chapter 8 inferential analysis of datashodhganga.inflibnet.ac.in/bitstream/10603/31029/15/15_chapter...
TRANSCRIPT

232
CHAPTER 8
INFERENTIAL ANALYSIS OF DATA
8.0 Chapter Overview
This chapter describes the inferential analysis of data. Inferential statistics try to infer
information about a population by formation of conclusions about the differences
between populations with regard to any given parameter or relationships between
variable. This chapter describes the different statistical tests applied to test the
hypothesis statistically
8.1 Introduction
The purpose of research is the discovery of general principles based upon the
observed relationship between variables (Best & Kahn, 2009). To achieve this
purpose, statistical analysis is done. In descriptive analysis; data are described with the
help of statistical measurements.
Description of data through mere descriptive analysis does not provide conclusive
results. It only helps to describe the properties of a specific sample under study. Thus
in order to obtain conclusive results, hypotheses formulated is tested in the research.
These hypotheses are tested statistically with the help of statistical techniques.
Inferential statistical techniques are used to test the hypotheses and on that basis it is
decided whether the hypotheses are accepted or rejected. This process of analysis that
follows description of data to provide conclusive results is called inferential analysis.
On the basis of these tests, generalization made to a certain sample group is extended
to the entire population and this process of extension is known as drawing inferences
on the basis of inferential analysis. Thus, an inferential analysis is aimed at testing of
hypothesis (Pandya, 2010).
Inferential statistics are used to make judgments about the probability that an observed
difference between groups is a dependable one or one that might happen by chance. In
this study with inferential statistics, one concludes that extend beyond the immediate
data alone. Thus, one uses inferential statistics to make inferences from our data to
more general conditions. Perhaps one of the simplest inferential tests is used when one
has to compare the average performance of two groups on a single measure to see if

233
there is a difference. Whenever one wishes to compare the average performance
between two groups one should consider the t-test for difference between groups.
Most of the major inferential statistics come from a general family of statistical model
known as the General Linear Model. This includes the t-test, Analysis of Variance
(ANOVA), Analysis of Covariance (ANCOVA), regression analysis and many of the
multivariate methods like factor analysis, multi-dimensional scaling, cluster analysis,
discriminate function analysis, population parameters from observing the sample
values.
8.2 Hypotheses
Hypotheses are educated guesses about possible difference, relationships or causes.
Hypotheses are statements of expectation about some characteristics of a population.
Etymologically, hypothesis are made up of two words, “hypo” (less than) and “thesis”
(less certain than thesis). It is the presumptive statement of a proposition or a
reasonable guess, based upon the available evidence, which the researcher seeks to
prove through his study.
Koul (2009), defines hypothesis as “a tentative or working proposition suggested as a
solution to a problem, and the theory as the final hypothesis which is defensibly
supported by all the evidence. The final hypothesis which fits all the evidence
becomes the chief conclusion inferred from the study (Koul, 2009).
According to Best and Kahn, a research hypothesis is a formal affirmative statement
predicting a single research outcome, a tentative explanation of the relationship
between two or more variables (Best & Kahn, 2009).
Simply stated, a hypothesis is an assumption or supposition to be proved or disproved.
It is a guiding idea, a tentative explanation or a statement of probabilities which serves
to initiate and guide observation, search for relevant data or considerations to predict
results or consequences. Hypotheses are measurable and testable. They are of various
types based on the manner in which they are tested.

234
Hypotheses are of two types:
Directional Hypothesis
Non-Directional Hypothesis
8.2.1 Directional Hypothesis
This hypothesis states a relationship between the variables being studied or a
difference between experimental treatments that the researcher expects to emerge.
Directional hypothesis can also be tested as a statistical hypothesis. However, a
statistical hypothesis can be stated in the directional form only when there is a
complete certainty that the findings will show a relationship or difference in the
expected direction. This is because the directional hypothesis can be tested using one-
tailed test of significance (Pandya, 2010).
8.2.2 Non-directional Hypothesis
If a given hypothesis do not indicate the nature of the relationship between two
variables (i.e. whether positive or negative) or it does not indicate the nature/direction
of differences between two or more groups on a variable (i.e. which group will
perform better) then it is known as the non-directional hypothesis.
In the present study, null hypothesis were formulated in order to study the information
literacy skills of student teachers and effect of intervention programs.
A null hypothesis is non-directional in nature, as it does not specify the direction of
differences between relationships among variables. According to Best and Kahn
(2009) the null hypothesis is related to a statistical method of interpreting conclusions
about population characteristics that are inferred from the variable relationships
observed in the sample (Best & Kahn, 2009).
Hypotheses are formed to study the existing conditions. Thus, the null hypothesis is
individually tested statistically in order to decide whether it should be accepted or
rejected.
8.3 Technique used for testing hypothesis
There are two types of statistical techniques which are used for testing of hypothesis.
They are parametric and non-parametric techniques.

