chapter 2 a methodology for text-based medicinal...
TRANSCRIPT

33
CHAPTER 2
A METHODOLOGY FOR TEXT-BASED MEDICINAL
PLANTS’ INFORMATION RETRIEVAL
In Chapter 1, we have introduced certain applications of
computers connected to the research work carried out. The literature
survey revealed that inspite of computers used in various fields such
as agriculture, horticulture and forestry, we do not have standard
databases on images of medicinal plants. India has rich treasure of
medicinal plants spread across the country. These medicinal plants
have disease healing properties. Hence, this Chapter deals with the
development of a methodology for text-based information retrieval
from a developed medicinal plant’s database.
2.1 NECESSITY OF MEDICINAL PLANT’S DATABASE
At present, we find a renewed interest in traditional system of
medicine, known as Ayurveda. India has rich repository of medicinal
plants. A proper care is needed to conserve, domesticate and use the
medicinal plants. The efforts are on to improve Ayurveda and
naturopathy as alternate systems of medicine. There is a proverb,
prevention is better than cure. To keep ourselves healthy and to
prevent diseases the knowledge of medicinal plants is necessary. The
documentation on medicinal plants exists in the form of books and
palm leaves. There also exist some online databases with free access.
The data available on the said media is inadequate. A holistic and

34
systematic approach is very much essential to promote productivity of
medicinal plants.
The knowledge of Indian medicinal plants is required by a
common man in view of prevailing home remedies. It would be
difficult, if not impossible, to identify, classify and use the Indian
medicinal plants by novice users. The knowledge of botanical and
colloquial names of medicinal plants are essential. Even though the
medicinal plants are catalogued over the years, still there is a serious
deficiency in terms of conservation, establishment of natural
preserves, location and protection of rare species. There is no
database for wide usage at present. The need for leveraging the
advanced technology is necessary for enabling easy, rapid
identification and retrieval of medicinal plants.
In this connection, we have developed a database and proposed
a methodology for information retrieval from the database. The work is
useful to common people, Ayurveda practitioners, researchers and
other agencies are involving in the use of medicinal plants. The design
of database depends on the data content, accessing methods and user
requirements. We have obtained the basic authentic data from (P.K.
Warrier, [99] for the development of database. We have carried out
literature survey to know about the state-of-the-art in medicinal plant
database.

35
2.2 RELATED WORK
Following is the gist of the literature survey in the area of
application of databases in different fields.
Carsten Kettner et. al., have created relational database system
MEDPHYT, which contains a complete information of European
pharmaceutical and toxicological plants. The database contains the
details of plant botanical characteristics, therapeutic use, etymology,
and synonyms. Apart from the botanical characterization, there exists
information on medical relevant biochemical compounds and their
physicochemical characteristics and toxicological as well as
pharmaceutical facts. The user queries for the required data using
AND Boolean operator. The information is retrieved with matching text
strings about botanical name, biochemy and toxication [76].
Srikanta Bedathur et al., have created a database system, called
BODHI (Bio-diversity Object Database arcHItecture). The database is
specifically designed for catering the special needs of biodiversity
applications. BODHI hosts purely plant-related data. An object-
oriented database is constructed to process queries in multi-domain
such as taxonomy characteristics, spatial distribution and genomic
sequences [119].
A multi-faceted information on medicinal plants of India is aggregated
by Foundation for Revitalization of Local Health Traditions (FRLHT),
Bangalore, India in the form of computerized databases, specialized

36
reports, information products, websites and trade bulletins
(http://www.frlht.org.in/ -Encyclopedia of medicinal plants) [52].
A plant conservation software called “PlantCon” is proposed
(http://www.cimap.res.in), Central Institute of Medicinal and
Aromatic Plants) [51].
(Andres, have proposed an approach to retrieve plant Images using
fuzzy concepts such as fuzzy subset theory and fuzzy thesauri. Few
electronic databases like, MAPA, CABabstracts, AGRIS, AGRICOLA,
PASCAL, MEDILINE, EMBASE, APINMAP are presented in this work
on the database retrieval, certain query processing and access
mechanism are also necessary to achieve time and space complexity.
Hence, to achieve an optimal query processing of medicinal plants
database, the authors have presented few literature on database
access approaches [6].
(Cao and Badia), has proposed an approach for representing query
in the form of graph model, in which each node represents an
operation and an edge associated with weight gives the cost. The
query transformation algorithms are provided for writing nested SQL
queries into equivalent flat queries, which are processed more
efficiently. Algebric optimization rules are used. The selection and
projection operations are pushed down. The join operation is executed
to reduce the number of tuples. The method is efficient and takes
shorter time with increasing sizes of relation [18].

