cis 629 parallel arch. intro parallel computer architecture slides blended from those of david...
Post on 21-Dec-2015
218 views
TRANSCRIPT

CIS 629 Parallel Arch. Intro
Parallel Computer Architecture
Slides blended from those of
David Patterson, CS 252 and
David Culler, CS 258
UC Berkeley

2CIS 629 Parallel Arch. Intro
Definition: Parallel Computer
•Definition: “A parallel computer is a collection of processiong elements that cooperate and communicate to solve large problems fast.”
Almasi and Gottlieb, Highly Parallel Computing ,1989
Role of a computer architect:
To design and engineer the various levels of a computer system to maximize performance and programmability within limits of technology and cost.

3CIS 629 Parallel Arch. Intro
Parallel Architecture Design Issues
–How large a collection of processors?–How powerful are processing elements?–How do they cooperate and communicate?–How are data transmitted between processors?–Where to put the memory and I/O? –What type of interconnection?–What are HW and SW primitives for programmer?–Does it translate into performance?

CIS 629 Parallel Arch. Intro 4
Is Parallel Computing Inevitable?
• Application demands: Our insatiable need for computing cycles
• Technology Trends
• Architecture Trends
• Economics
• Current trends:– Today’s microprocessors have multiprocessor support
– Servers and workstations becoming MP: Sun, SGI, DEC, COMPAQ!...
– Tomorrow’s microprocessors are multiprocessors

5CIS 629 Parallel Arch. Intro
Whither Parallel Machines?
• 1997, 500 fastest machines in the world: 319 MPPs, 73 bus-based shared memory (SMP), 106 parallel vector processors (PVP)
• 2000, 381 of 500 fastest: 144 IBM SP (~cluster), 121 Sun (bus SMP), 62 SGI (NUMA SMP), 54 Cray (NUMA SMP)

6CIS 629 Parallel Arch. Intro
Commercial Computing
• Relies on parallelism for high end– Computational power determines scale of business that can
be handled
• Databases, online-transaction processing, decision support, data mining, data warehousing

7CIS 629 Parallel Arch. Intro
Scientific Computing Demand

8CIS 629 Parallel Arch. Intro
Engineering Computing Demand
• Large parallel machines a mainstay in many industries
– Petroleum (reservoir analysis)
– Automotive (crash simulation, drag analysis, combustion efficiency),
– Aeronautics (airflow analysis, engine efficiency, structural mechanics, electromagnetism),
– Computer-aided design
– Pharmaceuticals (molecular modeling)
– Visualization
» in all of the above
» entertainment (films like Toy Story)
» architecture (walk-throughs and rendering)
– Financial modeling (yield and derivative analysis)
– etc.

9CIS 629 Parallel Arch. Intro
1980 1985 1990 1995
1 MIPS
10 MIPS
100 MIPS
1 GIPS
Sub-BandSpeech Coding
200 WordsIsolated SpeechRecognition
SpeakerVerification
CELPSpeech Coding
ISDN-CD StereoReceiver
5,000 WordsContinuousSpeechRecognition
HDTV Receiver
CIF Video
1,000 WordsContinuousSpeechRecognitionTelephone
NumberRecognition
10 GIPS
• Also CAD, Databases, …
Applications: Speech and Image Processing

10CIS 629 Parallel Arch. Intro
Summary of Application Trends
• Transition to parallel computing has occurred for scientific and engineering computing
• In rapid progress in commercial computing– Database and transactions as well as financial
– Usually smaller-scale, but large-scale systems also used
• Desktop also uses multithreaded programs, which are a lot like parallel programs
• Demand for improving throughput on sequential workloads
• Solid application demand exists and will increase

11CIS 629 Parallel Arch. Intro
Performance
0.1
1
10
100
1965 1970 1975 1980 1985 1990 1995
Supercomputers
Minicomputers
Mainframes
Microprocessors
Technology Trends
• What does this picture tell us?

