behavior-based ai amir massoud farahmand [email protected] [email protected]
Post on 21-Dec-2015
221 views
TRANSCRIPT

Behavior-based AIBehavior-based AIBehavior-based AIBehavior-based AI
Amir massoud FarahmandAmir massoud [email protected]@[email protected]@ipm.ir

Happy birthday to Artificial
Intelligence• 1941 Konrad Zuse, Germany, general purpose
computer• 1943 Britain (Turing and others) Collossus, for
decoding• 1945 ENIAC, US. John von Neumann a consultant• 1946 The Logic Theorist on JOHNNIAC--Newell, Shaw
and Simon• 1956 Dartmouth Conference organised by John
McCarthy (inventor of LISP) • The term Artificial Intelligence coined at
Dartmouth---intended as a two month, ten man study!

HP to AI (2)‘It is not my aim to surprise or shock you----but the simplest way I can summarize is to say that there are now in the world machines that think, that learn and that create. Moreover, their ability to these things is going to increase rapidly until........…’
(Herb Simon 1957)
Unfortunately, Simon was too optimistic!

What AI has done for us?
• Rather good OCR (Optical Character Recognition) and Speech recognition softwares
• Robots make cars in all advanced countries• Reasonable machine translation is available for a
large range of foreign web pages• Systems land 200 ton jumbo jets unaided every few
minutes• Search systems like Google are not perfect but very
effective information retrieval• Computer games and autogenerated cartoons are advancing
at an astonishing rate and have huge markets• Deep blue beat Kasparov in 1997. The world Go champion
is a computer.• Medical expert systems can outperform doctors in many
areas of diagnosis (but we aren’t allowed to find out easily!)

AI: What is it?• What is AI?• Different definitions
– The use of computer programs and programming techniques to cast light on the principles of intelligence in general and human thought in particular (Boden)
– The study of intelligence independent of its embodiment in humans, animals or machines (McCarthy)
– AI is the study of how to do things which at the moment people do better (Rich & Knight)
– AI is the science of making machines do things that would require intelligence if done by men. (Minsky) (fast arithmetic?)
• Is it definable?!• Turing test, Weak and Strong AI and …

AI: Basic assumption
• Symbol System Hypothesis: it is possible to construct a universal symbol system that thinks
• Strong Symbol System Hypothesis: the only way a system can think is through symbolic processing
• Happy birthday Symbolic (Traditional – Good old-fashioned) AI

Symbolic AI: Methods
• Knowledge representation (Abstraction)
• Search• Logic and deduction• Planning• Learning

Symbolic AI: was it efficient?
• Chess [OK!]• Block-worlds [OK!]• Daily Life Problems
– Robots [~OK!]– Commonsense [~OK!]– … [~OK]

Symbolic AI and Robotics
• Functional decomposition• Sequential flow• Correct perceptions is assumed to be done by vision-
researched in a “a-good-and-happy-will-come-day”!• Get a logic-based or formal description of percepts• Apply search operators or logical inference or
planning operators
PerceptionTask
executionPlanning
World Modelling
Motor control
sensors actuators

Challenges of real robotic system
• Sensors and Effectors Uncertainty• Partial Observability of Environment
• Non-stationarity

Requirements of control system of an intelligent
autonomous mobile robot
• Multiple-goal• Robust• Multiple-sensors• Extensible• [Learning]

Behavior-based approach to AI
• Behavioral (activity) decomposition [against functional decomposition]
• Behavior: Sensor->Action (Direct link between perception and action)
• Situatedness• Embodiment• Intelligence as Emergence of …

Behavioral decomposition
build maps
explore
avoid obstacles
locomote
manipulatethe world
sensors

Situatedness• No world modelling and abstraction
• No planning• No sequence of operations on symbols
• Direct link between sensors and actions
• The world is its own best model

Embodiment• Only an embodied agent is validated as one that can deal with real world.
• Only through a physical grounding can any internal symbolic system be given meaning

Emergence as a route to
Intelligence• Emergence: interaction of some simple systems which results in something more than sum of those systems
• Intelligence as emergent outcome of dynamical interaction of behaviors with the world

