chaitanya gokhale university of wisconsin-madison joint work with anhai doan, sanjib das, jeffrey...
TRANSCRIPT

Chaitanya GokhaleUniversity of Wisconsin-Madison
Joint work with AnHai Doan, Sanjib Das, Jeffrey
Naughton, Ram Rampalli, Jude Shavlik, and
Jerry Zhu
Corleone: Hands-Off Crowdsourcingfor Entity Matching
@WalmartLabs

2
Entity Matching
Has been studied extensively for decades No satisfactory solution as yet Recent work has considered crowdsourcing
Walmart Amazon
id Name brand price
1 HP Biscotti G72 17.3” Laptop ..
HP 395.0
2 Transcend 16 GB JetFlash 500
Transcend 17.5
.... … .. …. …… …..
…. .. …….. …. ..
id name brand price
1 Transcend JetFlash 700
Transcend 30.0
2 HP Biscotti 17.3” G72 Laptop ..
HP 388.0
.... … .. …. …… …..
…. .. …….. …. ..

3
Recent Crowdsourced EM Work Verifying predicted matches
– e.g., [Demartini et al. WWW’12, Wang et al. VLDB’12, SIGMOD’13]
Finding best questions to ask crowd – to minimize number of such questions – e.g., [Whang et al. VLDB’13]
Finding best UI to pose questions– display 1 question per page, or 10, or …? – display record pairs or clusters? – e.g., [Marcus et al. VLDB’11, Whang et al. TR’12]

4
Recent Crowdsourced EM Work Example: verifying predicted matches
– sample blocking rule: if prices differ by at least $50 do not match
Shows that crowdsourced EM is highly promising But suffers from a major limitation
– crowdsources only parts of workflow– needs a developer to execute the remaining parts
abc
de
A
B
Blocking Matching(a,d)(b,e)(c,d)(c,e)
(a,d) Y(b,e) N(c,d) Y(c,e) Y
Verifying (a,d) Y(c,e) Y

5
Does not scale to EM at enterprises– enterprises often have tens to hundreds of EM problems– can’t afford so many developers
Example: matching products at WalmartLabs
– hundreds of major product categories– to obtain high accuracy, must match each category separately – so have hundreds of EM problems, one per category
electronics
all
clothes
pants TVsshirts
walmart.com Walmart Stores (brick&mortar)
……...
……... ……
electronics
all
books
romance TVsscience
……...
……...
clothes
……
Need for Developer Poses Serious Problems
……

6
Need for Developer Poses Serious Problems
Can not handle crowdsourcing for the masses– masses can’t be developers, can’t use crowdsourcing startups either
E.g., journalist wants to match two long lists of political donors– can’t use current EM solutions, because can’t act as a developer– can pay up to $500– can’t ask a crowdsourcing startup to help
$500 is too little for them to engage a developer
– same problem for domain scientists, small business workers, end users, data enthusiasts, …

Our Solution: Hands-Off Crowdsourcing
Crowdsources the entire workflow of a task– requiring no developers
Given a problem P supplied by user U, a crowdsourced solution to P is hands-off iff– uses no developers, only crowd– user U does no or little initial setup work, requiring no special skills
Example: to match two tables A and B, user U supplies– the two tables– a short textual instruction to the crowd on what it means to match– two negative & two positive examples to illustrate the instruction
7

Hands-Off Crowdsourcing (HOC) A next logical direction for EM research
– from no- to partial- to complete crowdsourcing
Can scale up EM at enterprises Can open up crowdsourcing for the masses E.g., journalist wants to match two lists of donors
– uploads two lists to an HOC website– specifies a budget of $500 on a credit card– HOC website uses crowd to execute the EM workflow,
returns matches to journalist Very little work so far on crowdsourcing for the masses
– even though that’s where crowdsourcing can make a lot of impacts
8