37
(Ceri and Gottlob), have developed a translator that transforms SQL
queries into relational algebra with aggregate functions. The SQL
queries are written in the form relational algebra and query
optimizations are carried out using aggregate functions. (Hellerstein),
[50] has introduced the use of rank parameters to each operation
based on selectivity and cost per tuple. A heuristics algorithm is
proposed for selecting the tuples for execution with lower rank having
less number of attributes [22].
From the literature, it is observed that there exist few databases
on plants giving information on only plants name, chemical
composition and biodiversity. We have also found some medicinal
plants database in the form of books and websites. However, a
standard Indian medicinal plants database is not available to the
researcher, practitioners and common users. Further, it is also
observed that amount of technology application effort gone into this
area is very less. Hence, we have designed a database for medicinal
plants keeping in mind the need for medicinal values of the plants and
image based information retrieval. We have also proposed a
methodology for efficient information retrieval from the database of
medicinal plants.
2.3 DESIGN OF DATABASE SCHEMA
Over the last decade, the database research community is
actively involved in building varieties of ways of data management,
namely, genetic data, criminal data, demographic data and the like.

38
There is no data management work cited on Indian medicinal plants.
A medicinal plant is identified by its morphological characteristics.
Each plant has certain biochemical content through which it is drawn
for therapeutic use. Such information is widely used by the people in
the treatment of diseases. Hence, we have listed plants with their
features of parts and medicinal usage. The Figure 2.1 shows the major
available features about the medicinal plants.
Figure 2.1: Medicinal plant properties
A medicinal plant is identified and classified based on these
features. But, sometimes, the medicinal plants identification becomes
a problem due to overlapping features. Hence, for proper identification
of plants, an unique discriminating features need to be devised. In
Botany, taxonomy expert classifies the plants based on many criteria.
The plants having common characteristics are grouped into a class.
Therefore, to classify plants, it is necessary to identify the
characteristics of the given group. One of the oldest and commonly
used methods of grouping plants is based on physical or
Plant
Leaf arrangement
code
MedicinalProperty
Family code
Leaf shape
Plant picture
Local name
Seed Shape Part Blooming Type
Flower position
Reproduction
Bark Type
Tree Type
Leaf Composition
FruitType
Type Medicinal PropertyType

