bellevue big data meetup: dive deep into spark streaming
TRANSCRIPT

Dive deep into: Spark Streaming
Santosh Sahoo, Architect: Concur
Spark Core
SQLStructured Data
StreamingReal-time
MLibMachine Learning
GraphXGraph Data
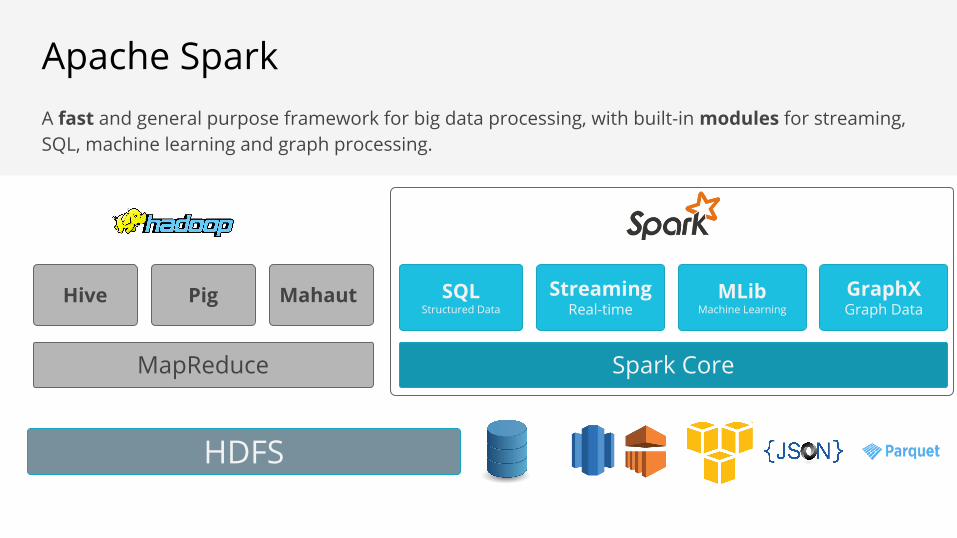
A fast and general purpose framework for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing.
Apache Spark
MapReduce
Hive Pig Mahaut
HDFS
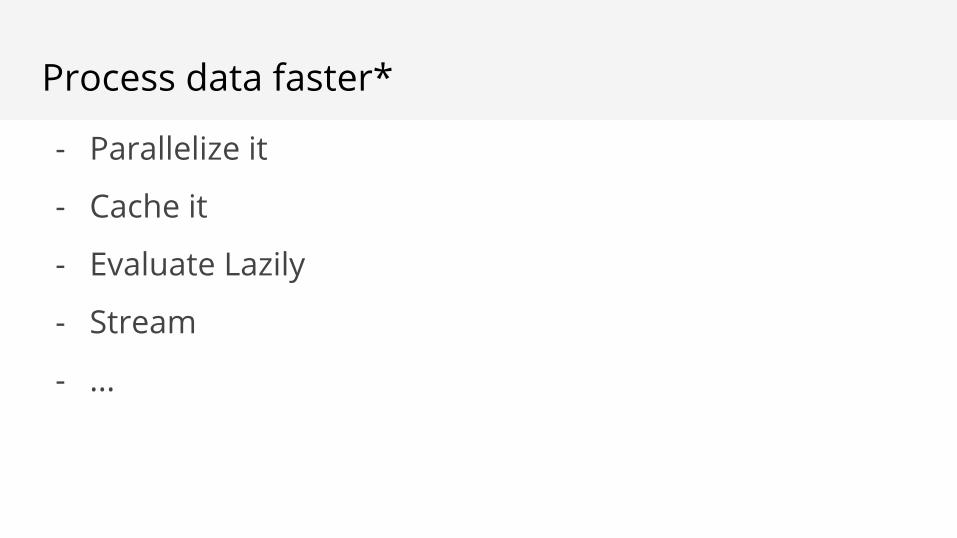
Process data faster*
- Parallelize it
- Cache it
- Evaluate Lazily
- Stream
- ...

How is Spark faster?
RDD - A Resilient Distributed Dataset, the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
Caching + DAG model is enough to run them efficiently Combining libraries into one program is much faster
DataFrames - schema-RDD

Real-time ProcessingContinuously processing stream of data, events or logs..

