chen zhang hans de sterck university of waterloo supporting multi-row distributed transactions with...
TRANSCRIPT

Chen ZhangHans De Sterck
University of Waterloo
Supporting Multi-row Distributed Transactions with Global Snapshot Isolation
Using Bare-bones HBase

OutlineIntroduction
General BackgroundSnapshot Isolation (SI) HBase
System DesignTransactional SI Protocol
System PerformanceFuture Work

General Background (1)Database transactions have been widely
used by websites, analytical programs, etc.Snapshot isolation (SI) has been adopted
by major DBMS for high throughputNo solution exists for traditional DBMS to be
easily replicated and scaled on cloudsColumn-oriented data stores are proven
to be scalable on clouds (BigTable, HBase). However, multi-row distributed transactions are not supported out-of-the-box

General Background (2)Google recently published a paper in
OSDI10, Oct. 4 (submission deadline May 7) about their “Percolator” system on top of BigTable for multi-row distributed transactions with SI
Our paper describes an approach for multi-row distributed transactions with SI on top of HBase, and it turns out that Google’s system has many design elements that are similar to ours

Snapshot Isolation (1)Snapshot Isolation (SI)
For transaction T1 that starts at timestamp ts1T1 is given the database snapshot up to ts1,
and T1 can do reads/writes on its own snapshot independently
When T1 commits, T1 checks to see if any other transactions have committed conflicting data updates. If not, T1 commits
Snapshot Isolation (2)
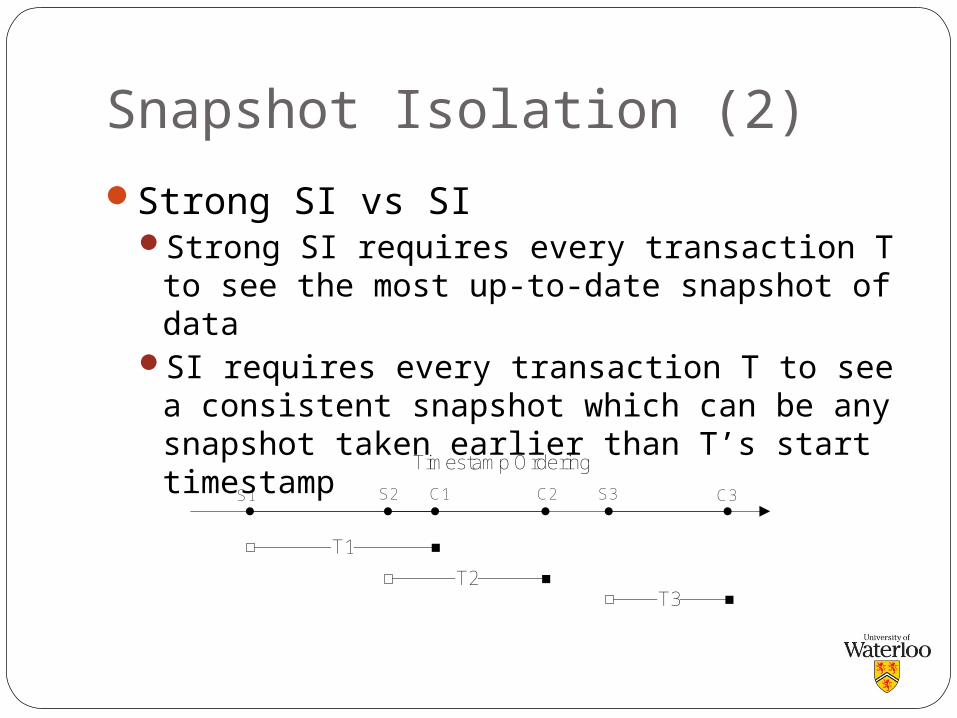
Strong SI vs SIStrong SI requires every transaction T to see
the most up-to-date snapshot of dataSI requires every transaction T to see a
consistent snapshot which can be any snapshot taken earlier than T’s start timestamp
T1
T2T3
Timestamp Ordering
S1 C1S2 C2 S3 C3

