c6614/6612 memory system
DESCRIPTION
C6614/6612 Memory System. MPBU Application Team . Agenda. Overview of the 6614/6612 TeraNet Memory System – DSP CorePac Point of View Overview of Memory Map MSMC and External Memory Memory System – ARM Point of View Overview of Memory Map ARM Subsystem Access to Memory - PowerPoint PPT PresentationTRANSCRIPT

Multicore Training
C6614/6612 Memory System
MPBU Application Team

Multicore Training
Agenda
1. Overview of the 6614/6612 TeraNet 2. Memory System – DSP CorePac Point of View
1. Overview of Memory Map2. MSMC and External Memory
3. Memory System – ARM Point of View1. Overview of Memory Map2. ARM Subsystem Access to Memory
4. ARM-DSP CorePac Communication1. SysLib and its libraries2. MSGCOM 3. Pktlib4. Resource Manager

Multicore Training
Agenda
1. Overview of the 6614/6612 TeraNet 2. Memory System – DSP CorePac Point of View
1. Overview of Memory Map2. MSMC and External Memory
3. Memory System – ARM Point of View1. Overview of Memory Map2. ARM Subsystem Access to Memory
4. ARM-DSP CorePac Communication1. SysLib and its libraries2. MSGCOM 3. Pktlib4. Resource Manager

Multicore Training
Cores @ 1.0 GHz / 1.2 GHz
C66x™CorePac
TCI6614
MSMC
2MBMSM
SRAM
64-Bit DDR3 EMIF
BCP
x2
x2
Coprocessors
VCP2x4
PowerManagement
Debug & Trace
Boot ROM
Semaphore
MemorySubsystem
SRI O
x4
PCIe
x2
UART
x2
AIF 2
x6
SPI
IC2
PacketDMA
Multicore Navigator
QueueManager
EMIF
16
x3 32KB L1P-Cache
32KB L1D-Cache
1024KB L2 Cache
RSA RSAx2
PLL
EDMAx3
HyperLink TeraNet
Network CoprocessorS w
itch
Ethe
rnet
Switc
hSG
MII
x2Packet
Accelerator
SecurityAccelerator
FFTC
TCP3d
TAC
x2RAC
ARMCortex-A832KB L1P-Cache
32KB L1D-Cache
256KB L2 Cache
USIM
TCI6614 Functional Architecture

Multicore Training
QMSS
C6614 TeraNet Data Connections
MSMCDDR3
Shared L2 S
S
CoreS
PCIe
S
TAC_BES
SRIO
PCIe
QM_SS
M
M
M
TPCC16ch QDMA
MTC0MTC1
M
MDDR3
XMC
M
DebugSS M
TPCC64ch
QDMA
MTC2MTC3MTC4MTC5
TPCC64ch
QDMA
MTC6MTC7MTC8MTC9
Network Coprocessor
M
HyperLink M
HyperLinkS
AIF / PktDMA M
FFTC / PktDMA M
RAC_BE0,1 M
TAC_FE M
SRIOS
S
RAC_FES
TCP3dS
TCP3e_W/RS
VCP2 (x4)S
M
EDMA_0
EDMA_1,2
CoreS MCoreS ML2 0-3S M
CPUCLK/2
256bit TeraNet 2A
FFTC / PktDMA M
TCP3dS
RAC_FES
VCP2 (x4)S VCP2 (x4)S VCP2 (x4)S
RAC_BE0,1 M
CPUCLK/3
128bit TeraNet 3A
S S S S
CPUCLK/2256bit TeraNet
2B
MPU
DDR3
ARM
ToTeraNet
2B
From ARM

Multicore Training
Agenda
1. Overview of the 6614/6612 TeraNet 2. Memory System – DSP CorePac Point of View
1. Overview of Memory Map2. MSMC and External Memory
3. Memory System – ARM Point of View1. Overview of Memory Map2. ARM Subsystem Access to Memory
4. ARM-DSP CorePac Communication1. SysLib and its libraries2. MSGCOM 3. Pktlib4. Resource Manager