Streaming use cases
● Stock Market
● Clickstream Analysis
● Fraud Detection
● Real Time bidding
● Trend analysis
● Real Time Data Warehousing
● ...
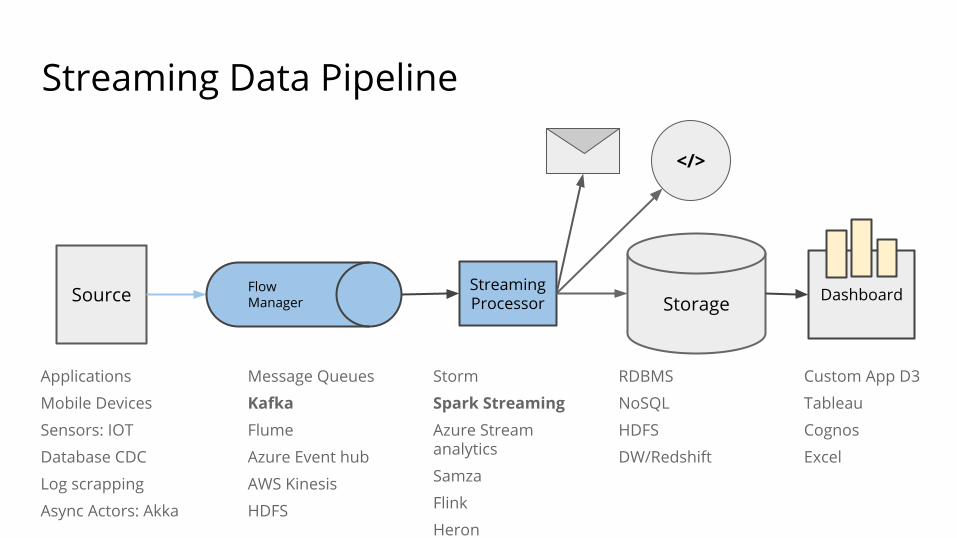
Source Flow Manager
StreamingProcessor Storage Dashboard
Streaming Data Pipeline
Applications
Mobile Devices
Sensors: IOT
Database CDC
Log scrapping
Async Actors: Akka
Message Queues
KafkaFlume
Azure Event hub
AWS Kinesis
HDFS
Storm
Spark StreamingAzure Stream analytics
Samza
Flink
Heron
RDBMS
NoSQL
HDFS
DW/Redshift
Custom App D3
Tableau
Cognos
Excel
</>
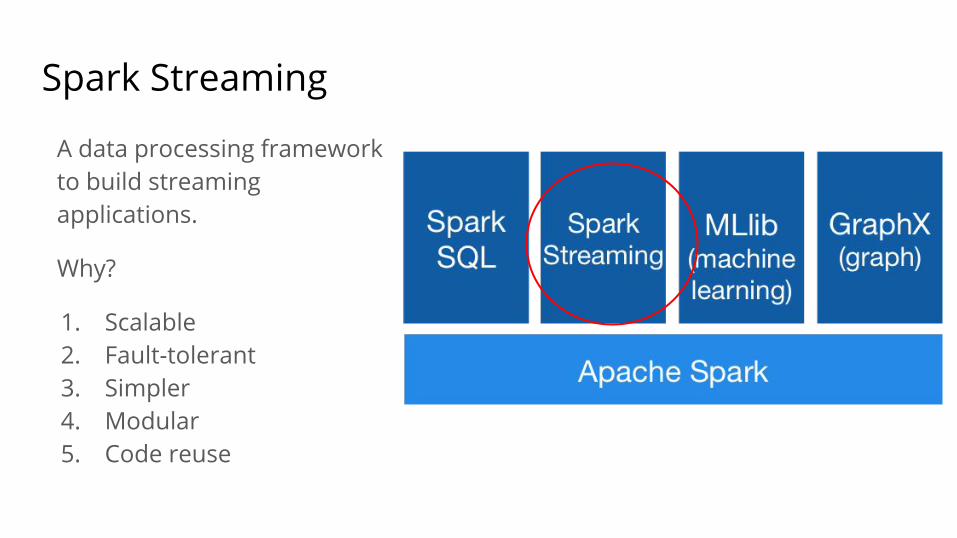
Spark Streaming
A data processing framework to build streaming applications.
Why?
1. Scalable2. Fault-tolerant3. Simpler4. Modular5. Code reuse

