centralized log management based on logstash and...
TRANSCRIPT

Centralized log management based on
Logstash and Kibana - case study
Dariusz Eliasz
20.05.2014 Atmosphere Conference

• What’s the problem ?
• Solutons
• Transport format
• Architecture
– Sender
– Log router
– Log collector
– Full text search engine
– GUI
• Use case
Agenda

What’s the problem ??



Solutons ??



Transport format - syslog
• RFC3164 (BSD syslog )
• limited size - 1kB
• format of a syslog message:
– PRIORITY (calculated from severity and facility)
– HEADER (tmestamp + hostname or IP)
– MSG (tag + content)
<34>Oct 11 22:14:15 mymachine su: 'su root' failed for lonvick on /dev/pts/8

Transport format - json
• JavaScript Object Notaton
• lightweight text-data interchange format
• language independent
• self-describing

Transport format - json
{
"LogType": "access_log",
"Vhost": "atmosphere-conference.com",
"HtpsOn": "false",
"Xrealip": "1.2.3.5",
"Clientp": "91.17.13.28",
"UserAgent": "Mozilla/4.0 (compatble; MSIE 6.0; Windows NT 5.1)",
}
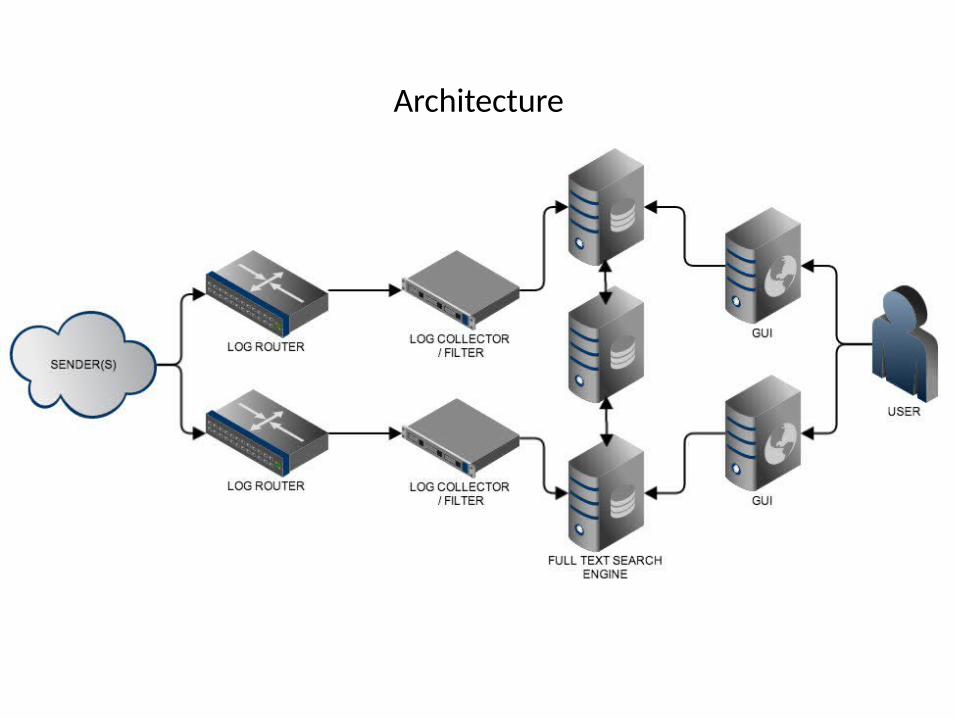
Architecture

Sender

Sender
• nxlog (htp://nxlog-ce.sourceforge.net/)
• multple input types:
– tcp socket
– udp socket
– fle input
– unx socket
• multple parser types:
– bsd syslog
– json

Sender
Good practce:
• make as much as possible processing on sender site, eg: apache access logs in
json format
• automate confguraton management
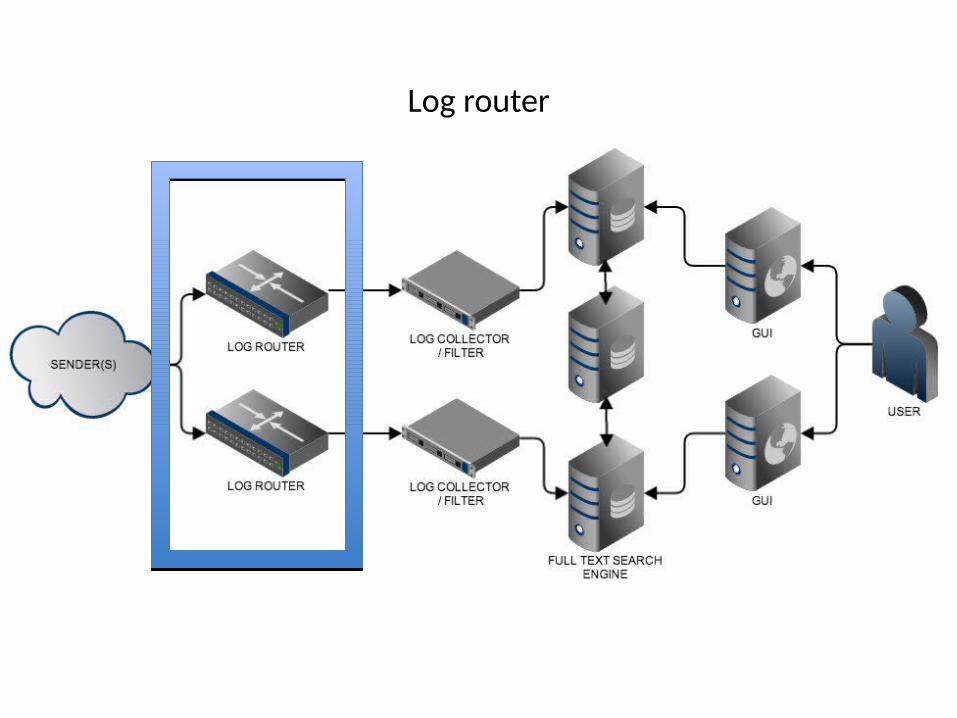
Log router

