bringing in the family to emphasise importance and win during crawling
TRANSCRIPT

USING ’PAGE IMPORTANCE’ AND FAMILY VOTES IN ONGOING CONVERSATION WITH GOOGLEBOT TO GET MORE THAN YOUR ALLOCATED CRAWL BUDGET & ’WIN’ IN THE BATTLE FOR ‘IMPORTANCE EMPHASIS’
BRINGING IN THE FAMILY DURING CRAWLING Dawn Anderson @ dawnieando




http://webpromo.expert/google-‐qa-‐duplicate-‐content/
Thanks for the mention Mr Mu J
https://youtu.be/KxCAVmXfVyI?t=3074

1994 - 1998
“THE GOOGLE INDEX IN 1998 HAD 60 MILLION PAGES” (GOOGLE)
(Source:Wikipedia.org)

2000
“INDEXED PAGES REACHES THE ONE BILLION MARK” (GOOGLE)
“IN OVER 17 MILLION WEBSITES” (INTERNETLIVESTATS.COM)

2001 ONWARDSENTER WORDPRESS, DRUPAL CMS’, PHP DRIVEN CMS’, ECOMMERCE PLATFORMS, DYNAMIC SITES, AJAX
WHICH CAN GENERATE 10,000S OR 100,000S OR 1,000,000S OF DYNAMICURLS ON THE FLY WITH DATABASE ‘FIELD BASED’ CONTENT
DYNAMIC CONTENT CREATION GROWS
ENTER FACETED NAVIGATION (WITH MANY # PATHS TO SAME CONTENT)
2003 – WE’RE AT 40 MILLION WEBSITES

2003 ONWARDS – USERS BEGIN TO JUMP ON THE CONTENT GENERATION BANDWAGGON
LOTS OF CONTENT – IN MANY FORMS

“WE KNEW THE WEB WAS BIG…” (GOOGLE, 2008)
https://googleblog.blogspot.co.uk/2008/07/we-‐knew-‐web-‐was-‐big.html
“1 trillion (as in 1,000,000,000,000) unique URLs on the web at once!”(Jesse Alpert on Google’s Official Blog, 2008)
2008 – EVEN GOOGLE ENGINEERS STOPPED IN AWE

2010 – USER GENERATED CONTENT GROWS
“Let me repeat that: we create as much information in two days now as we did from the dawn of man through 2003”
“The real issue is user-‐generated content.” (Eric Schmidt, 2010 – TechonomyConference Panel)
SOURCE: http://techcrunch.com/2010/08/04/schmidt-‐data/

Indexed Web contains at least 4.73 billion pages (13/11/2015)
CONTENT KEEPS GROWINGTotal number of websites
2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014
1,000,000,000
750,000,000
500,000,000
250,000,000
THE NUMBER OF WEBSITES DOUBLED IN SIZE BETWEEN 2011 AND 2012AND AGAIN BY 1/3 IN 2014

EVEN SIR TIM BERNERS-‐LEE(Inventor of www) TWEETED
2014 – WE PASS A BILLION INDIVIDUAL WEBSITES ONLINE
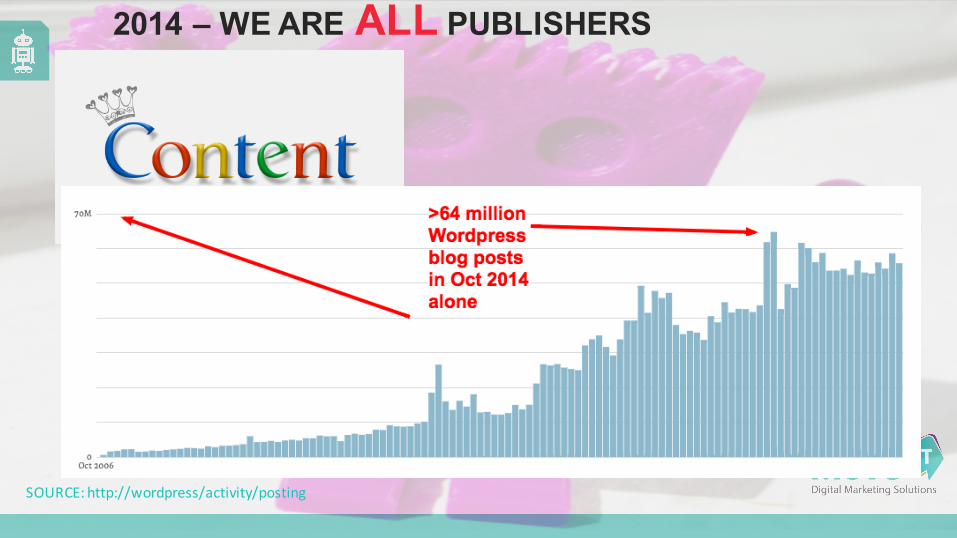
2014 – WE ARE ALL PUBLISHERS
SOURCE: http://wordpress/activity/posting

“Bloody brands becoming bloody publishers… Grumble grumble content marketing grumble.” (Jono Alderson, Twitter)
EVEN WETHERSPOONS

Grab your copy of the Wetherspoon, Smarties or Greggs News today
“Big lols” ;pppppp
WHO KNEW?

