chapter 5: cpu schedulingdefine : 3. ,0 1 2. predicted value for the next cpu burst 1. actual lenght...
TRANSCRIPT

Silberschatz, Galvin and Gagne ©2005Operating System Concepts –7th Edition, Jan 14, 2005
Chapter 5: CPU SchedulingChapter 5: CPU Scheduling

NCHU System & Network LabNCHU System & Network Lab
OutlineOutline
•Basic Concepts•Scheduling Criteria•Scheduling Algorithms•Multiple-Processor Scheduling•Real-Time Scheduling•Thread Scheduling•Operating Systems Examples•Java Thread Scheduling•Algorithm Evaluation

Silberschatz, Galvin and Gagne ©2005Operating System Concepts –7th Edition, Jan 14, 2005
Basic ConceptsBasic Concepts

NCHU System & Network LabNCHU System & Network Lab
Basic ConceptsBasic Concepts
•Maximum CPU utilization obtained withmultiprogramming–CPU scheduling is the basis of multiprogramming
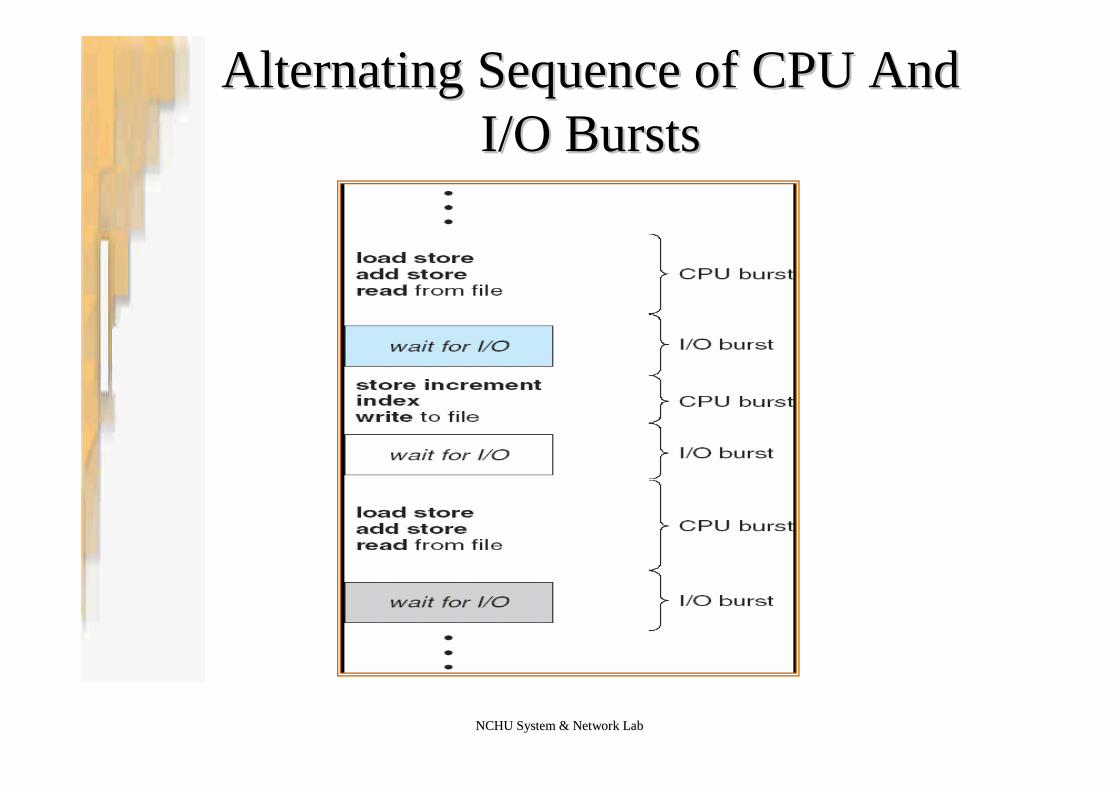
•Key to the success of CPU scheduling–CPU–I/O Burst Cycle –Process execution consists of a
cycle of CPU execution and I/O wait•CPU burst, I/O burst, CPU burst, I/O burst……
–CPU burst distribution –usually a large number of shortCPU bursts and a small number of long CPU bursts•I/O bound: has many short CPU bursts•CPU-bound: have a few long CPU burst
NCHU System & Network LabNCHU System & Network Lab
Alternating Sequence of CPU AndAlternating Sequence of CPU AndI/O BurstsI/O Bursts

NCHU System & Network LabNCHU System & Network Lab
Histogram of CPUHistogram of CPU--burst Timesburst Times