235
Parametric Techniques: can be applied for the purpose of testing the hypotheses if the
following conditions are satisfied. (Pandya, 2010)
a. When the sample is randomly selected.
b. When the variances of the various groups are equal or near equal..
c. When the data are in the form of interval scale or ratio scale.
d. When the observations are independent.
e. When the sample size is more than 30.
f. When the data follow a normal distribution.
Non-parametric Techniques:
When the above conditions are not satisfied, the non-parametric techniques have to be
used. The non-parametric tests are population free tests, as they are not based on the
characteristics of the population. They do not specify normally distributed populations
or equal variances.
The techniques which enable us to compare samples and make inferences or tests of
significance without having to assume normality in the populations are known as non-
parametric techniques.
Some of the non-parametric techniques are the chi square test, the rank difference
correlation coefficient, the sign test, the median test and the sum-of-ranks test. The
non-parametric techniques don’t have the “power” of parametric tests; that is; they are
less able to detect a true difference when such is present. Non parametric tests should
not be used, therefore, when other more exact tests are applicable.
In the present study, normality of data was established through descriptive analysis of
the data in Chapter 7. The sample size was 386 for the first phase and 111 for the
second phase, which is large sample. Data have been collected randomly wherein
every individual had to respond independently. Since all the conditions required for
parametric tests were satisfied, the following techniques were employed.
1. t – test
2. ANOVA
3. ω2estimate

236
8.4 t-test
A t-test is used to compare the mean scores obtained by two groups on a single
variable (Pandya, 2010). The critical ratio test or t-test is used for two sample
difference of means. Here it was applied to determine the differences between means
of two scores obtained from the one group based on the two variables. It is very useful
when the population variance is not known and when the sample size is small.
The formula for estimating the t ratio following ANOVA test is:
M1 - M2
t = σ12
+ σ22
N1 N2
Where, M1 = Mean of the first sample
M2 = Mean of second sample
σ1 = Standard deviation of first sample
σ2 = Standard deviation of second sample
N1 = Sample size of the first sample
N2 = Sample size of the second sample
8.4.1 Interpretation of t-ratio:
If the calculated t is less than the tabulated values of t in table D at 0.05 or 0.01 levels
then the null hypothesis is accepted. If the calculated t is greater than the tabulated t at
0.05 or 0.01 levels then the null hypothesis is rejected. In the present study, if the
ANOVA value is significant the hypothesis is further subjected to t-test (Garrett,
1985).
8.5 Analysis of Variance: ANOVA
It is used for comparing more than two groups on a single variable. It is a collection of
statistical models and their associated procedures, in which the observed variance is
partitioned into components due to the explanatory variables (Pandya, 2010)
Analysis of variance or ANOVA is used for testing hypotheses about the difference
among three or more means. This technique is used when multiple sample cases are
involved. Through this technique the differences among the means of all the

237
populations can be investigated simultaneously. If a variance within and between the
groups are computed and compared it is known as one-way analysis of variance.
For the present study, ANOVA was used to find the difference in the mean between
three groups, which were arts, science and commerce and difference in the mean
between two groups of graduate degree and post graduate degree
For computing ANOVA,
First the variance of the scores of all the groups is combined into one known as the
total group variances (SST).
The mean value of the variance of each of the group is computed separately, known as
among mean variance (SSm).
The differences between the total group variances and the among mean variances is
calculated as the within group variances (SSW).
F= Among mean variance
Within group variance
Steps for ANOVA:
1. Correction Factor =CF
2. CF= ∑
3. Total sum of square (SST) = ∑ − CF
4. Total sum of squares among mean variance (SSm) = ∑
+
∑
+
∑
− CF
5. Within groups variance (SSw)= SSt − SSm
6. Mean Square Variance (MS)
For among mean variance = (SSm) df= (K-1) where K is the number of groups.
df
For within groups variance = (SSw) df= (N-K) where N is the total sample.
Df
Interpretation of F- ratio:
The numerical value of F- ratio thus obtained is compared against table F values, with
the degree of freedom (K-1, N-K). If the obtained F is more than the tabulated value
of F at 0.05 or 0.01 levels then F is said to be significant at 0.05 or 0.01 levels
respectively and the null hypotheses are rejected. If the obtained F is less than the