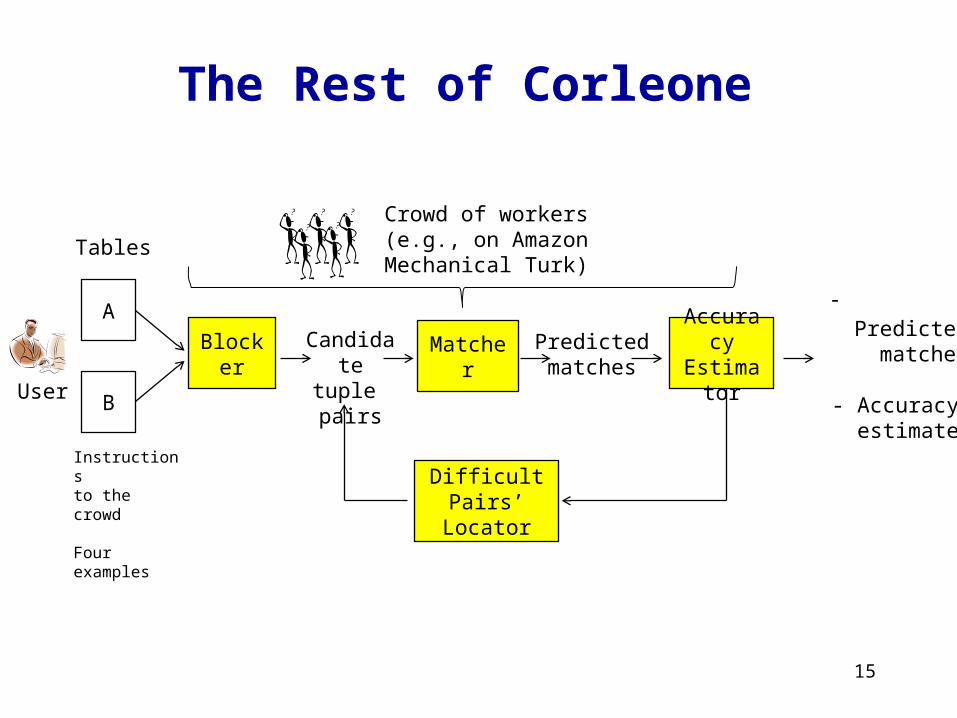
Our Solution: Corleone, an HOC System for EM
9
User
Matcher
B
Candidatetuple pairs
Instructions to the crowd
Four examples
Predictedmatches
A
Tables
Accuracy Estimator
- Predicted matches
- Accuracy estimates (P, R)
Difficult Pairs’ Locator
Crowd of workers(e.g., on Amazon Mechanical Turk)
Blocker

Blocking |A x B| is often very large (e.g., 10B pairs or more)
– developer writes rules to remove obviously non-matched pairs
– critical step in EM How do we get the crowd to do this?
– ordinary workers; can’t write machine-readable rules– if write in English, we can’t convert them into machine-readable
Crowdsourced EM so far asks people to label examples– no work has asked people to write machine-readable rules
10
trigram(a.title, b.title) < 0.2 [for matching Citations]
overlap(a.brand, b.brand) = 0 [for matching Products]
AND cosine(a.title, b.title) ≤ 0.1 AND a.price/b.price ≥ 3 OR b.price/a.price ≥ 3 ORisNULL(a.price,b.price))

Our Key Idea Ask people to label examples, as before
Use them to generate many machine-readable rules– using machine learning, specifically a random forest
Ask crowd to evaluate, select and apply the best rules
This has proven highly promising– e.g., reduce # of tuple pairs from 168M to 38.2K, at cost of $7.20
from 56M to 173.4K, at cost of $22– with no developer involved– in some cases did much better than using a developer
(bigger reduction, higher accuracy)
11

Blocking in Corleone
Sample Sfrom |A x B|
Four examples supplied by user (2 pos, 2 neg)
Stopping criterion satisfied?
Select q “most informative”unlabeled examples
Label the q selectedexamples using crowd
Amazon’s Mechanical Turk
Randomforest F
Train a random forest F
Decide if blocking is necessary– If |A X B| < τ, no blocking, return A X B. Otherwise do blocking.
Take sample S from A x B Train a random forest F on S (to match tuple pairs)
– using active learning, where crowd labels pairs
Y
N

Blocking in Corleone
13
isbn_match
N Y
No #pages_match
N Y
No Yes
title_match
N Y
No publisher_matchN Y
No year_match
N Y
No Yes
(isbn_match = N) No(isbn_match = Y) and (#pages_match = N) No
(title_match = N) No
(title_match = Y) and (publisher_match = Y) and (year_match = N) No
Extracted candidate rules
(title_match = Y) and (publisher_match = N) No
Extract candidate rules from random forest F
Example random forest F for matching books

Blocking in Corleone Evaluate the precision of extracted candidate rules
– for each rule R, apply R to predict “match / no match” on sample S– ask crowd to evaluate R’s predictions– compute precision for R
Select most precise rules as “blocking rules” Apply blocking rules to A and B using Hadoop, to obtain
a smaller set of candidate pairs to be matched
Multiple difficult optimization problems in blocking– to minimize crowd effort & scale up to very large tables A and B– see paper
14
The Rest of Corleone
15
User
Matcher
B
Candidatetuple pairs
Instructions to the crowd
Four examples
Predictedmatches
A
Tables
Accuracy Estimator
- Predicted matches
- Accuracy estimates
Difficult Pairs’ Locator
Crowd of workers(e.g., on Amazon Mechanical Turk)
Blocker

Empirical Evaluation
Mechanical Turk settings– Turker qualifications: at least 100 HITs completed with ≥ 95%
approval rate– Payment: 1-2 cents per question
Repeated three times on each data set, each run in a different week
Datasets Table A Table B |A X B| |M| # attributes # features
Restaurants 533 331 176,423 112 4 12
Citations 2616 64,263 168.1 M 5347 4 7
Products 2554 21,537 55 M 1154 9 23
16

