build agile and elastic data pipeline
TRANSCRIPT

ROBIN SYSTEMS
BUILD AN AGILE AND ELASTIC DATA PIPELINE
Deba Chatterjee – Director of ProductsSheela Toor – Director of Product Marketing

WHY DATA PIPELINE ?
› DATA is the new currency of the digital economy
› Data is an untapped valuable resource that organizations should learn to extract and use it to reap huge rewards
CONFIDENTIAL – RESTRICTED DISTRIBUTION
Courtesy: http://www.masquenegocio.com/wp-content/uploads/2014/07/Data-currency.jpg
Data Information Decision
Good Data beats Opinion !!!

DATA PIPELINE
› Data pipeline is an automated process that executes at regular interval to ingest, cleanse, transform and/oraggregate incoming feed of data to generate the output dataset in the format that is suitable for downstream processing, with no manual intervention.
CONFIDENTIAL – RESTRICTED DISTRIBUTION
data pipeline: (Worldwide – Last 5 Years)
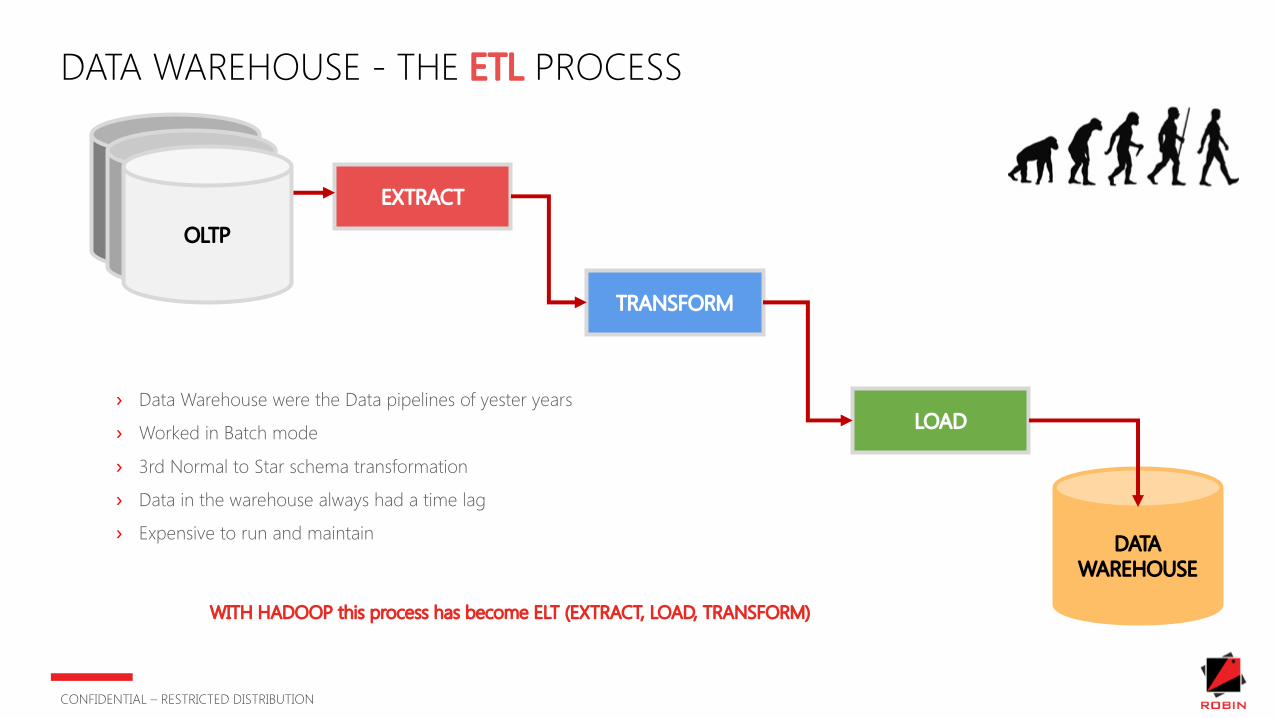
DATA WAREHOUSE - THE ETL PROCESS
CONFIDENTIAL – RESTRICTED DISTRIBUTION
EXTRACT
TRANSFORM
LOAD
OLTP
DATA WAREHOUSE
› Data Warehouse were the Data pipelines of yester years
› Worked in Batch mode
› 3rd Normal to Star schema transformation
› Data in the warehouse always had a time lag
› Expensive to run and maintain
OLTPOLTP
WITH HADOOP this process has become ELT (EXTRACT, LOAD, TRANSFORM)
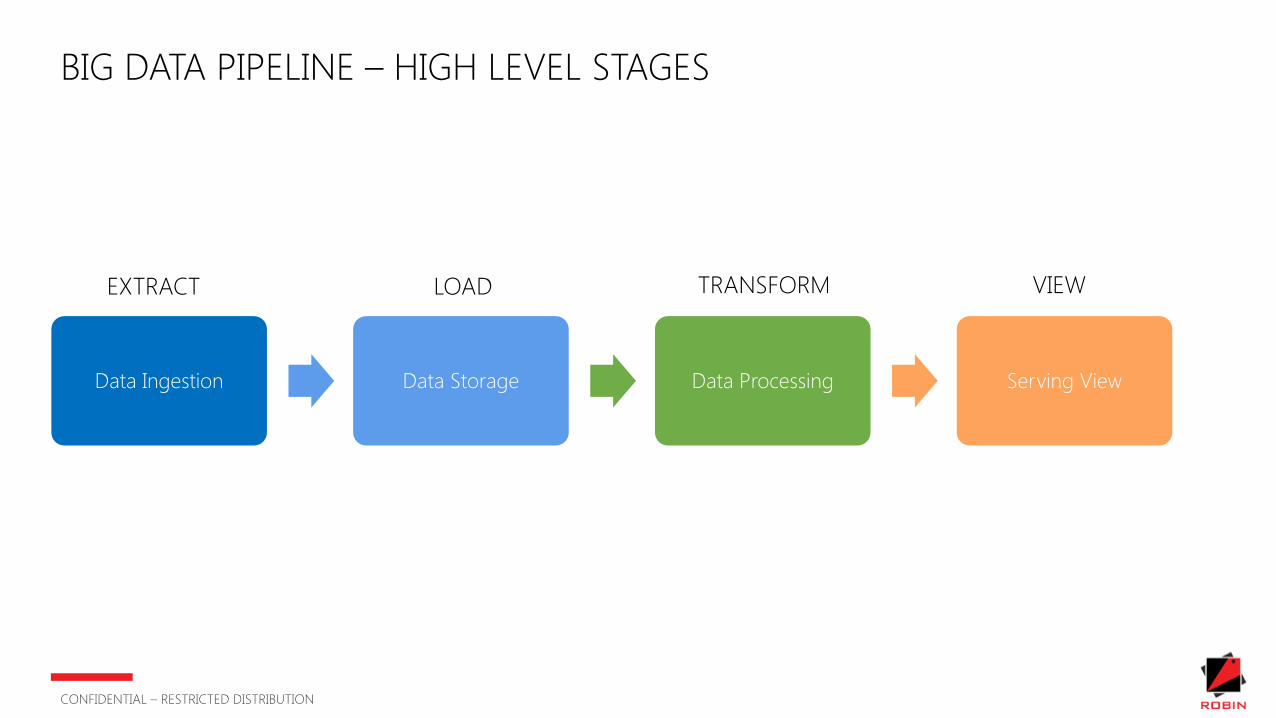
BIG DATA PIPELINE – HIGH LEVEL STAGES
CONFIDENTIAL – RESTRICTED DISTRIBUTION
Data Ingestion Data Storage Data Processing Serving View
EXTRACT LOAD TRANSFORM VIEW

