collaboration in the physical internet
TRANSCRIPT

Collaboration in the Physical Internet:
An exploration of third party data sharing enabled by
Enterprise Information Systems
M.J. Kreijkes
MSc Thesis presented for the degree:
DDM Technology & Operations Management (2018-2020)
9 December 2019
Lead supervisor: Dr. N.B. Szirbik
Second supervisor: Dr. A. Small
University of Groningen - Newcastle University – Deloitte NL
S2754061 - 180626986

1

2
Acknowledgements
This research was conducted to finish the MSc degrees of Technology & Operations
Management at the University of Groningen, and Operations & Supply Chain
Management at Newcastle University Business School. First, I would like to
acknowledge my two university supervisors, Dr. Nick Szirbik and Dr. Adrian Small.
Their guidance, support and feedback helped me a lot to improve the quality of
the research and keep me motivated. Furthermore, I would like to thank Marcel
Bakker for his excellent supervision and help to get me settled at the company,
arranging interviews and improving the research, also from a practical
perspective. Lastly, many thanks to all that were involved in another way in this
research: academics, interviewees, validation participants, colleagues, fellow
students, family and friends; without your input, finalizing this research would not
have been possible.

3
Abstract
Purpose: The logistics industry is too inefficient and inherently unsustainable due
to its polluting nature. A proposed solution is the Physical Internet, but there are
major challenges on how the envisaged increase in collaboration and data sharing
can be ensured. To find a solution, data sharing systems that are currently in place
have been examined and reverse engineered, revealing the critical requirements
for data sharing and future Enterprise Information Systems. Based on these
requirements, preliminary functional architectures of the Third Party Model are
designed.
Methodology: Design Science Research is carried out to design a solution to the
problem of collaboration and data sharing. Data is collected by conducting multiple
case studies including observations and semi-structured interviews with industry
experts. A validation workshop is conducted to evaluate the critical requirements.
Findings: The findings indicate that data sharing could potentially be enhanced
by using a third party mediator. In such a system, stakeholders require
transparency, while power and outputs are evenly distributed and not centrally
located. In addition, the system should be open to access and easy to implement,
but restricted by specific protocols that determine data and technology standards.
Originality/contribution: This is one of the first studies in PI that establishes
critical requirements and develops a Third Party Model for collaboration and data
sharing. The findings can be used in practice to develop new data sharing systems,
and by academics for future research towards data sharing in a PI context.
Keywords: Collaboration, Data Sharing, Design Science Research, Digital Supply
Chain, Enterprise Information Systems (EIS), Information Sharing, Information
Technology (IT), Logistics, Physical Internet, Third Party Model.
Word count: 14900 (excl. references, appendices)

4
Table of Contents
1 Introduction..................................................................................... 8
2 Theoretical background.................................................................. 10
2.1 Logistics......................................................................................... 10
2.2 Physical Internet ............................................................................. 13
2.3 Enterprise Information Systems ........................................................ 22
3 Research questions ........................................................................ 25
4 Methodology .................................................................................. 26
4.1 Research method ............................................................................ 26
4.2 Data collection ................................................................................ 29
4.3 Validation method ........................................................................... 30
4.4 Ethics and Risks .............................................................................. 30
5 Analysis of case studies ................................................................. 31
5.1 Methods of collaboration and data sharing .......................................... 31
5.2 Types of data shared ....................................................................... 33
5.3 Reasons for data sharing .................................................................. 34
5.4 Challenges in data sharing ................................................................ 36
5.5 Critical requirements ....................................................................... 37
6 Design ........................................................................................... 42
6.1 Third party model ............................................................................ 42
6.2 Operational concept ......................................................................... 44
6.3 Functional architectures ................................................................... 46
7 Validation ...................................................................................... 53
7.1 Validation of critical requirements ...................................................... 53

5
8 Discussion...................................................................................... 57
8.1 Discussion of findings ...................................................................... 57
8.2 Implications for theory ..................................................................... 59
8.3 Implications for practice ................................................................... 60
8.4 Limitations and future research directions ........................................... 60
9 Conclusion ..................................................................................... 62
10 References .................................................................................. 63
11 Appendices .................................................................................. 70
Appendix A – PESTLE analysis logistics industry ........................................ 70
Appendix B – Data collection .................................................................. 71
Appendix C - Code trees ........................................................................ 80

6
List of tables and figures
Table 1 - Strategic research directions in logistics (Speranza, 2018) ............... 11
Table 2 - Unsustainability symptoms and their impact (Montreuil, 2011) ......... 12
Table 3 - Four challenge areas for future EIS (El Kadiri et al., 2016) ............... 24
Table 4 - DSR artifact levels (Gregor & Hevner, 2013) .................................. 27
Table 5 - Strategies for enhancing research rigor (Devers, 1999) ................... 30
Table 6 - Methods of data sharing used by case companies ........................... 32
Table 7 - Types of sensitive data ............................................................... 33
Table 8 - Types of non-sensitive data ......................................................... 34
Table 9 - Characteristics of sound requirements (Buede & Miller, 2016) .......... 37
Figure 1 - Overview of information flows in the envisaged PI system ............... 9
Figure 2 - Interconnected supply network (Ballot et al., 2012) ....................... 14
Figure 3 - Container modularity (Montreuil, 2011)........................................ 15
Figure 4 – Example of efficient transport planning with collaboration .............. 21
Figure 5 - DSR cycle (based on Wieringa, 2009) .......................................... 28
Figure 6 - International Data Space architecture (Otto et al., 2016) ............... 42
Figure 7 – Potential design of a Third Party Model (TPM) ............................... 44
Figure 8 - Functional Architecture A-2 ........................................................ 46
Figure 9 - Interaction diagram A-2 ............................................................. 47
Figure 10 - Functional Architecture A-1....................................................... 48
Figure 11 - Interaction diagram A-1 ........................................................... 48
Figure 12 - Functional Architecture A.0 (alternative 1) .................................. 49
Figure 13 - Interaction diagram A.0 (alternative 1) ...................................... 50
Figure 14 - Functional Architecture A.0 (alternative 2) .................................. 51
Figure 15 - Interaction diagram A.0 (alternative 2) ...................................... 51
Figure 16 - Functional Architecture A.0 (alternative 3) .................................. 52
Figure 17 - Interaction diagram A.0 (alternative 3) ...................................... 52

7
List of abbreviations
ADOM Automation, Decentralization, Openness, Modularity
AI Artificial Intelligence
ALICE Alliance for Logistics Innovation through Collaboration in Europe
API Application Programming Interface
ASN Advanced Shipping Notification
CRM Customer Relationships Management
CSCMP Council of Supply Chain Management Professionals
EDI Electronic Data Interchange
EIS Enterprise Information System
ERP Enterprise Resource Planning
IoT Internet of Things
IS Information System
KPI Key Performance Indicator
LSP Logistics Service Provider
MAS Multi-Agent System
OLSCM Operations, Logistics and Supply Chain Management
PI Physical Internet
RFID Radio-Frequency Identification
SWOT Strengths, Weaknesses, Opportunities, Threats
TBL Triple Bottom Line (people, planet, profit)
TPM Third Party Model

8
1 Introduction
Every year in Europe, around €160 billion is lost due to low capacity utilization of
trucks and containers only, with tremendous unnecessary amounts of CO2
emissions as a result (CSCMP, 2015). As sustainability plays an increasingly
important role in the world, it is essential to enhance logistics processes. The
Physical Internet (hereafter PI) is a relatively new but promising concept, aiming
to improve efficiency and sustainability in logistics. It provides organizations with
the potential to radically decrease triple bottom line (TBL) issues e.g. transport
costs, CO2 emissions and truckdriver turnover. This can be achieved by combining
logistics networks, using smart modular containers, and an increased sharing of
information. Building on the four PI pillars of Automation, Decentralization,
Openness and Modularity (Montreuil et al., 2013), PI could be the missing link in
transforming towards a sustainable supply chain (Montreuil, 2011). The founding
father of the PI concept is Benoit Montreuil, who first described the concept in
2009 in his so-called Physical Internet Manifesto. In one of his seminal papers, PI
is defined as “an open global logistics system founded on physical, digital, and
operational interconnectivity, through encapsulation, interfaces and protocols”
(Montreuil et al., 2013). In combination with more recent research by several
academics (Ballot et al., 2014; Crainic & Montreuil, 2016; Treiblmaier, 2019), a
group of papers can be identified to be of paramount importance in this field.
These will be discussed thoroughly in the theoretical background section.
Due to the recency of this concept there are many gaps in several research areas
that need to be filled. One of the research roadmaps identified by European
Technology Platform ALICE is collaboration through Information Systems. In the
Physical Internet, every container acts autonomously through a digital twin, which
is connected to the internet. The Enterprise Information Systems (EIS) of the
expected stakeholders in the PI, also act as agents or digital twins. In the future
PI network, the digital twins of the millions of PI containers automatically have to
communicate all necessary information with the EIS of all agents (visualized in
figure 1). As each agent needs particular information and uses multiple,
distinctive, often monolithic EIS, the interplay can become very complex. With the
expected exponential increase in data sharing, issues of collaboration and trust
between stakeholders become apparent.

9
For the concept to become fully operational, which is envisioned to take place
between 2030-2040, developments in Enterprise Information Systems (EIS)
based on the four PI pillars will play a paramount role. What these developments
and challenges are, remains undetermined in literature. It is sure that the
tremendous increase in data/information creates additional challenges. This thesis
therefore addresses the question: how can data be shared effectively in the
Physical Internet, enabled by Enterprise Information Systems? A set of critical
requirements will be created to assist researchers and practitioners. Based on
these findings, a preliminary functional architecture to improve data sharing with
the use of a third party mediator will be designed and evaluated. Concluding, this
thesis will 1) provide exploratory research in the field of Enterprise Information
Systems and data sharing; 2) attempt to contribute to PI research by identifying
critical requirements and challenges for data sharing and future EIS and 3) provide
openings for future research in PI and EIS.
The remainder of this paper will contain a review of current (non-)academic
literature on logistics, PI and EIS, an explanation of the methodology used, the
findings that were obtained, and a thorough evaluation and discussion of these
results. Finally, the conclusion will summarize the main findings of this research.
Figure 1 - Overview of information flows in the envisaged PI system

10
2 Theoretical background
To describe the setting of the research, this chapter first examines recent
developments and challenges in logistics through a review of (academic) literature
and interviews with industry experts for practical insights. Subsequently, although
PI is a rather new concept, several papers provide great value in this field and will
be reviewed to build a greater understanding of what PI entails. After this, the
focus will be on the area of Enterprise Information Systems and data sharing,
which are vastly grounded in literature but will also be complemented with expert
interviews. Following the review of these fields, gaps in literature are identified,
based on which the research question and sub-questions are constructed.
2.1 Logistics
As PI is expected to exist within a logistics context, the present situation in
logistics should be examined first through an industry analysis. Based on this
analysis, challenges are identified, followed by the proposed solution to tackle
these challenges.
‘Logistics’ as a concept has countless definitions. The Council of Supply Chain
Management Professionals best describes it in context of this research as “The
process of planning, implementing, and controlling procedures for the efficient and
effective transportation and storage of goods including services, and related
information from the point of origin to the point of consumption for the purpose
of conforming to customer requirements. This definition includes inbound,
outbound, internal, and external movements” (CSCMP, 2013). Logistics does not
only relate to the actual transportation of goods as often assumed, but also
incorporates all other activities needed to ensure an optimal movement of goods
for the company or entire supply chain. It evolved from simply transporting goods
towards a strategy to generate value for the entire supply chain to end customers.

11
2.1.1. Industry analysis
Nowadays, logistics (sometimes called ‘transportation & logistics) is one of the
largest global industries, with a total worth over 4730 Billion USD (€4251 Billion)
(IMARC Group, 2018). It comprises almost all types of industries and is often
subdivided into segments such as land, water and air. With the increase in
globalization, the market became increasingly dominated by global logistics
corporations like FedEx, DHL, UPS, DSV and Maersk. More recently, large
technology companies like Amazon, Google and Alibaba are increasingly investing
in this industry, making it exceptionally competitive. Due to societal and
technological developments, the logistics industry is rapidly changing (Zijm et al.,
2019). Under the term ‘Industry 4.0’, developments in multiple industries are
made to increase efficiency, sustainability and customer satisfaction. New
technologies like Internet of Things (IoT) and Artificial Intelligence (AI) are
adopted by more and more companies (EFT & JDA, 2019). Furthermore, different
modes of transport like ships, planes, rail and road are combined to a greater
extent for intermodality advantages. Next to these technological developments,
there are also strategic developments. Speranza (2018) discusses three strategic
research directions: systemic, collaborative and dynamic directions (see table 1
below). Academics are increasingly focusing on integrating technological and
strategic developments. The Physical Internet addresses all three directions.
Systemic “Better solutions to problems can be identified when broader
parts of the supply chain are jointly modeled and optimized”.
Collaborative “A tool that enables integration and global optimization of a
supply chain”.
Dynamic “Systems should be more reactive to changes and provide more
effective responses”.
Table 1 - Strategic research directions in logistics (based on Speranza, 2018)
There is also a negative side to the large size of the industry. The logistics industry
extremely pollutes air, water and land, impacting the climate and biodiversity,
while creating road congestion and noise. Because of this, the logistics industry is
inherently unsustainable, so the term ‘sustainability’ should be used with caution.
Appendix A summarizes the industry assessment by means of a PESTLE analysis,
which fits best to this industry compared to SWOT or Porter’s Five Forces.

