chapter 11: storage and file structure
DESCRIPTION
Chapter 11: Storage and File Structure. 11.1 Overview of physical storage media 11.2 Magnetic disks 11.3 RAID 11.4 Tertiary access 11.5 Storage access 11.6 File organization 11.7 Organization of records in files 11.8 Data dictionary storage - PowerPoint PPT PresentationTRANSCRIPT

11.1
Chapter 11: Storage and File StructureChapter 11: Storage and File Structure
11.1 Overview of physical storage media
11.2 Magnetic disks
11.3 RAID
11.4 Tertiary access
11.5 Storage access
11.6 File organization
11.7 Organization of records in files
11.8 Data dictionary storage
Problems 11.1-11.5, 1.8, 11.9, 11.13, 11.14.

11.2
Classification of Physical Storage MediaClassification of Physical Storage Media
Speed with which data can be accessed
Cost per unit of data
Reliability data loss on power failure or system crash physical failure of the storage device
Differentiate between: volatile storage: loses contents when power is switched off non-volatile storage:
contents persist even when power is switched off
includes secondary and tertiary storage, as well as battery- backed up main-memory
How does this relate to anything you use?

11.3
Storage HierarchyStorage Hierarchy(speed and cost)(speed and cost)
Primary (fast, $$, volatile)
Secondary
(non-volatile,
moderately
fast)
Tertiary
(non-volatile,
slow access)
for data used often
can't store entire db
eeprom
floppy, zip
cd rom
sequential access mostly for backupalso called off-line

11.4
11.2 Magnetic Hard Disk Mechanism11.2 Magnetic Hard Disk Mechanism

11.5
Disk Performance Measures Disk Performance Measures
Access time – time it takes from when a read or write request is issued to when data transfer begins.
Consists of:
rotational latency – time it takes for the sector to be accessed to appear under the head. Average latency is 1 /2 of the worst case latency
seek time – time it takes to reposition the arm over the correct track. Average seek time is 1 /3rd the worst case seek time.
why?
Data-transfer rate – the rate at which data can be retrieved from or stored to the disk (after head is positioned)
Mean time to failure (MTTF) – the average time the disk is expected to run continuously without any failure

11.6
11.2.3 Optimization of Disk-Block Access11.2.3 Optimization of Disk-Block Access
Block – a contiguous sequence of sectors on a single track data is transferred between disk and main memory in blocks
sizes range from 512 bytes to several kilobytes
smaller blocks: more transfers from disk
larger blocks: more space wasted due to partially filled blocks
Mechanisms disk-arm-scheduling – order pending accesses to tracks so that
disk arm movement is minimized
file organization – optimize block access time by organizing the blocks to correspond to how data will be accessed
nonvolatile write buffers writing blocks to a non-volatile RAM buffer immediately and don't need to wait for actual disk writes to proceed
log disk – write a sequential log of block updates and do them later

11.7
11.3 RAID11.3 RAID
Redundant Arrays of Independent Disks: a large numbers of disks which appear as a single disk of high reliability by storing data redundantly
high capacity and high speed by using multiple disks in parallel
Redundancy – store extra information that can be used to rebuild information lost in a disk failure mirroring (or shadowing): duplicate every disk
Using disks in parallel (striping data across multiple disks) bit-level striping – split the bits of each byte across multiple disks
e.g. in an array of eight disks, write bit i of each byte to disk i
each access can read data at eight times the rate of a single disk
seek/access time worse than for a single disk (to find locations on all disks)
not used much any more
block-level striping – with n disks, block i of a file goes to disk (i mod n) + 1
requests for different blocks can run in parallel
11.8
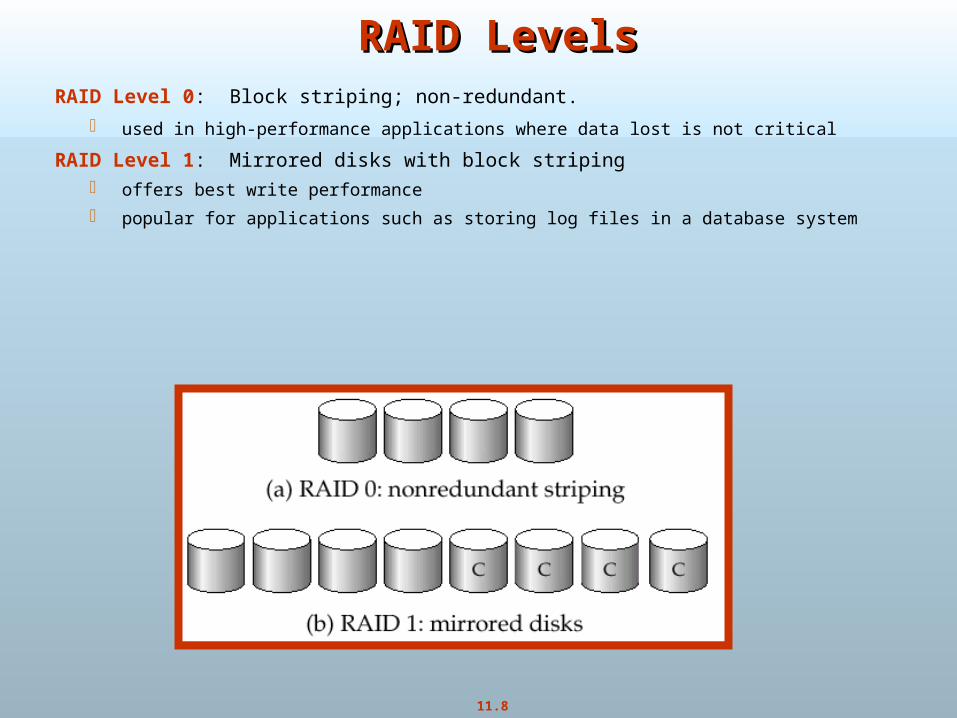
RAID LevelsRAID LevelsRAID Level 0: Block striping; non-redundant.
used in high-performance applications where data lost is not critical
RAID Level 1: Mirrored disks with block striping offers best write performance
popular for applications such as storing log files in a database system