BIG DATA PIPELINE
CONFIDENTIAL – RESTRICTED DISTRIBUTION
DATA INGEST
DATA STORAGE
DATA PROCESSING
DATA SERVING VISUALIZATION
DATA SOURCES
Databases
Social
Web
Sensor
Log

BIG DATA PIPELINES VARY ACROSS CUSTOMERS
CONFIDENTIAL – RESTRICTED DISTRIBUTION
DATA INGEST
DATA STORAGE
VISUALIZEDATA SOURCES
Databases
Social
Web
Sensor
Log
DATA SERVING
DATA PROCESSING

BUILD YOUR DATA PIPELINE
› Data Pipeline can be built using a combination of any of these components to address a variety of data need
CONFIDENTIAL – RESTRICTED DISTRIBUTION
Kafka Flume Sqoop Hadoop Spark Revolution R
Kafka Logstash Elasticsearch Kibana
› MDM: Customer 360, Product Catalog
› Personalization and Recommendation
› Internet of Things and Time Series
› Fraud Detection
› List Management
› Messaging
› Inventory Management
› Authentication
Kafka spark Streaming Cassandra

How do I provide developers access
to data ?
How to avoid overprovisioning
initially ?
Can I run multiple pipelines on the same
setup without compromising performance ?
When data sets & workload grows , can I avoid under
provisioning ?
How do you handle spikes and
growth ?
How do I quickly deploy my entire
pipeline ? How do I provide developers access
to data ?
How to avoid overprovisioning
initially ?
Can I run multiple pipelines on the same
setup without compromising performance ?
When data sets & workload grows , can I avoid under
provisioning ?
How do you handle spikes and
growth ?
How do I quickly deploy my entire
pipeline ?
DATA PIPELINE - CHALLENGES
CONFIDENTIAL – RESTRICTED DISTRIBUTION
When data sets & workload grows , can I avoid under
provisioning ?
How to avoid overprovisioning
initially ?
DATA PIPELINE IS A CLUSTER OF MULTIPLE CLUSTERED APPLICATIONS EXPECTED TO WORK IN UNISON
How do I quickly deploy my entire
pipeline ?
How do you handle spikes and
growth ?
How do I provide developers access
to data ?
Can I run multiple pipelines on the same
setup without compromising performance ?