238
tabulated F then, F is termed not significant and the null hypotheses are accepted.
When the ANOVA is significant then each pair of means is subjected to t-test to
determine which pair of means differ significantly. The present study had made use of
Vassar Stat software available online to calculate ANOVA.
8.6 ω2estimate
If the F - ratio in ANOVA is found to be significant the ω2estimate is calculated which
indicates the percentage of variance in the dependent variable compared on the basis
of the independent variable (Guilford & Fruchter, 1981). Its formula is as follows:
ω2est = ( K-1)(F-1)
(K-1) (F-1) +N
Where,
F = F-ratio
K= Number of groups
N= Total sample size
and
100ω2 = Percentage of variance in the dependent variable that is associated with the
independent variable
8.7 Testing of Hypothesis:
Phase 1
8.7.1 Testing of hypothesis 1
1. There is no significant difference in the information literacy skills of student teacher
from the
a) Arts faculty
b) Science faculty
c) Commerce faculty
The statistical technique used to test this hypothesis is one way classification of
ANOVA.
The following table shows ANOVA for information literacy scores of student teachers
on the basis of their faculty at graduation.
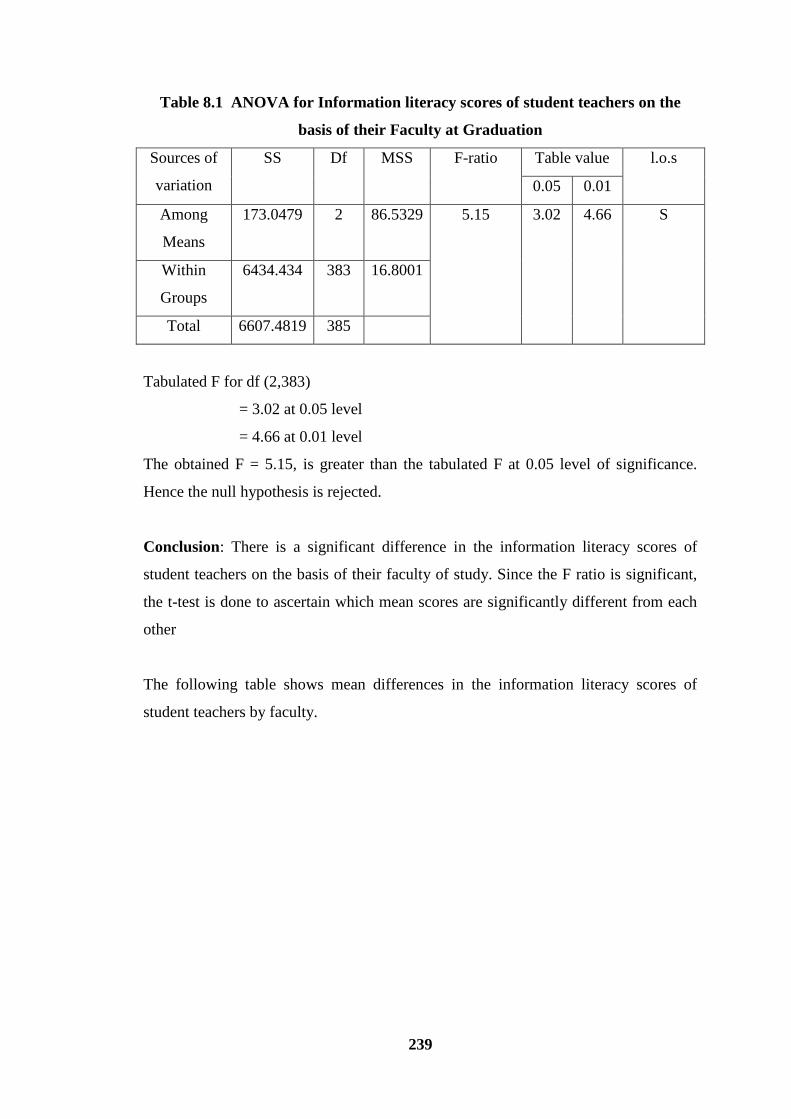
239
Table 8.1 ANOVA for Information literacy scores of student teachers on the
basis of their Faculty at Graduation
Sources of
variation
SS Df MSS F-ratio Table value l.o.s
0.05 0.01
Among
Means
173.0479 2 86.5329 5.15 3.02 4.66 S
Within
Groups
6434.434 383 16.8001
Total 6607.4819 385
Tabulated F for df (2,383)
= 3.02 at 0.05 level
= 4.66 at 0.01 level
The obtained F = 5.15, is greater than the tabulated F at 0.05 level of significance.
Hence the null hypothesis is rejected.
Conclusion: There is a significant difference in the information literacy scores of
student teachers on the basis of their faculty of study. Since the F ratio is significant,
the t-test is done to ascertain which mean scores are significantly different from each
other
The following table shows mean differences in the information literacy scores of
student teachers by faculty.

