ccnp route
DESCRIPTION
ccnp routerTRANSCRIPT

Enhanced Interior Gateway Routing Protocol, or EIGRP, is a Cisco proprietary, advanced distance vector dynamic routing protocol.
EIGRP Characteristics
Fast Convergence
EIGRP uses the DUAL algorithm to converge very quickly. It does this by knowing neighbor router’s routing tables and predefining primary and secondary routes to every destination network.
Triggered Updates
EIGRP uses partial triggered updates to its directly connected neighbors rather than periodically sharing its entire routing table. This saves link bandwidth because updates are only sent if a change is incurred, only the changes are sent in the update, and lastly – the updates are only sent to a routers’s affected neighbors. Very efficient!
Protocol Independent
Enhanced Interior Gateway Routing Protocol supports more than just IPv4. It supports IPv4, IPv6, IPX, and AppleTalk.
Multicast
EIGRP sends route updates, hellos, and queries to its neighbors using the multicast address 224.0.0.10 so end hosts are not affected. Hellos are sent out every 5 seconds by default to learn about new neighbors and make sure existing neighbors are still available.
VLSM
Variable length subnet masking is supported by EIGRP because it is a classless routing protocol. That means subnet masks are included in route updates.
Terminology
Feasible and Advertised Distance
EIGRP’s DUAL algorithm determines the best route to a particular network by using distance information, known as cost or metric. DUAL determines the lowest cost path by adding up the cost to the destination network. Neighbors exchange the cost to every route they know of when a neighbor adjacency is formed. A router then uses that information to calculate their own cost to the same network by adding the cost between themselves and their neighbor, then adding that to the neighbor’s advertised cost.

So, (the cost between neighbors) + (the neighbor’s cost to the destination network) = the total cost to the remote network, or the feasible distance. The cost the neighbor advertised to the remote network is known as the advertised distance.
See the diagram below.
Successor
Think of the successor as the active, or primary, route to a destination for EIGRP. The successor is actually the neighbor router that has the least-cost path to a destination network (a.k.a. has the lowest feasible distance). Successor routes are added directly to the routing table. You should also know that multiple successors can exists if they have identical feasible distance values.
Feasible Successor
This is more like the backup route EIGRP chooses to a destination network. The feasible successor feature is what makes EIGRP convergence so unique and so fast. It always tries to find a backup route. In the event that the successor fails, it can immediately switch over to the feasible successor (backup) route with very little delay. To qualify as a feasible successor, the AD must be less than the successor’s FD. This helps ensure a loop-free layer 3 path.

Tables
Neighbor Table
EIGRP discovers neighbors by sending out hellos every 5 seconds. When a routers receives a hello with the same AS number defined, it forms an adjacency and adds the local interface it used to reach it as well as the neighbor’s IP address to the EIGRP neighbor table.
Topology Table
When routers form an adjacency, they exchange route information. That information is transferred to the EIGRP topology table, which contains all the destinations advertised by a router’s neighbors.
There are two different types of entries in the topology table, active and passive. Now you may think that the active entry is the preferred or “actively-in-use” route, but surprisingly, the opposite is true. The route in the topology table that is in the active state signifies that it is “actively” looking for an alternative path to a destination because the successor has failed and no FS exists. Obviously this is not an ideal scenario.
If a router’s successor route becomes unavailable, but has a feasible successor – the FS will immediately become the successor and there is almost no delay incurred. This is the primary reason EIGRP convergence times tend to be some of the fastest of all the dynamic routing protocols.
If, however, a router’s successor becomes unavailable and does not have a FS to the destination, it will send query messages to all of its neighbors asking if they know of a path to the destination. The neighbors will either respond with a path or forward the query to all of their neighbor routers until a path is identified and relayed back to the original requester or no more neighbor routers exist. During the time the router is waiting back for a response, it is unable to forward traffic to the destination network, which can hurt EIGRP’s convergence time.
Passive entries represent routes that have at least a single successor and perhaps a feasible successor. They are what you should see in a normal, stable topology. Notice the “P’s” in the output from the show eigrp topology command below. They indicate that the entries in the EIGRP topology table are in the passive (read: normal) state.
R1#sh ip eigrp topology IP-EIGRP Topology Table for AS(1)/ID(10.1.1.1) Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply, r - reply Status, s - sia Status P 10.1.3.0/24, 1 successors, FD is 156160 via 10.1.100.3 (156160/128256), FastEthernet0/0 P 10.1.2.0/24, 1 successors, FD is 156160 via 10.1.100.2 (156160/128256), FastEthernet0/0 via 10.1.200.2 (2297856/128256), Serial1/0 P 10.1.1.0/24, 1 successors, FD is 128256 via Connected, Loopback1 P 192.168.100.0/24, 1 successors, FD is 156160 via 10.1.100.3 (156160/128256), FastEthernet0/0 P 10.1.100.0/24, 1 successors, FD is 28160 via Connected, FastEthernet0/0 P 10.1.200.0/24, 1 successors, FD is 2169856 via Connected, Serial1/0

EIGRP Messages
Hello
EIGRP hello packets are sent out every 5 seconds by default using multicast address 224.0.0.10 to maintain and discover neighbor relationships. On slower (T1 and below) and NBMA links, hellos are sent every 60 seconds to conserve bandwidth.
EIGRP hello packets also contain a hold timer which lets the router know if a neighbor is down. The hold timer is set to 15 seconds normally (~3 unresponsive hellos), and 180 seconds for slower WAN links. When a router receives a hello packet from another router with the same AS (Autonomous System) number, it automatically forms a neighbor relationship (also known as an adjacency).
Update
During the EIGRP start-up process on a router, an update message is sent out to its neighbors containing the contents of the router’s routing table. The only other time an update packet is sent is when network changes occur on a router and it then sends out an update message to its neighbors who the route change would affect.
Query
When EIGRP looses its successor route and does not have a FS, it sends out a query message to all of its neighbors asking if they know a path. (See topology section above)
Ack
Acknowledgement packets are sent in response to update, query, or reply packets.
Reply
When a router responds to a neighbor router looking for a route (query), it sends it in the form of a reply.
Graceful Shutdown
When an EIGRP process is shut down, the router sends out “goodbye” messages to its neighbors (ironically in the form of hello packets). The neighbors can then immediately begin recalculating paths to destinations that went through the shutdown router without having to wait for the hold timer to expire.
EIGRP Metrics
There are 5 descriptives EIGRP uses to calculate its metric, although Cisco generally does not recommend tuning these metrics unless you have a very specific purpose. You should be aware that only the bandwidth and delay numbers factor into the default formula.

Bandwidth – the lowest bandwidth value between the source and destination Delay – the cumulative delay along a series of links Reliability Load MTU
EIGRP Configuration
Step 1. Define EIGRP as the routing protocol with a predefined Autonomous System ID. Routers will not form a neighbor relationship if their AS numbers do not match.
R3(config)# router eigrp 1
Step 2. Define the attached networks you want to participate in EIGRP
Add each network to the EIGRP process with the network prefix mask command for each network. The mask is an inverted mask, like ACLs use. Example, a /24 mask would be 0.0.0.255.
The network prefix mask command tells the router which local interfaces will then participate in EIGRP. This can be very useful if you do not want specific interfaces to participate in EIGRP.
Using the mask statement will define how you want the routes summarized if you turn off auto summarization. If you choose not to use the mask, EIGRP will assume the networks are part of the major networks (class A,B,C boundaries) and could cause potential problems.

Example Configuration
R3(config-router)#router eigrp 1 R3(config-router)# network 10.1.100.0 0.0.0.225 R3(config-router)# network 192.168.100.0 0.0.0.3 R3(config-router)# network 192.168.100.4 0.0.0.3 R3(config-router)# no auto-summary
The output of R3′s running configuration can be seen below.
R3#sh run | begin router eigrp 1 ... router eigrp 1 network 10.0.0.0 network 192.168.100.0 0.0.0.3 network 192.168.100.4 0.0.0.3 no auto-summary
EIGRP Verification
show ip eigrp neighbors – displays EIGRP neighbors a router has discovered.
R3#sh ip eigrp neighbors IP-EIGRP neighbors for process 1 H Address Interface Hold Uptime SRTT RTO Q Seq (sec) (ms) Cnt Num 1 10.1.100.2 Fa0/0 13 00:12:23 737 4422 0 21 0 10.1.100.1 Fa0/0 14 00:12:29 535 3210 0 22
show ip eigrp topology – displays the output of the EIGRP topology tables including successor and feasible successor routes.
R3#sh ip eigrp topology IP-EIGRP Topology Table for AS(1)/ID(192.168.100.5) Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply, r - reply Status, s - sia Status P 192.168.100.4/30, 1 successors, FD is 128256 via Connected, Loopback15 P 10.1.3.0/24, 1 successors, FD is 128256 via Connected, Loopback3 P 10.1.2.0/24, 1 successors, FD is 156160 via 10.1.100.2 (156160/128256), FastEthernet0/0 P 10.1.1.0/24, 1 successors, FD is 156160 via 10.1.100.1 (156160/128256), FastEthernet0/0 P 192.168.100.0/30, 1 successors, FD is 128256 via Connected, Loopback11 P 10.1.100.0/24, 1 successors, FD is 28160 via Connected, FastEthernet0/0 P 10.1.200.0/24, 2 successors, FD is 2172416 via 10.1.100.1 (2172416/2169856), FastEthernet0/0 via 10.1.100.2 (2172416/2169856), FastEthernet0/0
show ip route – shows the ip routing table entries for all routing protocols.
R3#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route Gateway of last resort is not set 10.0.0.0/24 is subnetted, 5 subnets C 10.1.3.0 is directly connected, Loopback3 D 10.1.2.0 [90/156160] via 10.1.100.2, 00:14:46, FastEthernet0/0 D 10.1.1.0 [90/156160] via 10.1.100.1, 00:14:55, FastEthernet0/0 C 10.1.100.0 is directly connected, FastEthernet0/0 D 10.1.200.0 [90/2172416] via 10.1.100.2, 00:14:46, FastEthernet0/0 [90/2172416] via 10.1.100.1, 00:14:46, FastEthernet0/0 192.168.100.0/30 is subnetted, 2 subnets C 192.168.100.4 is directly connected, Loopback15 C 192.168.100.0 is directly connected, Loopback11