DATA PIPELINE CHECKLIST
Requirement Concern Support
How do I quickly deploy my entire pipeline ? Will I be able to use my existing commodity hardware for my data pipeline ?
How do I avoid overprovisioning and under provisioning of hardware ?
Will I be able to just run on enough hardware and not waste resources ?
How can I share data with my developers ? Will I be able to prevent them from making any changes ?
How do I handle seasonal spikes ? Will my setup allow me to scale each cluster separately ?
How can I run my data pipelines on shared infrastructure ?
Will I be able to address noisy neighbor problems ?
CONFIDENTIAL – RESTRICTED DISTRIBUTION

CONFIDENTIAL – RESTRICTED DISTRIBUTION
How do I quickly get going with my pipeline?

WHAT IS ROBIN ?
Software Only Solution – Runs on commodity hardware
Applications are deployedas Docker/LXC Containers
Application-definedCompute Plane
Application-definedStorage Plane
Compute Node
Storage Node
Compute Node Converged Node
Converged Node
Converged Node
Run and Manage APPLICATIONS
not Containers or Virtual Machines
PUSH BUTTONAPPLICATION
LIFECYCLE MGMT
DEPLOY
SCALE
FAILOVER
SNAPSHOT
CLONE
QOS

ANATOMY OF AN APPLICATION MANIFESTname: Apache Cassandraversion: "3.0”snapshot: enabledclone: enabled
roles: [seed, member]
seed:multinode: trueimage:
name: robinsys/Cassandraversion: "3.0"engine: docker
compute:memory: 1024M
storage:- type: commitlogmedia: ssdprotection: replicate
- type: datamedia: hddprotection: app-defined
env:CASSANDRA_CLUSTER_NAME: '{{APP_NAME}}‘MAX_HEAP_SIZE: 512MHEAP_NEWSIZE: 100M
vnodehooks:poststart: "bash check_cassandra“postcreate: "bash check_cassandra“postgrow: "bash check_cassandra“postrollback: "bash check_cassandra“postclone: "bash post_clone PEER_IP_LIST={{IP_LIST}}"
member:multinode: trueimage:
name: robinsys/Cassandraversion: "3.0"engine: lxc
affinityrules:- name: "different rack“target: "-rack“
- name: “local storage”target: “storage“
- name: “placement”target: tagstags: [“model: Dell R830”]
Application details like name, description, and the supported operations like snapshot, clone, etc.
Roles represent different services that make up the application
Container image to use for a specific role. Docker, or LXC
Default resource requirements for all containers in that role. These can be CPU, memory, storage volumes, and QoS policies
Application configuration parameters. These values are set as environment variables for the container
Applications hooks are scripts that automate application lifecycle operations such as start, stop, relocate, clone. Each hook defines a single script that can be written in bash, python, ansible, chef
Affinity rules to control placement of containers
A
B
C
D
E
F
A
B
C
D
E
F
G G

Hortonworks (HDP) 2.3
EACH COMPONENT HAS ITS MANAGEMENT COMPLEXITY
› Hadoop is an ecosystem and not a singleproduct
› Several components need to work togetherto deliver what users want
› Enterprise customers are grappling withHadoop’s operational complexity
› Provisioning enterprise grade Hadoop cantake from days to weeks
CONFIDENTIAL – RESTRICTED DISTRIBUTION
Pig 0.15.0
Hive 1.2.1 Tez 0.7.0 Solr 5.2.1
Spark 1.3.1
Slider 0.80.0
HBase1.1.1
Phoenix 4.4.0
Storm 0.10.0
Falcon 0.6.1
Atlas 0.5.0
Sqoop1.4.6
Flume 1.5.2
Kafka 0.8.2
Ambari2.1.0
Oozie4.2.0
Knox 0.6.0
Ranger 0.5.0
Zookeeper 3.4.6
Accumulo1.7.0

CONFIDENTIAL – RESTRICTED DISTRIBUTION
DEMOSingle click provisioning – How quickly can I get up and running ?

CONFIDENTIAL – RESTRICTED DISTRIBUTION
How do I handle seasonal spikes and growth ?

ONE – CLICK INSTANT SCALE - OUT
› On-demand Instant scale-out› Helps to right size your cluster with growing demand
APPLICATION CLUSTER
Cassandra CassandraCassandra Cassandra

ON-DEMAND INSTANT SCALE-UP
› On-demand Instant Scale-up› No data redistribution overhead› No need to stop the cluster› Ideal to meet temporary or seasonal demand
APPLICATION CLUSTER
Cassandra CassandraCassandra
› Scale-out isn’t always the solution› Results in data redistribution, which is expensive and time consuming› In some cases a non-reversible operation

CONFIDENTIAL – RESTRICTED DISTRIBUTION
How do I provide developers access to data ?

