big data, big corpus, and bigrams: calculating literary complexity nathaniel husted...
TRANSCRIPT

Big Data, Big Corpus, and Bigrams: Calculating Literary Complexity Nathaniel Husted [email protected]

You too can be a Big Data Scientist!

Terminology: Big Data Not a new concept (never believe marketers)
Moving target
Data sets large enough to cause extra considerations for processing and storage

Terminology: Big Corpora
Corpus (Plural: Corpora) – A sample set of texts for natural language processing.
Big Corpus – A very large, gigabyte level, set of texts.◦ Example: Corpus of Contemporary American English

Terminology: Bigrams
The Quick Brown Fox Leaves.
Also known as a Digram or n-gram for n=2.

Terminology: Bigrams
The Quick Brown Fox Leaves.
Also known as a Digram or n-gram for n=2.

Terminology: Bigrams
The Quick Brown Fox Leaves.
Also known as a Digram or n-gram for n=2.

Terminology: Bigrams
The Quick Brown Fox Leaves.
Also known as a Digram or n-gram for n=2.

Terminology: Literary Complexity
The Complexity of a Story.◦ Qualitative◦ How intertwined are the plot lines◦ How deep are the themes◦ How rich are the characters◦ How much attention it takes on the part of the read to comprehend the
whole
Examples of Complex Litearture:◦ Finnegan’s Wake by James Joyce◦ Foucault’s Pendulum by Umberto Eco

Terminology: A Little Graph Theory
Directed Edge
Undirected Edge
Vertex
Loop

Let’s Put Them All Together… Structural Complexity
How can we quantitatively measure the complexity of a novel?◦ Structural Complexity!◦ Biologists use structure to measure the complexity of molecules◦ System Scientists use it to measure the complexity of networks
What is Structural Complexity?◦ The amount of information contained in the relationship between elements
of a network.

Metrics of Structural Complexity
Normalized Edge Complexity (NEC)◦ How many unique bigrams there were versus the theoretical maximum.
Average Edge Complexity (AEC)◦ Average number of unique bigrams per word.
Shannon Information (SI)
Vertex degree magnitude-based Information (IVD)
http://www.vcu.edu/csbc/pdfs/quantitative_measures.pdf

Structural Complexity In Literature: Bigrams as Structural Cues
To use our structural complexity measures, we must “graph” our novel.
Bigrams provide a clear notion of a “graph edge”
Bigrams link work associations together

Structural Complexity In Literature: Bigrams as Structural Cues The Quick Brown Fox Leaves The House.
The
Quick
Brown
Fox
Leaves
House

How do we implement all these concepts? Python!
◦NetworkX◦NLTK◦XMLTree
SQLite (xargs)

What is our process?1. Choose our Corpus
2. Organize our Corpus
3. Parse our Corpus
4. Analyze our Graphs
5. Process our Results

Choosing our Corpus Project Gutenberg to the Rescue
◦ Tens of thousands of texts◦ Most, if not all, are in text formats (ASCII, ISO, UTF-8)◦ Convenient ISO Downloads◦ Public Domain!
Number of works: 19852
Number of authors: 7049
https://www.cs.Indiana.edu/~nhusted/project_source/pgdvd-en-corpus.tar.bz2

Organizing our Corpus Project Gutenberg provides a RDF Card Catalogue of their library.
Querying a 250+ MB RDF file with RDF libraries is SLOW.
Parsing with Python’s xml.etree.cElementTree is fast!
Due to Unicode Characters, Python 3 is a must.
Storing results in SQLite give us a compact, quickly searchable, format.

Parsing our Corpus in to Graphs!
Python, NetworkX, and NLTK to the rescue.
NLTK allows quick parsing of the novels.
NetworkX provides the easy to use graph library with algorithms.