“Grab your copy of the Wetherspoon News today.” (Wetherspoons, Twitter)
WETHERSPOON NEWS

“Big lols” ;pppppp
ALL THE FACTS AND VITAL OPINION

YUP - WE ALL‘LOVE CONTENT’
– A LOT
http://www.internetlivestats.com/total-‐number-‐of-‐websites/

“As of the end of 2003, the WWW is believed to include well in excess of 10 billion distinct documents or web pages, while a search engine may have a crawling capacity that is less than half as many documents” (MANY GOOGLE PATENTS)
EVERYTHING HAS A FINITE LIMIT –CAPACITY LIMITATIONS – EVEN FOR SEARCH ENGINES
Source: Scheduler for search engine crawler Google PatentUS 8042112 B1, (Zhu et al)

“So how many unique pages does the web really contain? We don't know; we don't have time to look at them all! :-‐)”
(Jesse Alpert, Google, 2008)
Source: https://googleblog.blogspot.co.uk/2008/07/we-‐knew-‐web-‐was-‐big.html
NOT ENOUGH TIME
SOME THINGS MUST BE FILTERED

A LOT OF THE CONTENT IS ‘KIND OF THE SAME’
“There’s a needle in here somewhere”
“It’s an important needle too”

Capacity limits on Google’s
crawling system
By prioritising URLs for crawling
By assigning crawl period
intervals to URLs
How have search engines responded?
By creating work ‘schedules’ for Googlebots
WHAT IS THE SOLUTION?
“To keep within the capacity limits of the crawler, automated selection mechanisms are needed to determine not only which web pages to crawl, but which web pages to avoid crawling”. -‐Scheduler for search engine crawler, (Zhu et al)

‘Managing items in a crawl schedule’
IncludeGOOGLE CRAWL SCHEDULER PATENTS
‘Scheduling a recrawl’
‘Web crawler scheduler that utilizes sitemaps from websites’
‘
‘Document reuse in a search engine crawler’
‘Minimizing visibility of stale content in web searching including revising web crawl intervals of documents’
‘Scheduler for search engine’
EFFICIENCY IS NECESSARY

CRAWL BUDGET
1. Crawl Budget – “An allocation of crawl frequency visits to a host (IP LEVEL)”
3. Pages with a lot of links get crawled more
4. The vast majority of URLs on the web don’t get a lot of budget allocated to them (low to 0 PageRank URLs).
2. Roughly proportionate to PageRank and host load / speed / host capacity
https://www.stonetemple.com/matt-‐cutts-‐interviewed-‐by-‐eric-‐enge-‐2/

BUT… MAYBE THINGS HAVE CHANGED?
CRAWL BUDGET / CRAWL FREQUENCY IS NOT JUST ABOUT HOST-LOAD AND PAGERANK ANY MORE
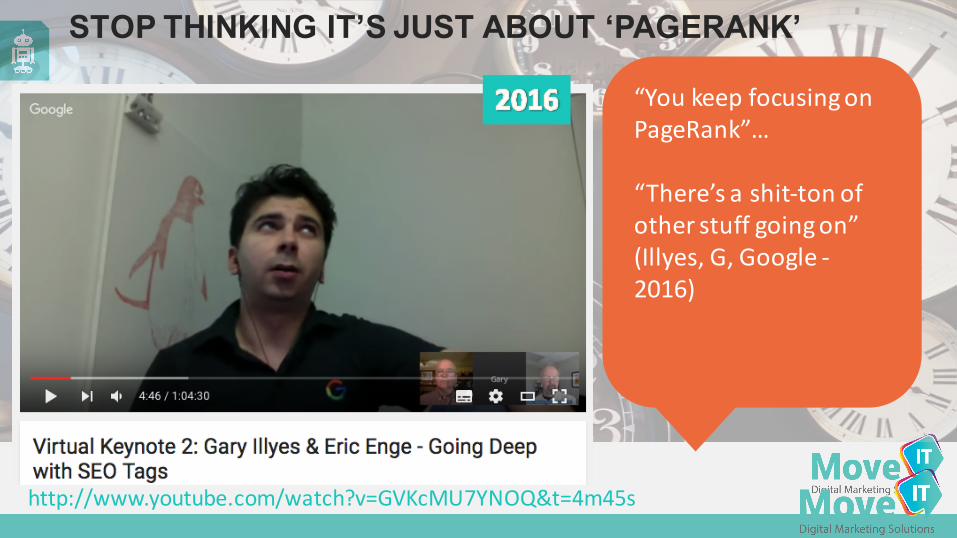
STOP THINKING IT’S JUST ABOUT ‘PAGERANK’
http://www.youtube.com/watch?v=GVKcMU7YNOQ&t=4m45s
“You keep focusing on PageRank”…
“There’s a shit-‐ton of other stuff going on” (Illyes, G, Google -‐2016)

THERE’S A LOT OF OTHER THINGS AFFECTING ‘CRAWLING’
Transcript: https://searchenginewatch.com/2016/04/06/webpromos-‐qa-‐with-‐googles-‐andrey-‐lipattsev-‐transcript/
WEB PROMOS Q & A WITH GOOGLES ANDREY LIPATTSEV