WHY DO I NEED TO CLONE PARTS OF MY DATA PIPELINE ?
CONFIDENTIAL – RESTRICTED DISTRIBUTION
https://www.elastic.co/blog/cluster-cloning-in-the-cloud
AdhocAnalytics
Test Upgrades DevOps Testing
ChangesIntegration
Testing
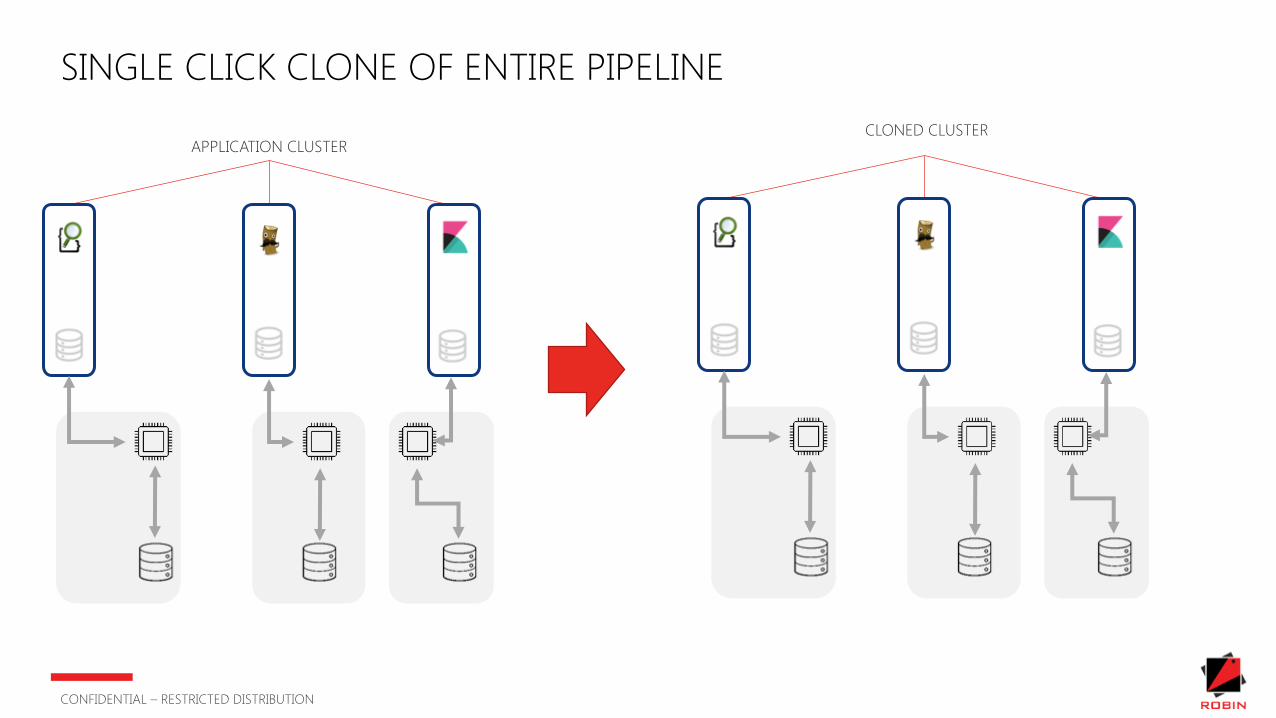
SINGLE CLICK CLONE OF ENTIRE PIPELINE
CONFIDENTIAL – RESTRICTED DISTRIBUTION
APPLICATION CLUSTERCLONED CLUSTER

CONFIDENTIAL – RESTRICTED DISTRIBUTION
DEMOSingle click scale-out of my data pipeline
Clone my data pipeline