But Spark vs Storm..?
● Storm is a stream processing framework that also does micro-batching (Trident).
● Spark is a batch processing framework that also does micro-batching (Spark Streaming).
Also read:https://www.quora.com/What-are-the-differences-between-Apache-Spark-and-Apache-Flink/answer/Santosh-Sahoo
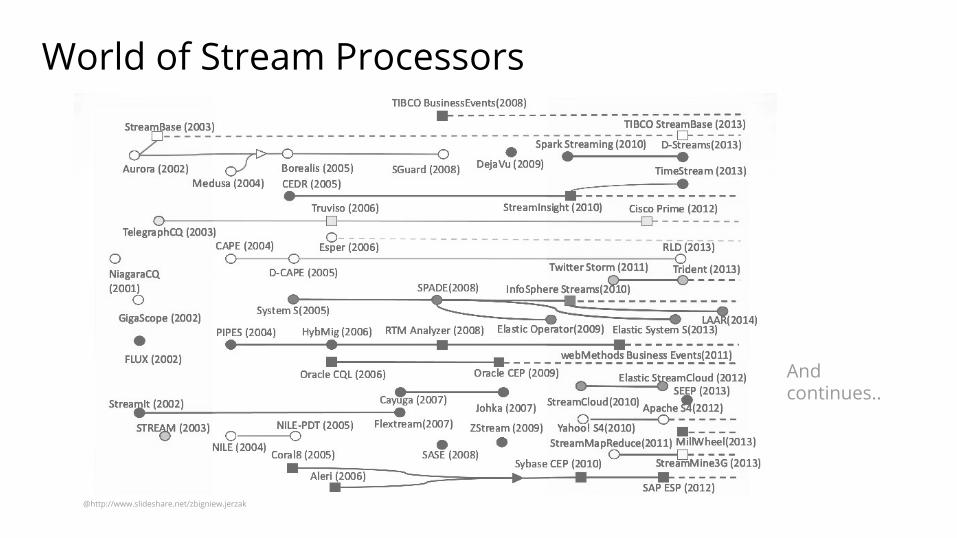
World of Stream Processors
@http://www.slideshare.net/zbigniew.jerzak
And continues..

Stream.scala1. val conf = new SparkConf().setAppName("demoapp").setMaster("local[1]")2. val sc = new SparkContext(conf)3. val ssc = new StreamingContext(sc, Seconds(2))
4. val kafkaConfig = Map("metadata.broker.list"->"localhost:9092")5. val topics = Set("topic1")6. val wordstream = KafkaUtils.createDirectStream(ssc, kafkaConfig,
topics )
7. wordstream.print()
8. ssc.start()9. ssc.awaitTermination()

DStream Operations1. map(func)
2. flatMap(func)
3. filter(func)
4. repartition(numPartitions)
5. union(otherStream)
6. count()
7. reduce(func)
8. countByValue()
9. reduceByKey(func, [numTasks])
10. join(otherStream, [numTasks])
11. cogroup(otherStream, [numTasks])
12. transform(func)
13. updateStateByKey(func)

Word count
1. val pairs = wordstream.map(word => (word, 1))
2. val wordCounts = pairs.reduceByKey(_ + _)
3. wordCounts.print()
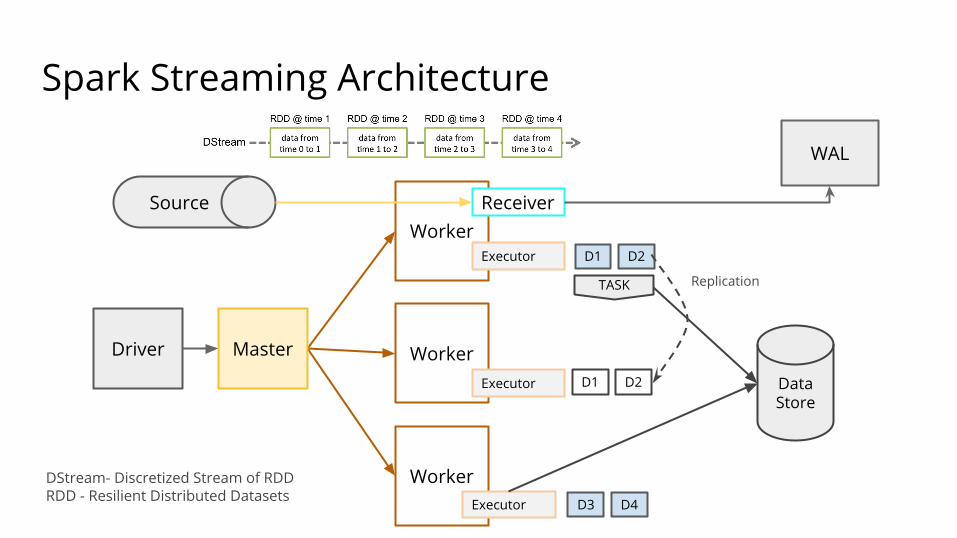
Spark Streaming Architecture
Worker
Worker
Worker
Receiver
Driver Master
Executor
Executor
Executor
Source
D1 D2
D3 D4
WAL
D1 D2
Replication
DataStore
TASK
DStream- Discretized Stream of RDDRDD - Resilient Distributed Datasets