39
morphological characteristics. These characteristics are shown in
Table 2.1. A plant is identified with its height, type, flowers and leaves.
Table 2.1: Database Schema PLANTS for Medicinal Plants
Sl
No
Coll
No
Hindi
name
Kannada
name
Englis
h name
Scientifi
cname
Distri
bution
About_pant Parts_
used
Property_used
1 AVS
2358
Tikho
r
Kuvehittu
Tavaksiri
Arrow
root
Marant
a
arundin
acea
Linn.
Cultiv
ated
throu
ghout
India
Herb,90-180cm high
leaves ovate-oblong
to ovate, lanceolate
base rounded or
cuneate,tip acute;
flowers white in
clusters,fertile
stamen with
appendage,ovary
one-celled,one-
ovuled.
Under
ground
rhizome
Starch of rhizome
refrigerant, tonic, cough
aphrodisiac, diarrhea
dyspepsia, bronchitis, a
nourishing food for infants,
invalids conval escents. As
ingredient in biscuits,cakes,
puddings, jellies,facepowder
2 AVS
1174
Jasu
m,
Jasut,
Java
Dasavala Shoe-
flower
plant,
hibisc
us
Hibiscu
s rosa-
sinensis
Linn.
Malvace
ae
Throu
ghout
india,
cultiv
ated
An evergreen shrub,
with pale grey or
whitish bark.
Leaves simple,
bright green, ovate,
entire,Serrate
towards the top,
minutehairs eneath;
flowers, solitary and
axillary, pedicels
jointed with pistil
and stamens
projecting from the
centre, anters
reniform or kidney
shaped; 1-celled.
roots,
leaves,
flowers
The roots are sweetish
useful in cough, venereal
diseases, menorrhagia,
pruritus and fever.
The leaves are burning
sensation, hepatopathy,
fatigue, abscesses,
expulsion of the placenta,
skin diseases, fever,
constipation and pruritus.
The flowers are used as
brain tonic, constipating,
urinary astringent and
cardiotinic. Useful in
kapha and pitta, boils,
inflammations,epilepsy,
cerebropathy,dysentery,
haemorrhoids,~
urethrorrhea, diabetes,
cardiac debility,
haemoptysis.
3 AVS 2516
Nim, Nimb
Huccabev, Cikkabevu
Neem tree,
Azadirachta indica
Throughout india,
in deciduous
forests,
also widely
cultivated
A medium to large sized tree, 15-20 m in height and 7 mt having grayish to bark greytubercled bark;
leaves compound, imparipinnte,leaflets
,opposite, elliptic, very oblique at
base,acute tip; flowers cream or
yellowish white in axillary panicles, staminal cylindric, widening above, 9-
10 lobed at the apex;
fruits1-seeded drupes,woody endocarp greenish yellow when ripe,
seeds ellipsoid,
bark,
leaves,
flowers,
seeds,
oil
The bark is astringent,
acrid,antiperiodic,
demulcent, insecticidal,
liver tonic, expectorant,
urinary astringent,
anthelmintic, pectoral and
tonic.
Use vitiated conditions of
pitta hyperdipsia, leprosy,
skin diseases, eczema,
leucoderma, pruritus,
intermittent and malarial
fevers, wounds, ulcers,
burning sensation, tumour,
uterine stimulant and
urinary astringent. They are
useful in fumours, leprosy,
skin diseasesl odontalgia,
intestinal worms,
haemorrhoids, pulmonary
tuberculosis,
opthalmopathy, wounds.

40
≈ : : : : : : : : : : :
≈
The arrangements include parts within a flower, arrangements of
groups of flowers, leaves shapes, patterns of veins, leaves bases and
apices shapes, margins, arrangements of leaflets, stems types, shapes
of fruits, sap color and smell of flowers etc.
We have designed a database for medicinal plants containing
the text, image features and information on medicinal plants in the
form of a relational database. The MS-Access format is used for data
storage and accessing is given through ASP.net interface. The text
database comprises of 500 medicinal plants species of which 164 are
herbs, 125 are shrubs and 159 are trees. The database also includes
52 plant species of climbers and creepers. The features for climbers
and creepers are not considered for image based retrieval. We have
collected images of 174 plant species from forests and parks, of which
32 plants species are herbs, 80 shrubs and 62 trees. However, few
plants species has irregular plant structure and uneven background.
From the images it is observed that these plants species are not
Sl No
Coll No
Hindi name
Kannada name
English
name
Scientificname
Distribution
About_pant Parts_ used
Property_used
500
AVS
2428
Lobiya
Santa
Alasandi Cow
pea
Vigna
unguicu
lata
Throu
ghout
india,
cultiva
t
A herb; leaves
pinnately 3-foliate,
leaflets 7.5-15 cm
long, broadly or
narrowly ovate,
often rhomboidal,
entire or slightly
lobed; flowers white,
pale violet or purple
with a yellow eye,
fruits pods, upto 90
cm long,10-20
seeded; seeds vary
in size, shape and
colour
Seeds The seeds are sweet,
astringent, appetiser,
laxative, anthelmintic,
anaphrodisiac, diuretic,
galactagogue and liver
tonic. They are useful in
vitiated conditions of kapha
and pitta, anorexia,
constipation, helminthiasis,
strangury, agalactia,
jaundice and general
debility.

