bringing code to the data: from mysql to rocksdb for high volume searches
TRANSCRIPT

Bringing code to the data: from MySQL to RocksDB for high volume searches
Ivan Kruglov | Senior Developer [email protected]
Percona Live 2016 | Santa Clara, CA

Agenda
● Problem domain ● Evolution of search ● Architecture ● Results ● Conclusion

Problem domain

Search at Booking.com
● Input ● Where – city, country,
region ● When – check-in date ● How long – check-out date ● What – search options
(stars, price range, etc.) ● Result
● Available hotels

Inventory vs. Availability
● Inventory is what hotels give Booking.com ● hotel/room inventory
● Availability = search + inventory ● under which circumstances one can book this room and at what price
● Availability >>> Inventory

[Booking.com] works with approximately 800,000 partners, offering an average of 3 room types, 2+ rates, 30 different length of stays across 365 arrival days, which yields something north of
52 billion price points at any given time.
http://www.forbes.com/sites/jonathansalembaskin/2015/09/24/booking-com-channels-its-inner-geek-toward-engagement/#2dbc6f6326b2

Evolution of search

Normalized availability (pre 2011)
● classical LAMP stack ● P – stands for Perl
● normalized availability ● write optimized dataset ● search request handled by single
worker ● too much of computation complexity ● large cities become unsearchable

Pre-computed availability (2011+)
● materialized == de-normalized, flatten dataset ● aim for constant time fetch ● read (AV) and write (inv)
optimized datasets

Pre-computed availability (2011+)
● materialized == de-normalized, flatten dataset ● aim for constant time fetch ● read (AV) and write (inv)
optimized datasets
● single worker ● as inventory grows still have
problems with big searches
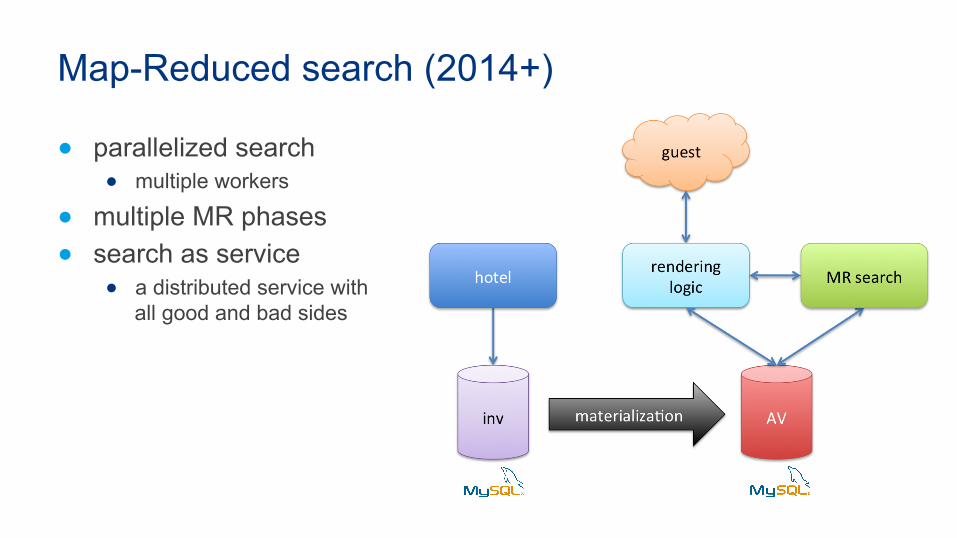
Map-Reduced search (2014+)
● parallelized search ● multiple workers
● multiple MR phases ● search as service
● a distributed service with all good and bad sides