Running Application
spark-submit \
--class AppMain \
--master spark://192.168.10.21:7077 \ #local[*]
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/code.jar \
1000
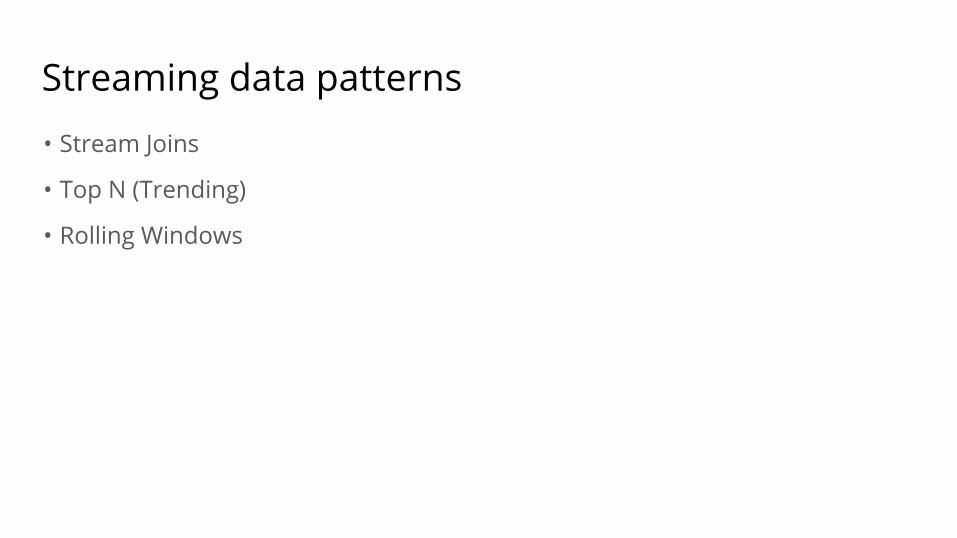
Streaming data patterns
• Stream Joins
• Top N (Trending)
• Rolling Windows

