big data patterns with mahout
TRANSCRIPT

1
Big DataAnalysis PatternsAtlanta Big Data User Group8/15/2013

2
whoami• Brad Anderson
• Solutions Architect at MapR (Atlanta)
• ATLHUG co-chair
• NoSQL East Conference 2009
• “boorad” most places (twitter, github)

3
Announcements
Next ATLHUG Meeting - Sept. 26–How Google Does Big Data
Wednesday – MapR Data Warehouse Offload Roadshow
MapR Upcoming Training• MapR M7 & HBase for Developers on August 27 in Campbell, CA
• MapR M7 & HBase for Developers on Sept 17 in Reston, VA
• MapR M5 for Administrators on Oct 3 in Campbell, CA
3

4
BIG DATA

5

6
Big Data is not new!
but the tools are.

7
The Good News in Big Data:
“Simple algorithms and lots of data trump complex models”
Halevy, Norvig, and Pereira, GoogleIEEE Intelligent Systems

8
The Challenge: So Many Solutions!
What solutions fit your business problem?
For example, do you need…
Apache Hadoop?
Apache Mahout?
Storm?
Apache Solr/Lucene?
Apache HBase (or MapR M7)?
Apache Drill (or Impala?)
d3.js or Tableau?
Node.js
Titan?8

9
Ask a Different Question
It may be more useful to better define the problem by asking some of these questions:
How large is the data to be stored?
How large is the data to be queried? (the analysis volume)
What time frame is appropriate for your query response?
How fast is data arriving? (bursts or continuously?)
Are queries by sophisticated users?
Are you looking for common patterns or outliers?
How are your data sources structures?
9

10
Picking the Best Solution
Your responses to these questions can help you better:
define the problem
recognize the analysis pattern to which it belongs
guide the choice of solutions to try
But first, here’s a quick review of a few of the technologies you might choose, and then we will focus on three of the questions as a part of the landscape.
10

11
Apache Solr/Lucene
Solr/Lucene is a powerful search engine used for flexible, heavily indexed queries including data such as
Full text
Geographical data
Statistically weighted data
Solr is a small data tool that has flourished in a big data world

12
Apache Mahout
Mahout provides a library of scalable machine learning algorithms useful for big data analysis based on Hadoop or other storage systems.
Mahout algorithms mainly are used for
Recommendation (collaborative filtering)
Clustering
Classification
Mahout can be used in conjunction with solutions such as Solr: You might use Mahout to create a co-occurrence data base that could then be queried using a search tool such as Solr

13
Apache Drill
Google Dremel clone
Pluggable Query Languages– Starts with ANSI SQL 2003
– Hive, Pig, Cascading, MongoQL, …
Pluggable Storage Backends– Hadoop, Hbase
– MongoDB (BSON)
– RDBMS?
Bypasses MapReduce

14
Storm
Realtime Stream Computation Engine
Horizontal Scalability
Guaranteed Data Processing
Fault Tolerance
Higher level abstraction over:– Message Queues
– Worker Logic
“The Hadoop of Realtime”

15
Titan
Distributed Graph Database
Property Graph
Pluggable Backend Storage– HBase or M7
– Cassandra
– Berkeley DB
Search Integrated– Solr/Lucene
– Elastic Search
Faunus– Batch processing of large graphs
Fulgora– Graph traversals on subset
– In-memory

16
Using the Answers to Guide Your Choices
For simplicity, let’s focus in on the first three questions:
How large is the data to be stored?
How large is the data to be queried? (the analysis volume)
What time frame is appropriate for your query response?

17
Big Data Decision Tree
How big is your data?
<10 GB >200 GBmid
What size queries?
Single element at a time
One passover 100%
Multiple passesover big chunks
Big storage Streaming
Response time?
< 100s(human scale)
throughputnot response
A
B C
ED
??