Behavior-based design
• Robust– not sensitive to failure of particular part of the system
– no need for precise perception as there is no modelling there
• Reactive: Fast response as there is no long route from perception to action
• No representation

A Simple problem• Goal: make a mobile robot controller that collects balls from the field and move them to home
• What we have:– Differentially controlled mobile robot
– 8 sonar sensors– Vision system that detects balls and home
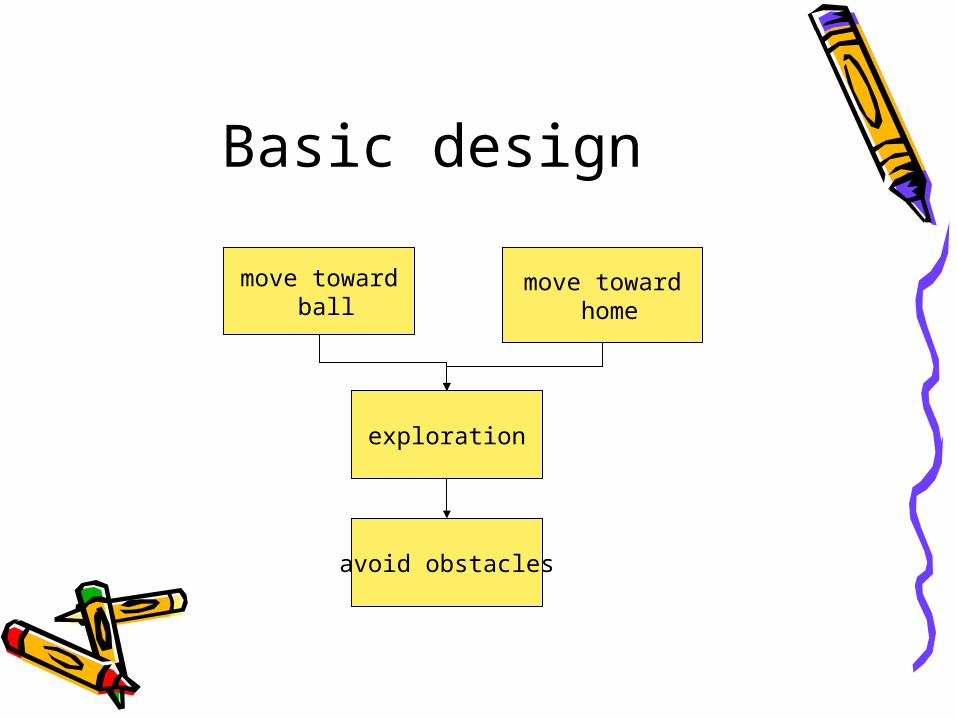
Basic design
move toward ball
move toward home
exploration
avoid obstacles

A simple shot

Different Controlling Mechanism
• Reactive– Fast, Suitable for structured & a priori known environment
– No internal representations• Deliberative
– Not practical (uncertainty, huge search spaces and …)
• Hybrid• Behavior-based

How can we automate it?!
How?!

Mataric’s Main Trends in Behavior-
based Learning• Learning Behavior Policy• Learning Models of the Environment• Learning Models from Behavior History
– Michaud
• Learning Models of Interaction– Goldberg
• Learning from Human and Other Agents– Nicolescu

Learning Behavior Policy
They learn (condition,behavior) using RL framework.– No Hierarchy– No MDP
Scaling up RL:– Reward Shaping (progress estimator)– Reward Sharing
• Social Learning– Perceptual Sharing

Learning Behavior Policy (2)
• Mataric, RL in the multi-robot domain, 1997.• Mataric, Reward function for accelerated
learning, 1994.• Mataric, Learning social behaviors, 1997.• Mataric, Using communication to reduce locality
in distributed multi-agent learning, 1997• Simsarian and Mataric, Learning to cooperate
using two six-legged mobile robots, 1995.Others• Maes and Brooks, Learning to coordinate
behaviors, 1990.• Mahadevan and Connel, Scaling RL to robotics by
exploiting the SSA, 1991.