show ip route eigrp – displays the EIGRP routes that the routing table is using. All internal EIGRP routes will be marked with a D (as in DUAL) at the beginning.
R3#sh ip route eigrp 10.0.0.0/24 is subnetted, 5 subnets D 10.1.2.0 [90/156160] via 10.1.100.2, 00:16:49, FastEthernet0/0 D 10.1.1.0 [90/156160] via 10.1.100.1, 00:16:57, FastEthernet0/0 D 10.1.200.0 [90/2172416] via 10.1.100.2, 00:16:49, FastEthernet0/0 [90/2172416] via 10.1.100.1, 00:16:49, FastEthernet0/0
EIGRP Default Routes
Defaults routes make life easier in many situations. They can decrease the size (and complexity) of the routing table by providing a path to all unspecified destinations.
One option is to use a static default route with the ip route 0.0.0.0 0.0.0.0 interface/address statement as discussed in the Routing Fundamentals page. This must be configured on every router that will use that default route.
Another option if you are running EIGRP is to use the ip default-network network-number command in global configuration mode. Any network that is reachable within the local router’s routing table is eligible to be used by EIGRP as a default route. Once configured, EIGRP will advertise the route to its EIGRP neighbors as a default route.
** If you want to use this method, in conjunction with a static route – you will have to first redistribute the static route into EIGRP.
** Once you use the ip default-network command to define a default route for EIGRP, the router creates a static route in the configuration without notifying you. That means in order to remove the default route, you must use the no ip route command instead of no ip default-network.
Summarization
EIGRP summarizes routes by their major classful boundaries, which can be problematic and cause specific subnets to not be advertised correctly.
To disable automatic summarization:
R1(config)# router eigrp 1 R1(config-router)# no auto-summary
It is also possible to manually summarize routes with EIGRP out specific interfaces. Under the interface configuration mode, use the ip summary-address eigrp autonomous-system command.
R1(config)# intferface s0/0/0 R1(config-if)# ip summary-address eigrp 1 10.1.2.0 255.255.255.0
EIGRP over WAN Networks

EIGRP + MPLS
MPLS defines the customer’s WAN routers as CE, or customer edge routers and the carrier’s border routers as PE, or provider’s edge routers. The CE routers appear to each other as directly connected peers. When CE West sends information to CE East, PE West intercepts the data, strips the Ethernet frame, encapsulates it into a MPLS packet, and forwards it over the service provider’s network to PE East. PE East strips off the MPLS information, re-encapsulates it into an Ethernet frame and forwards it on to CE East.
This transparent transport allows an EIGRP neighbor relationship to form between the two customer routers.
EIGRP + Frame Relay
Let’s face it; frame relay is a dying WAN technology. Other, more current WAN options like MPLS and metro Ethernet have taken over, but Cisco thinks it’s important for us to understand the underlying framework of how frame relay works. Frame relay works using switched, virtual circuits through the service provider network. One of the advantages of Frame Relay is that it allows multiple logical circuits to be configured on a single physical interface. Each VC is identified with a locally-significant DLCI, or Data-Link Connection Identifier. The layer 2 virtual circuit must then be mapped to a layer three neighbor, which can be either dynamic or static.
Frame relay is able to emulate point-to-point links by using multiple subinterface on a single physical interface (often used on hub-and-spoke topologies). This allows neighbor’s to be identified as down much more quickly for two reasons:

1. The default timers are shorter (5 sec hold timer, 15 second dead timer).2. The subinterface is marked down whenever its local DLCI goes down.
Static
To configure frame relay statically, configurations must be done on the interface level. The broadcast descriptive is required at the end of the statement because frame relay defaults to a non-broadcast medium. Also, static mappings can be applied to both multipoint interfaces as well as subinterfaces on a single physical port.
R1(config-if)# frame-relay map ip remote-ip-address loacl-dlci broadcast
Dynamic
Dynamic mappings use inverse ARP. In this case, routers only form EIGRP neighbor relationships with other routers they connect to using a frame relay virtual circuit.
No IP split horizon
When running EIGRP on frame relay multipoint subinterfaces, a major communication problem can occur. Split-horizon is a method of preventing routing loops in distance-vector routing protocols by prohibiting a router from advertising a route back onto the interface from which it was learned.
When a hub and spoke frame relay topology exists, multipoint subinterfaces are configured on the hub router. The issue is that split horizon is enabled by default, so in the example below, if R2 learns routes from R1, it cannot then pass those on to R3 because split horizon would prevent the advertisement from going out the same physical interface. This results in R2 being able to communicate with the spoke router’s networks, but R3 and R1 are unable to communicate with each other.
To remedy the situation, split horizon must be disabled on the R2 EIGRP process.
R2(config-if)# no ip split-horizon EIGRP as-number

Managing EIGRP Bandwidth
There are two important points to remember when running EIGRP over WAN links. The first is that EIGRP assumes that WAN interfaces run at T1 speed (1544 kbs). The second is that EIGRP will allocate up to 50% of a link’s bandwidth for EIGRP control traffic.
These two combined can be problematic on links that are slower than a T1 (like a 64k fractional T1 for example). In that situation, EIGRP messages could choke out data traffic quickly. To control that, the bandwidth command should be used in WAN links to tell EIGRP what the actual link bandwidth is.
R1(config)# int serial 0/0/0 R1(config-if)# bandwidth 64
EIGRP is often used on frame relay for this reason alone. The ability to control the routing protocol’s usable bandwidth so simply makes it a popular choice.
Other EIGRP Options
Passive Interfaces
Not to be confused with the passive (healthy) topology table entries, interfaces with the passive-interface command applied do not allow any routing updates or hellos out the interface. For EIGRP, this means that the router will not form adjacencies with connected routers on that particular port.
R1(config)# router eigrp 1 R1(config-router)# passive-interface gig 3/1
Unicast Neighbors
EIGRP uses multicast address 224.0.0.10 when sending messages to its neighbors. You should be aware that EIGRP can also use a unicast address when communicating with a specific neighbor. To configure it:
R1(config)#router eigrp 1 R1(config-router)# neighbor ip-address
The IP address used must be in one of the same subnet ranges as one of the router’s interfaces.
EIGRP load balancing
Out of the box, EIGRP will automatically load balance across equal-cost paths with no special configuration. EIGRP is unique, however, in its ability to load balance across unequal-cost paths with a single command.
The variance command allows unequal-cost load balancing over up to 6 different paths. But here’s the key, it only works when the cost of the path is lower than the variance number multiplied by the best metric.

Here is an example scenario.
R1 will by default use the path through R3 because it has the lowest metric. To enable unequal-cost load balancing, we can use the following command:
R1(config)#router eigrp 1 R1(config-router)# variance 2
The variance command multiplies the best cost (10,000) by 2 (20,000) and will begin load balancing across all paths with a FD less than that – which includes the path through R2(15,000). This will load balance the traffic in proportion to each path’s metric.
Maximum-paths
By default, Cisco IOS will load balance across 4 equal-cost paths only. Using the maximum-paths command, you can configure the router to load balance over up to 16 paths. Setting it to 1 disables the load balancing.
R1(config)#router eigrp 1 R1(config-router)# maximum-paths number-of-paths
EIGRP Authentication
EIGRP supports authentication of its messages using an MD5 hash. When configured, if an incoming EIGRP packet’s hash does not match the local hash, the packet is silently dropped.
Authentication configuration steps:

1. Configure a key chain to group the keys (read: passwords).2. Create a key(s) inside the keychain. The router will look inside the keychain and compare
the keys against incoming packets.3. Enable authentication and assign a key to an interface.4. Indicate MD5 as the authentication type.
Example
R1(config)# key chain TEST R1(config-keychain)# key 1 R1(config-keychain-key)# key-string samplepassword R1(config-keychain-key)# exit
R1(config)# interface gig 1/12 R1(config-if)# ip authentication mode eigrp 10 md5 R1(config-if)# ip authentication key-chain eigrp 10 TEST
EIGRP Stub Routing
If a router is a spoke in a hub-and-spoke router topology, it is considered a stub router. It is not a transit router and usually has only a single neighbor router, sometimes two.
Within EIGRP you can define a router as a stub router to limit the EIGRP queries. This saves bandwidth and prevents neighbor routers from requesting alternate routes when a path fails. If you have many spoke routers, this can dramatically improve EIGRP reconvergence time. The EIGRP stub router still receives all route updates from its neighbor(s) by default.
R1(config)#router eigrp 1
R1(config-router)# eigrp stub [receive-only | connected | static | summary | redistributed]
Options ResultReceive-only Router will not advertise any networks (including its own)Connected Router will advertise connected routes (enabled by default)Static Router will advertise static routesSummary Router will advertise summary routes (enabled by default)
RedistributedRouter will advertise routes that have been redistributed into EIGRP from another routing protocol or AS
EIGRP Best Practices
Summarize routes when possible Limit the network depth to 7 hops Limit the scope of EIGRP queries

OSPF, or Open Shortest Path First, is a link-state, open-standard, dynamic routing protocol. OSPF uses an algorithm known as SPF, or Dijkstra’s Shortest Path First, to compute internally the best path to any given route.
OSPF is classless and converges fairly quickly, using cost as it’s metric. A router running OSPF creates its own database which contains information on the entire OSPF network, not simply neighbor’s routes like EIGRP. This allows the router to make intelligent choices about path selection on its own instead of relying exclusively on neighbor information.
OSPF routers do form neighbor relationships though. They exchange hellos with neighboring routers and in the process learn their neighbor’s Router ID (RID) and cost. Those values are then sent to the adjacency table.
Every router is responsible for computing its own best paths to all destinations within an OSPF domain. Once the SPF algorithm selects the best paths, they are then eligible to be added to the routing table.
Link State Database
Once a router has exchanged hellos with its neighbors and captured Router IDs and cost information, it begins sending LSAs, or Link State Advertisements. LSAs contain the RID and costs to the router’s neighbors. LSAs are shared with every other router in the OSPF domain. A router stores all of its LSA information (including info it receives from incoming LSAs) in the Link State Database (LSDB).
I apologize if the acronyms are starting to pile up. OSPF, architecturally speaking, is more complicated than its counterpart EIGRP – and the long list of acronyms and definitions is part of that.
Areas
OSPF is different from EIGRP in that it uses areas to segment routing domains. This helps partition routers into manageable groups if the layer 3 network begins to get large. It all starts with area 0. Every OSPF network must contain an area 0, sometimes referred to as the backbone area and every additional area must be physically connected to area 0. From there, other areas are optional.
Note that the SPF algorithm only runs within a single area, so routers only compute paths within their own area. Inter-area routes are passed using border routers.