CONFIDENTIAL – RESTRICTED DISTRIBUTION
How do I avoid under & over provisioning ?
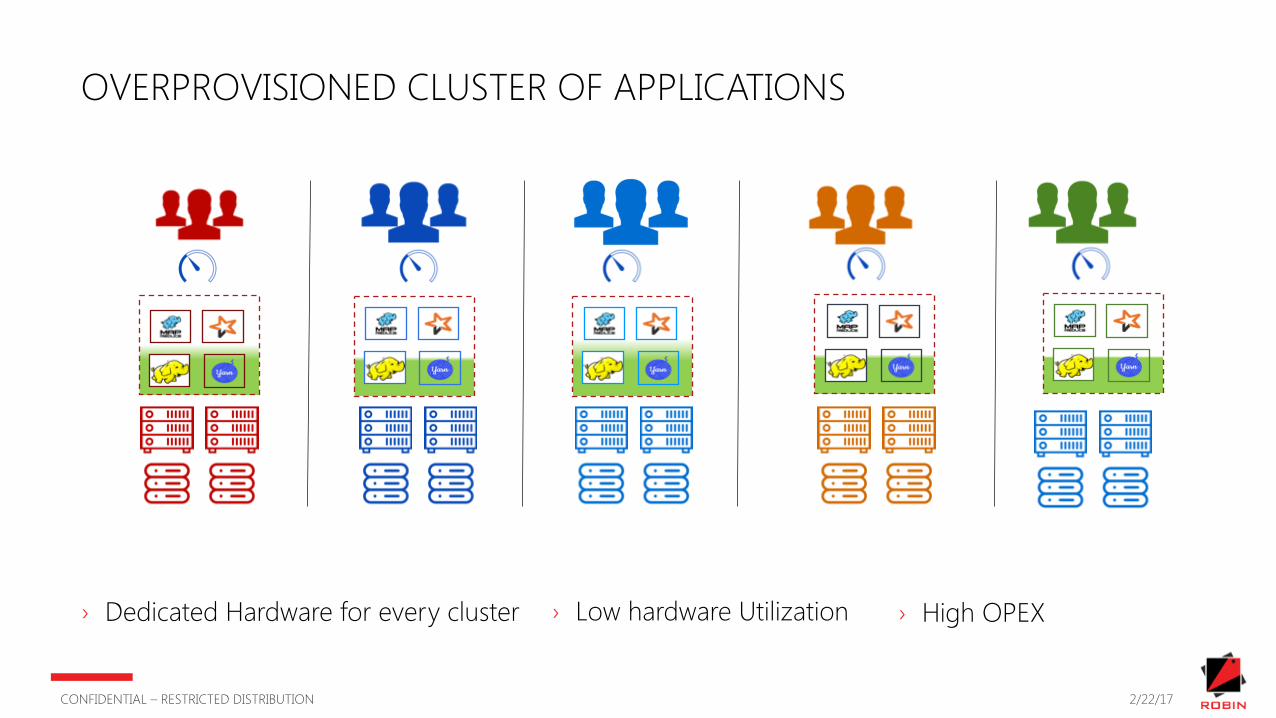
OVERPROVISIONED CLUSTER OF APPLICATIONS
› Dedicated Hardware for every cluster › Low hardware Utilization › High OPEX
CONFIDENTIAL – RESTRICTED DISTRIBUTION 2/22/17
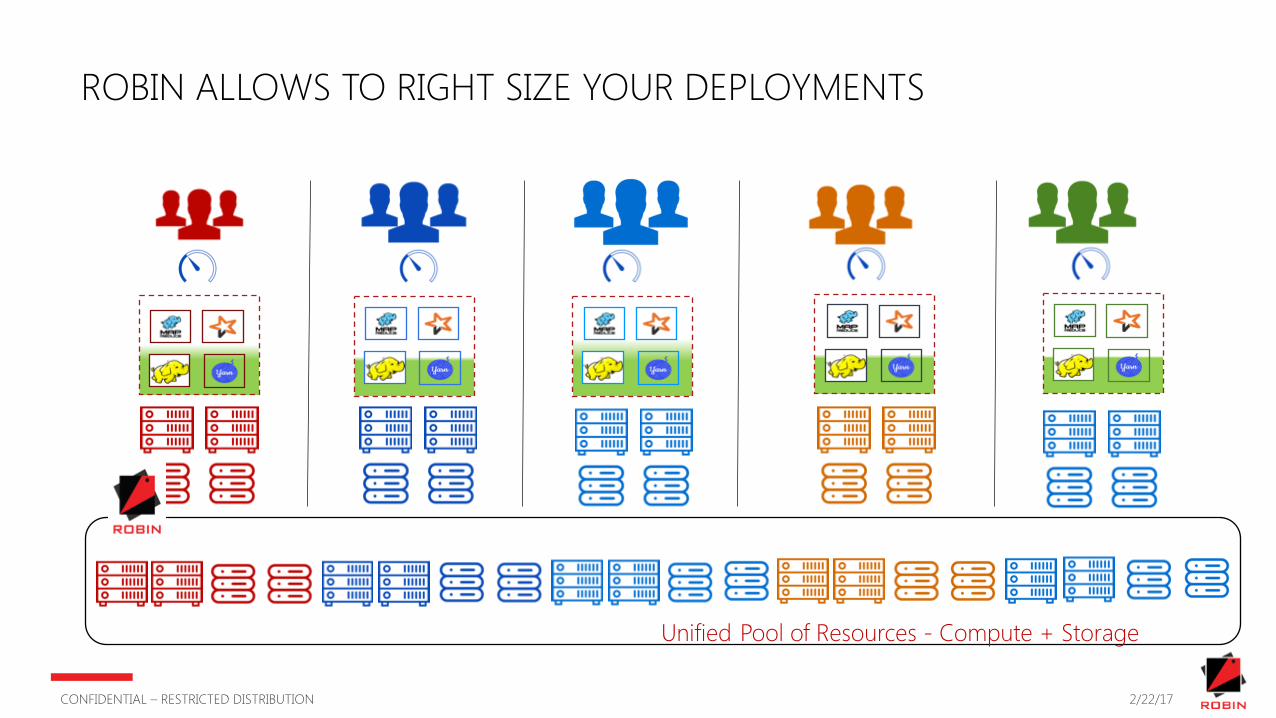
ROBIN ALLOWS TO RIGHT SIZE YOUR DEPLOYMENTS