Learning Models of the Environment
They used BBS to learn env. map to show that it is possible for BB structure as a representator mechanism.
• Map Building• Localization• Path planning

Learning Models from Behavior
HistoryStore active behaviors in tree-like structure in which each link shows transition probability.
Reduce interference by recognizing common patterns of interference.
• Michaud and Mataric, Learning from history for behavior-based mobile robots in non-stationary conditions, 1998.
• Michaud and Mataric, Representation of behavioral history for learning in non-stationary conditions

Learning Models of Interaction
Augmented Markov Model• It is a kind of HMM without any hidden state.
• Used in order to model behavior transition probability

Learning Models of Interaction (2)
• Why should we use AMM?– No a priori knowledge from env.
– Local sensing (need time to estimate env.)
– Non-stationary variability
• How can it help?– Deriving useful statistics from AMM such as mean first pass between two behavior

Learning Models of Interaction (3)
• In a demining task with different values of mine, extract demining time with AMM in order to maximize reward.
• Multi-agent– Individual performance evalutation (fault detection)
– Group affiliation– Group performance

Learning Models of Interaction (4)
• Dani Goldberg and Maja Mataric, Augmented Markov Models (Tech. Report)
• Goldberg and Mataric, Coordinating mobile robot group behavior using a model of interaction dynamics, 1999.
• Goldberg and Mataric, Learning multiple models for reward maximization, 2000.

Abstract Behaviors• Main deficiencies of basic BBS– It has no symbolic and abstract representation
– There is no ease of reusability and changing during operation

Abstract Behaviors (2)

Learning from Human and Other Agents
• Learning from demonstration • Use AB structure

Learning from Human and Other Agents
(2)• Learning is consisted of
– Store activated behaviors during demonstration
– Set preconditions of NAB

Learning from Human and Other Agents
(3)• Monica Nicolescu and Maja Mataric, Extending behavior-based systems capabilities using an abstract behavior representation, 2000.
• Nicolescu and Mataric, A hierarchical architecture for behavior-based robots, 2002.
• Nicolescu and Mataric, Natural methods for robot task learning: Instructive demonstration, generalization, and practice, 2003

Learning• Behavior learning
– How should a single behavior act?
• Structure learning– How should behaviors arranged in architecture?

Overview of learning methods common to Compute Science
• Supervised learning• Reinforcement learning (conditioning, or more precisely operant conditioning)
• Unsupervised learning

Reinforcement Learning
• Agent sense state of the environment
• Agent choose an action
• Agent receives reward from some critic
• Agent learns to maximize its received rewards through time

Structure learning• Structure representation
– Which architecture and How to make it?
• Structural credit assignment– What was wrong/right in this structure?
• Development of structure– When should we add a new behavior– …
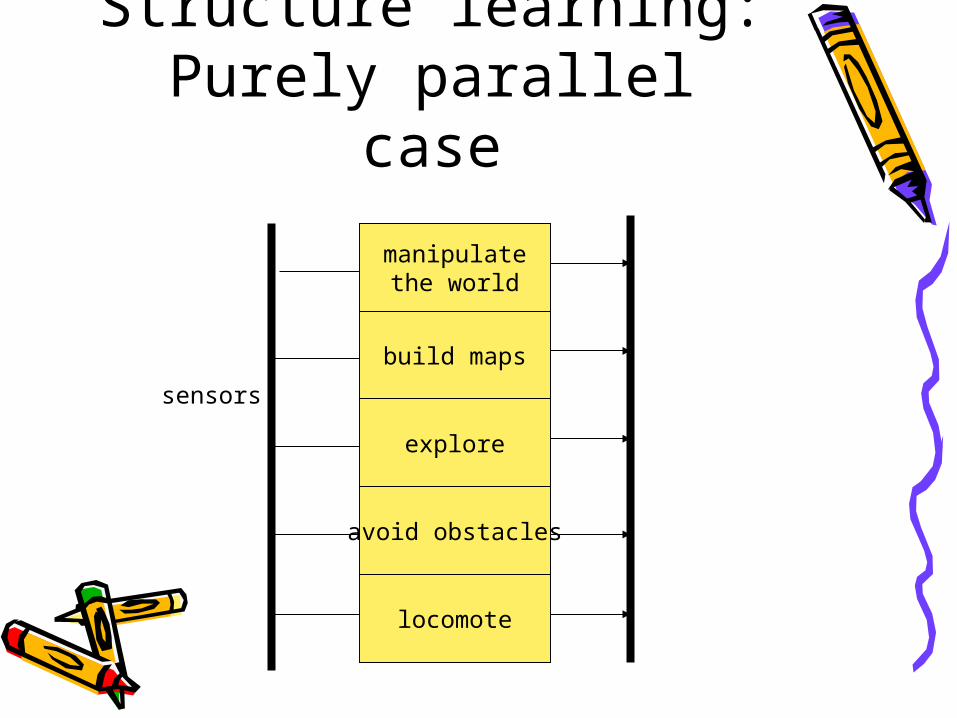
Structure learning: Purely parallel
case
build maps
explore
avoid obstacles
locomote
manipulatethe world
sensors

