chap. 10 part 1
TRANSCRIPT

Chap. 10 part 1
CIS*3090 Fall 2016
Fall 2016 CIS*3090 Parallel Programming 1

Purpose of chap. 10
Overview of HW technology
Doesn’t fit usual molds of “HPC cluster” or multicore or SMP system
New non-mainstream SW approaches
Theory and principles we studied still apply
The specific techniques { Pilot/MPI, pthreads, OpenMP } may not directly apply
Fall 2016 CIS*3090 Parallel Programming 2

Why we aren’t learning these platforms/languages
GPUs common
Inside every display adapter!
But difficult to exploit for general purpose computing (GPGPU), not standardized (yet)
Cells uncommon (except PlayStation 3)
IBM no longer developing new models
Painful to program, steep learning curve
Contrast multicores, clusters
Fall 2016 CIS*3090 Parallel Programming 3

Theme: Attached processors
Can be cost-effective to attach a special-purpose processor to GP CPU
Specially-designed logic optimizes certain operations with high speed/throughput
Aka co-processor, accelerator
Done for decades for floating point!
If you need the capability, buy it and plug it in
If not, save the cost, board space, power, heat
Still true today in embedded systems where unit cost is critical
Fall 2016 CIS*3090 Parallel Programming 4

Trend: Smart device adapters
Device adapters on PC bus became “smarter” and more powerful, turning into computers in own right
Display adapters, took over task of rendering text and 2D/3D graphics into raster scans
Offloads CPU program/OS from time-consuming tasks
Pay for the power/memory you need/want
Fall 2016 CIS*3090 Parallel Programming 5

FPGAs as accelerators
Field-programmable gate arrays
Our research group + SOE have a lot of experience with this
Aka reconfigurable logic, “soft hardware”
HW advantage from custom design
Circuit performs calculation needed by your app that’s time-consuming for CPU but can be done rapidly by dedicated HW
Multiple instances of same circuit
parallel computation! Fall 2016 CIS*3090 Parallel Programming 6

FPGA in use
“Programming” the FPGA
Circuit description (configuration) downloaded into device as bitstream
CPU program sends args/data to device via system bus or parallel/serial port
Perhaps FPGA interrupts CPU when done
CPU reads results from FPGA and program continues
Fall 2016 CIS*3090 Parallel Programming 7

Pros and cons
PRO: very fast calculations
App-specific
Reconfigure on-the-fly from library of “personalities”, “partial reconfiguration”
Cheap $ < fast CPU or custom IC
CON: difficult to design fast circuit well
Special knowledge/training needed
Time-consuming (minutes to hours) to convert HW description to bitstream
Fall 2016 CIS*3090 Parallel Programming 8

Designers turn to multicore
How to exploit Moore’s Law?
Transistor density still increasing
But power/heat limit single-CPU speed
“Mainstream” multicore chips (Intel, AMD)
Copies of existing instruction processor
Programming easy write in same HLL or
ASM, use same compiler
Easy to configure as SMP, exploit with multithreaded OS, OpenMP
Fall 2016 CIS*3090 Parallel Programming 9

Must extra cores simply be copies of “main” CPU?
Heterogeneous (vs. homogeneous) multiprocessors (MP)
Driven by video gaming industry
Specific subset of calculations they needed
Single-precision floating point
Not full instruction set, nor deeply pipelined CPU
Code segments small (e.g., shaders), so didn’t need (shared) access to huge RAM
IDEA: lower speed, special-purpose “cores” would be made up by quantity!
Fall 2016 CIS*3090 Parallel Programming 10

Designs went in 2 directions
(1) Video adapter manufacturers (NVIDIA, AMD) populated cards with multiple Graphics Processing Units
Optimized for “graphics pipeline” (Fig 10.3)
Not intended as GP computing platform!
But programmers wanted to make them easier to program for non-video apps GPGPU
In that sense, now used as co-processor:
Main CPU configures GPUs with app-specific program, uploads data, downloads results
Fall 2016 CIS*3090 Parallel Programming 11

Copyright © 2009 Pearson Education, Inc. Publishing as Pearson Addison-Wesley 12
Figure 10.3 The graphics pipeline.

GPU programming craze
Cheap, plentiful compute power
Just a step away on the system bus!
Awesome throughput (gigaflops = billions of floating point operations per second)
Growing much faster than CPUs (Fig 10.2)
Updated for 2013, http://michaelgalloy.com/2013/06/11/cpu-vs-gpu-performance.html
Based on higher-speed cores and more of them
Single precision much faster than double
Fall 2016 CIS*3090 Parallel Programming 13

Copyright © 2009 Pearson Education, Inc. Publishing as Pearson Addison-Wesley 14
Figure 10.2 GPU versus CPU
performance over time.

