challenges of a systematic approach to parallel computing...
TRANSCRIPT

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
August 24th, 2015, Vienna
The First European Workshop on Parallel and Distributed Computing Education for Undergraduate Students
Euro-EDUPAR 2015

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
Why “Parallel Computing” ?

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers
102
103
104
109
2025
1-4
4-8
12-64
106
2015
1
1
2-4
104
2005
Degree of parallelism

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers
1-4
4-8
12-64
106
102
103
104
109
2025 2015
1
1
2-4
104
2005
Parallel/Serial Amdahl’s law Synchronization Scheduling Load imbalance Parallel complexity Critical path Race condition Critical resource Critical section Overheads Communications Waiting Scalability Locality Large problems …
Degree of parallelism

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
Why “Supercomputing” ?




“If we want to out compete, we have to out compute”




Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
Why “Supercomputing Education” ?

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers

Supercomputing Education
What is information structure of algorithms and programs ?
How many students know this notion and can use it ?

Supercomputing Education
What is scalability/efficiency of applications/computers ?
How many students know root causes of scalability and efficiency
degradation ?
How many students are able to analyze algorithms / codes / architecture
for scalability and efficiency?

Supercomputing Education
How many students know what data locality is and why it is important to
keep data locality at a high level in applications for any computing
platform?
Random Access
FFT
Linpack

Supercomputing Education
How many qualified parallel computing university teachers are there in
your university / country ?

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
Why “Systematic Approach” ?

Exascale (at ≈2020-2021)
• Supercomputers – billions cores,
• Laptops – thousands cores,
• Mobile devices – dozens/hundreds cores.
Parallelism will be everywhere… And what does it mean ?
All software engineers need to be fluent in the concept of parallelism.
Do we need parallel computing education?

Bachelor degree – 3(4) years, Master degree – 2 years,
2015 + 5(6) years at universities = 2020 (2021)
If we start this activity now then we get first graduate students
at the “Exa”-point (2020-2021).
All our students will live in a “Extremely parallel Computer World”.
It is really time to think seriously about Parallel Computing and
Supercomputing education…
It is Time to Act ! (Exascale is NOT far away…)

Simple questions ? (ask students from your faculties…)
• What is complexity of a parallel algorithm? Why do we need to know a
critical path of an informational graph (data dependency graph)?
• Is it possible to construct a communication free algorithm for a particular
method?
• How to detect and describe potential parallelism of an algorithm? How to
extract potential parallelism from codes or algorithms?
• What is co-design?
• What is data locality?
• How to estimate data locality in my application?
• How to estimate scalability of an algorithm and/or application? How to
improve scalability of an application?
• How to express my problem in terms of MapReduce model?
• What is efficiency of a particular application?
• What parallel programming technology should I use for
SMP/GPU/FPGA/vector/cluster/heterogeneous computers? …
How many software developers will be able to use easily these notions?

Simple questions ? (ask students from your faculties…)
• What is complexity of a parallel algorithm? Why do we need to know a
critical path of an informational graph (data dependency graph)?
• Is it possible to construct a communication free algorithm for a particular
method?
• How to detect and describe potential parallelism of an algorithm? How to
extract potential parallelism from codes or algorithms?
• What is co-design?
• What is data locality?
• How to estimate data locality in my application?
• How to estimate scalability of an algorithm and/or application? How to
improve scalability of an application?
• How to express my problem in terms of MapReduce model?
• What is efficiency of a particular application?
• What parallel programming technology should I use for
SMP/GPU/FPGA/vector/cluster/heterogeneous computers? …
How many software developers will be able to use easily these notions?
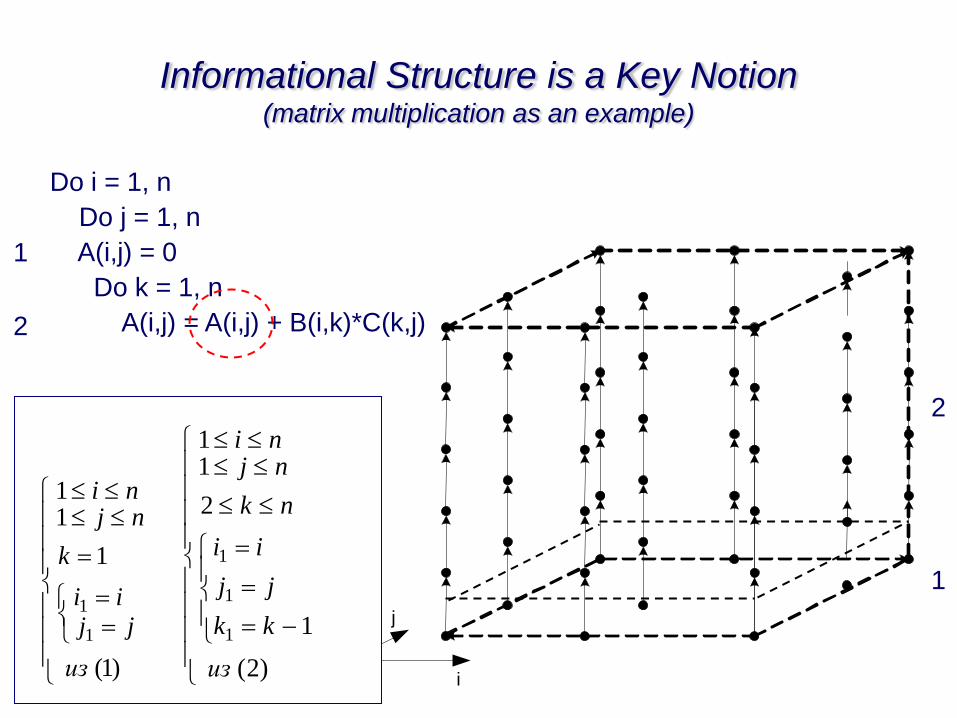
i
j
k
Informational Structure is a Key Notion (matrix multiplication as an example)
Do i = 1, n
Do j = 1, n
A(i,j) = 0
Do k = 1, n
A(i,j) = A(i,j) + B(i,k)*C(k,j)
1
2
1
2
)1(
1
11
1
1
из
iijj
k
ninj
)2(
1
2
11
1
1
1
из
kk
jj
ii
nk
ninj

