benefits of using mongodb over rdbmss
TRANSCRIPT

An Evening with MongoDB Chicago
March 3rd, 2015
#MongoDB

• Quick MongoDB Overview
• Benefits Using MongoDB Over RDBMSs
• MongoDB 3.0 Update
• ShopperTrak: Small Blobs & Big Logs
• MongoDB Community Update
• More Q&A with MongoDB Experts
Agenda

Benefits Using MongoDB Over RDBMSs
Sr. Solution Architect, MongoDB Inc.
@matthewkalan
Matt Kalan
#MongoDB

• Quick MongoDB Overview
• Benefits using MongoDB over RDBMSs
• What’s New in v3.0
Agenda

Why MongoDB

The World Has Changed
Data
• Volume
• Velocity
• Variety
Time
• Iterative
• Agile
• Short Cycles
Risk
• Always On
• Scale
• Global
Cost
• Open-Source
• Cloud
• Commodity

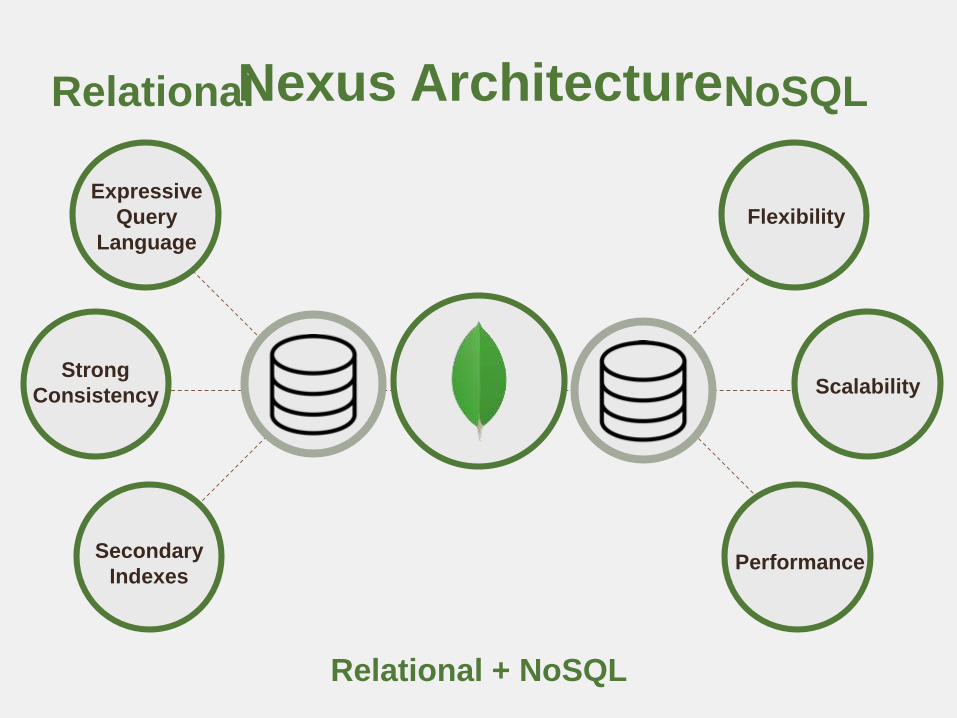
Expressive
Query
Language
Strong
Consistency
Secondary
Indexes
Flexibility
Scalability
Performance
Relational