WHY?BECAUSE…
THE WEB GOT ‘MAHOOOOOSIVE’
AND CONTINUES TO GET ‘MAHOOOOOOSIVER’
SITES GOT MORE DYNAMIC, COMPLEX, AUTO-GENERATED, MULTI-FACETED, DUPLICATED, INTERNATIONALISED, BIGGER, BECAME PAGINATED AND SORTED

WE NEED MOREWAYS TO GETMORE EFFICIENTAND FILTER OUTTIME-WASTINGCRAWLING SO WE CAN FIND IMPORTANT CHANGES QUICKLY
GOOGLEBOT’S TO-DO LIST GOT REALLY BIG

Hard and Soft Crawl Limits
Importance Thresholds
Min and Max Hints & ‘Hint
ranges’
ImportanceCrawl Periods
Scheduling
FURTHER IMPROVED CRAWLING EFFICIENCY SOLUTIONS NEEDED
Prioritization TieredCrawlingBuckets
(‘Real Time, Daily, Base Layer)

SEVERAL PATENTS UPDATED
‘Managing URLs’ (Alpert et al, 2013) (PAGE IMPORTANCE DETERMINING SOFT AND HARD LIMITS ON CRAWLING)
‘Managing Items in a Crawl Schedule’ (Alpert, 2014)
‘
‘Scheduling a Recrawl’ (Anerbach, Alpert, 2013) (PREDICTING CHANGE FREQUENCY IN ORDER TO SCHEDULE NEXT VISIT, EMPLOYING HINTS (Min & Max)
(SEEM TO WORK TOGETHER)
‘Minimizing visibility of stale content in web searching including revising web crawl intervals of documents’ (INCLUDES EMPLOYING HINTS TO DETECT PAGES ‘NOT’ TO CRAWL)

Crawled multiple times daily
Crawled daily Or bi-‐daily
Crawled least on a ‘round robin’ basis – only ‘active’ segment is crawledSplit into segments
on random rotation
MANAGING ITEMS IN A CRAWL SCHEDULE (GOOGLE PATENT)
Real TimeCrawl
Daily Crawl
Base Layer Crawl
3 layers / tiers / buckets for scheduling
URLs are moved in and out of layers based on past visits data
Most Unimportant
3 TIERED SCHEDULING FOR GOOGLEBOTS

CAN WE ESCAPE THE ‘BASE LAYER’ CRAWL BUCKET RESERVED FOR ‘UNIMPORTANT’ URLS?

10 typesof
Googlebot
SOME OF THE MAJOR SEARCH ENGINE CHARACTERS
History Logs / History Server
The URL Scheduler / Crawl Manager

HISTORY LOGS / HISTORY SERVERS
HISTORY LOGS / HISTORY SERVER -‐ Builds a picture of historical data and past behaviour of the URL and ‘importance’ score to predict and plan for future crawl scheduling
• Last crawled date• Next crawl due• Last server response• Page importance score• Collaborates with link
logs• Collaborates with
anchor logs• Contributes info to
scheduling

‘BOSS’- URL SCHEDULER / URL MANAGER
Think of it as Google’s line manager or ‘air traffic controller’ for Googlebots in the web crawling system
• Schedules Googlebot visits to URLs• Decides which URLs to ‘feed’ to Googlebot• Uses data from the history logs about past visits (Change rate and
importance)• Calculates importance crawl threshold• Assigns visit regularity of Googlebot to URLs• Drops ‘max and min hints’ to Googlebot to guide on types of
content NOT to crawl or to crawl as exceptions.• Excludes some URLs from schedules• Assigns URLs to ‘layers / tiers’ for crawling schedules• Scheduler checks URLs for ‘importance’, ‘boost factor’ candidacy,
‘probability of modification’• Budgets are allocated to IPs and shared amongst domains there
JOBS

• ‘Ranks nothing at all’• Takes a list of URLs to crawl from URL Scheduler• Runs errands & makes deliveries for the URL server, indexer /
ranking engine and logs• Makes notes of outbound linked pages and additional links
for future crawling• Follows directives (robots) and takes ‘hints’ when crawling• Tells tales of URL accessibility status, server response codes,
notes relationships between links and collects content checksums (binary data equivalent of web content) for comparison with past visits by history and link logs
• Will go beyond the crawl schedule if it finds something more important than URLs scheduled
GOOGLEBOT - CRAWLERJOBS

WHAT MAKES THE DIFFERENCE BETWEEN BASE LAYER AND ‘REAL TIME’ SCHEDULE ALLOCATION?

