bloom plseminar-sp15
TRANSCRIPT

<~ bloomJoe Hellerstein & BOOM Team
UC Berkeley

BOOM Team
peter alvaro neil conway bill marczak haryadi gunawi peter bailis sriram srinivasan
emily andrews andy hutchinson Joshua rosen
joe hellerstein ras bodik david maier alan fekete

And now, the 3-slide version of the talk...

<~ bloom is a language...
... for “disorderly” distributed computing because order is expensive ... with powerful program analysis
- CALM guidance on coordination - lineage-driven fault injection
... and concise, familiar syntax based on data-centric languages

What’s the Bloomin’ Problem?
1. All interesting systems are distributed systems
2. What is expensive? Coordination. Compute, storage and NW are very cheap.
3. What is hard? Programming. – Parallelism: i.e. consistency and coordination avoidance
– Partial Failure: i.e. fault tolerance with guarantees
Not your mom’s SW engineering concerns!

Key ideas in Bloom • Data-centric programming: all program state reified as data • Disorderly by default: both data and code • Local guarantees only; no built-in global abstractions. • Declarative syntax, asynchronous dataflow execution
DESIGN DECISIONS
• Static analysis of consistency (CALM) • Coordination synthesis (Blazes) • Lineage-driven fault injection (Molly) • GC for event logs (Edelweiss)
RESEARCH RESULTS AND PL TOOLS
Dedalus: A logic of space and time for sets and other semi-lattices The CALM Theorem: Consistency as Logical Monotonicity
FORMAL FOUNDATIONS
POSITIVE FALLOUT
• Concise, clear malleable code • Replicate, Scale Out, Compose
• Lineage of all state and messages • Dataflow, lineage & Lamport diagrams

Outline
• the costs of coordination • approaches to avoid coordination • Bloom • the CALM theorem • research results and sw engineering artifacts

Dancing Calmly With the Devil
Joe Hellerstein
ACM SOCC Keynote, 2014

I Can Give You Power
All the Compute you desire
All the Storage you desire
All the Data you desire

At What Cost?
The loss of illusions – Sequential computing
– Single-copy state
– Reliable components

Dancing with the Devil
• Coordination-Free Distributed Computing – Write sequential code for each processor
– Communicate without waiting
– Full-bandwidth computation
• Beware the risks: – Non-determinism
/inconsistency

Dancing with the Devil
• Coordination-Free Distributed Computing – Write sequential code for each processor
– Communicate without waiting
– Full-bandwidth computation
• Beware the risks: – Non-determinism
/inconsistency
– Split brain

Paying the Devil His Due
• Coordination: the last expensive thing – But maybe it’s wisest to pay?

Get Away, Satan!
• Coordination: the last expensive thing
“The first principle of successful scalability is to batter the consistency mechanisms down to a minimum, move them off the critical path, hide them in a rarely visited corner of the system, and then make it as hard as possible for application developers to get permission to use them” —James Hamilton (IBM, MS, Amazon)
[Birman, Chockler: “Toward a Cloud Computing Research Agenda”, LADIS09]
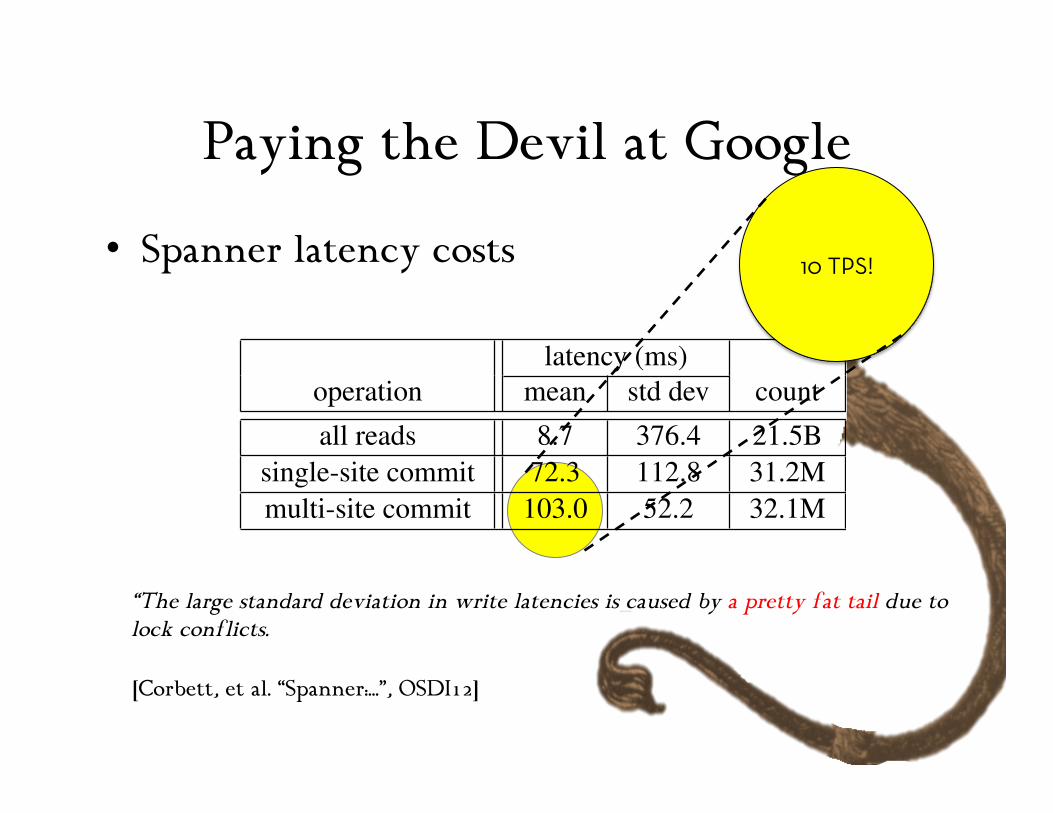
Paying the Devil at Google
• Spanner latency costs
“The large standard deviation in write latencies is caused by a pretty fat tail due to lock conflicts.
latency (ms)operation mean std dev countall reads 8.7 376.4 21.5B
single-site commit 72.3 112.8 31.2Mmulti-site commit 103.0 52.2 32.1M
Table 6: F1-perceived operation latencies measured over thecourse of 24 hours.
of such tables are extremely uncommon. The F1 teamhas only seen such behavior when they do untuned bulkdata loads as transactions.
Table 6 presents Spanner operation latencies as mea-sured from F1 servers. Replicas in the east-coast datacenters are given higher priority in choosing Paxos lead-ers. The data in the table is measured from F1 serversin those data centers. The large standard deviation inwrite latencies is caused by a pretty fat tail due to lockconflicts. The even larger standard deviation in read la-tencies is partially due to the fact that Paxos leaders arespread across two data centers, only one of which hasmachines with SSDs. In addition, the measurement in-cludes every read in the system from two datacenters:the mean and standard deviation of the bytes read wereroughly 1.6KB and 119KB, respectively.
6 Related Work
Consistent replication across datacenters as a storageservice has been provided by Megastore [5] and Dy-namoDB [3]. DynamoDB presents a key-value interface,and only replicates within a region. Spanner followsMegastore in providing a semi-relational data model,and even a similar schema language. Megastore doesnot achieve high performance. It is layered on top ofBigtable, which imposes high communication costs. Italso does not support long-lived leaders: multiple repli-cas may initiate writes. All writes from different repli-cas necessarily conflict in the Paxos protocol, even ifthey do not logically conflict: throughput collapses ona Paxos group at several writes per second. Spanner pro-vides higher performance, general-purpose transactions,and external consistency.
Pavlo et al. [31] have compared the performance ofdatabases and MapReduce [12]. They point to severalother efforts that have been made to explore databasefunctionality layered on distributed key-value stores [1,4, 7, 41] as evidence that the two worlds are converging.We agree with the conclusion, but demonstrate that in-tegrating multiple layers has its advantages: integratingconcurrency control with replication reduces the cost ofcommit wait in Spanner, for example.
The notion of layering transactions on top of a repli-cated store dates at least as far back as Gifford’s disser-tation [16]. Scatter [17] is a recent DHT-based key-valuestore that layers transactions on top of consistent repli-cation. Spanner focuses on providing a higher-level in-terface than Scatter does. Gray and Lamport [18] de-scribe a non-blocking commit protocol based on Paxos.Their protocol incurs more messaging costs than two-phase commit, which would aggravate the cost of com-mit over widely distributed groups. Walter [36] providesa variant of snapshot isolation that works within, but notacross datacenters. In contrast, our read-only transac-tions provide a more natural semantics, because we sup-port external consistency over all operations.
There has been a spate of recent work on reducingor eliminating locking overheads. Calvin [40] elimi-nates concurrency control: it pre-assigns timestamps andthen executes the transactions in timestamp order. H-Store [39] and Granola [11] each supported their ownclassification of transaction types, some of which couldavoid locking. None of these systems provides externalconsistency. Spanner addresses the contention issue byproviding support for snapshot isolation.
VoltDB [42] is a sharded in-memory database thatsupports master-slave replication over the wide area fordisaster recovery, but not more general replication con-figurations. It is an example of what has been calledNewSQL, which is a marketplace push to support scal-able SQL [38]. A number of commercial databases im-plement reads in the past, such as MarkLogic [26] andOracle’s Total Recall [30]. Lomet and Li [24] describe animplementation strategy for such a temporal database.
Farsite derived bounds on clock uncertainty (muchlooser than TrueTime’s) relative to a trusted clock refer-ence [13]: server leases in Farsite were maintained in thesame way that Spanner maintains Paxos leases. Looselysynchronized clocks have been used for concurrency-control purposes in prior work [2, 23]. We have shownthat TrueTime lets one reason about global time acrosssets of Paxos state machines.
7 Future Work
We have spent most of the last year working with theF1 team to transition Google’s advertising backend fromMySQL to Spanner. We are actively improving its mon-itoring and support tools, as well as tuning its perfor-mance. In addition, we have been working on improvingthe functionality and performance of our backup/restoresystem. We are currently implementing the Spannerschema language, automatic maintenance of secondaryindices, and automatic load-based resharding. Longerterm, there are a couple of features that we plan to in-
Published in the Proceedings of OSDI 2012 12
10 TPS!
[Corbett, et al. “Spanner:…”, OSDI12]
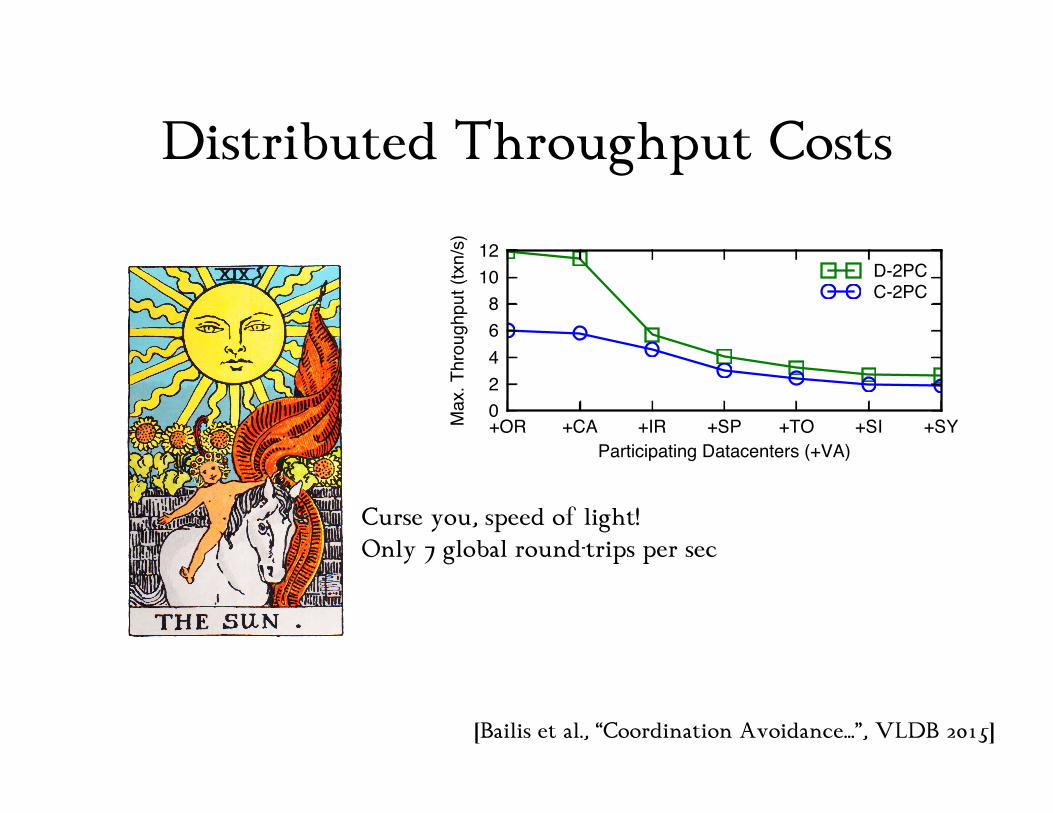
Distributed Throughput Costs
Figure 1: Microbenchmark performance of coordinated andcoordination-free execution of transactions of varying size writ-ing to eight items located on eight separate multi-core servers.
Quantifying coordination overheads. To further understand thecosts of coordination, we performed two sets of measurements—oneusing a database prototype and one using traces from prior studies.
We first compared the throughput of a set of coordinated andcoordination-free transaction execution. We partitioned a set ofeight data items across eight servers and ran one set of transactionswith an optimized variant of two-phase locking (providing serializ-ability) [15] and ran another set of transactions without coordination(Figure 1; see [10, Appendix A] for more details). With single-item,non-distributed transactions, the coordination-free implementationachieves, in aggregate, over 12M transactions per second and bot-tlenecks on physical resources—namely, CPU cycles. In contrast,the lock-based implementation achieves approximately 1.1M trans-actions per second: it is unable to fully utilize all multi-core pro-cessor contexts due to lock contention. For distributed transactions,coordination-free throughput decreases linearly (as an N-item trans-action performs N writes), while the throughput of coordinatingtransactions drops by over three orders of magnitude.
While the above microbenchmark demonstrates the costs of aparticular implementation of coordination, we also studied the ef-fect of more fundamental, implementation-independent overheads(i.e., also applicable to optimistic and scheduling-based concur-rency control mechanisms). We determined the maximum attainablethroughput for coordinated execution within a single datacenter(based on data from [60]) and across multiple datacenters (based ondata from [9]) due to blocking coordination during atomic commit-ment [15]. For an N-server transaction, classic two-phase commit(C-2PC) requires N (parallel) coordinator to server RTTs, while de-centralized two-phase commit (D-2PC) requires N (parallel) serverto server broadcasts, or N2 messages. Figure 2 shows that, in thelocal area, with only two servers (e.g., two replicas or two coordi-nating operations on items residing on different servers), throughputis bounded by 1125 transactions/s (via D-2PC; 668/s via C-2PC).Across eight servers, D-2PC throughput drops to 173 transactions/s(resp. 321 for C-2PC) due to long-tailed latency distributions. In thewide area, the effects are more stark: if coordinating from Virginiato Oregon, D-2PC message delays are 83 ms per commit, allowing12 operations per second. If coordinating between all eight EC2availability zones, throughput drops to slightly over 2 transactions/sin both algorithms. ([10, Appendix A] provides more details.)
These results should be unsurprising: coordinating—especiallyover the network—can incur serious performance penalties. Incontrast, coordination-free operations can execute without incurringthese costs. The costs of actual workloads can vary: if coordinatingoperations are rare, concurrency control will not be a bottleneck.For example, a serializable database executing transactions withdisjoint read and write sets can perform as well as a non-serializabledatabase without compromising correctness [34]. However, as these
a.) Maximum transaction throughput over local-area network in [60]
+OR +CA +IR +SP +TO +SI +SYParticipating Datacenters (+VA)
02468
1012
Max
. Thr
ough
put (
txn/
s)
D-2PCC-2PC
b.) Maximum throughput over wide-area network in [9] with transactions origi-nating from a coordinator in Virginia (VA; OR: Oregon, CA: California, IR: Ire-land, SP: São Paulo, TO: Tokyo, SI: Singapore, SY: Sydney)
Figure 2: Atomic commitment latency as an upper bound onthroughput over LAN and WAN networks.
results demonstrate, minimizing the amount of coordination andits degree of distribution can therefore have a tangible impact onperformance, latency, and availability [1,9,28]. While we study realapplications in Section 6, these measurements highlight the worstof coordination costs on modern hardware.
Our goal: Minimize coordination. In this paper, we seek to min-imize the amount of coordination required to correctly execute anapplication’s transactions. As discussed in Section 1, serializabilityis sufficient to maintain correctness but is not always necessary; thatis, many—but not all—transactions can be executed concurrentlywithout necessarily compromising application correctness. In theremainder of this paper, we identify when safe, coordination-freeexecution is possible. If serializability requires coordinating be-tween each possible pair of conflicting reads and writes, we willonly coordinate between pairs of operations that might compromiseapplication-level correctness. To do so, we must both raise thespecification of correctness beyond the level of reads and writesand directly account for the process of reconciling the effects ofconcurrent transaction execution at the application level.
3. SYSTEM MODELTo characterize coordination avoidance, we first present a sys-
tem model. We begin with an informal overview. In our model,transactions operate over independent (logical) “snapshots” of da-tabase state. Transaction writes are applied at one or more snap-shots initially when the transaction commits and then are integratedinto other snapshots asynchronously via a “merge” operator thatincorporates those changes into the snapshot’s state. Given a setof invariants describing valid database states, as Table 1 outlines,we seek to understand when it is possible to ensure invariants arealways satisfied (global validity) while guaranteeing a response(transactional availability) and the existence of a common state (con-vergence), all without communication during transaction execution(coordination-freedom). This model need not directly correspond to
[Bailis et al., “Coordination Avoidance…”, VLDB 2015]
Curse you, speed of light! Only 7 global round-trips per sec