All link state databases must match within an OSPF area. This means that the more OSPF-enabled routers are configured for the same area, the more LSA advertisements that must be sent out. After you reach about 50 routers, the high levels of LSA traffic and numerous routing table entries can become a problem. That is why Cisco recommends limiting an OSPF area to no more than 50-100 routers.
The following three factors determine the maximum number of routers:
How easily the area’s subnets can be summarized The type of areas being used The number of external LSAs being injected
An added bonus of partitioning out your OSPF network into areas is that it is a natural fit for a hierarchical IP scheme.
Area Types
Backbone areaAnother name for area 0

Regular area Non-backbone area, with both internal and external routes
Stub area Contains only internal routes and a default route
Totally Stubby Area Cisco proprietary option for a stub area
Not-So-Stubby area (NSSA) Contains internal routes, redistributed routes, and optionally a default route
Totally Stubby NSSA Cisco proprietary option for NSSA
Router Roles
Internal: All interfaces in a single area (routers 1, 4, 5 in diagram above)
Backbone: At least one interface assigned to area 0 (routers 1, 2 ,3 in diagram above)
Area Border Router (ABR): Have interfaces in two or more areas (routers 2 and 3 in diagram above) ABRs contain a separate Link State Database, separating LSA flooding between areas, optionally summarizing routes, and optionally sourcing default routes.
Autonomous System Boundary Router (ASBR): Has at least one interface in an OSPF area and at least one interface outside of an OSPF area.
OSPF Metric
Each interface is assigned a cost value based purely on bandwidth. The formula is:
Cost = (100Mbs/bandwidth)
Higher bandwidth means a lower cost.
Let’s run through some common examples quickly:
T1 line | 100,000 / 1544 = 64
10 Mbps | 100,000 / 10,000 = 10
100 Mbps | 100,000 / 100,000 = 1
1000 Mbps | 100,000 / 1,000,000 = .1 1 (OSPF still uses 1 for this, see explanation below)

The cost is then accrued at each hop along the path based on the link’s bandwidth. Unfortunately, OSFP was written when 100Mbs was considered fast. Because of that, it assigns the same cost to any interface with speeds higher than 100Mbs. To OSPF, a Fast Ethernet interface is weighted the same as a Gigabit Ethernet interface, both a cost of 1. To fix that problem, you can use the auto-cost command under the OSPF process.
R1(config-router)# auto-cost reference-bandwidth 1000
Another option is to simply change the cost on a per-interface basis with the ip ospf cost command (using any number between 1-65,535).
R1(config-if)# ip ospf cost 35
Link State Advertisements
LSAs contain a sequence number and a Router ID. Sequence numbers are 32 bits, starting with 0×80000001. The sequence number increases if:
a route is added or deleted a LSA ages out
The largest sequence number is always the most current. The default time that LSAs are aged out is 30 minutes. When an LSA enters a router, it checks it against its internal Link State Database (LSDB).
If it is new, it is added to the LSDB and the SPF algorithm is re-run. If it contains a Router ID (RID) that is already in the database, entries with an older
sequence number are discarded. If it receives an older version (according to its sequence number), it discards the LSA and
sends back the newer version to the original sender.
The command show ip ospf database will display the sequence numbers and age (in seconds) for each entry.
LSDB Overload
In large OSPF networks, if major network changes occur, a flood of LSAs will immediately hit the entire network. The number of incoming LSAs to each router could be substantial and bring the CPU and memory to its knees.
To mitigate that scenario, Cisco offers what it refers to as Link Sate Database Overload Protection. Once enabled, if the defined threshold is exceeded over one-minute time period, the router will enter the ignore state – dropping all adjacencies and clearing the OSPF database.
Know that this is a drastic response because routing will be disrupted during that period.
R1(config-router)# max-lsa number

LSA Definitions
LSA Type Name Description
1 Router LSA• Inter-area route advertisements• Produced by each OSPF router• Flooded within an area
2 Network LSA• Produced by routers on a multi-access link• Produced by DRs• Flooded within an area
3 Summary LSA• Advertises inter-area routes• Produced by an ABR• Flooded to adjacent areas
4 Summary LSA• Advertises routes to an ASBR• Produced by an ABR• Flooded to adjacent areas
5 External LSA• Advertises routes in another routing domain• Produced by an ASBR router• Flooded to adjacent areas
6 Multicast LSA • Used in multicast OSPF environments
7 NSSA LSA• Advertises routes in another routing domain• Produced by an ASBR within a NSSA
8 External Attributes LSA • Used in OSPF/BGP convergence9-11 Opaque LSAs • Used only for specific applications

OSPF Packet Types
HelloDiscovers neighbors and works as a keepalive.
Link State Request (LSR) Requests a Link State Update (LSU), see below.
Database Description (DBD) Contains a summary of the LSDB, including RIDs and sequence numbers.
Link State Update (LSU) Contains one or more complete LSAs.
Link State Acknowledgement (LSAck)Acknowledges all other OSPF packets (except hellos). OSPF sends the five packet types listed above over IP directly, using IP port 89 with an OSPF packet header. Multicast address 224.0.0.5 is used if sending to all routers, address 224.0.0.6 is used for sending to all OSPF DRs.

OSPF Neighbors
Hellos are sent out periodically using multicast on OSPF enabled routers. The router forms an adjacency with a peer router when it sees its own Router ID in the neighbor field of another router’s hello message. That indicates there is direct, bi-directional communication on the same subnet.
Note: On multi-access links, adjacencies are only formed between the router and the DR and BDR.
All of the following fields in an OSPF hello message must match for an adjacency to form:
hello timer dead timer area ID authentication type password stub area flag
As with many network protocols, hellos act as a form of keepalive or heartbeat. With OSPF, if four consecutive hellos are not received (the dead time), the router is considered down. Point-point interfaces: hellos every 10 seconds, 40 second dead timer
Nonbroadcast multiaccess (NBMA) interfaces: hellos every 30 seconds, 120 second dead timer
OSPF States
There are 7 different OSPF states when forming neighbor relationships. Take the time to learn the states and their corresponding functions.
1. Down State OSPF has not started and no hellos have been sent.
2. Init StateHellos are sent out all OSPF-participating interfaces.
3. Two-way State A hello is received from another router with its own RID in the neighbor field. All other required elements match and the routers become neighbors.
4. Exstart State Routers determine which one will begin the route exchange process with the other.
5. Exchange State Routers exchange DBDs.

6. Loading State Routers compare the DBD to their LS database. LSRs are sent out for missing or outdated LSAs. Each router then responds to the LSRs with a Link State Update. Finally, the LSUs are acknowledged.
7. Full State The LSDB is completely synchronized with the OSPF neighbor.
OSPF Configuration
OSPF configuration is not too complicated, but has some important syntax distinctions from EIGRP. First, it is configured from router configuration mode and requires a process ID appended to the router ospf command. The process ID is only locally significant, so don’t worry if it doesn’t match on other OSPF routers.
R1(config)# router ospf process-id
The next step is to determine which router interfaces you want participating in OSPF. Just like EIGRP, the network statements define which local router interfaces will participate.
R1(config)# router ospf 10 R1(config-router)# network 10.1.1.0 0.0.0.255 area 0 R1(config-router)# network 10.9.9.0 0.0.0.255 area 1
In the example above, interfaces in the 10.1.1.0/24 subnet will participate in OSPF area 0. Interfaces in the 10.9.9.0/24 subnet will participate in OSPF area 1. Unlike EIGRP, the subnet wildcard mask in the network statement is not optional because OSPF is classless by default. Let’s do another example.
R1 has six interfaces, all within area 0:GigabitEthernet 0/0: 192.168.100.1/24GigabitEthernet 0/1: 192.168.101.1/24GigabitEthernet 0/2: 192.168.102.1/24GigabitEthernet 0/3: 192.168.103.1/24Serial 1/0: 10.100.100.1/30Serial 1/1: 10.100.100.5/30
The simplest way to configure OSPF an all interfaces into area 0 would be to use this command:
R1(config-router)# network 0.0.0.0 255.255.255.255 area 0
A second option is to break up the 10. and 192. networks into different statements:
R1(config-router)# network 10.0.0.0 0.255.255.255 area 0 R1(config-router)# network 192.168.100.0 0.0.3.255 area 0
The third way to configure the interfaces to participate in OSPF:

R1(config-router)# network 10.100.100.1 0.0.0.0 area 0 R1(config-router)# network 10.100.100.5 0.0.0.0 area 0 R1(config-router)# network 192.168.100.1 0.0.0.0 area 0 R1(config-router)# network 192.168.101.1 0.0.0.0 area 0 R1(config-router)# network 192.168.102.1 0.0.0.0 area 0 R1(config-router)# network 192.168.103.1 0.0.0.0 area 0
All three approaches achieve the exact same result. The configuration you choose is up to you.
Interface Configuration
An alternative configuration option is to configure an interface to participate in OSPF directly. The ip ospf process-id area area-id command takes precedence over the more common network commands.
R1(config)# int gig 0/1 R1(config-if)# ip ospf 10 area 0
Router ID
The SPF algorithm uses a Router ID to identify hops along a path. The problem, of course, is that routers don’t have a generic “router ID” built in.
The designers of OSPF decided to use the highest IP address assigned to a loopback interface as the Router ID (RID) by default. If no loopback is configured, it will use the highest IP address assigned to an active interface when the OSPF process begins.
OSPF will not change the RID, even if another interface with a higher IP address comes online unless the OSPF process is restarted. This helps keep the network stable and happy.
Note: The clear ip ospf process command will also force the OSPF process to restart, but will cause an outage – so use it with caution.
Loopbacks are preferred for use as a router ID because they are virtual interfaces and are not affected by links going up and down. To configure a loopback interface, first create it and assign it an IP address.
R1(config)# int loopback 0 R1(config-if)# ip address 10.100.100.1 255.255.255.255
Static RIDs
It is also possible to manually define a static Router ID within OSPF with the router-id command.
R1(config)# router ospf 10 R1(config-router)# router-id 10.100.100.1
DRs & BDRs