41
suitable for developed feature extraction. Hence, we have considered
images of 30 plant species of each class, herbs, shrubs and trees for
the work. The leaves images of medicinal plant species are used to
investigate the leaf characteristics. The leaves samples of certain
species have varying shapes and margin features. The sample images
of plants species are shown in Figure 2.2.
(a) (b) (c) (d) (e)
(f) (g) (h) (i) (j)
Figure 2.2: Sample plant species in the database (a) Ocimum basilicum (b) Costus speciosa (c) Solanum melongena(d) Cycas circinalis
(e)Hibiscus rosa-sinensis (f)Ixora coccinia (g)Cocos nucifera
(h)Mangifera indica (i) Nerium indica (j) Prunus domestica
The master database (named as PLANTS) and contains the properties
such as, SlNo (Serial number), CollNo (Collection number), plant
names in Hindi, Kannada, English languages, Distribution,
About_plant, Parts_used and Property_used. The Hindi, kannada, and
English languages are national, Karnataka region and international
languages respectively. The property About_plant includes the
description of leave, flower, fruit and other properties required for the
description of a particular plant. The SlNo is used as primary key. The
Collection numbers are drawn from the book written by P.K.Warrier,
et. al,(2003). In addition to this, scientific names associated with the

42
medicinal plants are also kept as part of the database for unique
identification.
The global schema for medicinal plant database, PLANTS is
represented with Slno, Collno, Hindiname, Kanadaname,
Englishname, Scietificname, Distribution, About_plant, Parts_used,
Property_used. This schema contains few anomalies because of which
information is not inferred for further sub level access operation.
Hence, normalization of the databases is carried out.
2.3.1 Normalization of Databases
The database (PLANT) is not in 1NF (first normal form) and does
not satisfy the atomicity requirement. The schema contains multi-
valued attributes, about_plant (Mark I. Hwand et. al., 2001). The
about_plant is a composite attribute and consists of more than one
data. Hence, the attribute about_plant is decomposed to satisfy
atomicity and uniqueness as shown in Table 2.2. However, this
approach produces more number of duplications, which increases the
redundancy. Once the database is normalized, the 1NF produces
more number of null values if a plant does not contain the attributes
such as flower or fruit. Hence, we have formed separate sub schemas’
