chapter 7 (strickberger) from molecules to life … · eees 4150/5150, evolution sigler 1 chapter 7...
TRANSCRIPT

EEES 4150/5150, Evolution Sigler
1
Chapter 7 (Strickberger)
FROM MOLECULES TO LIFE Organisms depended on processes that transformed materials available outside of the cell into metabolic products necessary for cellular life. These processes in early organisms probably depended on heat to provide reactive energy. However, heat was not reliable, consistent, or efficient. Reactions were more or less explosive, oxidative, uncontrolled and unreliable. Over time, evolving cells/protocells gained the ability to use more controlled energy sources. Chemical energy providers – ATP (adenosine triphosphate). Energy was released in small amounts as needed. BUT Many of these reactions were slow. Shifting to chemical energy systems meant that catalysts would be necessary to facilitate energy expenditure. What were these catalysts? Example: ENZYMES (proteins) Catalyst/enzyme absent reaction proceeds slowly. Catalyst/enzyme present reaction proceeds quickly. Example – degradation of H2O2 by inorganic ferric Fe (Fe3+)

EEES 4150/5150, Evolution Sigler
2
Fe3+ alone can decompose H2O2 into H2O and O2 (rate = 1X)
When Fe3+ binds with heme, the reaction becomes 1000x more efficient
When Fe3+/heme binds with the enzyme catalase, the efficiency increases by a further 10,000,000x.
How did such proteins evolve?
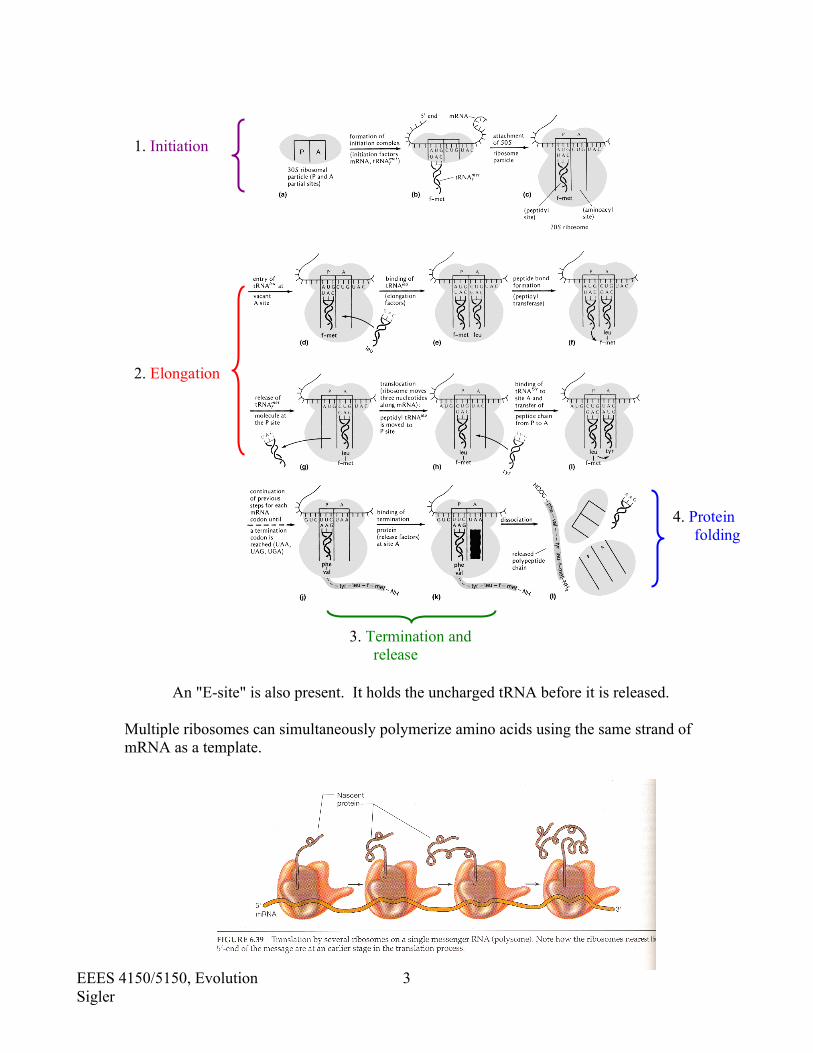
PROTEIN SYNTHESIS REVIEW The DNA sequence determines the mRNA sequence (transcription), which ultimately serves as a template for the polymerization of amino acids in a process called translation. The ultimate, proper structure and function of any protein (enzyme or structural) depends on the correct sequence of amino acids, which are linked together by the action of ribosomes. Protein synthesis occurs in four discrete steps. 1. Initiation 2. Elongation 3. Termination and release 4. Protein folding
EEES 4150/5150, Evolution Sigler
3
An "E-site" is also present. It holds the uncharged tRNA before it is released.
Multiple ribosomes can simultaneously polymerize amino acids using the same strand of mRNA as a template.
1. Initiation
2. Elongation
3. Termination and release
4. Protein folding