SPF works by mapping all paths to every destination on each router. It uses the RID to identify hops along each path and uses bandwidth as a metric between those hops. This whole system works really well when routers are connected with point-to-point links and OSPF traffic is simply sent using multicast address 224.0.0.5.
It doesn’t work well, however, when a router is connecting to multiaccess networks like an Ethernet VLAN. Multiaccess OSPF links require a Designated Router (DR) be elected to represent the entire segment. Another router is then elected as the Backup Designated Router, or BDR. On that specific multiaccess segment, routers only form adjacencies with the DR and BDR.
The DR uses type 2, network LSAs to advertise the segment over multicast address 224.0.0.5. The Non-Designated routers then use IP address 224.0.0.6 to communicate directly with the DR.
OSPF Election Process
1. When the OSPF process on a router starts up, it listens for hellos. If it does not receive any within its dead time, it elects itself the DR.
2. If hellos are received before the dead time expires, the router with the highest OSPF priority is elected as the DR. Next, the same process happens to elect the BDR. Note: If a router’s OSPF priority is set to 0, it will not participate in the elections.
3. If two routers happen to have the same OSPF priority, the router with the highest Router ID will become DR. The same is true for BDR.
Once a DR is elected, elections cannot take place again until either the DR or BDR go down. This essentially means that there is no OSPF DR preemption if another router comes online with a higher OSPF priority. In the case that the DR goes down, the BDR automatically is assigned the DR role and a new BDR election occurs.
Be aware that a router with a non-zero priority that happens to boots first can become the DR just because it did not receive any hellos when the OSPF process was started – even though it may have a low OSPF priority.
The default OSPF priority is 1 and Cisco recommends manually changing that on routers you want to become the DR and BDR.
Remember that DRs are only used on multiaccess links, so they are only significant on an interface level. A router with two different interfaces connected to two different multiaccess links will have separate DR elections for each segment. To set the OPSF priority, use the ip ospf priority command on the interface connected to the multiaccess segment. Values can be between 0-255.
R1(config)# int gig 0/1 R1(config-if)# ip ospf priority 255

OSPF over the WAN
Routing protocols assume both broadcast capabilities and full mesh connectivity on multiaccess networks. For OSPF, there are a few points to consider:
Full mesh environments can use physical interfaces, but often times subinterfaces are used
Partial mesh environments should be configured using point-to-point subinterfaces Hub-and-spoke environments should elect the hub as the DR or use point-to-point
subinterfaces – which don’t require a DR Frame Relay and ATM maps should include the broadcast attribute In multiaccess environments, the DR and BDR should have full virtual circuit
connectivity to all other routers
Summarization
First, it’s important to note that running the SPF algorithm on a router is extremely taxing on CPU resources and can easily consume them all. The reason is because OSPF has to compute the best path to every destination within its area. Avoiding running the algorithm whenever it isn’t required is a big win.
Summarization has two important benefits for OSPF. It prevents topology changes from being passed outside an area – thus reducing the number of routers re-running the SPF algorithm. It also consolidates many routes in to a single statement, reducing the memory load and database size on OSPF-enabled routers. There are two types of route summarization, inter-area and external.
Inter-area Summarization (LSA Type 3)
This occurs on ABRs to summarize routes between areas. This really only works well if the networks contained within an area are subnetted contiguously so that they can be easily summarized into a single statement. The new summary route’s cost will be equal to the lowest cost route within the summary range. After the command is entered, the router will automatically create a static route pointing to Null0.
Inter-area Summarization Example:
ABR-R1(config)# router ospf 10 ABR-R1(config-router)# area 2 range 10.100.0.0 255.255.0.0 In this example, the summary network 10.100.0.0/16 is summarized from area 2.
External Summarization (LSA Type 5)
This occurs on ASBRs for routes that are injected into OSPF via route redistribution. After the command is entered, the router will automatically create a static route pointing to Null0.
External Summarization Example:

ASBR-R1(config)# router ospf 10 ASBR-R1(config-router)# summary-address 192.168.0.0 255.255.0.0
In this example, an external network has been summarized into 192.168.0.0/16 and is injected into OSPF via a single type 5 LSA.
OSPF Passive Interfaces
Like EIGRP, OSPF supports the use of passive interfaces. The passive-interface interface command disables OSPF hellos from being sent out, thus disabling the interface from forming adjacencies out that interface.
OSPF Default Routes
Default routes are injected into OSPF via type 5 LSAs. There are multiple ways to inject default routes into OSPF, but Cisco recommends using the default-information originate command under the OSPF routing process.
R1(config)# router ospf 10 R1(config-router)# default-information originate [always] [metric metric]
If the always keyword is not used, OSPF will advertise a default route learned from another source, like a static route. If the always keyword is present, a default route will be advertised regardless if the route exists in the routing table.
Another option is to use the area range and summary-address commands discussed in the summarization section above. Using these will result in the router advertising a default route pointing to itself.
Stub and Not-So-Stubby Areas

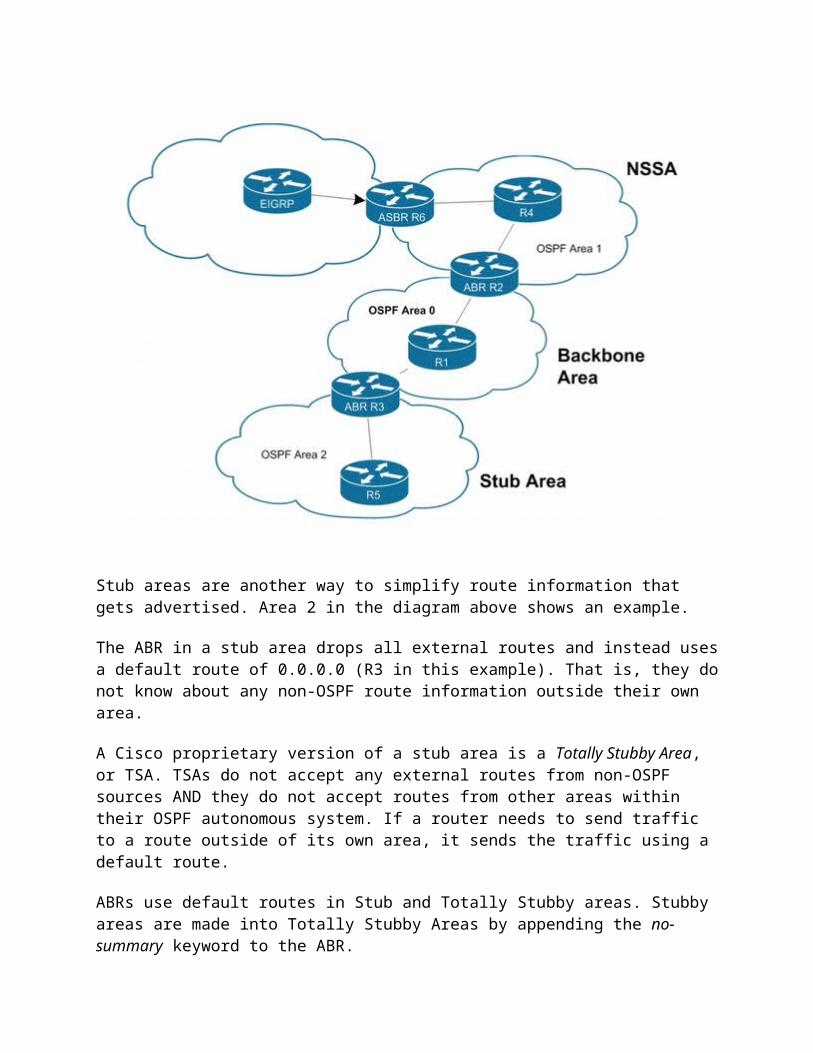
Stub areas are another way to simplify route information that gets advertised. Area 2 in the diagram above shows an example.
The ABR in a stub area drops all external routes and instead uses a default route of 0.0.0.0 (R3 in this example). That is, they do not know about any non-OSPF route information outside their own area.
A Cisco proprietary version of a stub area is a Totally Stubby Area, or TSA. TSAs do not accept any external routes from non-OSPF sources AND they do not accept routes from other areas within their OSPF autonomous system. If a router needs to send traffic to a route outside of its own area, it sends the traffic using a default route.
ABRs use default routes in Stub and Totally Stubby areas. Stubby areas are made into Totally Stubby Areas by appending the no-summary keyword to the ABR.
Configuration Example:
R3(config)# router ospf 10 R3(config-router)# area 2 stub no-summary R3(config-router)# area 2 stub default-cost 8