Map-Reduced search (2014+)
● parallelized search ● multiple workers
● multiple MR phases ● search as service
● a distributed service with all good and bad sides
● world search ~20s ● overheads
● IPC, serialization
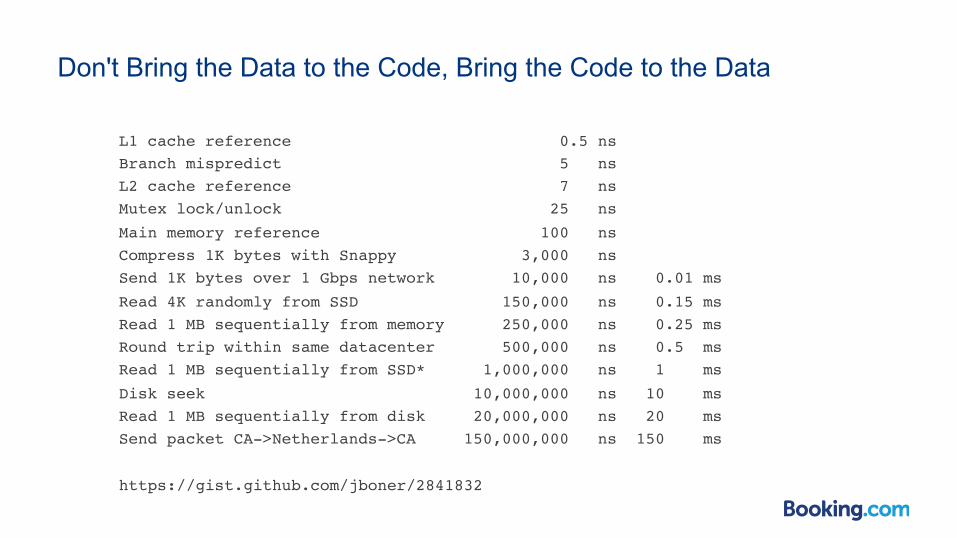
Don't Bring the Data to the Code, Bring the Code to the Data
L1 cache reference 0.5 nsBranch mispredict 5 nsL2 cache reference 7 nsMutex lock/unlock 25 ns
Main memory reference 100 nsCompress 1K bytes with Snappy 3,000 nsSend 1K bytes over 1 Gbps network 10,000 ns 0.01 ms
Read 4K randomly from SSD 150,000 ns 0.15 msRead 1 MB sequentially from memory 250,000 ns 0.25 msRound trip within same datacenter 500,000 ns 0.5 msRead 1 MB sequentially from SSD* 1,000,000 ns 1 ms
Disk seek 10,000,000 ns 10 msRead 1 MB sequentially from disk 20,000,000 ns 20 msSend packet CA->Netherlands->CA 150,000,000 ns 150 ms
https://gist.github.com/jboner/2841832
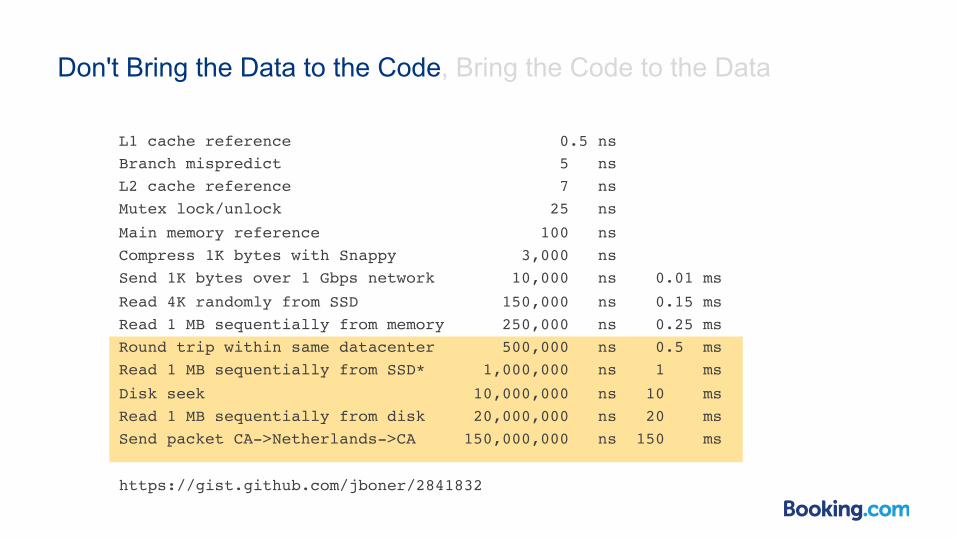
Don't Bring the Data to the Code, Bring the Code to the Data
L1 cache reference 0.5 nsBranch mispredict 5 nsL2 cache reference 7 nsMutex lock/unlock 25 ns
Main memory reference 100 nsCompress 1K bytes with Snappy 3,000 nsSend 1K bytes over 1 Gbps network 10,000 ns 0.01 ms
Read 4K randomly from SSD 150,000 ns 0.15 msRead 1 MB sequentially from memory 250,000 ns 0.25 msRound trip within same datacenter 500,000 ns 0.5 msRead 1 MB sequentially from SSD* 1,000,000 ns 1 ms
Disk seek 10,000,000 ns 10 msRead 1 MB sequentially from disk 20,000,000 ns 20 msSend packet CA->Netherlands->CA 150,000,000 ns 150 ms
https://gist.github.com/jboner/2841832