do i = n, 1, -1 s = 0 do j = i+1, n s = s + A(i,j)*x(j) end do x(i) = (b(i) - s)/A(i,i) end do
x(i) = (b(i) - s)/A(i,i)
s = s + A(i,j)*x(j)
s = s + A(i,j)*x(j)
x(i) = (b(i) - s)/A(i,i)
do i = n, 1, -1 s = 0 do j = n, i+1, -1 s = s + A(i,j)*x(j) end do x(i) = (b(i) - s)/A(i,i) end do
Order of iterations is the only difference !
Serial only Parallel execution
GAUSS elimination method (informational structure)

Simple questions ? (ask students from your faculties…)
• What is complexity of a parallel algorithm? Why do we need to know a
critical path of an informational graph (data dependency graph)?
• Is it possible to construct a communication free algorithm for a particular
method?
• How to detect and describe potential parallelism of an algorithm? How to
extract potential parallelism from codes or algorithms?
• What is co-design?
• What is data locality?
• How to estimate data locality in my application?
• How to estimate scalability of an algorithm and/or application? How to
improve scalability of an application?
• How to express my problem in terms of MapReduce model?
• What is efficiency of a particular application?
• What parallel programming technology should I use for
SMP/GPU/FPGA/vector/cluster/heterogeneous computers? …
How many software developers will be able to use easily these notions?

• Триада
Efficiency of Applications (variants of TRIAD operation)
Courtesy of Vad.Voevodin, MSU
Eff
icie
ncy,
%
1) A[i] = B[i]*X + C
2) A[i] = B[i]*X[i] + C
3) A[i] = B[i]*X + C[i]
4) A[i] = B[i]*X[i] + C[i]
5) A[ind1[i]] = B[ind1[i]]*X + C
6) A[ind1[i]] = B[ind1[i]]*X[ind1[i]] + C
7) A[ind1[i]] = B[ind1[i]]*X + C[ind1[i]]
8) A[ind1[i]] = B[ind1[i]]*X[ind1[i]] + C[ind1[i]]
ind1[i] = i
9) A[ind2[i]] = B[ind2[i]]*X + C
10) A[ind2[i]] = B[ind2[i]]*X[ind2[i]] + C
11) A[ind2[i]] = B[ind2[i]]*X + C[ind2[i]]
12) A[ind2[i]] = B[ind2[i]]*X[ind2[i]] + C[ind2[i]]
ind2[i] = random_access
1 2 3

Simple questions ? (ask students of your faculties…)
• What is complexity of a parallel algorithm? Why do we need to know a
critical path of an informational graph (data dependency graph)?
• Is it possible to construct a communication free algorithm for a particular
method?
• How to detect and describe potential parallelism of an algorithm? How to
extract potential parallelism from codes or algorithms?
• What is co-design?
• What is data locality?
• How to estimate data locality in my application?
• How to estimate scalability of an algorithm and/or application? How to
improve scalability of an application?
• How to express my problem in terms of MapReduce model?
• What is efficiency of a particular application?
• What parallel programming technology should I use for
SMP/GPU/FPGA/vector/cluster/heterogeneous computers? …
How many software developers will be able to use easily these notions?