The example above sets area 2 as a totally stubby area. The default-cost command is optional and in this case changed the default route cost from 1 to 8.
OSPF Stub Limitations
Virtual links cannot be included Cannot include an ASBR The stub configuration must be applied to every router within the stubby area Area 0 cannot be a stub
Bullet point 3 is extremely important. If two routers are connected, but one does not have the stub statement configured, the hello packets will be dropped and they will not form a neighbor adjacency.
Not-So-Stubby Areas, or NSSAs were an addendum to the original OSPF RFC and defined a new special LSA, type 7. NSSAs are very similar to stubby areas, but they allow the use of ASBRs in the area – something stub areas prohibit.
External routes are advertised by the ASBR as type 7 LSAs and the ABR then converts them into type 5 external LSAs when it advertises them to adjacent areas.
NSSA is configured using the area area-number nssa command as can been seen in the example below. Using the no-summary keyword turns the area into a Totally Stubby NSSA. A Totally Stubby NSSA does not accept external or summary routes from other areas.
Lastly, the NSSA ABR does not by default advertise a default route back into the area. The default-information-originate option does just that.
R4(config)# router ospf 10 R4(config-router)#area 1 nssa [no-summary] [default-information-originate]
OSPF Virtual Links
OSPF has strict rules around how areas connect and where they can be located. More specifically, every area must be physically connected to area 0 and area zero must be ‘contiguous’ – meaning it cannot broken into multiple, connected area 0s.
Virtual links were developed as a band-aid to situations that temporarily must violate those requirements. Virtual links connect areas that do not connect directly to area 0. It can also connect two area 0s together!
Keep in mind that Cisco recommends virtual links be a temporary workaround to a short-term problem, not a permanent design.
The diagram below illustrates an example when a virtual link could be used. Let’s pretend Company ABC and Company XYZ just announced a merger and now their corporate networks must do the same. In this case, both routers R1 and R2 have now become ABRs and the virtual

link configuration will be applied to them. The command area area-number virtual-link router-id is applied to each ABR.
Note that the area used in the command is the transit area that the virtual link resides in. Also, the RID identifies the RID of the OTHER router at the end of the link!
R1(config)# router ospf 20 R1(config-router)# area 1 virtual-link 10.30.30.30 R1(config-router)# exit R2(config)# router ospf 20 R2(config-router)# area 1 virtual-link 10.50.50.50
OSPF Authentication
Out of the box, OSPF does not authenticate its protocol’s messages or route updates. OSPF does, however, support two message authentication options:
Simple Authentication (using plaintext keys) MD5 Authentication
Matching authentication methods and keys must configured on each interface on a segment. Theoretically, different passwords could be applied to different router interfaces – the routers on the other ends of those links would just be required to have matching information.
Simple Authentication Example
R1(config)# int fa0/1 R1(config-if)# ip ospf authentication-key KEY123 R1(config-if)# ip ospf authentication R1(config-if)# exit R1(config)# router ospf 10 R1(config-router)# area 0 authentication
MD5 Authentication Example
R1(config)# int fa0/1 R1(config-if)# ip ospf message-digest-key 1 md5 KEY123 R1(config-if)# ip ospf authentication message-digest R1(config-if)# exit R1(config)# router ospf 10 R1(config-router)# area 0 authentication message-digest
NOTE: The 1 in the ip ospf message-digest-key 1 md5 KEY123 statement above is a key number.
OSPF Verification

The OSPF neighbor table can be viewed using the show ip ospf neighbor command. It shows the status of the OSPF database loading process, status of neighbor adjacencies, as well as DR and BDR assignments.
To show which OSPF routers are being used by the routing table, issue the show ip route ospf command
The show ip ospf command displays the RID, counters, and timers To see which router interfaces are participating in OSPF (and their area assignments), use
the show ip ospf interface command

Redistribution is necessary when routing protocols connect and must pass routes between the two. This can happen in a number of situations, but some examples include:
Organizations transitioning routing protocols Businesses merge, and so must their networks OSPF or EIGRP is used at the access and distribution layer of an enterprise and BGP is
used in the core
The challenge to redistributing routing protocols is that each routing protocol uses it own metric and they are not compatible with each other. Furthermore, there is no magic algorithm than can automatically translate metrics between, say RP and BGP.
To deal with this dilemma, a new seed metric is used as a staring point when redistribution is configured.
Configuring Redistribution
To configure redistribution between routing protocols, the redistribute protocol command is used under the routing protocol that recieves the routes.
R1(config-router)# redistribute protocol [AS/process-ID] [metric metric-vlaue]
Both RIP and EIGRP require the use the metric keyword.
EIGRP Redistribution Example
R1(config)# router eigrp 10 R1(config-router)# redistribute ospf 20 metric 1000 100 255 1 1500
The example above shows OSPF being redistruted into EIGRP with a metric of 1000 100 255 1 1500. That is a lot of different numbers for an EIGRP cost! That’s because EIGRP redistribution metric requires you to input all of the metric calculation manually:
bandwidth delay reliability loading mtu
You can perform a show interface on the outgoing router interface prior to implementing the redistribution to see what values the router is currently using.
OSPF Redistribution Example:
R1(config)# router ospf 100 R1(config-router)# redistribute eigrp 10 subnets

The example above redistributes EIGRP routes into OSPF. The subnets keyword at the end of the redistribute command is extremely important! Without this keyword, OSPF will redistribute networks at their classful boundaries – not something most administrators want.
If you don’t use it the IOS will even give you a warning. Make sure to include it.
Distribute Lists
Distribute lists are access lists applied to the routing process, determining which networks are allowed into the routing table or included in updates. They essentially act as a filter.
An access list applied to routing = distribute lists
When creating a distribute list, use the following steps:
Step 1. Identify the network addresses to be filtered and create an ACL – permitting the networks you want to be advertised.
Step 2. Determine if you want to filter updates coming into the router or leaving the router.
Step 3. Assign the ACL using the distribute-list command.
Incoming Distribute Lists:
R1(config-router)# distribute-list {acl-number | name} in [interface-type number]
Outgoing Distribute Lists:
R1(config-router)# distribute-list {acl-number | name} out [interface-name | routing-process | AS-number]
Route Maps

When a routing update arrives at an interface, a series of steps occur to process it correctly. The diagram below outlines those steps and serves as a foundation for the rest of this route redistribution and filtering section.
Route maps are extremely flexible and are used in a number routing scenarios including:
Controlling redistribution based on permit/deny statements Defining policies in policy-based routing (PBR) Add more mature decision making to NAT decisions than simply using static
translations When implementing BGP PBR
Route maps allow an administrator to define specific traffic and then take automated actions against it to control how routing information is processed and forwarded. Route maps uses logic similar to if/then statements in simple scripting.
In route map terms, it matches traffic against conditions and sets options for that traffic.

Each statement in a route map has a sequence number, which is read from lowest to highest. The router stops reading statements when it reaches its first matching statement.
Understand that there is an implicit deny included in all route maps. If traffic does not match any statement, it is denied.
Basic Route Map Configuration
R1(config)# route-map {tag} permit | deny [sequence_number]
That is how all route maps begin. Permit means that any traffic matching the match statement that follows is processed by the route map. Deny means that any traffic matching the match statement that follows is NOT processed by the route map. Know the difference.
Match & Set Conditions
If no match condition exists, the statement matches anything (similar to a ‘permit any’).
If no set condition exists, the statement is simply permitted or denied with no additional changes made.
If multiple match conditions are used on the same line, it is interpreted as a logical OR. In other words, if one condition is true, a match is made. For example, the router would interpret ‘match a b c’ as ‘a or b or c’.
If multiple match conditions are used on consecutive lines, it is interpreted as a logical AND. In other words, all conditions must be true before a match is made. For example, the router would interpret the following commands as match a and b and c:
route-map EXAMPLE permit 5 match a match b match c
Important route redistribution match conditions
ip address Refers to an access list that permits or denies networks
ip address prefix-list Refers to a prefix list that permits or denies prefixes
ip next-hop Refers to an access list that permits or denies ip next hops IP addresses
ip route-sourceRefers to an access list that permits or denies advertising router IP addresses
length Permits or denies packets based on length (in bytes)
metric Permits or denies routes with specific metrics from being redistributed
route-typePermits or denies redistribution based on the route type listed
tagRoutes can be labeled with a number that identifies it
Important Route Redistribution Set Conditions
metricSets the metric for redistributed routes
tag Tags a route with a numbered identifier
Route Map Verification
Use the show route-map command to verify route maps and PBR entries are filtering as expected.

BGP, or Border Gateway Protocol is an external, dynamic routing protocol. It is most often used between ISPs and between enterprises and their service providers. BGP is literally the routing protocol of the Internet because it connects independent networks together, enabling end-to-end transport. Scalability and stability are BGP’s focus, not speed – as a result it behaves very differently than most other routing protocols.
BGP is recommended whenever multihoming is a requirement (dual ISP connections to different carriers), when route path manipulation is needed, and in transit Autonomous Systems.
A Quick Overview
Routers running BGP are called BGP speakers. BGP uses autonomous system numbers to keep track of different administrative domains.
1-64511 are public, 64512-65535 are private. BGP is used to connect IGPs, interior gateway protocols like OSPF and EIGRP. Routing
between Autonomous Systems is referred to as interdomain routing. The administrative distance for eBGP routes is 20, iBGP is 200. BGP neighbors are called “peers” and must be statically assigned. Peers receive incremental, triggered updates as well as keepalives using TCP port 179. BGP is sometimes referred to as a “path-vector” protocol because its route to a network
uses AS numbers on the path to the destination. BGP uses it’s path-vector attributes to help in loop prevention. When an update leaves an
AS, the AS number is prepended to the update along with all the other AS numbers that have spread the update.
When a BGP router receives an update, it first scans through the list of AS numbers. If it sees it own AS number, the update is discarded.
BGP Databases
Like most modern routing protocols, BGP has two separate databases – a neighbor database and a BGP-specific database.
Neighbor Database Lists all of the configured BGP neighbors
Router# show ip bgp summary
BGP Database Lists all networks known by BGP along with their attributes.
Router# show ip bgp
BGP Message Types

There are four different BGP message types.
Open After a BGP neighbor is configured, the router sends an open message to establish peering with the neighbor.
Update The type of message used to transfer routing information between peers.
Keepalive BGP peers send keepalive messages every 60 seconds by default to maintain active neighbor status.
Notification If a problem occurs and a BGP peer connection must be dropped, a notification message is sent and the session is closed.
Internal vs. External
iBGP, or internal BGP is a peering relationship between BGP routers within the same autonomous system. eBGP, or external BGP describes a peering relationship between BGP routers in different autonomous systems. It is an important distinction to make.
In the diagram below, R1 and R2 are eBGP peers. R2 and R3 and iBGP peers.
BGP Next-Hop Self

When you have BGP neighbors peering between autonomous systems like R1 and R2 above, BGP uses the the IP address of the router the update was received from as its “next hop”. When a router receives an update from an eBGP neighbor, it must pass the update to its iBGP neighbors with-out modifying the next hop attribute.
The next-hop IP address is the IP address of the edge router belonging to the next-hop autonomous system.
For example, let’s say R1 sends an update to R2 from its 10.1.1.1 serial interface. R2 must keep the next-hop IP set as 10.1.1.1 when it passes the update along to R3, its iBGP peer. The problem is that R3 does not know about 10.1.1.1 and so it cannot use it as its next hop address.
The neighbor [IP address] next-hop-self command solves the problem by advertising itself as the next-hop address. In this example, it would be applied to R2 so any updates passed along to R3 would use an R2 address as the next-hop.
R2(config)# router bgp 65300 R2(config-router)# neighbor 10.2.2.2 next-hop-self R2(config)# exit
BGPs Synchronization Rule
The BGP synchronization rule states that a BGP router cannot use or forward new route updates it learns from iBGP peers unless it knows about the network from another source, like an IGP or static route.
The idea is to prevent using or forwarding on information that is unreliable and cannot be verified. Remember, BGP prefers reliability and stability over using the newest, fastest route.
This means that iBGP peers will not update each other unless an IGP is running under the hood. To remove the limitation, use the no synchronization command under BGP configuration mode. recent versions of IOS have it disabled by default, but it is important topic to understand.
Resetting BGP Sessions
Internet routers running BGP have enormous routing tables. When a filter is applied, like a route map, changes to BGP attributes occur. Those changes could affect many of the routes already in the routing table from BGP. Because BGP’s network list is usually very long, applying a route map or prefix list after BGP has converged can be disastrous. The router would have to check the filter against every possible route and attribute combination.
To make matters worse, if it were to apply the filters and pull routes back from neighbors, those changes could then cause another reconvergence – and on and on. In an effort to avoid that scenario (BGP loves stability), BGP will only apply attribute and network changes to routes AFTER the filter has been applied. All existing routes stay unchanged.