240
Table 8.2 Mean Differences in the Information literacy skills of student teachers
by Faculty
No Groups N Df Mean S.E.D Table value t-
ratio
l.o.s 1002
0.05 0.01
1 Arts 182 287 13.79 0.480
1.97
2.59
1.04
N.S
-
Commerce 107 14.29
2 Arts 182 275 13.79 0.5046
1.97
2.59
3.269
0.01
3.35
Science 97 15.44
3 Commerce 107 202 14.29 0.557
1.97
2.60
0.897
NS
-
Science 97 13.79
It can be seen from the preceding table that the mean information literacy skills of
student teachers from the arts and commerce faculties, arts and science faculties and
student teachers from commerce and science faculties significantly differ from each
other, with student teachers from science faculty being the highest, followed by those
from the commerce and arts faculties respectively i.e. student teachers from the
science faculty have higher information literacy skills compared to the student
teachers from commerce and arts faculty.
Interpretation of ‘t’
1. The obtained t = 1.04 for differences in information literacy skills in arts and
commerce faculties is less than 1.97 at 0.05 level of significance and hence not
significant at 0.05 level. The null hypothesis is therefore accepted.
2. The obtained t = 3.269 for differences in information literacy skills in arts and
science faculties is greater than 2.59 at 0.01 level of significance and it is
significant; hence, the null hypothesis is rejected.
3. The obtained t = 0.897 for differences in information literacy skills in science
and commerce faculties is less than 1.97 at 0.05 level of significance and
hence not significant at 0.05 level. The null hypothesis is therefore accepted.

241
Conclusion
1. There is no significant difference in the information literacy skills of student
teachers from arts and commerce faculties.
2. There is a significant difference in the information literacy skills of student
teachers from arts and science faculties. The information literacy skills of
student teachers from arts and science faculties differ significantly.
Information literacy skills of student teachers from science faculty are higher
than information literacy skills of student teacher of arts faculty. 3.35% of
variance in information literacy skills is associated with the type of facility.
3. There is no significant difference in the information literacy skills of student
teachers from the Science and commerce faculties.
Discussion
The difference in the information literacy skills scores of Arts, Science and Commerce
could have arisen due to the fact that science students are learning by doing, i.e. they
perform practical and gain knowledge by doing experiments themselves. In addition to
this they have to do projects and presentation as a part of their syllabus. Similarly they
have to keep themselves updated about the current discoveries in their field of study.
This helps in enhancement of their information literacy skills. Since the study of the
commerce and arts is limited to self whereby they learn by reading literature,
philosophy, history, preparing accounts, statistics etc. which limits their interaction
with the rest of the world and this has a direct impact on their information literacy
skills.
Figure 8.1 Bar Graph for student teachers Information literacy skills by Faculty
13.79
15.44
13.79
12.5
13
13.5
14
14.5
15
15.5
16
Arts Science Commerce
Mea
n S
core
s
Information Literacy skills by Faculty
Arts Science Commerce

242
8.7.2 Testing of hypothesis 2
The null hypothesis states that
There is no significant difference in the information literacy skills of student teachers
with
a) graduate degree
b) post graduate degree
The statistical technique used to test this hypothesis is one way classification of
ANOVA.
The following table shows ANOVA for information literacy skills of student teachers
on the basis of their degree.
Table 8.3 ANOVA for Information literacy scores of student teachers on the
basis of their Degree
Sources of
variation
SS df MSS F-ratio Table value l.o.s
0.05 0.01
Among
Means
28.7381 1 28.7381 1.68 3.86 6.70 NS
Within
Groups
6578.7438 384 17.1321
Total 6607.4819 385
Tabulated F for df (1,384)
= 3.86 at 0.05 level
= 6.70 at 0.01 level
The obtained F = 1.68, is lesser than the tabulated F at 0.05 AND 0.01 level of
significance. Hence the null hypothesis is accepted