such as PLANT_BODY, LEAVES, FLOWERS and FRUIT_SEEDS. These
are self-descriptive and contain atomic values as shown in Tables 2.2
to 2.6. The tables contain no grouping of elements and each row has
unique identifiers such as serial number and collection number,
which forms a concatenated key.
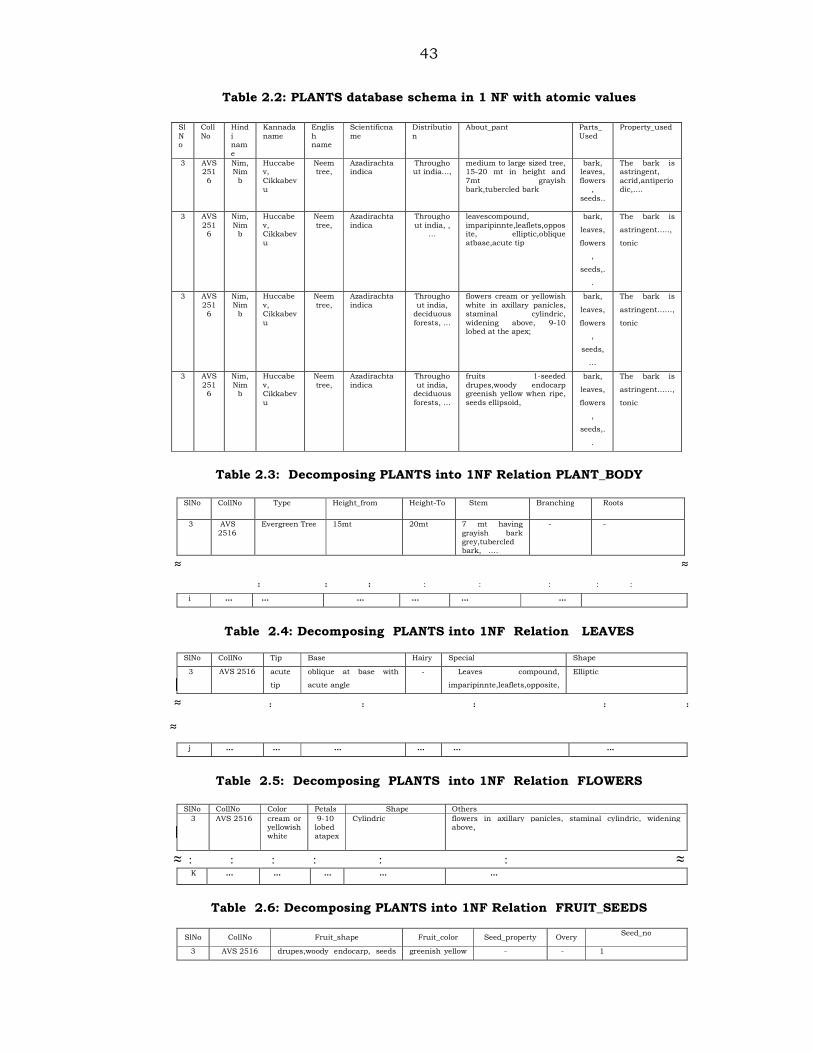
43
Table 2.2: PLANTS database schema in 1 NF with atomic values
Sl
No
Coll
No
Hind
i nam
e
Kannada
name
Englis
h name
Scientificna
me
Distributio
n
About_pant Parts_
Used
Property_used
3 AVS 251
6
Nim, Nim
b
Huccabev,
Cikkabevu
Neem tree,
Azadirachta indica
Throughout india…,
medium to large sized tree, 15-20 mt in height and
7mt grayish bark,tubercled bark
bark, leaves,
flowers,
seeds..
The bark is astringent,
acrid,antiperiodic,….
3 AVS
2516
Nim,
Nimb
Huccabe
v, Cikkabev
u
Neem
tree,
Azadirachta
indica
Througho
ut india, , …
leavescompound,
imparipinnte,leaflets,opposite, elliptic,oblique
atbase,acute tip
bark,
leaves,
flowers
,
seeds,.
.
The bark is
astringent…..,
tonic
3 AVS
2516
Nim,
Nimb
Huccabe
v, Cikkabev
u
Neem
tree,
Azadirachta
indica
Througho
ut india, deciduous
forests, …
flowers cream or yellowish
white in axillary panicles, staminal cylindric,
widening above, 9-10 lobed at the apex;
bark,
leaves,
flowers
,
seeds,
…
The bark is
astringent……,
tonic
3 AVS
2516
Nim,
Nimb
Huccabe
v, Cikkabev
u
Neem
tree,
Azadirachta
indica
Througho
ut india, deciduous
forests, …
fruits 1-seeded
drupes,woody endocarp greenish yellow when ripe,
seeds ellipsoid,
bark,
leaves,
flowers
,
seeds,.
.
The bark is
astringent……,
tonic
Table 2.3: Decomposing PLANTS into 1NF Relation PLANT_BODY
≈ ≈
: : : : : : : :
i … … … … … …
Table 2.4: Decomposing PLANTS into 1NF Relation LEAVES
SlNo CollNo Tip Base Hairy Special Shape
3 AVS 2516 acute
tip
oblique at base with
acute angle
- Leaves compound,
imparipinnte,leaflets,opposite,
Elliptic
≈ : : : : :
≈
j … … … … … …
Table 2.5: Decomposing PLANTS into 1NF Relation FLOWERS
SlNo CollNo Color Petals Shape Others
3 AVS 2516 cream or yellowish white
9-10 lobed atapex
Cylindric flowers in axillary panicles, staminal cylindric, widening above,
≈ : : : : : : ≈
K … … … … …
Table 2.6: Decomposing PLANTS into 1NF Relation FRUIT_SEEDS
SlNo CollNo Fruit_shape Fruit_color Seed_property Overy Seed_no
3 AVS 2516 drupes,woody endocarp, seeds greenish yellow - - 1
SlNo CollNo Type Height_from Height-To Stem Branching Roots
3 AVS
2516
Evergreen Tree 15mt 20mt 7 mt having
grayish bark grey,tubercled bark, ….
- -