If the network administrator decides that the filter needs to be applied to all routes, then the BGP instance must be reset – forcing the entire BGP table to pass through the filter. There are three ways to do this:
Hard reset Soft reset Route refresh
The hard and soft reset options aren’t discussed here because they are not directly relevant to the exam. You should know though, that both options are extremely memory-taxing on the router as all the routes must be recomputed. Route refresh was developed to solve the high memory problems, while still forcing a reset.
The following command performs the BGP route refresh:
Router# clear ip bgp [ * | neighbor-address]
BGP Configuration
Enabling BGP
Like other routing protocols, BGP must be enabled with the router command. Make sure to include the AS number.
R1(config)# router bgp autonomous-system-number
BGP Peering
Each neighbor must be statically assigned using the neighbor command. If the AS number matches the local router’s, it is an iBGP connection. If the AS number is different, it is an eBGP connection.
R1(config-router)# neighbor ip-address remote-as autonomous-system-number
If a router has a long list of directly connected neighbors, the BGP configuration can start to get long and difficult to follow – especially as neighbor policies are applied. Peer groups solve that.
Peer groupsBGP Peer groups are groups of peer neighbors that share a common update policy. Updating an entire group of neighbor statements can then be done with one command. Much easier for large BGP networks. Think of a peer group as a logical grouping of routers that are grouped under a single name to make changes faster and configurations shorter. Like OUs in Active Directory.
Peer groups not only reduce the number of lines of configuration, but they reduce the ease the overhead of the router. A BGP update process normally runs for each neighbor. If a peer group is

configured, a single update process runs for all routers in the group. Notice that this means that all of the router inside a peer group must be either all iBGP or eBGP neighbors.
Basic neighbor configuration example:
R1(config)# router bgp 65300 R1(config-router)# neighbor 10.1.1.1 remote-as 65300 R1(config-router)# neighbor 10.1.2.1 remote-as 65300 R1(config-router)# neighbor 10.1.3.1 remote-as 65300
Peer group configuration example:
R1(config)# router bgp 65300 R1(config-router)# neighbor MINE peer-group R1(config-router)# neighbor MINE remote-as 65300 R1(config-router)# neighbor 10.1.1.1 peer-group MINE R1(config-router)# neighbor 10.1.2.1 peer-group MINE R1(config-router)# neighbor 10.1.3.1 peer-group MINE
BGP Source Address
R1 in the diagram below has two different options when it comes to peering to R2. It can peer to the physical interface IP address, 10.1.1.2 or it can peer to R2′s loopback interface, 192.168.2.2.

If a peer relationship is made using the physical interface as the source address, problems can occur if the interface goes down. In this scenario, even if R2′s 10.1.1.2 interface drops, it still has connectivity to R2′s networks via R3 and R2′s other physical interface. Even though an IGP would still show R2′s network as accessible, the BGP peer relationship would drop because R1 cannot reach its peering address with R2.
Most implementations recommend using a loopback address as the BGP source address for this reason. Remember that the loopback address must be added to the IGP running for this to work. This way, if R2′s 10.1.1.2 interface fails, R2 will still be reachable. The update-source command accomplishes this.
Here’s an example:
R1(config)# router bgp 65400 R1(config-router)# neighbor 192.168.2.2 remote-as 65400 R1(config-router)# neighbor 192.168.2.2 update-source loopback0
R2(config)# router bgp 65400 R2(config-router)# neighbor 192.168.1.1 remote-as 65400 R2(config-router)# neighbor 192.168.1.1 update-source loopback0
Defining Networks
Network statements in BGP are used differently than in other routing protocols like EIGRP or OSPF. EIGRP and OSPF use the network statements to define which interfaces you want to participate in the routing protocol process.
BGP uses network statements to define which networks the local router should advertise. Each network doesn’t have to be originating from the local router, but the network must exist in the routing table. The optional mask keyword is often recommended as BGP supports subnetting and supernetting.
Example:
R1(config)# router bgp 65300 R1(config-router)# neighbor 10.1.1.1 remote-as 65300 R1(config-router)# network 10.1.1.0 255.255.255.0 R1(config-router)# neighbor 10.1.2.1 remote-as 65300 R1(config-router)# network 10.1.2.0 255.255.255.0
Understand that by default a BGP router will not advertise a network learned from one iBGP peer to another. This is why iBGP is not a good replacement for an IGP like EIGRP and OSPF.
BGP Path Selection
Unlike most other routing protocols, BGP is not concerned with using the fastest path to a given destination. Instead, BGP assigns a long list of attributes to each path. Each of these attributes can be administratively tuned for extremely granular control of route selections.
BGP also does not load balance across links by default. To select the best route, BGP uses the criteria in the following order:

1. Highest weight2. Highest local preference3. Choose routes originated locally 4. Path with the shortest AS path 5. Lowest origin code ( i < e < ? ) 6. Lowest MED 7. eBGP route over iBGP route 8. Route with nearest IGP neighbor (lowest IGP metric) 9. Oldest route 10. Neighbor with the lowest router ID 11. Neighbor with the lowest IP address
Controlling Path Selection
The most common method of controlling the attributes listed above is to use route maps. This allows specific attributes to be changed on specific routes. Before we get into route maps, let’s first discuss the three prominent attributes: weight, local preference, and MED.
Weight
On Cisco routers, weight is the most influential BGP attribute. The weight attribute is proprietary to Cisco and is normally used to select an exit interface when multiple paths lead to the same destination. Weight is local and is not sent to other routers. It can be a value between 0-65,535. 0 is the default. In the example below, if you want R2 to prefer to use R1 when sending traffic to 192.168.20.0 then the weight attribute could raised on R2 for R1.

R2(config)# router bgp 65100 R2(config-router)# neighbor 10.1.1.1 remote-as 65100 R2(config-router)# neighbor 10.2.2.1 remote-as 65100 R2(config-router)# neighbor 10.1.1.1 weight 100
Local Preference
Local preference is not proprietary to Cisco and can be used in a similar fashion to weight. It can be set for the entire router or for a specific prefix. Local preferences can range from 0-4,294,967,295, with 100 being the default value. Unlike weight, local preference is propagated to iBGP neighbors.
Using the diagram above, if an administrator wanted R2 to use R1 when sending traffic to 192.168.20.0, the configuration would look something like this:
R1(config)# router bgp 65100 R1(config-router)# bgp default local-preference 500
After the local preference is raised on R1, it will be shared with R2 and R2 will begin using it as its best path to the distant network (assuming the weight is the same of course). If you want to set the local preference on specific prefixes, route maps are usually the best option. Below is an example of the local preference being set using a route map:
R7(config)# router bgp 200 R7(config-router)# neighbor 10.10.10.1 remote-as 100 R7(config-router)# neighbor 10.10.10.1 route-map lp_example in R2(config-router)# exit R7(config)# access-list 7 permit 10.30.30.0 0.0.0.255 R7(config)# route-map lp_example permit 10 R7(config-rmap)# match ip address 7 R7(config-rmap)# set local-preference 300 R7(config-rmap)# exit R7(config)# route-map lp_example permit 20 R7(config-rmap)# set local-preference 100
MED
The MED attribute, or multi-exit discriminator is used to influence which path external neighbors use to enter an AS. MED is also much farther down on the attribute list, so attributes like weight, local preference, AS path length, and origin are used first. The default MED value is 0 and a lower value is preferred. A common scenario for MED is when a company has two connections to the same ISP for internet.
Weight or local preference could be used to send outgoing traffic on the higher bandwidth link, but local preference is not shared with routers outside an AS. MED could be set on one router so ISP routers prefer that path in.
To set the MED on all routes:
R1(config-router)# default-metric value
Here’s an example using a route map to influence incoming paths to 10.30.30.0/24 using MED:
R7(config)# router bgp 200 R7(config-router)# neighbor 10.10.10.1 remote-as 200 R7(config-router)# neighbor 10.10.10.1 route-map med_example out

R2(config-router)# exit R7(config)# access-list 7 permit 10.30.30.0 0.0.0.255 R7(config)# route-map med_example permit 10 R7(config-rmap)# match ip address 7 R7(config-rmap)# set metric 50 R7(config-rmap)# exit R7(config)# route-map med_example permit 20 R7(config-rmap)# set metric 150
BGP Verification
It’s important that you understand and are able to interpret to results of the show ip bgp command output. It displays the contents of the local BGP topology database- including the attributes assigned to each network. It is perhaps the most important BGP verification and troubleshooting tool!
Because BGP uses many attributes and sources routes in a number of ways, the output of the show ip bgp command can be a bit overwhelming if you don’t know what you are looking for.
R1# show ip bgp BGP table version is 21, local router ID is 10.0.22.24 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path *> 10.1.0.0 0.0.0.0 0 32768 ? * 10.2.0.0 10.0.22.25 10 0 25 ? *> 0.0.0.0 0 32768 ? * 10.0.0.0 10.0.22.25 10 0 25 ? *> 0.0.0.0 0 32768 ? *> 192.168.0.0/16 10.0.22.25 10 0 25 ?
Attributes
Here’s a breakdown of some important fields you should consider remembering:
* – An asterisk in the first column means that the route has a valid next hop.
s (suppressed) – BGP is not advertising the network, usually because it is part of a summarized route.
> – Indicates the best route for a particular destination. These will end up in the routing table.
i (internal) – If the third column has an i in it, it means the network was learned from an iBGP neighbor. If it is blank, it means the network was learned from an external source.
0.0.0.0 – The fifth column shows the next hop address for each route. A 0.0.0.0 indicates the local router originated the route (examples include a network command entered locally or a network an IGP redistributed into BGP on the router)
Metric (MED value) – The column titled Metric represents the configured MED values. Recall that 0 is the default and if another value exists, lower is preferred.
i/?- The last column displays information on how BGP originally learned the route. In the example above, ? is used for each route meaning they were all redistributed routes into BGP from an IGP. The other option is a question mark, which indicates that network commands were used to configure the route.