Structure learning: Purely parallel
case• Zero order representation
– Version 1! [We have not attacked because it is useless]
– Version 2! [OK!]
• First order representation– Version 1! [Somehow very OK, somehow not so!
– Version 2! [Not tested!]– Version 1.5! [OK!]
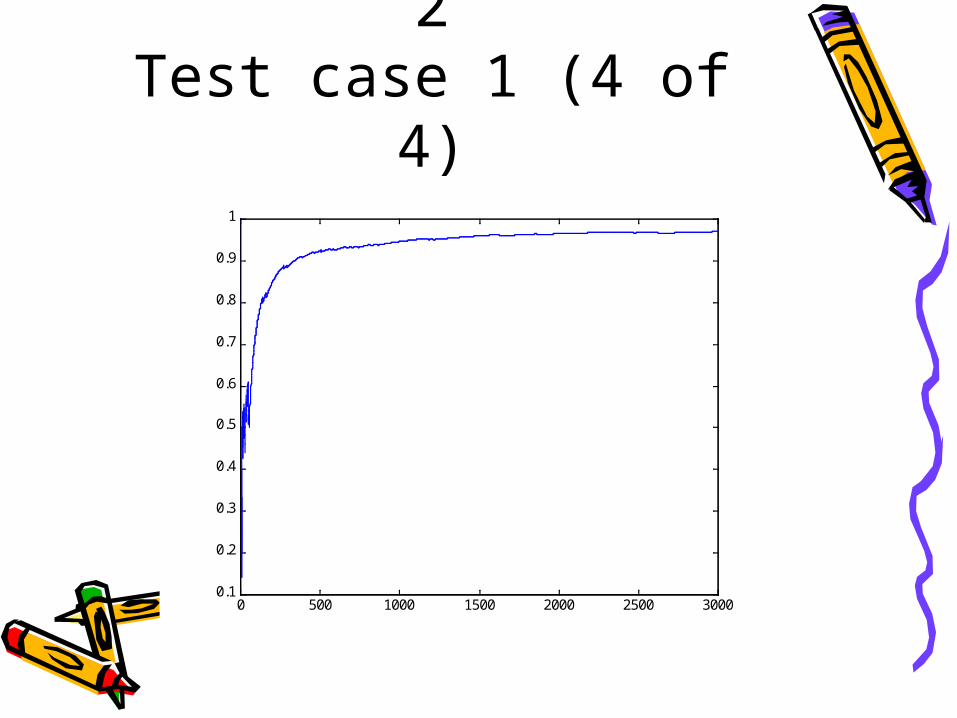
Zero Order Version 2
Test case 1 (4 of 4)
0 500 1000 1500 2000 2500 30000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1

Zero Order Version 2
Test case 1 (4 of 4)

Zero Order Version 2
Test case 2 (5 of 10)
0 500 1000 1500 2000 2500 3000-1
-0.9
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0