18
Use Cases Company
Data Shape
Technique(s)
Business Value

19
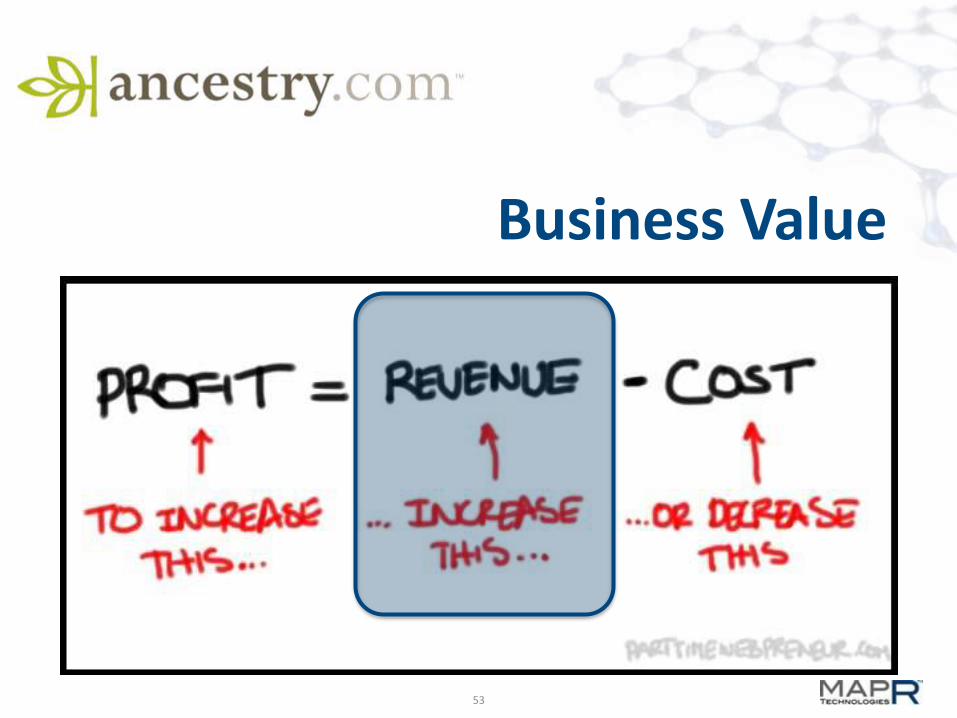
Business Value
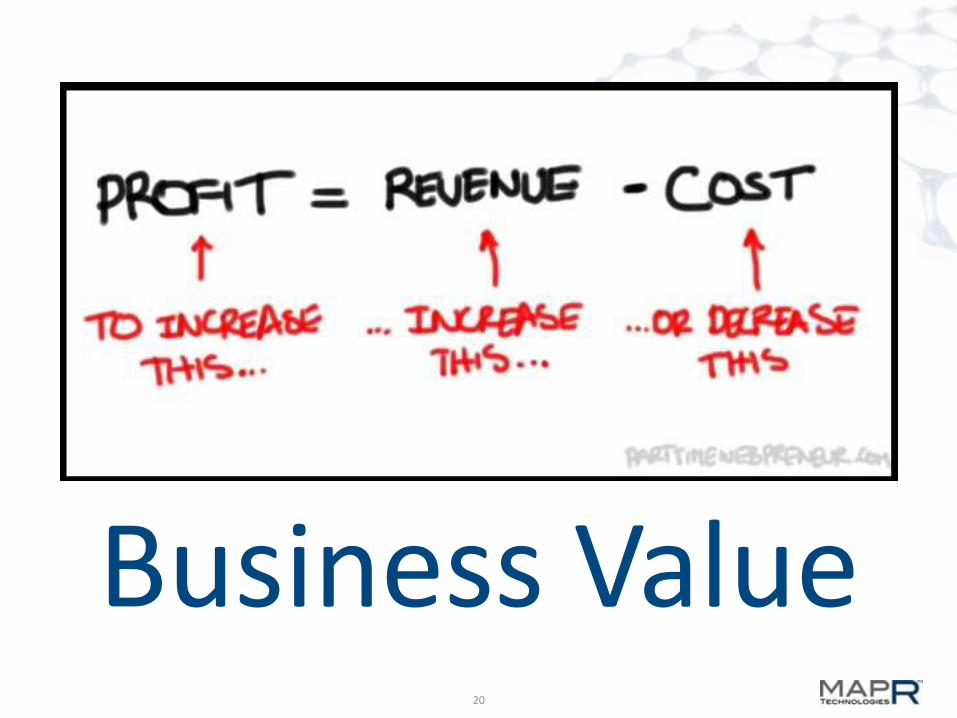
20
Business Value