VPN tunnels and IPSec are two topics covered on the exam, but not in great detail. You’ll need to know enough to verify a sample configuration and answer straightforward questions on both technologies. Let’s start with IPSec.
IPSec Basics
IPSec allows the establishment of a secure connection between two hosts. The IPSec protocol sets up a unidirectional SA (security association between the two endpoints). Because the association is unidirectional, an SA is created on both ends, resulting in two SAs per IPSec tunnel.
IPSec tunnels are often used as a backup to a WAN link failure. If a point-to-point WAN circuit drops, an IPSec tunnel can be configured to automatically be established over the internet to the remote site. When the primary WAN circuit comes back up, the IPSec tunnel is disconnected.
Floating Static Routes
Configuring an IPSec tunnel to activate when a primary link drops is commonly implemented as a floating static route. The idea is to configure the IPSec VPN as a static route, but with an administrative distance higher than that of the WAN routing protocol’s.
If the primary route is active, the backup link is not placed into the routing table because it has a higher administrative distance. If the primary route goes down, the static route becomes active.
To configure a floating static route, make sure you define a higher administrative distance value at the end of the statement:
R1(conf)# ip route prefix mask address|interface distance_value
VPN Tunnels
One major problem with standard IPSec sessions is that they do not support broadcast or multicast traffic. If you want to use an IPSec VPN in an “always on” fashion, then the tunnel needs to allow routing information to pass through. Of course dynamic routing protocols use broadcast or multicast to send hellos and updates, which creates a problem.
To get around this issue, a “tunnel within a tunnel” approach can be used. A generic tunnel can be configured within the IPSec tunnel to allow routing protocol information (along with all the other traffic). There are generally four ways to do this paired with IPSec:
DMVPN and GET VPN Both allow the creation of secure, “on-demand”, multipoint tunnels.

Virtual Tunnel Interface (VTI) A secure, “always-on” tunnel that supports multicast traffic. This allows routing protocols to operate within it.
Generic Routing Encapsulation (GRE) GRE tunnels may be the most common of the bunch – they are also the default tunnel mode on Cisco routers. GRE tunnels support many layer 3 protocols but perhaps most importantly allow multicast traffic accross the tunnel – permitting dynamic routing protocol traffic. Be aware that GRE tunnels add an additional 20 byte IP header as well as a 4 byte GRE tunnel header.
Branch Office Connectivity
The CCNP ROUTE exam covers several unusual topics related to managing and configuring the connectivity between an HQ site and a branch office. You need to be familiar with some of the underlying technologies used. Cisco ISR routers are often a good choice for branch sites as they support a wide variety of incoming services. In smaller offices, a single ISR may be used for a both remote connectivity and inter-VLAN routing. In that case, know that an Ethernet Switch Module would be required for the ISR router.
DSL
DSL, or Digital Subscriber Line, can be used as a backup WAN connection to a branch office. DSL uses frequencies not used by TDM phone systems on a phone line – allowing the extra bandwidth to be used for data connectivity. Asymmetrical DSL has higher downstream bandwidth than upstream, while with symmetric DSL they are both the same rate.
There are two primary methods for pushing L2 data across a DSL line:
PPPoEPoint-to-Point Protocol over Ethernet is the most common method and encapsulates PPP traffic into Ethernet frames.
PPoAPoint-to-Point Protocol over ATM is less common and routes PPP traffic over an ATM network between the customer and the DSL service provider. Both options can be configured on a Cisco router to terminate the DSL connectivity. PPPoE is especially helpful because it frees the local office’s computers from running PPPoE
Cable
Broadband cable providers also provide internet connectivity which can be used for WAN backup or provide internet connectivity for telecommuters. The internet signal is carried on the same line that the television is carried, but a cable modem allows the data traffic to be separated.
The international standard for sending data over a cable system is Data Over Cable Service Interface Specification (or DOCSIS). Many different versions of the standard are used

throughout the world. Cable system connections are typically not terminated directly into a Cisco router. Instead, a cable modem demodulates the incoming signal and converts the traffic to Ethernet frames, which a router can process.
IPv6 is an important topic – and not just for the exam. The growth of web-based services and diminishing IPv4 addressing will continue to push organizations towards IPv6, especially on web-facing networks.
IPv6 Basics
IPv4 addresses are 32 bits long and are represented in dotted-decimal format. IPv6 addresses are 128 bits and are in hexadecimal format.
The first 64 bits of an IPv6 address are reserved for the network portion and the last 64 bits are used for the host portion.
IPv6 Shorthand
The ability to shorten IPv6 addresses is very important to understand because it makes reading and writing them much easier.
There are two ways to condense an IPv6 address:

1. Leading zeros can be removed in any section.For example, 0021:0001:0000:030A:0000:0000:0000:0987E can be abbreviated as: 21:1:0:30A:0:0:0:987E
2. Sequential sections of all zeros can be shortened to a single double colon.This can only be used once per address. Using the same example address above, it can be further shortened to:
21:1:0:30A::987E
Unicast, Multicast, & Anycast
UnicastUnicast is for sending traffic to a single interface. In IPv6 there are actually two different unicast types, global unicast and link-local unicast.
Multicast Unlike IPv4, IPv6 addressing does not support broadcasts. Instead, it has replaced it with multicast (which is a more efficient variation). This is used for sending traffic to a group of devices.
Anycast IPv6 supports another new packet type – anycast. Anycast allows the same address to be used on multiple devices for load balancing and redundancy. Technically, it is used for sending traffic to the nearest interface in a group. While multiple devices may be running the same anycast address, only one will be used per packet sent.
Be aware that with IPv6, an interface can be assigned multiple addresses. Here is the list:
Unicast address Link-local address loopback (::1/128) All nodes multicast (FF00::1) Site-local multicast (FF02::2) Solicited-nodes multicast Default Route (::/0)
IPv6 Address Assignment
There are three different ways devices are assigned an IPv6 address: manual configuration, stateless autoconfiguration, or DHCPv6.
Manual Address Configuration

The first thing to know about manual IPv6 address configuration is that addresses assigned to a router interface use the address/prefix-length notation instead of the address mask notation. This is so much easier than typing 255.255… after every IP address!
Also, make sure you first enable IPv6 routing with the ipv6 unicast-routing global configuration command. Use the ipv6 address ipv6-address/prefix-length command to assign an address.
An example of an interface configured with an IPv6 address:
R1# conf t R1(config)# ipv6 unicast-routing R1(config)# int gig 1/1 R1(config-if)# ipv6 address 21:1:0:30A::987E/64
Manual Network Assignment
Another way to manually configure an IPv6 address is to configure the network and allow the host portion to be auto-populated based on the device’s MAC address. This can work well because MAC addresses are 64 bits long – the exact same length as the host portion of an IPv6 address!
An example configuration with the network portion defined:
R1(config)# int gig 1/1 R1(config-if)# ipv6 address 21:1:0:30A::/64
Note: Some systems have a 48 bit MAC address. In this case, it flips the 7th bit and inserts 0xFFFE into the middle of the MAC address. This modified version is called an EUI-64 address. To do this, add the keyword eui-64 to the end of the ipv6 address statement.
Stateless Autoconfiguration
Stateless autoconfiguration allows a device to self-assign an IP address for use locally without any outside information. Remember that interfaces using IPv6 will often have more than one IPv6 address assigned, and in this case stateless autoconfiguraiton will generate a link-local address in addition to any other manually assigned addresses. Link-local addresses are created using the prefix FE80:: and appending the device’s MAC address. Since every MAC address should be unique, it works well for auto-generated local IP addresses.
Link-local addresses are not routable within packets and are used for administrative purposes within the local segment. For example, most IGPs use link-local addresses for neighbor relationships and the link-local address is listed as the next-hop address in the routing table.
Once a router has created an IPv6 link-local address using stateless autoconfiguration, it uses NDP to make sure it is actually unique within the local network. NDP stands for Neighbor Discovery Protocol and uses ICMP packets as part of the neighbor discovery process.
To configure stateless autoconfiguration, use the ipv6 address autoconfig command.
R1(config)# int gig 1/1 R1(config-if)# ipv6 address autoconfig

IPv6 Routing
Static Routes
The configuration for IPv6 static routes is identical to IPv4, except for the ipv6 route keywords instead of ip route. Other than that, it is exactly the same.
An example of a static IPv6 default route:
R1(config)# ipv6 route ::/0 serial1/1
An example of an IPv6 static route with a next-hop address:
R1(config)# ipv6 route 2003:2:1:A::/64 2003:2:1:F::1
To view the IPv6 routes in the routing table, use the command show ipv6 route.
IPv6 EIGRP
There are many differences in the way EIGRP is configured for IPv6.
It still sends hellos out every 5 seconds to its neighbors, but when running EIGRP with IPv6 addresses it uses the multicast address FF02::A.
EIGRP messages are exchanged using the link-local address as the source address. Perhaps the biggest difference is that there is no network command. Instead, EIGRP routing is enabled on each participating interface.
Also, EIGRP running IPv6 requires a router ID be configured. The format is that of an IPv4 address – 32 digits and it can be a private address (non-routable) with no issues.
The last major change is that the EIGRP process starts in the shutdown state. You have to issue a no shut to bring it up on the router.
To configure IPv6 EIGRP:
R1(config)# ipv6 unicast-routing ! R1(config)# ipv6 router eigrp AS R1(config-rtr)# router-id ipv4-address R1(config-rtr)# no shut R1(config-rtr)# exit ! R1(config)# interface type number R1(config-if)# ipv6 eigrp AS
OSPFv3
OSPFv3 is an updated version of OSPF designed to accommodate IPv6 natively. Most of the configuration and function is identical to its predecessor, but a few changes were made starting with messaging.
OSPFv3 uses the multicast address FF02::5 and FF02::6, but like EIGRP it now uses its link-local address as the source address in advertisements.
It is possible to run multiple instances of OSPFv3 on each link.