What could be a solution ?
Trainings or student schools ?!

Trainings and Schools
Trainings on Intel programming tools.
Optimization and tuning of user’s
applications.
Trainings on Accelrys Material Studio
Student summer schools
on parallel programming
technologies

GPU Technology Schools
Major topics at schools:
• Massively Parallel Processing
• GPGPU Evolution
• Architecture of NVIDIA GPUs
• CUDA Programming Model
• CPU-GPU Interaction
• CUDA Memory Types
• Standard Algorithms on GPU: Matrix Multiplication, Reduction
• CUDA application libraries: CURAND, CUBLAS, CUSPARSE,
CUFFT, MAGMA, Thrust
• Program Profiling, Performance Analysis, Debugging
and Optimization
• Asynchronous Execution and CUDA Streams
• Multi-GPU Systems: Programming and Debugging
• nvcc Compiler Driver, cuda-gdb Debugger
• Kernel Configuration and Paralleling of Loops
• OpenACC Directives
In collaboration with NVIDIA and Applied Parallel Computing

What could be a solution ?
Not only trainings or student schools…
We must think about education!
No “Supercomputing and Parallel Computing Education” –
No Exascale Future…

Informatics Europe:
a survey on needs for Supercomputing education
Is “Parallel Computing & Supercomputing”
a strategically important area?
• Austria
• Denmark
• Estonia
• France – 3
• Germany – 5
• Greece
• India – 3
• Iran
• Italy
• Latvia
• Norway
•Pakistan
• Portugal
• Romania
• Russia – 12
• Serbia
• Spain – 15
• Sweden
• Switzerland
• Turkey – 8
• Ukraine
• United Kingdom – 3
Respondents – 64, from 22 countries:

Challenges of a Systematic Approach to Parallel Computing and Supercomputing Education
Why “Challenges” ?

HPC Educational Infrastructure
• Interaction with government, ministries, funding agencies.
• Close contacts with leading IT companies and research institutes.
• Strong interuniversity collaboration.
• Body of knowledge on HPC & Parallel Computing.
• All target groups: researchers, students, teachers, schoolchildren..
• All forms: Bachelors, Masters, PhDs, schools, universities, online..
• Courses, textbooks, intensive practice, trainings on HPC.
• Individual research projects of students.
• Bank of exercises and tests on HPC & Parallel Computing.
• National scientific conferences and student schools.
• Research on advanced computing techniques, HW, SW, apps…
• HPC and Industry.
• Supercomputing and HPC resources.
• International collaboration.
• PR, mass-media, Internet resources on HPC.

HPC Educational Infrastructure
• Interaction with government, ministries, funding agencies.
• Close contacts with leading IT companies and research institutes.
• Strong interuniversity collaboration.
• Body of knowledge on HPC & Parallel Computing.
• All target groups: researchers, students, teachers, schoolchildren..
• All forms: Bachelors, Masters, PhDs, schools, universities, online..
• Courses, textbooks, intensive practice, trainings on HPC.
• Individual research projects of students.
• Bank of exercises and tests on HPC & Parallel Computing.
• National scientific conferences and student schools.
• Research on advanced computing techniques, HW, SW, apps…
• HPC and Industry.
• Supercomputing and HPC resources.
• International collaboration.
• PR, mass-media, Internet resources on HPC.
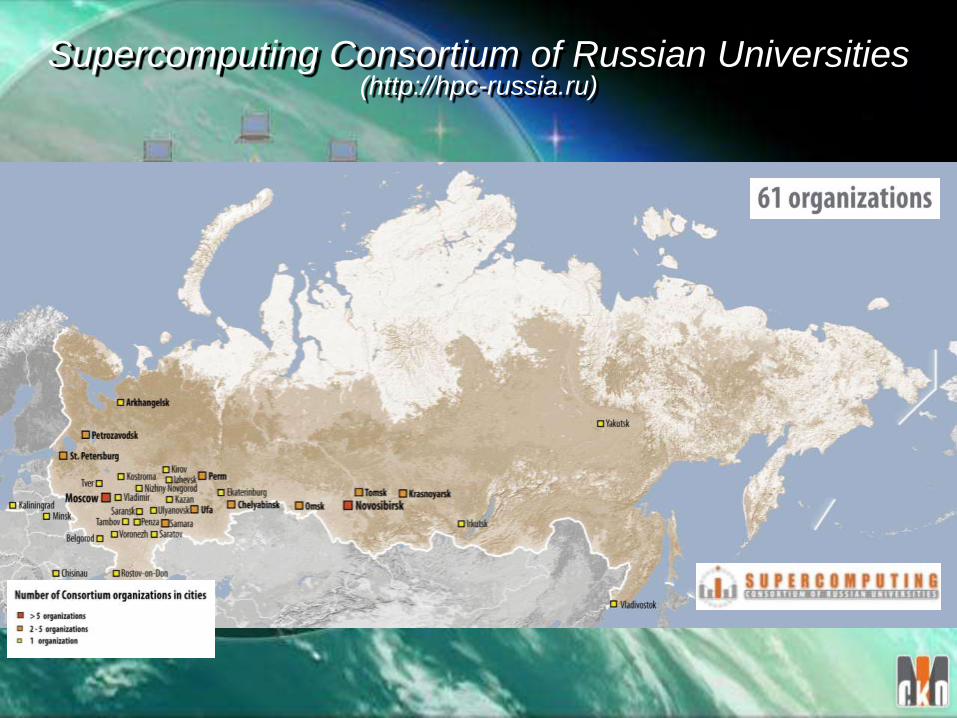
Supercomputing Consortium of Russian Universities (http://hpc-russia.ru)