11.9
RAID Levels (Cont.)RAID Levels (Cont.)
RAID Level 2: Memory-Style Error-Correcting-Codes (ECC) with bit striping
store 2 or more parity bits per byte on a disk to detect and correct
RAID Level 3: Bit-Interleaved Parity parity bit is stored for the byte that is spread over the disks
when a disk fails, a single parity bit is enough for error correction, not just detection (ECC done in level 2 already built into hard disks)
subsumes Level 2 (provides all its benefits, at lower cost)

11.10
RAID Levels (Cont.)RAID Levels (Cont.)
RAID Level 4: Block-Interleaved Parity; block-level striping, keeping a parity block on a separate disk for
corresponding blocks from N other disks
to find value of a damaged block, compute XOR of bits from corresponding blocks (including parity block) from other disks
higher I/O rates for independent block reads than Level 3 (Blocks on different disks can be read in parallel)
parity block becomes a bottleneck for independent block writes since every block write also writes to parity disk

11.11
RAID Levels (Cont.)RAID Levels (Cont.)
RAID Level 5: Block-Interleaved Distributed Parity partitions data and parity
among all N + 1 disks.
higher I/O rates than Level 4
(parity blocks not all on one disk)
RAID Level 6: P+Q Redundancy similar to level 5, but stores extra redundant information to guard
against multiple disk failures
better reliability than level 5 at a higher cost; not widely used

11.12
Choice of RAID LevelChoice of RAID Level
Factors: $$$$ performance: I/O operations per second, bandwidth during
normal operation performance during failure performance during rebuild of failed disk
RAID 0 used only when data safety is not important e.g. data can be recovered quickly from other sources
Level 2 and 4 never used since they are subsumed by 3 and 5
Level 3 is not used anymore since bit-striping forces single block reads to access all disks, wasting disk arm movement, which block striping (level 5) avoids
Level 6 is rarely used since levels 1 and 5 offer adequate safety for almost all applications
Competition is between 1 and 5

11.13
Choice of RAID Level (Cont.)Choice of RAID Level (Cont.)
Level 1 provides much better write performance than level 5 level 5 requires at least 2 block reads and 2 block writes to write a single
block
level 1 only requires 2 block writes
level 1 preferred for high update environments such as log disks
Level 1 has higher storage cost than level 5 disk drive capacities increasing rapidly (50%/year) whereas disk access
times have decreased much less (x 3 in 10 years)
I/O requirements have increased greatly, e.g. for Web servers
when enough disks have been bought to satisfy required rate of I/O, they often have spare storage capacity
so there is often no extra monetary cost for Level 1!
Level 5 preferred for applications with low update rate and large amounts of data
Level 1 preferred for all others

11.14
Interesting, but readableInteresting, but readable
11.3.5 Hardware Issues (special purpose or not? hot swapping?)
11.3.6 Other RAID Applications (broadcast data)
11.4 Tertiary Storage (optical disks and tapes)

11.15
11.5 Storage Access11.5 Storage Access
A database file is partitioned into fixed-length storage units (blocks)
Goal: minimize the number of block transfers between the disk and memory
Observation: we can reduce the number of disk accesses by keeping as many blocks as possible in main memory
Buffer – portion of main memory available to store copies of disk blocks
Buffer manager – subsystem responsible for allocating buffer space in main memory