Demo….
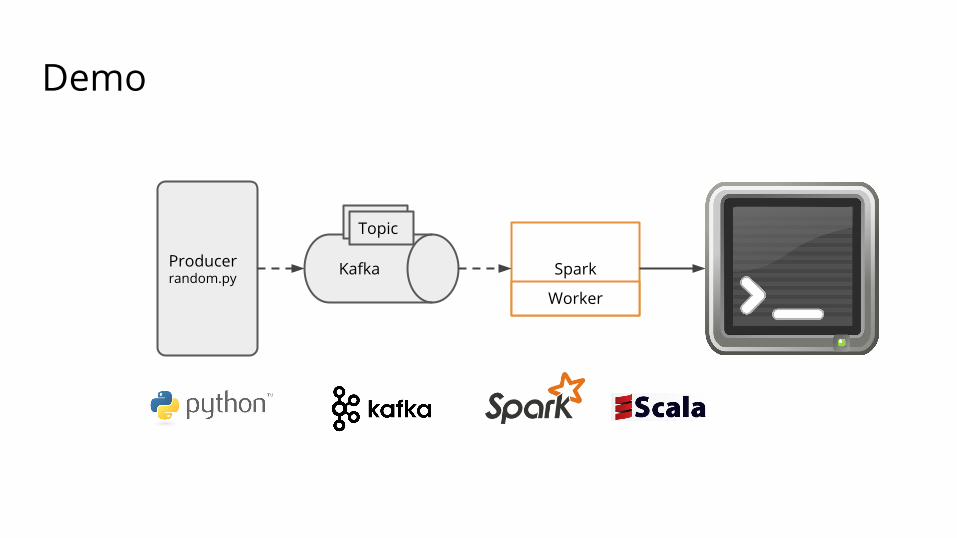
Demo
Producerrandom.py Kafka
TopicTopic
Spark
Worker
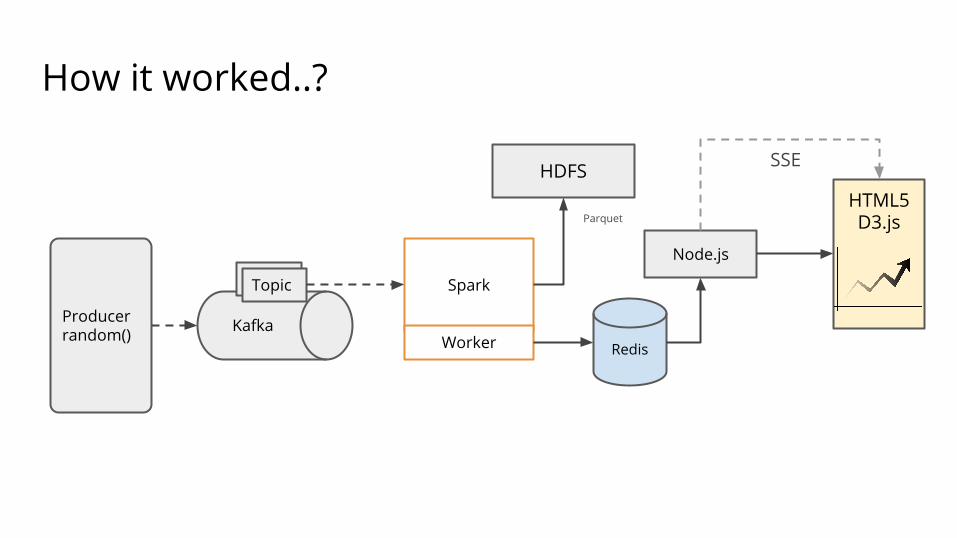
How it worked..?
Producerrandom() Kafka
TopicTopic Spark
Worker Redis
Node.js
HTML5D3.js
SSE
Parquet
HDFS

Composite Example
// Load data using SQLpoints = ctx.sql(“select latitude, longitude from hive_tweets”)
// Train a machine learning modelmodel = KMeans.train(points, 10)
// Apply it to a streamsc.twitterStream(...) .map(lambda t: (model.predict(t.location), 1)) .reduceByWindow(“5s”, lambda a, b: a + b)

