better exploiting os-cnns for better event recognition in...
TRANSCRIPT

Better Exploiting OS-CNNs for Better Event Recognitionin Images
Limin Wang, Zhe Wang, Sheng Guo, Yu Qiao
Shenzhen Institutes of Advanced Technology, CAS, China
December 12, 2015
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 1 / 23

Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 2 / 23
Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 3 / 23

Introduction
Figure: Examples of cultural event recognition dataset.
Event recognition in still images is very important for imageunderstanding, just like object and scene recognition.
Event is a complex concept and relevant to many other factors,including objects, human poses, human garments and scenecategories.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 4 / 23

Motivations
Object, scene, and event are three highly related concepts inhigh-level computer vision research.
As event is highly relevant with object and scene, transferringeffective representations learned for object and scenerecognition will be a reasonable choice. (our OS-CNN work)
Both global and local representations of CNNs will help inevent recognition and are complementary to each other. (ourTDD work)
L. Wang, Z. Wang, W. Du, and Y. Qiao Object-scene convolutional neural networks forevent recognition in images, in CVPR ChaLearn Workshop, 2015.
L. Wang, Y. Qiao, and X. Tang Action recognition with trajectory-pooleddeep-convolutional descriptors, in CVPR, 2015.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 5 / 23
Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 6 / 23
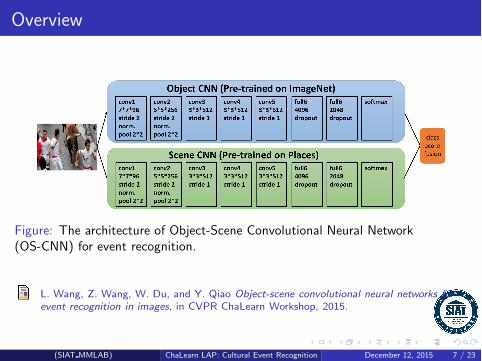
Overview
Figure: The architecture of Object-Scene Convolutional Neural Network(OS-CNN) for event recognition.
L. Wang, Z. Wang, W. Du, and Y. Qiao Object-scene convolutional neural networks forevent recognition in images, in CVPR ChaLearn Workshop, 2015.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 7 / 23

OS-CNNs
Object-Scene Convolutional Neural Networks are composed of two nets
Object nets: capturing useful information of objects to help eventrecognition.
We build object nets based on recent advances on object recognitionand pre-train it on the ImageNet dataset.
Scene nets: extracting scene information to assist event recognition.
We construct scene nets with the help of recent works on scenerecognition and pre-train it on the Places dataset.
Based on previous analysis, event is highly relevant with object and scene.Thus, we combine the recognition scores of both object and scene nets:
s(I) = αoso(I) + αsss(I).
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 8 / 23

Implementation Details
Network structure: we choose VGGNet-19 as our investigationstructure [1].
Learning policy: pre-train OS-CNNs with ImageNet-VGGNet models[1] and Places205-VGGNet models [2] + fine tuning.
Data augmentations: we use common data augmentationtechniques, such as corner crop, scale jittering, and horizontal flipping.
Speed up: we design a Multi-GPU extension version of Caffetoolbox, that is publicly available [3].
K. Simonyan, and A. Zisserman Very deep convolutional networks for large-scale imagerecognition, in ICLR, 2015.
L. Wang, S. Guo, W. Huang, and Y. Qiao Places205-VGGNet models for scenerecognition, in arXiv 1508.01667.
L. Wang, Y. Xiong, Z. Wang, and Y. Qiao Towards good practices for very deeptwo-stream ConvNets, in arXiv 1507.02159.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 9 / 23

Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 10 / 23

Scenario 1: OS-CNN Predictions
In this scenario, we directly use the outputs (softmax layer) ofOS-CNNs as final prediction results.
sos(I) = αoso(I) + αsss(I),
so(I) and ss(I) are the prediction scores of object nets and scene nets,αo and αs are their fusion weights.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 11 / 23

Scenario 2: OS-CNN Global Representations (pre-training)
In this scenario, we treat OS-CNNs as generic feature extractors andextract the global representation of an image region.
In this case, we only use the pre-trained models without fine-tuning.
Specifically, we use the activations of fully connected layers asfollows:
φpos(I) = [βoφ
po(I), βsφ
ps (I)],
φpo(I) and φ
ps (I) are the CNN activations from pre-trained object nets
and scene nets, βo and βs are the fusion weights.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 12 / 23