HBaseHBase is a column-oriented data store
A single global database-like table viewMulti-version data distinguished by timestampA data table is horizontally split into row regions
and each region is hosted by a region serverHBase guarantees single atomic row read/write

OutlineIntroduction
General BackgroundSnapshot Isolation (SI) HBase
System DesignTransactional SI Protocol
System PerformanceFuture Work

Design-Overview (1)General Design ObjectiveNo deployment of extra programs and
inherits HBase propertiesScalability, fault tolerance, high throughput,
access transparency, etc.Non-intrusive to user data and easy to be
adoptedNo modification to existing user data
Implement a client library to manage transaction at client side autonomously; no server-side changesTransactions put their own information into the
global tables Meanwhile query those tables for information
about other transactions to determine whether to commit/abort

Design-Overview (2)General SI Protocol
Every transaction, when it commits, obtains a unique, strictly incremental commit timestamp to determine the order between transactions and be used to enforce SI
Every transaction commits successfully by inserting a row in the Committed table
Every transaction, when it starts, read the commit timestamp of the most recently committed transaction, and use that as its start timestamp
T1
T2T3
Timestamp Ordering
S1 C1S2 C2 S3 C3

Design-Overview (3)Simplified Protocol WalkthroughGet start timestamp S, a snapshot of
Committed tableT reads/writes versions of data identified by SWhen T tries to commit
Checks conflicting updates committed by other transactions by scanning Committed table
T writes a row into Precommit table to indicate its attempt to commit
Checks conflicting commit attempts by scanning Precommit table
If both checks return no conflict, T proceeds to commit by atomically inserting one row to Committed table

Design-SI Protocol
For Read-only transactions: Only need to obtain start timestamp and read
the correct version of data from the snapshot No need to do Precommit/Commit
For Update transactions:Get start timestamp tsRead/writePrecommitCommit

Design-SI Protocol For Read-only Transaction TiGet start timestamp Si and maintain
DataSet DS in memoryData read {(L1, data1),…}
To read data item at L1If L1 is in DS, read from DS. OtherwiseQuery Version table and get C1Scan Committed table and get the most
recent transaction Ci that updates data to version V; update Version table with Ci
Use V to read data and add (L1, data) to DS if necessary

Design-SI Protocol For Update Transaction Ti (1)
Get start timestamp Si and maintain DataSet DSData read/written {(L1, data1),…}
Read data item at L1 (same as Read-only case)
WriteDirectly write to data tables with unique
timestamp Wi

Design-SI Protocol For Update Transaction Ti (2)
PrecommitGet precommit label PiScan Committed table at range [Si+1, ∞) for
conflicting commits with overlapping write set. If no conflicts, proceed
Add a row Pi to Precommit table. Scan Precommit Table at full range for other rows with overlapping writeset with either nothing under column “Committed” or a value under “Committed” column larger than Si. If no conflicts, proceed

