized access, profilemanagement, and context awareness in databases.
Sreenath, R.M., & Singh, M.P. (2004). Agent-based ser-vice selection. Journal of Web Semantics, 1(3), 261–279.doi:10.1016/j.websem.2003.11.006.
Tamani, E., & Evripidou, P. (2007). A pragmatic methodol-ogy to Web service discovery. In Proceedings of 5th IEEEinternational conference on Web services (pp. 1168–1171).doi:10.1109/ICWS.2007.13.
Tang, R., & Zou, Y. (2010). An approach for mining Web servicecomposition patterns from execution logs. In Proceedings of 8thIEEE international conference on web services (pp. 678–679).doi:10.1109/ICWS.2010.35.
Teevan, J., Dumais, S.T., Horvitz, E. (2005). Personalizing searchvia automated analysis of interests and activities. In Proceed-ings of 28th annual international acm sigir conference onresearch and development in information retrieval (pp. 449–456).doi:10.1145/1076034.1076111.
Verheecke, B., Cibran, M.A., Vanderperren, W., Suvee, D., Jonckers,V. (2004). AOP for dynamic configuration and management ofWeb services. International Journal of Web Services Research,1(3), 25–41.
Verma, K., Akkiraju, R., Goodwin, R., Doshi, P., Lee, J. (2004). Onaccommodating inter service dependencies in Web process flowcomposition. In Proceedings of 2004 AAAI spring symposium (pp.37–43).
Yang, W.-S., Dia, J.-B., Cheng, H.-C., Lin, H.-T. (2006). Miningsocial networks for targeted advertising. In Proceedings of 39thHawaii international international conference on systems science.doi:10.1109/HICSS.2006.272.
Zheng, Z., Ma, H., Lyu, M.R., King, I. (2009). WSRec: a collaborativefiltering based Web service recommender system. In Proceedingsof 7th IEEE international conference on Web services (pp. 437–444). doi:10.1109/ICWS.2009.30.
Wenge Rong is an assistant professor at Beihang University, China.He received his PhD from University of Reading, UK, in 2010;MSc from Queen Mary College, UK, in 2003; and BSc from Nan-jing University of Science and Technology, China, in 1996. He hasmany years of working experience as a senior software engineer innumerous research projects and commercial software products. Hisarea of research covers service computing, enterprise modelling, andinformation management.
Baolin Peng received his BSc in Computer Science from Yantai Uni-versity in 2012. He is currently a MSc student in Beihang University.His research interests include machine learning and natural languageprocessing, information retrieval and etc.
Yuanxin Ouyang is an associate professor at Beihang University,China. She received her PhD, and BSc from Beihang University in2005, 1997, respectively. Her area of research covers recommendationsystem, data mining, social networks and service computing.
Kecheng Liu is a professor of applied informatics and director of theInformatics Research Centre, University of Reading, UK. His researchwork includes information systems analysis and design, informationmanagement, e-business systems design, and intelligent and pervasiveworking and living environments. He has published one authored and11 edited books, and 180 papers.

Inf Syst Front
Zhang Xiong is a professor in School of Computer Science of Engi-neering of Beihang University and director of the Advanced ComputerApplication Research Engineering Center of National EducationalMinistry of China. He has published over 100 referred papers in inter
national journals and conference proceedings and won a National Sci-ence and Technology Progress Award. His research interests and pub-lications span from smart cities, knowledge management, informationsystems, intelligent transportation systems and etc.