Multicore Training
SoC Memory Map 1/2Start Address End Address Size Description
0080 0000 0087 FFFF 512K L2 SRAM
00E0 0000 00E0 7FFF 32K L1P
00F0 0000 00F0 7FFF 32K L1D
0220 0000 0220 007F 128K Timer 0
0264 0000 0264 07FF 2K Semaphores
0270 0000 0270 7FFF 32K EDMA CC
027D 0000 027d 3FFF 16K TETB Core 0
0c00 0000 0C3F FFFF 4M Shared L2
1080 0000 1087 FFFF 512K L2 Core 0 Global
12E0 0000 12E0 7FFF 32K Core 2 L1P Global

Multicore Training
SoC Memory Map 2/2 Start Address End Address Size Description
2000 0000 200F FFFF 1M System Trace Mgmt Configuration
2180 0000 33FF FFFF 296M+32K Reserved
3400 0000 341F FFFF 2M QMSS Data
3420 0000 3FFF FFFF 190M Reserved
4000 0000 4FFF FFFF 256M HyperLink Data
5000 0000 5FFF FFFF 256K Reserved
6000 0000 6FFF FFFF 256K PCIe Data
7000 0000 73FF FFFF 64M EMIF16 Data NAND Memory (CS2)
8000 0000 FFFF FFFF 2G DDR3 Data

Multicore Training
MSMC Block DiagramCorePac 2
Shared RAM2048 KB
CorePac Slave Port
CorePac Slave Port
SystemSlave Port
forShared SRAM
(SMS)
System Slave Port
for External Memory
(SES)
MSMC System Master Port
MSMC EMIF Master Port
MSMC Datapath
Arbitration256
256
256
MemoryProtection &
ExtensionUnit
(MPAX)
256 256
Events
MemoryProtection &
ExtensionUnit
(MPAX)
MSMC Core
To SCR_2_Band the DDR
Tera
Net
TeraNet
256
Error Detection & Correction (EDC)
256
256
256
CorePac Slave Port
CorePac Slave Port
256 256
XMCMPAX
CorePac 3
XMCMPAX
CorePac 0
XMCMPAX
CorePac 1
XMCMPAX

Multicore Training
XMC – External Memory Controller
The XMC is responsible for the following:
1. Address extension/translation2. Memory protection for addresses outside C66x3. Shared memory access path4. Cache and pre-fetch support
User Control of XMC:
5. MPAX (Memory Protection and Extension) Registers6. MAR (Memory Attributes) Registers
Each core has its own set of MPAX and MAR registers!

Multicore Training
The MPAX RegistersMPAX (Memory Protection and Extension) Registers: • Translate between physical and logical address• 16 registers (64 bits each) control (up to) 16 memory
segments.• Each register translates logical memory into
physical memory for the segment.
FFFF_FFFF
8000_00007FFF_FFFF
0:8000_00000:7FFF_FFFF
1:0000_00000:FFFF_FFFF
C66x CorePacLogical 32-bitMemory Map
SystemPhysical 36-bitMemory Map
0:0C00_00000:0BFF_FFFF
0:0000_0000
F:FFFF_FFFF
8:8000_00008:7FFF_FFFF
8:0000_00007:FFFF_FFFF
0C00_00000BFF_FFFF
0000_0000
Segment 1Segment 0
MPAX Registers

Multicore Training
The MAR RegistersMAR (Memory Attributes) Registers:• 256 registers (32 bits each) control 256 memory segments:
– Each segment size is 16MBytes, from logical address 0x0000 0000 to address 0xFFFF FFFF.
– The first 16 registers are read only. They control the internal memory of the core.
• Each register controls the cacheability of the segment (bit 0) and the prefetchability (bit 3). All other bits are reserved and set to 0.
• All MAR bits are set to zero after reset.