HPC Educational Infrastructure
• Interaction with government, ministries, funding agencies.
• Close contacts with leading IT companies and research institutes.
• Strong interuniversity collaboration.
• Body of knowledge on HPC & Parallel Computing.
• All target groups: researchers, students, teachers, schoolchildren..
• All forms: Bachelors, Masters, PhDs, schools, universities, online..
• Courses, textbooks, intensive practice, trainings on HPC.
• Individual research projects of students.
• Bank of exercises and tests on HPC & Parallel Computing.
• National scientific conferences and student schools.
• Research on advanced computing techniques, HW, SW, apps…
• HPC and Industry.
• Supercomputing and HPC resources.
• International collaboration.
• PR, mass-media, Internet resources on HPC.

Duration: 2010-2012
Coordinator of the project: M.V.Lomonosov Moscow State University
Wide collaboration of universities:
• Nizhny Novgorod State University
• Tomsk State University
• South Ural State University
• St. Petersburg State University of IT, Mechanics and Optics
• Southern Federal University
• Far Eastern Federal University
• Moscow Institute of Physics and Technology (State University)
• members of Supercomputing Consortium of Russian Universities
More than 600 people from 75 universities were involved in the project .
Budget: 236,42 million rubles (about $8M)
Project “Supercomputing Education” Presidential Commission for Modernization and Technological
Development of Russia’s Economy
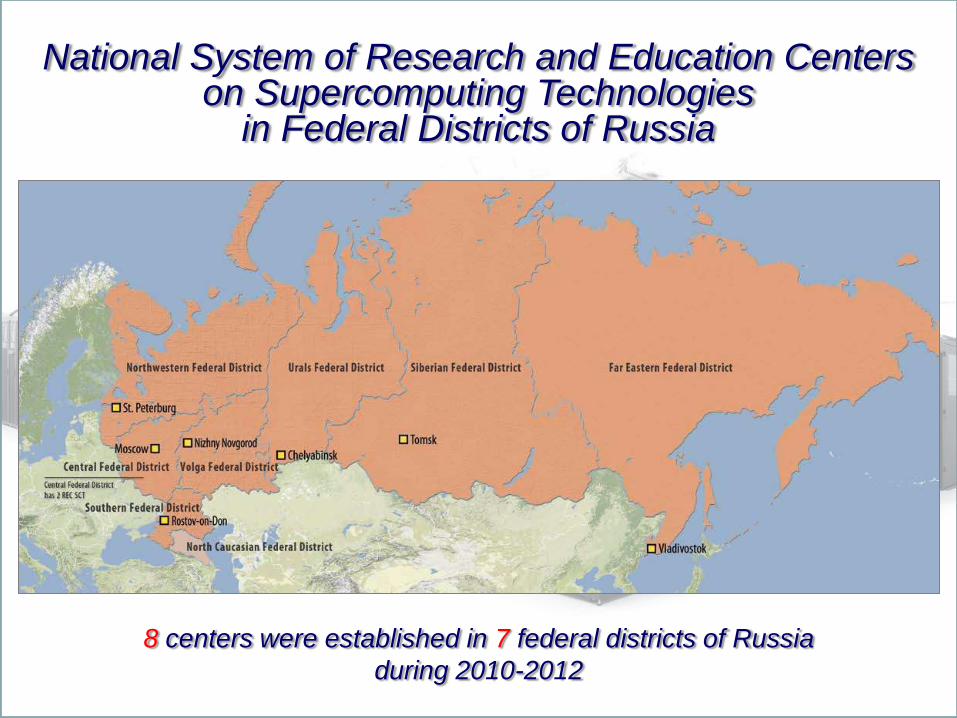
National System of Research and Education Centers on Supercomputing Technologies
in Federal Districts of Russia
8 centers were established in 7 federal districts of Russia
during 2010-2012

3269 people passed trainings, 60+ universities from 35 cities of Russia
All Federal Districts of Russia
Entry-Level Training on Supercomputing Technologies

Series of Books “Supercomputing Education”
There are 21 books in the “Supercomputing Education” series.
31.500 books of the series were delivered to 43 Russian universities.
National Book Contest-2013: Nomination “Textbooks of the 21th century” – 1st Prize

Retraining Programs for Faculty Staff
453 faculty staff passed trainings, 50 organisations, 29 cities, 10 education programs.
All Federal districts of Russia.

