big data .. are you ready for the next wave?
TRANSCRIPT

Big Data…Are you ready for the next wave?
MAHMOUD SABRY

Agenda
The Next Wave of Computing
Information, Data & Knowledge
Data warehouse vs. Database
Row-oriented vs. Column-oriented DB
Big Data Era
HP-Vertica
HP-Vertica Bulk Upload Example
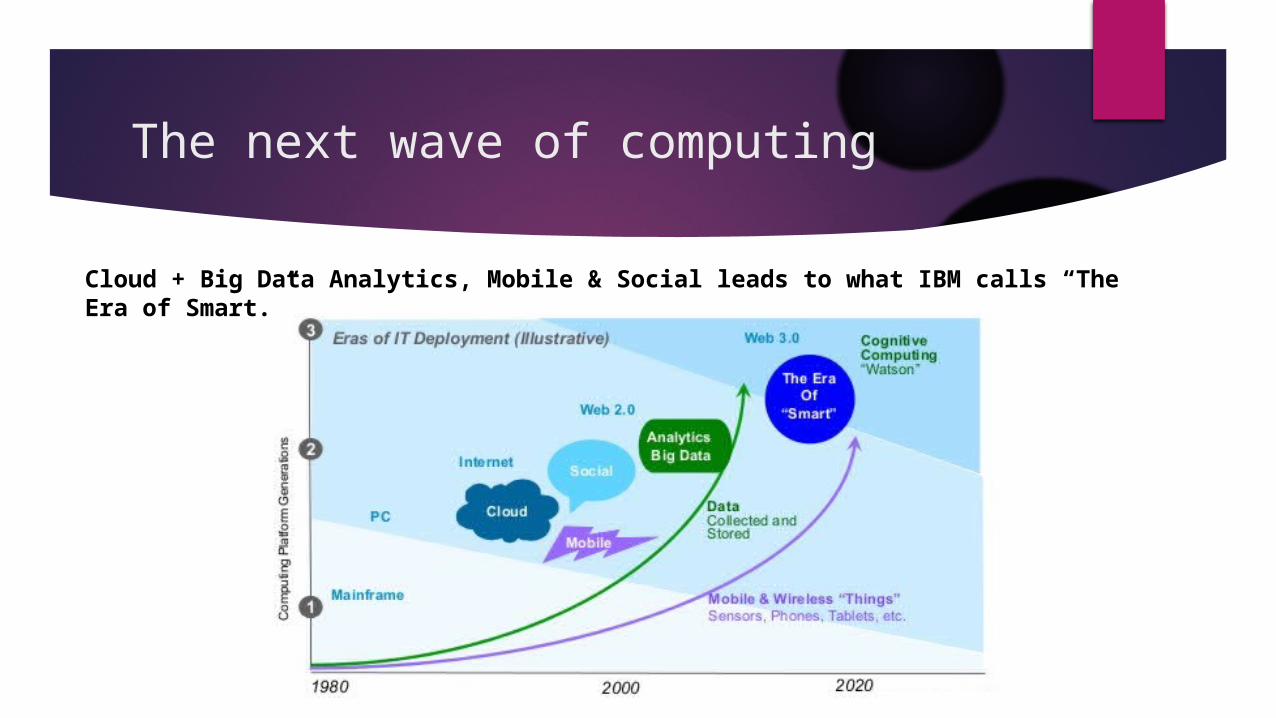
The next wave of computing
Cloud + Big Data Analytics, Mobile & Social leads to what IBM calls “The Era of Smart.”

Data, Information & Knowledge (1/3)
Data are raw facts, and have no meaning on their own
Example
Yes, Yes, No, Yes, No, Yes, No, Yes

Data, Information & Knowledge (2/3)
Information is data that have meaning in a context
Example
Yes, Yes, No, Yes, No, Yes, No, Yes, No, Yes, YesRaw Data
ContextResponses to the market
research question – “Would you buy brand x at price y?”
Information ???
Processing

Data, Information & Knowledge (3/3)
Knowledge
understanding of someone or something
acquired through experience or learning
Example
Based on last collected information, A Marketing Manager could use this information to decide whether or not to raise or lower price.