The Big Question: Dance or Pay?
• That is: – Run without coordination, and risk inconsistency?
– Or pay for coordination?
• More subtly: when to coordinate? – A case-by-case decision?
– Can uncoordinated stuff taint your coordinated stuff?

The Von Neumann Model
Focus on Mutable State Primacy of Ordering
– LIST of Instructions
– ARRAY of Memory
– MUTATION in time (R/W)
– Remember our lost illusions? • Sequential computing
• Single-copy state • Reliable components

The Von Neumann Model
Focus on Mutable State Primacy of Ordering
– LIST of Instructions
– ARRAY of Memory
– MUTATION in time (R/W)
– Remember our lost illusions? • Sequential computing
• Single-copy state • Reliable components


Outline
• the costs of coordination
• approaches to avoid coordination
• Bloom
• the CALM theorem
• research results and sw engineering artifacts

Design Philosophies
• Bottom-Up (systems, esp. research) – Let’s build storage (NoSQL, cache coherence, etc) – Define specific consistency guarantees for R/W interface
• Causal, weak isolated xactions, session guarantees…
• Top-Down (developer design patterns) – Let’s build the app – Ensure consistent behavior despite inconsistent storage
• Dynamo shopping cart
• Know-Nothing (everywhere) – Consistency? Why worry?*
Much dispute, esp. in NoSQL. Each is (often) right.
*[Bailis, et al., “Probabilistically Bounded Staleness…”, VLDB12]

Dancing on the Wrong Bottom
• Top-down actually works, often clever – Consistent apps on inconsistent storage – Much to be learned here from developer patterns!
• But bottom-up toolchain still gets in the way – Sequential languages – Idiosyncratic R/W consistency models – Debuggers for tracking ordered state mutation – Test harnesses that can’t cover the space
• End results that are hard to test, hard to trust

Dynamo: Building on Quicksand
• The roots of NoSQL
• Write a shopping cart on a mutable key/value store? – You’ll need to coordinate R/W!
• Instead, accumulate a log of shopping events. – At checkout, tally the full contents
[DeCandia, et al. 2007] [Campbell and Helland, 2009]
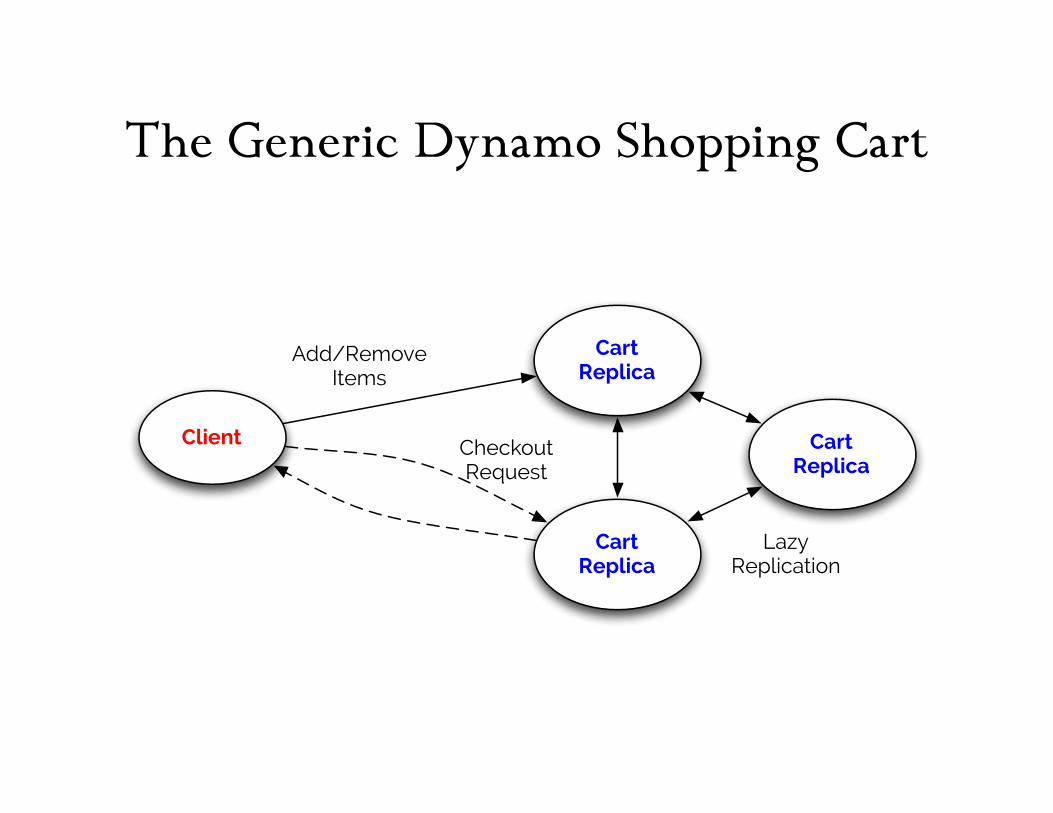
The Generic Dynamo Shopping Cart
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication

Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
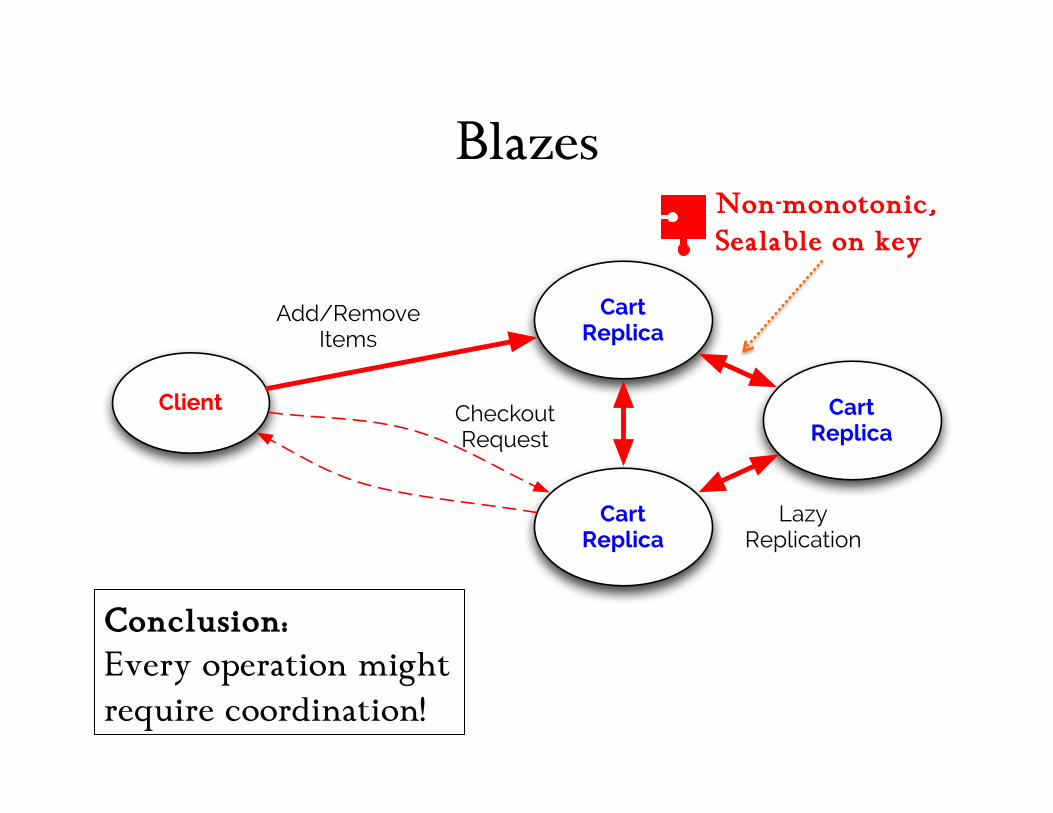
CALM Analysis: “Mutable State” Cart
Conclusion: Every operation might require coordination!
Mutation! Non-monotonic!
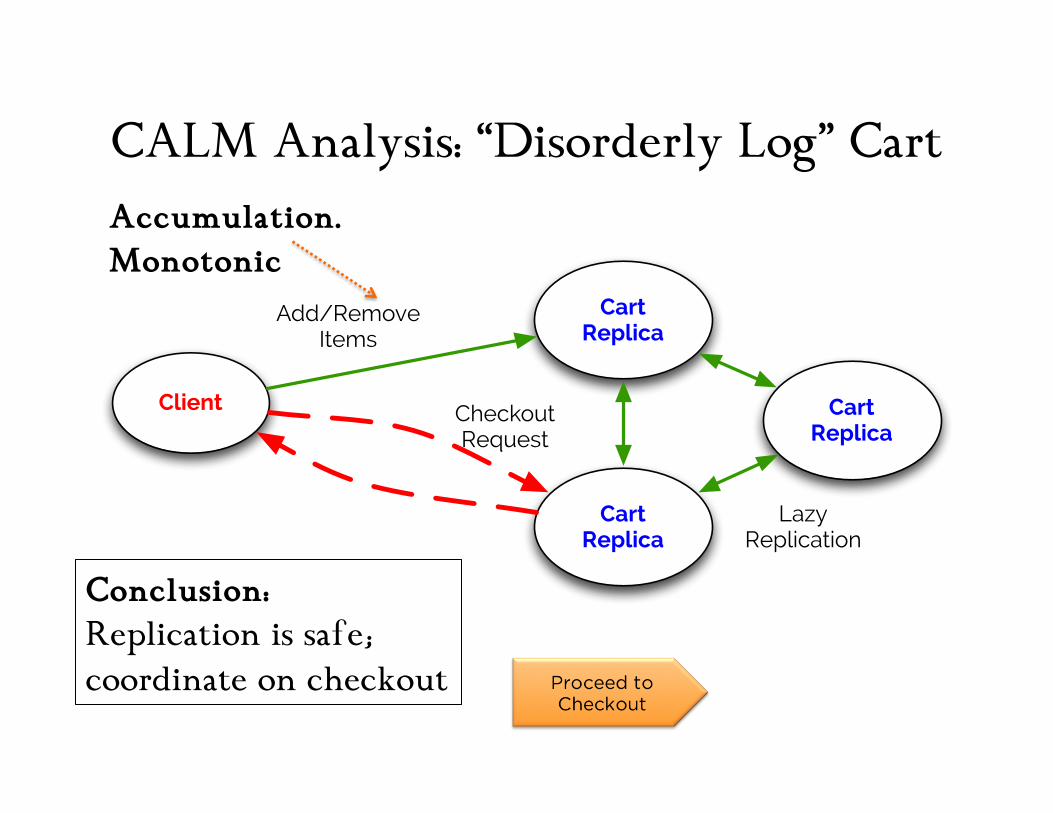
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
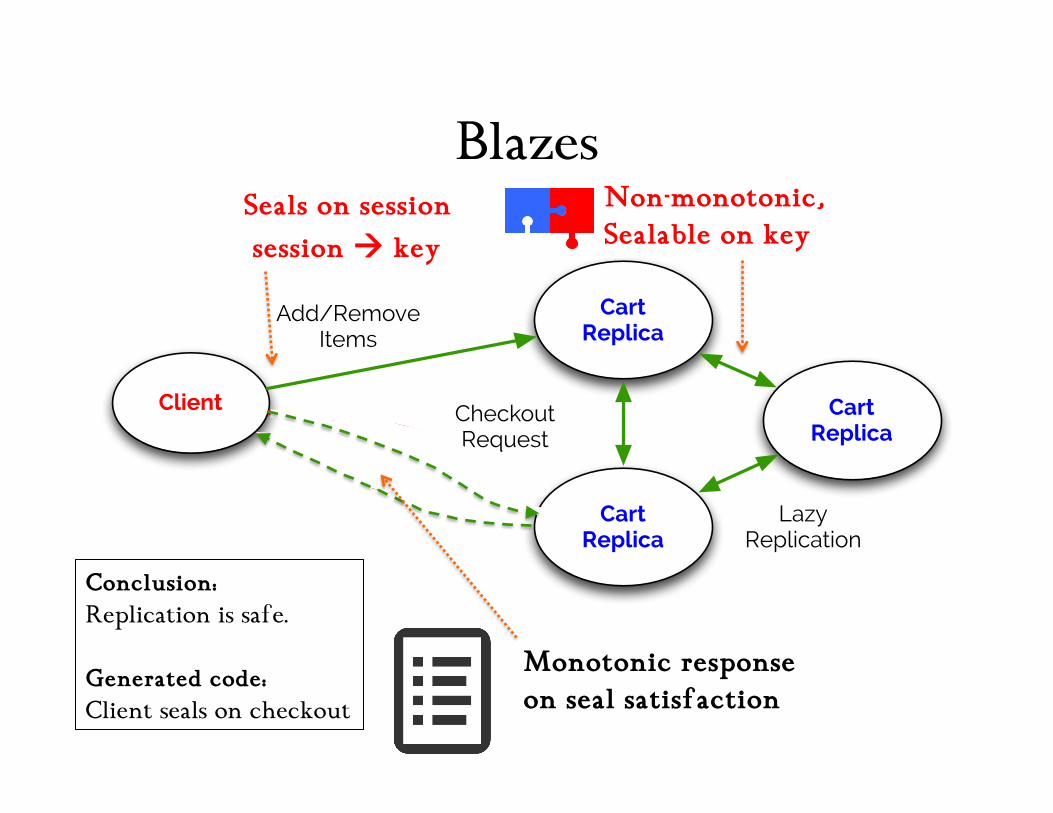
CALM Analysis: “Disorderly Log” Cart
Conclusion: Replication is safe; coordinate on checkout
Accumulation. Monotonic

We’ll do this in Bloom
• First, the traditional (bad) “destructive” cart – Mutable state in a distributed key/value store – I.e. NoSQL
• Then the more clever log-based solution • If time permits, something more clever yet!
• But first, some Bloom...