Education Courses
on Supercomputing Technologies
Development of new courses and extension of existing ones…
50 courses covering all major parts of the Body of Knowledge in SC…
• "Parallel Computing",
• "High Performance Computing for Multiprocessing Multi-Core Systems",
• "Parallel Database Systems",
• "Practical Training on MPI and OpenMP",
• "Parallel Programming Tools for Shared Memory Systems",
• "Distributed Object Technologies",
• "Scientific Data Visualization on Supercomputers",
• "Natural Models of Parallel Computing",
• "Solution of Aero- and Hydrodynamic problems by Flow Vision",
• "Algorithms and Complexity Analysis",
• "History and Methodology of Parallel Programming",
• "Parallel Numerical Methods",
• "Parallel Computations in Tomography",
• "Final-Element Modeling with Distributed Computations",
• "Parallel Computing on CUDA and OpenCL Technologies",
• "Biological System Modeling on GPU“,
• "High Performance Computing System: Architecture and Software",
• …

Intensive Trainings in Special Groups
40 special groups of trainees were formed,
790 trainees successfully passed advanced training,
15 educational programs,
All Federal districts of Russia.

55 students of MSU (Math, Physics, Chemistry, Biology, …)
Moscow State University in collaboration with:
• Intel
•T-Platforms
• NVIDIA
• TESIS
• IBM
• Center on Oil & Gas Research
• Keldysh Institute of Applied Mathematics, RAS
• Institute of Numerical Mathematics, RAS
IT-Companies + Research Institutes & Universities (special group of students on Parallel Software Development)

“Supercomputing Education” Project (key results for 2010-2012)
• National system of research and education centers on supercomputing
technologies: 8 centers in 7 Federal districts of Russia,
• Body of Knowledge on parallel computing and supercomputing,
• Russian universities involved in supercomputing education – 75,
• Entry-level trainings: 3269 people, 60+ universities, 34 Russian cities,
• Intensive training in special groups – 790 people, 40 special groups,
• Retrained faculty staff on HPC technologies – 453 people, 50 organizations,
• New and modified curriculum and courses of lectures – 50,
• Using distant learning technology – 731 people, 100 cities,
• Partners from science, education and industry – 120 Russian and 65 foreign
organizations,
• Series of books and textbooks “Supercomputing Education” – 21 books, 31500
books were delivered to 43 Russian universities,
• National system of scientific conferences and students schools on HPC,
• …

HPC Educational Infrastructure
• Interaction with government, ministries, funding agencies.
• Close contacts with leading IT companies and research institutes.
• Strong interuniversity collaboration.
• Body of knowledge on HPC & Parallel Computing.
• All target groups: researchers, students, teachers, schoolchildren..
• All forms: Bachelors, Masters, PhDs, schools, universities, online..
• Courses, textbooks, intensive practice, trainings on HPC.
• Individual research projects of students.
• Bank of exercises and tests on HPC & Parallel Computing.
• National scientific conferences and student schools.
• Research on advanced computing techniques, HW, SW, apps…
• HPC and Industry.
• Supercomputing and HPC resources.
• International collaboration.
• PR, mass-media, Internet resources on HPC.

Moscow State University (established in 1755)
41 faculties
350+ departments
5 major research institutes
45 000+ students,
2500 full doctors (Dr.Sci.), 6000 PhDs,
1000+ full professors,
5000 researchers.

Computing Center, MSU, 1955

MSU Computing Center, 1956
Peak performance: 2000 instr/sec Total area: 300 m2
Power consumption: 150 kWatt
“Strela” is the first Russian mass-
production computer