L1 cache reference 0.5 nsBranch mispredict 5 nsL2 cache reference 7 nsMutex lock/unlock 25 ns
Main memory reference 100 nsCompress 1K bytes with Snappy 3,000 nsSend 1K bytes over 1 Gbps network 10,000 ns 0.01 ms
Read 4K randomly from SSD 150,000 ns 0.15 msRead 1 MB sequentially from memory 250,000 ns 0.25 msRound trip within same datacenter 500,000 ns 0.5 msRead 1 MB sequentially from SSD* 1,000,000 ns 1 ms
Disk seek 10,000,000 ns 10 msRead 1 MB sequentially from disk 20,000,000 ns 20 msSend packet CA->Netherlands->CA 150,000,000 ns 150 ms
https://gist.github.com/jboner/2841832
Don't Bring the Data to the Code, Bring the Code to the Data

Map-Reduce + local AV (2015+) ● SmartAV – smart availability ● combined MR search with
local database
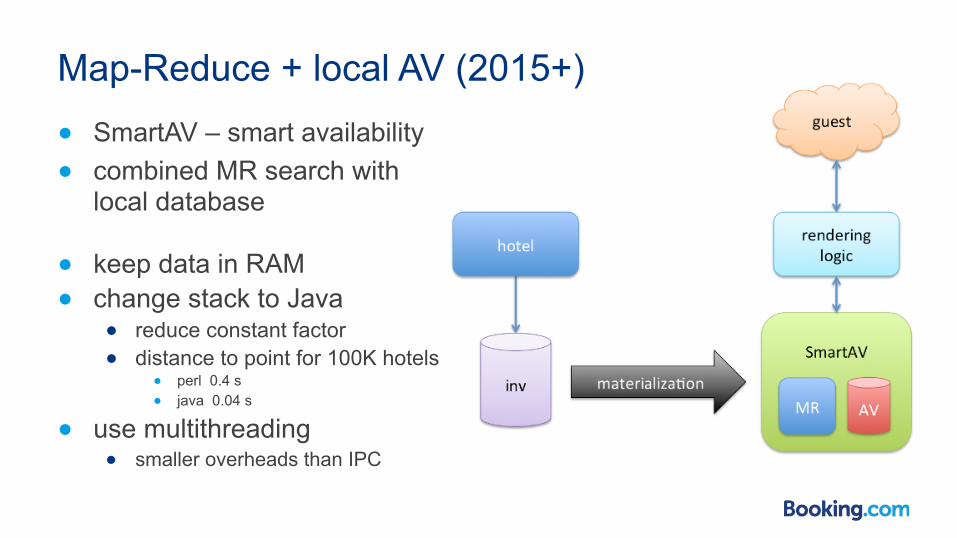
Map-Reduce + local AV (2015+) ● SmartAV – smart availability ● combined MR search with
local database
● keep data in RAM ● change stack to Java
● reduce constant factor ● distance to point for 100K hotels
● perl 0.4 s ● java 0.04 s
● use multithreading ● smaller overheads than IPC