Scenario 3: OS-CNN Global Representations (pre-training+ fine tuning)
In this scenario, We consider fine-tuning the OS-CNNs on the eventrecognition dataset and the resulted image representations becomedataset-specific.
After fine-tuning process, we obtain the following globalrepresentation with the fine-tuned OS-CNNs:
φfos(I) = [βoφ
fo(I), βsφ
fs (I)],
φfo(I) and φf
s (I) are the CNN activations from the fine-tuned objectnets and scene nets, βo and βs are the fusion weights.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 13 / 23

Scenario 4: OS-CNN Local Representations (pre-training+ fine tuning)
We consider exploring the activations of convolutional layers and wecall them as local representations of OS-CNNs.
After extracting OS-CNN local representations, we use channel
normalization and spatial normalization to pre-process them intotransformed convolutional feature maps !C (I) ∈ Rn×n×c .
The normalized CNN activation !C (I)(x , y , :) ∈ Rc at each postion iscalled as the Transformed Deep-convolutional Descriptor (TDD).
Finally, we employ Fisher vector to encode these TDDs into a globalrepresentation.
L. Wang, Y. Qiao, and X. Tang Action recognition with
trajectory-pooled deep-convolutional descriptors, in CVPR, 2015.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 14 / 23

Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 15 / 23

Experiment Setup
The challenge dataset contains 100 event classes (99 event classes +1 background) and it is divided into three parts: (i) development data(14,332 images), (ii) validation data (5,704 images), (iii) evaluationdata (8669 images)
As we can not access the label of evaluation data, we mainly train ourmodels on the development data and report the results on thevalidation data.
For final evaluation, we merge the development data and validationdata into a single training dataset and re-train our OS-CNN modelson this new dataset.
In our exploration experiments, we report our results evaluated as APvalue for each class and mAP value for all classes.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 16 / 23
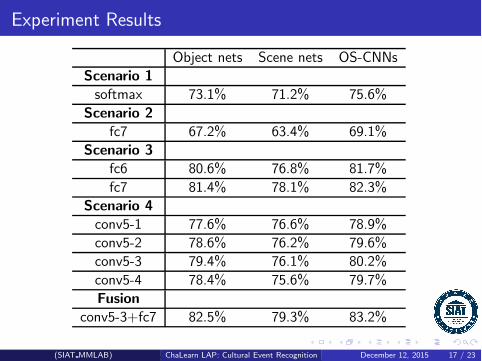
Experiment Results
Object nets Scene nets OS-CNNsScenario 1softmax 73.1% 71.2% 75.6%
Scenario 2fc7 67.2% 63.4% 69.1%
Scenario 3fc6 80.6% 76.8% 81.7%fc7 81.4% 78.1% 82.3%
Scenario 4conv5-1 77.6% 76.6% 78.9%conv5-2 78.6% 76.2% 79.6%conv5-3 79.4% 76.1% 80.2%conv5-4 78.4% 75.6% 79.7%Fusion
conv5-3+fc7 82.5% 79.3% 83.2%
Table: Event recognition performance of OS-CNN global and local(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 17 / 23