Outline
• the costs of coordination • approaches to avoid coordination • Bloom • the CALM theorem • research results and sw engineering artifacts
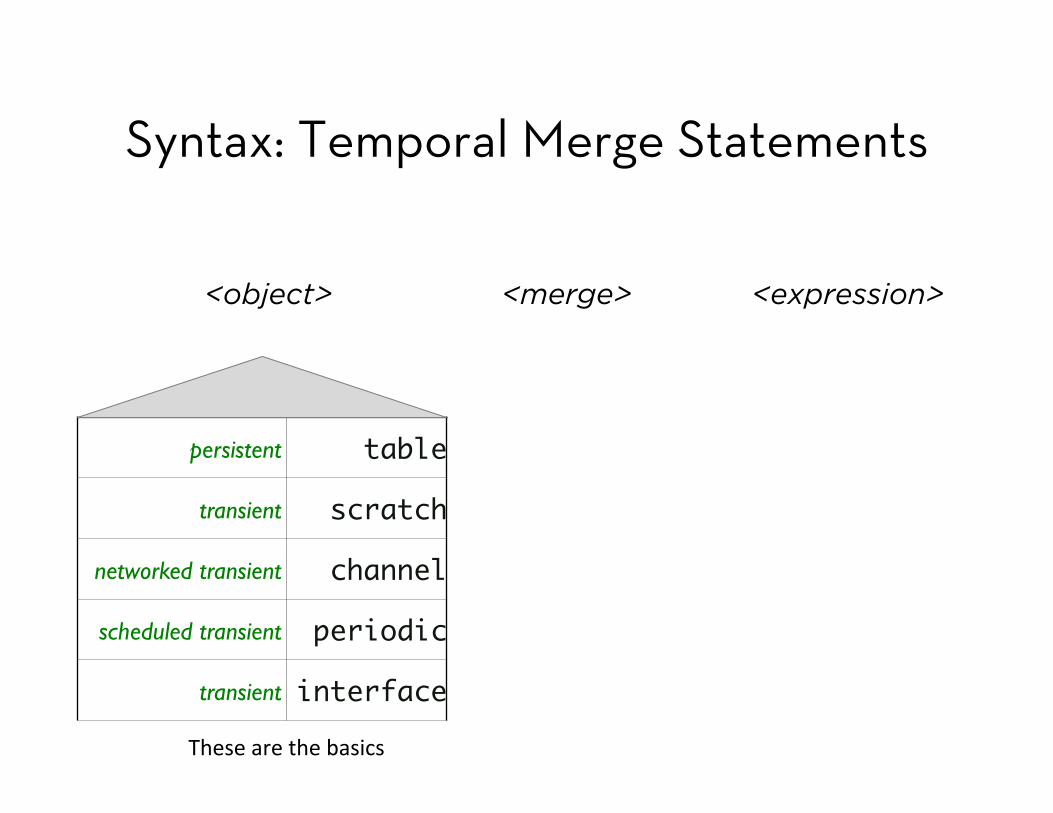
persistent table
transient scratch
networked transient channel
scheduled transient periodic
transient interface
<object> <merge> <expression>
These are the basics
Syntax: Temporal Merge Statements
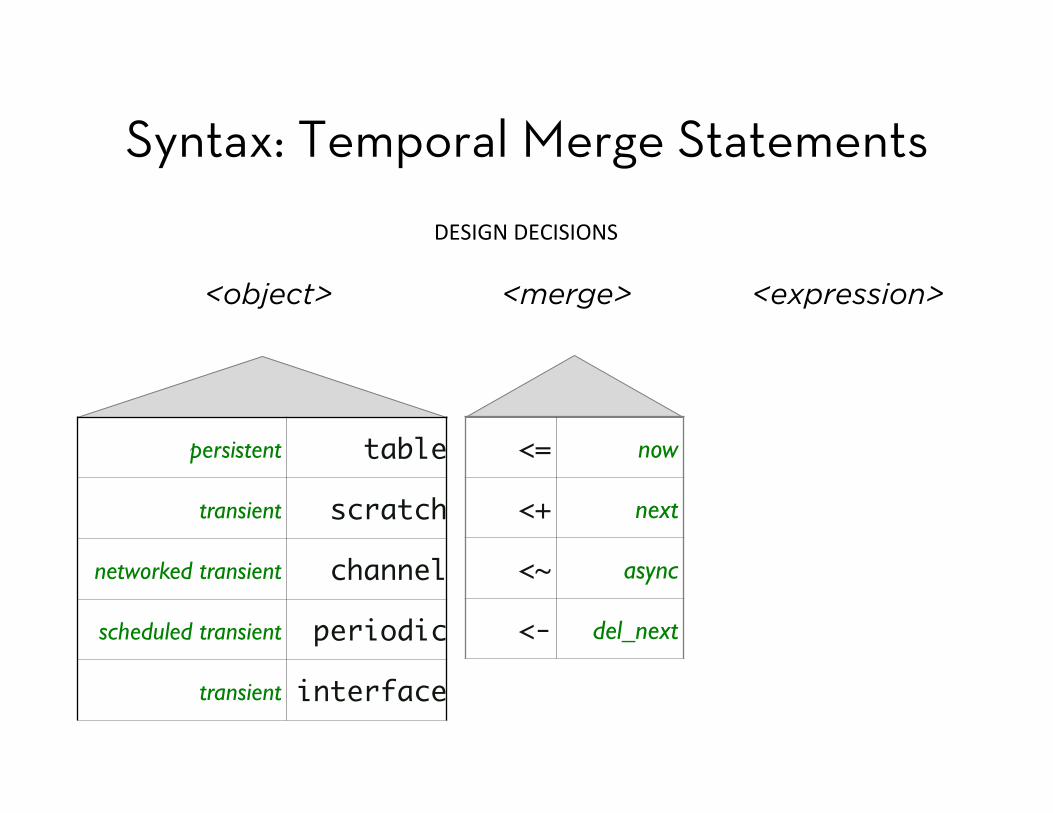
<= now
<+ next
<~ async
<- del_next
<object> <merge> <expression>
DESIGN DECISIONS
persistent table
transient scratch
networked transient channel
scheduled transient periodic
transient interface
Syntax: Temporal Merge Statements

<object> <merge> <expression>
<= now
<+ next
<~ async
<- del_next
<object>map, flat_map
reduce, group, argmin/max
(r * s).pairsempty? include?
persistent table
transient scratch
networked transient channel
scheduled transient periodic
transient interface
Syntax: Temporal Merge Statements Disorderly by
default: data & code

The Local Bloom Tick
bloom rules atomic, local.
events are data. { } data updates system events nw msgs
next Network I/O
⓵ ⓶ ⓷ now
next
Disorderly by default: data, code & execuMon model

A typical pattern
scratch :events !table :stuff !!# event handling as join of scratch and table! !# for each event, for each item in stuff ... !lhs <= (events * stuff).pairs {|e, s| ! ... !} !!

A Simple Bloom Program
1 class ChatServer ! 2 include Bud ! 3 include ChatProtocol! 4 ! 5 state do ! 6 channel :connect, [:@addr, :client] => [:nick] ! 7 channel :mcast! 8 table :nodelist ! 9 end!10 !11 bloom do !12 nodelist <= connect { |c| [c.client, c.nick] } !13 mcast <~ (mcast * nodelist).pairs { |m,n| !14 [n.key, m.val] !15 } !16 end!17 end
Let’s go shopping!

But first... Why is mutable state non-monotone?
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
Mutation! Non-monotonic!

But first... Why is mutable state non-monotone?
state do !table :fiction !scratch :fact !interface :input, :hearsay !interface :input, :retractions !
!end !!bloom do !
fiction <= hearsay !fact <= hearsay !
!!!end !

But first... Why is mutation non-monotone?
state do !table :fiction !scratch :fact !interface :input, :hearsay !interface :input, :retractions !
!end !!bloom do !
fiction <= hearsay !fact <= hearsay !fact <+ fact !
!!end !
This induction is how persistence is modeled
formally in Dedalus. Depends on the sequentiality of the
local clock (via <+)

But first... Why is mutation non-monotone?
state do !table :fiction !scratch :fact !interface :input, :hearsay !interface :input, :retractions !
!end !!bloom do !
fiction <= hearsay !fact <= hearsay !fact <+ fact !fiction <- retractions !
!end !

But first... Why is mutation non-monotone?
state do !table :fiction !scratch :fact !interface :input, :hearsay !interface :input, :retractions !scratch :del_fact!
end !!bloom do !
fiction <= hearsay !fact <= hearsay !fact <+ fact.notin(del_fact) !fiction <- retractions !del_fact <+ retractions !
end !
This is how state update is modeled formally in
Dedalus. notin breaks the induction, via classic non-
montonicity!
Upshot: the von Neumann model and most PLs have apparent non-
monotonicity everywhere! Stymies efforts to extract coordination-
avoidance

a simple key-value store: protocol module KVSProtocol! state do ! interface input, :kvput, [:key] => [:reqid, :value] ! interface input, :kvdel, [:key] => [:reqid] ! interface input, :kvget, [:reqid] => [:key] ! interface output, :kvget_response, ! [:reqid] => [:key, :value] ! end!end!!

a simple key-value store: protocol module KVSProtocol! state do ! interface input, :kvput, [:key] => [:reqid, :value] ! interface input, :kvdel, [:key] => [:reqid] ! interface input, :kvget, [:reqid] => [:key] ! interface output, :kvget_response, ! [:reqid] => [:key, :value] ! end!end!!

basic local kvs module BasicKVS! include KVSProtocol!! state { table :kvstate, [:key] => [:value] } !! bloom do ! # mutate ! kvstate <+- kvput {|s| [s.key, s.value]} !! # get ! temp :getj <= (kvget * kvstate).pairs(:key => :key) ! kvget_response <= getj do |g, t| ! [g.reqid, t.key, t.value] ! end!! # delete ! kvstate <- (kvstate * kvdel).lefts(:key => :key) ! end!end!

basic local kvs module BasicKVS! include KVSProtocol!! state { table :kvstate, [:key] => [:value] } !! bloom do ! # mutate ! kvstate <+- kvput {|s| [s.key, s.value]} !! # get ! temp :getj <= (kvget * kvstate).pairs(:key => :key) ! kvget_response <= getj do |g, t| ! [g.reqid, t.key, t.value] ! end!! # delete ! kvstate <- (kvstate * kvdel).lefts(:key => :key) ! end!end!
kvstate(N) +/-
getj(N)
kvput
+/-
kvget_response(N)
kvget
T
kvdel
+/-
S

cart client
module CartProtocol! state do ! channel :action_msg, ! [:@server, :client, :session, :reqid] => [:item, :cnt] ! channel :checkout_msg, ! [:@server, :client, :session, :reqid] ! channel :response_msg, ! [:@client, :server, :session] => [:items] ! end!end!!module CartClientProtocol! state do ! interface input, :client_action, [:server, :session, :reqid] => [:item, :cnt] ! interface input, :client_checkout, [:server, :session, :reqid] ! interface output, :client_response, [:client, :server, :session] => [:items] ! end!end!!module CartClient! include CartProtocol! include CartClientProtocol!! bloom :client do ! action_msg <~ client_action {|a| [a.server, ip_port, a.session, a.reqid, a.item, a.cnt]} ! checkout_msg <~ client_checkout {|a| [a.server, ip_port, a.session, a.reqid]} ! client_response <= response_msg! end!end!