Architecture

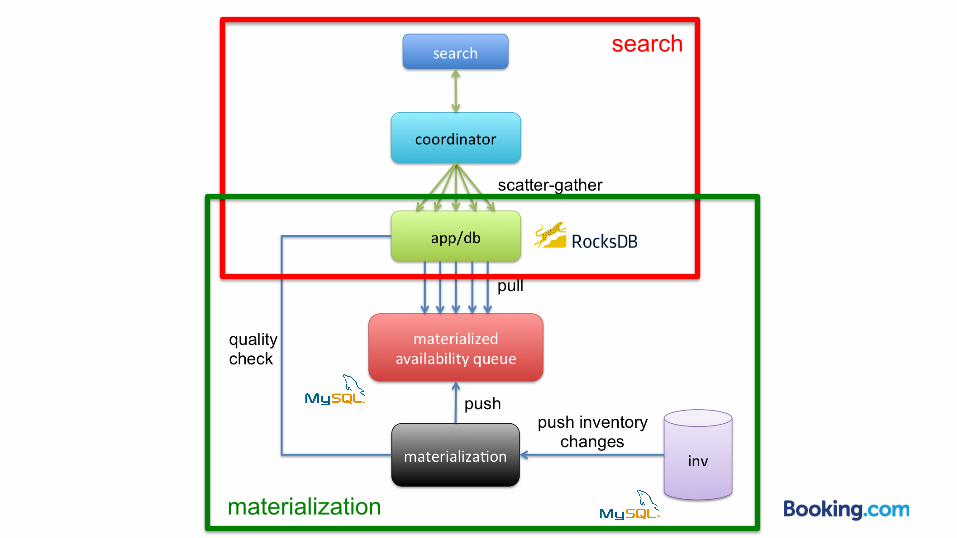
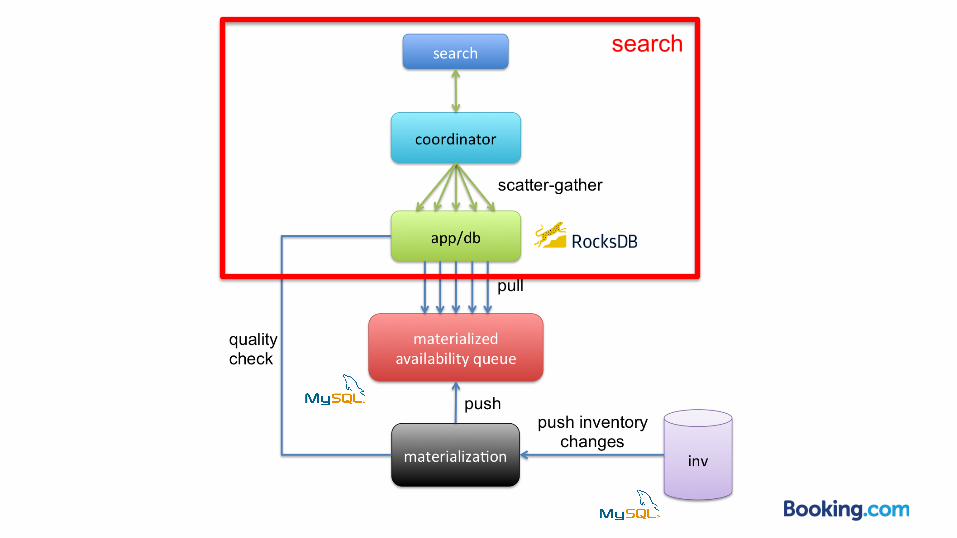
search
materialization
search
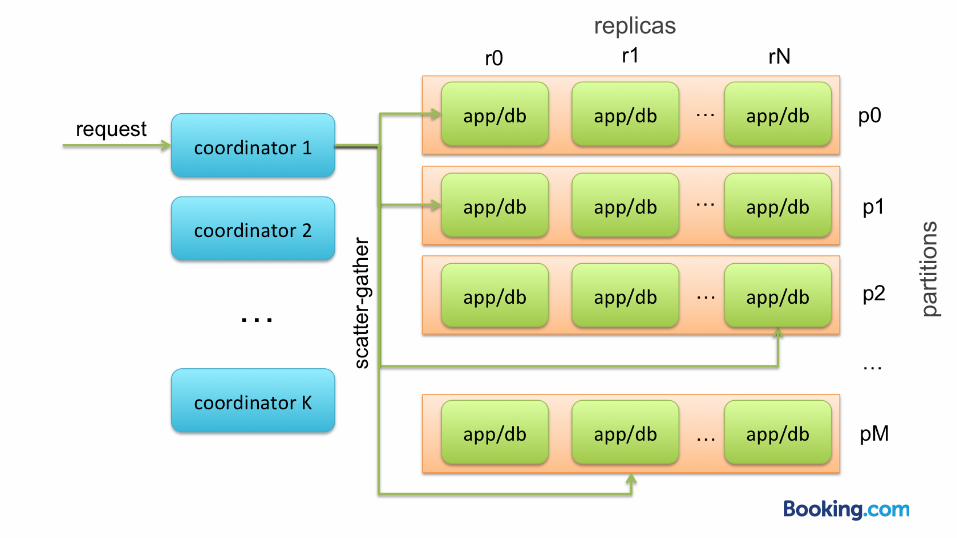
replicas
parti
tions