MSU Computing Center, 1959
The first computer in the world based on ternary (-1/0/1) logic.
“Setun” computer
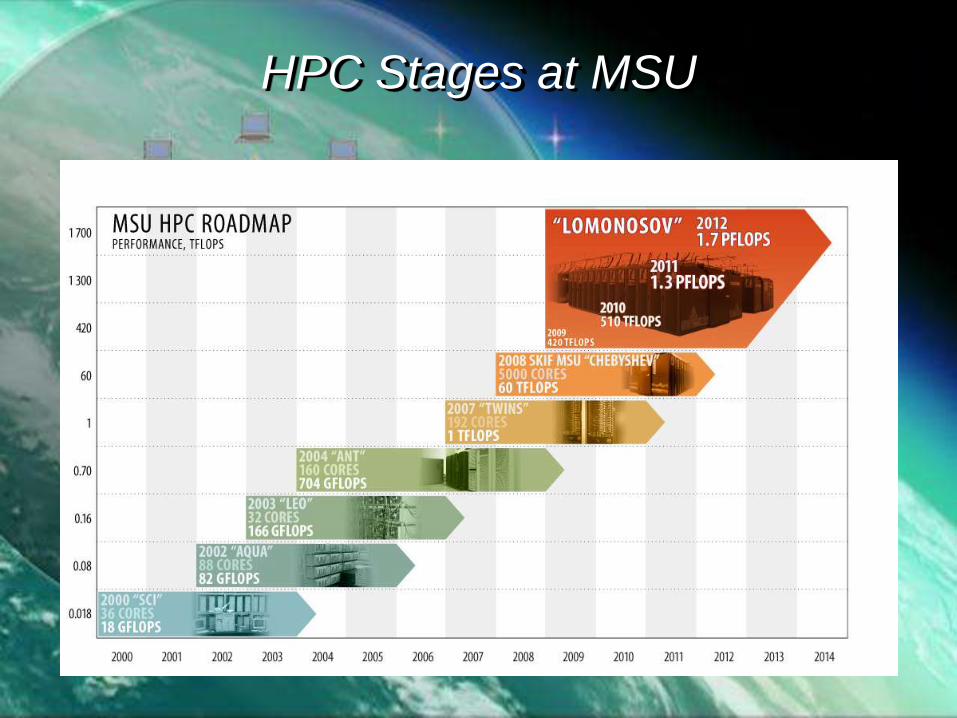
HPC Stages at MSU

1956 1959 1967
2009 2008
2008
2003
2000
103
1015
106
1010
Strela Setun BESM-6
BlueGene/P
“Chebyshev”
“Lomonosov”
Computing Facilities of Moscow State University (from 1956 up to now)

Brief Stats on MSU Supercomputer Center
Users: 2511
Projects: 1607
Organizations: 302
Computing Facilities of Moscow State University (from 1956 up to now)
1 rack = 256 nodes: Intel + NVIDIA = 515 Tflop/s
“Lomonosov-2” supercomputer (5 racks) = 2.5 Pflop/s
MSU Faculties / Institutes: 20+
Computational science is
everywhere…
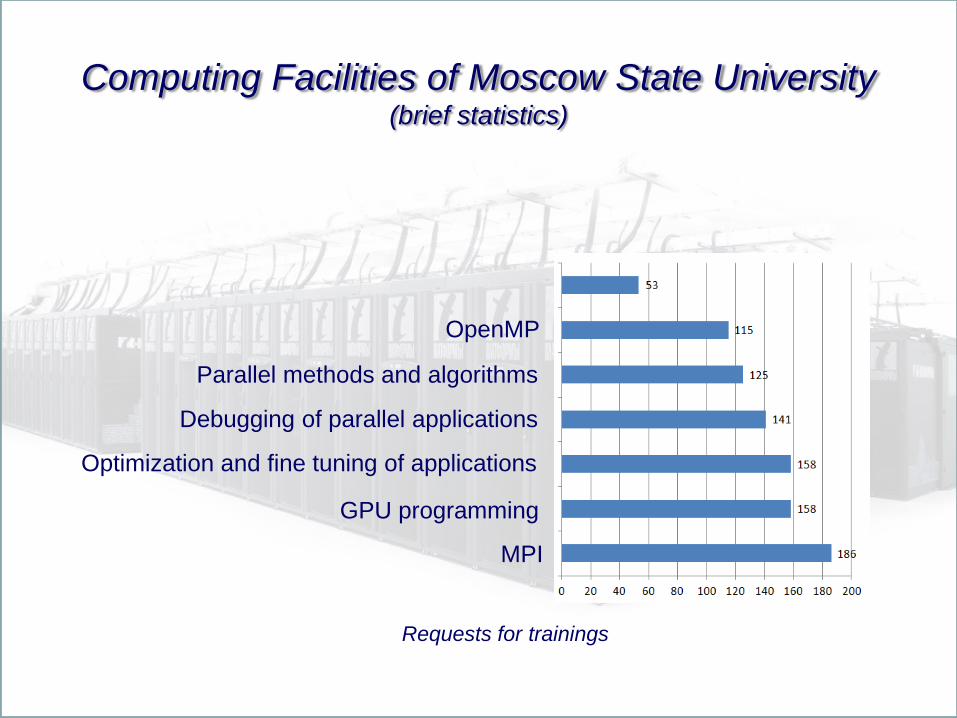
Computing Facilities of Moscow State University (brief statistics)
MPI
OpenMP
GPU programming
Optimization and fine tuning of applications
Debugging of parallel applications
Parallel methods and algorithms
Requests for trainings