Design-SI Protocol For Update Transaction Ti (3)
CommitGet Commit timestamp CiAdd a row Ci to Committed table with data
items in writeset as columns (HBase atomic row write)
Add “Ci” to row Pi in Precommit table
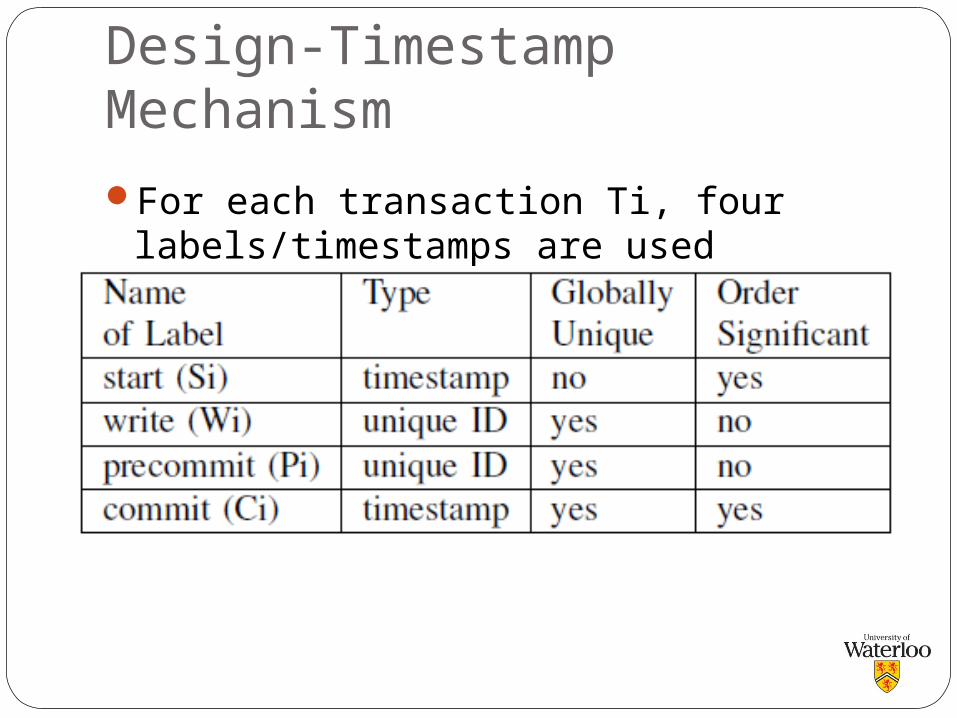
Design-Timestamp Mechanism
For each transaction Ti, four labels/timestamps are used

Design-Timestamp Mechanism
Issue globally unique and incremental timestamp/label by using the HBase atomic incrementColumnValue method on a single HBase Table

Design- Obtain Start TimestampFor example, at the time T1 starts, there is a
gap for C2 in Committed table
The snapshot for T1 is C3, which includes L1 with version W1, and L2 with version W3
Before T1 commits, C2 appears. The snapshot of T1 should have included L1 with version W2
Use CommittedIndex Table to store recent snapshot

OutlineIntroduction
General BackgroundSnapshot Isolation (SI) HBase
System DesignTransactional SI Protocol
System PerformanceFuture Work