CONTRIBUTING FACTORS
1. Page Importance (which may include PageRank)
3. Soft limits and hard crawl limits
4. Host load capability & past site performance (speed and access) (IP level and domain level within)
2. Hints (max and min)
5. Probability / predictability of ‘CRITICALMATERIAL’ change + importance crawl period

1 - PAGE IMPORTANCE - Page importance is the importance of a page independent of a query
• Location in Site (e.g. home page more important than parameter 3 level output)
• PageRank• Page type / file type• Internal PageRank• Internal Backlinks (IBP)• In-‐site Anchor Text Consistency• Relevance (content, anchors and elements) to a
topic (ONTOLOGY) (Similarity Importance)• Directives from in-‐page robot and robots.txt
management• Parent quality brushes off on child page qualityIMPORTANT PARENTS LIKELY SEEN TO HAVE IMPORTANT CHILD PAGES

2 - HINTS - ’MIN’ HINTS & ’MAX’ HINTS
MIN HINT / MIN HINT RANGES• e.g. Programmatically generated
content which changes content checksum on load
• Unimportant duplicate parameter URLs
• Canonicals• Rel=next, rel=prev• HReflang• Duplicate content• SpammyURLs?• Objectionable content
MAX HINT / MAX HINT RANGES• CHANGE CONSIDERED ‘CRITICAL
MATERIAL CHANGE’ (useful to users e.g. availability, price) & / or improved site sections or change to IMPORTANT but infrequently changing content?
• Important pages / page range updates
E.G. rel="prev" and rel="next" act as hints to Google, not absolute directives
https://support.google.com/webmasters/answer/1663744?hl=en&ref_topic=4617741

3 - HARD AND SOFT LIMITS ON CRAWLING
If URLs are discovered during crawling that are more important than those scheduled to be crawled then Googlebot can go beyond its schedule to include these up to a hard crawl limit
‘Soft’ crawl limit is set (Original schedule)
‘Hard’ crawl limit is set (E.G. 130% of schedule)
FOR IMPORTANT FINDINGS

4 – HOST LOAD CAPACITY / PAST SITE PERFORMANCE
Googlebot has a list of URLs to crawl
Naturally, if your site is fast that list can be crawled quicker
If Googlebotexperiences 500s e.g. she will retreat & ‘past performance’ is noted
If Googlebotdoesn’t get ‘round the list’ you may end up with ‘overdue’ URLs to crawl

SO WHAT?
5 - CHANGE

Not all change is considered equal
5 - CHANGE

WHAT MATTERS IS ‘CRITICAL MATERIAL
CHANGE’

Features are weighted for change importance to user (price > colour e.g.)
5 - CHANGE

What is the ‘importance crawl period’ set for your URL?
5 - CHANGESO WHAT?

Is your URLs ‘change rate’ much higher than your ‘importance crawl period’?
5 - CHANGE

Random shuffling is useless if your URL is unimportant
5 - CHANGE “shuffle($variable), rand($variable)” === ‘FAIL on ‘CRITICAL MATERIAL CHANGE’

In a different order
MEH “shuffle($variable), rand($variable)” === ‘FAIL on ‘CRITICAL MATERIAL CHANGE’

Your URL may even trip ‘hints’…
And get visited less
5 - CHANGE “I know your game buddy”

5 - CHANGEGUESS WHAT? -‐ CHANGE ON THE CNN HOME PAGE IS KIND OF MORE IMPORTANT THAN YOUR ‘ABOUT US’ PAGE
#WHOKNEW?
Hence – ‘Real Time API’ for ‘news sites’ to avoid ‘The Embarrassment Factor’

• There are many dynamic sites with low importance pages
changing frequently – SO WHAT• Constantly changing your page just to get Googlebot
back won’t work if the page is low importance (crawl importance period < change rate) POINTLESS
• Hints are employed to determine pages which simply change the content checksum with every visit
• Don’t just try to randomise things to catch Googlebot’seye
• That counter or clock you added probably isn’t going to help you get more attention, nor random or shuffle
• Change on some types of pages is more important than other pages (e.g. Home page CNN > SME about us page)
5 - CHANGE

• Current capacity of the web crawling system is high• Your URL has a high ‘importance score’• Your URL is in the real time (HIGH IMPORTANCE), daily crawl
(LESS IMPORTANT) or ‘active’ base layer segment (UNIMPORTANT BUT SELECTED)
• Your URL changes a lot with CRITICAL MATERIAL CONTENT change (AND IS IMPORTANT)
• Probability and predictability of CRITICAL MATERIAL CONTENT change is high for your URL (AND URL IS IMPORTANT)
• Your website speed is fast and Googlebot gets the time to visit your URL on its bucket list of scheduled URLs that visit
• Your URL has been ‘upgraded’ to a daily or real time crawl layer as it’s importance is detected as raised
• History logs and URL Scheduler ’learn’ together
FACTORS AFFECTING GOOGLEBOT HIGHER VISIT FREQUENCY

• Current capacity of web crawling system is low• Your URL has been detected as a ‘spam’ URL• Your URL is in an ‘inactive’ base layer segment (UNIMPORTANT)• Your URLs are ‘tripping hints’ built into the system to detect non-‐
critical change dynamic content• Probability and predictability of critical material content change is
low for your URL• Your website speed is slow and Googlebot doesn’t get the time to
visit your URL• Your URL has been ‘downgraded’ to an ‘inactive’ base layer
(UNIMPORTANT) segment• Your URL has returned an ‘unreachable’ server response code
recently• In-‐page robots management or robots.txt send wrong signals
FACTORS AFFECTING LOWER GOOGLEBOT VISIT FREQUENCY

