bayesian learning for conditional models alan qi mit csail september, 2005 joint work with t. minka,...
Post on 22-Dec-2015
217 views
TRANSCRIPT

Bayesian Learning for Conditional Models
Alan Qi
MIT CSAIL
September, 2005
Joint work with T. Minka, Z. Ghahramani, M.
Szummer, and R. W. Picard

Motivation
• Two types of graphical models: generative and conditional
• Conditional models:– Make no assumptions about data generation– Enable the use of flexible features
• Learning conditional models : estimating (distributions of) model parameters– Maximum likelihood approaches: overfitting– Bayesian learning

Outline
• Background – Conditional models for independent and relational data
classification – Bayesian learning
• Bayesian classification and Predictive ARD– Feature selection– Fast kernel learning
• Bayesian conditional random fields– Contextual object recognition/Segmentation
• Conclusions

Outline
• Background – Conditional models – Bayesian learning
• Bayesian classification and Predictive ARD
• Bayesian conditional random fields
• Conclusions

Graphical Models
Conditional models
- Logistic/Probit regression
- Classification of independent data
Conditional random fields
-Model relational data, such as natural language
and images
i
iitpp )|()( w,xwx,|t a
aZp )(
)(
1)( ty,x,
wxw,|t
x1 x2
t1 t2
w x1 x2
t1 t2
w

Bayesian learning
Simple: Given prior distributions and data likelihoods, estimate the posterior distributions of model parameters or the predictive posterior of a new data point.
Difficult: calculating the posterior distributions in practice.
– Randomized methods: Markov Chain Monte Carlo, Importance Sampling
– Deterministic approximation: Varitional methods, Expectation propagation.

Outline
• Background
• Bayesian classification and Predictive ARD– Feature selection– Fast kernel learning
• Bayesian conditional random fields
• Conclusions

Goal
Task 1: Classify high dimensional datasets with many irrelevant features, e.g., normal v.s. cancer microarray data.
Task 2: Sparse Bayesian kernel classifiers for fast test performance.

Part 1: Roadmap
• Automatic relevance determination (ARD)• Risk of Overfitting by optimizing hyperparameters
• Predictive ARD by expectation propagation (EP):
– Approximate prediction error
– EP approximation
• Experiments
• Conclusions

Bayesian Classification Model
Prior of the classifier w:
Labels: t inputs: X parameters: w
Likelihood for the data set:
Where is a cumulative distribution function for a standard Gaussian.

Evidence and Predictive Distribution
The evidence, i.e., the marginal likelihood of the hyperparameters :
The predictive posterior distribution of the label for a new input :

Automatic Relevance Determination (ARD)
• Give the classifier weight independent Gaussian priors whose variance, , controls how far away from zero each weight is allowed to go:
• Maximize , the marginal likelihood of the model, with respect to .
• Outcome: many elements of go to infinity, which naturally prunes irrelevant features in the data.
1

Two Types of Overfitting
• Classical Maximum likelihood:– Optimizing the classifier weights w can directly fit
noise in the data, resulting in a complicated model.
• Type II Maximum likelihood (ARD):– Optimizing the hyperparameters corresponds to
choosing which variables are irrelevant. Choosing one out of exponentially many models can also overfit if we maximize the model marginal likelihood.

Risk of Optimizing
X: Class 1 vs O: Class 2
Evd-ARD-1
Evd-ARD-2
Bayes Point

Predictive-ARD
• Choosing the model with the best estimated predictive performance instead of the most probable model.
• Expectation propagation (EP) estimates the leave-one-out predictive performance without performing any expensive cross-validation.

Estimate Predictive Performance• Predictive posterior given a test data point
• EP can estimate predictive leave-one-out error probability
• where q( w| t\i) is the approximate posterior of leaving out the ith label.
• EP can also estimate predictive leave-one-out error count
1Nx
wtwwxtx d)|(),|(),|( 1111 ptptp NNNN
N
iiii
N
iiii qtp
Ntp
N 1\
1\ d)|(),|(1
1),|(1
1wtwwxtx
N
1i21
\ )),|(I(1
iiitpN
LOO tx

Expectation Propagation in a Nutshell
• Approximate a probability distribution by simpler parametric terms:
• Each approximation term lives in an exponential family (e.g. Gaussian)
ii
iii
ii
fq
tfp
)(~
)(
))(()()( T
ww
xwwt|w
)(~
wif