21
Telecommunications Giant
ETL Offload

22
Lots of Data
Lots of Queries across Large Sets
Throughput important
Data ShapeTelecommunications

23
Techniques
AnalyticsETL
Telecommunications

24
Techniques
+
ETL (Hadoop) Analytics (Teradata)
Telecommunications

25
Business ValueTelecommunications

26
Credit CardIssuer

27
Customer Purchase History (big)
Merchant Designations
Merchant Special Offers
Throughput important
Recommendations
Data Shape
Credit CardIssuer

28
History matrix
One row per user
One column per thing
A Recommendation Engine with Mahout and Solr/Lucene
Techniques
Credit CardIssuer

29
Recommendation based on cooccurrence
Cooccurrence gives item-item mapping
One row and column per thing
Techniques
Credit CardIssuer

30
Cooccurrence matrix can also be implemented as a search index
Techniques
Credit CardIssuer
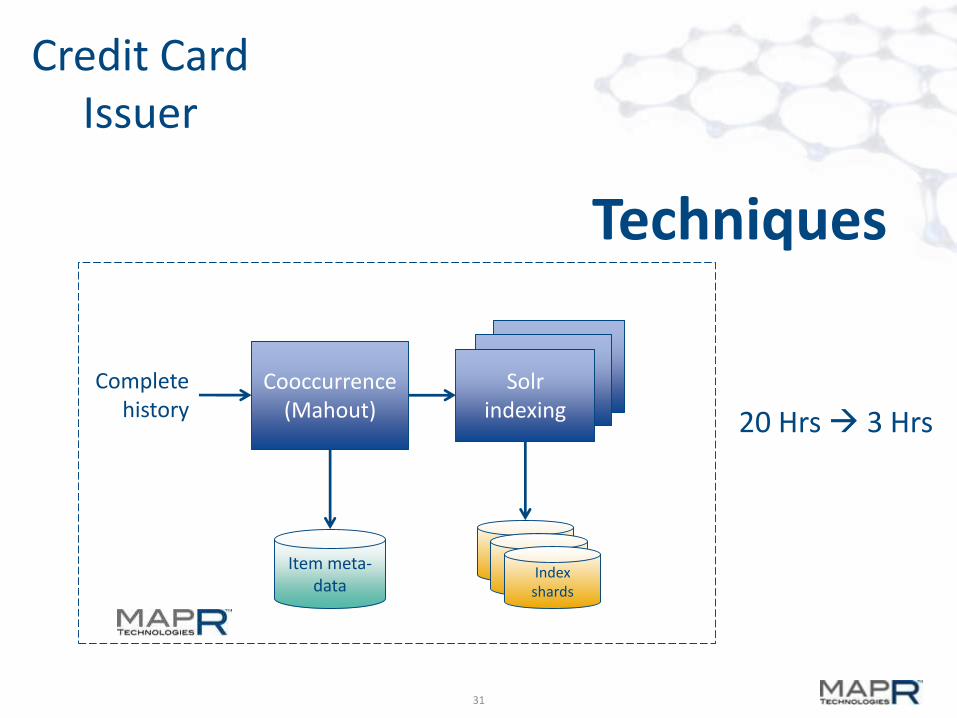
31
SolRIndexerSolR
IndexerSolr
indexingCooccurrence
(Mahout)
Item meta-data
Indexshards
Complete history
Techniques
20 Hrs 3 Hrs
Credit CardIssuer
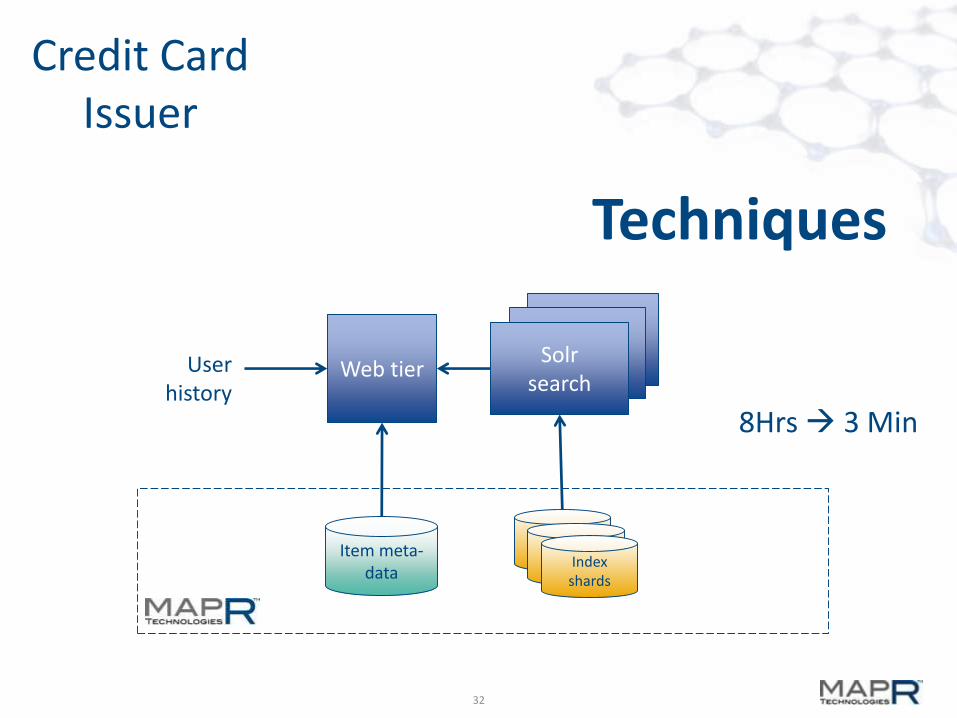
32
SolRIndexerSolR
IndexerSolr
searchWeb tier
Item meta-data
Indexshards
User history
Techniques
8Hrs 3 Min
Credit CardIssuer