GET MORE CRAWL BY ‘TURNING GOOGLEBOT’S HEAD’ – MAKE YOUR URLs MORE IMPORTANT AND ‘EMPHASISE’ IMPORTANCE

• Hard limits and soft limits• Follows ‘min’ and ‘max’ Hints• If she finds something important she will go beyond a
scheduled crawl (SOFT LIMIT) to seek out importance (TO HARD LIMIT)
• You need to IMPRESS Googlebot• If you ‘bore’ Googlebot she will return to boring URLs less
(e.g. with pages all the same (duplicate content) or dynamically generated low usefulness content)
• If you ’delight’ Googlebot she will return to delightful URLs more (they became more important or they changed with ‘CRITICAL MATERIAL CHANGE’)
• If she doesn’t get her crawl completed you will end up with an ‘overdue’ list of URLs to crawl
GOOGLEBOT DOES AS SHE’S TOLD –WITH A FEW EXCEPTIONS

• Your URL became more important and achieved a higher ‘importance score’ via increased PageRank
• Your URL became more important via increased IB(P) (INTERNAL BACKLINKS IN OWN SITE) relative to other URLs within your site (You emphasised importance)
• You made the URL content more relevant to a topic and improved the importance score
• The parent of your URL became more important (E.G. IMPROVED TOPIC RELEVANCE (SIMILARITY), PageRank OR local (in-‐site) importance metric)
• YOUR ‘IMPORTANCE SCORE’ OF SOME URLS EXCEEDED THE ‘IMPORTANCE SOFT LIMIT THRESHOLD’ SO THAT IT IS INCLUDED FOR CRAWLING WHILST BEING VISITED UP TO A POINT OF ‘HARD LIMIT’ CRAWLING (E.G. 130% OF SCHEDULED CRAWLING)
GETTING MORE CRAWL BY IMPROVING PAGE IMPORTANCE

HOW DO WE DO THIS?

INCREASE URL ‘IMPORTANCE’

AS BASE LAYER URL’S BECOME MORE IMPORTANT THEY WILL BE CRAWLED MORE… AND

47GOOD THINGS HAPPEN 40,000+ towns, cities and villages across the UK multiplied by X site categories (THAT’S A LOT OF LONG TAIL QUERY VOLUME)

THEY ARE PROMOTED TO THE ’DAILY OR REAL TIME’ CRAWL LAYER

TO DO - FIND GOOGLEBOTAUTOMATE SERVER LOG RETRIEVAL VIA CRON JOB
grep Googlebotaccess_log>googlebot_access.txt
ANALYSE THE LOGS

LOOK THROUGH SPIDER-EYESPREPARE TO BE HORRIFIED
Incorrect URL header response codes 301 redirect chainsOld files or XML sitemaps left on server from years agoInfinite/ endless loops (circular dependency)On parameter driven sites URLs crawled which produce same outputAJAX content fragments pulled in aloneURLs generated by spammersDead image files being visitedOld CSS files still being crawled and loading EVERYTHINGYou may even see ’mini’ abandoned projects within the siteLegacy URLs generated by long forgotten .htaccess regex pattern matchingGooglebot hanging around in your ‘ever-‐changing’ blog but nowhere else

URL CRAWL FREQUENCY ’CLOCKING’
Spreadsheet provided by @johnmu during Webmaster Hangout -‐ https://goo.gl/1pToL8
Identify your ‘real time’, ‘daily’ and ‘base layer’ URLs-‐ ARE THEY THE ONES YOU WANT THERE? WHAT IS BEING SEEN AS UNIMPORTANT?
NOTE GOOGLEBOT
Do you recognise all theURLs and URL ranges thatAre appearing?If not… Why not?

IMPROVE & EMPHASISE PAGE IMPORTANCE• Cross modular internal linking• Canonicalization• Important URLs in XML sitemaps• Anchor text target consistency (but not spammyrepetition of anchors
everywhere (it’s still output))• Internal links in right descending order – emphasise IMPORTANCE• Reduce boiler plate content and improve relevance of content and elements to
specific topic (if category) / product (if product page) / subcategory (if subcategory)
• Reduce duplicate content parts of page to allow primary targets to take ’IMPORTANCE’
• Improve parent pages to raise IMPORTANCE reputation of the children rather than over-‐optimising the child pages and cannibalising the parent.
• Improve content as more ‘relevant’ to a topic to increase ‘IMPORTANCE’ and get reassigned to a different crawl layer
• Flatten ‘architectures’• Avoid content cannibalisation• Link relevant content to relevant content• Build strong highly relevant ‘hub’ pages to tie together strength & IMPORTANCE

LOCAL ‘IMPORTANCE’ (IBP)

LOCAL IMPORTANCE IN DESCENDING ORDER (ROUGHLY)
https://support.google.com/webmasters/answer/138752?hl=en

Most Important Page 1
Most Important Page 2
Most Important Page 3
IS THIS YOUR BLOG?? HOPE NOT
#BIGSITEPROBLEMS – INTERNAL BACKLINKS SKEWED
IMPORTANCE DISTORTED BY DISPROPORTIONATE INTERNAL LINKING -LOCAL IB (P) – INTERNAL BACKLINKS

