big data architectural patterns and best practices on aws
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Rahul Bhartia
Partner Solution Architect
July 13, 2016
Big Data Architectural Patterns and
Best Practices on AWS

What to expect from this session
• Simplify big data processing
• Understand the technologies
• Leverage design patterns

Architectural principles applied to big data
• Basics
• Highly available, durable and scalable
• Use the right tool
• Data structure, access patterns, cost
• Decoupled design
• Data bus — immutable streams
• Stateless design
• Data repository — projections (data stores)

Evolution of Big Data
Architecture

Databases
Transactions
Data
warehouse
Evolution of big data architecture
Extract, transform and load (ETL)

Databases
Files
Transactions
Logs
Data
warehouse
Evolution of big data architecture
ETL
ETL

Databases
Files
Streams
Transactions
Logs
Events
Data
warehouse
Evolution of big data architecture
? Hadoop ?
ETL
ETL

A growing ecosystem…
Amazon
Glacier
Amazon S3 Amazon
DynamoDB
Amazon
RDS
Amazon EMR
Amazon
Redshift
AWS Data
Pipeline
Amazon Kinesis Amazon
CloudSearch
Amazon
Kinesis-
enabled app
AWS Lambda Amazon
Machine
Learning
Amazon
SQS
Amazon
ElastiCache
Amazon
DynamoDB
Streams

Collect and Store
Databases
Files
Streams
Transactions
Logs
Events
Data
warehouseHadoop
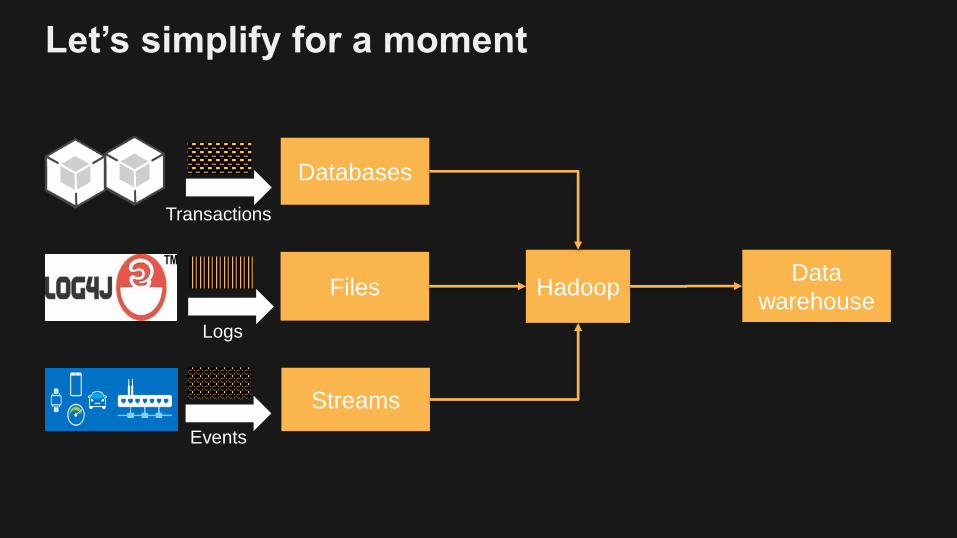
Let’s simplify for a moment

Files
Streams
Logs
Events
Data
WarehouseHadoop
Collect — transactions
Transactions
Extract
Amazon
RDS
Amazon
DynamoDB
Change data capture
Amazon DynamoDB
Streams
AWS Database
Migration Service

Hadoop
Databases
Streams
Transactions
Events
Data
Warehouse
Collect — logs
Log
collectorsLogs

Logs
Files Hadoop
Databases
Transactions
Data
Warehouse
Collect — streams
Events Amazon
Kinesis
Apache
Kafka
AWS
Lambda
Amazon
Kinesis
application
Spark
Streaming
Apache
Storm

Data
Warehouse
Streams
Events
Logs
Files
Databases
Transactions
Store — data repository
Hadoop
Search
Access
QueryProcess
Archive