Computing Facilities of Moscow State University (brief statistics)
Diversity of software in use

Computing Facilities of Moscow State University (brief statistics)
Diversity of parallel programming technologies in use

Supercomputer Centers and Applications
Challenge of the Day – Extremely Low Efficiency (for free)
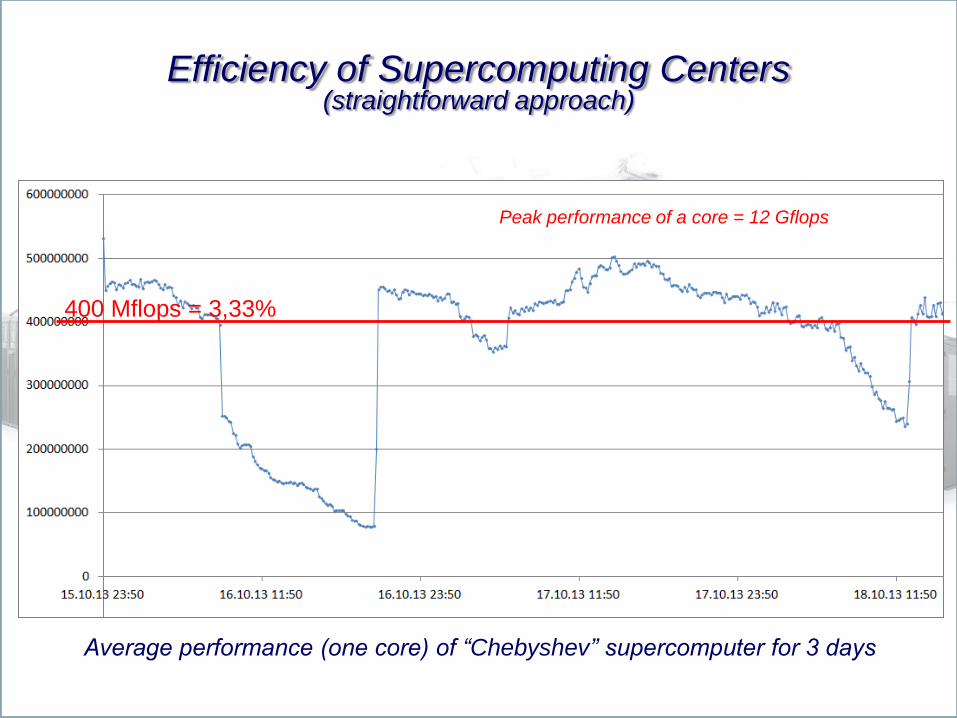
Average performance (one core) of “Chebyshev” supercomputer for 3 days
Efficiency of Supercomputing Centers (straightforward approach)
400 Mflops = 3,33%
Peak performance of a core = 12 Gflops

1 Pflop/s system… What do we expect?
Efficiency of Supercomputing Centers
What is in reality? A small, small, small fraction…
Supercomputers and Steam Locomotives…
Who are more efficient?
Current trend: peculiarities of hardware, complicated job flows, poor data
locality, huge degree of parallelism in hardware, etc… decrease
efficiency of supercomputers dramatically.
1Pflop * 60sec * 60min * 24hours * 365days = 31,5 ZettaFlop (1021) per year
useful

Solving problems: main stages
Problem
Method
Algorithm
Programming Technology
Code
Compiler
Supercomputer (millions, billions…)
One-semester course for Bachelors: “Supercomputers and Parallel Data Processing” at CMC MSU
Computer-specific side Problem-specific side

Solving problems: main stages
Problem
Method
Algorithm
Programming Technology
Code
Compiler
Supercomputer (millions, billions…)
Problem-specific side Computer-specific side
Computer Architectures
Parallel Programming Technologies
Structure of Algorithms and Programs
One-semester course for Bachelors: “Supercomputers and Parallel Data Processing” at CMC MSU

Supercomputers and Parallel Data Processing (one-semester course for Bachelors at CMC MSU)
Introduction. Computers/supercomputers, parallel computing, large problems, history of parallelism in
computer architecture, supercomputing in our life, Amdahl’s law…
Architecture of parallel computing systems. Shared/distributed memory computers, SMP/NUMA/ccNUMA, multicore processors,
clusters, distributed computing, vector-parallel computers, vector instructions, VLIW,
superscalar architectures, GPU, exascale challenges…
Performance of parallel computing systems. Rpeak and Rmax, MIPS/Mflops, Linpack, STREAM, NPB, HPCC, APEX, general-purpose and
special-purpose processors, root causes for performance degradation…
Parallel programming technologies. Parallel programs, SPMD, Masters/Workers; parallel programming technologies: efficiency,
productivity, portability; MPI, OpenMP, Linda, Send/Recv/Put/Get, efficiency, scalability…
Introduction to information structure of algorithms and programs. Graph-based models of programs, control/information graphs, graphs/histories, information
(dependency) graph, information dependency, information independency, parallel
processing, resource of parallelism, equivalent transformations of codes, critical path…
3
5
2
4
2
Lectures

What is at the end?