NoSQL
Expressive
Query
Language
Strong
Consistency
Secondary
Indexes
Flexibility
Scalability
Performance
Expressive
Query
Language
Strong
Consistency
Secondary
Indexes
Flexibility
Scalability
Performance
Relational NoSQLNexus Architecture
Relational + NoSQL
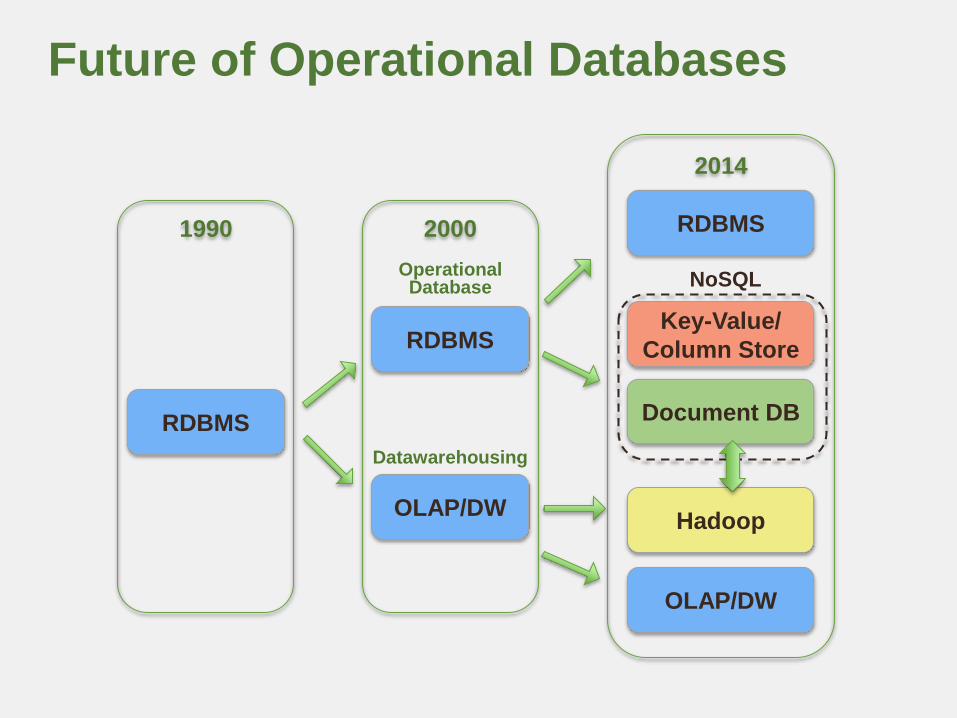
Future of Operational Databases
2014
RDBMS
Key-Value/
Column Store
OLAP/DW
Hadoop
2000
RDBMS
OLAP/DW
1990
RDBMS
Operational Database
Datawarehousing
Document DB
NoSQL

Match the Data in your Application for Better Performance & Agility
Relational MongoDB
{ customer_id : 1,
first_name : "Mark",
last_name : "Smith",
city : "San Francisco",
phones: [ {
number : “1-212-777-1212”,
dnc : true,
type : “home”
},
{
number : “1-212-777-1213”,
type : “cell”
}]
}
Customer ID
First Name Last Name City
0 John Doe New York
1 Mark Smith San Francisco
2 Jay Black Newark
3 Meagan White London
4 Edward Daniels Boston
Phone Number Type DNCCustomer
ID
1-212-555-1212 home T 0
1-212-555-1213 home T 0
1-212-555-1214 cell F 0
1-212-777-1212 home T 1
1-212-777-1213 cell (null) 1
1-212-888-1212 home F 2
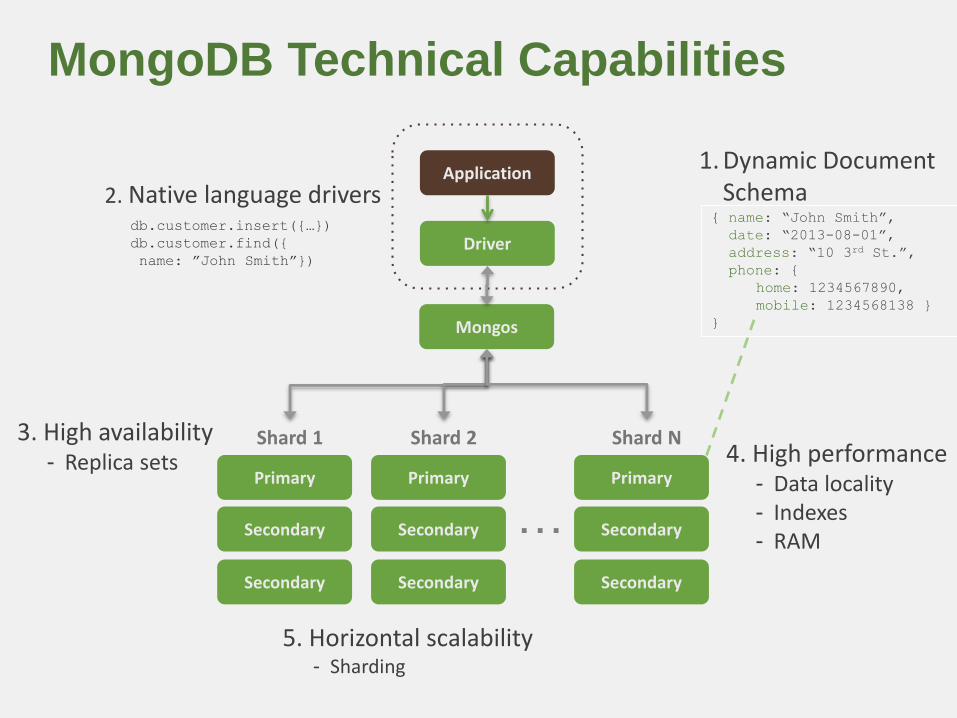
MongoDB Technical Capabilities
Application
Driver
Mongos
Primary
Secondary
Secondary
Shard 1
Primary
Secondary
Secondary
Shard 2
…Primary
Secondary
Secondary
Shard N
db.customer.insert({…})
db.customer.find({
name: ”John Smith”})
1. Dynamic Document Schema
{ name: “John Smith”,
date: “2013-08-01”,
address: “10 3rd St.”,
phone: {
home: 1234567890,
mobile: 1234568138 }
}
2. Native language drivers
4. High performance- Data locality- Indexes- RAM
3. High availability- Replica sets
5. Horizontal scalability- Sharding