33
Techniques
PurchaseHistory
Merchant Information
Merchant Offers
RecommendationEngine Results
(Mahout)
PresentationData Store
(DB2)
App
App
App
App
App
Hadoop Export(4 hrs)
Import(4 hrs)
Credit CardIssuer

34
Techniques
PurchaseHistory
Merchant Information
Merchant Offers
RecommendationEngine Results
(Mahout)
RecommendationSearch Index
(Solr)
App
App
App
App
App
Hadoop
IndexUpdate(3 min)
Credit CardIssuer

35
Business Value
Credit CardIssuer

36
Idle Alerts
Waste & Recycling Leader

37
Truck Geolocation Data– 20,000 trucks– 5 sec interval (arriving quickly)
Landfill Geographic Boundaries
Data Shape

38
Techniques
TruckGeolocation
Data
Realtime Stream Computation(Storm)
Batch Computation(MapReduce)
ImmediateAlerts
Tax ReductionReporting
HadoopStorage
Shortest PathGraph Algorithm
(Titan)
Route Optimization

39
Business Value

40
Social Engagement Application
Beverage Company

41
Tweets, FB Messages
Person, Activity links
Graph Traversal
Data Shape

42
Consumer Activity Graph
Wal*Mart.com
CVS
Dollar General
Ebay
Ebay Motors
Toys R UsStubHub
Shopping.com
Sam’s

43
Techniques
Property Graph(Titan)
Key/Value Store(MapR M7)
Social Activity Stream
Graph Traversal(Faunus/Fulgora)

44
Business Value

45
Fraud DetectionData Lake

46
Anti-Money Laundering
Consumer Transactions
Data Sources

47
TechniquesAnti-Money Laundering
SystemConsumer Transactions
System
48
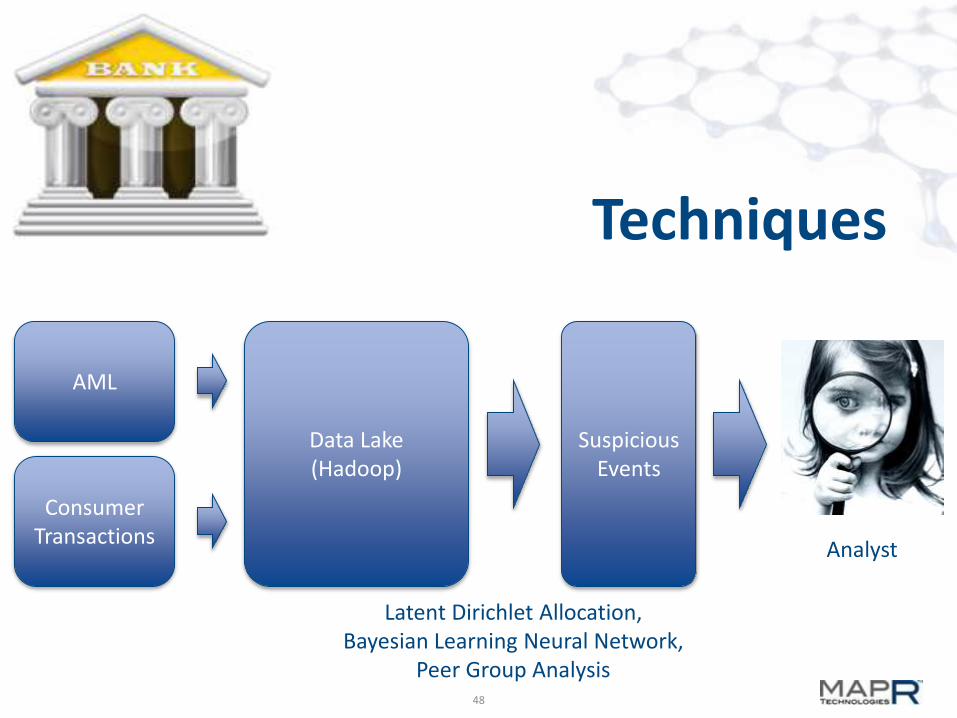
Techniques
AML
Consumer Transactions
Data Lake(Hadoop)
Suspicious Events
Latent Dirichlet Allocation,Bayesian Learning Neural Network,
Peer Group Analysis
Analyst