44
ellipsoid when ripe
≈ : : : : : : : ≈ L … … … … … …
The subschema LEAVES and FLOWERS violate 2NF (second
normal form). Because every non-prime characteristic, such as,
shape, base and apices of leaves are completely dependent on primary
key. The flower is also dependent on the color and petals. Hence,
further normalization makes the features to be independent so that
leaves and flowers are used to identify uniquely the plants. Therefore,
the databases LEAVES and FLOWERS are normalized into 2NF and
further into sub schemas. Thus, this property helps us to recognize
the medicinal plants. Similarly, other tables PLANT_BODY and
FRUIT_SEED are also subjected to 2NF normalization.
SubSchemas:
LEAVES1(SlNo,CollNo,Tip)
LEAVES2(SlNo,CollNO,Base),LEAVES3(SlNo,CollNo, Shape)
FLOWER1(SlNo,CollNo,Color),FLOWER2(SlNo,CollNo,Petals)
FLOWER3(SlNo,CollNo,Shape).
2.4 QUERY PROCESSING
The database design contains two major components, the
database and the query processor. The data base design writes the
data to and reads data from the data store. It manages record level
access with minimum cost. The query processor accepts Structured
Query Language (SQL) query from user, executes the query and
produces the relevant information. A typical query processing on a
Medicinal Plant Database for retrieving the required information is

45
shown in Figure 2.3. The typical stages through which a query
proceeds have the following functionality.
Figure 2.3: Query execution using heuristic rule
The query parser is designed to check the validity of the query
syntax. A syntactically correct query is represented translated into an
internal form. We have used a query tree, which is a useful
representation for relational calculus expressions. The query
standardization examines all the algebraic expressions that are
equivalent to the given query and chooses the one that has the least
cost. By cost, we mean the number of tuples executed. The Code
Generator transforms the access plan generated by the
standardization process into calls to the query processor. The query
processor is responsible for actual execution of the query.
The queries may have alternate execution plans, which are
equivalent in terms of the results, but there is variation in costs. The
cost is expressed in terms of amount of time needed to execute a
query. We have used two approaches for querying, Heuristic approach
Relational Calculus
Query Parser
Query Standardization process
Code Generator/Interpreter
Query Processor
Record–at-a-
time calls
Relational Algebra
Query Language (SQL)
Retrieved information

46
and Cost Based approach. The cost-based approach uses the
knowledge of the underlying data and storage structures, which is not
considered in this work. The goal of our approach is to retrieve the
image based information as efficiently as possible. We have used
heuristic approach for medicinal plants information retrieval.
The heuristic approach is rule-based method for producing an
efficient execution plan. The selection, projection and join operations
are used to convert a given SQL query into standard relational
algebraic expression. A query tree represents the algebraic query.
During execution, query tree is transformed into an equivalent tree by
rearranging the operations without loosing information (Ceri.S.and
Gottlob [22]. For the purpose of rearrangement, a heuristic rule is
used, where cascaded selects are broken into individual selects. In
addition, the selects and projects are pushed down so that query
results in minimum number of tuples during inner query and join
operation executions. Consider the query “Retrieve the medicinal
plants with ovate leaves”. The inner query is written as under:
σ shape = ‘ovate’ (LEAVES)
The query has resulted in retrieval of 30% of plants from the
database. From the detailed execution of a query with different
alternatives, the characteristics we observed that the number of tuples
returned for the characteristic ‘root’ is minimum and for ‘leaves’ is
maximum. We have concluded that mainly leaves than their other
parts characterize all the plants. Thus, leaves help for image based

47
retrieval of medicinal plants. For an illustration, the number of tuples
obtained after query execution on different parts of plants on plants
database of 100 plants are given in Table 2.7.
Table 2.7: Plants Database parameters after query execution
From the Table 2.7, it is revealed that ‘plant-body’ and ‘leaves’
are the most prominent parts in the identification of plants. Hence,
plant-body dimensions and leaves features are used for further image
based retrieval of information. For efficient and accurate access of the
information of plants, consider an illustration for the execution of the
query “Retrieve the plants with Kanada name and SlNo and having
ovate leaves”. The query is written in relational algebra as given
under.
∏ Kanada_name, slno ( ( σ shape= ‘ovate’(LEAVES)) ∞ LEAVES. slno = PLANTS. slno PLANT)
The possible three alternatives for execution of this query are shown
in Figure 2.4.
The push down strategy is adopted for the above query given in Figure
2.4. The query processing strategy by T3 is effective than T2 and T1.
The selection of ovate leaves is moved down at the leaf level of the
Relation Cardinality
PLANTS 100
FLOWERS 84
LEAVES 100
FRUIT_SEED 80
PLANTBODY 100