Comparing Development in SQL to MongoDB

Adding and testing business features
OR
Integrating with other components, tools, and systems
Database(s)
ETL and other data transfer operations
Messaging
Services (web & other)
Other open source frameworks incl. ORMs
What Are Developers Doing All Day?

Why Can’t We Just Save and Fetch Data?
Because the way we think about data at the
business use case level…
…which traditionally is VERY different than the
way it is implemented at the database level
…is different than the way it is implemented at
the application/code level…

This Problem Isn’t New…
…but for the past 40 years, innovation at the business & application layers
has outpaced innovation at the database layer
1974 2014
Business
Data Goals
Capture my company’s
transactions daily at
5:30PM EST, add them up
on a nightly basis, and print
a big stack of paper
Capture my company’s global transactions in real-time
plus everything that is happening in the world
(customers, competitors, business/regulatory/weather),
producing any number of computed results, and passing
this all in real-time to predictive analytics with model
feedback; results in real-time to 10000s of mobile
devices, multiple GUIs, and b2b and b2c channels
Release
Schedule
Semi-Annually Yesterday
Application
/Code
COBOL, Fortran, Algol,
PL/1, assembler,
proprietary tools
C, C++, VB, C#, Java, javascript, groovy, ruby, perl
python, Obj-C, SmallTalk, Clojure, ActionScript, Flex,
DSLs, spring, AOP, CORBA, ORM, third party software
ecosystem, the whole open source movement, … and
COBOL and Fortran
Database I/VSAM, early RDBMS Mature RDBMS, legacy I/VSAM
Column & key/value stores, and…mongoDB

Exactly How Does MongoDB Change Things?
• MongoDB is designed from the ground up to
address rich structure (maps of maps of lists
of…), not just tables• Standard RDBMS interfaces (i.e. JDBC) do not exploit features
of contemporary languages
• Object Oriented Languages and scripting in Java, C#,
Javascript, Python, Node.js, etc. is impedance-matched to
MongoDB
• In MongoDB, the data is the schema
• Shapes of data go in the same way they come
out

Rectangles are 1974. Maps and Lists are 2014
{ customer_id : 1,
first_name : "Mark",
last_name : "Smith",
city : "San Francisco",
phones: [ {
type : “work”,
number: “1-800-555-1212”
},
{ type : “home”,
number: “1-800-555-1313”,
DNC: true
},
{ type : “home”,
number: “1-800-555-1414”,
DNC: true
}
]
}

An Actual Code Example (Finally!)
Let’s compare and contrast RDBMS/SQL to MongoDB
development using Java over the course of a few weeks.
Some ground rules:1. Observe rules of Software Engineering 101: assume separation of application,
data access layer (DAL), and persistor implementation
2. DAL must be able to
a. Expose simple, functional, data-only interfaces to the application
• No ORM, frameworks, compile-time bindings, special tools
b. Exploit high performance features of the persistor
3. Focus on core data handling code and avoid distractions that require the same
amount of work in both technologies
a. No exception or error handling
b. Leave out DB connection and other setup resources
4. Day counts are a proxy for progress, not actual time to complete indicated task

The Task: Saving and Fetching Contact data
Map m = new HashMap();
m.put(“name”, “matt”);
m.put(“id”, “K1”);
Start with this simple,
flat shape in the Data
Access Layer:
save(Map m)And assume we
save it in this way:
Map m = fetch(String id)And assume we
fetch one by primary
key in this way:
Brace yourself…..