EP in a NutshellThree key steps:• Deletion Step: approximate the “leave-one-out”
predictive posterior for the ith point:
• Minimizing the following KL divergence by moment matching:
• Inclusion:
ij
jii ffqq )(
~)(
~/)()(\ wwww
))()(~
||)()((minarg \\
)(~
wwwww
ii
ii
f
qfqfKL
i
)()(~
)( \ www ii qfq
The key observation: we can use the approximate predictive posterior, obtained in the deletion step, for model selection. No extra computation!
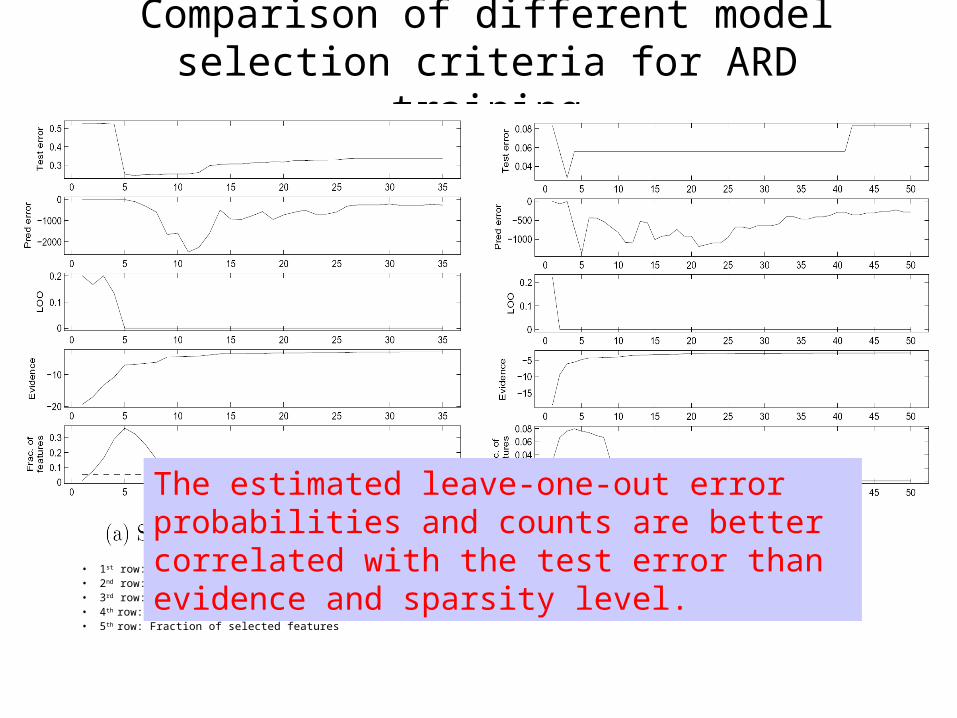
Comparison of different model selection criteria for ARD training
• 1st row: Test error• 2nd row: Estimated leave-one-out error probability• 3rd row: Estimated leave-one-out error counts• 4th row: Evidence (Model marginal likelihood)• 5th row: Fraction of selected features
The estimated leave-one-out error probabilities and counts are better correlated with the test error than evidence and sparsity level.

Gene Expression Classification
Task: Classify gene expression datasets into different categories, e.g., normal v.s. cancer
Challenge: Thousands of genes measured in the micro-array data. Only a small subset of genes are probably correlated with the classification task.

Classifying Leukemia Data
• The task: distinguish acute myeloid leukemia (AML) from acute lymphoblastic leukemia (ALL).
• The dataset: 47 and 25 samples of type ALL and AML respectively with 7129 features per sample.
• The dataset was randomly split 100 times into 36 training and 36 testing samples.
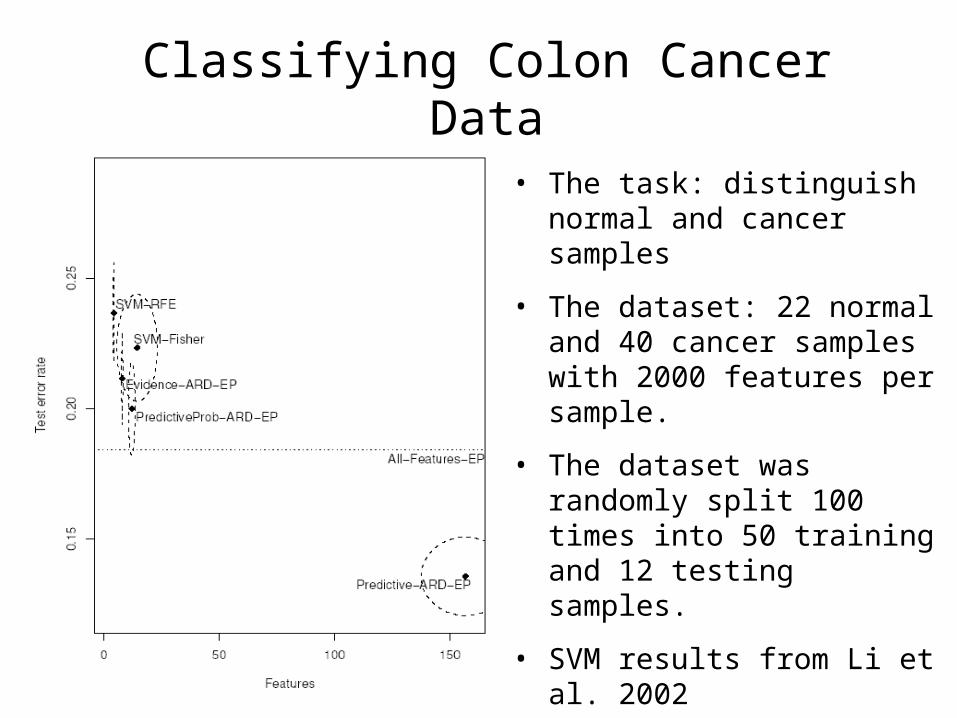
Classifying Colon Cancer Data
• The task: distinguish normal and cancer samples
• The dataset: 22 normal and 40 cancer samples with 2000 features per sample.
• The dataset was randomly split 100 times into 50 training and 12 testing samples.
• SVM results from Li et al. 2002