NCHU System & Network LabNCHU System & Network Lab
CPU SchedulerCPU Scheduler
•Selects from among the processes in memory that are ready toexecute, and allocates the CPU to one of them
•CPU scheduling decisions may take place when a process:–Switches from running to waiting state–Switches from running to ready state–Switches from waiting to ready state–Terminates
•Nonpreemptive or cooperative scheduling–When scheduling takes place only under 1 and 4–Process keeps the CPU until it releases the CPU
•Preemptive scheduling–All others are preemptive–A process having obtained the CPU may be forced to release the CPU

NCHU System & Network LabNCHU System & Network Lab
DispatcherDispatcher
•Dispatcher module gives control of the CPU to theprocess selected by the CPU scheduler
•This involves:–Switching context–Switching to user mode–Jumping to the proper location in the user program to
restart that program
•Dispatch latency –time it takes for the dispatcher tostop one process and start another running–Should be as fast as possible

NCHU System & Network LabNCHU System & Network Lab
Scheduling CriteriaScheduling Criteria
•CPU utilization –keep the CPU as busy as possible•Throughput –# of processes that complete their
execution per time unit•Turnaround time –amount of time to execute a
particular process•Waiting time –amount of time a process has been
waiting in the ready queue•Response time –amount of time it takes from when a
request was submitted until the first response isproduced–For interactive processes, we may not care the turnaround
time

NCHU System & Network LabNCHU System & Network Lab
Scheduling Criteria (Cont.)Scheduling Criteria (Cont.)
•Optimization Criteria -- may be conflict–Max CPU utilization–Max throughput–Min turnaround time–Min waiting time–Min response time
•In real cases…–Minimize the variance in the response time (predictable)–Minimize the average waiting time

Silberschatz, Galvin and Gagne ©2005Operating System Concepts –7th Edition, Jan 14, 2005
Scheduling AlgorithmsScheduling Algorithms

NCHU System & Network LabNCHU System & Network Lab
FirstFirst--Come, FirstCome, First--Served (FCFS)Served (FCFS)SchedulingScheduling
•Ready queue is a FIFO queue•Example:
Process CPU Burst TimeP1 24P2 3P3 3
•Suppose that the processes arrive in the order: P1 , P2 , P3•The Gantt Chart for the schedule is:
–Waiting time for P1 = 0; P2 = 24; P3 = 27–Average waiting time: (0 + 24 + 27)/3 = 17
P1 P2 P3
24 27 300

NCHU System & Network LabNCHU System & Network Lab
FirstFirst--Come, FirstCome, First--Served (FCFS)Served (FCFS)Scheduling (Cont.)Scheduling (Cont.)
•Suppose that the processes arrive in the order: P2 , P3 , P1
•The Gantt chart for the schedule is:–Waiting time for P1 = 6; P2 = 0; P3 = 3–Average waiting time: (6 + 0 + 3)/3 = 3–Much better than previous case
•Convoy effect: all the other processes wait for the one bigprocess to get off the CPU–Result in lower CPU and device utilization
•FCFS scheduling is nonpreemptive–Unsuitable for time-sharing systems
P1P3P2
63 300

NCHU System & Network LabNCHU System & Network Lab
ShortestShortest--JobJob--First (SJF) SchedulingFirst (SJF) Scheduling
•Use the of next CPU burst lengths to schedule theprocess with the shortest CPU burst time
•Should be termed as: shortest-next-CPU-burstalgorithm–Depend on the length of next CPU burst of a process, not
total length•Two schemes:
–nonpreemptive –once CPU given to the process it cannotbe preempted until completes its CPU burst
–preemptive –if a new process arrives with CPU burstlength less than remaining time of current executingprocess, preempt.•Sometimes called the Shortest-Remaining-Time-First (SRTF)

NCHU System & Network LabNCHU System & Network Lab
Example of NonExample of Non--Preemptive SJFPreemptive SJF

NCHU System & Network LabNCHU System & Network Lab
Example of Preemptive SJFExample of Preemptive SJF

NCHU System & Network LabNCHU System & Network Lab
ShortestShortest--JobJob--First (SJF) SchedulingFirst (SJF) Scheduling(Cont.)(Cont.)
•SJF is optimal –gives minimum average waiting time for agiven set of processes
•Problem: cannot be implemented in CPU scheduler–No way to know the length of the next CPU burst
•Sol.: predict–by using the length of previous CPU bursts, using exponential
averaging
:Define4.10,3.
burstCPUnexttheforvaluepredicted2.
burstCPUoflenghtactual1.
1n
thn nt