Multicore Training
• Speeds up processing by making shared L2 cached by private L2 (L3 shared).
• Uses the same logical address in all cores; Each one points to a different physical memory.
• Uses part of shared L2 to communicate between cores. So makes part of shared L2 non-cacheable, but leaves the rest of shared L2 cacheable.
• Utilizes 8G of external memory; 2G for each core.
XMC: Typical Use Cases

Multicore Training
Agenda
1. Overview of the 6614/6612 TeraNet 2. Memory System – DSP CorePac Point of View
1. Overview of Memory Map2. MSMC and External Memory
3. Memory System – ARM Point of View1. Overview of Memory Map2. ARM Subsystem Access to Memory
4. ARM-DSP CorePac Communication1. SysLib and its libraries2. MSGCOM 3. Pktlib4. Resource Manager

Multicore Training
ARM Core
AXI2VBUS Bridge
(CPU/2)
SSMCPU/2
AINTCCPU/2
Clk Div
Sec/PublicROM 176KB
ublic
ICE Crusher
System Interrupts
Debug Bus
L1D 32KB
L2 Cache256 KB
Integer Core
ger
Neon Core
ARM A8 Core 1.2GHz
L1L 32KB
128
/32
Sec/Public RAM 64KB
OCP2ATB
CoreSight Embedded
Trace Macrocell
ARM Corepac
/32
/64
256b TeraNet running at CPU/2Connecting to ARM_128 switch
for DDR_EMIF
128b TeraNet running at CPU/3Connecting to ARM_64 switch
Master 0 Master 1
/32
Multicore Training
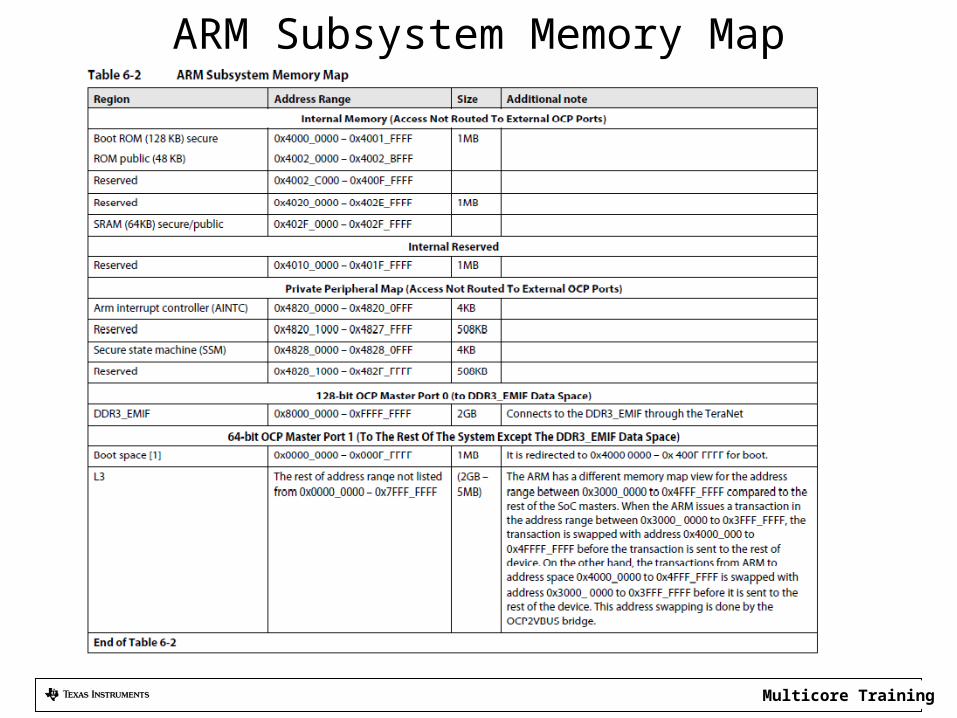
ARM Subsystem Memory Map

Multicore Training
ARM Subsystem Ports
• 32-bit ARM addressing (MMU or Kernel)• 31 bits addressing into the external memory
– ARM can address ONLY 2GB of external DDR (No MPAX translation) 0x8000 0000 to 0xFFFF FFFF
• 31 bits are used to access SOC memory or to address internal memory (ROM)

Multicore Training
ARM Visibility Through the TeraNet Connection
• It can see the QMSS data at address 0x3400 0000• It can see HyperLink data at address 0x4000 0000• It can see PCIe data at address 0x6000 0000• It can see shared L2 at address 0x0C00 0000 • It can see EMIF 16 data at address 0x7000 0000
– NAND– NOR– Asynchronous SRAM