Experiment Results (cont’d)
Object nets outperform scene nets and the combination of themimproves recognition performance.
Combining fine tuned features with linear SVM classifier (scenario 3)is able to obtain better performance than direct using the softmaxoutput of CNNs (scenario 1).
Comparing fine-tuned features (scenario 3) with pre-trained features(scenario 2), we may conclude that fine tuning on the target datasetis very useful.
Global representations (scenario 3) is better than local ones (scenario4) and the combination of them further boots the recognitionperformance.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 18 / 23
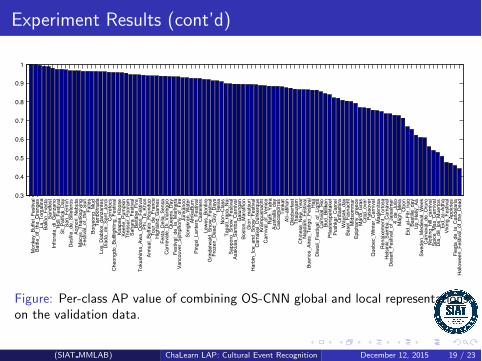
Experiment Results (cont’d)
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Monkey_Buffet_Festival
Battle_of_the_O
ranges
La_Tom
atina
Ballon_Fiesta
Sandfest
Infiorata_di_Genzano
Holi_Festival
St_Patrick_Day
San_Fermin
Desfile_de_Silleteros
Aomori_Nebuta
Macys_Thanksgiving
Festival_of_the_Sun
Falles
Boryeong_M
udTamborrada
Los_Diablos_danzantes
Diada_de_Sant_Jordi
Correfocs
Cheongdo_Bullfighting_Festival
Kaapse_Klopse
Keene_Pumpkin
Thrissur_Pooram
Sahara_Festival
Beltane_Fire
Tokushima_Aw
a_Odori_Festival
Phi_Ta_Khon
Annual_Buffalo_R
oundup
Tour_de_France
Highland_Gam
esFesta_Della_Sensa
Carnevale_D
i_Viareggio
Queens_Day
Festival_de_la_M
arinera
Vancouver_Symphony_of_Fire
Junkanoo
Songkran_W
ater
AfrikaBurn
Pingxi_Lantern_Festival
Castellers
Lewes_Bonfire
Grindelwald_Snow
_Festival
Frozen_D
ead_Guy_D
ays
Heiva
Non−C
lass
Tapati_rapa_N
uiSapporo_Snow
_Festival
Asakusa_Samba_C
arnival
Galungan
Boston_M
arathon
Gion_matsuri
Harbin_Ice_and_Snow
_Festival
Carnaval_Dunkerque
Kram
pusnacht
Carnival_of_Venice
Rath_Yatra
Australia_day
Cascamorras
Timkat
Ati−atihan
Oktoberfest
Thaipusam
Chinese_N
ew_Year
Naadam_Festival
Buenos_Aires_Tango_Festival
Hajj
Diwali_Festival_of_Lights
Carnival_Rio
Bud_Billiken
Pflasterspektakel
Pushkar_Cam
elOnbashira
Waysak_day
Basel_Fasnacht
Midsommar
Epiphany_greece
Mardi_G
ras
Crop_over
Passover
Quebec_Winter_Carnival
Maslenitsa
Renaixement_Tortosa
Helsinki_Samba_C
arnaval
Desert_Festival_of_Jaisalmer
4_de_Julio
Magh_Mela
Obon
Eid_al−Fitr_Iraq
Bastille_day
Up_Helly_Aa
Sweden_M
edieval_Week
Carnaval_de_O
ruro
Notting_hill_carnival
Spice_Mas_C
arnival
Dia_de_los_Muertos
Eid_al−Adha
Viking_Festival
Apokries
Fiesta_de_la_C
andelaria
Halloween_Festival_of_the_Dead
Figure: Per-class AP value of combining OS-CNN global and local representationson the validation data.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 19 / 23

Experiment Results (cont’d)
Figure: Examples of images that our method succeeds and fails in top-1evaluation.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 20 / 23
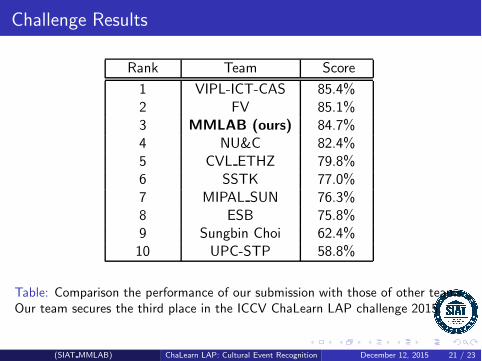
Challenge Results
Rank Team Score
1 VIPL-ICT-CAS 85.4%2 FV 85.1%3 MMLAB (ours) 84.7%4 NU&C 82.4%5 CVL ETHZ 79.8%6 SSTK 77.0%7 MIPAL SUN 76.3%8 ESB 75.8%9 Sungbin Choi 62.4%10 UPC-STP 58.8%
Table: Comparison the performance of our submission with those of other teams.Our team secures the third place in the ICCV ChaLearn LAP challenge 2015.
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 21 / 23

Outline
1 Introduction
2 OS-CNNs Revisited
3 Exploring OS-CNNs
4 Experiments
5 Conclusions
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 22 / 23

Conclusions
We have presented a new architecture for event recognition, calledobject-scene convolutional neural networks (OS-CNN), by capturingeffective information from the perspectives of object and scene.
From our experimental results, object nets outperform scene nets onevent recognition, and the combination of them further improveperformance.
We comprehensively study four scenarios to better exploit OS-CNNsfor better cultural event recognition.
Global representations (fully connected layers) is a bit better thanlocal representations (convolutional layers) and the combination ofthem further boots the recognition performance.
code and model coming soon at https://wanglimin.github.io
(SIAT MMLAB) ChaLearn LAP: Cultural Event Recognition December 12, 2015 23 / 23