12
2.1.2. Challenges
Despite the increasing focus on achieving higher efficiency and sustainability,
there remains a huge potential to further develop this industry. In 2008, the
efficacy rate was estimated to be less than 10% (Ballot & Fontane, 2008). There
are many other wastes in the current logistics industry, as summarized by
Montreuil in table 2. This table also indicates what type of waste it entails, in
relation to the Triple Bottom Line (TBL) of people, planet and profit. These wastes
are strengthened by the amount of uncertainty in the current logistics industry,
caused by many factors e.g. new regulations, technologies, public pressure
regarding climate change, depletion of natural resources, and as mentioned by
several interviewees, the rise of e-commerce.
Symptoms People Planet Profit
1. We are shipping air and packaging X X
2. Empty travel is the norm rather than the exception X X
3. Truckers have become the modern cowboys X X
4. Products mostly sit idle, stored where unneeded, still
often unavailable
X X
5. Production and storage facilities are poorly used X X
6. So many products are never sold, never used X X X
7. Products do not reach those who need them the
most
X X
8. Products unnecessarily move X X
9. Fast & reliable intermodal transport is still a dream X X X
10. Getting products in/out of cities is a nightmare X X X
11. Networks are neither secure nor robust X X
12. Smart automation & technology are hard to justify X X
13. Innovation is strangled X X X
Table 2 - Unsustainability symptoms and their impact (Montreuil, 2011)
Over the past decades, an increasing focus was on integrating the global supply
chain, coupled with developments in the digital supply chain. Most of these,
however, only address one or a couple of symptoms. As a possible, long-term
solution to all the increasingly demanding challenges described above, Montreuil
proposed the Physical Internet.

13
2.2 Physical Internet
Apart from a description of the concept in the Physical Internet Manifesto in 2009,
PI first occurred in academic literature in 2010 (Montreuil et al., 2010). Therefore,
no exhaustive body of papers is available to consult yet compared to other
research areas in logistics, supply chain and operations management. Resultingly,
most of the research in this field (44%) is conceptual/theoretical (Treiblmaier et
al., 2016).
The Physical Internet is an analogy from the Digital Internet, which had similar
goals, challenges and requirements several decades ago. PI is described as “an
open global logistics system founded on physical, digital, and operational
interconnectivity, through encapsulation, interfaces and protocols” (Montreuil et
al., 2013) and is primarily focusing on shipments larger than standard parcel sizes
(UPS, DHL etc) till standard container sizes (20/40 FT). It is expected to bring
radical (digital) innovations to the current logistics network which improve
efficiency and sustainability. This can be achieved by "transforming the way
physical objects are handled, moved, stored, realized, supplied and used"
(Montreuil, 2013). In other words, with the use of digital innovations, new
technologies, as well as smart modular containers (PI-containers) and an
increased sharing of information, PI can come into existence. This requires
warehouse sharing, intermodal transport and increasing collaboration between
stakeholders to create an open supply web (sharing of supply networks).
To achieve collaboration, trust should be established between stakeholders to
facilitate the increasing need in data sharing. Figure 2 below visualizes a simplified
version of the way PI can transform logistics. If the supply networks of company
1 and company 2 in the current logistics system would operate independently, the
result would be the closed, complex and tangled supply web at the bottom left.
This can be transformed to the open, integrated supply network in the bottom
right, based on the PI principles. The advantages are clearly visible, e.g. routing
can be optimized, to increase efficiency. A simulation study in France with
Carrefour and Casino confirmed the expected advantages, where 50% of goods
transport shifts from road to rail, cutting costs by around 32% and reducing
greenhouse gas emissions by 60% (Ballot et al., 2014).

14
Figure 2 - Interconnected supply network (Ballot et al., 2012)
2.2.1 Physical Internet pillars
It is evident that PI is a global, overarching and integrating framework, which
consists of many elements that should interconnect with each other. Most
importantly, the PI is expected to be built on four foundational pillars that have
shortly been mentioned in the introduction: Automation, Decentralization,
Openness and Modularity, often abbreviated as ADOM. Combining these primary
requirements is what makes PI different from current best practices in logistics.
Based on these pillars, the requirements of future EIS and data sharing will have
to be constructed.
Automation concerns performing a task with minimal human support. In the ideal
scenario, the container will automatically determine its most efficient route, truck
(un)loading will be done automatically as much as technically possible, as well as
information flows between agents via the container. This pillar is perceived to have
the least challenges for implementation, as automation is a well-known concept
that has been invested in since decades. However, automation can create
resistance among lower skilled workforce, as it tends to take over their jobs. This
is somewhat true, although a recent study found out that automation is estimated
to create more jobs than they replace in the next four years (58 million), only in
different fields (McKinsey Global Institute, 2017; World Economic Forum, 2018).

15
Decentralization indicates that there should not be a central authority governing
the system. This is of paramount importance to provide autonomy to the
containers and protect data in the PI network. Despite the advantages, complete
decentralization could also create challenges when all stakeholders pursue their
own goals, potentially leading to congestion at specific important hubs or areas.
Recent papers discuss whether a certain degree of centralization might be more
beneficial to the envisaged PI system (Ambra et al., 2019). Having multiple third
parties with an advisory role could help mitigating this risk.
The PI network is transparent and open for everyone to join: from suppliers,
container owners, transportation companies, hubs to customers, independent of
their sizes and without any limits. Openness requires transparency and sharing
of information. With more data available, supply chains can plan more efficiently,
creating advantages to all stakeholders. Developments have to be made to ensure
only required stakeholders have access to the information/data they need.
Another efficiency related advantage of PI is modularity: shipping and combining
multiple (smaller) containers that are able to interlock with each other and the
mode of transport by latching and the use of intelligent technology. This has the
potential to radically improve the container space utilization rate, which is
currently too low as described by Montreuil, caused by high weight, volume or
value. Figure 3 below provides a visual representation of how multiple containers
of varying sizes can be combined into one shipping unit. A challenge in this area
can be to determine the right size of the required container for a specific shipment.
Figure 3 - Container modularity (Montreuil, 2011)

16
2.2.2 Main elements in the Physical Internet
The Physical Internet consists of several important elements, which will all be
described below. All elements have physical (actors) as well as virtual entities
(agents), which communicate with each other through software (EIS). In terms of
software, the Physical Internet can be described as a decentralized multi-agent
system (MAS). In the field of Computer Science, MAS is defined as “a system
composed of multiple interacting computing elements, known as agents. Agents
are computer systems that have two important capabilities: autonomous actions
and interacting with others.” (Wooldridge, 2009). These agents act towards
specific objectives, while observing their environment using sensors and
intelligence (AI) (Weiss, 2013). In the PI, these agents communicate with each
other and with the EIS of the main actors. However, data sharing issues like
privacy, confidentiality and security become even more apparent in a
decentralized multi-agent system, as there is a lack of control. Companies prefer
to have a certain degree of sovereignty over their data: the ability to keep control
over who has access to their data and when. This creates a trade-off: while the
advantages of data sharing are evident, many companies still decide not to share
because of the uncertainties regarding security.
PI Container
In the current logistics systems, shipping containers are mostly very static and do
not perform any functions other than encapsulating and protecting the shipped
goods. Contrastingly, the future PI container is regarded to become the most
important agent in the envisaged system as it will have autonomy to make its own
decisions for the container owner. Each container will have an agent, a digital twin
existing in the cloud, that will make decisions on routes, transportation modes and
costs easier. Data flows between other elements are expected to go through the
PI container. The most considerable challenge is that the agent of the container
has to communicate with agents of the EIS of all other stakeholders automatically,
to ensure efficiency. As there are countless different agents and EIS,
interoperability and integration issues become apparent.

17
Suppliers
Nowadays, suppliers mostly have a responsible role in making sure all goods of
required quality are made ready for shipment correctly. An important task is to
provide the LSPs and customers with a large amount of information about units,
dimensions, type of goods shipped and more, possibly by providing an Advanced
Shipping Notification (ASN) to the LSP and customer. In the PI system, it is
important that the supplier still provides this information, which is expected to be
communicated through the smart PI container to the other agents that require it.
Suppliers are seen as the driving force behind PI developments, as they can
indirectly force their clients (LSPs) to change (Meyer & Hartmann, 2019). The
main advantage to suppliers is that the PI opens additional markets, as they can
offer their products to a whole new range of customers.
Customers
On the receiving end of the shipments are the customers. Currently, customers
activate the shipment process by placing an order. Next to that, there are not
many tasks other than checking whether the container arrives on time and
planning delivery with transporters. This is not expected to be different in a PI
system. The main advantages that PI can offer are more automation and a larger
market, as customers should be able to order everything, from everywhere, at
every moment.
Logistics Service Providers (LSPs)
LSPs have one of the most important roles in the current system, being in contact
with almost every other agent. Information about shipments has to be provided
to both supplier and customer, containers should be arranged, hubs and carriers
should be contacted for connecting transport, but most of all, goods have to be
moved. Most of these activities are expected to be performed by the PI container
automatically in the future PI network, such that the transporter can purely focus
and specialize on the physical transport of the modular containers. The largest
expected challenge for LSPs is the disruption from their traditional business model
towards the envisaged shared network of the Physical Internet.

18
Intermodal hubs
Hubs are the places where goods are changed from one transportation unit to the
other. This can be done at seaports, airports, railway stations or warehouses.
When a shipment uses more than one type of transport, it is called intermodal.
For example, if goods arrive in a seaport and are transported to the hinterland by
train or truck. Intermodal transport is expected to increase customer service,
while decreasing lead times and shipment costs (Cambra-Fierro & Ruiz-Benitez,
2009). Currently, these hubs play a large role already and in the future PI network,
their role will be even more important due to the expected increase in containers
and use of intermodality. The main difference is that several hubs such as
warehouses should become shared hubs with other stakeholders, instead of being
privately used. In this way, the benefits of a shared PI network as described in
figure 2 can become operational. This requires a radical change in the business
model for warehouse owners.
Container owners
Container owners play a fairly passive role in the current logistics system. Shipping
containers can be owned by LSPs, but also by other companies that lease or rent
out these containers to make a profit, but are not involved in any transport related
activities. In the PI, the primary objective will not be different (making profit), but
it is expected that the amount of container owners will increase. This is caused by
the increase in smaller containers of various sizes, which are easier to purchase
and own, as they operate themselves guided by basic instructions from the
owners. Furthermore, owners will be able to specify certain tasks to their
containers. Thus, one of the main functions of the PI container is to maximize
profit (or any other target) for its owner by operating as efficiently as possible.
Third party mediator
A potential new stakeholder to ensure collaboration and effective data sharing can
be a third party mediator. This mediator (or multiple mediators) should be able to
improve trust and collaboration between stakeholders, to achieve a higher degree
of openness. Data providers can provide their data to these mediators, who then

19
distribute the required information to customers that need it, but only with
approval of the supplier. In this way, suppliers keep sovereignty over their data.
Furthermore, the mediator can perform an optimization of the acquired data and
provides this optimized advice to the stakeholders. Chapter 6 describes the
functions of the mediator in more detail.
2.2.3 Research avenues for the Physical Internet
The previous sections indicated several challenges to logistics and PI, as well as
the most important elements. To speed up research and developments, the EU
set up a European Technology Platform (ETP) for PI: ALICE (Alliance for Logistics
Innovation through Collaboration in Europe), as part of the Innovation Union
initiative (ETP-ALICE, 2019). The ALICE ETP identified five roadmaps for future PI
research: information systems; sustainable, safe and secure supply chains;
corridors, hubs and synchromodality; global supply network coordination and
collaboration; and urban logistics. All roadmaps were first envisaged to be
completed around 2050, however more recently the target for PI was set to 2030-
2040, while aiming for entirely carbon neutral, zero emission supply chains around
2050 (Ballot, 2018). As supply chain development in recent years is mainly driven
by innovations in information systems (Treiblmaier, 2019), there is an increasing
need to advance research in this area.
Comparable to most traditional supply chains, a PI network contains three types
of flows: physical, information, and financial. The largest share of PI research
concentrates primarily on the first type: the flow of physical goods/containers and
design of systems for specific areas (e.g. last mile) or industries (e.g. fresh food).
Less focus is on the flow of financials or information, preferably through Enterprise
Information Systems, which are prerequisites to actually perform the physical
flows. The main challenge in EIS is that researchers regard current EIS as being
too rigid for interoperability (Zacharewicz et al., 2017) needed in PI to share
information. However, no research directly addresses the issue on how the
decentralized multi-agent system of PI interacts with the often monolithic
regarded EIS systems currently in use, so interoperability will remain a huge
barrier to overcome.

20
Collaboration
Next to interoperability of EIS, collaboration between stakeholders is regarded as
an essential requirement to establish a shared network. There is extensive
research on current collaboration networks, and several examples might clarify
what the advantages are. In general, the main reason for collaboration is to
improve performance in an increasingly dynamic market (Cao & Zhang, 2011).
An example could be a retailer that collaborates with his suppliers, where the
retailer provides his demand forecast to the suppliers. With this forecast, suppliers
can more effectively plan their production and deployment of staff, in order to
provide better service to the retailer. They can offer shorter delivery times which
provides an opportunity to decrease warehouse costs, as both parties need to
keep less items in stock. Another potential improvement is the quality of products.
In many industries, stakeholders collaborate by combining R&D resources to
create innovative solutions, becoming more competitive in their market. Large
global logistics service providers also often collaborate with smaller local
companies to improve their coverage and increase flexibility. They can use more
of the capacity of their local partner during periods when demand is higher, and
use their own capacity when demand is lower.
The general benefits of collaboration in and across current supply chains, often
expressed in KPIs, are evident and well researched. But why is collaboration
expected to be even more advantageous in the future PI system? It remains
difficult to validate as the system is not in place yet, but there are several future
visions that describe the importance of collaboration.
Theoretically, in a shared PI network, transport planning and routing can be done
more efficiently. When actors collaborate and share their data with the network,
it is more clear to the PI containers who has capacity on which route or not. Based
on that information, containers can make better decisions on which type of
transportation to take, which route fits best, or which alternative route can be
chosen. Take three containers that should go from location A to B for example.
Figure 4 below represents the situation. The most optimal route seems to go via
barge to location B directly. However, the two barges that go to this destination
are fully booked. There is another barge which has spare capacity, but goes to
destination C. This is not far from destination B, but needs additional truck

21
transport to get there. By using the available information, the PI can see whether
a truck will be able to take the containers from C to B. In this way, one of the
goals of PI can be achieved: optimizing capacity utilization. This can only be done
when collaboration between different actors is in place.
Figure 4 – Example of efficient transport planning with collaboration
Next to capacity optimization, collaboration is also required to effectively share
resources. Sharing resources is expected to make the PI a thriving system
(Montreuil et al., 2013), and radically improves flexibility. Furtado & Frayret
(2014) identify that infrastructures such as transportation hubs, warehouses,
hauling capacity and trailers should be shared to accommodate the flow of goods
in the future PI system. This has several advantages. Distances between hubs
become smaller, goods can be stored in warehouses closer to where they are
needed, or orders for the same customer can be bundled more effectively, all
reducing lead times.
A significant challenge in collaboration is how the expected increase in
data/information sharing between stakeholders can be designed properly, while
complying to competition laws. Currently, most information is shared from point-
to-point, e.g. supplier to customer or LSP. In a PI network, data should be shared
with all stakeholders to gain interconnectivity benefits described above, creating
a complex situation where data privacy and security can become a large issue. A
novel business model architecture that uses a third party company as mediator
was proposed by several academics (Dalmolen et al., 2018; 2019a) to improve
data security and therefore collaboration, but this was not examined in a specific
PI context. The lack of academic knowledge and paramount importance for further
developments to handle the expected ‘data explosion’ in the PI indicates that a
gap exists, and research in the area of EIS and data sharing should be conducted.