Multicore Training
ARM Access SOC Memory
• Do you see a problem with HyperLink access?– Addresses in the 0x4 range are part of the internal ARM
memory map.
• What about the cache and data from the Shared Memory and the Async EMIF16?– The next slide presents a page from the device errata.
Description Virtual Address from Non-ARM Masters Virtual Address from ARM
QMSS 0x3400_0000 to 0x341F_FFFF 0x4400_0000 to 0x441F_FFFF
HyperLink 0x4000_0000 to 0x4FFF_FFFF 0x3000_0000 to 0x3FFF_FFFF

Multicore Training
Errata User’s Note Number 10

Multicore Training
ARM Endianess
• ARM uses only Little Endian.• DSP CorePac can use Little Endian or Big
Endian.• The User’s Guide shows how to mix ARM core
Little Endian code with DSP CorePac Big Endian.

Multicore Training
Agenda
1. Overview of the 6614/6612 TeraNet 2. Memory System – DSP CorePac Point of View
1. Overview of Memory Map2. MSMC and External Memory
3. Memory System – ARM Point of View1. Overview of Memory Map2. ARM Subsystem Access to Memory
4. ARM-DSP CorePac Communication1. SysLib and its libraries2. MSGCOM 3. Pktlib4. Resource Manager

Multicore Training
MCSDK Software Layers
Hardware
SYS/BIOSRTOS
Software Framework Components
Inter-ProcessorCommunication
(IPC)Instrumentation
Communication Protocols
TCP/IPNetworking
(NDK)
Algorithm Libraries
DSPLIB IMGLIB MATHLIB
Demonstration Applications
HUA/OOB IO Bmarks ImageProcessing
Low-Level Drivers (LLDs)
Chip Support Library (CSL)
EDMA3
PCIe
PA
QMSS
SRIO
CPPI
FFTC
HyperLink
TSIP
…
Platform/EVM Software
Bootloader
PlatformLibrary
Power OnSelf Test (POST)
OSAbstraction Layer
ResourceManager
Transports- IPC- NDK

Multicore Training
SysLib Library – An IPC Element
Application
System Library(SYSLIB)
Low-Level Drivers (LLD)
Hardware AcceleratorsQueue Manager Subsystem
(QMSS)
NetworkCoprocessor
(NETCP)
CPPI LLD PA LLD SA LLD
ResourceManager (ResMgr)
Packet Library(PktLib)
MsgComLibrary
NetFPLibrary
ResourceManagement
SAP
PacketSAP
CommunicationSAP
FastPathSAP

Multicore Training
MsgCom Library
• Purpose: To exchange messages between a reader and writer.
• Read/write applications can reside:– On the same DSP core– On different DSP cores– On both the ARM and DSP core
• Channel and Interrupt-based communication:– Channel is defined by the reader (message
destination) side– Supports multiple writers (message sources)

Multicore Training
Channel Types
• Simple Queue Channels: Messages are placed directly into a destination hardware queue that is associated with a reader.
• Virtual Channels: Multiple virtual channels are associated with the same hardware queue.
• Queue DMA Channels: Messages are copied using infrastructure PKTDMA between the writer and the reader.
• Proxy Queue Channels – Indirect channels work over BSD sockets; Enable communications between writer and reader that are not connected to the same Navigator.

Multicore Training
Interrupt Types
• No interrupt: Reader polls until a message arrives.• Direct Interrupt: Low-delay system; Special queues
must be used.• Accumulated Interrupts: Special queues are used;
Reader receives an interrupt when the number of messages crosses a defined threshold.

Multicore Training
Blocking and Non-Blocking
• Blocking: The Reader can be blocked until message is available.
• Non-blocking: The Reader polls for a message. If there is no message, it continues execution.

Multicore Training
Case 1: Generic Channel Communication
Zero Copy-based Constructions: Core-to-Core
Reader
Writer
MyCh1
Put(hCh,msg);Tibuf *msg = PktLibAlloc(hHeap);
PktLibFree(msg);Tibuf *msg =Get(hCh);
hCh=Find(“MyCh1”); hCh = Create(“MyCh1”);
Delete(hCh);
NOTE: Logical function only
1. Reader creates a channel ahead of time with a given name (e.g., MyCh1).2. When the Writer has information to write, it looks for the channel (find).3. Writer asks for a buffer and writes the message into the buffer.4. Writer does a “put” to the buffer. The Navigator does it – magic!5. When the Reader calls “get,” it receives the message.6. The Reader must “free” the message after it is done reading.