Unified Pool of Resources - Compute + Storage
CONFIDENTIAL – RESTRICTED DISTRIBUTION 2/22/17
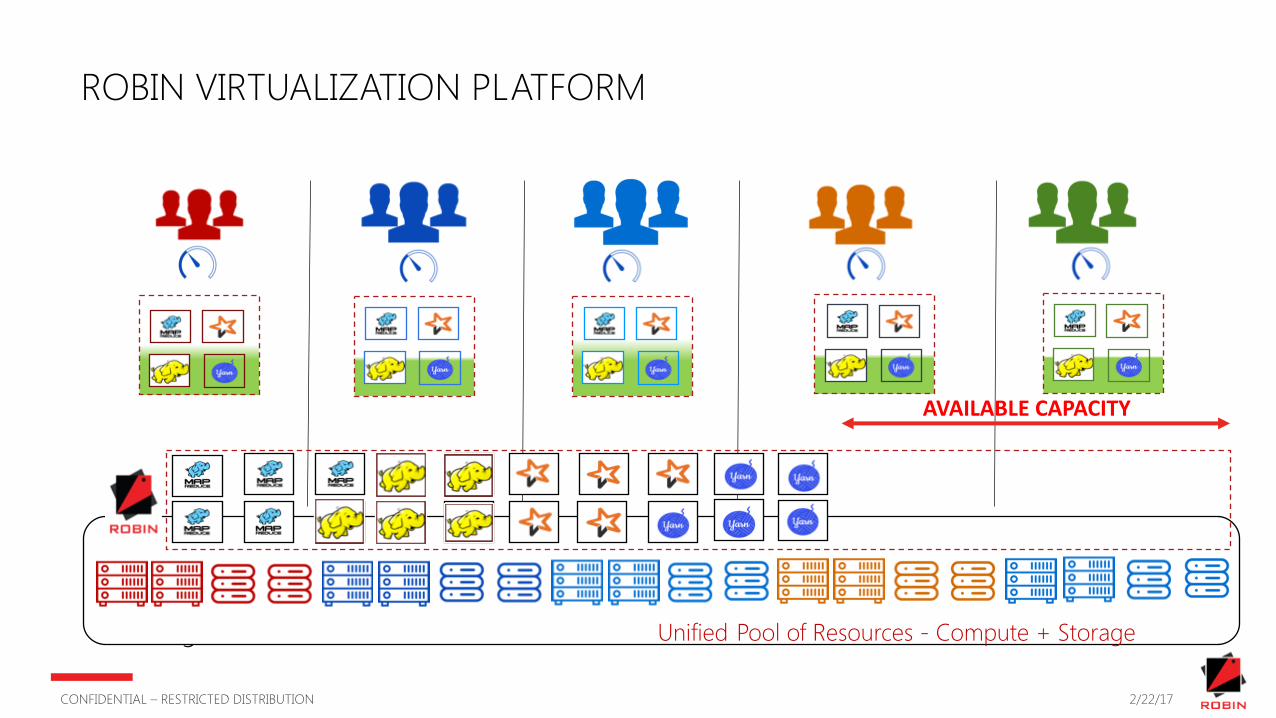
ROBIN VIRTUALIZATION PLATFORM
› Dedicated Hardware for every tenant› Low Utilization › High OPEX Unified Pool of Resources - Compute + Storage
AVAILABLECAPACITY
CONFIDENTIAL – RESTRICTED DISTRIBUTION 2/22/17