THE PARENTS REPUTATION BRUSHES OFF ON THE KIDS
Cat Cat
Root
Sub Sub Sub Sub
P P P P P P P P P P P
MAKE CATEGORY AND SUBCATEGORY PARENTS AWESOME
PRODUCT PAGES FROM AWESOME PARENT CATEGORIES BECOME MORE IMPORTANT

OR MAKE AN AWESOME ‘FAMILY GATHERING’ OF HIGHLY RELATED ‘NEEDS MET’ CONTENT IN A ‘HUB’
FAQ GUIDES
HELP HUB
C C FF T T G G S S S
MAKE AWESOMEHUB PAGES – MAKE AWESOME ‘BRIDGES’ TO SIGNAL IMPORTANCE
IDENTIFY ‘NEEDS’ AND TARGET A STARTING ‘HUB’ PAGE TO CONNECT RELATED ‘BROTHERS, SISTERS, AUNTIES, UNCLES & GRANNY URLS
SUPPORT TEAM
TUTORIALSFIND A LIVE CLASS
GET STARTED

AWESOMENESS ON CATEGORY PAGES IS NOT JUST REWRITING COMPETITOR CONTENT
Cat Cat
Root
Sub Sub Sub Sub
P P P P P P P P P P P
PRODUCT PAGES FROM AWESOME PARENT CATEGORIES BECOME MORE IMPORTANT
’ADD VALUE’

WHERE IS THE ‘CRITICAL MATERIAL DIFFERENCE’??

ADD ‘CRITICAL MATERIAL
VALUE’WHAT IS MISSING?

ADD ‘CRITICAL MATERIAL DIFFERENCE’
HELP HUB HERO
What more can you add to the existing offerings out there?
What is the user seeking now?
Answer questions Engage community Wow transactional

EMPHASISE IMPORTANCEVIA SIBLING VOTES
Cat Cat
Root
Sub Sub Sub Sub
P P P P P P P P P P P

TRIP ‘MAX HINTS’ NOT ‘MIN HINTS’
“Hold the diary… I found some unexpected stuff which is more important than I planned to see today… I’ll be here a while longer”

BUT… BE CAREFUL

WRONG TARGET RANKING

SKEWED AWESOMENESS

ADDRESS SKEWED INTERNAL LINKING VIA ‘AUNTIE & UNCLE INTERNALLINKING’
Cat Cat
Root
Sub Sub Sub Sub
P P P P P P P P P P P
AT A ‘TEMPLATE LEVEL’
MOST INTERNAL LINKS

USE COMPOUNDING ‘HELP’, ‘HUB’, ‘HERO’FAMILY MEMBERS
Hero (Transactional & Brand hero subs)
Hub
Root theme
Sub Sub
Sub Sub
P P P P P P
F F F F F
Intent
Sub
Compounding Hero ‘Intent’
Sell product (convince)
Entertain / inspire
F
Compounding Hub ‘Intent’
Help
Sub Sub SubSub Sub
Compounding Help‘Intent’
Inform (Answer questions)
K K K K K K K
STRONG LOCAL IMPORTANCE

EMPHASISE IMPORTANCE WISELY
USE CUSTOMXMLSITEMAPS
E.G. XML UNLIMITEDSITEMAP GENERATOR
PUT IMPORTANT URLS IN HERE
IF EVERYTHING IS IMPORTANT THEN IMPORTANCE IS NOT DIFFERENTIATED

KEEP CUSTOM SITEMAPS ‘CURRENT’ AUTOMATICALLY
AUTOMATEUPDATESWITH CRON JOBS OR WEB CRON JOBS
IT’S NOT AS TECHNICAL AS YOU MAY THINK – USE WEB CRON JOBS

BE ‘PICKY’ ABOUT WHAT YOU INCLUDE IN XML SITEMAPS
EXCLUDE ANDINCLUDE CRAWLPATHS IN XML SITEMAPS TO EMPHASISEIMPORTANCE

IF YOU CAN’T IMPROVE - EXCLUDE (VIA NOINDEX) FOR NOW • YOU’RE OUT FOR NOW
• When you improve you can come back in
• Tell Googlebot quickly that you’re out (via temporary XML sitemap inclusion)
• But ‘follow’ because there will be some relevance within these URLs
• Include again when you’ve improved
• Don’t try to canonicalizeme to something in theindex

OR REMOVE – 410 GONE(IF IT’S NEVER COMINGBACK)
http://faxfromthefuture.bandcamp.com/track/410-‐gone-‐acoustic-‐demo
EMBRACE THE ‘410 GONE’
There’s Even A SongAbout It

#BIGSITEPROBLEMS – LOSE THE INDEX BLOAT
LOSE THE BLOAT TO INCREASE THE CRAWLNo. of unimportant URLs indexed extend far beyond the available importance crawl threshold allocation

Tags: I, must, tag, this, blog, post, with, every, possible, word, that, pops, into, my, head, when, I, look, at, it, and, dilute, all, relevance, from, it, to, a, pile, of, mush, cow, shoes, sheep, the, and, me, of, it
Image Credit: Buzzfeed
Creating ‘thin’ content and Even more URLs to crawl
#BIGSITEPROBLEMS - LOSE THE CRAZY TAG MAN