Multicore Training
Case 2: Low-Latency Channel CommunicationSingle and Virtual Channel
Zero Copy-based Construction: Core-to-Core
Reader
Writer
NOTE: Logical function only
1. Reader creates a channel based on a pending queue. The channel is created ahead of time with a given name (e.g., MyCh2).
2. Reader waits for the message by pending on a (software) semaphore.3. When Writer has information to write, it looks for the channel (find).4. Writer asks for buffer and writes the message into the buffer.5. Writer does a “put” to the buffer. The Navigator generates an interrupt . The ISR posts the
semaphore to the correct channel.6. The Reader starts processing the message.7. Virtual channel structure enables usage of a single interrupt to post semaphore to one of
many channels.
MyCh3
MyCh2hCh = Create(“MyCh2”);
Posts internal Sem and/or callback posts MySem;chRx(driver)
Put(hCh,msg);Tibuf *msg = PktLibAlloc(hHeap);
PktLibFree(msg);
hCh=Find(“MyCh2”); Get(hCh); or Pend(MySem);
hCh = Create(“MyCh3”);Get(hCh); or Pend(MySem);
PktLibFree(msg);Put(hCh,msg);Tibuf *msg = PktLibAlloc(hHeap);hCh=Find(“MyCh3”);

Multicore Training
Case 3: Reduce Context Switching
Zero Copy-based Constructions: Core-to-Core
Reader
Writer
1. Reader creates a channel based on an accumulator queue. The channel is created ahead of time with a given name (e.g., MyCh4).
2. When Writer has information to write, it looks for the channel (find).3. Writer asks for buffer and writes the message into the buffer.4. The writer put the buffer. The Navigator adds the message to an accumulator queue.5. When the number of messages reaches a water mark, or after a pre-defined time out, the
accumulator sends an interrupt to the core.6. Reader starts processing the message and makes it “free” after it is done.
MyCh4
Accumulator
chRx(driver)
PktLibFree(msg);
Tibuf *msg =Get(hCh);
Delete(hCh);
Put(hCh,msg);Tibuf *msg = PktLibAlloc(hHeap);
hCh=Find(“MyCh4”);
hCh = Create(“MyCh4”);
NOTE: Logical function only

Multicore Training
Case 4: Generic Channel Communication
ARM-to-DSP Communications via Linux Kernel VirtQueue
Reader
Writer
1. Reader creates a channel ahead of time with a given name (e.g., MyCh5).2. When the Writer has information to write, it looks for the channel (find). The kernel is aware of the user
space handle.3. Writer asks for a buffer. The kernel dedicates a descriptor to the channel and provides the Writer with a
pointer to a buffer that is associated with the descriptor. The Writer writes the message into the buffer. 4. Writer does a “put” to the buffer. The kernel pushes the descriptor into the right queue. The Navigator
does a loopback (copies the descriptor data) and frees the Kernel queue. The Navigator loads the data into another descriptor and sends it to the appropriate core.
5. When the Reader calls “get,” it receives the message.6. The Reader must “free” the message after it is done reading.
MyCh5
Put(hCh,msg);msg = PktLibAlloc(hHeap);
PktLibFree(msg);
Tibuf *msg =Get(hCh);hCh=Find(“MyCh5”);
hCh = Create(“MyCh5”);
Delete(hCh);
RxPKTDMA
TxPKTDMA
NOTE: Logical function only