Day 1: Initial efforts for both technologies
DDL: create table contact ( … )
init()
{
contactInsertStmt = connection.prepareStatement
(“insert into contact ( id, name ) values ( ?,? )”);
fetchStmt = connection.prepareStatement
(“select id, name from contact where id = ?”);
}
save(Map m)
{
contactInsertStmt.setString(1, m.get(“id”));
contactInsertStmt.setString(2, m.get(“name”));
contactInsertStmt.execute();
}
Map fetch(String id)
{
Map m = null;
fetchStmt.setString(1, id);
rs = fetchStmt.execute();
if(rs.next()) {
m = new HashMap();
m.put(“id”, rs.getString(1));
m.put(“name”, rs.getString(2));
}
return m;
}
SQLDDL: none
save(Map m)
{
collection.insert(
new BasicDBObject(m));
}
MongoDB
Map fetch(String id)
{
Map m = null;
DBObject dbo = new BasicDBObject();
dbo.put(“id”, id);
c = collection.find(dbo);
if(c.hasNext()) }
m = (Map) c.next();
}
return m;
}

Day 2: Add simple fields
m.put(“name”, “matt”);
m.put(“id”, “K1”);
m.put(“title”, “Mr.”);
m.put(“hireDate”, new Date(2011, 11, 1));
• Capturing title and hireDate is part of adding a new
business feature
• It was pretty easy to add two fields to the structure
• …but now we have to change our persistence code
Brace yourself (again) …..

SQL Day 2 (changes in bold)DDL: alter table contact add title varchar(8);
alter table contact add hireDate date;
init()
{
contactInsertStmt = connection.prepareStatement
(“insert into contact ( id, name, title, hiredate ) values
( ?,?,?,? )”);
fetchStmt = connection.prepareStatement
(“select id, name, title, hiredate from contact where id =
?”);
}
save(Map m)
{
contactInsertStmt.setString(1, m.get(“id”));
contactInsertStmt.setString(2, m.get(“name”));
contactInsertStmt.setString(3, m.get(“title”));
contactInsertStmt.setDate(4, m.get(“hireDate”));
contactInsertStmt.execute();
}
Map fetch(String id)
{
Map m = null;
fetchStmt.setString(1, id);
rs = fetchStmt.execute();
if(rs.next()) {
m = new HashMap();
m.put(“id”, rs.getString(1));
m.put(“name”, rs.getString(2));
m.put(“title”, rs.getString(3));
m.put(“hireDate”, rs.getDate(4));
}
return m;
}
Consequences:1. Code release schedule linked
to database upgrade (new
code cannot run on old
schema)
2. Issues with case sensitivity
starting to creep in (many
RDBMS are case insensitive
for column names, but code is
case sensitive)
3. Changes require careful mods
in 4 places
4. Beginning of technical debt

MongoDB Day 2
save(Map m)
{
collection.insert(m);
}
Map fetch(String id)
{
Map m = null;
DBObject dbo = new BasicDBObject();
dbo.put(“id”, id);
c = collection.find(dbo);
if(c.hasNext()) }
m = (Map) c.next();
}
return m;
}
Advantages:1. Zero time and money spent on
overhead code
2. Code and database not physically
linked
3. New material with more fields can
be added into existing collections;
backfill is optional
4. Names of fields in database
precisely match key names in
code layer and directly match on
name, not indirectly via positional
offset
5. No technical debt is created
✔ NO
CHANGE

Day 3: Add list of phone numbers
m.put(“name”, “matt”);
m.put(“id”, “K1”);
m.put(“title”, “Mr.”);
m.put(“hireDate”, new Date(2011, 11,
1));
n1.put(“type”, “work”);
n1.put(“number”, “1-800-555-1212”));
list.add(n1);
n2.put(“type”, “home”));
n2.put(“number”, “1-866-444-3131”));
list.add(n2);
m.put(“phones”, list);• It was still pretty easy to add this data to the structure
• .. but meanwhile, in the persistence code …
REALLY brace yourself…

SQL Day 3 changes: Option 1: Assume just 1 work and 1 home phone numberDDL: alter table contact add work_phone varchar(16);
alter table contact add home_phone varchar(16);
init()
{
contactInsertStmt = connection.prepareStatement
(“insert into contact ( id, name, title, hiredate,
work_phone, home_phone ) values ( ?,?,?,?,?,? )”);
fetchStmt = connection.prepareStatement
(“select id, name, title, hiredate, work_phone,
home_phone from contact where id = ?”);
}
save(Map m)
{
contactInsertStmt.setString(1, m.get(“id”));
contactInsertStmt.setString(2, m.get(“name”));
contactInsertStmt.setString(3, m.get(“title”));
contactInsertStmt.setDate(4, m.get(“hireDate”));
for(Map onePhone : m.get(“phones”)) {
String t = onePhone.get(“type”);
String n = onePhone.get(“number”);
if(t.equals(“work”)) {
contactInsertStmt.setString(5, n);
} else if(t.equals(“home”)) {
contactInsertStmt.setString(6, n);
}
}
contactInsertStmt.execute();
}
Map fetch(String id)
{
Map m = null;
fetchStmt.setString(1, id);
rs = fetchStmt.execute();
if(rs.next()) {
m = new HashMap();
m.put(“id”, rs.getString(1));
m.put(“name”, rs.getString(2));
m.put(“title”, rs.getString(3));
m.put(“hireDate”, rs.getDate(4));
Map onePhone;
onePhone = new HashMap();
onePhone.put(“type”, “work”);
onePhone.put(“number”, rs.getString(5));
list.add(onePhone);
onePhone = new HashMap();
onePhone.put(“type”, “home”);
onePhone.put(“number”, rs.getString(6));
list.add(onePhone);
m.put(“phones”, list);
}
This is just plain bad….