22
2.3 Enterprise Information Systems
Before exploring the third party data sharing model, it is evident to define the
concept of EIS, and why these are preferred for sharing information. Enterprise
Information Systems can be defined as “software systems for business
management, encompassing modules supporting organizational functional areas
such as planning, manufacturing, sales, marketing, distribution, accounting,
financial, human resources management, project management, inventory
management, service and maintenance, transportation and e-business” (Rashid
et al., 2002). These help to control the performance of business processes
(O’Brien, 2003). EIS generally comprise six particular types of systems: Enterprise
Resource Planning (ERP), Supply Chain Management (SCM), Manufacturing
Execution Systems (MES), Customer Relationship Management (CRM), Product
Lifecycle Management (PLM) and Business Intelligence (BI) (Romero & Vernadat,
2016). These commonly used modules can help organizations to achieve high
operational efficiency, significant cost savings, and thus maximization of profit
(Olson & Kesharwani, 2009). Furthermore, these can help to increase the product
value by offering a better client service (Zacharewicz et al., 2017). ERP systems
are often seen as the backbone system, bringing many crucial improvements to
the company (El Kadiri et al., 2016) and is therefore one of the fastest growing,
most profitable areas in the software industry (Da Xu, 2011). The €75 billion
industry is largely dominated by large software companies that offer complete
packages, such as SAP, Microsoft and Oracle (Statista, 2019).
2.3.1 Data sharing
One of the main assets of EIS is the ability to share data with others. It is often
interrelated with the concept of collaboration, as one often causes the other and
vice versa. The types of logistics related data that are often shared ranges from
updates about lead times and arrival times to expected demand and planning data.
Methods of data sharing range from only face-to-face (F2F) communication
towards fully integrated Enterprise Information Systems. Data sharing can be
done vertically, so within the company (between departments) or supply chain
(with suppliers/customers), but also horizontally, which means between supply
chains (with potential competitors). Horizontal data sharing is often more

23
challenging due to potential misuse of company sensitive data. This creates a
dichotomy for many businesses: sharing sensitive information securely can prove
to be very profitable, but data leakage might cause disastrous consequences.
Next to data sharing, the concept of Big Data has gained a lot of attention in
research and practice over the past decade. Through data mining and analysis,
companies can radically improve their performance, often measured in KPIs
(McAfee et al., 2012). Because of these advantages, data is nowadays often
regarded as the most valuable resource to possess. Despite this shift towards a
data economy, many improvements can be made to improve effectiveness of data
sharing. Due to the lack of international data standards, many systems exist that
are not interoperable with each other. Ultimately, the goal for EIS is to provide an
open and interoperable system, that can be used easily by all stakeholders,
accessed anywhere and is able to communicate with other types of EIS (Panetto
et al., 2016), while companies maintain sovereignty over their data. This would
align with the general requirements of a system for the Physical Internet.
2.3.2 Best practices
To achieve this ultimate goal, companies, practitioners and academics are
continuously trying to develop and refine new functionalities. Some recent trends
are for instance cloud-based systems, advanced analytics, and Internet of All
Things (IoAT), which is an extension to the better-known Internet of Things (IoT)
(Bughin et al., 2013). Most of the developments are driven by the increasing
requirements for more data, collaboration and flexibility, to create so-called Next
Generation EIS. These next-gen EIS are expected to have several innovative
characteristics that differ from monolithic legacy systems (Panetto et al., 2016):
- Use of IoT technology
- Software-as-a-Service (SaaS)
- Use of blockchain (Distributed Ledger Technology) (Badzar, 2016)
- Interoperable with other EIS
- Able to process larger amounts of data (via 5G e.g.)
Despite the advantages of using (next-gen) EIS, companies currently share data
via many different technologies, ranging from simple e-mail and excel sheets to
more integrated Electronic Data Interchange (EDI) connections, Application

24
programming interfaces (API) or data hubs. Especially data hubs are an important
development, as data from multiple sources can be collected and analyzed
collectively. This could be from multiple departments, but also from multiple
companies, which is regarded as important requirement for PI. Recent
technological developments make it possible to consolidate data from different
types of EIS.
2.3.3 Challenges for EIS
Despite the rapid developments in the past decades, academics still identify
substantial challenges for the next-gen EIS, indicating four areas described in
table 3: (1) data value chain management; (2) context awareness; (3) interaction
and visualization; and (4) human learning (El Kadiri et al., 2016). This thesis
mainly addresses the first area, which is about allowing integration, sharing and
security of data through interoperability of systems.
Area Description
Data value chain
management
How to allow data/information analysis, mining, integration,
sharing, security through interoperability?
Context
awareness
How to offer scalability and integration capabilities between
business processes within EIS?
Interaction and
visualization
How to deliver new and intuitive ways for interacting with
EIS?
Human learning How to support development of professional competences
triggered by new scientific/technological advances?
Table 3 - Four challenge areas for future EIS (El Kadiri et al., 2016)
The next chapter will highlight the research question and sub-questions for this
research, based on the gaps found during the literature analysis.

25
3 Research questions
The review of the theoretical background above indicated several research gaps.
One of the most apparent gaps is related to Enterprise Information Systems in a
PI context. It is clear that EIS will play a paramount role, but in what way remains
ambiguous. Resulting from this, a second gap can be identified: bridging the
difference between current best practice EIS and future EIS that are able to align
with the PI requirements. It is evident that developments in EIS should be made
before PI can work properly. But most importantly, due to the expected data
explosion in a time where privacy and security become more prevalent, issues of
collaboration and data sharing are fundamental and have to be addressed first.
Based on these gaps, this thesis aims to answer the following research question:
How can data be shared effectively in the Physical Internet, enabled by
Enterprise Information Systems?
To answer this question, several sub-questions will be investigated first, through
multiple case studies and interviews. These will be examined and discussed in the
following chapters.
1. What are the current systems used for sharing data?
2. What types of data are considered to be sensitive?
3. What are the critical requirements for sharing data (or not)?
4. How can a preliminary functional architecture of the Third Party Model
(TPM) for data sharing be designed?

26
4 Methodology
This chapter describes the research method used that fits best to find an answer
to the research question(s). Subsequently, the methods of data collection and
validation will be described. For these sections, advantages and limitations will be
discussed. The final section explains about potential ethics and risk issues involved
in this research, and how these are addressed.
4.1 Research method
A first step after reviewing the existing literature is to determine what type of
research is most capable of producing knowledge to answer the research question,
based on its distinct characteristics. The characteristics of this research topic are
qualitative and exploratory, which indicates a direction towards conducting case
studies or Design Science Research (DSR). As the goal is to solve a practical
problem (data sharing and collaboration issues in/across supply chains), PI is an
envisaged concept and the research is strongly interconnected with the field of
(Enterprise) Information Systems, the choice for DSR was made. This is conducted
following the guidelines of Hevner et al. (2004) Van Aken et al. (2016) and
multiple articles by Wieringa & Heerkens (2007; 2009). Several other academics
(Holmstrom et al., 2009; Gregor & Hevner, 2013) discuss additional ways to
conduct DSR and how to produce valuable knowledge.
DSR as a research method originates from the field of Engineering and Information
Systems and only recently gained attention in the area of Supply Chain and
Operations Management. It can be described as “the creation of new knowledge
through design of novel or innovative artifacts (things or processes that have or
can have material existence) and analysis of the use and/or performance of such
artifacts along with reflection and abstraction” (Hevner & Chatterjee, 2010). This
implies that research of this type not only aims to create academic knowledge,
but also aims to solve practical, real life problems in emerging or envisaged
systems. The created knowledge is called an artifact, which can have three levels
based on their abstractness (Purao, 2002). Gregor and Hevner (2013) also add a
level of maturity to the characteristics, where maturity spurs with the development
of general theory. See table 4 below for an overview.

27
Artifact characteristic Type of contribution Artifact examples
Abstract / mature Level 3: well-
developed design
theory
General design theories
(mid-range and grand
theories)
Level 2: nascent
design theory /
knowledge as
operational principles
Constructs, methods,
models, design principles,
technological rules
Specific / less mature
Level 1: situated
implementing artifact
Instantiations (products or
implemented processes)
Table 4 - DSR artifact levels (Gregor & Hevner, 2013)
This research aims to create a level 2 artifact: design principles (also called critical
requirements, to be used in this research) to create a novel business model. It is
not uncommon for DSR research to develop design principles. Several reputable
papers that create these as an artifact are Markus et al. (2002) and Lindgren et
al. (2004) but also more recent work (Seidel et al., 2018) can be viewed as an
example. In these papers, design principles like transparency and flexibility are
often discussed among others.
In DSR, the system under analysis can be either emergent (developing from
existing systems), or envisaged (as a future vision). However, in practice
envisaged systems are often constructed in an emerging sense. As a research
guideline, Hevner created a three cycle view on how to conduct DSR (Hevner,
2007). The relevance cycle comes first and addresses context variables in the
research environment, where a problem is occurring. This is followed by the design
cycle, which builds and evaluates artifacts. Finally, the rigor cycle addresses the
issue whether the created knowledge contributes to scientific theories and
methods. Wieringa (2009) later adjusted the three cycle view into one cycle and
named it the ‘Regulative Cycle’ (or Engineering Cycle). In general, this research
cycle contains four phases: first: problem investigation; second: solution design;
third: design validation and fourth: solution implementation. However, for an
envisaged concept like PI, the cycle has to be slightly adjusted as the proposed
solution cannot be implemented yet (phase four). This adjusted cycle is visualized
in figure 5, which will be used as a guideline in this research.

28
Figure 5 - DSR cycle (based on Wieringa, 2009)
The first phase analyzes the systems that are currently in place, which might be
replaced by the PI. Here, often the challenge or problem can be identified. This
was done in section 2.1, where the state of the art in logistics was discussed and
challenges are identified. Phase two examines literature about the envisaged
system, in this case the PI, which was done in section 2.2. In the next phase, the
artifact will be designed. For this research, novel critical requirements will be
created. The final phase is about evaluating and validating the designed artifact
to ensure that the created knowledge is valuable, and the problem is relevant.
The primary advantages in conducting DSR are that generating academic
knowledge can be combined with practical, relevant problem solving, while
allowing for exploratory research. Furthermore, there are no strict guidelines in
how to conduct the research or analyze it, which improves flexibility. However,
taking such an approach also has several limitations: DSR is not as accepted yet
in some areas as a valid research method, results can be abstract and therefore
it might be difficult to test the validity and generalizability. Furthermore, not
following certain guidelines might cause researchers to lose their focus on the real
problem and the system under analysis (Kotzé et al., 2015).
2. Study envisaged system
1. Analyze existing systems
4. Design validation 3. Solution
design

29
4.2 Data collection
In DSR, there are multiple ways to collect data for the research. For qualitative
studies, common methods are case studies, literature reviews, questionnaires,
interviews, action research (observation) or focus groups. Combining several
methods is possible and can enhance the validity of the study by means of data
triangulation (Denzin & Lincoln, 2011; Carter et al., 2014).
For this research, both primary and secondary data will be used. Information is
generated by a literature review complemented with multiple semi-structured
interviews and observations during 7 case studies. It is often agreed to that the
optimal amount of case studies lies between four and ten, depending on the
information quality (Eisenhardt, 1989). Mason (2010) argues that information
becomes saturated after six case studies in qualitative studies due to the concept
of diminishing returns. This implies that more data does not necessarily mean
more information. Interviewees consist out of logistics, PI, EIS experts and other
relevant stakeholders to create a holistic overview. Cases will be selected based
on several criteria, summarized in Appendix B, table 1. An overview of
interviewees/cases can also be found in Appendix B, table 2.
To perform the research effectively, the interviews will be recorded, then
transcribed and analyzed (using analytical software, Atlas.ti), following the
guidelines from Zhang and Wildemuth (2009). This implies converting the
recording to text, based on which coding trees can be created. These indicate the
keywords per question discussed, to establish critical requirements. Participants
will receive an interview guide and have the option to fill in a consent form before
the interview, while security and anonymity of data is provided by the researcher.
Based on the critical requirements, the design will be created. Both the
requirements and design will be evaluated. An overview of the interview guide can
be found in Appendix B.

30
4.3 Validation method
To enhance the rigor of this research, several strategies of Devers (1999) will be
used in the collection of data. These strategies in table 5 improve the main
research criteria of validity (internal and external), reliability and objectivity.
Criteria Strategies
Internal validity Triangulation; search for disconfirming evidence;
subject review
External validity Have a detailed description of the study context
Reliability Data archiving; skeptical peer reviews
Objectivity Journal keeping; or a combination of strategies
above
Table 5 - Strategies for enhancing research rigor (based on Devers, 1999)
To further assure the rigor and validity of the research, the created artifact in DSR
should be evaluated (Venable et al., 2016). The artifacts to be validated are the
critical requirements. This validation stage can be conducted in multiple ways. The
preferred option is to implement the design, which is impossible as PI is yet to
come into existence. For envisioned systems, expert panels, focus groups,
workshops or additional interviews can be used to evaluate the design principles.
In this research, experts in data sharing and/or PI are consulted to assess the
relevance of the problem and quality of the findings. If the validation stage
provides additional important insights, adjustments can be made to the critical
requirements and functional architecture.
4.4 Ethics and Risks
An often overlooked part in the research process is the ethics and risks involved
in conducting research. It is important to discuss and address to ensure a safe
and harmless process. As human subjects are involved in the data collection stage
for interviews, several actions should be taken. To address the potential issues,
forms on how to prevent and handle with possible ethical problems and
risks/hazards have been completed before the data collection took place. Table 3
in appendix B shortly summarizes the actions that were taken.