49
Business Value

50
Machine LearningSearch Relevance
DNA Matching

51
Birth, Death, Census, Military, Immigration records
Search Behavior Activity
DNA SNP (snips)
Data Sources

52
Techniques
Record Linking
Search Relevance
Clickstream Behavior
Security Forensics
DNA Matching
53
Business Value

54
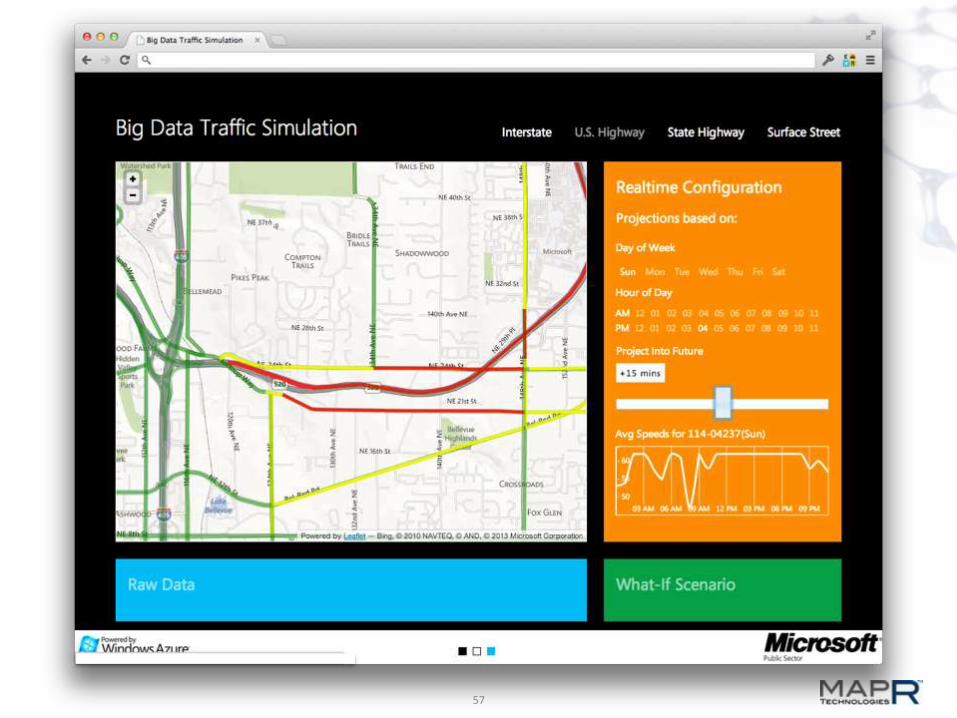
Traffic Analytics

55
Inrix Road Segment Data– Avg Speed / minute / segment– Reference Speeds
Road Segment Geolocation Data
Data Sources

56
Techniques
Bottleneck Detection Algorithm
Time Offset Correlations– Alternate Routes
Predictive Congestion Analysis– Growth & Term Assumptions
57

58

59
Business Value

60
Similar Characteristics Lots of Data
Structured, Semi-Structured, Unstructured
Varied Systems Interoperating– Hadoop, Storm, Solr, MPP, Visualizations
Increase Revenue
Decrease Costs

61
Questions?