Data Warehouse vs. Database (1/2)
Feature DWH DB
Data Stored It usually stores the Historical data whose accuracy is maintained over time.
It mainly stores the Current data which always guaranteed to be up-to-date.
Characteristic It is based on Informational Processing.
It is based on Operational Processing.
Function It is used for long-term informational requirements and decision support.
It is used for day-to-day operations.
Focus The focus is on “Information OUT” The focus is on “Data IN”
Number of records accessed
A bunch of millions of records. A few tens of records.

Data Warehouse vs. Database (2/2)
Feature DWH DB
Access It mostly use the read access for the stored data.
The most frequent type of access type is read/write.
Orientation Based on Analysis. Based on Transaction.
Common users
Analysts DBAs
KPI Query throughput Transaction throughput
Unit of work Complex queries Short and simple transactions
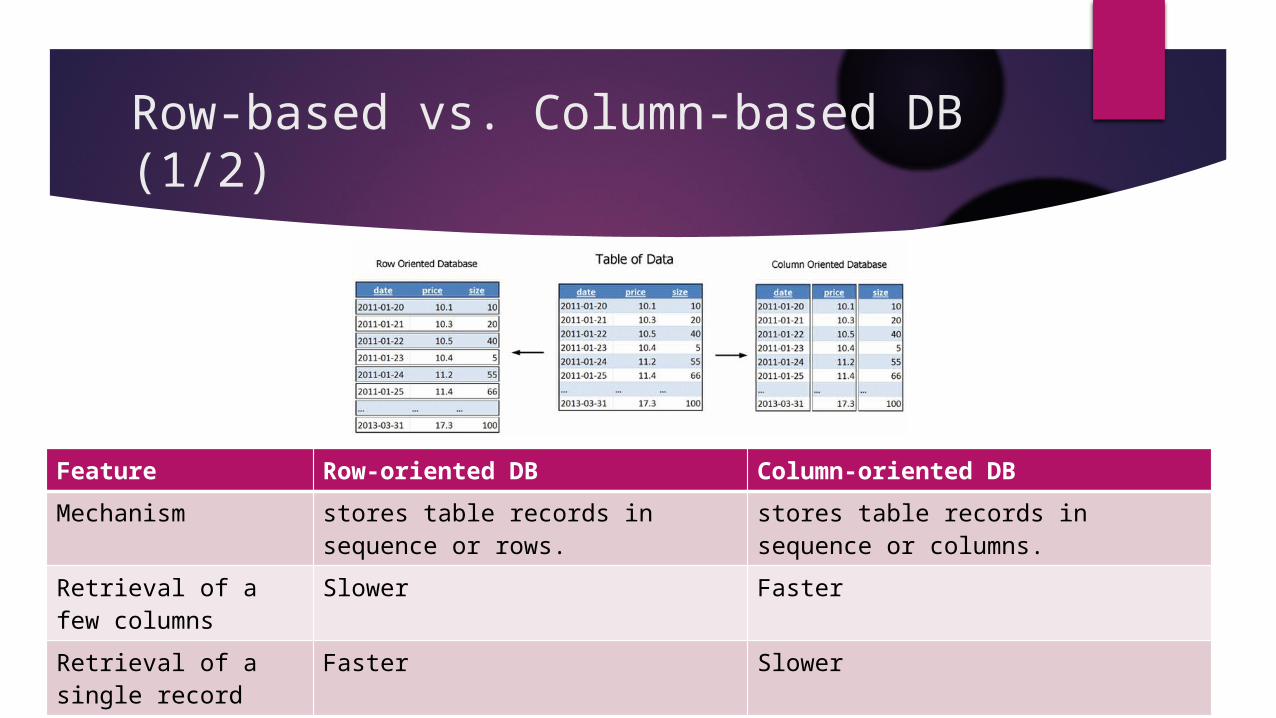
Row-based vs. Column-based DB (1/2)
Feature Row-oriented DB Column-oriented DB
Mechanism stores table records in sequence or rows.
stores table records in sequence or columns.
Retrieval of a few columns
Slower Faster
Retrieval of a single record
Faster Slower

Row-based vs. Column-based DB (2/2)
Feature Row-oriented DB Column-oriented DB
Insertion/Updating of single new record
Faster Slower
Aggregation of Single Column, e.g. sum(price)
Slower Faster
Compression Higher. As stores similar data together
It depends!
Examples Oracle OLTPMS SQL Server up to 2008
HP-VerticaSybase IQMS SQL Server 2012

Big Data Era – Famous quote
From the dawn of civilization until 2003, humankind generated five exabytes of data. Now we produce five exabytes every two days…and the pace is accelerating.
Eric Schmidt,Executive Chairman, Google

Big Data – Definition
The basic idea behind the phrase 'Big Data' is that everything we do is increasingly leaving a digital trace (or data), which we (and others) can use and analyze.
Big Data therefore refers to our ability to make use of the ever-increasing volumes of data.