SQL Day 3 changes: Option 2:Proper approach with multiple phone numbersDDL: create table phones ( … )
init()
{
contactInsertStmt = connection.prepareStatement
(“insert into contact ( id, name, title, hiredate )
values ( ?,?,?,? )”);
c2stmt = connection.prepareStatement(“insert into
phones (id, type, number) values (?, ?, ?)”;
fetchStmt = connection.prepareStatement
(“select id, name, title, hiredate, type, number from
contact, phones where phones.id = contact.id and
contact.id = ?”);
}
save(Map m)
{
startTrans();
contactInsertStmt.setString(1, m.get(“id”));
contactInsertStmt.setString(2, m.get(“name”));
contactInsertStmt.setString(3, m.get(“title”));
contactInsertStmt.setDate(4, m.get(“hireDate”));
for(Map onePhone : m.get(“phones”)) {
c2stmt.setString(1, m.get(“id”));
c2stmt.setString(2, onePhone.get(“type”));
c2stmt.setString(3, onePhone.get(“number”));
c2stmt.execute();
}
contactInsertStmt.execute();
endTrans();
}
Map fetch(String id)
{
Map m = null;
fetchStmt.setString(1, id);
rs = fetchStmt.execute();
int i = 0;
List list = new ArrayList();
while (rs.next()) {
if(i == 0) {
m = new HashMap();
m.put(“id”, rs.getString(1));
m.put(“name”, rs.getString(2));
m.put(“title”, rs.getString(3));
m.put(“hireDate”, rs.getDate(4));
m.put(“phones”, list);
}
Map onePhone = new HashMap();
onePhone.put(“type”, rs.getString(5));
onePhone.put(“number”, rs.getString(6));
list.add(onePhone);
i++;
}
return m;
}
This took time and money

SQL Day 5: Zombies! (zero or more between entities)
init()
{
contactInsertStmt = connection.prepareStatement
(“insert into contact ( id, name, title, hiredate )
values ( ?,?,?,? )”);
c2stmt = connection.prepareStatement(“insert into
phones (id, type, number) values (?, ?, ?)”;
fetchStmt = connection.prepareStatement
(“select A.id, A.name, A.title, A.hiredate, B.type,
B.number from contact A left outer join phones B on
(A.id = B. id) where A.id = ?”);
}
Whoops! And it’s also wrong!We did not design the query accounting
for contacts that have no phone number.
Thus, we have to change the join to an
outer join.
But this ALSO means we have to change
the unwind logic
This took more time and
money!
while (rs.next()) {
if(i == 0) {
// …
}
String s = rs.getString(5);
if(s != null) {
Map onePhone = new HashMap();
onePhone.put(“type”, s);
onePhone.put(“number”, rs.getString(6));
list.add(onePhone);
}
}
…but at least we have a DAL…
right?

MongoDB Day 3
Advantages:1. Zero time and money spent on
overhead code
2. No need to fear fields that are
“naturally occurring” lists
containing data specific to the
parent structure and thus do not
benefit from normalization and
referential integrity
3. Safe from zombies and other
undead distractions from productivity
save(Map m)
{
collection.insert(m);
}
Map fetch(String id)
{
Map m = null;
DBObject dbo = new BasicDBObject();
dbo.put(“id”, id);
c = collection.find(dbo);
if(c.hasNext()) }
m = (Map) c.next();
}
return m;
}
✔ NO
CHANGE

By Day 14, our structure looks like this:
n4.put(“geo”, “US-EAST”);
n4.put(“startupApps”, new String[] { “app1”, “app2”, “app3” } );
list2.add(n4);
n4.put(“geo”, “EMEA”);
n4.put(“startupApps”, new String[] { “app6” } );
n4.put(“useLocalNumberFormats”, false):
list2.add(n4);
m.put(“preferences”, list2)
n6.put(“optOut”, true);
n6.put(“assertDate”, someDate);
seclist.add(n6);
m.put(“attestations”, seclist)
m.put(“security”, mapOfDataCreatedByExternalSource);
• It was still pretty easy to add this data to the structure
• Want to guess what the SQL persistence code looks like?
• How about the MongoDB persistence code?