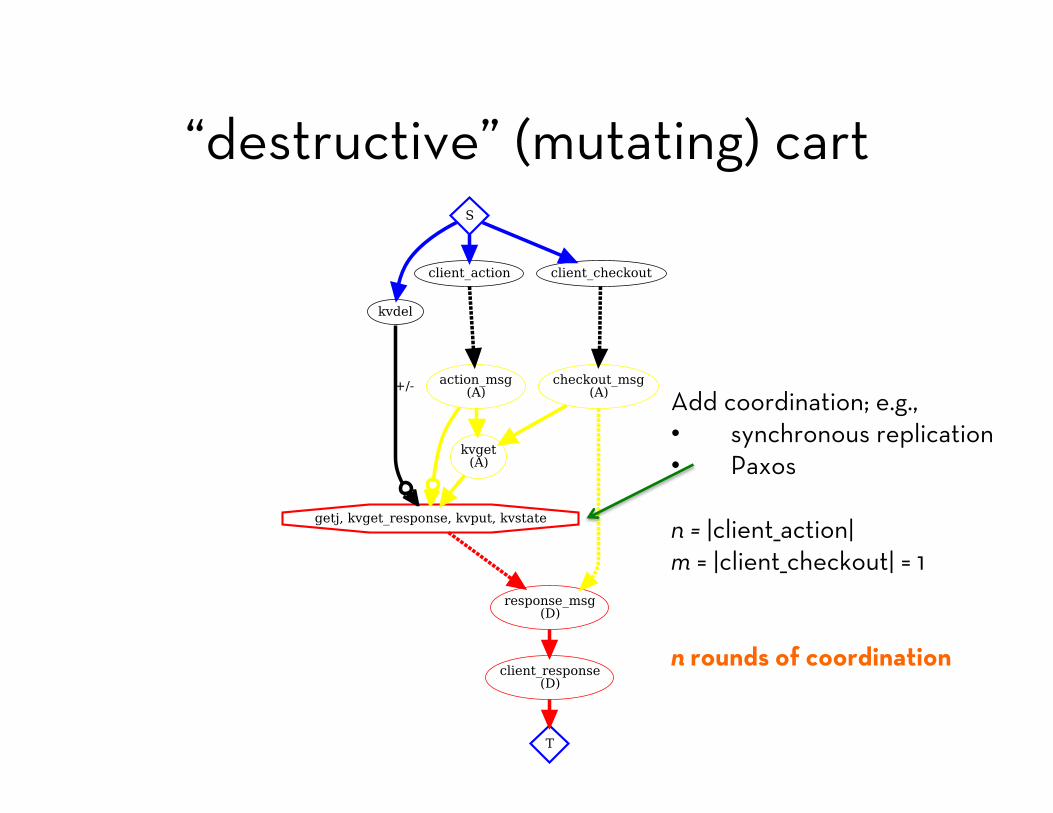
“destructive” (mutating) cart
module DestructiveCart! include CartProtocol! include KVSProtocol!! bloom :on_action do ! kvget <= action_msg {|a| [a.reqid, a.session] } ! kvput <= (action_msg * kvget_response).outer(:reqid => :reqid) do |a,r| ! val = r.value || {} ! [a.client, a.session, a.reqid, ! val.merge({a.item => a.cnt}) {|k,old,new| old + new}] ! end! end!! bloom :on_checkout do ! kvget <= checkout_msg {|c| [c.reqid, c.session] } ! response_msg <~ (kvget_response * checkout_msg).pairs(:reqid => :reqid) do |r,c| ! [c.client, c.server, r.key, r.value.select {|k,v| v > 0}.sort] ! end! end!end!

“destructive” (mutating) cart

“destructive” (mutating) cart
Asynchrony
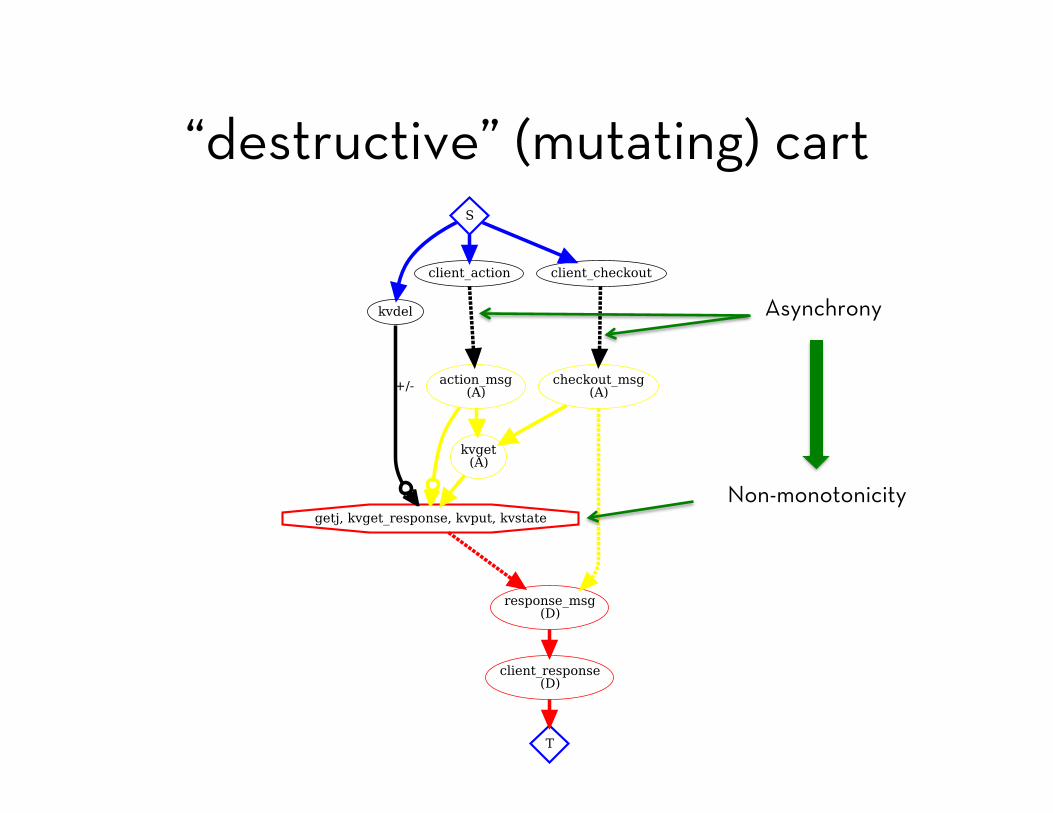
“destructive” (mutating) cart
Asynchrony
Non-monotonicity

“destructive” (mutating) cart
Asynchrony
Non-monotonicity
Divergent Results?
“destructive” (mutating) cart
Add coordination; e.g., • synchronous replication • Paxos n = |client_action| m = |client_checkout| = 1 n rounds of coordination

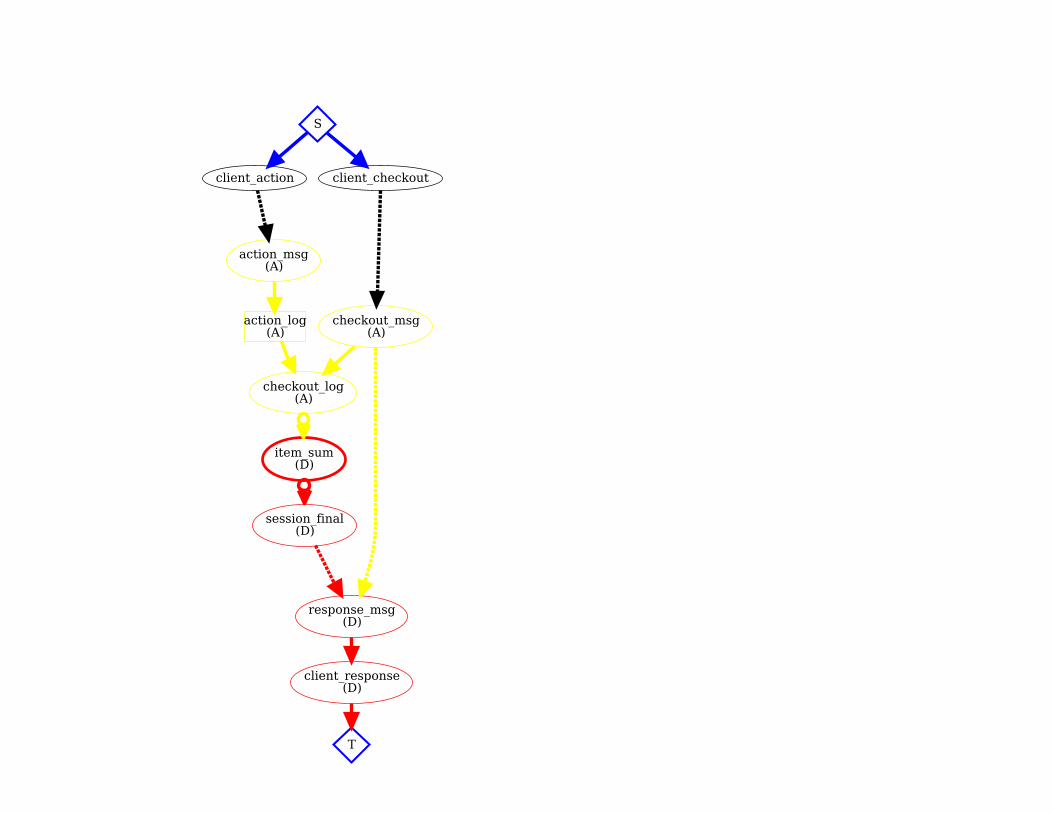
disorderly cart
module DisorderlyCart include CartProtocol
state do table :action_log, [:session, :reqid] => [:item, :cnt] scratch :item_sum, [:session, :item] => [:num] scratch :session_final, [:session] => [:items, :counts] end
bloom :on_action do action_log <= action_msg {|c| [c.session, c.reqid, c.item, c.cnt] } end
bloom :on_checkout do temp :checkout_log <= (checkout_msg * action_log).rights(:session => :session) item_sum <= checkout_log.group([:session, :item], sum(:cnt)) do |s| s if s.last > 0 # Don't return items with non-positive counts. end session_final <= item_sum.group([:session], accum_pair(:item, :num)) response_msg <~ (session_final * checkout_msg).pairs(:session => :session) do |c,m| [m.client, m.server, m.session, c.items.sort] end endend