31
5 Analysis of case studies
To validate the literature, create critical requirements and preliminary functional
architectures, current systems have to be analyzed first. This can be done by
observing systems that stakeholders have in place and reverse engineer these,
revealing the critical requirements that make these systems work (Szirbik, 2019).
The current systems were analyzed by conducting interviews and observations.
All case studies examined general logistics processes (related to PI), and at least
four aspects of data sharing: methods, types of data, reasons, and challenges.
These are introduced below and provide a base for developing critical
requirements (coding trees can be found in appendix B). Concludingly, this chapter
answers sub-question 1 and 2.
5.1 Methods of collaboration and data sharing
This section describes the contemporary methods that are used for sharing data
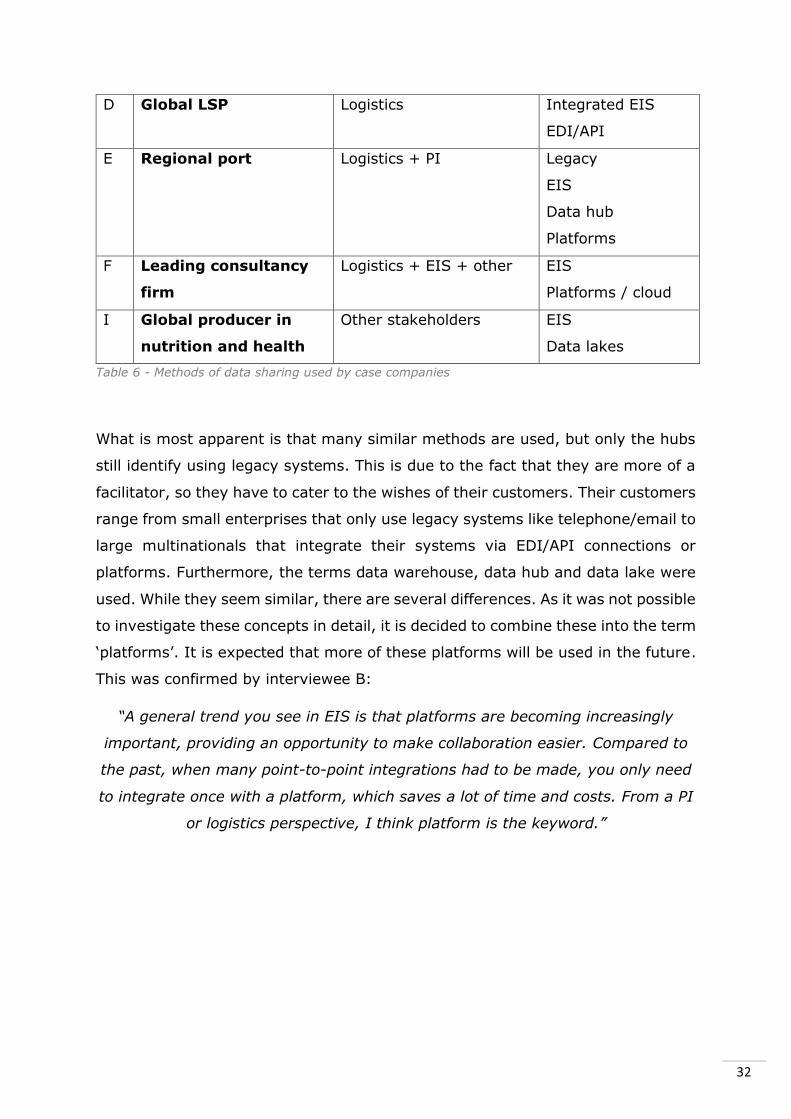
and information by case study companies. Table 6 provides an overview of the
methods that were discovered per case company. Interviewees from the
consultancy firm described contemporary methods in general based on their
thorough experience.
Nr Company Category Methods used
A Global B2B distributor
luxury goods
Other stakeholders Custom built EIS
EDI
Data warehouse
B Leading consultancy
firm
Logistics + EIS + other EIS
EDI/API
Platforms
Cloud
C Leading global port Logistics + PI Legacy
EIS
API
Platforms
32
D Global LSP Logistics Integrated EIS
EDI/API
E Regional port Logistics + PI Legacy
EIS
Data hub
Platforms
F Leading consultancy
firm
Logistics + EIS + other EIS
Platforms / cloud
I Global producer in
nutrition and health
Other stakeholders EIS
Data lakes
Table 6 - Methods of data sharing used by case companies
What is most apparent is that many similar methods are used, but only the hubs
still identify using legacy systems. This is due to the fact that they are more of a
facilitator, so they have to cater to the wishes of their customers. Their customers
range from small enterprises that only use legacy systems like telephone/email to
large multinationals that integrate their systems via EDI/API connections or
platforms. Furthermore, the terms data warehouse, data hub and data lake were
used. While they seem similar, there are several differences. As it was not possible
to investigate these concepts in detail, it is decided to combine these into the term
‘platforms’. It is expected that more of these platforms will be used in the future.
This was confirmed by interviewee B:
“A general trend you see in EIS is that platforms are becoming increasingly
important, providing an opportunity to make collaboration easier. Compared to
the past, when many point-to-point integrations had to be made, you only need
to integrate once with a platform, which saves a lot of time and costs. From a PI
or logistics perspective, I think platform is the keyword.”

33
5.2 Types of data shared
Next to understand the methods that are used for data sharing, it is essential to
know what types of data stakeholders currently share, and might share in the
future PI. The first aspect that became apparent is that companies often classify
their data. Many used a distinction between strategic and tactical data, or
potentially sensitive vs. non-sensitive data. Non-sensitive data is considered to be
widely or publicly available, whereas sensitive data is better secured and more
private. As discussed, sharing of sensitive data can bring the largest benefits, but
can be commercially sensitive caused by data leakage. However, sometimes
companies are not sure about what is potentially sensitive data or not, so they
play safe and do not share much. This is one of the challenges that will be
discussed more in depth in section 5.4.
Sensitive data
Findings from case studies indicate that most data that is shared, is potentially
sensitive. Therefore, this data is often shared only with trusted suppliers,
customers or other supply chain partners. To create a more concise overview,
sensitive data types were grouped into five categories: transport information,
customer/supplier information, sales data, planning data and financial data. Table
7 below indicates what types of data belong to which category.
Category Data types
Transport info Name of LSP / carrier; container number; truck
number plate; delivery destination; delivery times
(ETA/ETD); contents of shipment
Customer/supplier info Customer names; supplier names; preferred supplier;
quality; origin; payment terms
Sales data Order info (confirmation; picking list); customer
orders; historical demand; quantities sold
Planning data Strategy; capacity; stock; demand forecast; Research
& Developments (R&D); marketing plans
Financial data Production costs; profit margins; values; purchase
costs at suppliers; specific overhead costs
Table 7 - Types of sensitive data

34
Non-sensitive data
This type of data includes data that everybody can have access to. For instance,
the dimensions and weights of a product can be found easily, for instance on the
internet or when the product is purchased. Therefore, it makes less sense to keep
this data private. Without the addition of sensitive types of data, non-sensitive
data are not valuable to others.
Category Data types
Administrative data Public records; data required by governments;
amount of employees; vessel/container GPS
Product info Dimensions; weights; goods classification (customs);
Annual report data Income statements; cash flows; sustainable practices;
balance sheets; dividends
Table 8 - Types of non-sensitive data
5.3 Reasons for data sharing
Several reasons why companies should collaborate and share data were already
discussed in the theoretical background. However, case studies provided
additional insights about the reasons for data sharing.
Reasons for sharing data
Case companies described many reasons why they share their data with suppliers,
customers, LSPs or others. It increases their market share, they can optimize their
planning, offer a better service by for instance improving quality or delivery speed,
and there are other financial benefits. These advantages all relate to the concept
of efficiency: increasing output while decreasing inputs. Interviewee A gave the
following example:
“We could share more data with for instance LSPs, to align our demand with
their capacity. Currently, LSPs always come at a specific time with a specific
capacity that was agreed upon beforehand. If we would give them real-time
insight in our data, they could keep track of the amount of packages ready for
shipment and adjust their capacity to this, improving efficiency.”

35
Another scenario was explained by interviewee E from the regional port:
“This year, we did an analysis of arrival times of ships in our port. The research
concluded that almost a third of the ships arrived more than 2 hours too early,
or more than 2 hours too late. This has a huge impact on all stakeholders
involved. Currently, we are building a data platform to share this arrival data
more effectively through the chain.”
However, data is not only shared on their own initiative to improve efficiency.
Some case companies discussed that there are many laws and regulations from
governments that require companies to share certain types of data. This is
mostly related to customs, who need information on the value and type of
products that are shipped in/out of a country, but also passenger data that is
required for crew and others that are located on a vessel, to prevent stowaways
and other illegal activities.
Reasons for not sharing data
The main reasons for not sharing (sensitive) data are related to technological
inabilities and trust. Specifically when it comes down to horizontal data sharing,
case companies do not trust their (potential) competitors to handle their data in
a way that creates benefit for both. They are afraid of a misuse of their data, so
potential benefits are lost. Furthermore, companies fear losing control over their
data. Once their data becomes available to others or via a platform, they have
concerns about security over their data and not being able to decide who has
access to their data and when. This concept is called data sovereignty. This relates
to the next reason identified for not sharing data: most companies are resistant
to change. They feel that changing the way they conduct business can be harmful
to future profitability, so are not willing to change. This can be caused by the
culture of a company, something that can prove very difficult to change.
Interviewee E identified resistance as one of the most challenging barriers towards
PI adoption:
“I agree that we should go into the direction of PI, but the main hurdles lie in
the change process, the willingness to change. We should create tangible
examples of advantages to show what is possible.”

36
5.4 Challenges in data sharing
Next to the methods, types of data and reasons, it is paramount to discuss the
challenges that companies currently experience. These are often closely related
to the reasons for not sharing data, and should be applied when designing critical
requirements and a functional architecture. Challenges are categorized in two
groups: business and technology.
Business related challenges
These type of challenges relate to the challenges experienced by people in a
company, specifically the people responsible for decision-making. As mentioned
above, there is a lot of uncertainty regarding trust, data security and control, but
also about ownership. Once data is shared (with a platform e.g.), who owns it,
and makes sure everybody benefits? Additionally, effective data sharing requires
substantial investments in IT, costing a considerable amount of time for testing,
but also money, as often expert knowledge from outside has to be brought in. This
creates a lack of visibility of short term benefits. For several companies, it was
sometimes unclear what types of data they could share or not. Interviewee A
mentioned the following:
“It remains unclear what additional types of data we should share compared to
what we do now. We do not see the short term benefits of sharing more data.”
Technology related challenges
Challenges related to technology are less related to people but more to technical
restrictions. Although the technology to share data is developing rapidly, there are
still several challenging barriers to overcome. The main challenges identified by
case companies were interoperability and complexity, where interoperability
issues are often caused by complexity. This complexity is created by the fact that
there are many different stakeholders, which all have their own information
infrastructure as there are no regulations about data standards. Several large
multinationals try to tackle this issue by requiring specific data standards from
their suppliers and customers, but these still differ between those multinationals.

37
5.5 Critical requirements
Based on the input from literature and case study interviews, critical requirements
can be established. These critical requirements, sometimes called stakeholder
requirements, determine what is required for the unit of analysis to function. The
unit of analysis in this study is a system of effective data sharing. Critical
requirements can be categorized in four segments: input/output requirements;
technology requirements; trade-off requirements and system qualification
requirements. This partitioning provides a coherent structure and helps with
establishing more rigorous and sound critical requirements (Buede & Miller, 2016).
The critical requirements will be designed using the guidelines from Buede & Miller
(2016). Table 9 describes their characteristics of sound requirements. These
characteristics will be tested on the critical requirements during the validation
phase.
Characteristics Description
Unambiguous Each requirement has only one interpretation
Understandable Each requirement is clear to those who review them
Correct The requirement states something required of the system
Concise No unnecessary information is included
Traced Each requirement can be traced to a document/statement
Traceable Derived requirements must be traceable to a higher level
Design independent Each requirement does not specify a particular solution
Verifiable Each requirement can be verified cost-effectively
Table 9 - Characteristics of sound requirements (Buede & Miller, 2016)

38
5.5.1 Input/output/control requirements
The input, output and control requirements are created from analyzing inputs,
outputs and controls from the external environment that should make the system
work. Control requirements are a special type of input, while these do not really
provide data but information that is related to policies and guidelines, bringing
certain restrictions. Based on literature and findings in case study interviews, the
following high-level requirements could be established:
- Input: The system shall be open to receive data from all sources, according
to specific data standards and data quality requirements.
As the PI is expected to be an open system, everybody should be able to contribute
their data. Many stakeholders expressed their concerns about the quality of data
from other stakeholders, which is currently often one of the main difficulties.
- Output: The system shall produce a transparent, fair and equal output
based on the relative input from each stakeholder.
Most of the interviewees mentioned their concerns about a fair output from the
system. If this can not be promised, stakeholders would be reluctant to using the
system.
- Output: The system shall produce visible, short term benefits for all
stakeholders.
Next to a fair output, interviewees required that outputs should create visible short
term benefits, otherwise the investment plan will likely be rejected.
- Control: The system shall be restricted by specific protocols and business
rules that were agreed upon by all stakeholders.
To determine what is required for stakeholders to participate, some interviewees
mentioned creating specific protocols or business rules. Dalmolen et al. (2019b)
also discuss that rules over usage conditions should be established. These should
describe how identification, authentication and authorization are addressed in the
data sharing system. Especially authorization is considered to be difficult in
technical and legal terms. It becomes paramount for the protocols to establish the
distinction between access only or user policies.