NCHU System & Network LabNCHU System & Network Lab
Examples of Exponential AveragingExamples of Exponential Averaging
•=0–n+1 = n
–Recent history does not count
•=1–n+1 = tn
–Only the actual last CPU burst counts•If we expand the formula, we get:
n+1 = tn+(1 - )tn -1 + …+(1 - )jtn -j + …+(1 - )n +10
•Since both and (1 - ) are less than or equal to 1,–Each successive term has less weight than its predecessor

NCHU System & Network LabNCHU System & Network Lab
Priority SchedulingPriority Scheduling
•A priority number (integer) is associated with eachprocess
•The CPU is allocated to the process with the highestpriority (smallest integer highest priority)–Preemptive–nonpreemptive
•Problem: starvation–Low priority processes may never execute
•Solution : aging–As time progresses increase the priority of the process

NCHU System & Network LabNCHU System & Network Lab
Example of Priority SchedulingExample of Priority Scheduling
Process Burst Time PriorityP1 10 3P2 1 1P3 2 4P4 1 5P5 5 2
P5 P3P2
6 190
P4
161
P1
18
Average Waiting Time = 8.2

NCHU System & Network LabNCHU System & Network Lab
Round Robin (RR)Round Robin (RR)•Each process gets a small unit of CPU time (time quantum)
–Usually 10-100 milliseconds.– After this time has elapsed, the process is preempted.
• If there are n processes in the ready queue and the timequantum is q,–Each process gets 1/n of the CPU time in chunks of at most q time units
at once.–No process waits more than (n-1)q time units.
•Performance–q large FIFO–q small q must be large with respect to context switch, otherwise
overhead is too high•Rule of thumb: 80% of CPU bursts should be shorter than the
time quantum

NCHU System & Network LabNCHU System & Network Lab
Example: RR with Time QuantumExample: RR with Time Quantum= 20= 20

NCHU System & Network LabNCHU System & Network Lab
How a Smaller Time QuantumHow a Smaller Time QuantumIncreases Context SwitchesIncreases Context Switches

NCHU System & Network LabNCHU System & Network Lab
Turnaround Time Varies With TheTurnaround Time Varies With TheTime QuantumTime Quantum

NCHU System & Network LabNCHU System & Network Lab
Multilevel Queue SchedulingMultilevel Queue Scheduling•Ready queue is partitioned into separate queues:
–According to process properties and scheduling needs– foreground (interactive) and background (batch)
•Normally, processes are permanently assigned to one queue•Each queue has its own scheduling algorithm, for example
– foreground –RR–background –FCFS
•Scheduling must be done between the queues–Fixed priority scheduling: serve all from foreground then from
background.•Possibility of starvation.
–Time slice –each queue gets a certain amount of CPU time which itcan schedule amongst its processes•Example: 80% to foreground in RR and 20% to background in FCFS

NCHU System & Network LabNCHU System & Network Lab
Multilevel Queue SchedulingMultilevel Queue Scheduling

NCHU System & Network LabNCHU System & Network Lab
Multilevel Feedback QueueMultilevel Feedback Queue
•A process can move between the various queues•Idea
–Separate processes with different CPU-burstcharacteristics
–A process waiting too long in a lower-priority queue maybe moved to a higher-priority queue
•Thus–Leave I/O-bound and interactive processes in the higher-
priority queues

NCHU System & Network LabNCHU System & Network Lab
Example of Multilevel FeedbackExample of Multilevel FeedbackQueueQueue
•Three queues:–Q0 –RR with time quantum 8 milliseconds–Q1 –RR time quantum 16 milliseconds–Q2 –FCFS
•Scheduling–A new job enters queue Q0 which is served RR.
•When it gains CPU, job receives 8 milliseconds.•If it does not finish in 8 milliseconds, job is moved to queue Q1.
–At Q1 job is again served RR and receives 16 additionalmilliseconds.•If it still does not complete, it is preempted and moved to queue Q2.

NCHU System & Network LabNCHU System & Network Lab
Multilevel Feedback QueuesMultilevel Feedback Queues

NCHU System & Network LabNCHU System & Network Lab
MultipleMultiple--Processor SchedulingProcessor Scheduling
•CPU scheduling more complex when multiple CPUs areavailable–Separate vs. common ready queue–Load sharing
•Asymmetric multiprocessing –only the master processhandle the scheduling algorithm and accesses the system datastructures
•Symmetric Multiprocessing (SMP) –each processor makesits own scheduling decisions–Access and update a common data structure–Must ensure two processors do not choose the same process–Windows, Linux, Mac OS