EEES 4150/5150, Evolution Sigler
4
How could the development of this trait (multiple ribosomes working on same transcript) have given certain organisms an advantage over those that did not have this capacity?
Question: What could happen to the protein structure if a mutation in the original DNA sequence was carried through transcription and translation and altered the correct amino acid sequence?
WHICH CAME FIRST, PROTEINS OR NUCLEIC ACIDS? Today, all amino acid sequences for enzymes that serve as catalysts derive from the nucleotide sequences in RNA (nucleic acid), which are coded by sequences of DNA (nucleic acid). At the same time, the chain of nucleic acid information transfer (DNA> DNA> RNA> protein) is entirely dependent on appropriate enzymes (proteins).

EEES 4150/5150, Evolution Sigler
5
Question: How could these functional and information systems evolve independently of each other?
One theory: protein systems developed before a dependence on nucleic acid template systems.
Evidence 1– proteins possess a greater number of functionally different forms than nucleic acids. Therefore, many functional structures could have arisen by chance.
Example: the relatively high diversity possible in protein structures: Twenty amino acid alternatives exist for each position in a polypeptide chain
(remember, only 4 exist for nucleic acids). Therefore, a sequence of 5 amino acids has 205, or more than 3 million possible arrangements.
Lots of potential functional diversity in proteins with short amino acid
sequences. A sequence of five nucleic acid bases can have 45, or 1024, possibilities.
This diversity in proteins was likely facilitated by the structures of the 20 amino acids, which are much more different from each other than the structures of the four nucleic acid bases.

EEES 4150/5150, Evolution Sigler
6
More diverse interactions with each other. More diverse interactions with other compounds. Water, metal ions, polymers, etc.
It makes sense that such diverse molecules might be the progenitor to today’s primary information molecule.
In this scenario, the functions were of primary importance and the information transfer was secondary.
Evidence 2- Experiments conducted under pre-biological conditions showed that chains of polypeptides are much easier to produce spontaneously than polymers of nucleic acids nucleotides.
However, the sustained synthesis of useful proteins would rely on system by which new proteins could be quickly produce when needed, i.e., via a template system, and not by chance.

EEES 4150/5150, Evolution Sigler
7
Therefore another, alternative prevailing theory is that the early world was an RNA world (not DNA…discussed later), as opposed to a protein world, where RNA served as a template . But how would the nucleic acids replicate...need enzymes for this.
Perhaps nucleic acids that exhibited self-replicating ability arose first.
A possibility: Auto-catalytic nucleic acids Some RNA molecules possess catalytic activity in the absence of proteins. These are called RNA catalysts or ribozymes – short pieces of RNA that
can catalyze reactions without the help of other enzymes. Page 130 in your book provides ample evidence in support of the RNA world theory. Arguments against the “RNA-world” theory:
1. Ribose can assume multiple conformations called “stereoisomers”…some of
these forms would not allow for an appropriate structure of the ribose sugar backbone of early nucleic acids.
This would have prevented accurate complementary base pairing.
2. Ribose is extremely unstable (hydrolytic cleavage at 2’ -OH), so a consistent supply was likely unavailable.
Argument against the argument: Perhaps ribose-like analogs that did not exhibit isomerism were the backbone of the nucleic acid chain.
Paring difficulties would be minimized. These analog substrates could have been more stable and more easily found than ribose.