CPU vs GPU performance 11-Jun-2013
Fall 2016 CIS*3090 Parallel Programming 15

Cell Broadband Engine (BE)
(2) Self-contained heterogeneous MP
Sony, Toshiba & IBM teamed to create platform for high-end video games
PlayStation 3 targeted for entertainment
Potential for high-speed parallel programming
Unique architecture (Fig 10.5)
PPE: PowerPC core, GP computer
SPEs: 8-16 “Synergistic” cores
Mere 256K of local memory each!
No cache-coherent “global memory”
Fall 2016 CIS*3090 Parallel Programming 16
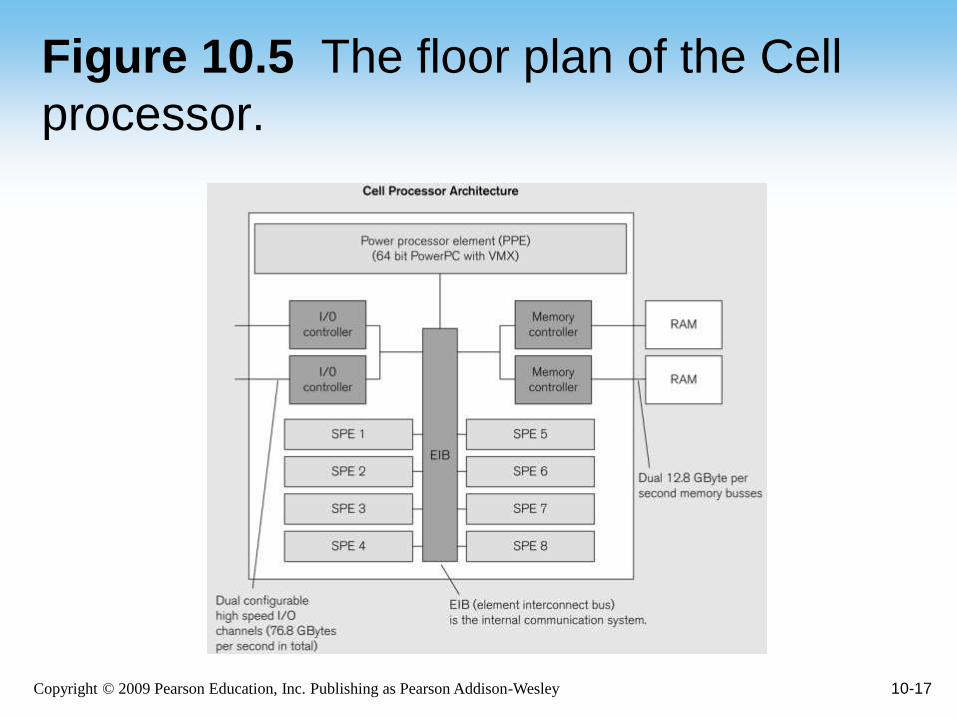
Copyright © 2009 Pearson Education, Inc. Publishing as Pearson Addison-Wesley 10-17
Figure 10.5 The floor plan of the Cell
processor.

Cell programming
Needs two compilers
PPE intentionally low-performance
Runs Linux, but should put app on the SPEs
SPEs have SIMD instructions
E.g., multiply 4 pairs of numbers to give 4 results in one instruction
To access, usually requires ASM language, or library calls that invoke those instructions
“Everyone said” difficult to program
And they’re right! Fall 2016 CIS*3090 Parallel Programming 18

Pilot to the rescue!
My grad student Natalie Girard
No one using SHARCNET’s Cell cluster
Needed to combine pthreads, MPI, Cell SDK
Extended Pilot to Cell = CellPilot
Possible to treat SPEs as processes
Communicate with channels transparently
Within single Cell node
Across heterog. cluster of Cells + other computers
Using “best” means: DMA, message, mailbox
From what we learned with CellPilot…
Fall 2016 CIS*3090 Parallel Programming 19

Another grad, Ben Kelly
Renesas IMAPCAR2: 128-core chip!
Embedded automotive image processing
Works in 128-way SIMD mode, or
Micro cluster of CP + 32 threads SPMD mode
How can 32-thread SMP work?!
Same as Cell, skip cache coherency HW
Dilemma: shared mem. but not coherent!
Pthreads programming becomes treacherous
Solution: AutoPilot for message-passing
Hides complex, easy-to-abuse low-level I/O Fall 2016 CIS*3090 Parallel Programming 20

Summarizing so far
Trend of attached co-processors
(1) GPU attached to conventional CPU
(2) CPU + heterogeneous cores on chip
Both feature explicit data movement
How do they do it?
KEY: skip the coherent shared memory!
Saves on digital logic space for more cores
Reduces overhead, improves mem. bandwidth
Downside: programming headache
Fall 2016 CIS*3090 Parallel Programming 21

Worth mentioning: SHARCNET clusters with accelerators
Tried each of above technologies
Cell BEs + conventional computers Gone!
Cluster with shared GPU on pairs of nodes
Cluster with bank of FPGAs Gone?
Cluster with 2 Intel Xeon Phi on one node
All lightly used!
Difficult to learn and program
Available for “exploring outside course” projects
Fall 2016 CIS*3090 Parallel Programming 22

Road map for chap 10
Topics
Decent introduction to GPU programming
Overview of HW, programmer model, CUDA
NVIDIA training video
OpenACC: new OpenMP-like alternative
Overview of Intel Xeon Phi
Intended to be “GPGPU killer” and win back market share
Best feature: easy to program in popular HLL (like “normal” CPU)
Fall 2016 CIS*3090 Parallel Programming 23

Last handful of “trendy” topics: read for yourself
Grid computing
Internet pulls together a virtual parallel computing utility you can buy time on, like a far-flung distributed parallel cluster
More challenging to utilize than conventional HPC cluster!
Lambda latencies vary by orders of magnitude whether nodes co-located or remote
Can say Grid evolved into Cloud
Fall 2016 CIS*3090 Parallel Programming 24

More trends
Transactional memory
Getting memory HW to do the work normally associated with SW locks
Locks become bottlenecks in par. programs
Similar to Peril-L full/empty variables!
MapReduce developed by Google
“A tool for searching huge data archives”
Fall 2016 CIS*3090 Parallel Programming 25

“Go” language
Publicized by Google in 2009
“Optimized for multicore processors, with many features automatically taking advantage of multithreading.”
“Go promotes writing systems and servers as sets of lightweight communicating processes.”
Inspired by CSP & pi-calculus, like Pilot
Turns out was pre-existing “Go!” language, and author objected!
Fall 2016 CIS*3090 Parallel Programming 26