NCHU System & Network LabNCHU System & Network Lab
Processor AffinityProcessor Affinity
•Processor Affinity–When process migrates to another processor
•Cache memory must be invalidated and re-populated
–Most SMP systems avoid migration of processfrom one processor to another•Attempt to keep a process running on the same
processor

NCHU System & Network LabNCHU System & Network Lab
Load BalancingLoad Balancing
•Keep the workload evenly distributed across allprocessors
•Two approaches–Push migration
•A specific task periodically checks the load on each processor•If imbalance, push processes from overloaded to idle or less-busy
processor–Pull migration
•An idle process pulls a waiting task from a busy processor–Can be implemented in parallel
•But loading balancing counteracts the benefits ofprocessor affinity

NCHU System & Network LabNCHU System & Network Lab
Symmetric MultithreadingSymmetric Multithreading
•Symmetric multithreading–Create multiple logical processors on the same
physical processor
–A feature provided in architecture, not software
–Hyperthreading technology on Intel processor

NCHU System & Network LabNCHU System & Network Lab
A SMT ArchitectureA SMT Architecture
To the OS, four processors are available

NCHU System & Network LabNCHU System & Network Lab
Thread SchedulingThread Scheduling
•Process-contention scope–Local Scheduling –How the threads library
decides which thread to put onto an available LWP
•System-contention scope–Global Scheduling –How the kernel decides
which kernel thread to run next

Silberschatz, Galvin and Gagne ©2005Operating System Concepts –7th Edition, Jan 14, 2005
Operating System ExamplesOperating System Examples
Solaris schedulingWindows XP scheduling
Linux scheduling

NCHU System & Network LabNCHU System & Network Lab
Solaris SchedulingSolaris Scheduling
•Priority-based process scheduling–Classes: real time, system, time sharing, interactive
–Each class has different priority and schedulingalgorithm

NCHU System & Network LabNCHU System & Network Lab
Solaris SchedulingSolaris Scheduling

NCHU System & Network LabNCHU System & Network Lab
Windows XP SchedulingWindows XP Scheduling
•Priority-based preemptive scheduling•32-level priority scheme
–Variable (1-15) and real-time (16-31) classes, 0(memory manage)
–A queue for each priority.•Traverses the set of queues from highest to lowest until
it finds a thread that is ready to run–Run the idle thread when no ready thread–Base priority of each priority class
•Initial priority for a thread belonging to that class

NCHU System & Network LabNCHU System & Network Lab
Windows XP PrioritiesWindows XP Priorities
Relative priority
Priority class
Base priority

NCHU System & Network LabNCHU System & Network Lab
Linux SchedulingLinux Scheduling
•Preemptive, priority-based scheduling with twopriority ranges–Real-time: 0~99–Nice (for time-sharing): 100~140
•Time-sharing: dynamic priority-based–The runqueue consists of tasks that are ready to run–Consists of active array and expired array–Priority is changed depends on task’s interactivity
•Real-time: static priority-based–FCFS and RR–Highest priority process always runs first

NCHU System & Network LabNCHU System & Network Lab
The Relationship Between Priorities andThe Relationship Between Priorities andTimeTime--slice lengthslice length

NCHU System & Network LabNCHU System & Network Lab
List of Tasks Indexed According toList of Tasks Indexed According toPrioritiesPriorities

Silberschatz, Galvin and Gagne ©2005Operating System Concepts –7th Edition, Jan 14, 2005
Algorithm EvaluationAlgorithm Evaluation

NCHU System & Network LabNCHU System & Network Lab
Algorithm EvaluationAlgorithm Evaluation
•Define the criteria for evaluation and comparison–Ex. Maximize CPU utilization under the constraint that the
maximum response time is 1 second•Evaluation methods
–Deterministic modeling–Queuing models–Simulations–Implementation
•Environment in which the scheduling algorithm isused will change–Your algorithm is good today, but still good tomorrow?

NCHU System & Network LabNCHU System & Network Lab
Deterministic ModelingDeterministic Modeling
•Analytic evaluation ––(algorithm) + (workload) = (number of formula)–This number is used to evaluate the performance of the
algorithm for that workload–Deterministic modeling is one analytic evaluation
•Deterministic modeling ––Takes a particular predetermined workload and defines the
performance of each algorithm for that workload–Require exact numbers for input, and answers apply
only to the input