HadoopData
Warehouse
Streams
Events
Logs
Files
Databases
Transactions
AWS — data repository
Search
Access
QueryProcess
Archive
Amazon
RDS
Amazon
DynamoDB
Amazon
Elasticsearch
Service
Amazon
Glacier
Amazon S3
Amazon
Redshift
Amazon Elastic
MapReduce
Amazon
Machine Learning
Amazon
ElastiCache

What data store should I use?
Amazon
ElastiCache
Amazon
DynamoDB
Amazon
Aurora
Amazon
Redshift
Amazon
ES
Amazon S3 Amazon
Glacier
Type Cache NoSQL SQL (DB) SQL (DW) Search Storage Archive
Average
latency
Milliseconds Milliseconds Milliseconds
– Seconds
Seconds Milliseconds –
Seconds
Relative to
size
Hours
Data
volume
MBs GB–TBs
(no limit)
GB–TB
(64 TB Max)
GB–TB GB–TB MB–PB
(no limit)
GB–PB
(no limit)
Item size KBs KB
(400 KB max)
KB
(64 KB)
MB
(1 MB max)
MB
(1 MB max)
MB–GB
(5 TB max)
GB
(40 TB max)
Cost
GB/month
$$ ¢¢ ¢¢ ¢¢ ¢¢ ¢ ¢/10

Cost-conscious design
“...many small files, perhaps up to a billion during peak.
The total size would be on the order of 1.5 TB per month…
Should I use Amazon S3 or Amazon DynamoDB? ”
https://calculator.s3.amazonaws.com/index.html

Events
Logs
Transactions
Design Pattern: Collect and store
Amazon
RDS
Amazon
DynamoDB
Amazon
ES
Amazon
S3
Amazon
Redshift
D
a
t
a
b
u
s
Data
repository
Amazon
RDS
Amazon
DynamoDB
AWS
DMS
Amazon
Kinesis
Streams
Amazon
Kinesis
Firehose

Why data bus?
• Decoupled producers and consumers
• Immutable streams of events
• Write once; read many times
• Multiple consumers

What about queues and pub/sub ?
• Decouple producers and
consumers/subscribers
• Persistent buffer
• Collect multiple streams
• No client ordering
• No parallel consumption for
Amazon SQS
• Amazon SNS can route
to multiple queues or ʎ
functions
• No streaming MapReduce
Consumers
Producers
Producers
Amazon SNS
Amazon SQS
queue
topic
function
ʎ
AWS Lambda
Amazon SQSqueue
Subscriber

Why data repository?
• Decoupled storage — create compute sized for the
workload
• Immutable history — recompute facts as desired
• Multiple projections — as needed (query, search,
compute)

Why Amazon S3 for big data?
• Natively supported by frameworks like — Spark, Hive, Presto, etc.
• Can run transient Hadoop clusters
• Multiple clusters can use the same data
• Designed for 99.999999999% durability
• Low cost at $0.03 per GB per month

Process and Analyze

Process / analyze
• Interactive — seconds on warm/cold data
• Self-service dashboards
• Batch — minutes or hours on cold data
• Daily / weekly / monthly reports
• Streaming — milliseconds or seconds on hot data
• Billing/fraud alerts, 1-minute metrics

Process / analyze
• Interactive query : Amazon Redshift,
Presto, Impala, Spark-SQL, Hive (Tez)
• Data processing: MapReduce, Pig, Spark,
Hive (MR)
• Streaming: Spark Streaming, AWS
Lambda, Amazon KCL
Amazon
Redshift
Presto
Pig
Streaming
Amazon
Kinesis app
AWS
Lambda
Am
azo
n E
lasti
c M
ap
Red
uce
Flink, Storm,
Apex

Design pattern — interactive querying
Amazon
Kinesis
Streams
Presto
Spark-SQL
Hive (Tez)
Amazon
Redshift
Amazon
S3
Kinesis
Analytics
Ad hoc
Streams
Reports