243
Interpretation of F ratio
The obtained F = 1.68 for differences in information literacy skills in student teachers
with graduate and post graduate degree is less than 3.86 at 0.05 level of significance
and hence not significant at 0.05 level. The null hypothesis is therefore accepted
Conclusion: There is no significant difference in the information literacy scores of
student teachers on the basis of their degree of study.
Phase 2
8.7.3 Testing of hypothesis 3
The null hypothesis states that
There is no significant difference in the pre-test scores on information literacy skills of
student teachers in control and experimental group.
Table 8.4 Relevant Statistics of Pre-test Information literacy skill scores of
Experimental and Control Group
Variable Group N Df Mean SD Table
value
T
value
Los
.05 .01
Information
Literacy
Skills
Experimental
65 109 13.661 3.894
1.98
2.63
0.71
ns
Control
46 13.239 2.368
df = total N – 2 = 111-2 = 109
From Table D, for df = 109 NS = not significant
Tabulated t = 1.98 at 0.05 level l.o.s = level of significance
= 2.63at 0.01 level
Interpretation of t:
The obtained value of ‘t’ for Information literacy skill is 0.71 which is smaller than
the table value 1.98 at the 0.05 level of significance is and 2.63 at 0.01 level of
significance. The obtained value of t is 0.71 which is less than both the tabulated
value for both levels of significance. Hence the null hypothesis is accepted.

244
Conclusion
There is no significant difference in the Information literacy skills scores of control
and experimental group, i.e. both the groups are on the same level. Thus it can be said
that student teachers from both the experimental and control groups are nearly similar
in their information literacy skills. Hence it assures that both the groups were similar
before administering the pre-tests consisting of information literacy skills as well as
implementation of the treatment. i.e. information literacy instruction program.
8.7.4 Testing of hypothesis 4
The null hypothesis states that
There is no significant difference in the post test scores on information literacy skills
of student teachers in control and experimental group.
Table 8.5 Relevant statistics of Post-test Information literacy skills scores of
Experimental and Control group
Variable Group n Df mean sd Table
value
T
value
Los
.05 .01
Information
Literacy
Skills
Experimental
65 109 17.538 3.894
1.98
2.63
5.543
S
Control
46 12.97 4.534
df = total N – 2 = 111-2 = 109 l.os = level of significance
From Table D, for df = 109 S = Significant
Tabulated t = 1.98 at 0.05 level
= 2.63 at 0.01 level
From the table it can be seen that for df = 67, the table value at 0.05 level of
significance is 1.98 and at 0.01 level of significance is 2.63. The obtained value of t is
5.543 which is more than tabulated values for 0.01 levels of significance. Hence the
null hypothesis is rejected.

245
Conclusion
There is a significant difference in the post- test information literacy skills scores of
the control group and the experimental group after exposing them to the Information
literacy instruction program.
Figure 8.2 Graphical Representation of the Mean score of Information literacy
skills Post-test of Experimental and Control group
0
2
4
6
8
10
12
14
16
18
20
EXPERIMENTALGROUP
CONTROL GROUP
Mea
n S
core
s
Groups
EXPERIMENTAL GROUP CONTROL GROUP

246
8.7.4 Testing of hypothesis 5
The null hypothesis states that
There is no significant effect of the treatment on students’ information literacy skills
post-test scores when the differences in the pre-test scores of the two groups have
been controlled.
Conclusion: There is a significant difference in the post-test information literacy
scores when the differences in the pre-test scores have been controlled. The post-test
information literacy scores of experimental group is higher as compared to the post-
test information literacy scores of the control group when the difference in the pre test
have been controlled. Thus it can be said that there was significant effect of the
treatment on students’ information literacy scores. Hence the null hypothesis is
rejected. In order to estimate the effect and size of treatment Wolf’s formula was
applied
8.8 Estimating the magnitude and the effect of the size of treatment
The magnitude and the effect size of treatment have been estimated by using Wolf’s
formula
Wolf’s formula for computing the effect size is as given below
The effect size of the experiment by applying Wolf’s formula:
Where
d = Magnitude of Effectiveness of experiment
M1 = Mean score of the dependent variable of the experimental group
M2 = Mean score of the dependent variable of the control group
SD = standard deviation of the dependent variable of the control group
The following criteria provided by Wolf’s have been used for interpreting the
results.
Magnitude size Effect Size
0.2 Minimum effect
0.5 moderate effect
0.8 Maximum effect