Coordinator
● acts as proxy ● knows cluster state ● query randomly chosen replica in all partitions
(scatter-gather) ● retry if necessary ● merge partial results into final result
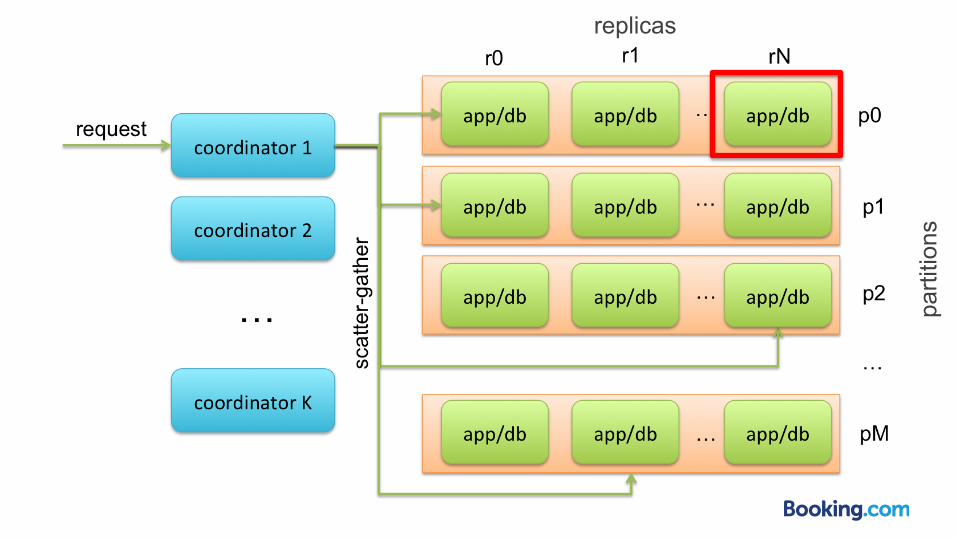
replicas
parti
tions


Inverted indexes ● dataset
| 0 | hello world || 1 | small world || 2 | goodbye world |
{ "hello" => [ 0 ], "goodbye" => [ 2 ], "small" => [ 1 ], "world" => [ 0, 1, 2 ] # must be sorted}
● query (hello OR goodbye) AND world([ 0 ] OR [ 2 ]) AND [ 0, 1, 2]
merge [ 0, 2 ]
● indexes for ufi, country, region, district and more