39
5.5.2 System-wide technology requirements
These requirements relate to the technical capabilities of the system as a whole,
not to the inputs, outputs or controls separately. These are closely related to the
technological challenges in current data sharing systems. A system to share data
effectively requires the following:
- The system shall provide interoperability.
Interoperability indicates that different stakeholders with different EIS should be
able to make use of the system. Interviewees expressed that it would be
impossible that one EIS would be used by all stakeholders. Therefore, there should
be no restriction to what type of EIS is used by stakeholders, although they should
have certain ISO certified functionalities, which can be included in the protocols
or business rules described above. How this could be provided is not within the
scope of this research.
- The system shall be easy and inexpensive to test, implement and use.
As the Physical Internet should be open to everybody this is an important
requirement, especially for smaller stakeholders. Systems that are very complex
and expensive to test, implement and use often run out of time and budget,
causing entire projects to fail. A well-known example from the UK is the failed NHS
Connecting for Health IT system, which was abandoned after almost ten years of
investments at an estimate cost of more than £10 (€12) billion (Syal, 2013). As
the terms ‘easy’ and ‘inexpensive’ are subject to interpretation, these are hard to
define specifically. Therefore, it is critical for each stakeholder to assess their own
situation and capabilities.
- The system shall provide a secure and fast connection with stakeholders
EIS. Data should be available in securely and in real-time to provide the
most optimal advice.
- The system shall always be accessible. The technology used could provide
cloud-access, which should be available without any disruptions.
The last two technology requirements are recommended by interviewees for any
new system that should provide real-time analysis, not just for data sharing in a
PI context. Both are developing rapidly and were not identified as potentially large
issues for the new system.

40
5.5.3 Trade-off requirements
While designing a system, there are typically trade-offs to be considered.
Traditionally, the trade-off is often between performance and costs. This is not
different to the system under analysis. However, another trade-off was also
identified, which discusses the level of centralization versus decentralization that
the system applies. Most case companies discussed that not one party should have
control over the system, indicating their preference towards a certain level of
decentralization. However, as Ambra et al. (2019) discussed, a certain degree of
centralization could bring more benefits to all stakeholders. Therefore, the right
balance should be found. Concludingly, the trade-offs are summarized below:
- The system shall not have too much power and control, but everybody
wants that all stakeholders use the advice provided by the system, as this
will bring the largest benefits. Here, the trade-off is the level of
decentralization vs. centralization.
The issue that was mentioned most by interviewees was the power structure of
the system. As it would contain a lot of sensitive data from many stakeholders,
the controlling party potentially has too much power when the system is
centralized. Therefore, decentralization might be preferred, but then trust should
be established to make sure everybody uses the advice provided by the system.
- The system shall not be too expensive to implement, but it should have
several functionalities. If the system is easy and cheap to implement,
quality and functionalities are often less.
Again, interviewees described that this is a trade-off that comprises every system
design and not just for data sharing in a PI context. Nevertheless, it is an
important trade-off to consider, as sensitive data is included. As discussed above,
the system should have several functionalities to provide security, which should
be described clearly in the PI protocols. This decreases the degree of discussion
that is possible on this trade-off.

41
5.5.4 System qualification requirements
System qualification requirements are needed for testing and validating the
system, and should be used before and during integration. Several requirements
that should be established and tested in advance:
- Companies shall first assess their own readiness for sharing data with the
system, as input data is needed for the system to function.
Readiness relates to the willingness to share data, as well as being able to adhere
to the data requirements required by the protocols and business rules (data
standards and quality). Several interviewees mentioned that they expect most
stakeholders in their supply chains to have issues regarding the willingness to
share data, as well as their technical capacities to actually share this data. Many
still use outdated systems or EIS and are reluctant to IT investments that would
make this system possible. Regarding willingness, the following was expressed:
“Even though most stakeholders know it would be beneficial to the entire
economy to share more data, they are just not willing to share as it helps their
competitors as well. This is something deeply embedded in some companies
cultures and could prove very difficult to change.”
- Trust shall be established with the system or with the controlling party of
the system (mediator).
All interviewees explained that trust is one of the most important but also difficult
requirements to build. If trust is not established, stakeholders might not share
their data, ignore the advice offered by the system or even try to misuse the
system for their own benefits. There are many options on how trust can be
established, ranging from formal contracts to more informal meetings. As this
research area is very broad, how this trust is to be established is not included in
the scope of this research, but provides an opportunity for future research.

42
6 Design
This section examines the use of a third party company in the PI network
(hereafter named ‘mediator’), where data sharing is driven by Enterprise
Information Systems. First, a general description of this proposed third party
model is provided. Second, building upon literature and the critical requirements
established in the previous chapter, a preliminary functional architecture will be
designed, using CORE, a systems engineering software tool. This architecture
describes the functions and interactions between functions of the proposed model.
6.1 Third party model
A novel business model architecture using a third party company, sometimes also
called ‘trustee’, ‘mediator’ (to be used hereafter) or ‘orchestrator’ for logistics
systems was proposed by several academics such as Dalmolen et al. (2018;
2019a) and Lee and Whang (2000). Dalmolen et al. identify the International Data
Space (IDS) architecture as one with potential for improving collaboration and
data sharing. The International Data Space (previously called Industrial Data
Space) is “a virtual data space using standards and common governance models
to facilitate the secure exchange and easy linkage of data in business ecosystems”
(Otto et al., 2016). It utilizes so-called broker service providers, clearing houses
and identity providers for data exchange and is best described by figure 6 below:
Figure 6 - International Data Space architecture (Otto et al., 2016)

43
Furthermore, the EU also recommends the use of a neutral trustee to enhance
horizontal collaboration in logistics, “to whom different stakeholders give data to
be held and analyzed, preventing the transfer of potentially sensitive commercial
data such as volumes, delivery addresses, costs, product characteristics etc.”
(Bogens and Verstrepen, 2013). However, these proposed architectures were not
addressed to align with the specific PI context, but aimed at data sharing in
traditional supply chains. Furthermore, they only address one-to-one collaboration
between one data provider and one data consumer, whereas the PI system needs
many more stakeholders to collaborate. Additionally, it remains unclear who
should share their data, when, and what data. Therefore, academics encourage
additional research on this type of model.
In the next section, a new architecture will be examined and a preliminary design
will be made in a PI context, assuring no central point of authority, as well as
opportunities for multi-lateral collaboration. To achieve this, it should consist of
multiple third party mediators that only have an advisory role. These mediators
could be focusing on a specific region (Benelux, South-East Asia e.g.) or industry
(FMCG, metal e.g.), and are able to offer recommendations on profitable/reliable
business partners, efficient routes, transportation modes or data sharing methods.
In this way, data sharing is expected to be more transparent, while companies will
be able to consult a third party when they want to establish a certain degree of
collaboration but think sensitive data might be compromised. The PI containers
can also consult these third party mediators, but in the end the final decisions
remain with the PI containers. Through formal contracts and learning, the
companies and containers can start trusting mediators they use more often. It is
yet to be established in future research whether these mediators would be physical
companies or digital entities using software solutions such as data hubs.

44
6.2 Operational concept
The model under discussion could look like figure 7 below. In short, the system
should work as following on a day-to-day basis: multiple data providers (in this
model only two are displayed for visibility, but it can be an infinite amount) share
their standard, non-sensitive data through the PI. These data providers can be the
stakeholders in the future envisaged PI as discussed in section 2.2.2. However,
the PI is unable to operate effectively with only this data. It requires additional,
potentially company sensitive data to reap the benefits from a shared network.
Therefore, companies could provide their potentially sensitive data to a trusted
mediator. This mediator then anonimizes, analyzes and optimizes all the data
combined, and provides its optimal advice to all stakeholders that provided their
data. Furthermore, it would provide this data to the PI so it can take this into
consideration while optimizing shipment decisions. The other way around, the PI
provides their data to the mediator if it needs additional data to optimize its advice
towards stakeholders. Concludingly, the functioning of the system depends on the
stakeholders, whether they use the optimal advice that is provided to them or not.
Figure 7 – Potential design of a Third Party Model (TPM)
The mediator can use a ‘recommender system’, which enables to provide
recommendations on for instance to suppliers for potential customers, and vice
versa, based on each stakeholders preferences. This helps with “resolving the
cognitive overload and the overabundance of data and information” (Kembellec et
al., 2014), as is expected in the PI. Netflix uses a recommenders system to provide

45
recommendations on what to watch next based on ones previous views, whereas
Facebook uses this system to recommend potential connections based on current
connections and/or interests. To ensure an adequate degree of decentralization,
the mediator is expected to only have an advisory role, keeping the final decision
for the stakeholders to be made. There are several exceptions to consider in
designing such a system. This is due to the fact that there are many different
stakeholders, with different strategies, objectives and requirements.
One-off shipments
For shipments that are expected to only happen once, there is no need for
supplier, customer, LSP or other stakeholders to share sensitive data with each
other. They can share standard shipment data simply through PI, which should be
sufficient. Only with repeated shipments, collaboration can become beneficial due
to collaborative planning and other reasons discussed earlier.
Logistics Service Providers
For LSPs the situation is slightly different, as they have to share data and
collaborate no matter the frequency or type of shipment, in order to establish and
operate a shared PI network. They also need to share assets (such as
warehouses). Therefore, sharing company sensitive data is often required. LSPs
are expected to become the main users of the mediator services.
Antitrust / competition laws
Direct collaboration and data sharing between competitors might be legally
restricted due to antitrust or competition laws. Competitors comply to this law if
every other stakeholder (especially end consumers) benefits from the
collaboration. As this is very dynamic, difficult to measure and establish, another
option is to share data indirectly (via a mediator), as is opted for in this paper. In
this way, no direct collaboration or data sharing is established and compliance
with antitrust and competition laws is achieved (Vargas et al., 2018).

46
6.3 Functional architectures
To describe the operational concept using a more systematic method, functional
architectures should be developed. Next to the functional architectures,
interaction diagrams will also be provided to highlight the interactions between
the functions, connecting their inputs, outputs and controls. The design of these
architectures is guided by literature, as well as the critical requirements and other
findings that resulted from case study interviews and observations. Most
importantly, the function under analysis is A.0 ‘perform mediator functions’. To
start, the wider context of function A.0 will be described first, after which three
alternatives will be provided for the first level decomposition of function A.0.
6.3.1 Function A-2: Perform PI context functions
This first functional architecture describes the widest external context of function
A.0 in the PI. As discussed before, PI can be segregated into three types of flows,
which here provide the first decomposition of the PI. Function A.0 is included under
the A-1 function: perform information flows.
Figure 8 - Functional Architecture A-2

47
Figure 9 - Interaction diagram A-2
6.3.2 Function A-1: Perform information flows
The functional architecture of A-1 describes the external context of function A.0
in more detail. Next to performing mediator functions, identifying a need for data
and processing the mediator advice are also included for performing information
flows in a Physical Internet network.

48
Figure 10 - Functional Architecture A-1
Figure 11 - Interaction diagram A-1

49
6.3.3 Function A.0: Perform mediator functions
As the mediator functions can be performed in many different ways, three
alternative options will be presented below. Each alternative has different
characteristics based on which the mediator operates.
Alternative 1
The first alternative is characterized by a more reactive approach by the mediator,
after trust is already established. To perform its functions, it expects that
stakeholders will provide the data to the mediator without need to ‘ask’ for it.
Furthermore, this alternative takes into account a decentralized approach of PI,
as the mediator is only allowed to provide optimized advice without actually
implementing it. Most of the system is controlled by PI protocols.
Figure 12 - Functional Architecture A.0 (alternative 1)

50
Figure 13 - Interaction diagram A.0 (alternative 1)
Alternative 2
The second alternative is characterized by a more proactive approach by mediator,
while still taking into account the decentralized nature of PI. The difference with
the first alternative is that the mediator actively looks for stakeholders that could
benefit from providing their data. The mediator then tries to establish trust with
these stakeholders, possibly through formal contracts. Once this is established, it
can provide their optimized advice, just like in the first alternative. Again, PI
protocols largely control the system.
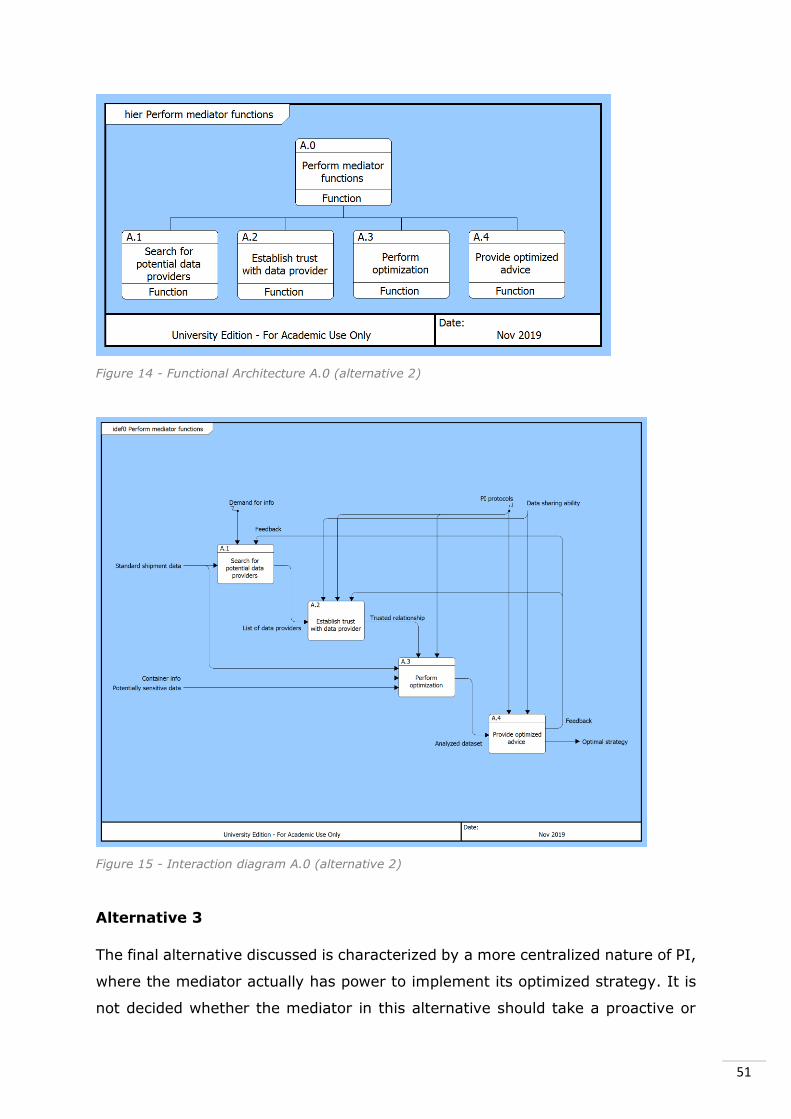
51
Figure 14 - Functional Architecture A.0 (alternative 2)
Figure 15 - Interaction diagram A.0 (alternative 2)
Alternative 3
The final alternative discussed is characterized by a more centralized nature of PI,
where the mediator actually has power to implement its optimized strategy. It is
not decided whether the mediator in this alternative should take a proactive or