Which query tool should I use?
Amazon EMR (Hive, Presto, Spark) Amazon Redshift
Scale / Throughput ~ Nodes ~Nodes
Storage Amazon S3 Local Storage
Optimization Framework dependent Columnar storage, Data compression, and
Zone maps
Metadata Hive Meta-store Redshift Managed
BI tools supports Yes (JDBC/ODBC & Custom) Yes (JDBC/ODBC)
Access controls Integration with LDAP Users, Groups and Access Controls
UDF support Yes Yes (Scalar)
Use-case Ad-hoc data query Optimized for Data Warehousing

Design pattern — event analytics
Producer
Amazon
Kinesis
Streams
Amazon
KCL
AWS
Lambda
Spark
Streaming
Amazon EMR
Amazon
SNS
Amazon
ES
Amazon
DynamoDB
Amazon
RDS
Amazon
Redshift
Analysis
Amazon
S3
Storm, Flink,
othersAmazon Kinesis
Analytics
Notifications

Which Stream Processing Technology Should I Use?
Amazon EMR
(Spark
Streaming)
Apache Storm,
Apache Flink,
Apache Apex
Kinesis Client
Library
AWS Lambda
Scale /
throughput
~ Nodes ~ Nodes ~ Nodes Automatic
Reliability KCL and Spark
check points
Framework
managed
Managed by KCL Managed by Lambda
Uses Multistage
processing
Single stage
processing
Simple event
based triggers
Manageability Yes (Amazon
EMR)
Do it yourself Amazon EC2 +
Auto Scaling
AWS Managed
Fault tolerance Single AZ Configurable Multi AZ Multi AZ
Programming
languages
Java, Python,
Scala
Almost any
language
Java, others via
MultiLangDaemon
Node.js, Java

Design pattern — microbatch analytics
Amazon
Kinesis
Firehose
Amazon
Redshift
Amazon
S3
Presto Spark-SQL
Reports
Adhoc

Consume
• Business users
• Metrics/KPIs
• Data analysts/scientists
• Notebooks
• Applications
• API
• Predictions
Bu
sin
ess
inte
llig
en
ce
Amazon
QuickSight
IDE
/no
teb
oo
ks
AP
Is
Amazon
Big Data
Competency
Partners
Amazon
Machine
Learning
Vis
ualizati
on
s

Machine learning
The ability to learn without being explicitly programmed
- Supervised learning ← “Teach” program- Classification ← Is this transaction fraud? (yes/no)
- Regression ← Customer lifetime value?
- Unsupervised learning ← Let it learn by itself- Clustering ← Market segmentation
- Deep learning ← “Feature Generation”- Neural Networks ← Image Recognition
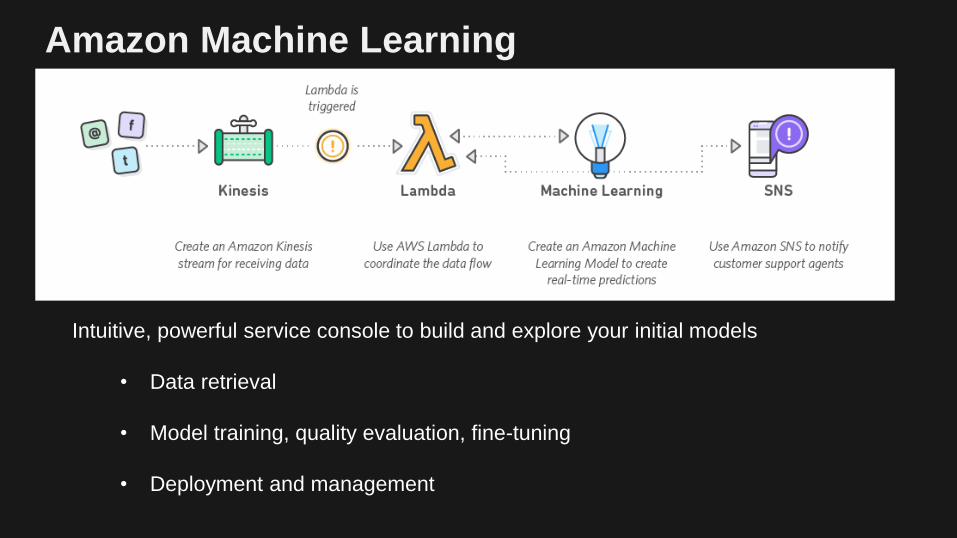
Amazon Machine Learning
Intuitive, powerful service console to build and explore your initial models
• Data retrieval
• Model training, quality evaluation, fine-tuning
• Deployment and management