CIS 629 Parallel Arch. Intro 12
0 1 2 3 4 5 6+0
5
10
15
20
25
30
l
l
ll l
0 5 10 150
0.5
1
1.5
2
2.5
3
Fraction of total cycles (%)
Number of instructions issued
Speedup
Instructions issued per cycle
How far will ILP go?
• Infinite resources and fetch bandwidth, perfect branch prediction and renaming
– real caches and non-zero miss latencies

13CIS 629 Parallel Arch. Intro
What about Multiprocessor Trends?
l
l
l
l
l
l
l
l
ll
l l
l l
l l
l
l
l
ll
l
l
l
l
l
l
0
10
20
30
40
CRAY CS6400
SGI Challenge
Sequent B2100
Sequent B8000
Symmetry81
Symmetry21
Power
SS690MP 140 SS690MP 120
AS8400
HP K400AS2100SS20
SE30
SS1000E
SS10
SE10
SS1000
P-ProSGI PowerSeries
SE60
SE70
Sun E6000
SC2000ESun SC2000SGI PowerChallenge/XL
SunE10000
50
60
70
1984 1986 1988 1990 1992 1994 1996 1998
Number of processors

CIS 629 Parallel Arch. Intro 14
Economics
• Commodity microprocessors not only fast but CHEAP– Development costs tens of millions of dollars
– BUT, many more are sold compared to supercomputers
– Crucial to take advantage of the investment, and use the commodity building block
• Multiprocessors being pushed by software vendors (e.g. database) as well as hardware vendors
• Standardization makes small, bus-based SMPs commodity
• Desktop: few smaller processors versus one larger one?
• Multiprocessor on a chip?

15CIS 629 Parallel Arch. Intro
Scientific Supercomputing
• Proving ground and driver for innovative architecture and techniques
– Market smaller relative to commercial as MPs become mainstream
– Dominated by vector machines starting in 70s
– Microprocessors have made huge gains in floating-point performance
» high clock rates
» pipelined floating point units (e.g., multiply-add every cycle)
» instruction-level parallelism
» effective use of caches (e.g., automatic blocking)
– Plus economics
• Large-scale multiprocessors replace vector supercomputers

16CIS 629 Parallel Arch. Intro
LINPACK (MFLOPS)
s
s
ss
s
s
u
u
u
uu
uuu
u
u u
1
10
100
1,000
10,000
1975 1980 1985 1990 1995 2000
s CRAY n = 100n CRAY n = 1,000
u Micro n = 100l Micro n = 1,000
CRAY 1s
Xmp/14se
Xmp/416Ymp
C90
T94
DEC 8200
IBM Power2/990MIPS R4400
HP9000/735DEC Alpha
DEC Alpha AXPHP 9000/750
IBM RS6000/540
MIPS M/2000
MIPS M/120
Sun 4/260
n
nn
n
n
n
l
l
l
l l
l ll
ll
l
Raw Uniprocessor Performance: LINPACK

17CIS 629 Parallel Arch. Intro
LINPACK (GFLOPS)
n CRAY peakl MPP peak
Xmp/416(4)
Ymp/832(8) nCUBE/2(1024)iPSC/860
CM-2CM-200
Delta
Paragon XP/S
C90(16)
CM-5
ASCI Red
T932(32)
T3D
Paragon XP/S MP(1024)
Paragon XP/S MP(6768)
n
n
n
n
l
l
nl
l
l
ll
l
ll
0.1
1
10
100
1,000
10,000
1985 1987 1989 1991 1993 1995 1996
Raw Parallel Performance: LINPACK
SIMD
MIMD

18CIS 629 Parallel Arch. Intro
Flynn Taxonomy of Parallel Architectures
• SISD (Single Instruction Single Data)– Uniprocessors
• MISD (Multiple Instruction Single Data)– none
• SIMD (Single Instruction Multiple Data)– Vector processors, data parallel machines– Examples: Illiac-IV, CM-2
• MIMD (Multiple Instruction Multiple Data)– Examples: Sun Enterprise 5000, Cray T3D, SGI Origin
» Flexible» Use off-the-shelf micros
• MIMD current winner: <= 128 processor

19CIS 629 Parallel Arch. Intro
Major MIMD Styles
1. Centralized shared memory ("Uniform Memory Access" time or "Shared Memory Processor")
2. Decentralized memory (memory module with CPU) • get more memory bandwidth, lower memory latency
• Drawback: Longer communication latency
• Drawback: Software model more complex

20CIS 629 Parallel Arch. Intro
Decentralized Memory versions
1. Shared Memory with "Non Uniform Memory Access" time (NUMA)
2. Message passing "multicomputer" with separate address space per processor– Can invoke software with Remote Procedue Call (RPC)
– Often via library, such as MPI: Message Passing Interface
– Also called "Syncrohnous communication" since communication causes synchronization between 2 processes