Like the IPv6 implementation of EIGRP, a 32 bit router ID must be manually created. It will not automatically create one based on highest loopback or interface address. The RID that is assigned will then be used to determine the DR and BDR on a segment (highest wins).
OSPFv3 has dropped it’s native authentication options. Instead, it relies on the underlying authentications built into IPv6, like IPSec.
The configuration is now done on each individual interface. The following is an example configuration:
R2(config)# ipv6 unicast-routing ! R2(config)# ipv6 router ospf 100 R2(config-rtr)# router-id 10.10.10.1 R2(config-rtr)# area 1 stub no-summary R2(config-rtr)# exit ! R2(config)# interface gig1/1 R2(config-if)# ipv6 address 2003:2:1:2::1/64 R2(config-if)# ipv6 ospf 100 area 0 ! R2(config)# interface gig1/2 R2(config-if)# ipv6 address 2003:2:1:A::1/64 R2(config-if)# ipv6 ospf 100 area 1 R2(config-if)# ipv6 ospf priority 30
MP-BGP
MP-BGP, or multiple protocol BGP, was outlined in RFC 2858 and includes extensions to the original BGP standard that allows support for other protocols – one of which is IPv6! The command address-family was added to specify which new protocol functionality is being configured and is used when applying IPv6 addressing.
Like EIGRP and OSPFv3, an IPv4 address must be configured as a router ID. The BGP configuration is not done at the interface level, it still is done in router configuration mode. The major difference is that neighbors must be first defined under router BGP configuration mode and then “activated” under IPv6 address-family mode submode. Networks and other parameters are also configured under IPv6 address-family mode submode.
R3(config)# ipv6 unicast-routing ! R3(config)# router bgp 600 R3(config-rtr)# router-id 10.10.10.10 R3(config-rtr)# neighbor 2003:76:1:1::10 remote-as 700 R3(config-rtr)# address-family ipv6 unicast R3(config-rtr-af)# neighbor 2003:76:1:1::10 activate R3(config-rtr-af)# network 2003:2:2::/48 R3(config-rtr-af)# exit R3(config-rtr)# exit
Migrating to IPv6
Three options exist for transitioning from IPv4 to IPv6: dual stack, tunneling, or NAT.
Dual Stack This involves running IPv4 alongside IPv6 on the same system.
Tunneling This option allows you to encapsulate IPv6 traffic within an IPv4 header.
NAT A new network translation extension, NAT-PT allows IPv6-to4 translation.
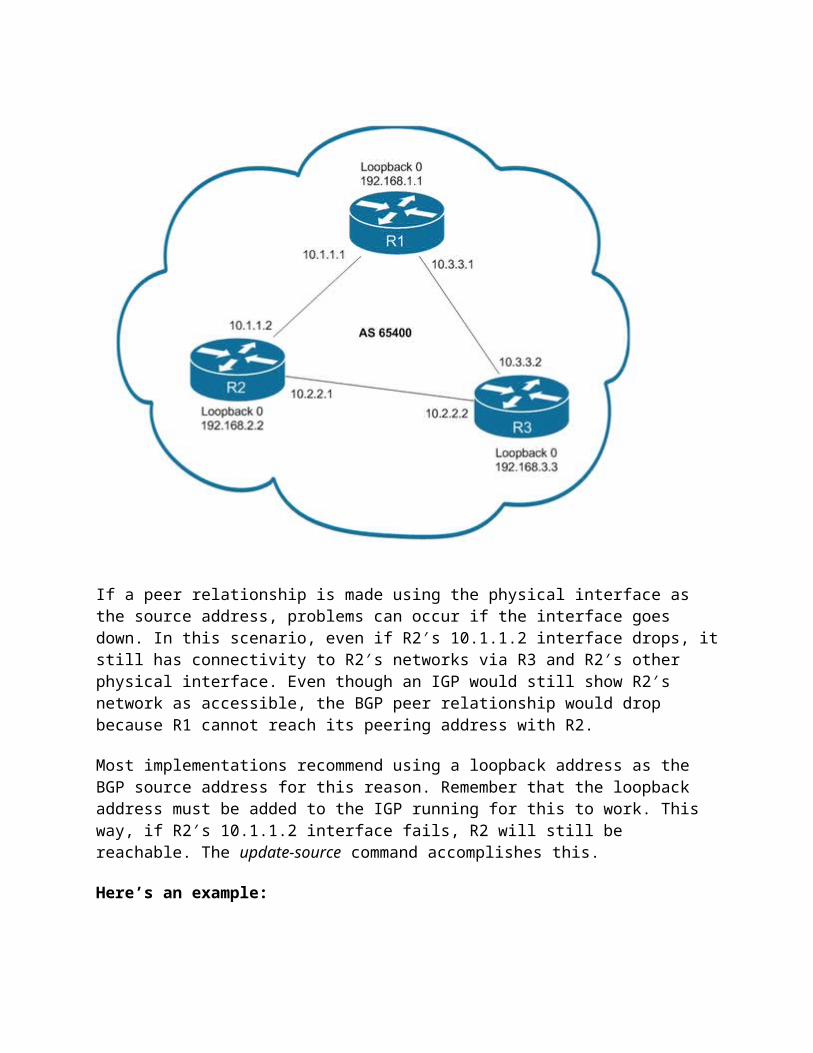
Dual Stack
Using a dual-stack transition allows servers, clients, and applications to be slowly moved to IPv6. Both protocols can run concurrently and neither communicating with the other. If both IPv4 and IPv6 are running on a server for example, IPv6 will be used.
Dual Stack configuration example:
R1# config t R1(config)# ipv6 unicast-routing R1(config)# ipv6 cef ! R1(config)# interface serial1/0/1 R1(config-if)# ip address 192.168.1.1 R1(config-if)# ipv6 address 2001:1:3:1::1/64
IPv6 Tunneling
Dual-stacking IPv4 alongside IPv6 on systems works well, but it requires most of your infrastructure to support IPv6. In many cases, the network core does not support IPv6 or it has not been implemented. IPv6 tunnels solve this problem by allowing IPv6 islands to exist and bridges them over IPv4 systems.
Because IPv6 tunnels provide virtual IPv6 connectivity through an IPv4 transport, it does not matter what specific IPv4 transport is used. The only requirement is that there is end-to-end IPv4 connectivity between both ends.
Manual Tunnels
The tunnels discussed here are from one router to another. The source router (RouterA) encapsulates the IPv6 traffic in IPv4 headers, then forwards it to the other end of the tunnel (Router B). Router B then decapsulates the packets and forwards them on to their destination using native IPv6.
Manual IPv6 tunnels are easy to configure using the tunnel mode ipv6ip command. Using the Router A/B example above, the configuration on Router A would look something like this:
RouterA(config)# interface tunnel0 RouterA(config-if)# ipv6 address 2001:2:0:7::/64 RouterA(config-if)# tunnel source 10.1.1.1 RouterA(config-if)# tunnel destination 10.3.3.1 RouterA(config-if)# tunnel mode ipv6ip RouterA(config-if)# exit
GRE Tunnels
First, GRE tunnels are the default tunnel method on Cisco routers. GRE tunnels are very flexible and work over most protocols.
The configuration is exactly the same as the manual configuration example above, but you do not have to specify the tunnel mode. Also, routing protocols can be enabled on GRE tunnel interfaces just as if they were physical interfaces.

6to4 Tunnels
6to4 tunnels are similar to the manual tunnel, but set up the tunnel dynamically.
6to4 tunnels use 2002::/16 IPv6 addresses in front of the 32 bit IPv4 address of the edge router – creating a 48 bit prefix. Each router on both sides of the tunnel needs a route to its peer. They only support static and BGP routes, so be careful.
Configure the tunnel as if it was a manual tunnel, using the IPv4 address as the source, but don’t enter a destination.The tunnel requires an IPv6 address using the method just described. Finally, use the command tunnel mode ipv6ip 6to4.
NAT
Translation is a unique solution because it allows IPv4 devices to communicate with IPv6 devices without the dual stack requirement. NAT-PT allows bidirectional translation services.
1. To enable NAT-PT IPv4 to IPv6 translation on a router, the first step is to use the ipv6 nat command on each interface participating in the translation.
2. The second step is to define at least one NAT-PT prefix. Only traffic matching the prefix will be translated. To apply it globally on the router, enter ipv6 nat prefix/prefix_length in global configuration mode. To apply it to traffic on a specific interface, enter ipv6 nat prefix/prefix_length in interface configuration submode.
3. Define the address mappings (either static or dynamic) using the options discussed below.
Static NAT-PT
For an IPv6 to IPv4 static mapping:
R1(config)# ipv6 nat v6v4 source ipv6_address ipv4_address
For an IPv4 to IPv6 static mapping:
R1(config)# ipv6 nat v4v6 source ipv4_address ipv6_address
Dynamic NAT-PT
There are many ways to implement dynamic NAT using IPv6, but at its most basic level a pool of addresses is created and the router temporarily assigns them to hosts as they need them.
For an IPv4 to IPv6 static mapping:
R1(config)# ipv6 nat v4v6 pool name beginning_ipv6 ending_ipv6 prefix-length prefix-length R1(config)# ipv6 nat v4v6 source list (access-list_number | name) pool name

For an IPv6 to IPv4 static mapping:
R1(config)# ipv6 nat v6v4 pool name beginning_ipv4 ending_ipv4 prefix-length prefix-length R1(config)# ipv6 nat v6v4 source list (access-list_number | name) pool name