Log router
nxlog
nxlog logstash
logstash
redis
redissyslog-ng
syslog-ng redis

Log router
### JSON PARSER
parser p_json {
json-parser (prefx("_json."));
};
### FILTERS
flter f_someflter {
("${_json.SomeJsonField}” == ”abc.com”)
};
### INPUTS & OUTPUTS
### LOG PATHS
log {
source(s_network_json);
destnaton(d_udp_logstash);
destnaton(d_tcp_hadoop);
#fags(fow-control); # disabled to separate destnatons
};

Log router
Good practce:
• good separaton of destnatons
• calculate enough redis size – it’s yor bufer
• batch events writes to redis
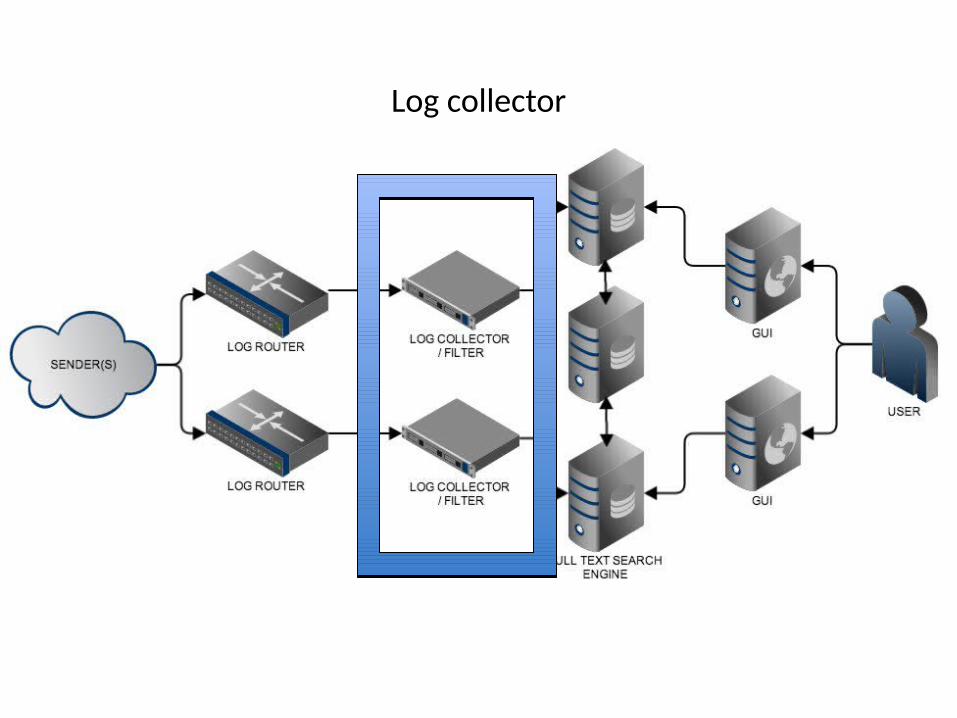
Log collector

Log collector
• Logstash htp://logstash.net/
• collectng, parsing and storing logs tool
• plugins:
Inputs
• fle
• gelf
• tcp
• log4j
• redis
• varnishlog
Codecs
• json
• line
• msgpack
• netlow
• multline
Filters
• grok
• alter
• cidr
• geoip
• grep
• mutate
Outputs
• elastcsearch
• graphite
• jira
• tcp
• zeromq
• zabbix

Log collector
Good practce:
• keep up2date version of java & logstash
• use batch & multthread read from redis
• read logs
• bulk writes to elastcsearch

Full text search engine
• Elastcsearch htp://www.elastcsearch.org/
• distributed, real-tme search and analytcs engine
• store documents as a JSON
• high availability
• schema free
• index mult-tenancy
• on top of Lucene

Full text search engine
• every index is replicated
• every index sharded
• index parttoning – tme based
• data retenton – tme based

Full text search engine
Good practce:
• half memory for ES (<30GB), half for system cache
• bootstrap.mlockall: true
• gateway.recover_afer_nodes
• indices.felddata.cache.size
• authorizaton via proxy
• curator
• Marvel plugin