SQL Day 14
Error: Could not fit all the code into this space.
…actually, I didn’t want to spend 2 hours putting the code together..
But very likely, among other things:
• n4.put(“startupApps”,new String[]{“app1”,“app2”,“app3”});
was implemented as a single semi-colon delimited string
• m.put(“security”, anotherMapOfData);
was implemented by flattening it out and storing a subset of fields

MongoDB Day 14 – and every other day
Advantages:1. Zero time and money spent on
overhead code
2. Persistence is so easy and flexible
and backward compatible that the
persistor does not upward-
influence the shapes we want to
persist i.e. the tail does not wag
the dog
save(Map m)
{
collection.insert(m);
}
Map fetch(String id)
{
Map m = null;
DBObject dbo = new BasicDBObject();
dbo.put(“id”, id);
c = collection.find(dbo);
if(c.hasNext()) }
m = (Map) c.next();
}
return m;
}
✔ NO
CHANGE

But what about “real” queries?
• MongoDB query language is a physical map-of-
map based structure, not a String• Operators (e.g. AND, OR, GT, EQ, etc.) and arguments are
keys and values in a cascade of Maps
• No grammar to parse, no templates to fill in, no whitespace,
no escaping quotes, no parentheses, no punctuation
• Same paradigm to manipulate data is used to
manipulate query expressions
• …which is also, by the way, the same paradigm
for working with MongoDB metadata and
explain()

MongoDB Query Examples
SQL CLI select * from contact A, phones B where
A.did = B.did and B.type = 'work’;
MongoDB CLI db.contact.find({"phones.type”:”work”});
SQL in Java String s = “select * from contact A, phones B
where A.did = B.did and B.type = \'work\’”;
ResultSet rs = execute(s);
MongoDB via
Java driver
DBObject expr = new BasicDBObject();
expr.put(“phones.type”, “work”);
Cursor c = contact.find(expr);
Find all contacts with at least one work phone

MongoDB Query Examples
SQL select A.did, A.lname, A.hiredate, B.type,
B.number from contact A left outer join phones B
on (B.did = A.did) where b.type = 'work' or
A.hiredate > '2014-02-02'::date
MongoDB CLI db.contacts.find({"$or”: [
{"phones.type":”work”},
{"hiredate": {”$gt": new ISODate("2014-02-
02")}}
]});
Find all contacts with at least one work phone or
hired after 2014-02-02

MongoDB Query Examples
MongoDB via
Java driver
List arr = new ArrayList();
Map phones = new HashMap();
phones.put(“phones.type”, “work”);
arr.add(phones);
Map hdate = new HashMap();
java.util.Date d = dateFromStr(“2014-02-02”);
hdate.put(“hiredate”, new BasicDBObject(“$gt”,d));
arr.add(hdate);
Map m1 = new HashMap();
m1.put(“$or”, arr);
contact.find(new BasicDBObject(m1));
Find all contacts with at least one work phone or
hired after 2014-02-02

…and before you ask…
Yes, MongoDB query expressions
support
1. Sorting
2. Cursor size limit
3. Projection (asking for only parts of the rich
shape to be returned)
4. Aggregation (“GROUP BY”) functions

The Fundamental Change with mongoDB
RDBMS designed in era when:
• CPU and disk was slow &
expensive
• Memory was VERY expensive
• Network? What network?
• Languages had limited means to
dynamically reflect on their types
• Languages had poor support for
richly structured types
Thus, the database had to
• Act as combiner-coordinator of
simpler types
• Define a rigid schema
• (Together with the code) optimize
at compile-time, not run-time
In mongoDB, the
data is the schema!

What Does All This Add Up To?
• MongoDB easier than RDBMS/SQL for real
problems
• Quicker to change
• Much better harmonized with modern languages
• Comprehensive indexing (arbitrary non/unique
secondaries, compound keys, geospatial, text
search, TTL, etc….)
• Horizontally scalable to petabytes
• Isomorphic HA and DRModern Database for Modern
Solutions
+
=

What’s New in MongoDB 3.0

• WiredTiger Storage Engine and Flexible Storage Architecture
• Ops Manager
• Enhanced Query Language and Tools
• Advanced Security and Auditing
• Low-Latency Experience Across the Globe
MongoDB 3.0 Headlines