Asynchrony
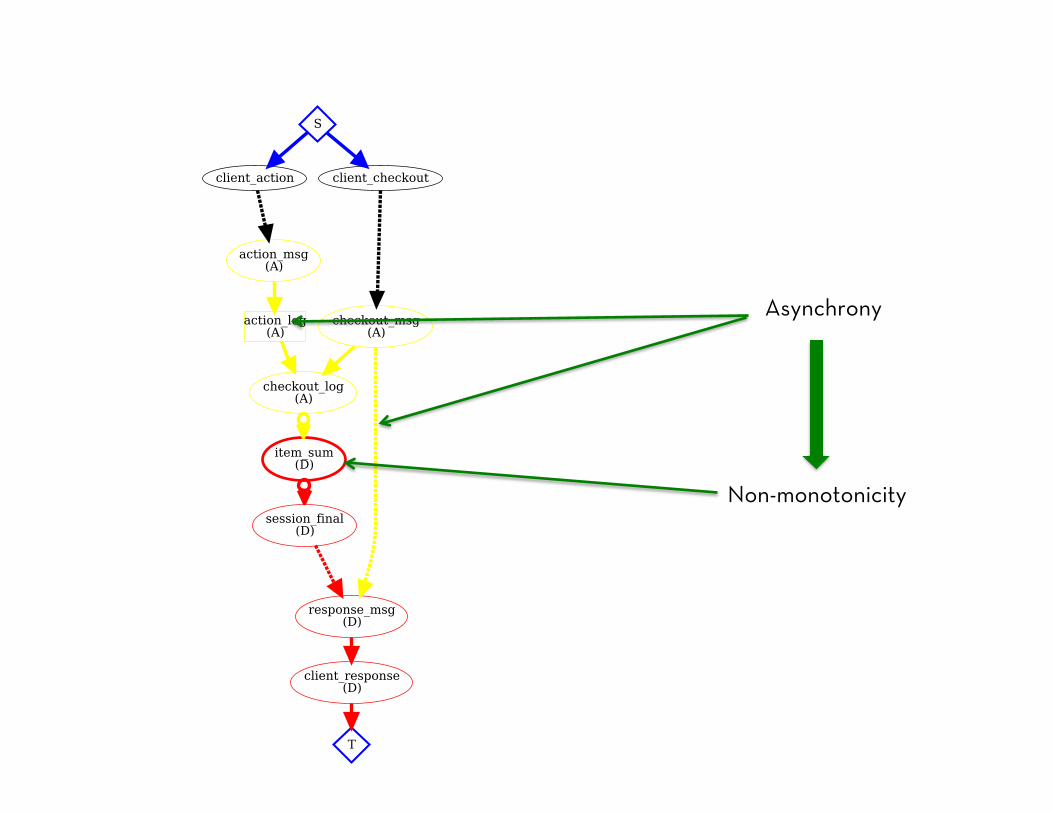
Asynchrony
Non-monotonicity

Asynchrony
Non-monotonicity
Divergent Results?
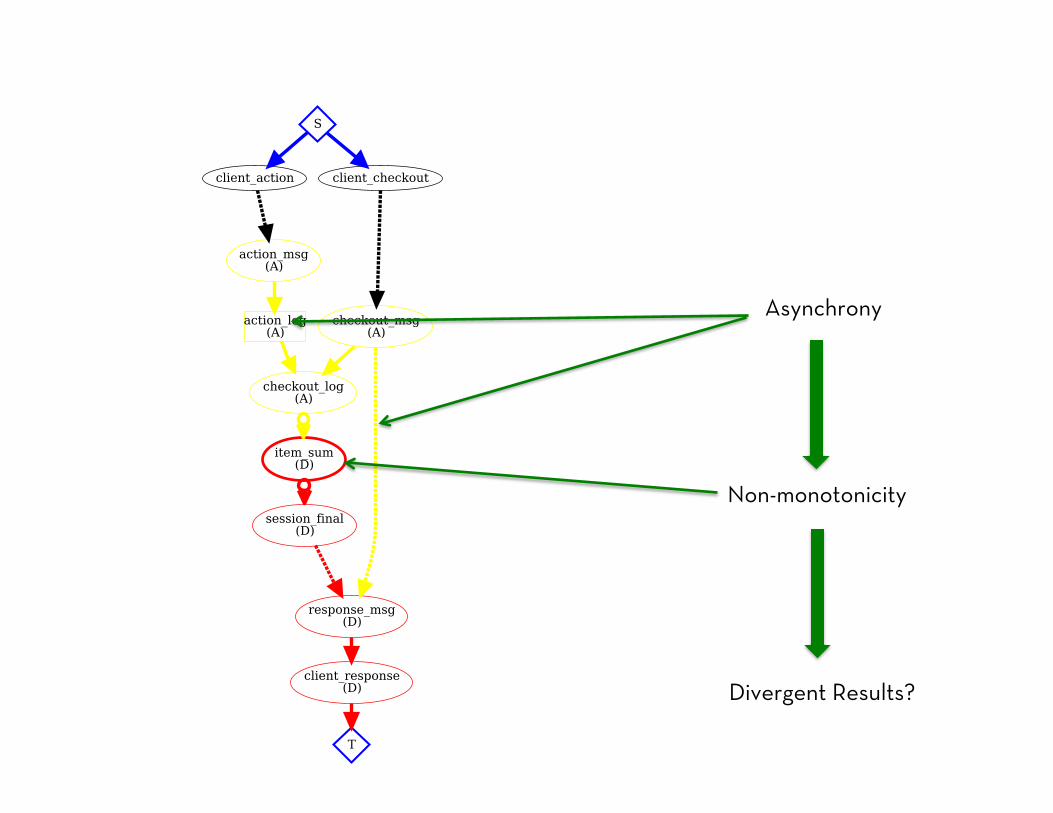
Asynchrony
Non-monotonicity
Divergent Results?
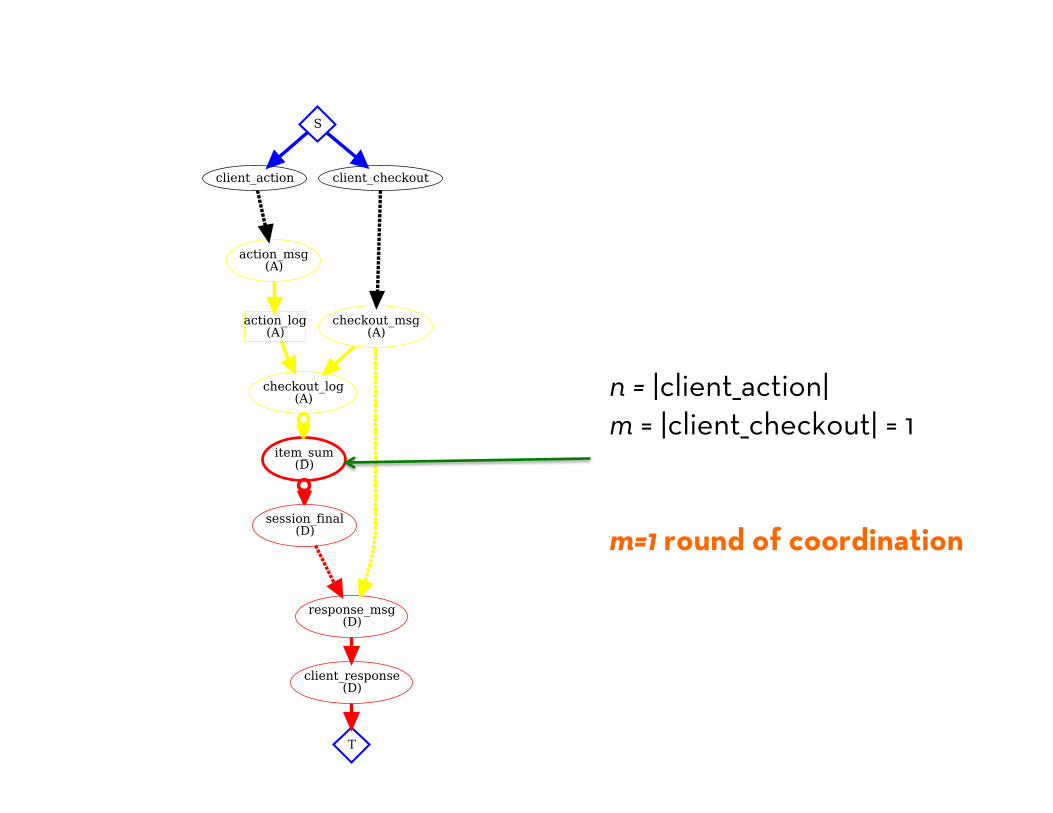
n = |client_action| m = |client_checkout| = 1 m=1 round of coordination

Beyond Collections
• Shopping carts are nice because they’re sets – But lots of standard distributed systems stuff isn’t
• E.g. counters, clocks, version vectors, etc.
• What’s so great about sets? – Order insensitive (union Commutes) – Batch insensitive (union Associates) – Retry insensitive (union “Idempotes”)
• Design pattern: “ACID 2.0” – Can we apply the idea to other structures?

Bounded Join SemiLattices
A pair <S, ⋁> such that: • S is a set • ⋁ is a binary operator
(“least upper bound”) – Associative, Commutative, and Idempotent – Induces a partial order on S:
x ≤S y if x ⋁ y = y

Lattices: Practice
• Objects that “grow” over time • Have an interface with an
ACI merge method – Bloom’s “object <= expression”

Time
Set (Merge = Union)
Increasing Int (Merge = Max)
Boolean (Merge = Or)
{a}{b} {c}
{a,b} {b,c} {a,c}
{a,b,c}
5
5 7
7
3 7 false false
false
true
true
true

Beyond Objects
• Lattices represent disorderly data • What about disorderly computation?

f : S→T is a morphism iff: f(a ⋁S b) = f(a) ⋁T f(b)

Time
Set (Merge = Union)
Increasing Int (Merge = Max)
Boolean (Merge = Or)
size() >= 3
Morphism: set → increase-int
Morphism: increase-int → boolean
{a}{b} {c}
{a,b} {b,c} {a,c}
{a,b,c}
2
3
1
false
true
false
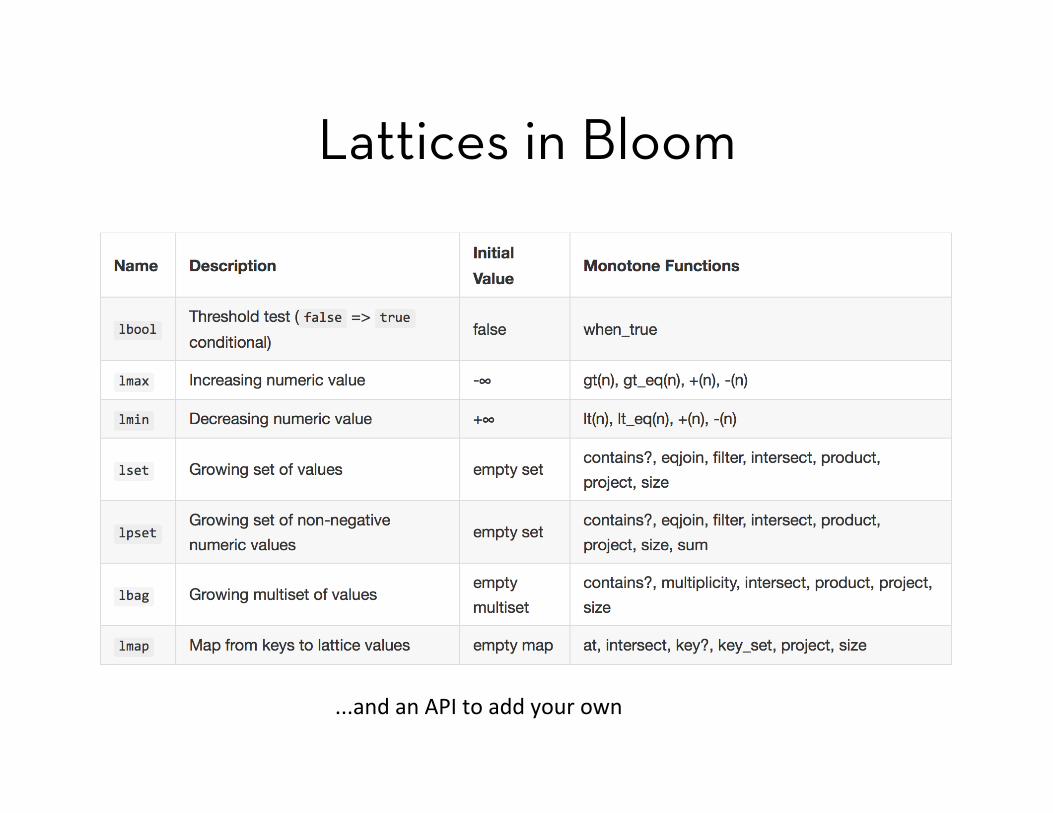
Lattices in Bloom
...and an API to add your own