Apache Kafka
No nonsense logging platform
● 100K/s throughput vs 20k of RabbitMQ
● Log compaction
● Durable persistence
● Partition tolerance
● Replication
● Best in class integration with Spark○ http://spark.apache.org/docs/latest/streaming-kafka-integration.html
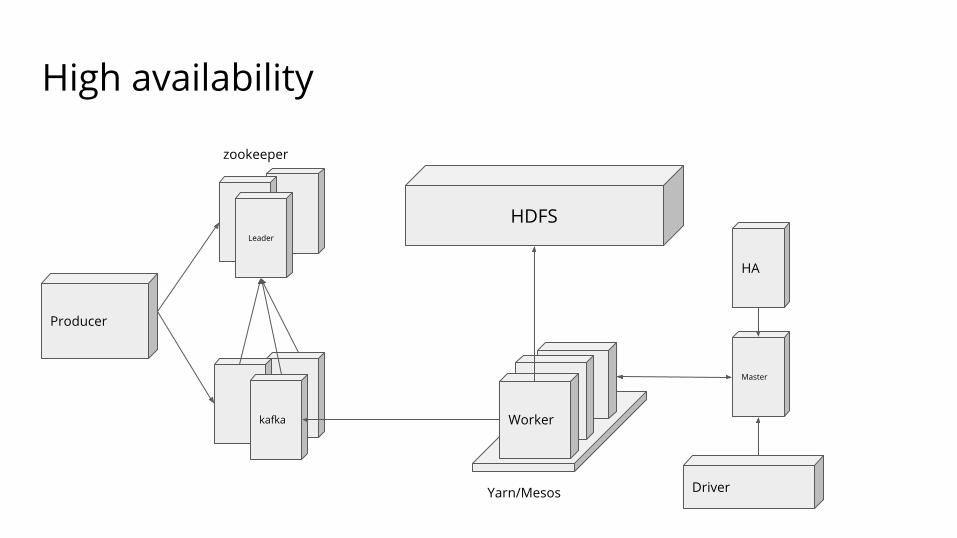
High availability
Leader
zookeeper
kafka
Producer
HA
Master
Worker
DriverYarn/Mesos
HDFS
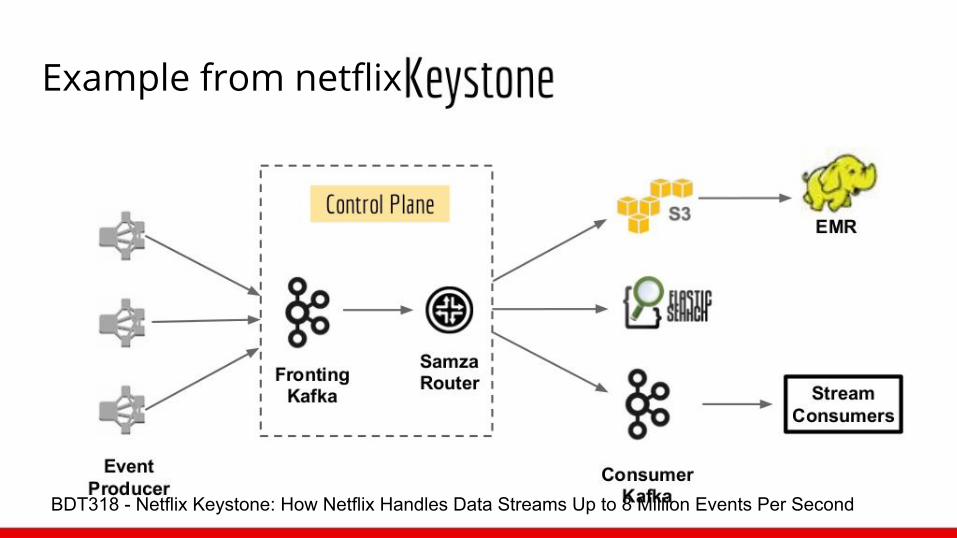
Example from netflix
BDT318 - Netflix Keystone: How Netflix Handles Data Streams Up to 8 Million Events Per Second
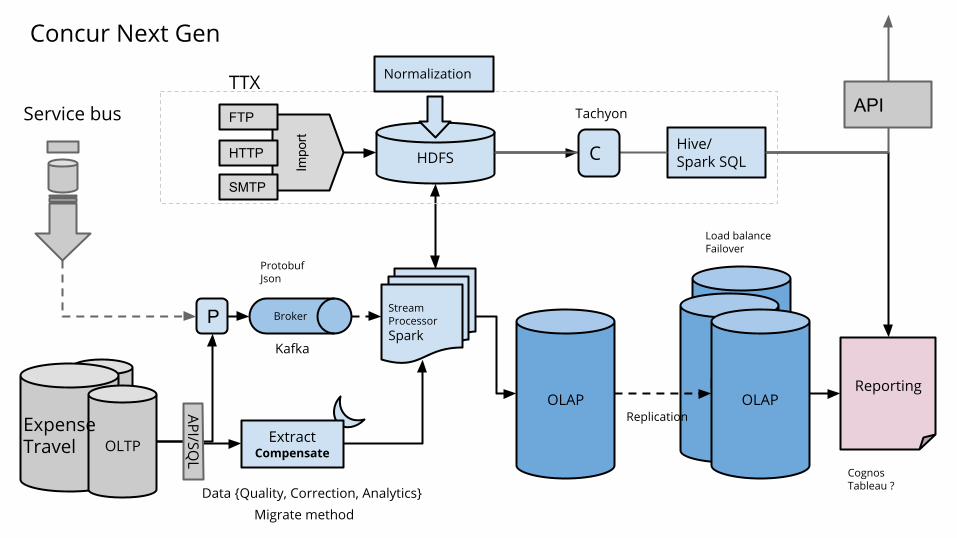
OLTP
Reporting
CognosTableau ?
StreamProcessorSpark
HDFSImpo
rt
FTP