Analyzing Our Graphs’ Structural Complexity
IVD
AEV

Storing and Analyzing the Results
Store the results in SQLite ◦ Conveniently searchable, still.◦ Conveniently readable in R.
Use R for Statistical Analysis◦ Personal Preference
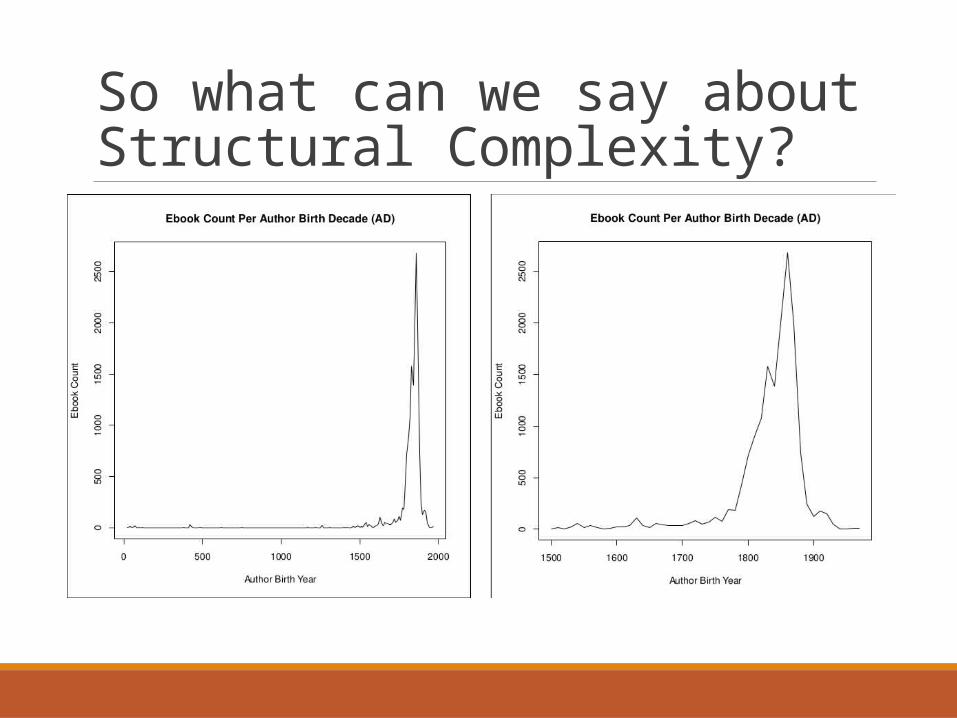
So what can we say about Structural Complexity?

It seems to have dropped in the late 1800s

Structural Complexity is Analogous to Literary Complexity
Determine authors who have literature deemed “complex”
Publisher’s Weekly Top 10 Most Difficult Books: http://www.publishersweekly.com/pw/by-topic/industry-news/tip-sheet/article/53409-the-top-10-most-difficult-books.html

Structural Complexity is Analogous to Literary Complexity
http://www.publishersweekly.com/pw/by-topic/industry-news/tip-sheet/article/53409-the-top-10-most-difficult-books.html

Structural Complexity is Analogous to Literary Complexity
http://www.publishersweekly.com/pw/by-topic/industry-news/tip-sheet/article/53409-the-top-10-most-difficult-books.html

Structural Complexity is Analogous to Literary Complexity
http://www.publishersweekly.com/pw/by-topic/industry-news/tip-sheet/article/53409-the-top-10-most-difficult-books.html

Conclusions Structural Complexity is analogous to qualitative measurements of literary complexity
Structural Complexity even allows comparison of novels to other structures such as DNA and protein-protein sequences
Results are preliminary◦ Data is not Gaussian◦ Still some catalog creation errors◦ “Big Data” is still sparse

Big Conclusion: Open Source Science!
Results are Creative Commons!
Code is GPL V3!
Dataset is public domain!
You can do your own analysis!
http://cgi.cs.indiana.edu/~nhusted/dokuwiki/doku.php?id=projects:graphalyzer
https://github.iu.edu/nhusted/GutenbergGraphalyzer
You too can be a Big Data Scientist!