Performance Comparison Two traditional solutions: Baseline 1 and Baseline 2
– developer performs blocking– supervised learning to match the candidate set
Baseline 1: labels the same # of pairs as Corleone
Baseline 2: labels 20% of the candidate set– for Products, Corleone labels 3205 pairs, Baseline 2 labels 36076
Also compare with results from published work
17
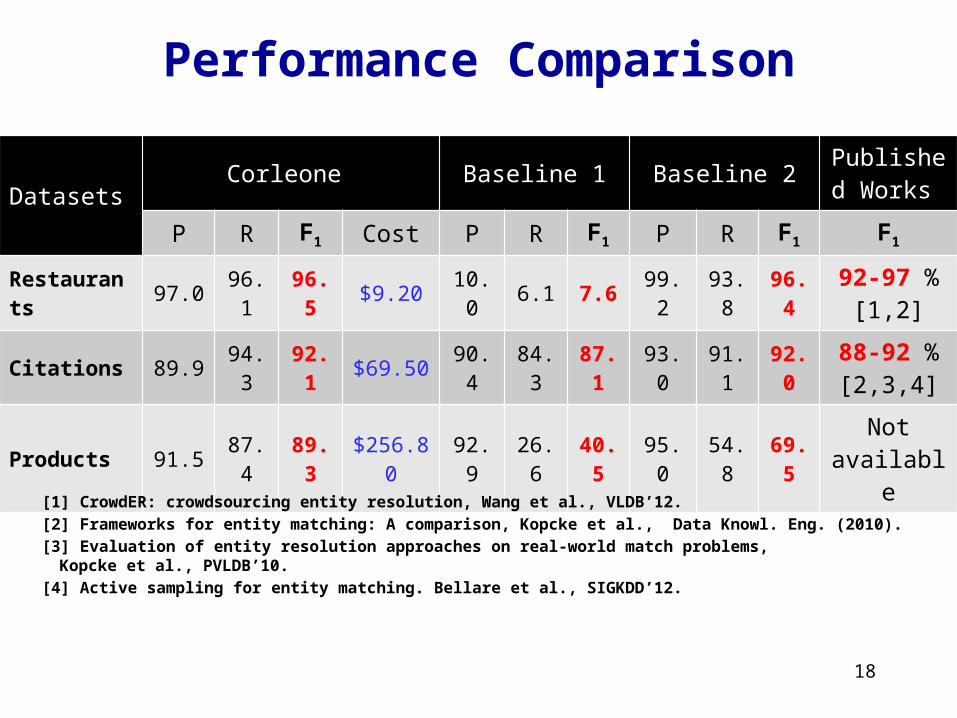
Performance Comparison
DatasetsCorleone Baseline 1 Baseline 2
Published Works
P R F1 Cost P R F1 P R F1 F1
Restaurants 97.0 96.1 96.5 $9.20 10.0 6.1 7.6 99.2 93.8 96.492-97 %
[1,2]
Citations 89.9 94.3 92.1 $69.50 90.4 84.3 87.1 93.0 91.1 92.088-92 % [2,3,4]
Products 91.5 87.4 89.3 $256.80 92.9 26.6 40.5 95.0 54.8 69.5Not
available
18
[1] CrowdER: crowdsourcing entity resolution, Wang et al., VLDB’12.
[2] Frameworks for entity matching: A comparison, Kopcke et al., Data Knowl. Eng. (2010).
[3] Evaluation of entity resolution approaches on real-world match problems,Kopcke et al., PVLDB’10.
[4] Active sampling for entity matching. Bellare et al., SIGKDD’12.

Comparison against blocking by a developer– Citations: 100% recall with 202.5K candidate pairs – Products: 90% recall with 180.2K candidate pairs
See paper for more experiments– on blocking, matcher, accuracy estimator, difficult pairs’ locator, etc.
DatasetsCartesian Product
Candidate Set
Recall (%)
Total cost
Time
Restaurants 176.4K 176.4K 100 $0 -
Citations 168 million 38.2K 99 $7.20 6.2 hours
Products 56 million 173.4K 92 $22.00 2.7 hours
19
Blocking

Conclusion Current crowdsourced EM often requires a developer Need for developer poses serious problems
– does not scale to EM at enterprises– cannot handle crowdsourcing for the masses
Proposed hands-off crowdsourcing (HOC)– crowdsource the entire workflow, no developer
Developed Corleone, the first HOC system for EM– competitive with or outperforms current solutions– no developer effort, relatively little money– being transitioned into production at WalmartLabs
Future directions– scaling up to very large data sets– HOC for other tasks, e.g., joins in crowdsourced RDBMSs, IE