247
If the obtained D is greater than 0.8, it indicated that there have been maximum effect
of the treatment of the students.
Table 8.6 Effect of Information literacy skills Instruction Module (Independent
Variable) on Information literacy skills (Dependent Variable)
Dependent
Variable
Experimental
Gr. Mean
Control
Gr.
Mean
Control
Gr. SD
Effect Effect
Conclusion
Information
Literacy
skills
17.538 12.97 4.534 1.00 High
Findings and Conclusions
The effect size of treatment on information literacy skills program is 1.0, which means
there is high effect of treatment on enhancement of information literacy skills of
student teachers of the experimental group.
Interpretation
The treatment i.e. the information literacy instruction module developed by the
researcher for the enhancement of information skills among the student teachers of the
experimental group was effective. It means student teachers have gained the
knowledge and understanding of the research process and research skills to a large
extent.

248
8.9 Phase 3 Analysis of the Research Project
Phase three of the study involved analysis of the research project to assess the extent
of usage of information literacy skills in the preparation of the research project.
65 project reports of the students from the experimental college were analyzed to the
extent of usage of information literacy skills. Analyses of the project were done on the
basis of the model i.e. A Portfolio Assessment Model developed by NJIT. This model
included four independent variables based on the standards given by ACRL. Brief
information of the four variables follows:
Citation: According to this model, citing sources so that they could be found was
more important than strict adherence to a standard citation style. If all the elements
necessary to easily locate a referenced work are present and clear, it would seem to be
strong evidence that a student understood the particular attributes of a source, even if
the punctuation or capitalization might not conform to standard documentation
systems sponsored by MLA or APA. If students were to cite used sources in this
fashion, they would achieve competence in ACRL Performance outcomes 2.5, c and
D that is competence would be exhibited if students differentiated between types of
sources and included all pertinent information in the varying cases so that sources
could be retrieved by a reader without undue burden. For example, in the case of a
print source, the place of publication of a book is not as important to locate it as the
date of publication. Finally, consistently following proper citation style and usage for
both text and cited works compiled with ACRL standard 5, because such adherence is
evidence that the student acknowledges the intellectual property right issues
surrounding the information use in our society.
Evidence of Research: Evidence was sought in a student project that relevant research
had been conducted that went beyond the syllabus and sources recommended by the
instructor. If the student sought ideas from a variety of additional sources to become
truly informed about the topic in hand, it would be good evidence that ACRL
Standards 1 and 2 were being met. Additionally, papers with little variety or diversity
of sources in scope, subject and format were less likely to have been well researched.
Appropriateness: Did students choose sources that were not only relevant, but had a
high probability of being accurate and authoritative? If so, they were meeting
standards 1 and 3. Standard 1 and 3 require that information literate students evaluate
information and its sources critically and inferentially, incorporate selected
information into both a knowledge base and value system. If students were able to use

249
outside information as part of the knowledge base on which the essay was developed,
these standards are met.
Integration: Did students integrate the information found in the argument of the paper
or where the citations pasted in to fulfil a source requirement? Evidence of integration
would include the use of concepts from outside sources to build a foundation,
compare, contrast and refute arguments- that is, to use sources in a fashion that were
not merely cosmetic. The use of in text citations relevant to the concepts and
arguments made would be taken as further evidence of integrative ability. This
variable was also intended to assess the degree to which a student was able not only to
summarize the main ideas from sources consulted, but synthesize ideas to construct
new concepts. To meet standard 4- to use “information effectively to accomplish a
specific purpose” – the sources cited would be used reflectively in the paper. For
instance, if a student was able to use outside information as part of the knowledge
base on which the essay was developed, that student would meet ACRL Performance
indicator 4.1
Analysis of the Report
Based on the criteria suggested by the Portfolio Assessment model, researcher
scrutinize the research projects submitted by students. On the basis of the analysis
overall information literacy score was given on the 6 point Likert type scale. Only 10
research projects submitted by the students were found to demonstrate an acceptable
level of information literacy skills whereas 55 projects submitted by the students were
found to demonstrate below average information literacy skills.
Interpretation
Results indicate that only 15.38% of the research projects had made use of the
information literacy skills learnt during the information literacy instruction.
Observations
While analyzing the research report of the student it was observed that
1. Students with particular guides were following a common format.
2. Arrangement of the bibliography was not alphabetical
3. There was review of related literature and recent reviews were missing.
4. There were not more than ten references in a project.

250
8.10 Summary
The chapter on inferential analysis discussed the results obtained from the statistical
analysis for accepting or rejecting the hypothesis of the study. The next chapter will
discuss the data through pre-test post-test analysis.