EEES 4150/5150, Evolution Sigler
8
EVOLUTION OF PROTEIN SYNTHESIS Amino acids have no catalytic function in an unpolymerized form. Therefore the polymerization process used for condensing amino acids into
polypeptides must have been selected for early in evolution. Using heat and poor energy sources, this process was inefficient and non-
reproducible. So, how could the first efficient protein systems have evolved? 1. Once the process of amino acid polymerization was established, selection likely lead to
biomolecules that exhibited improved polymerization efficiency.
- Adaptor molecules (early tRNA?) evolved that were important for bringing the amino acids to a…
- polymerizing enzyme (an early ribosome?). 2. Both the template (RNA) and adaptor molecules (early tRNA) might have both been capable of
recognition, which would help the early, inefficient polymerizing enzyme.
3. If the early polymerizing enzyme was in fact “ribosome-like”, it likely contained nucleotides as part of its structure, as today’s ribosomes are made up of proteins and rRNA.
These RNA nucleotide sequences might have served as sites for adaptor molecule (tRNA)- amino acid complex attachment, i.e. complementarity.
These would have stabilized tRNA molecules as amino acid were placed into the growing polypeptide.
An X-ray structure of a bacterium ribosome. The rRNA-molecules are colored orange, the proteins of the small subunit are blue and the proteins of the large subunit are green.

EEES 4150/5150, Evolution Sigler
9
Nucleotides in the RNA were complementary to other, free, available
nucleotides. Represents a primitive replication mechanism. Therefore… 4. Replicating nucleotide sequences formed “master” nucleic acid molecules.
Stored as the early “genetic material”.
Later, these differentiated into the three functional classes (all likely RNA, not DNA yet)
1. Storage
2. Messenger 3. Translational (ribosomal and transfer) 5. Organisms later developed the use of DNA as the genetic information storage material.
DNA probably came after RNA (we know that DNA can be synthesized from RNA via a process called reverse transcription).
Later organisms had an advantage because DNA is more stable than RNA, therefore using DNA provides a better storage strategy for important genetic information.
Remember, the structural difference; a 2’ H in DNA instead of a 2’ OH in RNA.
2’ OH is a target for hydrolysis.