48
∏ Kanada_name, slno ∏ Kanada_name, slno ∏ Kanada_name, slno
∞ Slno=Slno σ Shape= ‘ovate’ ∞ Slno=Slno
σ Shape= ‘ovate’ PLANTS ∞ Slno=Slno ∏ slno ∏ Kanada_name,slno
LEAVES
LEAVES PLANTS σ Shape= ‘ovate’ PLANTS
LEAVES T1 T2 T3
Figure 2.4: (i) T1 and T2 are Query Trees (ii) T3 Efficient Tree
Tree and the projections and joins are rearranged so that
minimum number of tuples is obtained giving a good selectivity factor.
Based on selectivity and dilation factor efficient query execution plan
is generated. From this approach, we infer that the proposed approach
gives a good result for any type of plant species.
2.4.1 Query based retrieval of medicinal plant species
In order to retrieve the medicinal plants from the database with
respect to user needs a view-based approach is developed. The
characteristics differ from plant to plant.
We have established the relations in the view level. Many entries
in database PLANT are NULL as their values are either well defined or
exist. It not only suppresses the insert or update or delete anomalies
but also minimizes the normalization overhead. The main purpose of
the work undertaken is to uniquely identify the medicinal plants,
immaterial of normalization of the database for optimum processing
and storage. A typical example of common queries is given as in the
Box 2.1.

49
The variable names (preceded by @) represent the pass values
because the statements are all compounded and the ‘*value*’ format
detects the key words evenwhen they are embedded in a sentence
along with other words. Since “height” attribute is numeric, absolute
values need to be passed in order to detect the medicinal plants with
specific heights. The developed database design allows access to the
plant information by joining more than one subschema. Hence, we
have accessed the plant information with the combination of more
than one feature.
Therefore, the user expresses a detailed query, using
conjunctions and disjunctions of the medicinal plants features.
Moreover, in the case of medicinal plants, we use continuous
property, such as the leaf size, or an interval data such as between
2cm and 5 cm or a linguistic variable such as small, medium and tall.
It is also common to use modifiers such as very small to attribute a
different level of importance. An illustration of complex query
execution on global and fragmentation schemas for medicinal plant
database is given in Box 2.2. The query retrieves the medicinal plant’s
English name that has white flower, conical fruits and herbaceous.
We have presented some preliminary results of experimentation
on the designed database. Basically plants are classified as herbs,
shrubs and trees. Hence, to find the percenatage of these classfication
large numbers of queries are executed on the database. Plants are
divided mainly into three categories herbs, shrubs and trees using the

50
query as follows.
Box 2.1. Example of common queries
SELECT * from PLANT_BODY where type = ‘herb’.
SELECT * from PLANT_BODY where type = ‘herb’.
Figure 2.5 gives the percentage of retrieval of different medicinal
plants from the database. Pie chart indicates percentage of plants
grown in India in following categories of growth forms, herbs, shrubs
and trees.
(i) Classification based on the base tip of leaves SELECT[plants].[kanada_name],[plants].[hindi_name],[plants].[sci_name],[plants].[distribution],
[plants].[parts_used], [plants].[about_plant]
FROM plants, leaves
WHERE([plants].[slno]=[leaves].[slno]) And ([plants].[collno]=[leaves].[collno]) And (([leaves].[base] Like
[@base]) Or ([leaves].[tip] Like [@tip]));
(ii) Classification based on flower color
SELECT[plants].[kanada_name],[plants].[hindi_name],[plants].[sci_name],[plants].[distribution],[plants
].[parts_used],[plants].[about_plant], [flowers].[color], [flowers].[shape]
FROM plants, flowers
WHERE(([plants].[slno]=[flowers].[slno])And[plants].[collno]=[flowers].[collno])And (([flowers].[shape]
Like [@shape]) Or ([flowers].[color]=[@color])))
ORDER BY [COLOR];
(iii) Classification based on fruit shape description
SELECT *
FROM fruit_seed
WHERE len(fruit_shape)>1;
(iV) Classification based on fruit seed
SELECT[plants].[kanada_name],[plants].[hindi_name],[plants].[sci_name],[plants].[distribution],
[plants].[parts_used], [plants].[about_plant]
FROM plants, fruit_seed
WHERE(([plants].[slno]=[fruit_seed].[slno])And([plants].[collno]=[fruit_seed].[collno])And(([fruit_seed].[fr
uit_shape]Like[@Fruit_shape])Or [fruit_seed].[seed_property]=[@Seed])));