ROBIN VIRTUALIZATION PLATFORM
› Dedicated Hardware for every tenant› Low Utilization › High OPEX Unified Pool of Resources - Compute + Storage
AVAILABLECAPACITY
CONFIDENTIAL – RESTRICTED DISTRIBUTION 2/22/17

SHARE “PEAKS AND TROUGHS”
› Identification and placement key to success
Tenant1Tenant2Tenant3
Legend
Unconsolidated Consolidated
CONFIDENTIAL – RESTRICTED DISTRIBUTION 2/22/17

DATA SHARING
› Build a “Virtual Data Lake” by sharing HDFS across Hadoop clusters
› Enables applications to share data due to a unified view across various data silos
ROBIN APP-AWARE ORCHESTRATOR ROBIN APP-AWARE ORCHESTRATOR
VirtualDataLake
Shares the same HDFS

CONFIDENTIAL – RESTRICTED DISTRIBUTION
DEMOHDFS Data Sharing

CONFIDENTIAL – RESTRICTED DISTRIBUTION
Can I run multiple clusters on the same setup without compromising performance ?

APP-TO-DISK QUALITY OF SERVICE
ROBIN APP-AWARE COMPUTE LAYER
node.js
ROBIN APP-AWARE COMPUTE LAYER
ROBIN CONTAINER-AWARE DATA LAYER
IOIOIO
Application-centric QoS
› Max IOPs to throttle usage
› Min IOPs to guarantee performance
› Relative weights to prioritize appsaccording to business needs
PostgresMongoDB Cassandra
MAX enforced here
MIN guaranteed here Because Robin controls the entire IO pipeline (App-to-Disk) it can truly enforce QoS
Priorities enforced here

ROBIN APP-AWARE COMPUTE LAYER
ROBIN CONTAINER-AWARE DATA LAYER
SOLVING NOISY-NEIGHBOR PROBLEM
Postgres Hadoop
Apps using multiple data volumes:Very common for most Data Apps(Hadoop, Cassandra, Oracle, …)
Because Robin controls all IOs originating on the compute host it can do IO tagging & App-aware IO scheduling
v2v1 v3 v4
v1 v2v1 v3 v4
v1
1. But App could generate IOPs at a rate equal tosum of max IOPs of each volume it uses
2. Arbitrarily capping each volume prevents activevolumes from utilizing available capacity whenother volumes are quite
Non-Robin Solution
Throttle max IOPs for each volume separately
FAIL
1. Configure max IOPs SLA per App (not individualdata volumes)
2. Tag IOs across each volume with the App ID
3. Enforce max IOPs SLA per App ID
Robin Solution
Throttle max IOPs per Appv1 v2v1 v3 v4
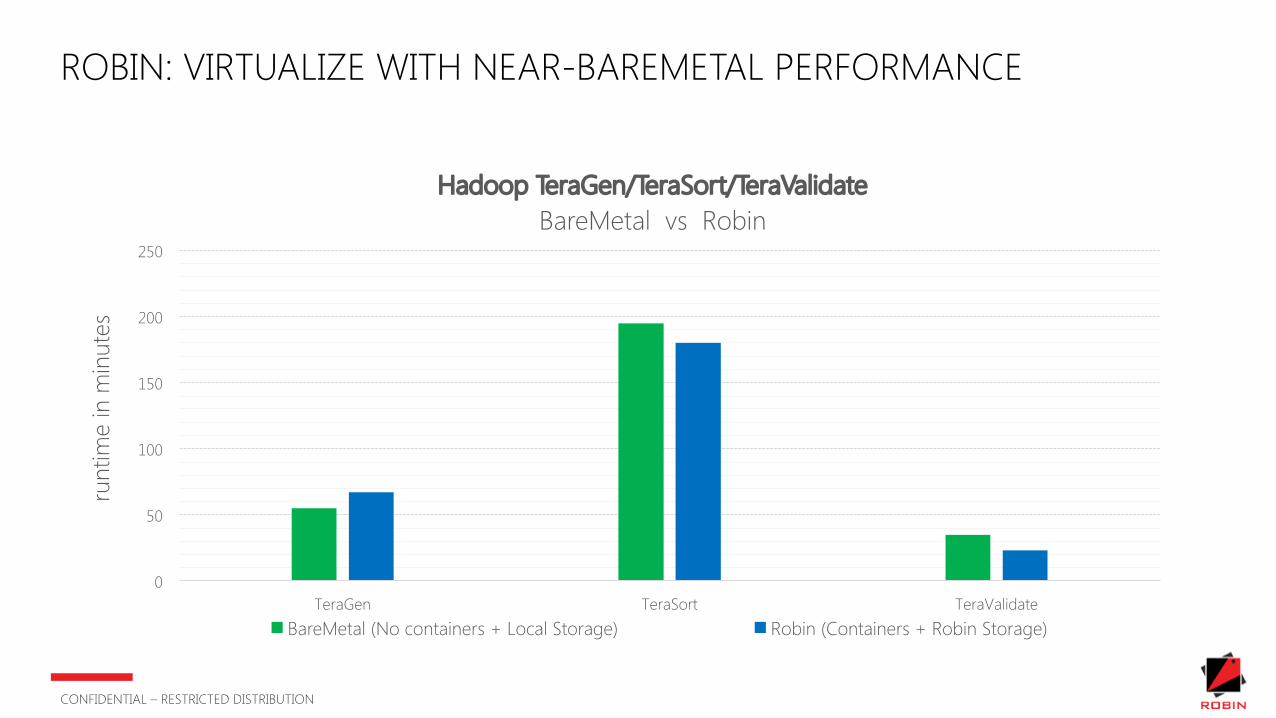
ROBIN: VIRTUALIZE WITH NEAR-BAREMETAL PERFORMANCE
0
50
100
150
200
250
TeraGen TeraSort TeraValidate
Hadoop TeraGen/TeraSort/TeraValidateBareMetal vs Robin
BareMetal (No containers + Local Storage) Robin (Containers + Robin Storage)
runt
ime
in m
inut
es
CONFIDENTIAL – RESTRICTED DISTRIBUTION

CONFIDENTIAL – RESTRICTED DISTRIBUTION
DEMOEliminate noisy neighbor and ensure QoS