EEES 4150/5150, Evolution Sigler
10
However, there is one problem: early enzymes (no matter how they might have come about) were few in number Considering the high number of processes needed to sustain early life, what problem might that have lead to? Question: We established that four nucleotide bases were enough to provide adequate diversity in
nucleic acid sequences (Chapter 6). Can you think of another reason why only four nucleotide bases make up our base choices? Why not more?
Inefficient enzyme systems were likely susceptible to selecting incorrect bases when replicating nucleic acids, which would lead to mutations.
RNA polymerases especially, as opposed to DNA polymerases, lack any proofreading activity, so errors were probably common. More bases to choose from = a greater chance to pick the wrong one. High mutation frequency would limit genetic material to short sequences. Produces inefficient, potentially nonfunctional, enzymes.
Answer: A limited number of bases to choose from will limit the likelihood of non-specific and inefficient early enzyme systems picking the wrong one.
Therefore, to limit errors in an error-prone system, four bases provided adequate genetic diversity while limiting error propagation. Remember, early enzyme systems were inefficient, non-specific, and error-prone. Following the evolution of the basic protein synthesis machinery…: 1. Evolution selected for several, self-contained ribosomes featuring ever-increasing efficiency
(relatively). It also continued to use a nucleotide-based mechanism in adapter molecules (early tRNA), selected by a ribosome according to the mRNA transcript sequence.
Likely, the number of differing ribosomes was great (make a lot of different ribosomes,
and one might just work) and each was associated with producing a specific protein. So, each protein (enzyme) was synthesized by its own, specific type of
ribosome?
What’s wrong with that?
EEES 4150/5150, Evolution Sigler
11
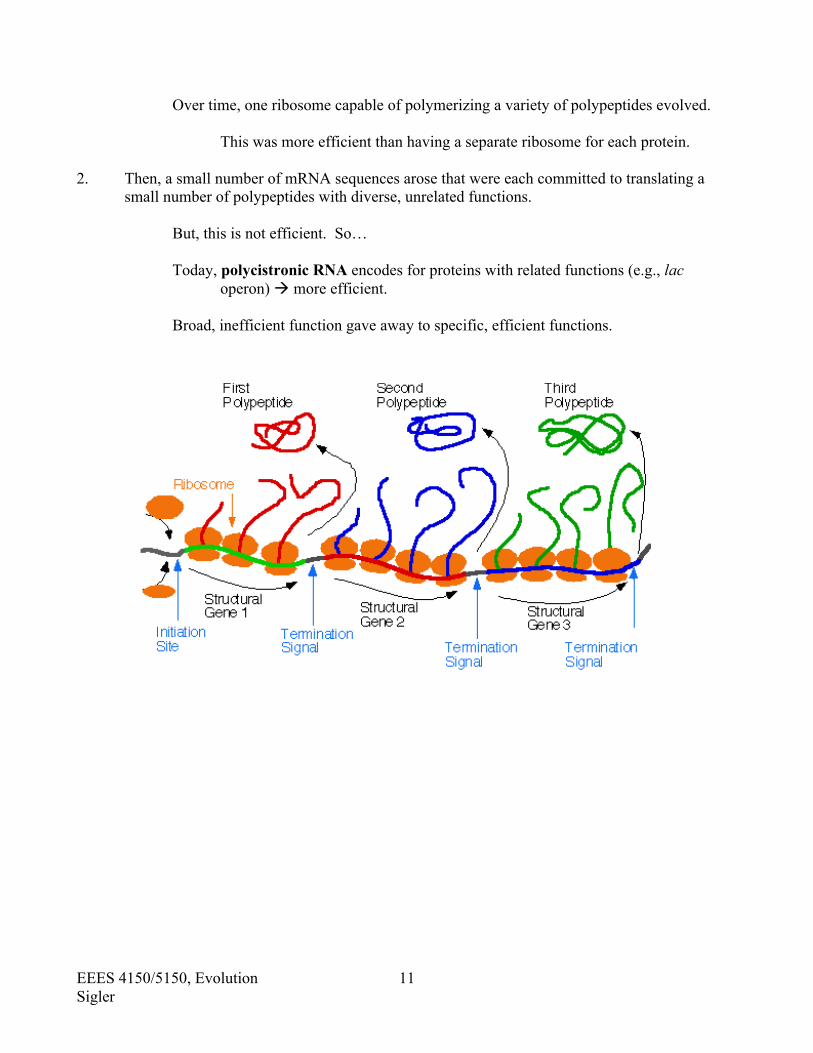
Over time, one ribosome capable of polymerizing a variety of polypeptides evolved.
This was more efficient than having a separate ribosome for each protein.
2. Then, a small number of mRNA sequences arose that were each committed to translating a small number of polypeptides with diverse, unrelated functions.
But, this is not efficient. So…
Today, polycistronic RNA encodes for proteins with related functions (e.g., lac operon) more efficient.
Broad, inefficient function gave away to specific, efficient functions.

EEES 4150/5150, Evolution Sigler
12
EVOLUTION OF THE GENETIC CODE The information transfer between nucleic acids and proteins is dependent on a genetic code. The code insures the correct sequence of the 20 amino acids in the growing polypeptide chain.
The genetic code:

EEES 4150/5150, Evolution Sigler
13
This represents today’s genetic code, but this code likely evolved from a more primitive precursor. What do we know about today’s code?
1. mRNA molecules contain four bases: A,C,G,U and vary in length and sequence.
Why uracil??
RNA needs to be short-lived (why?). The high water solubility (and thus fast degradation) of uracil keeps RNA from accumulating.
The methylation of uracil creates thymine (found in DNA), which is less
soluble, and therefore more stable.
2. The descriptive coding unit of mRNA is called a codon, which is a three-nucleotide word. Each codon is read by the ribosome in a continuous, non-overlapping manner from start
to finish, resulting in the “sentence” or the translation of the gene sequence. The “reading frame” defines which three nucleotides are read as a codon. Consider the RNA sequence AGUCAUUAGGGC:
AGU CAU UAG GGC Vs.
A GUC AUU AGG GC Vs.
AG UCA UUA GGG C
EEES 4150/5150, Evolution Sigler
14
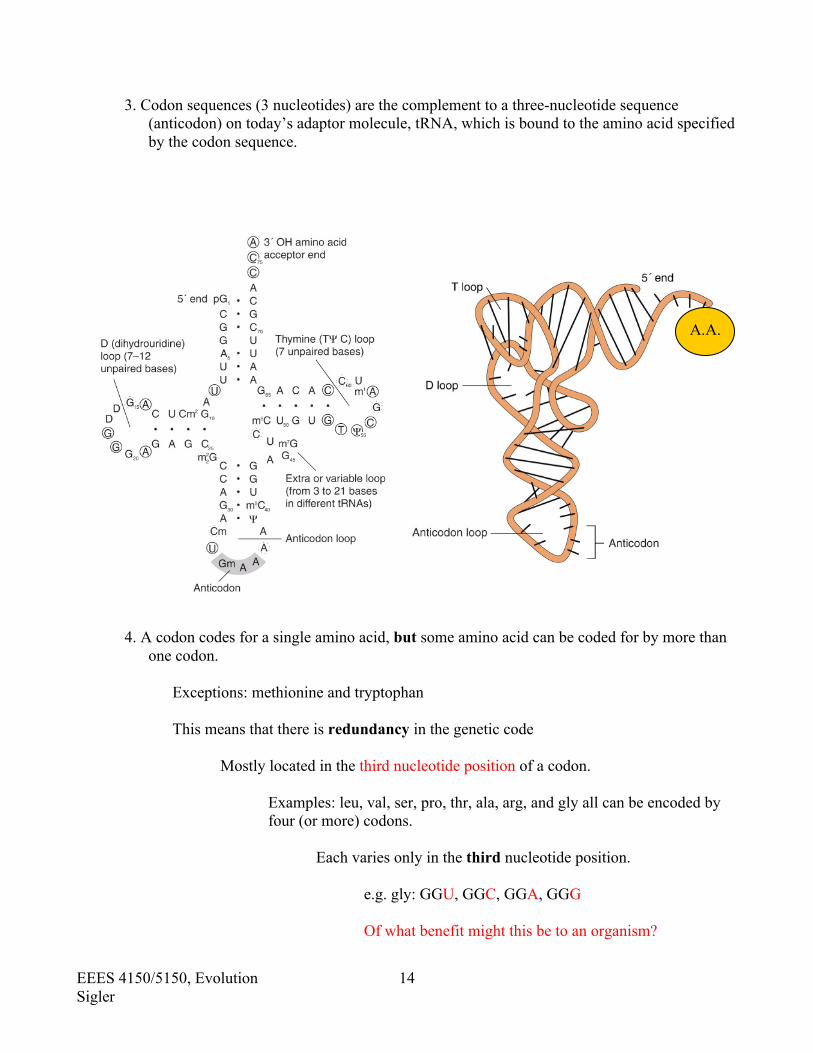
3. Codon sequences (3 nucleotides) are the complement to a three-nucleotide sequence (anticodon) on today’s adaptor molecule, tRNA, which is bound to the amino acid specified by the codon sequence.
4. A codon codes for a single amino acid, but some amino acid can be coded for by more than
one codon.
Exceptions: methionine and tryptophan This means that there is redundancy in the genetic code Mostly located in the third nucleotide position of a codon.
Examples: leu, val, ser, pro, thr, ala, arg, and gly all can be encoded by four (or more) codons.
Each varies only in the third nucleotide position. e.g. gly: GGU, GGC, GGA, GGG Of what benefit might this be to an organism?
Complementary to the codon.
A.A.