Monotone Voting QUORUM_SIZE = 5 RESULT_ADDR = "example.org" class QuorumVote include Bud state do channel :vote_chn, [:@addr, :voter_id] channel :result_chn, [:@addr] lset :votes lmax :vote_cnt lbool :vote_done end bloom do votes <= vote_chn {|v| v.voter_id} vote_cnt <= votes.size got_quorum <= vote_cnt.gt_eq(QUORUM_SIZE) result_chn <~ got_quorum.when_true { [RESULT_ADDR] } end end!

• IniMally all clocks are zero. • Each Mme a process experiences an
internal event, it increments its own logical clock in the vector by one.
• Each Mme a process prepares to send a message, it increments its own logical clock in the vector by one and then sends its enMre vector along with the message being sent.
• Each Mme a process receives a message, it increments its own logical clock in the vector by one and updates each element in its vector by taking the maximum of the value in its own vector clock and the value in the vector in the received message (for every element).
Vector Clocks: bloom v. wikipedia
bootstrap do my_vc <= {ip_port => Bud::MaxLattice.new(0)} end
bloom do next_vc <= out_msg { {ip_port => my_vc.at(ip_port) + 1} } out_msg_vc <= out_msg {|m| [m.addr, m.payload, next_vc]} next_vc <= in_msg { {ip_port => my_vc.at(ip_port) + 1} } next_vc <= my_vc next_vc <= in_msg {|m| m.clock} my_vc <+ next_vc end

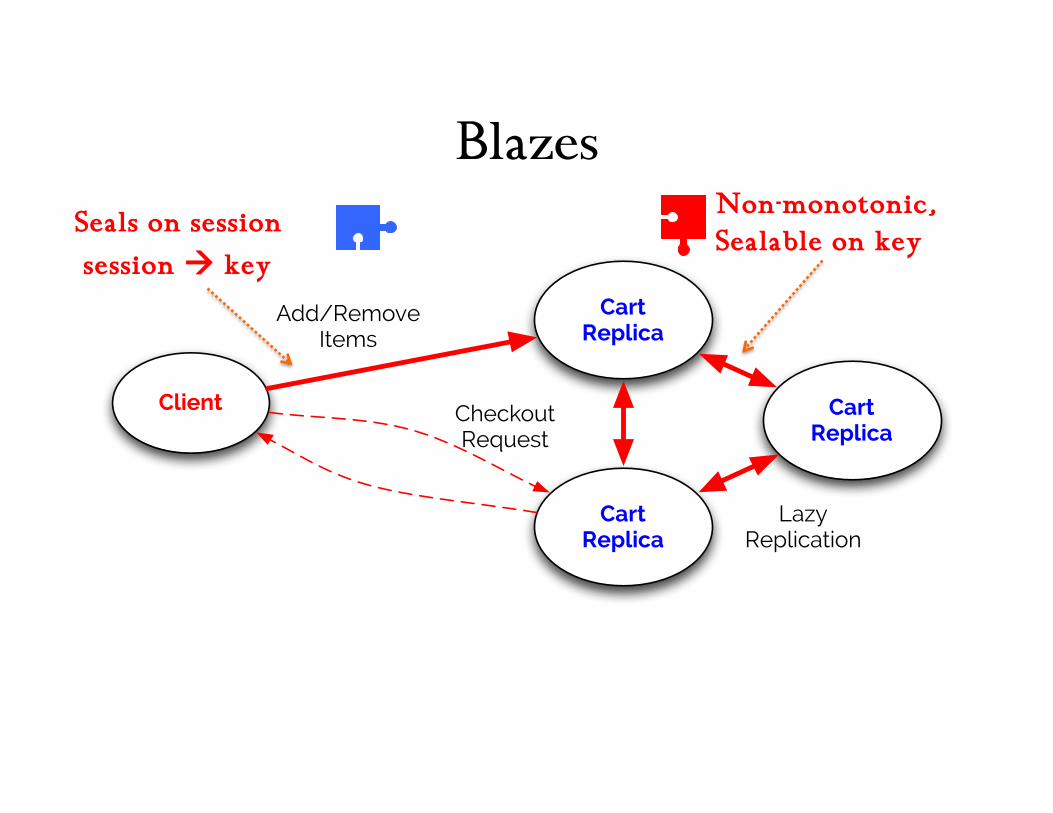
Observation: Once a checkout occurs, no more shopping actions
can be performed in-progress
completed

Observation: The client knows locally
what a legal checkout looks like
can label its requests to capture this e.g. use gap-free sequence #s on requests
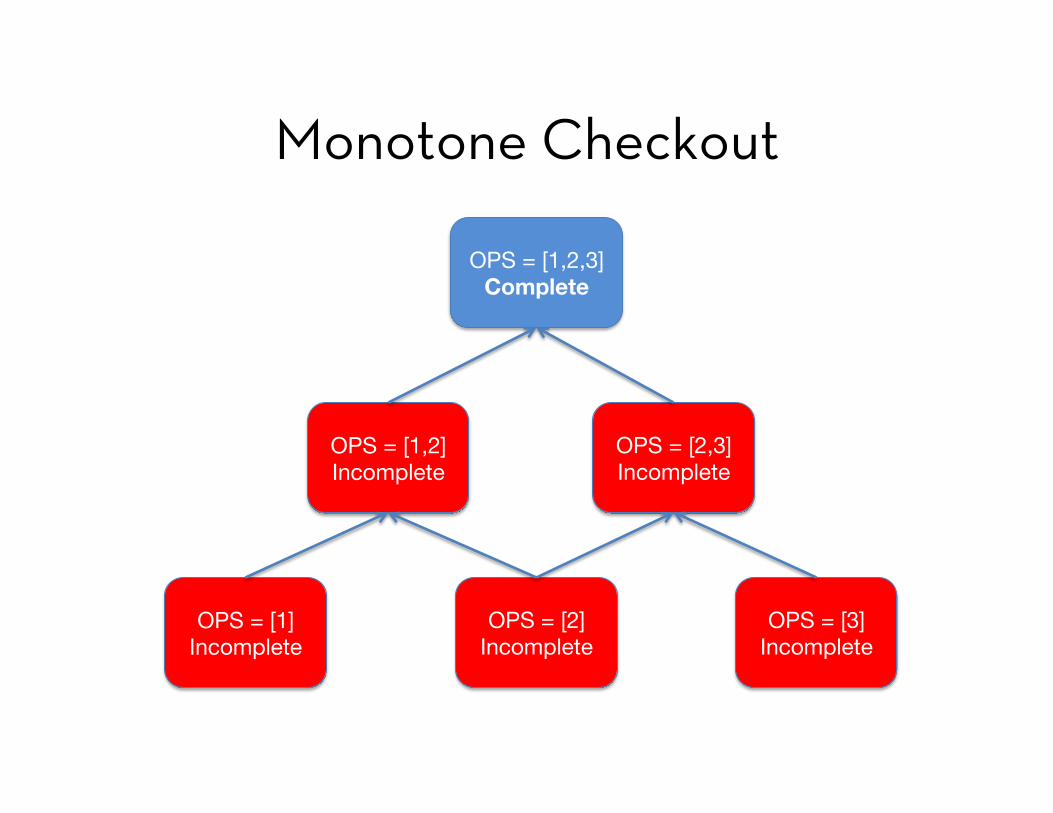
Monotone Checkout
OPS = [1]Incomplete
OPS = [2]Incomplete
OPS = [3]Incomplete
OPS = [1,2]Incomplete
OPS = [2,3]Incomplete
OPS = [1,2,3]Complete

The Monotone Cart module MonotoneReplica! include MonotoneCartProtocol!! state { lmap :sessions } !! bloom do ! sessions <= action_msg do |m| ! c = CartLattice.new({m.op_id => [ACTION_OP, m.item, m.cnt]}) ! { m.session => c } ! end!! sessions <= checkout_msg do |m| ! c = CartLattice.new({m.op_id => [CHECKOUT_OP, m.lbound, m.addr]}) ! { m.session => c } ! end!! response_msg <~ sessions.to_collection do |session, cart| ! cart.is_complete.when_true { ! [cart.checkout_addr, session, cart.summary] ! } ! end! end!end!
Accumulate
Wait for complete cart
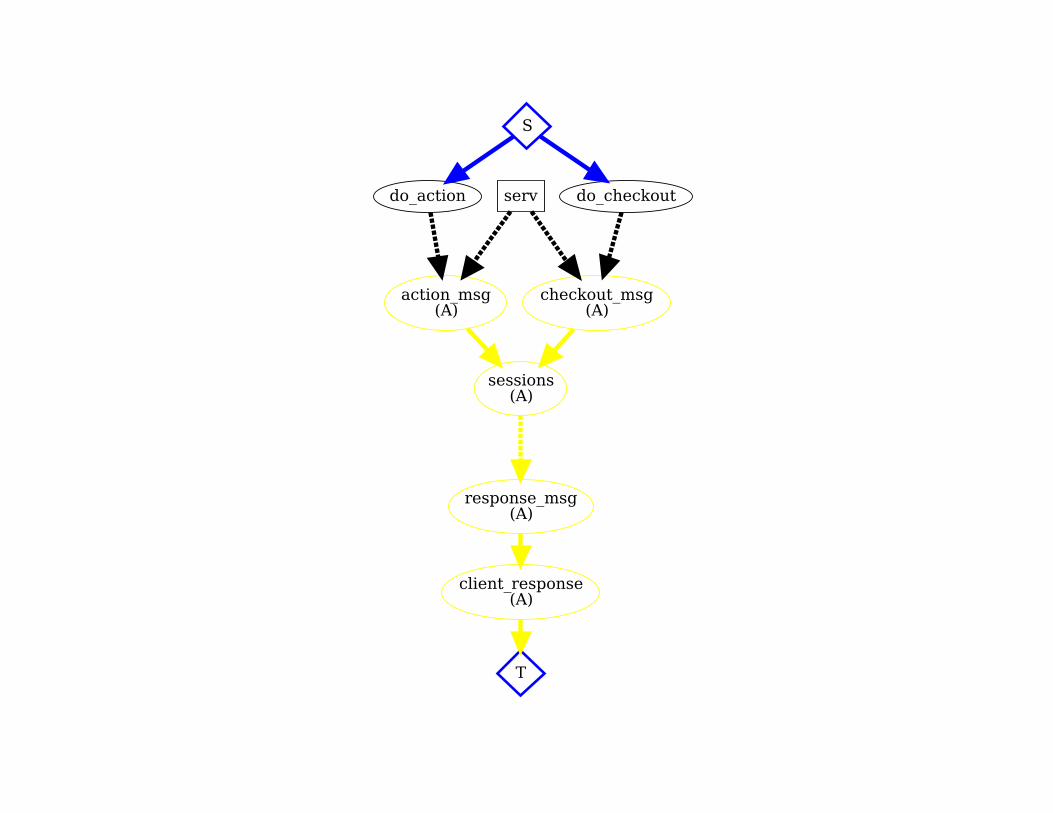