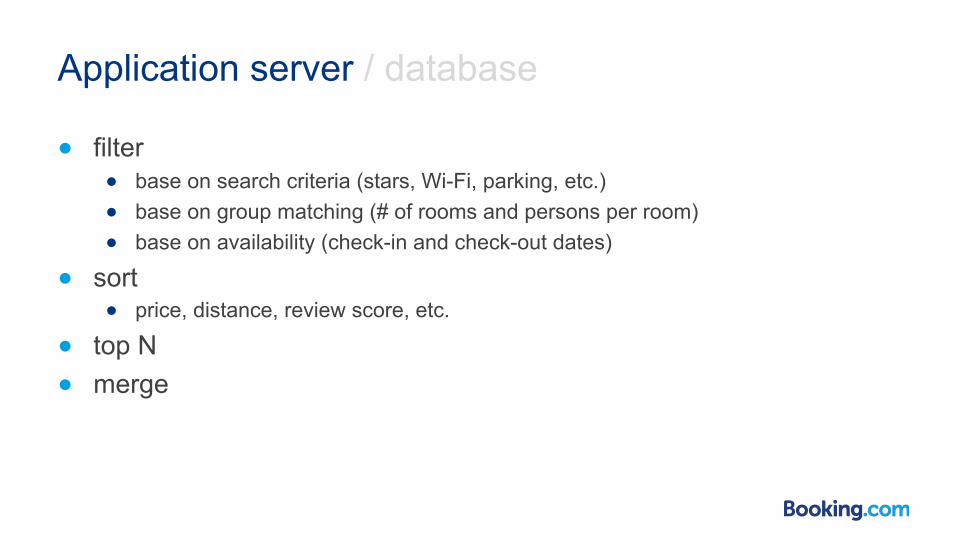
Application server / database
● filter ● base on search criteria (stars, Wi-Fi, parking, etc.) ● base on group matching (# of rooms and persons per room) ● base on availability (check-in and check-out dates)
● sort ● price, distance, review score, etc.
● top N ● merge

Application server / database
● data statically partitioned (modulo partitioning by hotel id) ● hotel data
● kept in RAM ● not persisted – easy enough to fetch and rebuild ● updated hourly
● availability data ● persisted ● real-time updates ● 1
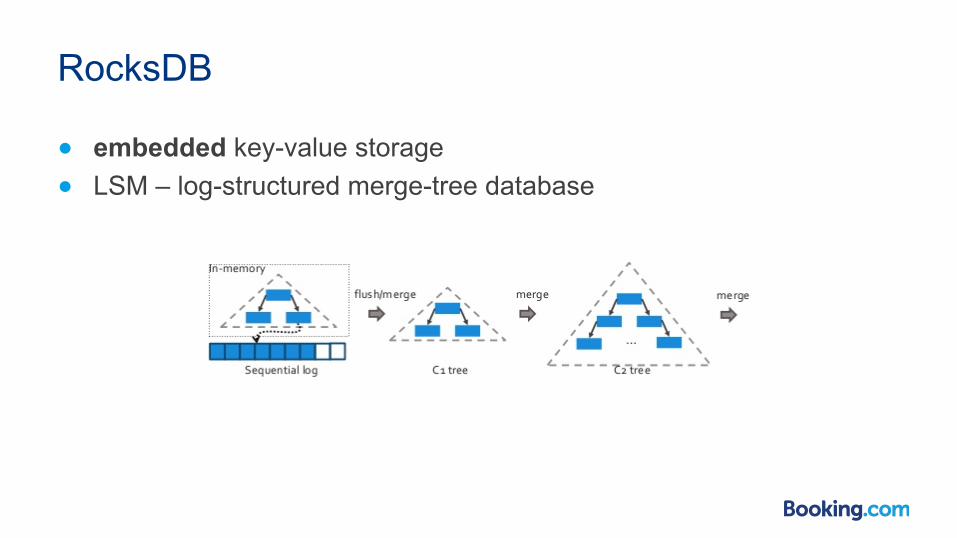
RocksDB
● embedded key-value storage ● LSM – log-structured merge-tree database

Why RocksDB?
● needed embedded key-value storage ● tried MapDB, Kyoto/Tokyo cabinet, leveldb
● reason of choice ● stable random read performance under random writes and compaction
(80% reads, 20% writes)
● works on HDDs with ~1.5K updates per second ● dataset fits in RAM (in-memory workload)

RocksDB use and configuration
● RocksDB v3.13.1 ● JNI + custom patch ● config is result of iterative try-and-
fail approach ● optimized for read-latency
● mmap reads ● compress on app level ● WriteBatchWithIndex for read-your-
own-writes ● multiple smaller DBs instead of one
big ● simplify purging old availability
config: .setDisableDataSync(false) .setWriteBufferSize(15 * SizeUnit.MB) .setMaxOpenFiles(-1) .setLevelCompactionDynamicLevelBytes(true) .setMaxBytesForLevelBase(160 * SizeUnit.MB) .setMaxBytesForLevelMultiplier(10) .setTargetFileSizeBase(15 * SizeUnit.MB) .setAllowMmapReads(true) .setMemTableConfig(newHashSkipListMemTableConfig()) .setMaxBackgroundCompactions(1) .useFixedLengthPrefixExtractor(8) .setTableFormatConfig(new PlainTableConfig() .setKeySize(8) .setStoreIndexInFile(true) .setIndexSparseness(8));