11.16
Buffer ManagerBuffer Manager
Programs call the buffer manager when they need a block from disk
If the block is already in the buffer, the requesting program is given its address in main memory
If the block is not in the buffer:
1. the buffer manager allocates space in the buffer for the block, replacing (throwing out) some other block, if required, to make space for the new block
2. the block that is thrown out is written back to disk only if it was modified since the most recent time that it was written to/fetched from the disk
3. the buffer manager reads the new block from the disk to the buffer, and passes the address of the block in main memory to requester

11.17
11.5.2 Buffer-Replacement Policies11.5.2 Buffer-Replacement Policies
Typical problem: which blocks to write to disk and erase from buffer?
Pinned block – block that is not allowed to be written back to disk
Blocks are pinned during transactions
Idea – use pattern of block references to predict future references
LRU: replace the block least recently used can be bad for queries involving repeated scans of data.
e.g. compute the join of relations r = (r1, r2, ...) and s = (s1, s2, s3, s4) with buffer size 5. Will toss s1 to read r2 and then s2 to read s1
MRU: replace the block most recently used e.g. employee info when computing payroll
requires a block be unpinned before tossing.
What would you use for caching web pages
list of Word files
clothes in a closet

11.18
11.6 File Organization11.6 File Organization
How is a database stored?
Database: a collection of files file: a sequence of records.
record: a sequence of fields.
One approach: assume record size is fixed
each file has records of one particular type only
different files are used for different relations
Easiest to implement

11.19
Fixed-Length RecordsFixed-Length Records
Simple approach: store record i starting from byte n (i – 1), where n is the size of
each record.
record access is simple but records may cross blocks
modification: do not allow records to cross block boundaries
Deletion of record 5: alternatives: move records 5 + 1, . . ., 8
to 5, . . . , 8 – 1
move record 8 to 5
do not move records, but link all free records on afree list

11.20
Free ListsFree Lists
Free list is a linked list of available space
Store the address of the first deleted record in the file header
Use this first record to store the address of the second deleted record, and so on
More space efficient: use an existing field for pointers

11.21
Variable-Length Records: Slotted Page Variable-Length Records: Slotted Page StructureStructure
Slotted page header contains: number of record entries
end of free space in the block
location and size of each record
Deleting a record: change size in header to -1
move other records down
change pointers in header