Big Data – Characteristics (6 V’s)
Volume Terabytes, Distributed, Tables & Files
Velocity Real-time processing/Streams
Variety Structured, Semi-structured & Un-structured data
Value Correlations & Statistical analysis
Veracity Accountability, Trust, Origin & Reputation
Variability Changing Data/model

Big Data – What is Hadoop ?
Apache™ Hadoop® is an open source platform that enables distributed processing of large data sets across clusters of servers.
It is designed to scale up from a single server to thousands of machines, with very high degree of fault tolerance.

Big Data – HL Archit. Of Hadoop
A programming model for large scale data processing.
A distributed file-system that stores data on Clustered machines.
Schedules map or reduce jobs to task trackers with an awareness of the data location.
keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept.

Big Data – MapReduce, How it works ?
Map: Filter & sort of data Reduce: Summarize & aggregate of data

HP-Vertica
An analytic database management platform. Founded in 2005.
Helps you monetize all of your data in real-time and at massive scale.
Queries run 50-1,000x faster.
Store 10-30x more data per server.
Openness and simplicity (use any BI/ETL tools, Hadoop, etc.)
Suited for “Structured” data only.
HP Vertica Flex Zone: built on the HP Vertica core, enables load and analyze structured and semi-structured data, such as social media, sensor, log files, and machine data.

HP-Vertica Features (1/6)
Column Orientation
Vertica organizes data for each column
Each column is stored separately on disk
Only reads the columns needed to answer the query
Significant reduction of disk I/O

HP-Vertica Features (2/6)
Advanced Compression
Vertica replaces slower disk I/O with faster CPU cycles to encode data elements into a more compact form
and query them.
Vertica’s innovative query engine operates directly on compressed data, meaning that it can actually require fewer CPU operations to process the compressed version of a table.

HP-Vertica Features (3/6)
High Availability
RAID-like functionality within database
If a node fails, a copy is available on one of the surviving nodes
Always-on Queries and Loads
System continues to load and query when nodes are down
Automatically recovers missing data by querying other nodes

HP-Vertica Features (4/6)
Automatic Database Designer (DBD)
Recommends a physical DB design that provides the best performance for the user's workload
Analyzes your logical schema, sample data, and sample queries
Minimizes DBA tuning
Run anytime for additional optimization, without stopping the database

HP-Vertica Features (5/6)
Massively Parallel Processing (MPP)
Parallel design leverages data projections to enable distributed storage and workload
Active redundancy
Automatic replication, failover and recovery

HP-Vertica Features (6/6)
Native SQL and Application Integration
Standard SQL Interface
Simple integration with Hadoop and existing BI and ETL tools
Supports SQL, ODBC, JDBC and majority ETL and BI reporting products

HP-Vertica Bulk Upload Example (1/3)
HP Vertica 7.0, Single instance on VMware workstation v.11
Installed on Windows 8 machine HP-EliteBook 8440p, 8GB RAM
HP Vertica virtual machine has below specs:
Memory: 4GB
Disk: 16 GB
Processor: Single Processor Intel(R) Core(TM) i7 CPU M 620 @ 2.67GHz

HP-Vertica Bulk Upload Example (2/3)
Scenario Details
Upload a table with “|” delimited columns from a local text file
Table file size is: 1.30099 GB
No. of rows is: 10252864
No. of columns Is: 21
Table is partitioned into 10 partitions by using “customer_age“ column
Only one projection (the default “<table_name>_Super” )

HP-Vertica Bulk Upload Example (3/3)
Scenario Actions and Results
Upload by using “DIRECT” option to load directly to disk (ROS: Read Optimized Storage)
COPY public.myTable from '/opt/vertica/examples/VMart_Schema/myTable.tbl' DIRECT;
Time taken is more than 4 minutes
Upload without using “DIRECT” option to load to memory(WOS: Write Optimized Storage)
COPY public.myTable from '/opt/vertica/examples/VMart_Schema/myTable.tbl';
Time taken is about 2.3 minutes

Thanks!