DATA PIPELINE CHECKLIST
Requirement Concern
How do I quickly deploy my entire pipeline ? Will I be able to use my existing commodity hardware for my data pipeline ?
✔
How do I avoid overprovisioning and under provisioning of hardware ?
Will I be able to just run on enough hardware and not waste resources ?
✔
How can share data with my developers ? Will I be able to prevent them from making any changes ?
✔
How do I handle seasonal spikes ? Will my setup allow me to scale each cluster separately ? ✔
How can I run my data pipelines on shared infrastructure ?
Will I be able to address noisy neighbor problems ? ✔
CONFIDENTIAL – RESTRICTED DISTRIBUTION
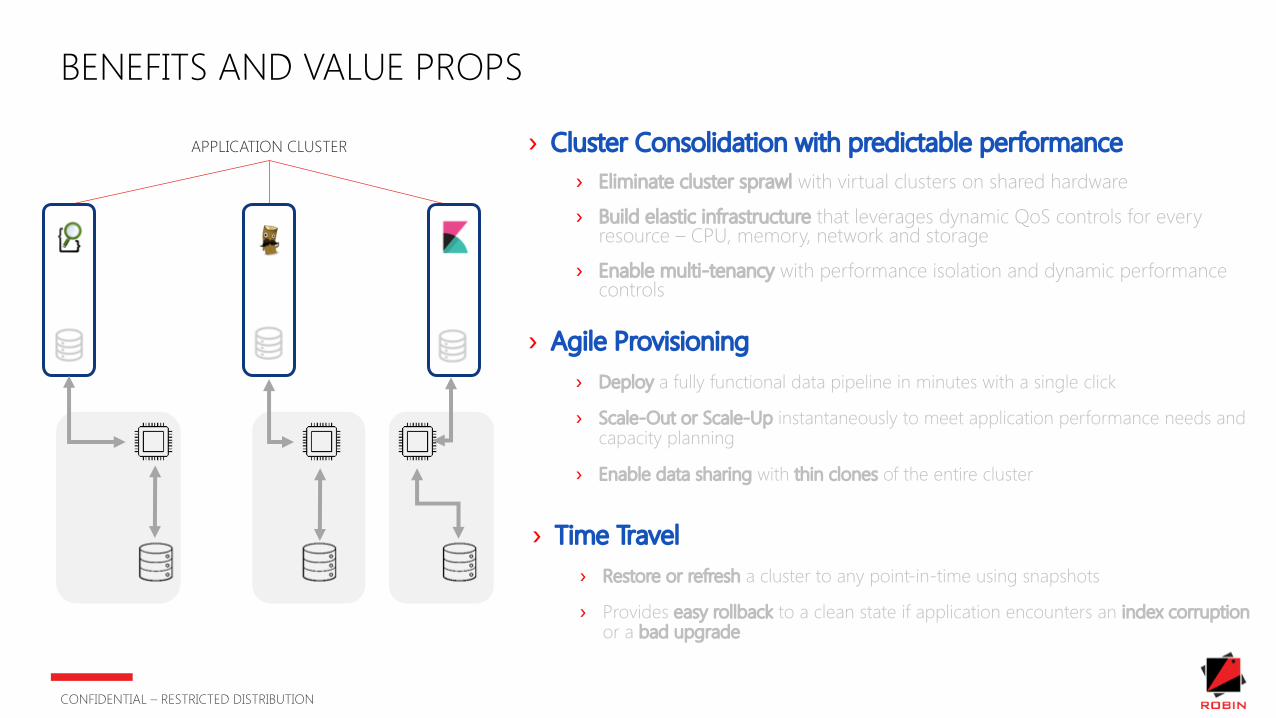
BENEFITS AND VALUE PROPS
› Cluster Consolidation with predictable performance› Eliminate cluster sprawl with virtual clusters on shared hardware
› Build elastic infrastructure that leverages dynamic QoS controls for every resource – CPU, memory, network and storage
› Enable multi-tenancy with performance isolation and dynamic performance controls
CONFIDENTIAL – RESTRICTED DISTRIBUTION
› Agile Provisioning› Deploy a fully functional data pipeline in minutes with a single click
› Scale-Out or Scale-Up instantaneously to meet application performance needs and capacity planning
› Enable data sharing with thin clones of the entire cluster
› Time Travel› Restore or refresh a cluster to any point-in-time using snapshots
› Provides easy rollback to a clean state if application encounters an index corruption or a bad upgrade
APPLICATION CLUSTER

BENEFITS AND VALUE PROPS
› Cluster Consolidation with predictable performance› Eliminate cluster sprawl with virtual clusters on shared hardware
› Build elastic infrastructure that leverages dynamic QoS controls for every resource – CPU, memory, network and storage
› Enable multi-tenancy with performance isolation and dynamic performance controls
CONFIDENTIAL – RESTRICTED DISTRIBUTION
› Agile Provisioning› Deploy a fully functional data pipeline in minutes with a single click
› Scale-Out or Scale-Up instantaneously to meet application performance needs and capacity planning
› Enable data sharing with thin clones of the entire cluster
› Time Travel› Restore or refresh a cluster to any point-in-time using snapshots
› Provides easy rollback to a clean state if application encounters an index corruption or a bad upgrade
APPLICATION CLUSTER MAXIMIZEData Center Utilization
Predictable Performance
FASTER TIME-TO-MARKET1-Click Lifecycle Management
SIMPLIFYOperational Support

www.robinsystems.com [email protected] YOU