First Order Version 1
Test case 3 (4 ordered behaviors)
0 500 1000 1500 2000 2500 3000-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1

First Order Version 1
Test case 3 (4 ordered behaviors)
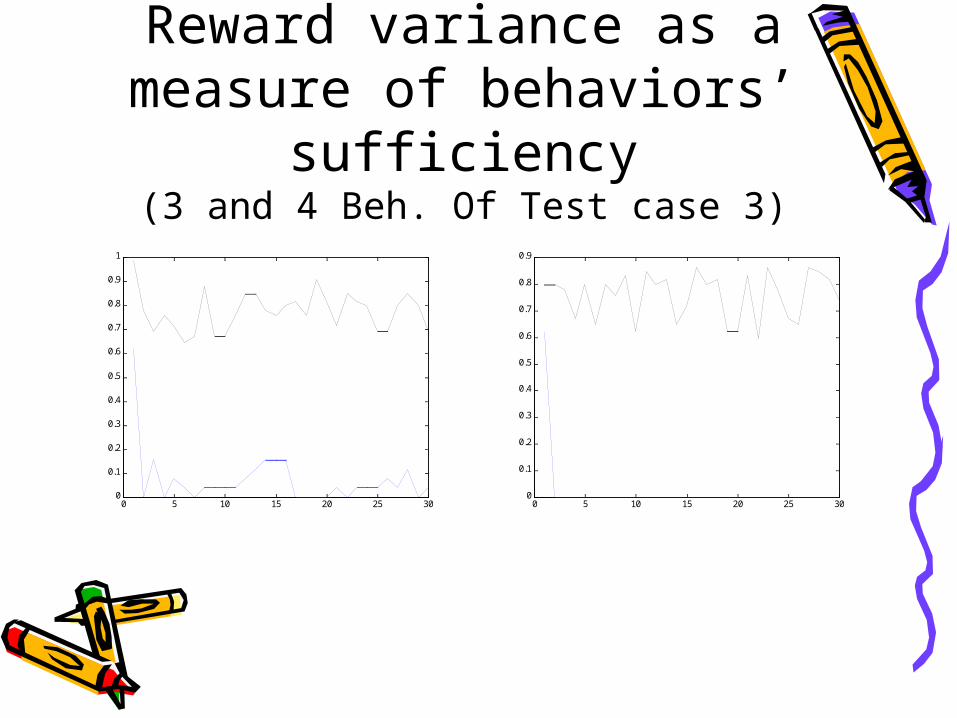
Reward variance as a measure of behaviors’
sufficiency(3 and 4 Beh. Of Test case 3)
0 5 10 15 20 25 300
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1e-greedy exploration
0 5 10 15 20 25 300
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9greedy run

First Order Version 1
Test case 3 (4 ordered behaviors)
0 50 100 150 200 250 300 350 400 450 500-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1

First Order Version 1
Test case 3 (4 ordered behaviors)
0 50 100 150 200 250 300 350 400 450 5001
1.5
2
2.5
3
3.5
4Layer 1 (upper)
0 50 100 150 200 250 300 350 400 450 5001
1.5
2
2.5
3
3.5
4Layer 2
0 50 100 150 200 250 300 350 400 450 5001
1.5
2
2.5
3
3.5
4Layer 3
0 50 100 150 200 250 300 350 400 450 5001
1.5
2
2.5
3
3.5
4Layer 4 (lower)

Readings• Brooks, “Elephant don’t play chess,” Robotics and
Autonomous Systems 6(1,2), 1990• Brooks, “Intelligence without representation,”
Artificial Intelligence Journal 47, 1991• Brooks, “Intelligence without reason,” Proc. 1991
Int. Joint Conf. AI• Brooks, “A robust layered control system for a
mobile robot,” IEEE J. of Robotics and Auto., 1986• Brooks, “A robot that walks: emergent behavior from
a carefully evolved network”, Neural Computation 1, 1989
• Brooks, Cambrian Intelligence, 1999• Other Brooks works• Mataric’s works

Juergen Schmidhuber