HTTP
SMTP
P
ProtobufJson
Broker
Kafka
Hive/Spark SQL
OLAP
Load balanceFailover
HANA
HANAOLAP
Replication
Service bus
Normalization
ExtractCompensate
Data {Quality, Correction, Analytics}Migrate method
API/SQL
ExpenseTravel
TTXAPI
Concur Next Gen
C
Tachyon
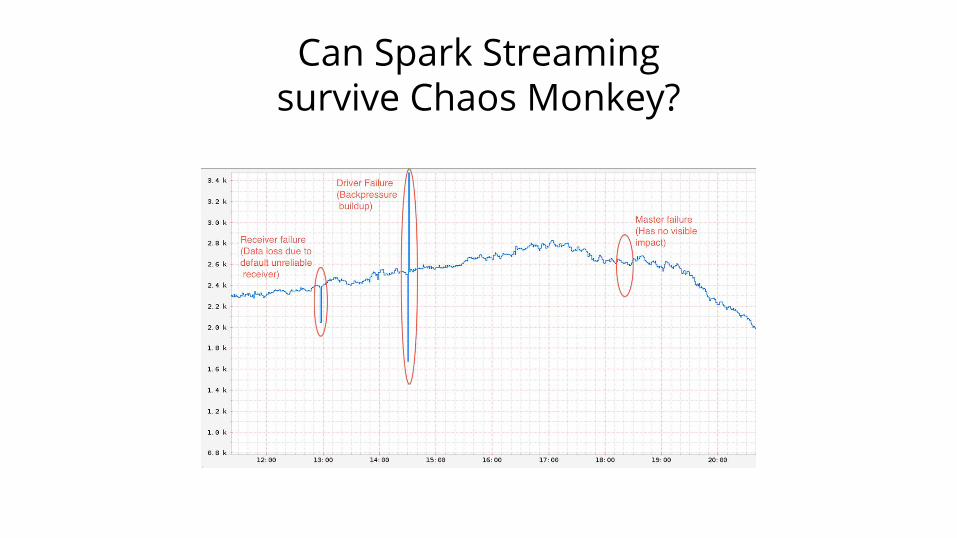
Can Spark Streaming survive Chaos Monkey?
http://techblog.netflix.com/2015/03/can-spark-streaming-survive-chaos-monkey.html
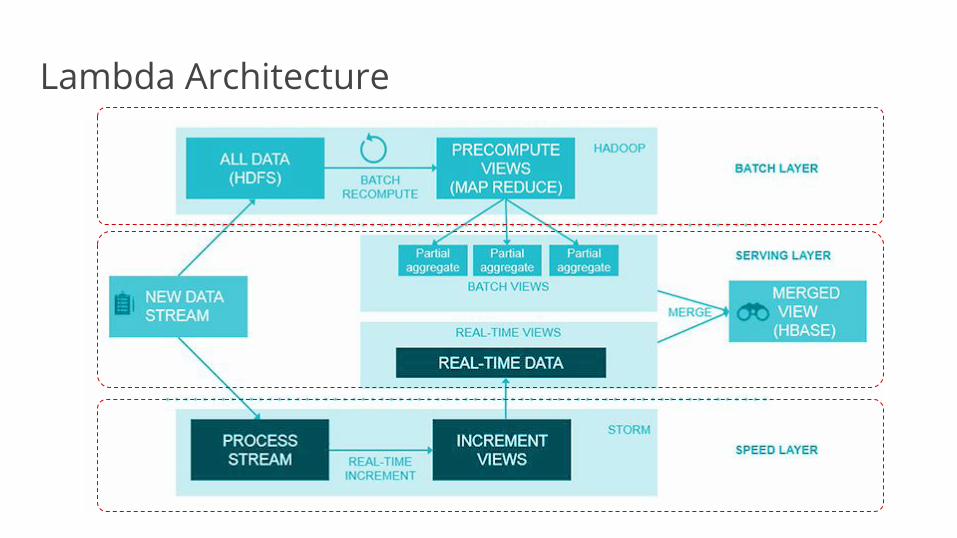
Lambda Architecture

Thank You!@santoshsaho
speakerdeck.com/santoshsahoogithub.com/santoshsahoo/spark-streaming-deepdive
linkedin.com/in/sahoosantosh
Concur is hiringhttps://www.concur.com/en-us/careers