52
reactive approach. However, as this mediator has more power, it might be possible
that it is able to require certain types of data from all stakeholders, so trust is less
important to be established compared to the first two alternatives.
Figure 16 - Functional Architecture A.0 (alternative 3)
Figure 17 - Interaction diagram A.0 (alternative 3)

53
7 Validation
The critical requirements are evaluated with two expert workshops. One from an
academic (PI) perspective (S. Dalmolen) and the other from a business
perspective (at a leading consultancy firm), where both participants are
experienced in the area of data sharing. This validation was conducted to examine
the relevance of the problem, the characteristics of the critical requirements (using
table 9 on p.37), the feasibility of the proposed solution (model) to the problem,
and to gain additional expert insights. The functional architectures were not
discussed, as these are only designed preliminarily and need to be developed
further in future research. In the workshops, the research context and problem
statement were presented and shortly explained first. When these were clear, the
critical requirements were presented per category, on which an open discussion
started. This discussion was advanced by several questions if needed, and
provided valuable feedback about the requirements in both workshops.
7.1 Validation of critical requirements
Most importantly, both participants found the critical requirements to be
understandable and correct for a data sharing system. No extra clarifications were
needed to explain the critical requirements, but several of the requirements could
be made slightly more specific. However, according to both participants this also
depended on the scope of the research. Furthermore, the problem statement was
regarded clear and very relevant, and the requirements follow a coherent
partitioning. Nevertheless, both participants had concerns on the practical
applicability of a third party data sharing system and how it would align with
currently used networks, that are mostly closed. The first participant summarized
it as following:
“What you propose is an open infrastructure, where everybody can share data
securely and in controlled manner. The problem is relevant and the requirements
understandable and usable. However, even though the system would provide
clear benefits to all stakeholders, I am not sure whether it would take off.”

54
The reasons for this was discussed by both participants, and mainly revolve around
the issue of trust. Even though it might be technically possible to securely share
sensitive data, many stakeholders do not trust these systems yet. To achieve a
higher level of trust, more real life examples of successful data sharing systems
should be available. This also relates to the output requirement, that indicates
that short-term benefits should be visible. In addition to the issue of trust, the
participants claimed that many companies are technically not ready to share data
effectively, and IT investments will be needed. These will only be made when
again trust is established, so this is seen as a fundamental requirement.
Input/output/control requirements
These requirements were confirmed to be correct and could be used in designing
a data sharing system. However, as discussed above, some might need to be
complemented with a more detailed description. This is mainly for the control
requirement. For example, the second participant mentioned the following about
the control requirement:
“The control requirement states that specific protocols and business rules should
be used, but providing some additional information or examples on these
concepts would be recommended.”
The first participant provided remarks about including the concepts of
identification, authentication and authorization, which are now added to section
5.5.1. Furthermore, participants stressed the importance and challenge of data
standards and quality in the input requirements. Nevertheless, they remained
sceptic whether all stakeholders could deliver this. This also relates to the
technological challenges discussed in section 5.4 and the technology requirements
discussed in the next section.

55
System-wide technology requirements
In the second category, participants again confirmed the requirements, but
discussed that the concept of interoperability could use some additional
explanation and demarcation. However, it would be out of the scope of this
research to fully discuss how interoperability could be achieved. The first
participant indicated that it would be a potential future research direction for
multiple research papers, as it is a very broad research area. Regarding the second
requirement, the terms ‘easy’ and ‘inexpensive’ are used, but participants
discussed that these should be defined clearly. A discussion could be included on
compared to what the system should be easy and inexpensive, and in what stage.
The first participant provided the following comment:
“It is quite a bold statement now, which you could make more reasonable by
giving an example of an actual system implementation that was not easy and
inexpensive and therefore failed.”
Following from this comment, a real life example was added to section 5.5.2. The
advice from the first participant would be to design the system using a practice
called Continuous Integration & Continuous Delivery (often abbreviated as CICD
or CI/CD). This method provides a faster, more transparent and flexible
implementation, which would align with the terms of ‘easy’ and ‘inexpensive’.
Trade-off requirements
The critical requirements in this third category are regarded as applicable and
generally relevant to most IT systems by the participants. The first participant
clearly argued why he prefers a decentralized system over a centralized one, which
aligns with the general opinion of the interviewees:
“A centralized platform might seem great, but there are often issues about who
creates the platform, who is responsible for the costs, or who owns it. Next to
that, you have the potential danger of vendor or community lock-ins.”
Vendor or community lock-ins create dependency on a system, limiting the ability
to flexibly move to a different system without substantial effort and investments.

56
The second participant also expressed a preference towards a more decentralized
system:
“If the system would be owned by, lets say a company like to Google or
Amazon, I am sure most companies will not even consider sharing their data
with this system.”
The second trade-off, between functionalities and costs, also links back to the
previous category. In the technology requirements, it should be defined which
functionalities a system should at least have, so there is less opportunity for
discussion around this trade-off. Here, a reference could be made to ISO
qualifications of system/software quality, and these could be included in the PI
protocols and business rules. Nevertheless, this is regarded as a very relevant
requirement for the system, and often a difficult dilemma in business cases.
System qualification requirements
For the final category, the participants confirmed that without these requirements
the system would not work at all, and therefore these would be correct. There
were again some remarks on the level of detail of these requirements and how
these relate to the system directly. Like interoperability, trust is also regarded as
a very broad research area. To fully incorporate this would also be out of the scope
of the research. It is definitely an important requirement to consider, but the
participants did not see the need to go into too much detail. Advice from the first
participant was to take the IDS as an example for building trust:
“In IDS (International Data Spaces) there are different roles, which need
different certifications. Next to that, there are also software certifications
considered. This could help building trust, and maybe the government could play
an essential role in this process.”

57
8 Discussion
This study examined the process of effective data sharing in a Physical Internet
context. A proposed solution is a data sharing system using a mediator, for which
multiple critical requirements were developed. Furthermore, a preliminary design
of this system was created. The findings have implications for both theory and
practice. This chapter discusses the findings, implications, limitations of this study
and recommendations for future research.
8.1 Discussion of findings
The findings of this study can be divided into several segments. First, the findings
of case studies will be discussed, after which the critical requirements are
examined. Next, the third party data sharing model and preliminary functional
architectures are discussed, and last, the validation phase.
Case studies
Most of the findings from case studies confirmed what was found in literature,
meaning that it helps building the literature related to PI and data sharing by
confirming existing theories. No new methods of data sharing or data types were
discovered, but one finding was that mostly ports/hubs use a very wide range of
methods, as they have to adapt to their high amount of stakeholders who use a
large range of data sharing systems. Therefore, interoperability of EIS might also
depend on the amount of stakeholders, and the distribution of power. Having more
power, companies could require their less powerful stakeholders to adapt to their
system or platform. Next to these, the reasons for (not) sharing data were also
examined. This section was very important for the creation of critical
requirements, as it described the stakeholders needs. The need to share data for
regulatory purposes was discovered as additional reason during case studies.
Other reasons were similar as those discussed in the literature review. Most
challenges for data sharing were also similar to the ones identified in the literature
review, relating to either a business or technology perspective.

58
Critical requirements
The main contribution of this study are the critical requirements, which have been
discussed in section 5.5 and the validation chapter. The key findings are that a
data sharing system should be transparent, open, interoperable, easy to
implement and have a certain level of decentralization. These build on existing
evidence from literature, complemented by several novel findings of the case
studies, and can be used independent of future design decisions.
Third party data sharing model
Another contribution of this study is the exploration of a novel data sharing model
and its proposed operational concept. The proposed design is described in a
functional context, while offering several alternatives based on different design
decisions. All alternatives have specific benefits and disadvantages. Depending on
the design decisions, one alternative might be preferred over the others. However,
at this stage it is impossible to confirm which alternative is best. The first
alternative could be preferred when the system is virtual, based on a software
architecture, which makes it harder to be proactive. When the system is not just
virtual but provided by a real company, as in alternative 2, proactiveness becomes
more interesting. The third alternative depends on the PI protocols, which
establish the degree of centralization in the system. Clearly, alternative 3 would
not function in a decentralized system, whereas alternatives 1 and 2 would operate
less effectively in a centralized system. Concluding, it depends on the design
decisions which alternative fits best, or whether a different alternative should be
designed.
Validation
The validation workshop proved to be a very valuable method, as it confirmed the
relevance of the problem and the usability of the novel critical requirements. Both
participants expressed the importance of collaboration and their preference
towards a decentralized system. This contradicts the claims of Stein et al. (2019)
who argue for internalization (in-sourcing) as an alternative strategy. The paper
takes Amazon as an example that exhibits basic concepts of the PI by internalizing

59
its crucial logistics activities. A disadvantage is the possible creation of a huge
monopoly. Furthermore, as internalization only applies to the logistics parts of the
supply chain and not to the suppliers and customers, processes cannot be
optimized for the entire chain. While the paper does not make evident claims, it
does have an interesting alternative viewpoint which calls for more research in
this direction.
Based on the feedback of the validation, there is a preference for first two
alternatives of the functional architectures as these imply a decentralized system.
Furthermore, trust was seen as a fundamental requirement to establish, so it
cannot simply be assumed to exist. Therefore, the validation indicates a
preference for the second alternative to be used in further research.
8.2 Implications for theory
The findings of case studies mostly fit with theories found in literature. For
example, PI literature discusses that decentralization is needed, which was
confirmed as a requirement during case studies. Therefore, it contributes to a
clearer understanding of the topic of data sharing and builds the theoretical
support for this concept. The novel findings are the critical requirements and third
party data sharing model. These show what stakeholders require from a data
sharing system, while indicating a first step towards a system design. Therefore,
it provides additional insights for literature about data sharing and collaboration,
but also for PI. Furthermore, it examines the use of ‘mediators’, a research area
that still remains underdeveloped and therefore needs additional research. Next
to this, future research could assess which of the three alternatives should be
implemented and further develop these. Lastly, the collected data of case studies
can be used by other academics for research purposes in a similar context.
To summarize, the case studies provide many synergies with the literature
discussed first. The critical requirements fill in a research gap, as these have not
been established before for a data sharing system in a PI context.

60
8.3 Implications for practice
Although PI is still a very abstract concept to most companies, collaboration and
data sharing is actually one of the topics that companies are increasingly
investigating in. The research identifies several reasons why companies do not
share data, and tries to find a solution to this. Therefore, the practical relevance
leans towards the side of data sharing via a third party model. In practice,
companies that are interested in participating in an increased data sharing
environment could see how case companies address this issue, what best practices
are, as well as the main challenges that are currently experienced. Furthermore,
companies that successfully shared data to improve a certain process can use the
critical requirements developed in this research, to extend data sharing to improve
additional processes. Using these requirements, a specific system can be designed
for this. Next to this, practitioners can gain inspiration on how to start designing
functional architectures by analyzing the presented alternatives. Incrementally
improving more processes through more data sharing using a third party mediator
has the potential to create a stronger competitive position. The entire supply chain
benefits from increased information availability, while complying to competition
and antitrust laws.
8.4 Limitations and future research directions
As with any research, this study has several limitations, and most are linked to
future research directions. First, using a DSR methodology has the limitation that
it is mostly exploratory, creating only theoretical solutions, and not an exhaustive
list of critical requirements. Future research should therefore focus on following
the DSR cycle, so more case studies should be conducted, more critical
requirements could be discovered and validated, and more detailed designs could
be proposed and tested. Next to that, this research collected data from several
case companies in the Netherlands only. Although most of these are multinationals
and different but relevant industries were chosen, the geographic location of the
cases might limit generalizability of the research.

61
Furthermore, future research could explore and develop the research areas of
interoperability and trust in a third party data sharing context. For example, the
trade-off between centralization and decentralization provides interesting
research opportunities, as well as different technological solutions for secure data
sharing (e.g. blockchain). To help building more supporting literature, future
research should try to find additional scenarios where data sharing provided to be
helpful. These success stories can potentially convince more stakeholders to
consider sharing more data. Additionally, potential exceptions should be identified
based on which solutions can be proposed. Currently, it is not evident what would
happen when data is not accurate, available, or in the worst case, when data
leakage happens. Who can be held responsible and what are the consequences?
Lastly, a novel business model for the mediator should be explored. For example,
there should be established whether the mediator would be an actual company or
only exists as information infrastructure, and how it would generate enough
revenue to cover their costs.
To summarize, it is advised for future research to follow the DSR cycle and collect
more data, conduct more validations and design additional functional architectures
in order to further develop effective data sharing systems for the Physical Internet.

62
9 Conclusion
This thesis addresses the issue of collaboration and data sharing in a future PI
network. The main research question, how can data be shared effectively in the
PI, enabled by Enterprise Information Systems, was examined using four sub-
questions. By analyzing current data sharing systems of real case companies,
methods of data sharing and types of sensitive data were identified, answering
sub-question 1 and 2. The majority of data is shared via EIS, using EDI or API
connections. Companies consider most of their data to be potentially sensitive,
except for publicly available data such as product dimensions. Based on the
findings of the cases, the critical requirements of sub-question 3 could be created
and validated. These critical requirements are the main artifacts of this study and
contribute to both literature and practice, as these can be considered by academics
or practitioners in future research or developments. The analysis of sub-question
4 provides several examples of how such a system could be designed, depending
on the level of proactiveness and decentralization of the system. This is also novel
knowledge, but more data is needed to design this system more in depth.
To conclude, the main research question can be answered in theory only, due to
the exploratory nature of this research. In theory, data can be shared more
effectively through a platform (EIS) provided by a third party mediator, if the
system adheres to the critical requirements that were created. The theoretical
potential of a third party model was confirmed during interviews and validation,
but concerns were raised for the practical applicability. Therefore, this thesis
provides an innovative starting point towards additional research in third party
data sharing systems. Future research should be conducted to collect more data,
develop more requirements and designs, and validate these more. Once a
grounded base of literature is established, the research question could be tested
more practically, and actual implementations could be introduced.