What models can be used for development
of parallel codes?
Correct
SPMD YES
NUMA
Master / Workers YES
VLIW
Send / Receive YES
Put / Get YES
Key words: models, parallel program, computer architectures, parallel processes, message passing, shared
and distributed memory computers…

What is at the end?

A computer multiplies two square dense matrices
(type real) by the classical method for 5 seconds
at a performance of 50 Gflops.
What is the matrix size?
Correct
500 * 500
1000 * 1000
2500 * 2500
4000 * 4000
5000 * 5000 YES
There is no correct answer
Key words: complexity of algorithms, structure of algorithms, sustained performance, peak performance,
serial and parallel computing…

Algorithms + Software + Architectures
Is a Key Point of
Supercomputing Education

HPC Educational Infrastructure
• Interaction with government, ministries, funding agencies.
• Close contacts with leading IT companies and research institutes.
• Strong interuniversity collaboration.
• Body of knowledge on HPC & Parallel Computing.
• All target groups: researchers, students, teachers, schoolchildren..
• All forms: Bachelors, Masters, PhDs, schools, universities, online..
• Courses, textbooks, intensive practice, trainings on HPC.
• Individual research projects of students.
• Bank of exercises and tests on HPC & Parallel Computing.
• National scientific conferences and student schools.
• Research on advanced computing techniques, HW, SW, apps…
• HPC and Industry.
• Supercomputing and HPC resources.
• International collaboration.
• PR, mass-media, Internet resources on HPC.

National system of student schools
• February, Arkhangelsk
• April, Saint-Petersburg
• June, Moscow
• October, Nizhny Novgorod
• December, Tomsk

Summer Supercomputing Academy
at Moscow State University
June,22 – July,3, 2015
• Plenary lectures by prominent scientists, academicians,
CEO/CTO’s from Russia and abroad,
• 6 parallel educational tracks,
• Trainings on a variety of topics,
• Attendees: from students up to professors (about 120 attendees).
Supported by: Intel, IBM, NVIDIA, T-Platforms, HP, NICEVT

Scientific workshop "Extreme Scale Scientific Computing"

Summer Supercomputing Academy
at Moscow State University
June,22 – July,3, 2015
Educational tracks:
• MPI / OpenMP programming technologies
• NVIDIA GPU programming technologies
• Intel new architectures and software tools
• Industrial mathematics and computational hydrodynamics
• OpenFOAM/Salome/Paraview open software
• Parallel computing for school teachers of informatics
Supported by: Intel, IBM, NVIDIA, T-Platforms, HP, NICEVT

Schoolchildren at MSU Supercomputing Center (600+ visitors per year)


Schoolchildren at MSU Supercomputing Center (600+ visitors per year)

Parallel Computing and Primary School? Easily!
Synchronization Synchronization Parallel execution
Critical resource Load balancing Scheduling
Courtesy of M.A.Plaksin, Perm, Russia
Can you do it faster ? How to work in a team ?

Parallel Computing and Primary School? Easily!
Synchronization Synchronization Parallel execution
Critical resource Load balancing Scheduling
Courtesy of M.A.Plaksin, Perm, Russia
Can you do it faster ? Parallel/Serial Amdahl’s law
Synchronization Scheduling
Load imbalance Parallel complexity
Critical path Race condition
Critical resource Critical section
Overheads Communications
Waiting Scalability
Locality Large problems
…
How to work in a team ?

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers
1-4
4-8
12-64
106
102
103
104
109
2025 2015
1
1
2-4
104
2005
Who will live/work beyond Exascale ?

Tablets, Smartphones…
PCs, Laptops…
Servers…
Supercomputers
1-4
4-8
12-64
106
102
103
104
109
2025 2015
1
1
2-4
104
2005
Who will live/work beyond Exascale ?

My deep gratitude to:
Our Colleagues from
Supercomputing Consortium of Russian Universities
Victor Gergel, NNSU Nina Popova, MSU

Thank You !
August 24th, 2015, Vienna
The First European Workshop on Parallel and Distributed Computing Education for Undergraduate Students
Euro-EDUPAR 2015