Further Evidence of Fit
• BOOM Analytics* & follow-ons – BFS: the Bloom Filesystem – KVS variants
• MV, Causal, Session Guarantees, Transactional, …
• Variety of classical protocols • Concurrent editing • Programming the Cloud Course
http://programthecloud.github.io
*[Alvaro, et al. “BOOM Analytics: …”, Eurosys10]

Outline
• the costs of coordination • developer approaches to avoid coordination • Bloom • the CALM theorem • research results and sw engineering artifacts

CAP and CALM
• CAP: a negative result – Given replicated data with reads and writes – You cannot have all of C+A+P in general – Said differently: replica consistency requires coordination
• CALM: a positive result – Application-level consistency is achievable without
coordination for a well-defined class of programs. • “Eventual consistency” with a formal semantics • C&A in the face of P!

The CALM Theorem Consistency As Logical Monotonicity
Also: • CRON Conjecture • Coordination Complexity
[Hellerstein: PODS ’09 keynote, “The Declarative Imperative”]
Monotonic => Consistent – w/o coordination!
¬Monotonic => ¬Consistent – To achieve consistency, you must use coordination
– “Seal” input to non-monotonic operations.

Much Depends on Definitions
• Consistency
• Monotonicity
• Coordination

Consistency: Confluence
• Non-Determinism (of Message Ordering)
• Yet deterministic outcomes – Upon eventual receipt of
same set of messages
– Deterministic outcomes (“state” and “computation”)

CALM Intuition: Logic & Sets
• Monotonic logic – Sets with accumulation
– Select/Project/Join
– Streaming execution
• Non-Monotonic logic – Negation (Not Exists)
– Set Difference
– Dedalus-style Deletion/Mutation
– No streaming execution. Requires “sealing” a set.

Sealing, Time, Space, Coordination
• Non-monotonicity requires sealing things ¬∃item ∊ Cart ( fragile(item) ) ⟺ ∀item ∊ Cart (¬fragile (item) )
• Time: a mechanism to seal fate. – Before and after
“Time is what keeps everything from happening at once.” — Ray Cummings

Sealing, Time, Space, Coordination
• Non-monotonicity requires sealing things ¬∃item ∊ Cart ( fragile(item) ) ⟺ ∀item ∊ Cart ( fragile(item) )
• Time: a mechanism to seal fate. – Before and after
• Space: multiple perceptions of time

Sealing, Time, Space, Coordination
• Non-monotonicity requires sealing things ¬∃item ∊ Cart ( fragile(item) ) ⟺ ∀item ∊ Cart ( fragile(item) )
• Time: a mechanism to seal fate. – Before and after
• Space: multiple perceptions of time
• Coordination: sealing across space/time. – Global Consensus on the “final” contents of a piece of state
– 2-Phase Commit & Paxos are the classic protocols

Is Monotonicity Restrictive?
• Actually, it’s all of PTIME!
• Maybe time doesn’t matter so much – Remember: Time is the thing that prevents everything
from happening all at once. • Anti-parallelism!
– Avoid it

Theoretical Results
• CALM Proofs – Abiteboul, et al.: M=>C [PODS ’11]
– Ameloot, et al.: CALM [PODS ’11, JACM ‘13]
– Marczak, et al.: Model-Theory treatment [Datalog 2.0 ’12]
– Ameloot, et al.: More permissive M [PODS ’14 best paper]
• CRON (Proofs & Refutations) – Ameloot, et al.: [JCSS ’15]
• Coordination Complexity: MP Model – Koutris & Suciu (min-coordination & LB): [PODS ’11]
– Beame et al. (minimizing replication): [PODS ’13]
• More! See survey by Ameloot [SIGMOD Record 6/14]

Thinking CALMly
• Using CALM as a guide to analyze designs…
• Leads us formally toward “kitchen wisdom” like the shopping carts – Associative/commutative methods
– Immutable state
– Event log exchange
– etc.

Outline
• the costs of coordination
• approaches to avoid coordination
• Bloom
• the CALM theorem
• research results and sw engineering artifacts

Blazes
• CALM Analysis & Coordination – Exploit punctuations for coarse-grained barriers
– Auto-synthesize app-specific coordination
• Applications for Bloom and beyond – CALM for annotated “grey boxes” in dataflows
– Applied to Bloom and to Twitter Storm
[Alvaro et al., ICDE13]
peter alvaro
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
Blazes
Conclusion: Every operation might require coordination!
Non-monotonic, Sealable on key
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
Blazes Seals on session session à key
Non-monotonic, Sealable on key
Client
Cart Replica
Cart Replica
Cart Replica
Add/RemoveItems
CheckoutRequest
LazyReplication
Blazes
Conclusion: Replication is safe. Generated code: Client seals on checkout
Monotonic response on seal satisfaction
Seals on session session à key
Non-monotonic, Sealable on key

BloomUnit: Declarative Testing
• Declarative Input/Output Specs
• Alloy-driven synthesis of interesting inputs
• CALM-driven collapsing of behavior space
[Alvaro et al., DBTest12]
peter alvaro

Edelweiss (Bloom and Grow)
• Enforce the event-log-exchange pattern
• Bloom with no deletion • Program-specific GC in Bloom
– Delivered message buffers
– Persistent state eclipsed by new versions
[Conway et al., VLDB 2014]
neil conway

Molly: Lineage-Driven Fault Injection
• In the field, end-to-end fault testing is done by fault injection – E.g. ChaosMonkey at Netflix
• Random Injection in a huge space – Is there a principled way to cover the space?
• The idea: – Take the lineage from a successful run of the protocol – Let an adversary “foil it” by breaking data derivations (a
SAT problem) – Rerun and see if FT protocol generates a new
successful run – Repeat.
peter alvaro
[Alvaro et al., SIGMOD 2015]

Impact

Summary
• Coordination is the key remaining cost in cloud computing – Paxos, 2PC, etc.
• Q: When can coordination be avoided w/o inconsistency? A: CALM: exactly for monotonic programs
• Q: How can coordination be avoided practically? A: Application-level reasoning is the engine of innovation
• DSLs are reliable vehicles for that innovation – Patterns: Reinforce healthy design patterns – Theorems: Formal approaches supporting analysis and code synthesis – Software: Data-centric DSLs like Bloom are well-suited to the domain
<~ bloom

What’s Next?
• Double down – Reassess, redesign, reimplement
– Bootstrap off a high-performance kernel (L1-scale database?)
• Lock-free obsessions in recent DB and OS work echo themes
– Explore event-log-exchange more deeply
• Immutable. Fully monotonic?
• Attack some new domains – HCI, esp. Interaction and visualization
– Asynch ML
– Programming clouds in the large: Containers, orchestration
• Connections to synthesis – Maybe leave uses in a familiar
programming model, but synthesize the higher-level code
• Connections to other language themes – FRP – e.g. Rx, Akka, etc.
– Event programming for user interaction, e.g. D3.js
– Stronger typing as a means to improve CALM analysis, etc.
– Information Flow Control meets Data Lineage
– Approximation
• Software tools – Debugging distributed systems,
deployment, testing...


Getting Practical
• How can new PLs/libraries help? 1. Encourage monotonicity
2. Guard non-monotonicity cheaply
3. Enable checkers to test for nonmonotonicity and guard it
• Can we address hard debugging problems? 1. Consistency and Coordination
2. Fault tolerance
3. Garbage collection
• Can we define a nice PL that people can use?
• Performance in the small?

Hello, Clouds
$ rebl!stdio <~ [['Hello,'], ['Clouds']] !/tick!/q !

Sets
$ rebl !stdio <~ [['Hello,'], ['Clouds'], ['Clouds']] !/tick!/tick!/q !

Bloom State: Tables
$ rebl!table :clouds !clouds <= [[1, "Cirrus"], [2, "Cumulus"]] !stdio <~ clouds.inspected!

Bloom State: Tables
$ rebl!table :clouds !clouds <= [[1, "Cirrus"], [2, "Cumulus"]] !stdio <~ clouds.inspected !/tick !/lsrules !/rmrule 1 !/lsrules!!

State Mutation $rebl !table :clouds !clouds <= [[1, "Cirrus"], [2, "Cumulus"]] !clouds <- [[1, "Cirrus"]] !stdio <~ clouds.inspected !/tick !/tick !/lsrules !/rmrule 1 !/tick !!

Bloom State: scratch
$ rebl!scratch :passing_clouds!passing_clouds <= [[3, "Nimbus"], [2, "Cumulonimbus"]] !stdio <~ passing_clouds.inspected!/tick !/lsrules!/rmrule 1 !/tick !/q !

What have we learned so far? • rebl: the interactive Bloom terminal and its slash (/) commands. • Bloom collections: unordered sets of items, which are set up by collection
declarations. So far we have seen persistent table and transient scratch collections. By default, collections are structured as [key,val] pairs.
• Bloom statements: expressions of the form lhs op rhs, where the lhs is a collection and the rhs is either a collection or an array-of-arrays.
• Bloom timestep: an atomic single-machine evaluation of a block of Bloom statements.
• Bloom merge operators: • The <= merge operator for instantaneously merging things into a collection. • The <~ merge operator for asynchronously merging things into collections
outside the control of tick evaluation: e.g. terminal output. • stdio: a built-in Bloom collection that, when placed on the lhs of an asynch
merge operator <~, prints its contents to stdout. • inspected: a method of Bloom collections that transforms the elements to be
suitable for textual display on the terminal.