21CIS 629 Parallel Arch. Intro
Speedup
• Speedup (p processors) =
• For a fixed problem size (input data set), performance = 1/time
• Speedup fixed problem (p processors) =
Performance (p processors)
Performance (1 processor)
Time (1 processor)
Time (p processors)
22CIS 629 Parallel Arch. Intro
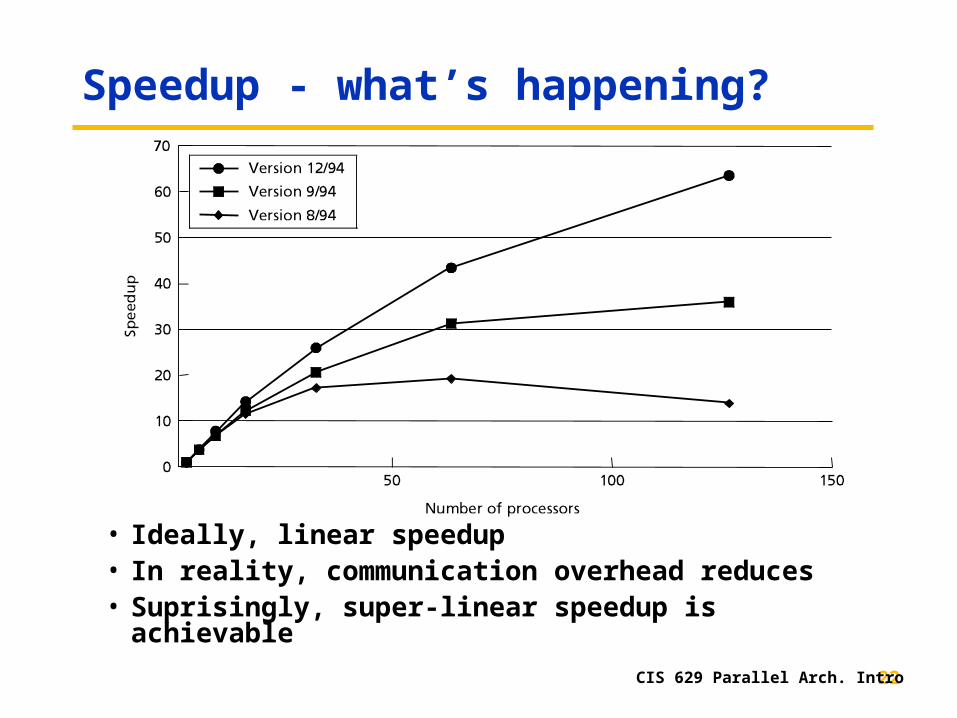
Speedup - what’s happening?
• Ideally, linear speedup• In reality, communication overhead reduces• Suprisingly, super-linear speedup is achievable

23CIS 629 Parallel Arch. Intro
Amdahl’s Law
• Most fundamental limitation on parallel speedup
• If fraction s of seq execution is inherently serial, speedup <= 1/s
• Example: 2-phase calculation– sweep over n-by-n grid and do some independent computation– sweep again and add each value to global sum
• Time for first phase = n2/p
• Second phase serialized at global variable, so time = n2
• Speedup <= or at most 2
• Trick: divide second phase into two– accumulate into private sum during sweep– add per-process private sum into global sum
• Parallel time is n2/p + n2/p + p, and speedup at best
2n2
n2
p + n2
2n2
2n2 + p2

24CIS 629 Parallel Arch. Intro
Amdahl’s Law
1
p
1
p
1
n2/p
n2
p
wor
k do
ne c
oncu
rren
tly
n2
n2
Timen2/p n2/p
(c)
(b)
(a)

25CIS 629 Parallel Arch. Intro
Concurrency Profiles
– Area under curve is total work done, or time with 1 processor– Horizontal extent is lower bound on time (infinite processors)
– Speedup is the ratio: , base case:
– Amdahl’s law applies to any overhead, not just limited concurrency
Concurrency
150
219
247
286
313
343
380
415
444
483
504
526
564
589
633
662
702
7330
200
400
600
800
1,000
1,200
1,400
Clock cycle number
fk k
fkkp
k=1
k=1
1
s + 1-sp

26CIS 629 Parallel Arch. Intro
Communication Performance Metrics: Latency and Bandwidth
1. Bandwidth– Need high bandwidth in communication– Match limits in network, memory, and processor– Challenge is link speed of network interface vs. bisection
bandwidth of network
2. Latency– Affects performance, since processor may have to wait– Affects ease of programming, since requires more thought to
overlap communication and computation– Overhead to communicate is a problem in many machines
3. Latency Hiding– How can a mechanism help hide latency?– Increases programming system burdern– Examples: overlap message send with computation, prefetch
data, switch to other tasks