Multicore Training
Case 5: Low-Latency Channel Communication
ARM-to-DSP Communications via Linux Kernel VirtQueue
Reader
Writer
1. Reader creates a channel based on a pending queue. The channel is created ahead of time with a given name (e.g., MyCh6).
2. Reader waits for the message by pending on a (software) semaphore.3. When Writer has information to write, it looks for the channel (find). The kernel space is aware of the
handle.4. Writer asks for buffer. The kernel dedicates a descriptor to the channel and provides the Writer with a
pointer to a buffer that is associated with the descriptor. The Writer writes the message into the buffer. 5. Writer does a “put” to the buffer. The kernel pushes the descriptor into the right queue. The Navigator
does a loopback (copies the descriptor data) and frees the Kernel queue. The Navigator loads the data into another descriptor, moves it to the right queue, and generates an interrupt. The ISR posts the semaphore to the correct channel
6. Reader starts processing the message.7. Virtual channel structure enables usage of a single interrupt to post semaphore to one of many channels.
PktLibFree(msg);
MyCh6
PktLibFree(msg);
hCh = Create(“MyCh6”);
RxPKTDMA
chIRx(driver) Get(hCh); or Pend(MySem);
TxPKTDMA
Put(hCh,msg);msg = PktLibAlloc(hHeap);
hCh=Find(“MyCh6”);
Delete(hCh);
NOTE: Logical function only

Multicore Training
Case 6: Reduce Context Switching
ARM-to-DSP Communications via Linux Kernel VirtQueue
Reader
Writer
NOTE: Logical function only
1. Reader creates a channel based on one of the accumulator queues. The channel is created ahead of time with a given name (e.g., MyCh7).
2. When Writer has information to write, it looks for the channel (find). The Kernel space is aware of the handle.
3. The Writer asks for a buffer. The kernel dedicates a descriptor to the channel and gives the Write a pointer to a buffer that is associated with the descriptor. The Writer writes the message into the buffer.
4. The Writer puts the buffer. The Kernel pushes the descriptor into the right queue. The Navigator does a loopback (copies the descriptor data) and frees the Kernel queue. Then the Navigator loads the data into another descriptor. Then the Navigator adds the message to an accumulator queue.
5. When the number of messages reaches a watermark, or after a pre-defined time out, the accumulator sends an interrupt to the core.
6. Reader starts processing the message and frees it after it is complete.
MyCh7
PktLibFree(msg);
Msg = Get(hCh);
hCh = Create(“MyCh7”);
RxPKTDMA Accumulator
chRx(driver)
TxPKTDMA
Put(hCh,msg);
msg = PktLibAlloc(hHeap);
hCh=Find(“MyCh7”);
Delete(hCh);

Multicore Training
Code Example
ReaderhCh = Create(“MyChannel”, ChannelType, struct *ChannelConfig); // Reader specifies what channel it wants to create
// For each messageGet(hCh, &msg) // Either Blocking or Non-blocking call,pktLibFreeMsg(msg); // Not part of IPC API, the way reader frees the message can be application specific
Delete(hCh);
Writer:hHeap = pktLibCreateHeap(“MyHeap); // Not part of IPC API, the way writer allocates the message can be application specifichCh = Find(“MyChannel”);
//For each messagemsg = pktLibAlloc(hHeap); // Not part of IPC API, the way reader frees the message can be application specificPut(hCh, msg); // Note: if Copy=PacketDMA, msg is freed my Tx DMA.…msg = pktLibAlloc(hHeap); // Not part of IPC API, the way reader frees the message can be application specificPut(hCh, msg);

Multicore Training
Packet Library (PktLib)
• Purpose: High-level library to allocate packets and manipulate packets used by different types of channels.
• Enhance capabilities of packet manipulation• Enhance Heap manipulation

Multicore Training
Heap Allocation
• Heap creation supports shared heaps and private heaps.
• Heap is identified by name. It contains Data buffer Packets or Zero Buffer Packets
• Heap size is determined by application.• Typical pktlib functions:
– Pktlib_createHeap– Pktlib_findHeapbyName– Pktlib_allocPacket

Multicore Training
Packet Manipulations
• Merge multiple packets into one (linked) packet
• Clone packet• Split Packet into multiple packets• Typical pktlib functions:
– Pktlib_packetMerge– Pktlib_clonePacket– Pktlib_splitPacket

Multicore Training
PktLib: Additional Features
• Clean up and garbage collection (especially for clone packets and split packets)
• Heap statistics• Cache coherency

Multicore Training
Resource Manager (ResMgr) Library
• Purpose: Provides a set of utilities to manage and distribute system resources between multiple users and applications.
• The application asks for a resource. If the resource is available, it gets it. Otherwise, an error is returned.

Multicore Training
ResMgr Controls
• General purpose queues• Accumulator channels• Hardware semaphores• Direct interrupt queues• Memory region request