63
10 References
van Aken, J., Chandrasekaran, A. and Halman, J. (2016) ‘Conducting and
publishing design science research: Inaugural essay of the design science
department of the Journal of Operations Management’, Journal of Operations
Management, 47, pp. 1-8.
Ambra, T., Caris, A. and Macharis, C. (2019) ‘Towards freight transport system
unification: reviewing and combining the advancements in the physical internet
and synchromodal transport research’, International Journal of Production
Research, 57(6), pp. 1606-1623.
Badzar, A. (2016) ‘Blockchain for securing sustainable transport contracts and
supply chain transparency - an explorative study of blockchain technology in
logistics’, Lund University, Service Management and Service Studies. Lund
University Libraries.
Ballot (2018) ‘Introduction in Physical Internet’ [pdf]. Available at:
https://www.pi.events/content/presentations-pdf-download (last accessed: 5
August 2019)
Ballot, E. and Fontane, F. (2008) ‘Rendement et efficience du transport: un
nouvel indicateur de performance’ [Rendement and efficiency in transport : a new
performance indicator], (No. hal-00878313).
Ballot, E., Gobet, O. and Montreuil, B. (2012) ‘Physical internet enabled open
hub network design for distributed networked operations’. In Borangiu, T.,
Thomas, A. and Trentesaux, D. (ed.) Service orientation in holonic and multi-agent
manufacturing control. Berlin, Heidelberg: Springer, pp. 279-292.
Ballot, E., Montreuil, B. and Meller, R. (2014) The physical internet. La
Documentation Française.
Bogens, M. and Verstrepen, S. (2013) CO3 position paper: added value of ICT
on logistics horizontal collaboration: identifying the need for an integrated
approach. Available at: http://www.co3-project.eu/wo3/wp-
content/uploads/2011/12/CO3-D-4-4-Added-value-of-ICT-in-Logistics.pdf (last
accessed: 5 September 2019).

64
Buede, D. M. and Miller, W. D. (2016) The engineering design of systems:
models and methods. John Wiley & Sons.
Cambra-Fierro, J. and Ruiz-Benitez, R. (2009) ‘Advantages of intermodal
logistics platforms: insights from a Spanish platform’ Supply Chain Management:
An International Journal, 14(6), pp. 418-421.
Cao, M. and Zhang, Q. (2011) ‘Supply chain collaboration: Impact on
collaborative advantage and firm performance’, Journal of Operations
Management, 29(3), pp. 163-180.
Carter, N., Bryant-Lukosius, D., DiCenso, A. and Neville, A. J. (2014), ‘The use
of triangulation in qualitative research’, Oncology nursing forum, 41(5).
Council of Supply Chain Management Professionals (CSCMP, 2013) Supply
Chain Management Terms and Glossary. Available at:
https://cscmp.org/CSCMP/Academia/SCM_Definitions_and_Glossary_of_Terms/C
CSCM/Educate/SCM_Definitions_and_Glossary_of_Terms.aspx?hkey=60879588-
f65f-4ab5-8c4b-6878815ef921 (last accessed: 2 August 2019).
Council of Supply Chain Management Professionals (CSCMP, 2015) Conference
on improving transport capacity utilization in the supply chain. Available at:
http://cscmpbenelux.org/event-report-improving-transport-capacity-utilization/
(last accessed: 15 July 2019).
Crainic, T.G. and Montreuil, B. (2016) ‘Physical internet enabled
hyperconnected city logistics’, Transportation Research Procedia, 12, pp. 383-398.
Da Xu, L. (2011) ‘Enterprise systems: state-of-the-art and future trends’, IEEE
Transactions on Industrial Informatics, 7(4), pp. 630-640.
Dalmolen, S., Bastiaansen, H., Moonen, H., Hofman, W., Punter, M. and
Cornelisse, E. (2018) ‘Trust in a multi-tenant, logistics, data sharing
infrastructure: Opportunities for blockchain technology’, In 5th International
Physical Internet Conference (IPIC 2018), pp. 299-309.
Dalmolen, S., Bastiaansen, H., Somers, E., Djafari, S., Kollenstart, M., and
Punter, M. (2019a) ‘Maintaining control over sensitive data in the Physical
Internet: Towards an open, service-oriented, network-model for infrastructural

65
data sovereignty’, In 6th International Physical Internet Conference (IPIC 2019),
pp. 296-311.
Dalmolen, S., Bastiaansen, H., Kollenstart, M. and Punter, M. (2019b)
‘Infrastructural sovereignty over agreement and transaction data (‘metadata’) in
an open network-model for multilateral sharing of sensitive data, In 40th
International Conference on Information Systems, Munich, 2019.
Denzin, N. K. and Lincoln, Y. S. (Eds.). (2011) The Sage handbook of
qualitative research. Sage.
Devers, K. J. (1999) ‘How will we know" good" qualitative research when we
see it? Beginning the dialogue in health services research’, Health services
research, 34(5.2), pp. 1153.
EFT Supply Chain & Logistics Business Intelligence and JDA Software (2019)
‘Global Logistics Report 2019’. Statista. Available at:
www.statista.com/study/63732/global-logistics-report-2019 (last accessed: 5
August 2019)
Eisenhardt, K. M. (1989) ‘Building theories from case study research’, Academy
of management review, 14(4), pp. 532-550.
El Kadiri, S., Grabot, B., Thoben, K. D., Hribernik, K., Emmanouilidis, C., Von
Cieminski, G. and Kiritsis, D. (2016) ‘Current trends on ICT technologies for
enterprise information systems’, Computers in Industry, 79, pp. 14-33.
European Union. (2013) ETP ALICE. Available at: https://www.etp-logistics.eu/
(last accessed: 10 June 2019)
Furtado, P. and Frayret, J. M. (2014) ‘Impact of resource sharing of freight
transportation’. In 1st International Physical Internet Conference, Québec City,
Canada, May.
Gregor, S. and Hevner, A. R. (2013) ‘Positioning and presenting design science
research for maximum impact’, MIS quarterly, pp. 337-355.
Hevner, A.R., March, S. T., Park, J. and Ram, S. (2004) ‘Design science in
information systems research’, MIS quarterly, 28(1), pp. 75-105.
Hevner, A. and Chatterjee, S. (2010) ‘Design science research in information
systems’, Design research in information systems, pp. 9-22.

66
Holmström, J., Ketokivi, M. and Hameri, A.P. (2009) ‘Bridging practice and
theory: a design science approach’, Decision Sciences, 40(1), pp. 65-87.
IMARC Group (2018) ‘Logistics Market: Global Industry Trends, Share, Size,
Growth, Opportunity and Forecast 2019-2024’. Available at:
https://www.imarcgroup.com/logistics-market (last accessed: 2 August 2019)
Kembellec, G., Chartron, G. and Saleh, I. (ed) (2014) Recommender systems.
London: ISTE.
Kotzé, P., van der Merwe, A. and Gerber, A. (2015) ‘Design science research
as research approach in doctoral studies’, AMCIS 2015 Proceedings.
Lindgren, R., Henfridsson, O. and Schultze, U. (2004) ‘Design principles for
competence management systems: a synthesis of an action research study’, MIS
quarterly, pp. 435-472.
Markus, M. L., Majchrzak, A. and Gasser, L. (2002) ‘A design theory for
systems that support emergent knowledge processes’, MIS quarterly, pp. 179-
212.
Mason, M. (2010) ‘Sample size and saturation in PhD studies using qualitative
interviews’, In Forum qualitative Sozialforschung / Forum: qualitative social
research, 11(3).
McAfee, A., Brynjolfsson, E., Davenport, T. H., Patil, D. J. and Barton, D.
(2012) ‘Big data: the management revolution’, Harvard business review, 90(10),
pp. 60-68.
McKinsey Global Institute (MGI, 2017) ‘Jobs lost, jobs gained: Workforce
transitions in a time of automation’. Available at:
https://www.mckinsey.com/featured-insights/future-of-work/jobs-lost-jobs-
gained-what-the-future-of-work-will-mean-for-jobs-skills-and-wages (last
accessed: 26 August 2019)
Meyer, T. and Hartmann, E. (2019) ‘The bumpy road to the adoption of the
Physical Internet – Overcoming barriers from a stakeholder perspective’, In 6th
International Physical Internet Conference, IPIC 2019, pp. 406-419.

67
Montreuil, B. (2009–2012) ‘Physical Internet Manifesto: Globally Transforming
the Way Physical Objects are Handled, Moved, Stored, Realized, Supplied and
Used’, Versions 1.1 to 1.11.
Montreuil, B., Meller, R.D. and Ballot, E. (2010) 'Towards a Physical Internet:
the impact on logistics facilities and material handling systems design and
innovation', Progress in material handling research. pp. 305–327.
Montreuil, B. (2011) ‘Toward a Physical Internet: meeting the global logistics
sustainability grand challenge’, Logistics Research, 3(2-3), pp. 71-87.
Montreuil, B., Meller, R. D. and Ballot, E. (2013) ‘Physical internet foundations’,
In Borangiu, T., Thomas, A. and Trentesaux, D. (ed.) Service orientation in holonic
and multi-agent manufacturing control. Berlin, Heidelberg: Springer, pp. 151-166.
O’Brien, J.A. (2003) Introduction to information systems: essentials for the e-
business enterprise. Boston, MA: McGraw-Hill.
Olson, D. L. and Kesharwani, S. (2009) Enterprise information systems:
contemporary trends and issues. World Scientific.
Otto, B., Auer, S., Cirullies, J., Jürjens, J., Menz, N., Schon, J. and Wenzel, S.
(2016) ‘Industrial data space: digital sovereignity over data’, Fraunhofer White
Paper.
Panetto, H., Zdravkovic, M., Jardim-Goncalves, R., Romero, D., Cecil, J. and
Mezgár, I. (2016) ‘New perspectives for the future interoperable enterprise
systems’, Computers in Industry, 79, pp. 47-63.
Pearson, K.E. and Saunders, C.S. (2009) Strategic Management of Information
Systems. 5th edn. John Wiley & Sons.
Purao, S. (2002) ‘Design research in the technology of information systems:
Truth or dare’, GSU Department of CIS Working Paper, 34.
Rashid, M.A., Hossain, L. and Patrick, J.D. (2002) ‘The evolution of ERP
systems: A historical perspective’, In Nah, F.F.H. (ed.) Enterprise Resource
Planning: Solutions and Management. IGI Global, pp. 35-50.
Romero, D. and Vernadat, F. (2016) ‘Enterprise information systems state of
the art: Past, present and future trends’, Computers in Industry, 79, pp. 3-13.

68
Seidel, S., Chandra Kruse, L., Székely, N., Gau, M. and Stieger, D. (2018)
‘Design principles for sensemaking support systems in environmental
sustainability transformations’, European Journal of Information Systems, 27(2),
pp. 221-247.
Speranza, M.G. (2018) ‘Trends in transportation and logistics’, European
Journal of Operational Research, 264(3), pp. 830-836.
Statista (2019) ‘Enterprise software’. Available at:
https://www.statista.com/study/20237/business-software-statista-dossier (last
accessed: 22 August 2019)
Stein, S., Prandtstetter, M., Starkl, F., and Reiner, G. (2019) ‘Is collaboration
necessary? Or: Might the Physical Internet be implemented by internalization?’,
In 6th International Physical Internet Conference, IPIC 2019, pp. 286-295.
Syal, R. (2013) The Guardian. Available at:
https://www.theguardian.com/society/2013/sep/18/nhs-records-system-10bn
(last accessed: 21 November 2019).
Szirbik, N. B. (2019) Design Science Research for Technology and Operations
Management. University of Groningen, the Netherlands.
Treiblmaier, H., Mirkovski, K. and Lowry, P.B. (2016) 'Conceptualizing the
physical internet: Literature review, implications and directions for future
research', Annual European Research Seminar, (November), pp. 1–17.
Treiblmaier, H. (2019) ‘Combining Blockchain Technology and the Physical
Internet to Achieve Triple Bottom Line Sustainability: A Comprehensive Research
Agenda for Modern Logistics and Supply Chain Management’, Logistics, 3(1), pp.
10.
Vargas, A., Patel, S. and Patel, D. (2018) ‘Towards a business model
framework to increase collaboration in the freight industry’ Logistics, 2(4), pp. 22.
Venable, J., Pries-Heje, J. and Baskerville, R. (2016) ‘FEDS: a framework for
evaluation in design science research’, European Journal of Information Systems,
25(1), pp. 77-89.
Weiss, G. (2013) Multiagent Systems. 2nd edn. Cambridge, MA: The MIT Press.

69
Wieringa, R. (2007) Writing a report about design research, February, pp. 1-
9. (PDF provided by the university of Groningen).
Wieringa, R. and Heerkens, H. (2007) ‘Designing requirements engineering
research’, Fifth International Workshop on Comparative Evaluation in
Requirements Engineering, October, pp. 36-48.
Wieringa, R. (2009) ‘Design science as nested problem solving’, Proceedings
of the 4th international conference on design science research in information
systems and technology, May, pp. 8.
Wieringa, R., Heerkens, H. and Regnell, B. (2009) ‘How to write and read a
scientific evaluation paper’, 17th IEEE International Requirements Engineering
Conference, August, pp. 361-364.
Wooldridge, M. (2009) An introduction to multiagent systems. 2nd edn.
Chichester: John Wiley & Sons.
World Economic Forum (WEF, 2018) ‘The Future of Jobs Report 2018’. Available
at: https://www.weforum.org/reports/the-future-of-jobs-report-2018 (last
accessed: 26 August 2019)
Zacharewicz, G., Diallo, S., Ducq, Y., Agostinho, C., Jardim-Goncalves, R.,
Bazoun, H., Wang, Z. and Doumeingts, G. (2017) ‘Model-based approaches for
interoperability of next generation enterprise information systems: state of the art
and future challenges’, Information Systems and e-Business Management, 15(2),
pp. 229-256.
Zhang, Y. and Wildemuth, B.M. (2009) ‘Qualitative analysis of content’,
Applications of social research methods to questions in information and library
science, 308, pp. 319-330.
Zijm, H., Klumpp, M., Regattieri, A. and Heragu, S. (2019) Operations,
Logistics and Supply Chain Management. Springer.