materialization
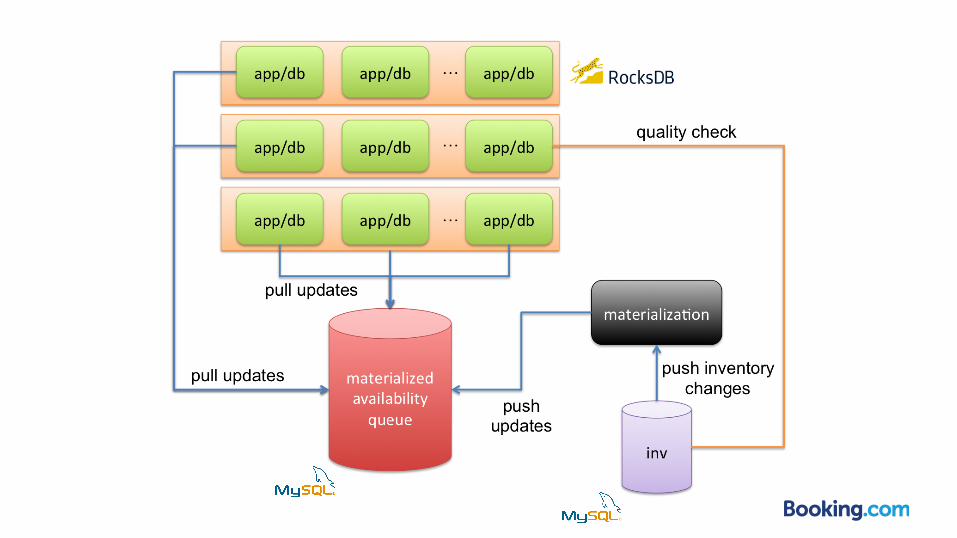
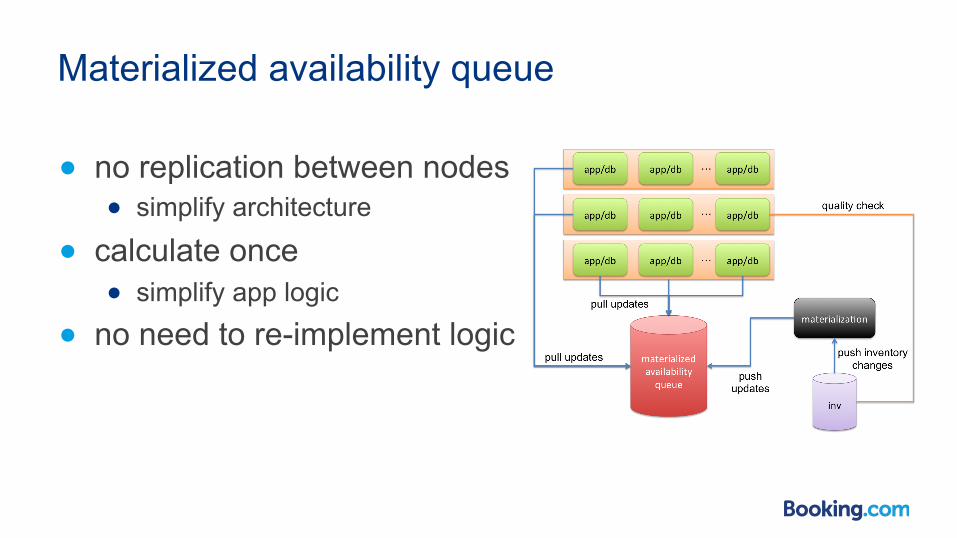
Materialized availability queue
● no replication between nodes ● simplify architecture
● calculate once ● simplify app logic
● no need to re-implement logic
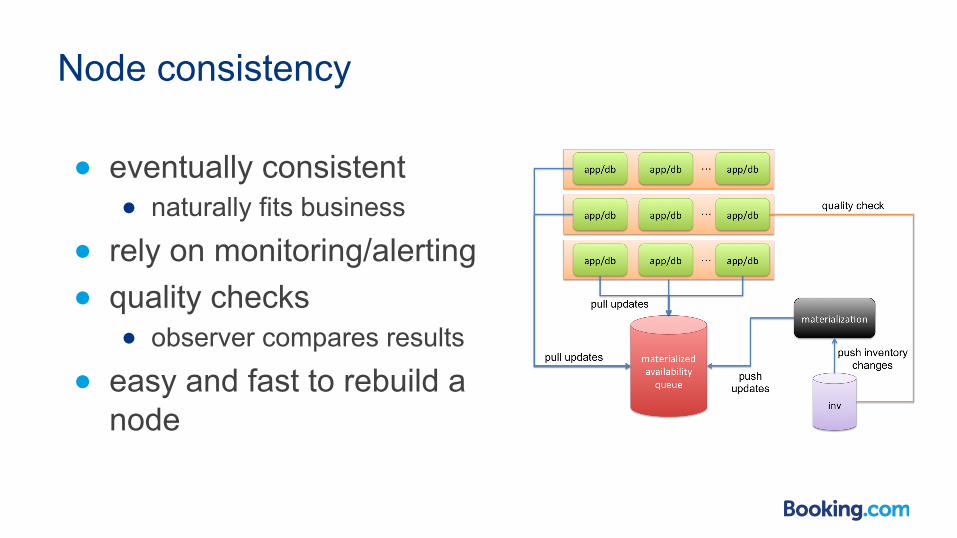
Node consistency
● eventually consistent ● naturally fits business
● rely on monitoring/alerting ● quality checks
● observer compares results
● easy and fast to rebuild a node