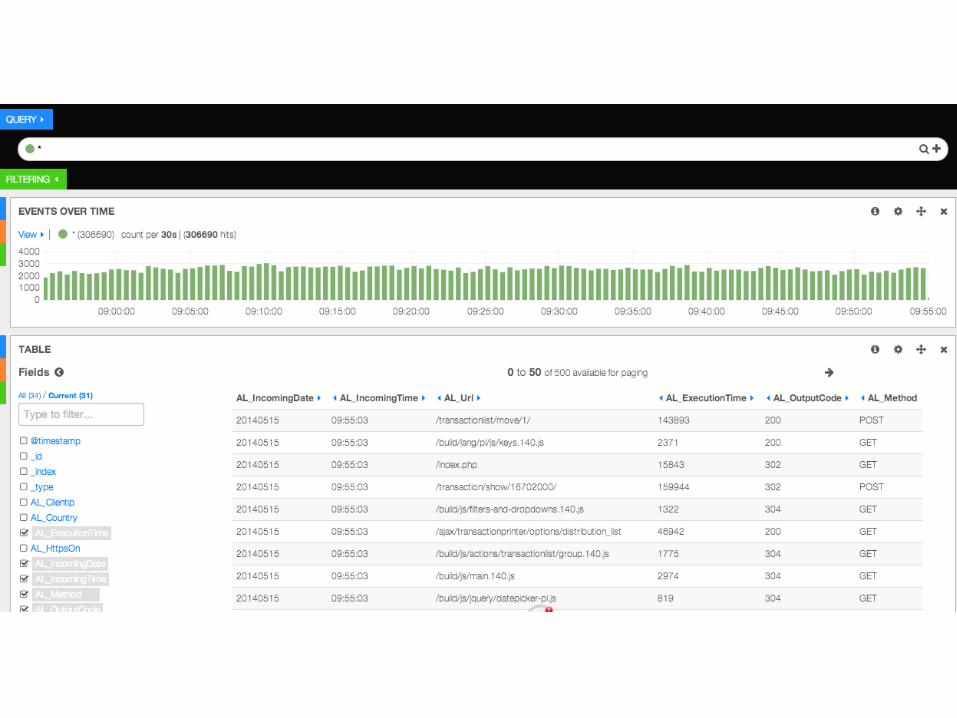
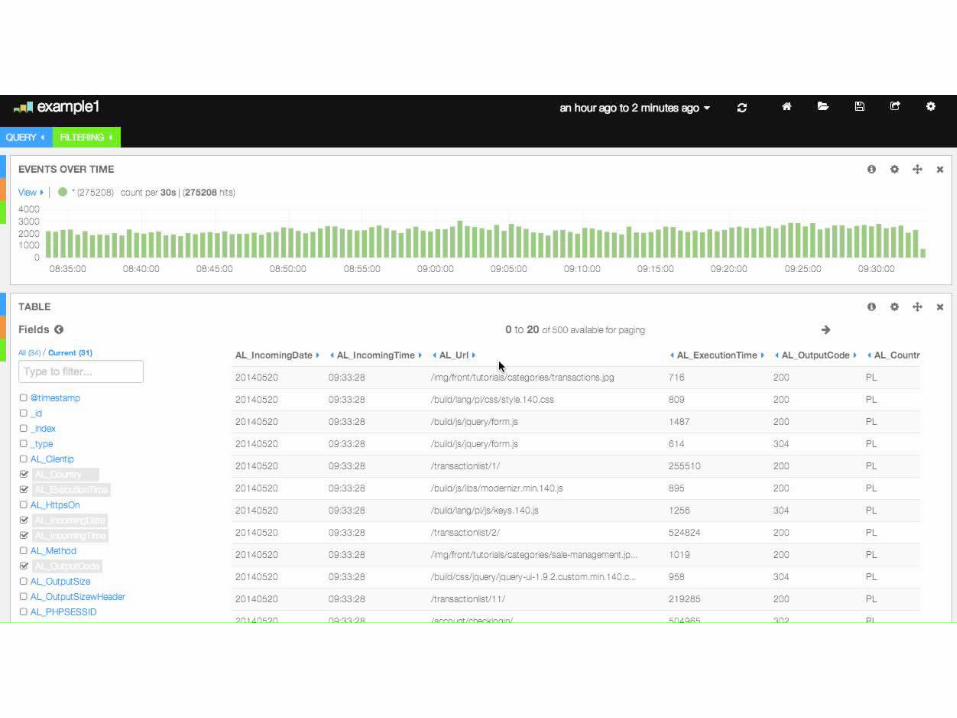
GUI
• Kibana 3 htp://www.elastcsearch.org/overview/kibana/
• search, graph & analyze logs
• JavaScript based (AngularJS)
• only simple htp server needed

Q&A

Sources
Images:
htp://www.datalife7.com/2014/01/einsteins-secret-to-problem-solving-and.html
htp://www.formengifs.com/victorinox-swiss-army-swiss-champ-multtool-knife/
htp://www.slashgear.com/google-data-center-hd-photos-hit-where-the-internet-lives-gallery-17252451/