70
11 Appendices
Appendix A – PESTLE analysis logistics industry
Elements Analysis
Political As logistics is a global industry, many different political
situations should be accounted for. Currently, there is a lot of
uncertainty resulting from the Brexit case and the tense
relation between China and the US.
Economic Over the past decades, the industry has been growing
steadily. Volumes are expected to keep increasing, but profits
might decline relatively as green transportation has to be used
more, often being more expensive compared to conventional
shipping methods.
Social Social pressure for transparent, sustainable practices but
increasing demand for cheap logistics services, creating a
dichotomy which can be difficult for companies to address.
Technological Many opportunities to develop the industry, ranging from
more efficient contemporary fuel use to automation and
intelligent use of new technologies like AI and IoT.
Legal Next to basic legal requirements which differ across countries,
the industry is increasingly involved in legal issues as
governments have to regulate emissions and pollution.
Climate agreements cause logistics providers to innovate and
develop sustainable solutions for future transport.
Environmental One of the biggest threats to the current industry, which is
inherently bad for the environment. The main issue is the
pollution that is caused by logistics processes.
Table A1 – PESTLE analysis logistics industry
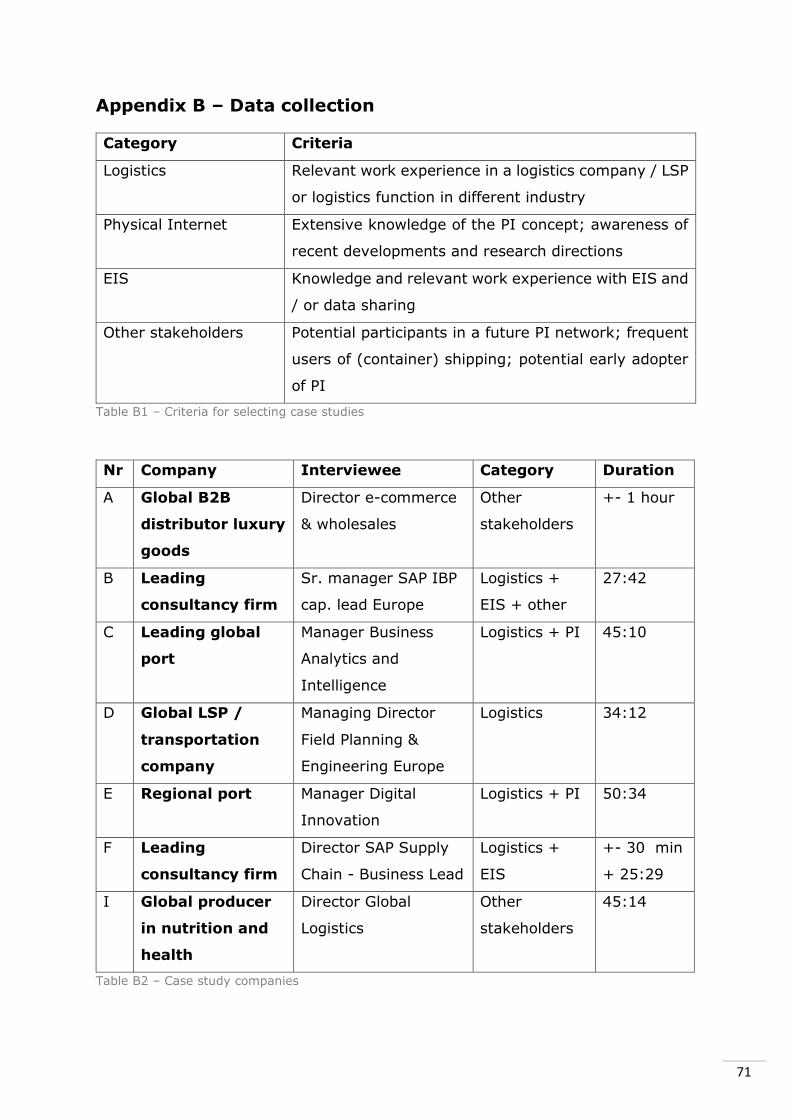
71
Appendix B – Data collection
Category Criteria
Logistics Relevant work experience in a logistics company / LSP
or logistics function in different industry
Physical Internet Extensive knowledge of the PI concept; awareness of
recent developments and research directions
EIS Knowledge and relevant work experience with EIS and
/ or data sharing
Other stakeholders Potential participants in a future PI network; frequent
users of (container) shipping; potential early adopter
of PI
Table B1 – Criteria for selecting case studies
Nr Company Interviewee Category Duration
A Global B2B
distributor luxury
goods
Director e-commerce
& wholesales
Other
stakeholders
+- 1 hour
B Leading
consultancy firm
Sr. manager SAP IBP
cap. lead Europe
Logistics +
EIS + other
27:42
C Leading global
port
Manager Business
Analytics and
Intelligence
Logistics + PI 45:10
D Global LSP /
transportation
company
Managing Director
Field Planning &
Engineering Europe
Logistics 34:12
E Regional port Manager Digital
Innovation
Logistics + PI 50:34
F Leading
consultancy firm
Director SAP Supply
Chain - Business Lead
Logistics +
EIS
+- 30 min
+ 25:29
I Global producer
in nutrition and
health
Director Global
Logistics
Other
stakeholders
45:14
Table B2 – Case study companies

72
Potential hazards Action
Breach of personal or company data
(interview recording)
Secure, encrypted storage of data;
anonymous storage of data and
interview recordings and transcripts
Confusion/insecurity of interviewees Providing an interview guide with
consent form to enhance clarity,
opportunities for questions
Accidents during transportation Responsible travelling; no risks taken;
timely planning
Involvement of vulnerable individuals /
groups in data collection
No involvement of these persons
Harm during company visits for
interviews and observations
Responsible behavior at visited
companies; wearing of safety
equipment if necessary (shoes, vest,
helmet, safety glasses etc.)
Table B3 – Ethics and risks

73
Interview guide – information sheet
Collaboration in the Physical Internet:
An exploration of third party data sharing enabled by Enterprise Information
Systems
Introduction
Dear interviewee,
With great gratitude, this interview guide is shared with you. First of all, thank
you for volunteering to participate in this research. Your input will create valuable
information to this research for my Master Thesis in Technology & Operations
Management. This document will provide you with all necessary information
needed before the interview will be conducted.
As the thesis will be written in English, this is the preferred language for the
interview. However, if you wish to do the interview in Dutch, this would be no
problem. Please notify this before, at the start or during the interview. In that
case, I will provide you with a Dutch version of the interview guide.
This page contains an outline of the interview guide, as well as a description of
the interview procedure. On page 2, you can find the context of the research,
which shortly explains what the research is about. Page 3 contains a consent form.
Please read it carefully, and send back a signed version when you agree with all
the statements. On page 4 and 5, the interview scheme is provided. Here, the
main questions are indicated, so you have the opportunity to prepare for the
interview. There might be some deviation from these questions when needed, to
ensure a smooth process and quality of information.
Procedure
After a short introduction, the audio recording will be started with your permission.
This recording will only be used for transcribing the interview so it can be used for
the data analysis, under complete confidentiality. From this point onwards, the

74
‘official’ interview commences. It begins by restating that the interviewee agrees
to the consent form. If agreed upon, the questions will be asked.
In case you want to skip a certain question, this is not a problem and can be
notified. If you feel at any moment to withdraw from the interview, this can also
be done without giving any reasons and will not have any consequences.
When all questions have been answered to a satisfactory extent, there will be an
option for you to ask additional questions or give remarks that might have come
up during the interview. Furthermore, feedback about the interview can be
provided. When agreed upon, the audio recording will then be ended and the
interview is finished. The interview is expected to take about 30-45 minutes. If
any valuable managerial insights are discovered in the research, a copy can be
requested for your use.
Research context
This thesis research is about a relatively new concept in logistics: the Physical
Internet (PI). The aim of this concept is to improve efficiency in logistics, which
in turn promotes the sustainability of the systems served by PI. It uses smart,
green, modular containers, combined with an interconnected network of
warehouses, transport modes, and information sharing. Key requirements of PI
are (ADOM):
- Automation: processes should be automated as much as possible (truck
loading, information sharing, container decoupling, transportation etc).
- Decentralization: There is no one governing body that regulates the
system. Containers have the autonomy to determine their most efficient
route.
- Openness: the PI is open to everybody, and information should be
available when needed.
- Modularity: Goods can be packed in smart containers of many different
sizes, which can be interlocked/combined into one shipping unit (like a 20ft
container or TEU).

75
Pictures can say more than a thousand words, so videos can say even more.
Therefore, if you want to know more about the Physical Internet, you can open
the following link to watch a short YouTube video that describes this concept.
The Physical Internet - YouTube link
(https://www.youtube.com/watch?v=PJyzFaKOXnY&feature=youtu.be)
As information sharing is one of the main requirements of PI, collaboration efforts
and trust between stakeholders should be improved to ensure this. Especially
during times where data privacy and security becomes more apparent. The
objective is therefore to explore how to handle this expected ‘data explosion’.
A novel business model architecture that was proposed by several academics will
be examined. This model uses data sharing through a third party mediator
company. The mediator has to be trusted by all involved stakeholders, and gives
recommendations (based on a recommenders system) on information flows and
business partners that are optimal for the specific company, while having no
authority. This business model is part of the discussion.
Resultingly, the main research question is: how can data be shared effectively in
the Physical Internet, enabled by Enterprise Information Systems?
Thank you for reading the information sheet about this research. Hopefully
everything was clear up to this moment. If not, do not hesitate to contact me with
any questions you might have. If you are happy to participate, please continue to
the consent form on the next page.

76
Participant consent form for interviews Interviewee nr: _____
Before participating in the interview, please read the statements below and
confirm these by ticking the box. If all are confirmed, please sign below.
Statement Tick
1. I voluntarily participate in this interview.
2. I understand that the researcher can use (parts of) this interview for
his research.
3. I understand that this research will be publicly available.
4. I understand that I can withdraw at any time from the interview
without reason and consequences, even after signing this form.
5. I understand that I can withdraw my responses up until two weeks
after the interview. The data will then be terminated.
6. I understand that I am free to decline any question that I do not wish
to answer.
7. I confirm that I understand the information provided in the
information sheet above.
8. I have had the opportunity to ask questions about the information
sheet above.
9. I agree that the interview will be audio recorded for transcription
purposes.
10. I understand that the researcher provides complete security,
confidentiality and anonymity of all my data.
11. I understand that the anonymized data will be retained and can be
used for future research in this field.
Participant name: _____________________
Participant signature: Date: _____________
Researcher name: Mart Kreijkes
Researcher signature: Date: _____________
E-Mail: [email protected] Phone: +31614712504

77
Main interview questions
General / warm-up questions
1. Could you shortly introduce yourself?
a. Background
b. Education
c. Expertise
d. Work experience
e. Years in industry/function
2. Could you also introduce the company you work for? (if relevant)
a. Industry / market
3. What is your current role and responsibilities within this company?
a. Role
b. Responsibilities
c. Years in this role
4. Have you heard before about the concept of PI?
a. If yes, when, how, why?
b. If no, show video / describe the concept.
5. What are your first thoughts about this concept?
Specific questions:
Logistics companies (for logistics processes knowledge):
- Start with warm-up questions above.
- What do you see as important/recent developments in the logistics
industry?
- What challenges are there still?
- Could you describe the regular logistics processes for a shipment, going
from supplier to customer? (physical as well as information flows)
o What types of logistics data are you currently sharing with other
companies?
o Is data sharing done frequently, and how is this currently done
(which EIS?)?
o What issues do you currently experience related to data sharing?

78
o What kind of data do you need from others to work efficiently?
- How important is data security to you (your company)?
o Do you sometimes feel competitors/customers might have access to
valuable data via shipments?
- In what ways can trust be enhanced with other companies that you
collaborate with?
- Any experience with 3rd party companies/mediators for collaboration with
other companies?
- Would this model be something you would consider using?
- Would you trust the PI (container) to make optimal decisions for you?
Enterprise Information Systems (EIS) experts:
- Start with warm-up questions above.
- What systems (do you currently have that/are often used that) could
describe as EIS?
- What is your view on the flexibility of (these) EIS?
- What are the current best practices of EIS?
o What are their core abilities compared to ‘older’ EIS?
o How is data sharing addressed through EIS?
- What aspects of PI do you think touch (these) EIS?
- To what extend would it be possible to adjust (these) EIS to align with PI?
- What would the challenges be in this adjustment?
- Can you think of any developments that might help improve collaboration?
- How important is data security to you (your company)?
- In what ways can trust be enhanced with other companies that need your
data?
- Do you have any experience with third party companies regarding data
sharing?
o If yes, how do you feel about this?
o If no, do you think this might be helpful?
- What kind of EIS could be used for this third party type of collaboration?

79
Other stakeholders (customers/suppliers/hubs, retailers e.g.):
- Start with warm-up questions above.
- Could you describe your current logistics processes for a shipment?
o What types of logistics data are you currently sharing with other
companies?
o Is data sharing done frequently / how is this currently done (which
EIS?)?
o What are the reasons for sharing this data?
o What issues do you currently experience related to data sharing?
o What kind of data do you need from others to work efficiently?
- What are the latest developments you made in your logistics (digitally)?
o Anything related to Automation, Decentralization, Openness or
Modularity?
o To what extend did your EIS enable or hold back these
developments?
- How do you ensure smooth collaboration with other companies? (in logistics
context)
o In what ways do you improve collaboration?
o Do you have any experience with third party mediators?
- Would you trust the PI (container) to make optimal decisions for you?
o Would advise from a trusted third party company help with this?
Closure: Thank you for all the valuable answers, this will be very helpful for the
research. Is there anything else you would like to add before we end?

80
Appendix C - Code trees
Figure C1 - Coding tree I - methods of data sharing
Figure C2 - Coding tree II - types of data shared

81
Figure C3 - Coding tree III - reasons for sharing data (or not)
Figure C4 - Coding tree IV - challenges in data sharing