Most Important Page 1
Most Important Page 2
Most Important Page 3
IS THIS YOUR BLOG?? HOPE NOT
#BIGSITEPROBLEMS – INTERNAL BACKLINKS SKEWED
IMPORTANCE DISTORTED BY DISPROPORTIONATE INTERNAL LINKING -LOCAL IB (P) – INTERNAL BACKLINKS

Optimize Everything: I must optimize ALL the pages across a category descendants for the same terms as my primary target category page so that each of them is of almost equal relevance to the target page and confuse crawlers as to which isthe important one. I’ll put them all in a sitemap as standard too just for good measure.
Image Credit: Buzzfeed
HOW CAN SEARCH ENGINESKNOW WHICH IS MOST IMPORTANTTO A TOPIC IF ‘EVERYTHING’ ISIMPORTANT??
#BIGSITEPROBLEMS - WARNING SIGNS – LOSE THE ‘MISTER OVER-OPTIMIZER’
‘OPTIMIZE ALL THE THINGS’

Duplicate Everything: I must have a massive boiler plate area in the footer, identical sidebars and a massive mega menu with all the same output in sitewide. I’ll put very little unique content into the page body and it will also look very much like it’s parents and grandparents too. From time to time I’ll outrank my parents and grandparent pages but ‘Meh’…
Image Credit: Buzzfeed
HOW CAN SEARCH ENGINESKNOW WHICH IS MOST IMPORTANTPAGE IF ALL IT’S CHILDREN AND GRANDCHILDREN ARE NEARLY THE SAME??
#BIGSITEPROBLEMS - WARNING SIGNS – LOSE THE ‘MISTER DUPLICATER’
‘DUPLICATE ALL THE THINGS’

IMPROVE SITE PERFORMANCE - HELP GOOGLEBOT GET THROUGH THE ‘BUCKET LIST’ – GET FAST AND RELIABLE
Avoid wasting time on ‘overdue-‐URL’ crawling (E.G. Send correct response codes, speed up your site, etc)
8,666,964 B1
½ time
> 2 x page crawl p/day
Added to Cloudflare CDNWatch out for CDNsThough – It’s a shared IP (shared budget / capacity ??)

GOOGLEBOT GOES WHERE THE ACTION IS
USE ‘ACTION’ WISELY
DON’T TRY TO TRICK GOOGLEBOT BY FAKING ‘FRESHNESS’ ON LOW IMPORTANCE PAGES – GOOGLEBOT WILL REALISE
UPDATE IMPORTANT PAGES OFTEN
NURTURE SEASONAL URLs TO GROW IMPORTANCE WITH FRESHNESS (regular updates) & MATURITY (HISTORY)
DON’T TURN GOOGLEBOT’S HEAD INTO THE WRONG PLACES
Image Credit: Buzzfeed
’GET FRESH’ AND STAY ‘FRESH’
‘BUT DON’T TRY TO FAKE FRESH & USE FRESH WISELY’

IMPROVE TO GET THE HARD LIMITS ON CRAWLING
By improving yourURL importance on an ongoing basis viaIncreased pagerank, content improvements (e.g. quality hub pages), internal link strategies, IB (P), restructuring,You can get the ‘hard limit’ or get visited more generally
CAN IMPROVING YOUR SITE HELP TO ‘OVERRIDE’ SOFT LIMIT CRAWL PERIODS SET?

YOU THINK IT DOESN’T MATTER… RIGHT?
YOU SAY…
” GOOGLE WILL WORK IT OUT”
”LET’S JUST MAKE MORE CONTENT”

WRONG – ‘CRAWL TANK’ IS UGLY
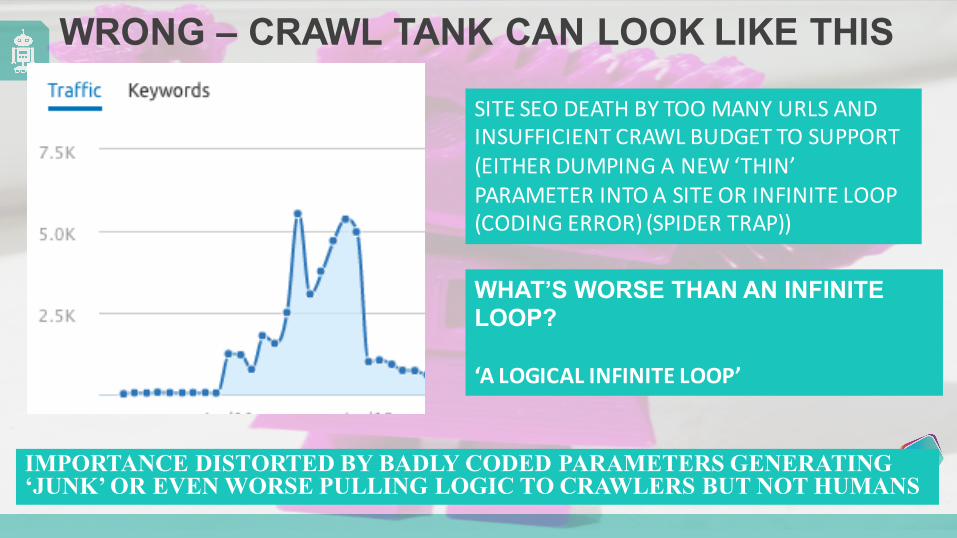
WRONG – CRAWL TANK CAN LOOK LIKE THIS
SITE SEO DEATH BY TOO MANY URLS AND INSUFFICIENT CRAWL BUDGET TO SUPPORT (EITHER DUMPING A NEW ‘THIN’ PARAMETER INTO A SITE OR INFINITE LOOP (CODING ERROR) (SPIDER TRAP))
WHAT’S WORSE THAN AN INFINITE LOOP?
‘A LOGICAL INFINITE LOOP’
IMPORTANCE DISTORTED BY BADLY CODED PARAMETERS GENERATING ‘JUNK’ OR EVEN WORSE PULLING LOGIC TO CRAWLERS BUT NOT HUMANS