Bayesian Sparse Kernel Classifiers
• Using feature/kernel expansions defined on training data points:
• Predictive-ARD-EP trains a classifier that depends on a small subset of the training set.
• Fast test performance.

Test error rates and numbers of relevance or support vectors on breast cancer dataset.
50 partitionings of the data were used. All these methods use the same Gaussian kernel with kernel width = 5. The trade-off parameter C in SVM is chosen via 10-fold cross-validation for each partition.

Part 1: Conclusions
• Maximizing marginal likelihood can lead to overfitting in the model space if there are a lot of features.
• We propose Predictive-ARD based on EP for – feature selection
– sparse kernel learning
• In practice Predictive-ARD works better than traditional ARD.

Outline
• Background
• Bayesian classification and Predictive ARD
• Bayesian conditional random fields
– Contextual object recognition/Segmentation
• Conclusions

x1 x2
t1 t2
w
• Generalize traditional classification model by introducing correlation between labels.
Potential functions:
• Model data with interdependence and structure, e.g, web pages, natural languages, and multiple visual objects in a picture.
• Information at one location propagates to other locations.
Part 2: Conditional random fields (CRFs)

Bayesian Conditional Networks• Bayesian training to avoid overfitting
• Need efficient training:– The exact posterior of w
– The Gaussian approximate posterior of w

Learning the parameter w by ML/MAP
Maximum likelihood (ML) : Maximize the data likelihood
where
Maximum a posterior (MAP):Gaussian prior on w
ML/MAP problem: Overfitting to the noise in data.

EP in a Nutshell• Approximate a probability distribution by simpler
parametric terms (Minka 2001):
– For Bayesian networks:– For Markov networks:
– For conditional classification:– For conditional random fields:
Each approximation term or lives in an exponential family (such as Gaussian & Multinomial)
a
afp )()( xx a
afq )(~
)( xx
)(~
xaf
)|()( ajaia xxpf x
)()( yx,x aaf
)|()( w,xw aaa tpf
),,()( wxw aaa tf
)(~
waf
a
aa
a fqfp )(~
)()()( wwwxt,|w

EP in a Nutshell (2)• The approximate term minimizes the
following KL divergence by moment matching:
))()(~
||)()((minarg \\
)(~
xxxxx
aa
aa
f
qfqfD
a
)(~
)()(
~)(\
x
xxx
aabb
a
f
qfq
Where the leave-one-out approximation is
)(~
xaf

EP in a Nutshell (3)Three key steps:• Deletion Step: approximate the “leave-one-out”
predictive posterior for the ith point:
• Minimizing the following KL divergence by moment matching (Assumed Density filtering):
• Inclusion:
ij
jii ffqq )(
~)(
~/)()(\ xxxx
))()(~
||)()((minarg \\
)(~
xxxxx
ii
ii
f
qfqfKL
i
)()(~
)( \ xxx ii qfq

Two Difficulties for Bayesian Training
• the partition function appears in the denominator– Regular EP does not apply
• the partition function is a complicated function of w

Turn Denominator to Numerator (1)
• Transformed EP:
– Deletion:
– ADF:
– Inclusion:

Turn Denominator to Numerator (2)• Power EP:
– Deletion:
– ADF:
– Inclusion:
Power EP minimizes divergence

Approximating the partition function
• The parameters w and the labels t are intertwined in Z(w):
where k = {i, j} is the index of edges.
The joint distribution of w and t:
• Factorized approximation:

Remove the intermediate level
Flatten Approximation Structure
Increased efficiency, stability, and accuracy!
Iterations
Iterations
Iterations

Model Averaging for Prediction
• Bayesian training provides a set of estimated models
• Bayesian model averaging combines predictions from all the models to eliminate overfitting
• Approximate model averaging: weighted belief propagation

Results on Synthetic Data
• Data generation: first, randomly sample input x, fixed true parameters w, and then sample the labels t
• Graphical structure: Four nodes in a simple loop• Comparing maximum likelihood trained CRF with BCRFs: 10
Trials. 100 training examples and 1000 test examples.
BCRFs significantly outperformed ML-trained CRFs.

FAQs Labeling
• The dataset consists of 47 files, belonging to 7 Usenet newsgroup FAQs. Each file has multiple lines, which can be the header (H), a question (Q), an answer (A), or the tail (T).
• Task: label the lines that are questions or answers.

FAQs Features

Results
BCRFs outperform MAP-trained CRFs with a high statistical significance on FAQs labeling.

Ink Application: analyzing handwritten organization charts
• Parsing a graph into different components: containers vs. connectors

Comparing results
Results from Bayes Point Machine
Results from MAP-trained CRF
Results from BCRF
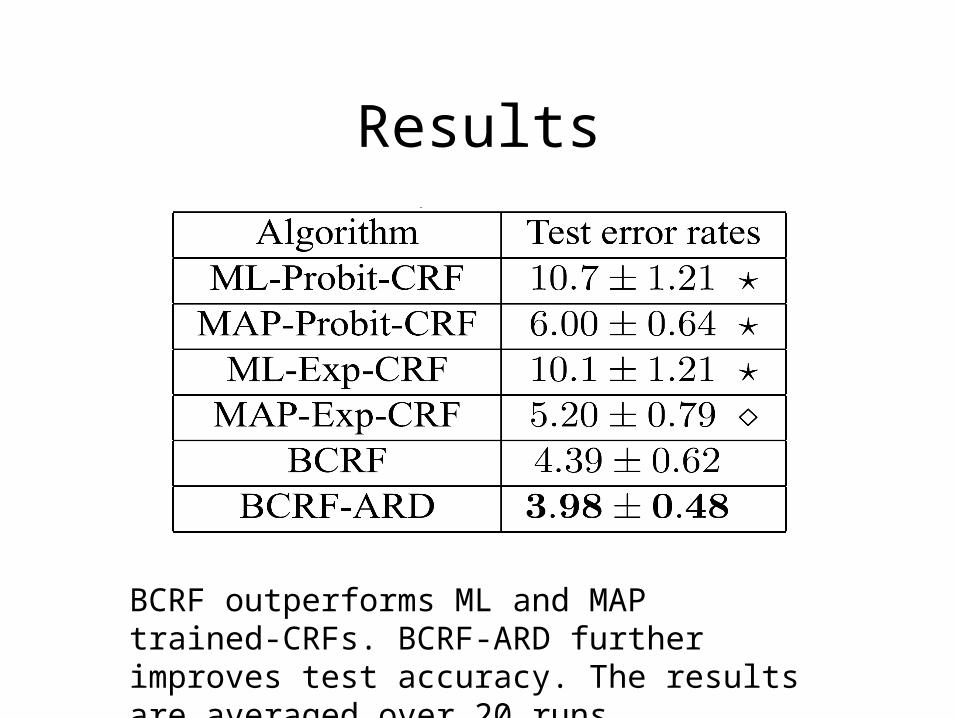
Results
BCRF outperforms ML and MAP trained-CRFs. BCRF-ARD further improves test accuracy. The results are averaged over 20 runs.

Part 2:ConclusionsBayesian CRFs:
• Model the relational data
• BCRFs improve the predictive performance over ML- and MAP-trained CRFs, especially by approximate model averaging
• ARD for CRFs enables feature selection
• More applications: image segmentation and joint scene analysis, etc.

Outline
• Background
• Bayesian classification and Predictive ARD
• Bayesian conditional random fields
• Conclusions

Conclusions
1. Predictive ARD by EP Gene expression classification: Outperformed
traditional ARD, SVM with feature selection
2. Bayesian conditional random fieldsFAQs labeling and joint diagram analysis: Beats
ML- and MAP-trained CRFs
3. Future work

END

Appendix: Sequential Updates
• EP approximates true likelihood terms by Gaussian virtual observations.
• Based on Gaussian virtual observations, the classification model becomes a regression model.
• Then, we can achieve efficient sequential updates without maintaining and updating a full covariance matrix. (Faul & Tipping 02)