Design pattern: Closed loop systems
Amazon S3
Amazon
EMR
Amazon
MLConsume
Amazon
Redshift
Amazon
DynamoDB
Amazon
API Gateway
Batch
prediction
Real-time
prediction
Infrastructure
intelligence
Harness data generated from
your systems and infrastructure
Advanced
analytics
Anticipate future behaviors and
conduct what-if analysis
Big data partner solutions
Solutions vetted by the AWS Partner Competency Program
Data
integration
Move, synchronize, cleanse,
and manage data
Data analysis and
visualization
Turn data into actionable insight
and enhance decision making

AWS
instance
type
High
memory
X1
Compute
optimized C4
Storage
optimized D2
General
purpose M4
Memory
optimize R3
IO
optimized
I2
Graphics
optimized
G2
Intel processorIntel Xeon
E7-8880 v3
Custom Intel
Xeon E5-2666 v3
Custom Intel
Xeon E5-2676 v3
Custom Intel
Xeon E5-2676 v3
Intel Xeon
E5-2670 v2
Intel Xeon
E5-2670 v2
Intel Xeon
E5-2670
Intel AVX AVX 2.0 AVX 2.0 AVX 2.0 AVX 2.0 Yes Yes Yes
Intel AES-NI Yes Yes Yes Yes Yes Yes No
Intel Turbo Boost Yes Yes Yes Yes Yes Yes Yes
Intel TSX Yes No No No No No No
SSD storage EBS EBS No EBS Yes Yes Yes
AWS & Intel® = Better Together
https://software.intel.com/en-us/articles/caffe-training-on-multi-node-distributed-memory-systems-based-on-intel-xeon-processor-e5
10+ year partnershipEC2 instances with Intel® technologies

Amazon SQS apps
Streaming
Amazon Kinesis
Analytics
Amazon KCL
apps
AWS Lambda
Amazon Redshift
COLLECT STORE CONSUMEPROCESS / ANALYZE
Amazon Machine
Learning
Presto
Amazon
EMR
Amazon Elasticsearch
Service
Apache Kafka
Amazon SQS
Amazon Kinesis
Streams
Amazon Kinesis
Firehose
Amazon DynamoDB
Amazon S3
Amazon ElastiCache
Amazon RDS
Amazon DynamoDB
Streams
Ho
tH
ot
Wa
rm
Fa
st
Slo
wF
ast
Batc
hM
essag
eIn
tera
cti
ve
Str
eam
ML
Searc
h
SQ
L
N
oS
QL
Cach
eF
ile
Qu
eu
eS
tream
Amazon EC2
Mobile apps
Web apps
Devices
MessagingMessage
Sensors and
IoT platformsAWS IoT
Data centersAWS Direct
Connect
AWS Import/ExportSnowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
RECORDS
DOCUMENTS
FILES
MESSAGES
STREAMS
Amazon QuickSight
Apps & Services
An
aly
sis
& v
isu
ali
zati
on
No
teb
oo
ks
IDE
AP
I
Lo
gg
ing
IoT
Ap
pli
cati
on
sT
ran
sp
ort
Messag
ing
ETL
Reference architecture

Summary
• Use the right tool for the job
• Latency, throughput, access patterns
• Decoupled “data bus”
• Data → Store ↔ Process → Answers
• Leverage managed services
• No/low admin
• Lambda architecture ideas
• Immutable (append-only) log, batch/speed/serving layer
• Be cost conscious
• Big data ≠ Big cost

Remember to complete
your evaluations!

Thank you!