NCHU System & Network LabNCHU System & Network Lab
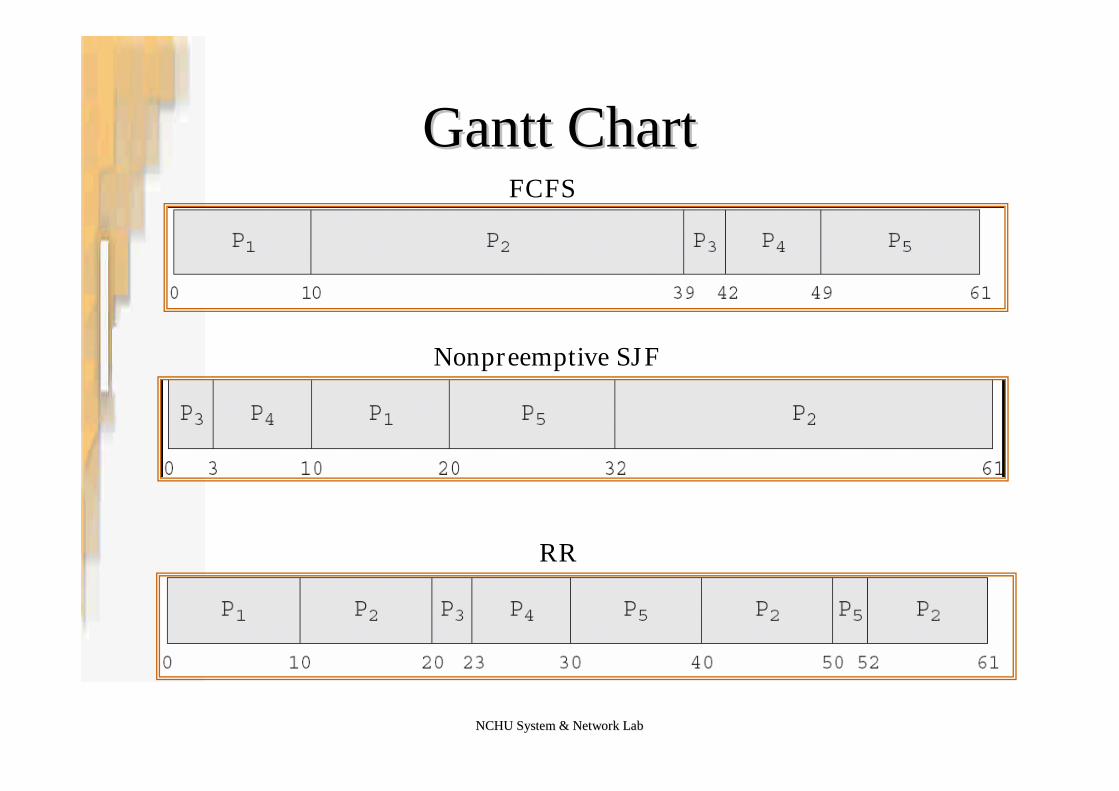
Example of Deterministic ModelingExample of Deterministic Modeling
•Example:–CPU burst time: P1 = 10, P2 = 29, P3 = 3, P4 = 7,
P5 = 12–Algorithm evaluations
•If FCFS, average waiting time = 28•If nonpreemptive SJF, average waiting time = 13•If RR, average waiting time = 23•In this case, nonpreemptive SJF is the best•Similar to what we have done in this Chapter
–Simple, fast, and give exact numbers
NCHU System & Network LabNCHU System & Network Lab
Gantt ChartGantt ChartFCFS
Nonpreemptive SJF
RR

NCHU System & Network LabNCHU System & Network Lab
QueueingQueueing ModelsModels
•Input:–Distribution of CPU and I/O bursts–Distribution of process arrival time
•Output: compute the average throughput,utilization, waiting time…–Mathematical and statistical analysis
•Approximation of a real system –accuracymay be questionable

NCHU System & Network LabNCHU System & Network Lab
SimulationsSimulations
•Programming a model of the computer system–Use software data structure to model queues, CPU,
devices, timers…•Data to drive the simulation
–Random-number generator according toprobability distributions•Processes, CPU- and I/O-burst times, arrivals/departures
–Trace tape –the usage logs of a real system•Disadvantage –expensive

NCHU System & Network LabNCHU System & Network Lab
Evaluation of CPU Scheduler byEvaluation of CPU Scheduler bySimulationSimulation

NCHU System & Network LabNCHU System & Network Lab
ImplementationImplementation
•Code a scheduling algorithm, put it in OS, and see…•Put the actual algorithm in the real system for
evaluation under real operating conditions•Difficulty
–High cost•Coding the algorithm and modifying the OS•Reaction of the users to a constantly changing OS
–Environment in which the algorithm is used will change•Good solutions
–Flexible scheduling algorithm that can be altered by thesystem managers or users to tune
–Use APIs that modify the priority of a process or thread