Performance (1)
Test the basic timestamp/label issuing mechanism using a single HBase table
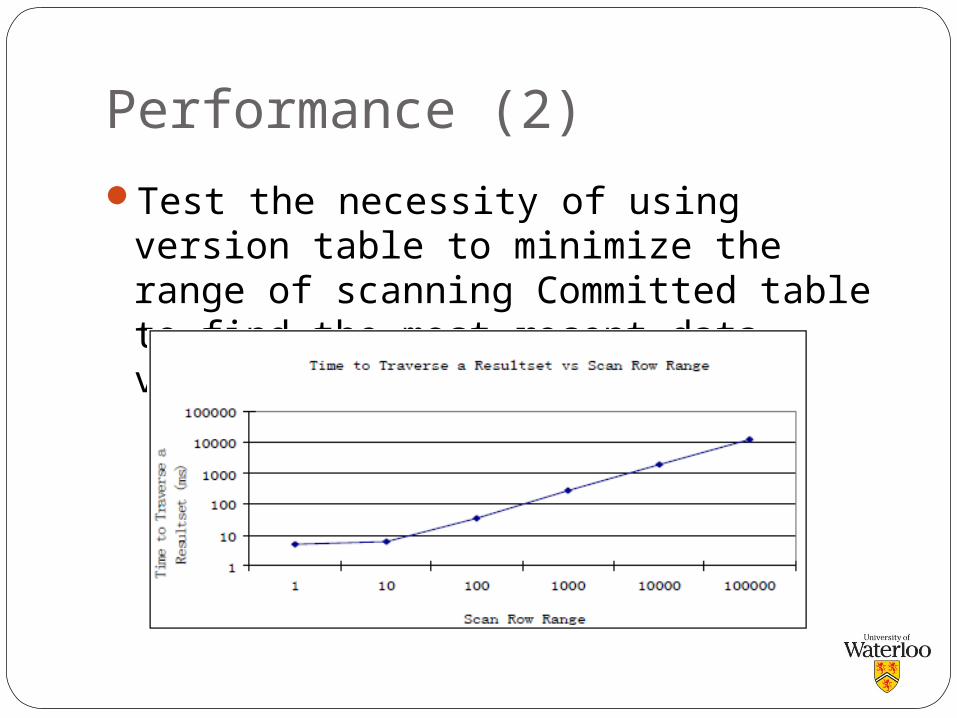
Performance (2)
Test the necessity of using version table to minimize the range of scanning Committed table to find the most recent data version
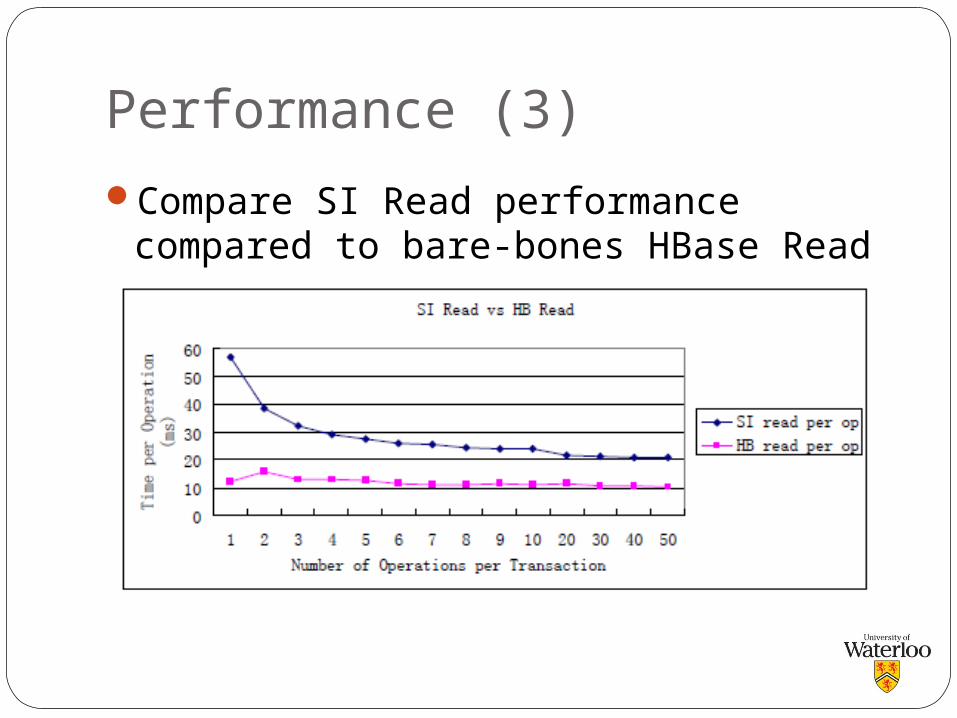
Performance (3)
Compare SI Read performance compared to bare-bones HBase Read

Performance (4)Compare SI Write performance
compared to bare-bones HBase Write

Future WorkSupport strong SI with no blocking reads
providing high throughput Add mechanism in handling
straggling/failed transactionsExplore and experiment with usage
application scenarios

General Background (3) Similarities-Compared with PercolatorSupport ACID transactions and guarantee
snapshot isolation utilizing the multi-version data support from the underlying column store
Implemented as client library rather than as server side middleware
Dispense globally unique and well-ordered timestamps from a central location
Share some similar protocols for the commit process

General Background (4) Differences-Compared with PercolatorPercolator focuses on analytical workloads that
tolerate large latency; our system focuses on random data access with high throughput and low latency for web applications
Percolator achieves Strong SI but reads may be blocking, sacrificing throughput to data freshness; our system achieves SI and does not block reads, sacrificing data freshness to high throughput
Percolator requires modification to existing user data; our system uses a separate set of tables, which is non-intrusive to user data
Percolator relies on BigTable single row atomic transaction which is not supported by HBase

Questions
Thank you!