11.22
Organization of Records in FilesOrganization of Records in Files
Heap – a record can be placed anywhere in the file where there is space. Text: "there is no ordering of relations"
What was a heap in CS 132? a complete binary tree in which the value stored in each node is
greater than or equal to the value in each of its children.
Sequential – store records in sequential order, based on the value of the search key of each record
Hashing – a hash function computed on some attribute of each record; the result specifies in which block of the file the record should be placed
Clustering – records of several different relations can be stored in the same file but store related records on the same block to minimize I/O
11.23
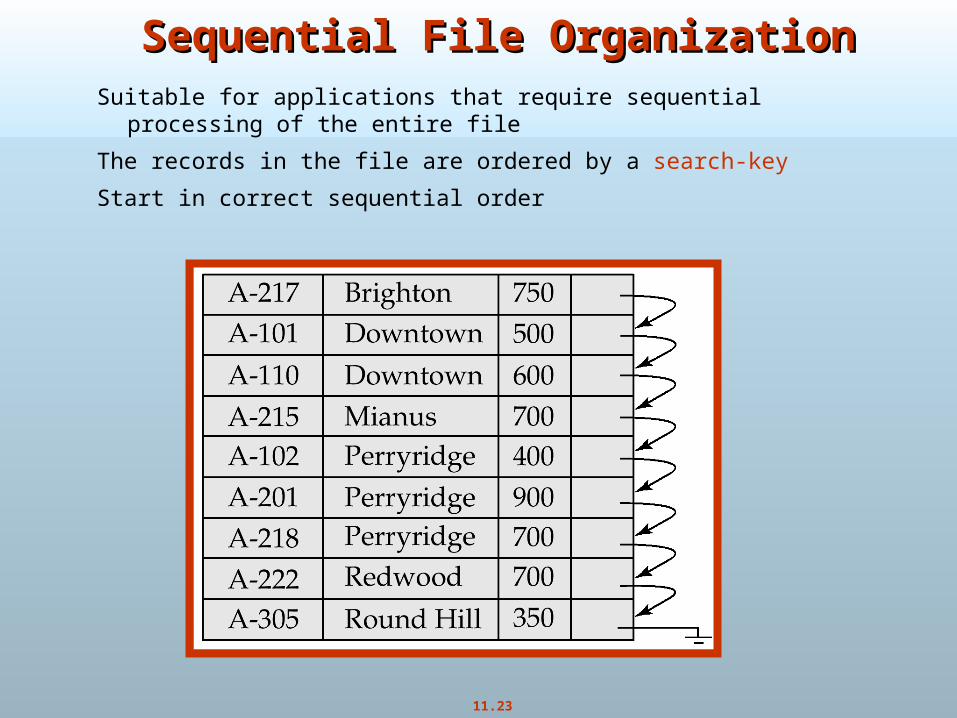
Sequential File OrganizationSequential File OrganizationSuitable for applications that require sequential processing of the entire
file
The records in the file are ordered by a search-key
Start in correct sequential order
11.24
Sequential File Organization (Cont.)Sequential File Organization (Cont.)
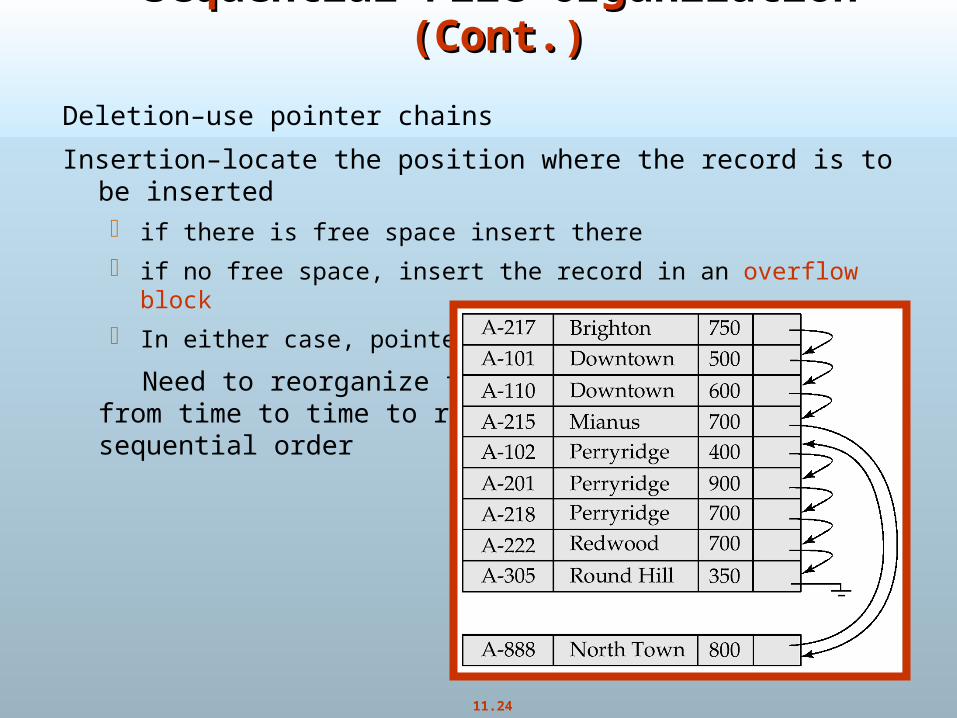
Deletion–use pointer chains
Insertion–locate the position where the record is to be inserted if there is free space insert there
if no free space, insert the record in an overflow block
In either case, pointer chain must be updated
Need to reorganize the filefrom time to time to restoresequential order

11.25
Clustering File OrganizationClustering File Organization
Store records of several different relations in the same block
E.g., clustering organization of customer and depositor: good for queries involving depositor customer, and for queries involving one single
customer and his accounts bad for queries involving only customer results in variable size records

11.26
Data Dictionary StorageData Dictionary Storage
information about relations user and accounting information, including passwords statistical and descriptive data. E.g. # of tuples in each relation physical file organization information information about indices (Chapter 12)
Data dictionary (also called system catalog) stores metadata: (data about data) such as
Options
specialized structures (formulate metadata as relations):
Relation-metadata = (relation-name, number-of-attributes, storage-organization, location) Attribute-metadata = (attribute-name, relation-name, domain-type,
position, length) ... What would this look like for bank?

11.27
Metadata for branch:Metadata for branch:
create table branch (branch_name char(15), branch_citychar(30), assets integer, primary key (branch_name))
Relation-metadata: (relation-name, number-of-attributes, storage-organization, location)
(branch, 3, ISAM, 2000)
Attribute-metadata: (attribute-name, relation-name, domain-type, position, length)
(branch_name, branch, char, 1, 30)
(branch_city, branch, char, 2, 60)