WRONG –SITE DROWNED
- IN IT’SOWN SEA OF UNIMPORTANT URLS

VIA ‘EXPONENTIAL URL UNIMPORTANCE’Your URLs exponentially confirmed unimportant with each iterative crawl visit to other similar or duplicate content checksum URLs. Fewer and fewer internal links and ‘thinner and thinner’ relevant content.
MULTPLE RANDOM URLs competing for same query confirm irrelevance of all competing in-‐site URLs with no dominant single relevant IMPORTANT URL

WRONG – ‘SENDING WRONG SIGNALS TO GOOGLEBOT’ COSTS DEARLY
(Source:Sistrix)
“2015 was the year where website owners managed to be mostly at fault, all by themselves” (Sistrix 2015 Organic Search Review -‐2016)

WRONG - NO-ONE IS EXEMPT
(Source:Sistrix)
“It doesn’t matter how big your brand is if you ‘talk to the spider’ (Googlebot) wrong ” – You can still ‘tank’

WRONG – GOOGLE THINKS SEOS SHOULD UNDERSTAND CRAWL BUDGET

”EMPHASISE IMPORTANCE”“Make sure the right URLs get on Googlebot’smenu and increase URL
importance to build Googlebot’s appetite for your site more”
Dawn Anderson @ dawnieando
SORT OUT CRAWLING

TWITTER -‐ @dawnieandoGOOGLE+ -‐ +DawnAnderson888LINKEDIN -‐ msdawnandersonTHANK YOUDawn Anderson @ dawnieando

REFERENCES
Efficient Crawling Through URL Ordering (Page et al) -‐ http://oak.cs.ucla.edu/~cho/papers/cho-‐order.pdfCrawl Optimisation (Blind Five Year Old – A J Kohn -‐ @ajkohn) http://www.blindfiveyearold.com/crawl-‐optimizationScheduling a recrawl (Auerbach) -‐ http://www.google.co.uk/patents/US8386459Scheduler for search engine crawler (Zhu et al) -‐ http://www.google.co.uk/patents/US8042112Efficient crawling through URL ordering (Page et al) -‐ http://oak.cs.ucla.edu/~cho/papers/cho-‐order.pdfGoogle Explains Why The Search Console Reporting Is Not Real Time (SERoundtable) https://www.seroundtable.com/google-‐explains-‐why-‐the-‐search-‐console-‐has-‐reporting-‐delays-‐21688.htmlCrawl Data Aggregation Propagation (Mueller) -‐ https://goo.gl/1pToL8Matt Cutts Interviewed By Eric Enge -‐ https://www.stonetemple.com/matt-‐cutts-‐interviewed-‐by-‐eric-‐enge-‐2/Web Promo Q and A with Google’s Andrev Lippatsev -‐https://searchenginewatch.com/2016/04/06/webpromos-‐qa-‐with-‐googles-‐andrey-‐lipattsev-‐transcript/Google Number 1 SEO Advice – Be Consistent -‐ https://www.seroundtable.com/google-‐number-‐one-‐seo-‐advice-‐be-‐consistent-‐21196.html

REFERENCESInternet Live Stats -‐ http://www.internetlivestats.com/total-‐number-‐of-‐websites/Scheduler for search engine crawler Google PatentUS 8042112 B1, (Zhu et al) -‐ https://www.google.com/patents/US8707313Managing items in crawl schedule – Google Patent (Alpert) http://www.google.ch/patents/US8666964Document reuse in a search engine crawler -‐ Google Patent (Zhu et al)https://www.google.com/patents/US8707312Web crawler scheduler that utilizes sitemaps (Brawer et al) -‐http://www.google.com/patents/US8037054Distributed crawling of hyperlinked documents (Dean et al) -‐http://www.google.co.uk/patents/US7305610Minimizing visibility of stale content (Carver) -‐http://www.google.ch/patents/US20130226897

REFERENCEShttps://www.sistrix.com/blog/how-‐nordstrom-‐bested-‐zappos-‐on-‐google/https://www.xml-‐sitemaps.com/generator-‐demo/