Pluggable Storage API New Storage Engine: WiredTiger

Flexible Storage Architecture
● Vision: Many storage engines optimized for many different use cases
● One data model, one API, one set of operational concerns – but under
the hood, many options for every use case under the sun
Content
Repo
IoT Sensor
BackendAd Service
Customer
AnalyticsArchive
MongoDB Query Language (MQL) + Native Drivers
MongoDB Document Data Model
MMAP V1 WT In-Memory HDFSProprietary
Storage
Supported in MongoDB 3.0 Future Possible Storage Engines
Managem
ent
Se
curity
Example Future State
Experimental in
MongoDB 3.0

WiredTiger Storage Engine
• Same data model, same query
language, same ops
• Write performance gains driven by
document-level concurrency control
• Storage savings driven by native
compression
• 100% backwards compatible
• Non-disruptive upgradeMongoDB 3.0MongoDB 2.6
Performance
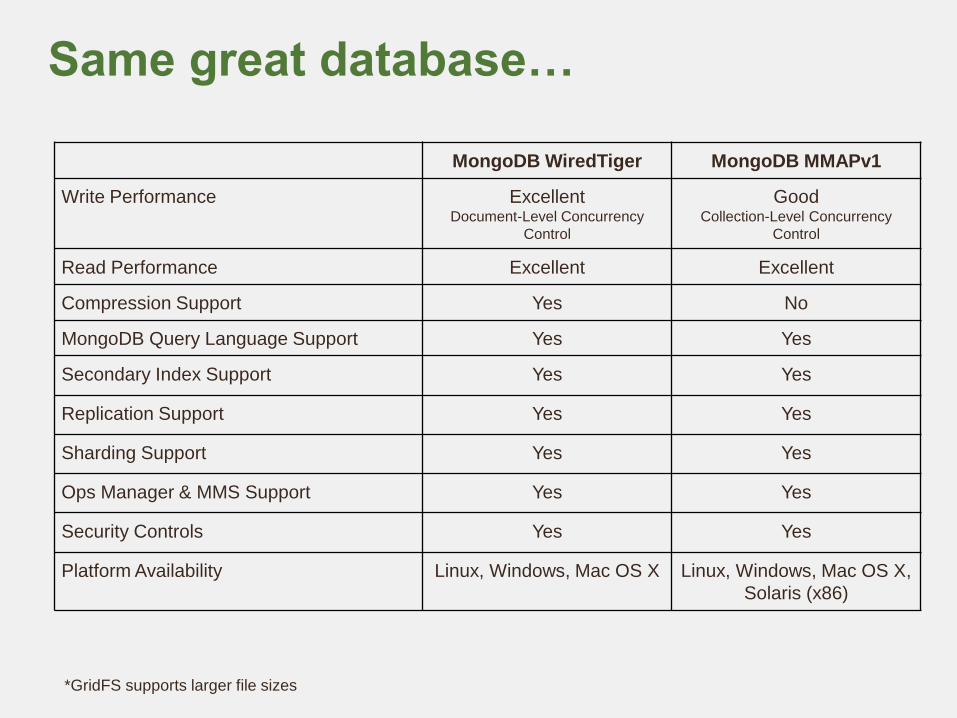
Same great database…
MongoDB WiredTiger MongoDB MMAPv1
Write Performance ExcellentDocument-Level Concurrency
Control
GoodCollection-Level Concurrency
Control
Read Performance Excellent Excellent
Compression Support Yes No
MongoDB Query Language Support Yes Yes
Secondary Index Support Yes Yes
Replication Support Yes Yes
Sharding Support Yes Yes
Ops Manager & MMS Support Yes Yes
Security Controls Yes Yes
Platform Availability Linux, Windows, Mac OS X Linux, Windows, Mac OS X,
Solaris (x86)
*GridFS supports larger file sizes

7x-10x Higher Performance
• Document-level concurrency control
• Improved vertical scalability and performance predictability
• Especially good for write-intensive apps, e.g.,
Internet of
Things (IoT)
Messaging
Apps
Log Data Tick Data

50%-80% Less Storage via Compression
• Better storage utilization
• Higher I/O scalability
• Multiple compression options
– Snappy
– zlib
– None
• Data and journal compressed on disk
• Indexes compressed on disk and in memory

Ops Manager

Single-click provisioning, scaling & upgrades, admin tasks
Monitoring, with charts, dashboards and alerts on 100+ metrics
Backup and restore, with point-in-time recovery, support for sharded clusters
MongoDB Ops Manager
The Best Way to Manage MongoDB In Your Data Center
Up to 95% Reduction in Operational Overhead

Integrates with Existing Infrastructure

How Ops Manager Helps You
Scale EasilyMeet SLAs
Best Practices,
Automated
Cut
Management
Overhead