51
Box 2.2: Typical query execution on global and fragmentation schemas
Box 2.2 Different schema of the database
Hence, the conjugate queries usually require plant classification based
on plant type and their features. The shrubs are in small numbers
and considered for query processing.
Global schema
PLANTS(slno,collno,hindiname,kanadaname,englishname,scietificname,
distribution,about_plant, parts_used,property_used)
Subschema
LEAVES(slno,tip,base,spacial,hairy, shape)
FRUIT(slno,fruit_shape,fruit_color,seed_property,ovary,seed_no)
FLOWER(slno,color,shape,petals,others)
PLANTBODY(slno, type,height_from,height_to,stem,branching,roots)
Fragmentation Schema
PLANT_FL = SL FLOWER.color= ‘white’ PJslno (FLOWER)
PLANT_FR = SL FRUIT.shape= ‘conical’ PJ slno (FRUIT)
PLANT_TP = SL PLANTBODY.type= ’ herb’ PJ slno (PLANTBODY)
PLANT_TEMP = (PJ slno (PLANT_FL JN PLANT_FL.slno = PLANT_FR.slno PLANT_FR ))
PLANT_RECN = PLANT_TEMP JN PLANT_TEMP.slno = PLANT_TP.slno PLANT_TP
PLANTNAME_RECN_UNIQUE = PJslno,Englishname(PLANTS JN(PLANTS.slno =
PLANT_RECN.slno ) PLANT_RECN)
Plants_with_white_Flower={2,3,4,63,71,72,75,10,83,54,84,62,8,33,55,16,1,7,9,
13, 18,34, 5,11,6,20,61}
Plants_ With_Conical_Fruits = { 7,54 }
Herb_Plants={1,2,4,5,6,12,19,25,27,32,33,36,37,42,45,49,54,55,60,65,66,74,7
5, 76,77,82,84}
White flower∩ Conical_Fruits ∩ Herb_Plants = {54}
Therefore plant 54 is a herb which possesses a conical fruit with white flower.

52
Figure 2.5: Percentage of medicinal plants with categories of growth forms
Figure 2.6: Classification of medicinal plants based on the
plant properties
From the graph shown in Figure 2.6, we conclude that leaves, height,
flower, branching and fruits are the most common properties which
are defined for majority of the plants and amongst them leaves are the
most well defined properties in the recognition of plants. Hence, the
retrieval percentage obtained is high.

53
Figure 2.7: Classification based on the plant sub properties
The plants with properties given in Figure 2.6 constitute 90% of the
entire database. The climbers and creepers constitute only 10% of the
medicinal plants and are also identified by leaf and tendril properties.
Moreover, there are some plants, which have the same global but
varies with local properties. Hence, in order to classify, we have found
out some minute local properties specific to a particular plant. Such
properties are used to differentiate between similar plants. Figure 2.7
gives the percentage of retrieval versus sub properties. The medicinal
plants are categorized based on the sub properties combined in a
single query. From the experimentation, we have observed that most
of the plants are well defined by the common properties.
2.5 INDIAN MEDICINAL PLANT DATABASE ON THE WEB
In order to make the database online, it is web enabled and
implemented using ASP.Net and Web Matrix Server. The developed
design schema shows how easily the plant properties are fragmented

54
and analyzed. The OLEDB database interface is considered, which
involves the MS-Access and core component ADO.Net integrated with
Web Matrix. The connection string provides a direct path to MS-
Access, which is located on the web directory. For record
representation, a serialized object (DataGrid) and one non serializable
object (DataReader) are used. The grid is used for displaying and
joining results, where the reader is used to fetch independent records.
Summary
We have developed a standard database for Indian medicinal
plants from using various sources such as books, images and utility
package. The proposed methodology has given 85% accuracy for a
unique property. The database facilitates retrieval of plants from their
properties. Hence, the developed design methodology helps in the
preparation of home remedies. The work focuses on combining text
and image for image based information retrieval. Ultimate goal is to
develop a machine vision system for medicinal plants considering
their properties and sub properties for retrieval.