EEES 4150/5150, Evolution Sigler
15
WHY THIS PARTICULAR CODE?
Four bases, taken three at a time (43), give 64 possible codons. These codons can be used in 1070 different ways to code for 21 entities (20 amino acids and 1 stop signal.
It is likely that many codes came about by chance throughout evolution and only one code survived.
Possibilities of an early code:
An early hypothesis: Today’s code derived from a prior code that used less than three nucleotides per codon.
Singlet code = each of the nucleotide bases encodes for a single amino acid.
Gives three amino acids plus “stop” signal? (four “codons”) OR Doublet code = pairs of bases encode each amino acid.
Gives 15 amino acids plus “stop” signal? (16 “codons”) BUT
Four amino acids (one for each codon) are not enough to provide adequate protein diversity. Likely too radical of transition for the organism to change from single to double to triple nucleotide systems.
Each subsequent system would encode too much “new” information.
eg., AU-GA-GC to AUG-GAU-GCC is a big change to handle.
Another hypothesis: Early genetic code was a doublet code with the third position occupied by a “spacer”.
The “spacer theory” is supported by physio-spacial considerations.
Three nucleotides are needed for
adequate stability in tRNA-mRNA pairing.

EEES 4150/5150, Evolution Sigler
16
Another hypothesis: Early codes used a four- or five nucleotide codon system. However, this would result in attractions too strong for rapid decoupling of the codons
from anticodons following synthesis. Also would leave too much space for efficient coupling of amino acids. So, the three-codon system was appropriate, as it satisfied physical, chemical and amino acid diversity
considerations. Today’s code probably evolved under three selective conditions…all have something to do with redundancy. 1. Nucleotide substitutions (eg. A instead of G) caused by mutations (replication errors or mutagens)
should produce as few changes, as possible, in the chosen tRNA/amino acids. Redundancy in the genetic code (above) facilitates this requirement. An incorrect nucleotide in the mRNA sequence (especially in the third position of a
codon) might not be problematic. leu: CUU, CUG, CUA, CUT This redundancy also “uses up” the code, which reduces the number of potential stop
codons that might be formed by mutation. tyr: UAC, UAU vs.
STOP: UAA, UAG, UGA i.e., it might be better to have the wrong amino acid than a STOP signal.
2. The number of codons that code for a specific amino acid should be proportional to the frequency of
those amino acids in the resulting proteins.
A proportional arrangement does exist although the reasons surrounding why the relationship exists is unclear.
Comparison between observed and expected frequencies of amino acids.

EEES 4150/5150, Evolution Sigler
17
3. Errors occurring during translation should result in minimal protein changes. Limited by redundancy at the third nucleotide position in the codon. Most translational errors occur here, so this makes sense. Errors also occur at the first codon position…therefore…
The code also shows some redundancy at the first position to enable the coding of the same amino acid:
UUA – leu CUA – also leu… …or the redundancy enables the error to code for an amino acid with similar
structure/function. UUA – leu GUA – val
EARLY VERSIONS OF THE GENETIC CODE
Version 1: codon quartets specified each amino acid. Each amino acid was represented by only one tRNA molecule whose anticodon could pair with
all four codons in a quartet where the first two nucleotides were common. Would allow 15 AA and a STOP codon. In this scenario, only the first two bases in the codon were important. Could also support the “spacer theory”.

EEES 4150/5150, Evolution Sigler
18
Version 2: Duplication in tRNA genes allowed new anticodons to evolve (the tRNAs would mutate and then be able to accommodate new amino acids that were not previously usable for protein synthesis). Example: The gene for an early tRNA molecule with the anticodon AAU (phe) could have been
duplicated (cell now carries more than one copy). Before the duplication, the original AAU tRNA would pair with anticodons
UUA, UUC, UUG and UUU.
Following gene duplication, perhaps the duplicated gene mutated, producing anticodon AAG (phe).
The original AAU tRNA then binds only with UUA and UUG (today’s leu), while the new AAG can pair with UUU and UUC (phe).
Presents the opportunity for new amino acids to be bound to tRNAs and an expansion
of the number of anticodon- amino acid pairs to the 20 that we have today.

EEES 4150/5150, Evolution Sigler
19