Security and Tools Enhancements

Enhanced Query Language and Tools
• Faster Loading and Export
• Easier Query Optimization
• Faster Debugging
• Richer Geospatial Apps
• Better Time-Series Analytics
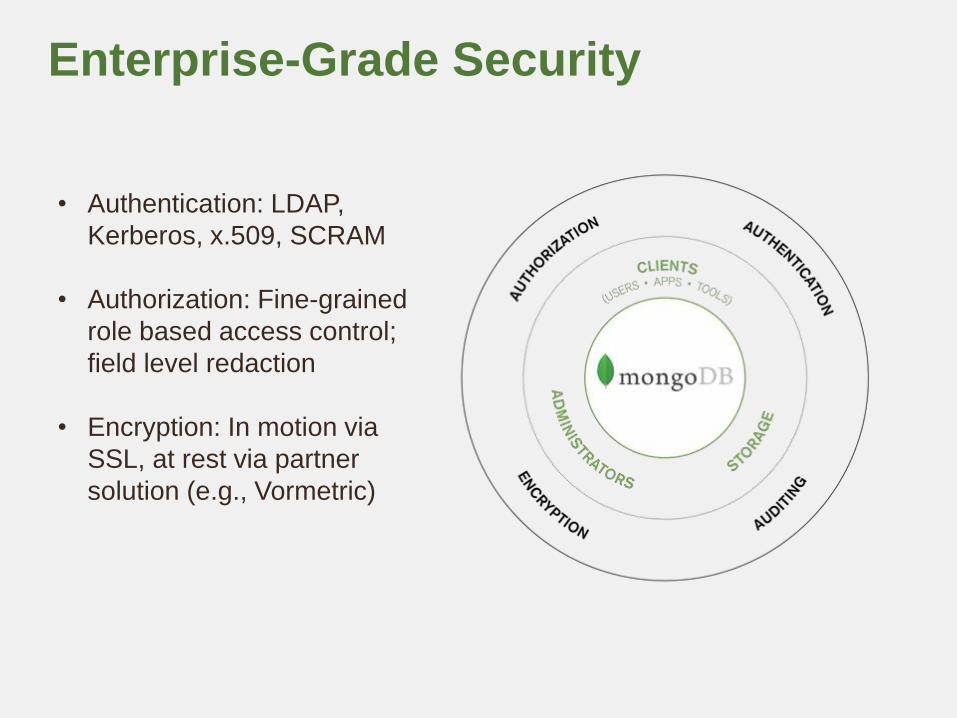
Enterprise-Grade Security
• Authentication: LDAP,
Kerberos, x.509, SCRAM
• Authorization: Fine-grained
role based access control;
field level redaction
• Encryption: In motion via
SSL, at rest via partner
solution (e.g., Vormetric)

Native Auditing for Any Operation
• Essential for many compliance standards (e.g., PCI DSS, HIPAA, NIST 800-
53, European Union Data Protection Directive)
• MongoDB Native Auditing
– Construct and filter audit trails for any operation against the database,
whether DML, DCL or DDL
– Can filter by user or action
– Audit log can be written to multiple destinations

Low-Latency Experience Across the Globe

Low-Latency Experience – Anywhere
• Amazon – Every 1/10 second delay resulted in 1% loss of sales
• Google – Half a second delay caused a 20% drop in traffic
• Aberdeen Group – 1-second delay in page-load time
– 11% fewer page views
– 16% decrease in customer satisfaction
– 7% loss in conversions
NYC SF London Sydney
NYC -- 84 69 231
SF 84 -- 168 158
London 69 168 -- 315
Sydney 231 158 315 --
Network Latencies Between Cities (ms)

Low-Latency via Large Replica Sets

MongoDB 3.0 Supports Core Proposition
Reduce Risk for Mission-Critical
Deployments
• Ops Manager automated best
practices, zero-downtime ops
• Auditing in compliance
• Flexible Storage Architecture future
proof
• 7x-10x Performance meet SLAs
Lower TCO
• Vertical scalability server utilization
• Compression 80% storage utilization
• Ops Manager lower cost to manage
Accelerate Time-to-Value
• Enhanced Query Language and Tools
less coding required
• Ops Manager up and running quickly,
decrease ops effort by 95%
• 7x-10x Performance easier to scale
Leverage Data + Tech for
Competitive Advantage
• 7x-10x Performance + Ops Manager +
Flexible Storage Architecture
MongoDB suitable for more use cases


We Are Here To Help
MongoDB Enterprise AdvancedThe best way to run MongoDB in your data center
MongoDB Management Service (MMS)The easiest way to run MongoDB in the cloud
Production SupportIn production and under control
Development SupportLet’s get you running
ConsultingWe solve problems
TrainingGet your teams up to speed

Q&A