Results
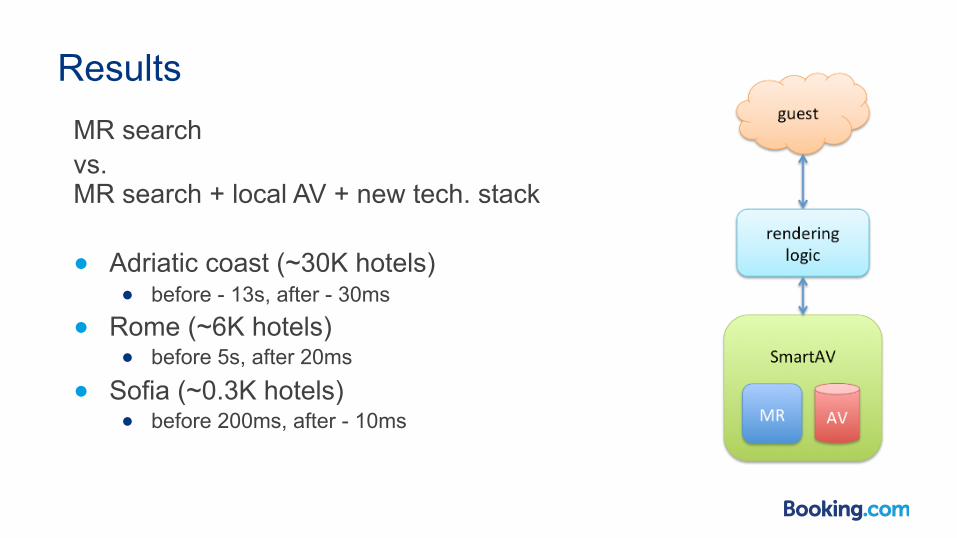
Results MR search vs. MR search + local AV + new tech. stack
● Adriatic coast (~30K hotels) ● before - 13s, after - 30ms
● Rome (~6K hotels) ● before 5s, after 20ms
● Sofia (~0.3K hotels) ● before 200ms, after - 10ms

Conclusion

Conclusion
1. search on top of normalized dataset in MySQL 2. search on top of pre-computed (flattened)
dataset in MySQL 3. MR-search on top of pre-computed dataset in
MySQL 4. MR-search on top of local dataset in RocksDB
(authoritative dataset in MySQL) ● full rewrite, but conceptually a small step ● locality matters ● technology stack (constant factor) matters
